
Apache Flink is an open-source, unified stream-processing and batch-processing framework. Its core is a distributed streaming data-flow engine that you can use to run real-time stream processing on high-throughput data sources. Currently, it is widely used to build applications for fraud/anomaly detection, rule-based alerting, business process monitoring, and continuous ETL to name a few. On AWS, we can deploy a Flink application via Amazon Kinesis Data Analytics (KDA), Amazon EMR and Amazon EKS. Among those, KDA is the easiest option as it provides the underlying infrastructure for your Apache Flink applications.
For those who are new to Flink (Pyflink) and KDA, AWS provides a good resource that guides how to develop a Flink application locally and deploy via KDA. The guide uses Amazon Kinesis Data Stream as a data source and demonstrates how to sink records into multiple destinations - Kinesis Data Stream, Kinesis Firehose Delivery Stream and S3. It can be found in this GitHub project.
In this series of posts, we will update one of the examples of the guide by changing the data source and sink into Apache Kafka topics. In part 1, we will discuss how to develop a Flink application that targets a local Kafka cluster. Furthermore, it will be executed in a virtual environment as well as in a local Flink cluster for improved monitoring. The Flink application will be amended to connect a Kafka cluster on Amazon MSK in part 2. The Kafka cluster will be authenticated by IAM access control, and the Flink app needs to change its configuration accordingly by creating a custom Uber Jar file. In part 3, the application will be deployed via KDA using an application package that is saved in S3. The application package is a zip file that includes the application script, custom Uber Jar file, and 3rd-party Python packages. The deployment will be made by Terraform.
- Part 1 Local Flink and Local Kafka (this post)
- Part 2 Local Flink and MSK
- Part 3 AWS Managed Flink and MSK
[Update 2023-08-30] Amazon Kinesis Data Analytics is renamed into Amazon Managed Service for Apache Flink. In this post, Kinesis Data Analytics (KDA) and Amazon Managed Service for Apache Flink will be used interchangeably.
Architecture
The Python source data generator (producer.py) sends random stock price records into a Kafka topic. The messages in the source topic are consumed by a Flink application, and it just writes those messages into a different sink topic. This is the simplest application of the AWS guide, and you may try other examples if interested.
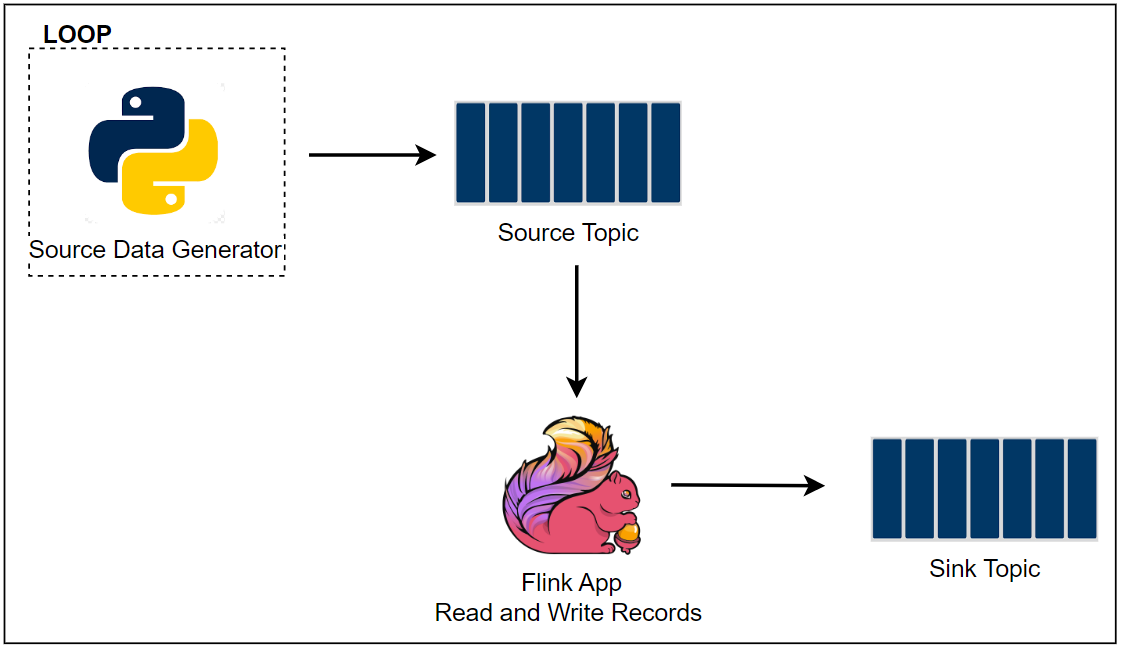
Infrastructure
A Kafka cluster and management app (Kpow) are created using Docker while the Python apps including the Flink app run in a virtual environment in the first trial. After that the Flink app is submitted to a local Flink cluster for improved monitoring. The Flink cluster is also created using Docker. The source can be found in the GitHub repository of this post.
Preparation
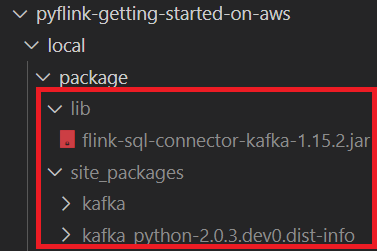
As discussed later, the Flink application needs the Apache Kafka SQL Connector artifact (flink-sql-connector-kafka-1.15.2.jar) in order to connect a Kafka cluster. Also, the kafka-python package is downloaded to check if --pyFiles option works when submitting the app to a Flink cluster or deploying via KDA. They can be downloaded by executing the following script.
1# build.sh
2#!/usr/bin/env bash
3SCRIPT_DIR="$(cd $(dirname "$0"); pwd)"
4SRC_PATH=$SCRIPT_DIR/package
5rm -rf $SRC_PATH && mkdir -p $SRC_PATH/lib
6
7## Download flink sql connector kafka
8echo "download flink sql connector kafka..."
9VERSION=1.15.2
10FILE_NAME=flink-sql-connector-kafka-$VERSION
11DOWNLOAD_URL=https://repo.maven.apache.org/maven2/org/apache/flink/flink-sql-connector-kafka/$VERSION/flink-sql-connector-kafka-$VERSION.jar
12curl -L -o $SRC_PATH/lib/$FILE_NAME.jar ${DOWNLOAD_URL}
13
14## Install pip packages
15echo "install and zip pip packages..."
16pip install -r requirements.txt --target $SRC_PATH/site_packages
17
18## Package pyflink app
19echo "package pyflink app"
20zip -r kda-package.zip processor.py package/lib package/site_packages
Once downloaded, the Kafka SQL artifact and python package can be found in the lib and site_packages folders respectively as shown below.
Kafka Cluster
A Kafka cluster with a single broker and zookeeper node is used in this post. The broker has two listeners and the port 9092 and 29092 are used for internal and external communication respectively. The default number of topic partitions is set to 2. Details about Kafka cluster setup can be found in this post.
The Kpow CE is used for ease of monitoring Kafka topics and related resources. The bootstrap server address is added as an environment variable. See this post for details about Kafka management apps.
The Kafka cluster can be started by docker-compose -f compose-kafka.yml up -d.
1# compose-kafka.yml
2version: "3.5"
3
4services:
5 zookeeper:
6 image: bitnami/zookeeper:3.5
7 container_name: zookeeper
8 ports:
9 - "2181"
10 networks:
11 - kafkanet
12 environment:
13 - ALLOW_ANONYMOUS_LOGIN=yes
14 volumes:
15 - zookeeper_data:/bitnami/zookeeper
16 kafka-0:
17 image: bitnami/kafka:2.8.1
18 container_name: kafka-0
19 expose:
20 - 9092
21 ports:
22 - "29092:29092"
23 networks:
24 - kafkanet
25 environment:
26 - ALLOW_PLAINTEXT_LISTENER=yes
27 - KAFKA_CFG_ZOOKEEPER_CONNECT=zookeeper:2181
28 - KAFKA_CFG_BROKER_ID=0
29 - KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=INTERNAL:PLAINTEXT,EXTERNAL:PLAINTEXT
30 - KAFKA_CFG_LISTENERS=INTERNAL://:9092,EXTERNAL://:29092
31 - KAFKA_CFG_ADVERTISED_LISTENERS=INTERNAL://kafka-0:9092,EXTERNAL://localhost:29092
32 - KAFKA_CFG_INTER_BROKER_LISTENER_NAME=INTERNAL
33 - KAFKA_CFG_NUM_PARTITIONS=2
34 volumes:
35 - kafka_0_data:/bitnami/kafka
36 depends_on:
37 - zookeeper
38 kpow:
39 image: factorhouse/kpow-ce:91.2.1
40 container_name: kpow
41 ports:
42 - "3000:3000"
43 networks:
44 - kafkanet
45 environment:
46 BOOTSTRAP: kafka-0:9092
47 depends_on:
48 - zookeeper
49 - kafka-0
50
51networks:
52 kafkanet:
53 name: kafka-network
54
55volumes:
56 zookeeper_data:
57 driver: local
58 name: zookeeper_data
59 kafka_0_data:
60 driver: local
61 name: kafka_0_data
Flink Cluster
In order to run a PyFlink application in a Flink cluster, we need to install Python and the apache-flink package additionally. We can create a custom Docker image based on the official Flink image. I chose the version 1.15.2 as it is the recommended Flink version by KDA. The custom image can be built by docker build -t pyflink:1.15.2-scala_2.12 ..
1FROM flink:1.15.2-scala_2.12
2
3ARG PYTHON_VERSION
4ENV PYTHON_VERSION=${PYTHON_VERSION:-3.8.10}
5ARG FLINK_VERSION
6ENV FLINK_VERSION=${FLINK_VERSION:-1.15.2}
7
8# Currently only Python 3.6, 3.7 and 3.8 are supported officially.
9RUN apt-get update -y && \
10 apt-get install -y build-essential libssl-dev zlib1g-dev libbz2-dev libffi-dev && \
11 wget https://www.python.org/ftp/python/${PYTHON_VERSION}/Python-${PYTHON_VERSION}.tgz && \
12 tar -xvf Python-${PYTHON_VERSION}.tgz && \
13 cd Python-${PYTHON_VERSION} && \
14 ./configure --without-tests --enable-shared && \
15 make -j6 && \
16 make install && \
17 ldconfig /usr/local/lib && \
18 cd .. && rm -f Python-${PYTHON_VERSION}.tgz && rm -rf Python-${PYTHON_VERSION} && \
19 ln -s /usr/local/bin/python3 /usr/local/bin/python && \
20 apt-get clean && \
21 rm -rf /var/lib/apt/lists/*
22
23# install PyFlink
24RUN pip3 install apache-flink==${FLINK_VERSION}
A Flink cluster is made up of a single Job Manger and Task Manager, and the cluster runs in the Session Mode where one or more Flink applications can be submitted/executed simultaneously. See this page for details about how to create a Flink cluster using docker-compose.
Two environment variables are configured to adjust the application behaviour. The RUNTIME_ENV is set to DOCKER, and it determines which pipeline jar and application property file to choose. Also, the BOOTSTRAP_SERVERS overrides the Kafka bootstrap server address value from the application property file. We will make use of it to configure the bootstrap server address dynamically for MSK in part 2. Finally, the current directory is volume-mapped into /etc/flink so that the application and related resources can be available in the Flink cluster.
The Flink cluster can be started by docker-compose -f compose-flink.yml up -d.
1version: "3.5"
2
3services:
4 jobmanager:
5 image: pyflink:1.15.2-scala_2.12
6 container_name: jobmanager
7 command: jobmanager
8 ports:
9 - "8081:8081"
10 networks:
11 - kafkanet
12 environment:
13 - |
14 FLINK_PROPERTIES=
15 jobmanager.rpc.address: jobmanager
16 state.backend: filesystem
17 state.checkpoints.dir: file:///tmp/flink-checkpoints
18 heartbeat.interval: 1000
19 heartbeat.timeout: 5000
20 rest.flamegraph.enabled: true
21 web.backpressure.refresh-interval: 10000
22 - RUNTIME_ENV=DOCKER
23 - BOOTSTRAP_SERVERS=kafka-0:9092
24 volumes:
25 - $PWD:/etc/flink
26 taskmanager:
27 image: pyflink:1.15.2-scala_2.12
28 container_name: taskmanager
29 command: taskmanager
30 networks:
31 - kafkanet
32 volumes:
33 - flink_data:/tmp/
34 - $PWD:/etc/flink
35 environment:
36 - |
37 FLINK_PROPERTIES=
38 jobmanager.rpc.address: jobmanager
39 taskmanager.numberOfTaskSlots: 3
40 state.backend: filesystem
41 state.checkpoints.dir: file:///tmp/flink-checkpoints
42 heartbeat.interval: 1000
43 heartbeat.timeout: 5000
44 - RUNTIME_ENV=DOCKER
45 - BOOTSTRAP_SERVERS=kafka-0:9092
46 depends_on:
47 - jobmanager
48
49networks:
50 kafkanet:
51 external: true
52 name: kafka-network
53
54volumes:
55 flink_data:
56 driver: local
57 name: flink_data
Virtual Environment
As mentioned earlier, all Python apps run in a virtual environment, and we have the following pip packages. We use the version 1.15.2 of the apache-flink package because it is the recommended version by KDA. We also need the kafka-python package for source data generation. The pip packages can be installed by pip install -r requirements-dev.txt.
1# requirements.txt
2kafka-python==2.0.2
3
4# requirements-dev.txt
5-r requirements.txt
6apache-flink==1.15.2
7black==19.10b0
8pytest
9pytest-cov
Application
Source Data
A single Python script is created to generate fake stock price records. The class for the stock record has the asdict, auto and create methods. The create method generates a list of records where each element is instantiated by the auto method. Those records are sent into the relevant Kafka topic after being converted into a dictionary by the asdict method.
A Kafka producer is created as an attribute of the Producer class. The source records are sent into the relevant topic by the send method. Note that both the key and value of the messages are serialized as json.
The data generator can be started simply by python producer.py.
1# producer.py
2import os
3import datetime
4import time
5import json
6import typing
7import random
8import logging
9import dataclasses
10
11from kafka import KafkaProducer
12
13logging.basicConfig(
14 level=logging.INFO,
15 format="%(asctime)s.%(msecs)03d:%(levelname)s:%(name)s:%(message)s",
16 datefmt="%Y-%m-%d %H:%M:%S",
17)
18
19datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S.%f")
20
21
22@dataclasses.dataclass
23class Stock:
24 event_time: str
25 ticker: str
26 price: float
27
28 def asdict(self):
29 return dataclasses.asdict(self)
30
31 @classmethod
32 def auto(cls, ticker: str):
33 # event_time = datetime.datetime.now().isoformat(timespec="milliseconds")
34 event_time = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S.%f")
35 price = round(random.random() * 100, 2)
36 return cls(event_time, ticker, price)
37
38 @staticmethod
39 def create():
40 tickers = '["AAPL", "ACN", "ADBE", "AMD", "AVGO", "CRM", "CSCO", "IBM", "INTC", "MA", "MSFT", "NVDA", "ORCL", "PYPL", "QCOM", "TXN", "V"]'
41 return [Stock.auto(ticker) for ticker in json.loads(tickers)]
42
43
44class Producer:
45 def __init__(self, bootstrap_servers: list, topic: str):
46 self.bootstrap_servers = bootstrap_servers
47 self.topic = topic
48 self.producer = self.create()
49
50 def create(self):
51 return KafkaProducer(
52 bootstrap_servers=self.bootstrap_servers,
53 key_serializer=lambda v: json.dumps(v, default=self.serialize).encode("utf-8"),
54 value_serializer=lambda v: json.dumps(v, default=self.serialize).encode("utf-8"),
55 )
56
57 def send(self, stocks: typing.List[Stock]):
58 for stock in stocks:
59 try:
60 self.producer.send(self.topic, key={"ticker": stock.ticker}, value=stock.asdict())
61 except Exception as e:
62 raise RuntimeError("fails to send a message") from e
63 self.producer.flush()
64
65 def serialize(self, obj):
66 if isinstance(obj, datetime.datetime):
67 return obj.isoformat()
68 if isinstance(obj, datetime.date):
69 return str(obj)
70 return obj
71
72
73if __name__ == "__main__":
74 producer = Producer(
75 bootstrap_servers=os.getenv("BOOTSTRAP_SERVERS", "localhost:29092").split(","),
76 topic=os.getenv("TOPIC_NAME", "stocks-in"),
77 )
78 max_run = int(os.getenv("MAX_RUN", "-1"))
79 logging.info(f"max run - {max_run}")
80 current_run = 0
81 while True:
82 current_run += 1
83 logging.info(f"current run - {current_run}")
84 if current_run - max_run == 0:
85 logging.info(f"reached max run, finish")
86 producer.producer.close()
87 break
88 producer.send(Stock.create())
89 secs = random.randint(5, 10)
90 logging.info(f"messages sent... wait {secs} seconds")
91 time.sleep(secs)
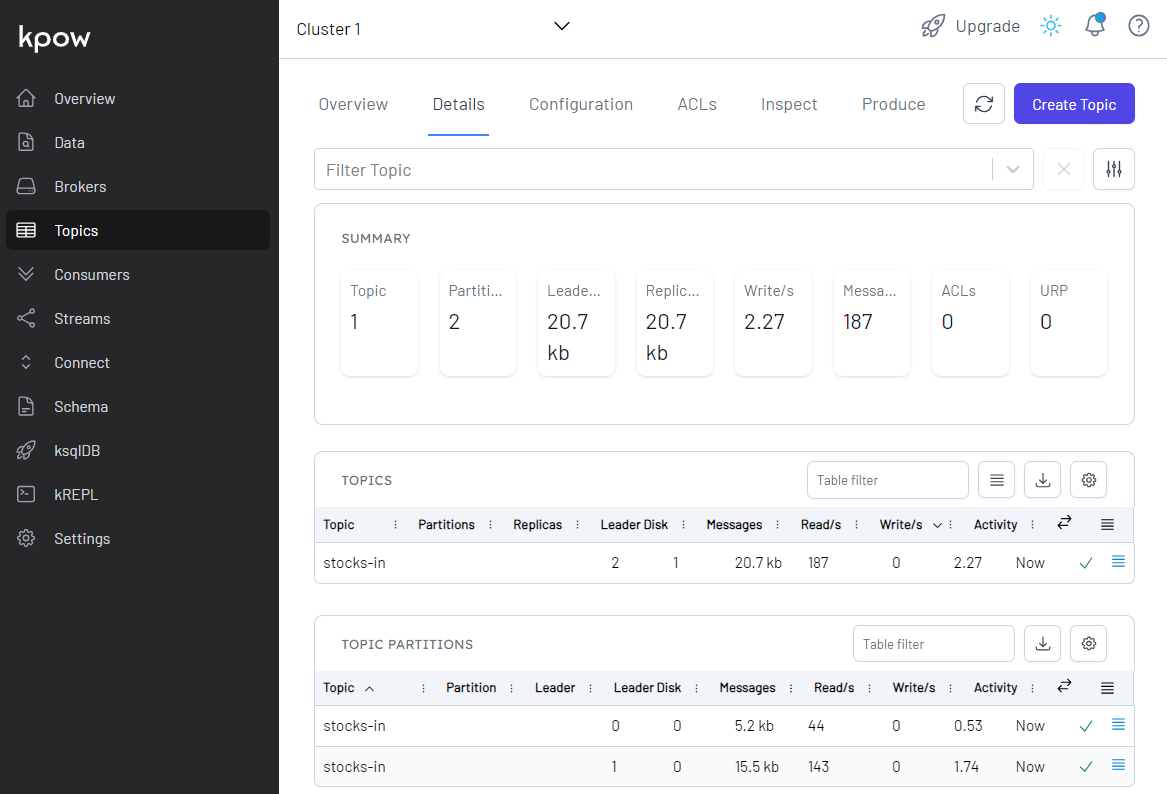
Once we start the app, we can check the topic for the source data is created and messages are ingested in Kpow.
Process Data
The Flink application is built using the Table API. We have two Kafka topics - one for the source and the other for the sink. Simply put, we can manipulate the records of the topics as tables of unbounded real-time streams with the Table API. In order to read/write records from/to a Kafka topic, we need to specify the Apache Kafka SQL Connector artifact that we downloaded earlier as the pipeline jar. Note we only need to configure the connector jar when we develop the app locally as the jar file will be specified by the --jarfile option when submitting it to a Flink cluster or deploying via KDA. We also need the application properties file (application_properties.json) in order to be comparable with KDA. The file contains the Flink runtime options in KDA as well as application specific properties. All the properties should be specified when deploying via KDA and, for local development, we keep them as a json file and only the application specific properties are used.
The tables for the source and output topics can be created using SQL with options that are related to the Kafka connector. Key options cover the connector name (connector), topic name (topic), bootstrap server address (properties.bootstrap.servers) and format (format). See the connector document for more details about the connector configuration. When it comes to inserting the source records into the output table, we can use either SQL or built-in add_insert method.
In the main method, we create all the source and sink tables after mapping relevant application properties. Then the output records are inserted into the output Kafka topic. Note that the output records are printed in the terminal additionally when the app is running locally for ease of checking them.
1# processor.py
2import os
3import json
4import re
5import logging
6
7import kafka # check if --pyFiles works
8from pyflink.table import EnvironmentSettings, TableEnvironment
9
10logging.basicConfig(
11 level=logging.INFO,
12 format="%(asctime)s.%(msecs)03d:%(levelname)s:%(name)s:%(message)s",
13 datefmt="%Y-%m-%d %H:%M:%S",
14)
15
16RUNTIME_ENV = os.environ.get("RUNTIME_ENV", "KDA") # KDA, DOCKER, LOCAL
17BOOTSTRAP_SERVERS = os.environ.get("BOOTSTRAP_SERVERS") # overwrite app config
18
19logging.info(f"runtime environment - {RUNTIME_ENV}...")
20
21env_settings = EnvironmentSettings.in_streaming_mode()
22table_env = TableEnvironment.create(env_settings)
23
24APPLICATION_PROPERTIES_FILE_PATH = (
25 "/etc/flink/application_properties.json" # on kda or docker-compose
26 if RUNTIME_ENV != "LOCAL"
27 else "application_properties.json"
28)
29
30if RUNTIME_ENV != "KDA":
31 # on non-KDA, multiple jar files can be passed after being delimited by a semicolon
32 CURRENT_DIR = os.path.dirname(os.path.realpath(__file__))
33 PIPELINE_JAR = "flink-sql-connector-kafka-1.15.2.jar"
34 table_env.get_config().set(
35 "pipeline.jars", f"file://{os.path.join(CURRENT_DIR, 'package', 'lib', PIPELINE_JAR)}"
36 )
37logging.info(f"app properties file path - {APPLICATION_PROPERTIES_FILE_PATH}")
38
39
40def get_application_properties():
41 if os.path.isfile(APPLICATION_PROPERTIES_FILE_PATH):
42 with open(APPLICATION_PROPERTIES_FILE_PATH, "r") as file:
43 contents = file.read()
44 properties = json.loads(contents)
45 return properties
46 else:
47 raise RuntimeError(f"A file at '{APPLICATION_PROPERTIES_FILE_PATH}' was not found")
48
49
50def property_map(props: dict, property_group_id: str):
51 for prop in props:
52 if prop["PropertyGroupId"] == property_group_id:
53 return prop["PropertyMap"]
54
55
56def create_source_table(
57 table_name: str, topic_name: str, bootstrap_servers: str, startup_mode: str
58):
59 stmt = f"""
60 CREATE TABLE {table_name} (
61 event_time TIMESTAMP(3),
62 ticker VARCHAR(6),
63 price DOUBLE
64 )
65 WITH (
66 'connector' = 'kafka',
67 'topic' = '{topic_name}',
68 'properties.bootstrap.servers' = '{bootstrap_servers}',
69 'properties.group.id' = 'source-group',
70 'format' = 'json',
71 'scan.startup.mode' = '{startup_mode}'
72 )
73 """
74 logging.info("source table statement...")
75 logging.info(stmt)
76 return stmt
77
78
79def create_sink_table(table_name: str, topic_name: str, bootstrap_servers: str):
80 stmt = f"""
81 CREATE TABLE {table_name} (
82 event_time TIMESTAMP(3),
83 ticker VARCHAR(6),
84 price DOUBLE
85 )
86 WITH (
87 'connector' = 'kafka',
88 'topic' = '{topic_name}',
89 'properties.bootstrap.servers' = '{bootstrap_servers}',
90 'format' = 'json',
91 'key.format' = 'json',
92 'key.fields' = 'ticker',
93 'properties.allow.auto.create.topics' = 'true'
94 )
95 """
96 logging.info("sint table statement...")
97 logging.info(stmt)
98 return stmt
99
100
101def create_print_table(table_name: str):
102 return f"""
103 CREATE TABLE {table_name} (
104 event_time TIMESTAMP(3),
105 ticker VARCHAR(6),
106 price DOUBLE
107 )
108 WITH (
109 'connector' = 'print'
110 )
111 """
112
113
114def main():
115 ## map consumer/producer properties
116 props = get_application_properties()
117 # consumer
118 consumer_property_group_key = "consumer.config.0"
119 consumer_properties = property_map(props, consumer_property_group_key)
120 consumer_table_name = consumer_properties["table.name"]
121 consumer_topic_name = consumer_properties["topic.name"]
122 consumer_bootstrap_servers = BOOTSTRAP_SERVERS or consumer_properties["bootstrap.servers"]
123 consumer_startup_mode = consumer_properties["startup.mode"]
124 # producer
125 producer_property_group_key = "producer.config.0"
126 producer_properties = property_map(props, producer_property_group_key)
127 producer_table_name = producer_properties["table.name"]
128 producer_topic_name = producer_properties["topic.name"]
129 producer_bootstrap_servers = BOOTSTRAP_SERVERS or producer_properties["bootstrap.servers"]
130 # print
131 print_table_name = "sink_print"
132 ## create a souce table
133 table_env.execute_sql(
134 create_source_table(
135 consumer_table_name,
136 consumer_topic_name,
137 consumer_bootstrap_servers,
138 consumer_startup_mode,
139 )
140 )
141 ## create sink tables
142 table_env.execute_sql(
143 create_sink_table(producer_table_name, producer_topic_name, producer_bootstrap_servers)
144 )
145 table_env.execute_sql(create_print_table("sink_print"))
146 ## insert into sink tables
147 if RUNTIME_ENV == "LOCAL":
148 source_table = table_env.from_path(consumer_table_name)
149 statement_set = table_env.create_statement_set()
150 statement_set.add_insert(producer_table_name, source_table)
151 statement_set.add_insert(print_table_name, source_table)
152 statement_set.execute().wait()
153 else:
154 table_result = table_env.execute_sql(
155 f"INSERT INTO {producer_table_name} SELECT * FROM {consumer_table_name}"
156 )
157 logging.info(table_result.get_job_client().get_job_status())
158
159
160if __name__ == "__main__":
161 main()
1// application_properties.json
2[
3 {
4 "PropertyGroupId": "kinesis.analytics.flink.run.options",
5 "PropertyMap": {
6 "python": "processor.py",
7 "jarfile": "package/lib/flink-sql-connector-kinesis-1.15.2.jar",
8 "pyFiles": "package/site_packages/"
9 }
10 },
11 {
12 "PropertyGroupId": "consumer.config.0",
13 "PropertyMap": {
14 "table.name": "source_table",
15 "topic.name": "stocks-in",
16 "bootstrap.servers": "localhost:29092",
17 "startup.mode": "earliest-offset"
18 }
19 },
20 {
21 "PropertyGroupId": "producer.config.0",
22 "PropertyMap": {
23 "table.name": "sink_table",
24 "topic.name": "stocks-out",
25 "bootstrap.servers": "localhost:29092"
26 }
27 }
28]
Run Locally
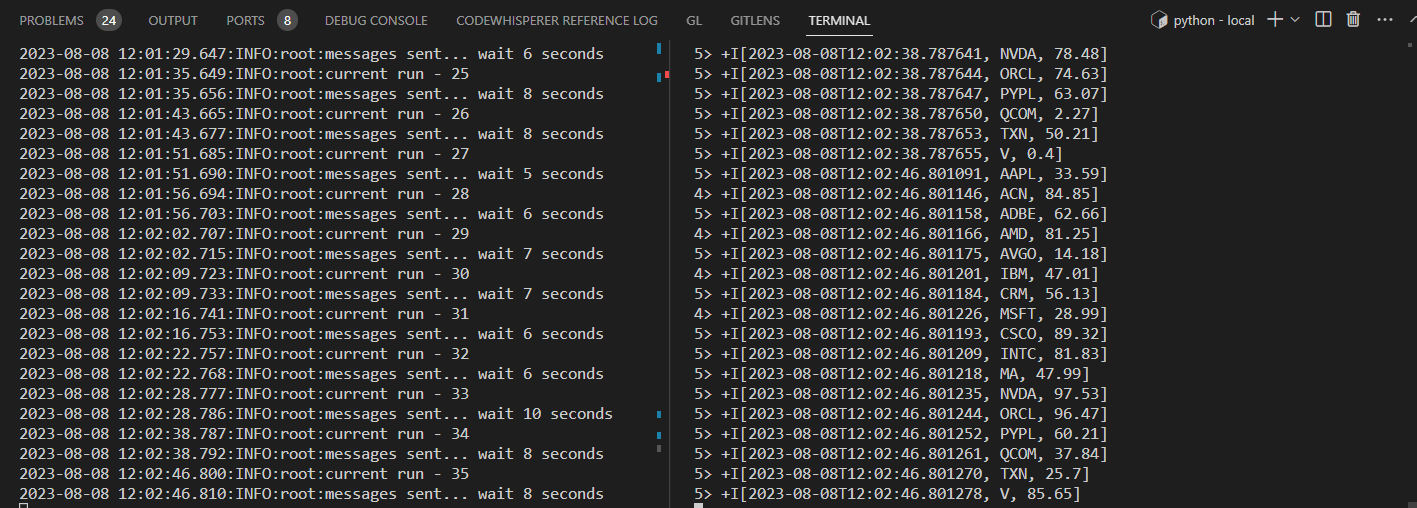
We can run the app locally as following - RUNTIME_ENV=LOCAL python processor.py. The terminal on the right-hand side shows the output records of the Flink app while the left-hand side records logs of the producer app. We can see that the print output from the Flink app gets updated when new source records are sent into the source topic by the producer app.
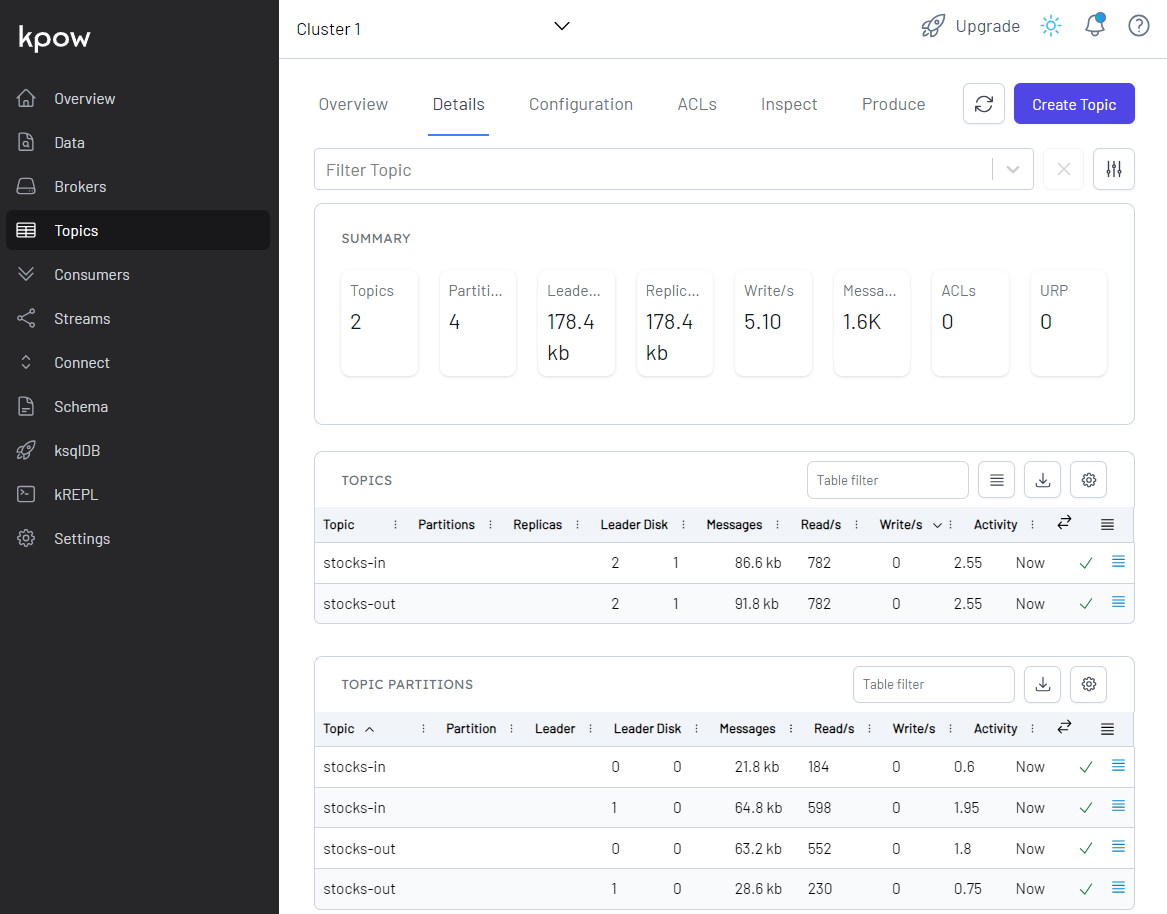
We can also see details of all the topics in Kpow as shown below. The total number of messages matches between the source and output topics but not within partitions.
Run in Flink Cluster
The execution in a terminal is limited for monitoring, and we can inspect and understand what is happening inside Flink using the Flink Web UI. For this, we need to submit the app to the Flink cluster we created earlier. Typically, a Pyflink app can be submitted using the CLI interface by specifying the main application (–python), Kafka connector artifact file (–jarfile), and 3rd-party Python packages (–pyFiles) if necessary. Once submitted, it shows the status with the job ID.
1$ docker exec jobmanager /opt/flink/bin/flink run \
2 --python /etc/flink/processor.py \
3 --jarfile /etc/flink/package/lib/flink-sql-connector-kafka-1.15.2.jar \
4 --pyFiles /etc/flink/package/site_packages/ \
5 -d
62023-08-08 02:07:13.220:INFO:root:runtime environment - DOCKER...
72023-08-08 02:07:14.341:INFO:root:app properties file path - /etc/flink/application_properties.json
82023-08-08 02:07:14.341:INFO:root:source table statement...
92023-08-08 02:07:14.341:INFO:root:
10 CREATE TABLE source_table (
11 event_time TIMESTAMP(3),
12 ticker VARCHAR(6),
13 price DOUBLE
14 )
15 WITH (
16 'connector' = 'kafka',
17 'topic' = 'stocks-in',
18 'properties.bootstrap.servers' = 'kafka-0:9092',
19 'properties.group.id' = 'source-group',
20 'format' = 'json',
21 'scan.startup.mode' = 'earliest-offset'
22 )
23
242023-08-08 02:07:14.439:INFO:root:sint table statement...
252023-08-08 02:07:14.439:INFO:root:
26 CREATE TABLE sink_table (
27 event_time TIMESTAMP(3),
28 ticker VARCHAR(6),
29 price DOUBLE
30 )
31 WITH (
32 'connector' = 'kafka',
33 'topic' = 'stocks-out',
34 'properties.bootstrap.servers' = 'kafka-0:9092',
35 'format' = 'json',
36 'key.format' = 'json',
37 'key.fields' = 'ticker',
38 'properties.allow.auto.create.topics' = 'true'
39 )
40
41WARNING: An illegal reflective access operation has occurred
42WARNING: Illegal reflective access by org.apache.flink.api.java.ClosureCleaner (file:/opt/flink/lib/flink-dist-1.15.4.jar) to field java.lang.String.value
43WARNING: Please consider reporting this to the maintainers of org.apache.flink.api.java.ClosureCleaner
44WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations
45WARNING: All illegal access operations will be denied in a future release
46Job has been submitted with JobID 02d83c46d646aa498a986c0a9335e276
472023-08-08 02:07:23.010:INFO:root:java.util.concurrent.CompletableFuture@34e729a3[Not completed]
We can check the submitted job by listing all jobs as shown below.
1$ docker exec jobmanager /opt/flink/bin/flink list
2Waiting for response...
3------------------ Running/Restarting Jobs -------------------
408.08.2023 02:07:18 : 02d83c46d646aa498a986c0a9335e276 : insert-into_default_catalog.default_database.sink_table (RUNNING)
5--------------------------------------------------------------
6No scheduled jobs.
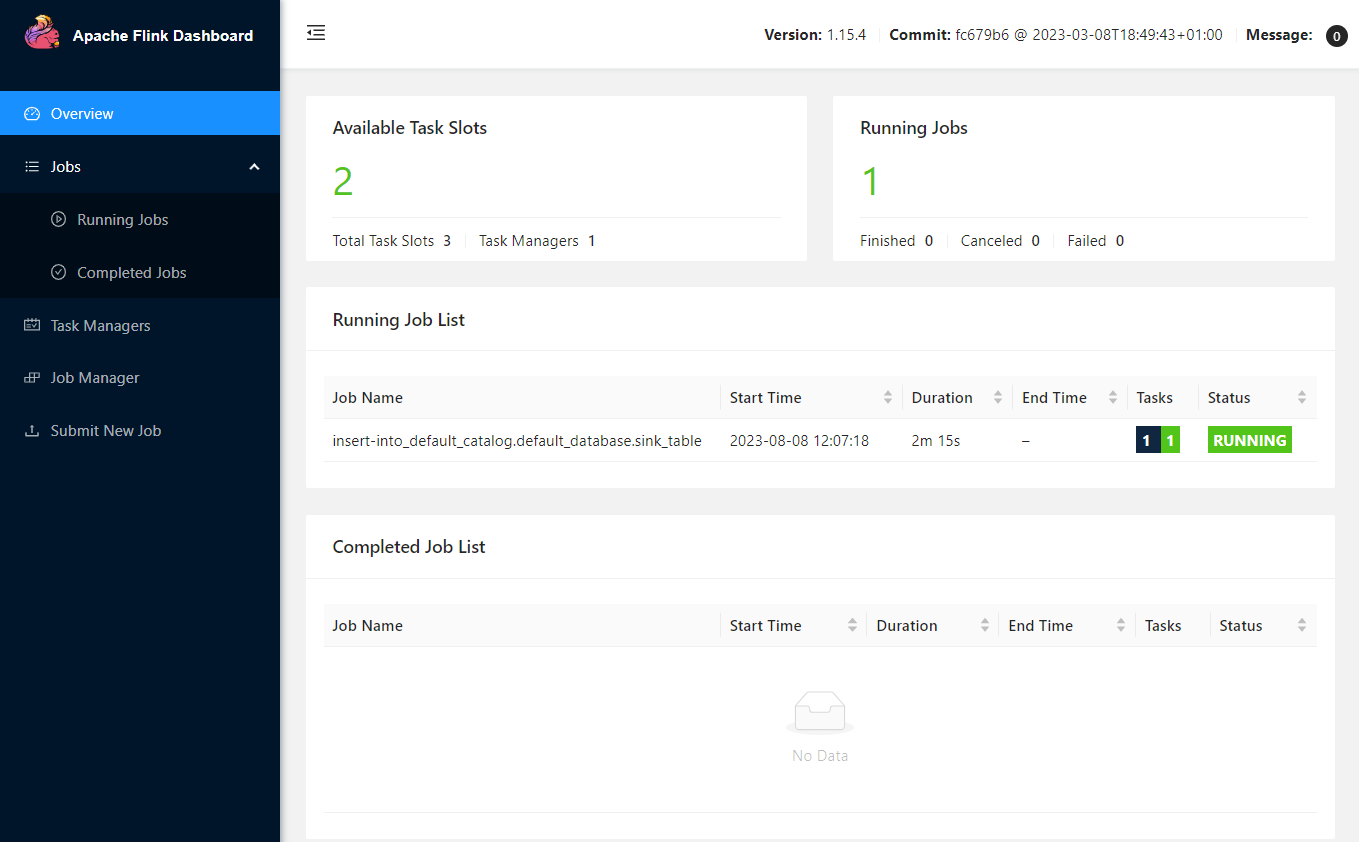
The Flink Web UI can be accessed on port 8081. In the Overview section, it shows the available task slots, running jobs and completed jobs.
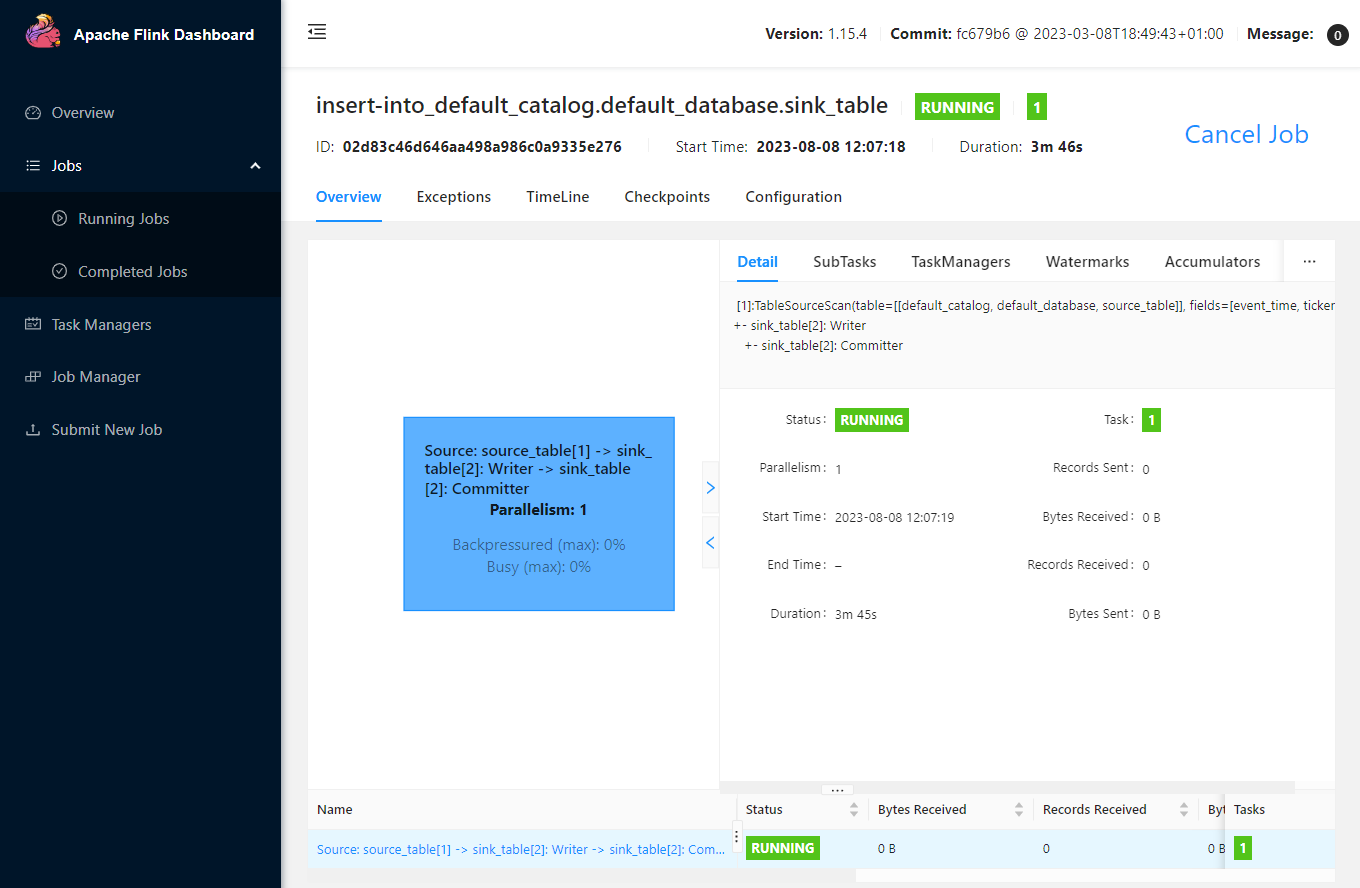
We can inspect an individual job in the Jobs menu. It shows key details about a job execution in Overview, Exceptions, TimeLine, Checkpoints and Configuration tabs.
We can cancel a job on the web UI or using the CLI. Below shows how to cancel the job we submitted earlier using the CLI.
1$ docker exec jobmanager /opt/flink/bin/flink cancel 02d83c46d646aa498a986c0a9335e276
2Cancelling job 02d83c46d646aa498a986c0a9335e276.
3Cancelled job 02d83c46d646aa498a986c0a9335e276.
Summary
Apache Flink is widely used for building real-time stream processing applications. On AWS, Kinesis Data Analytics (KDA) is the easiest option to develop a Flink app as it provides the underlying infrastructure. Updating a guide from AWS, this series of posts discuss how to develop and deploy a Flink (Pyflink) application via KDA where the data source and sink are Kafka topics. In part 1, the app was developed locally targeting a Kafka cluster created by Docker. Furthermore, it was executed in a virtual environment as well as in a local Flink cluster for improved monitoring.










Comments