We discuss how to set up a Spark cluser between 2 Ubuntu guests. Firstly it begins with machine preparation. Once a machine is baked, its image file (VDI) is be copied for the second one. Then how to launch a cluster by standalone mode is discussed. Let’s get started.
Machine preparation
If you haven’t read the previous post, I recommend reading as it introduces Putty as well. Also, as Spark need Java Development Kit (JDK), you may need to apt-get it first - see this tutorial for further details.
I downloaded Spark 1.6.0 Pre-built for Hadoop 2.6 and later and unpacked it in my user directory as following.
cd ~
wget http://www.us.apache.org/dist/spark/spark-1.6.0/spark-1.6.0-bin-hadoop2.6.tgz
tar zxvf spark-*.tgz
mv ./spark*/ spark
Then I prepared ‘password-less’ SSH access (no passphrase) from the master machine to the other by generating a ssh key.
mkdir .ssh
ssh-keygen -t rsa
Enter file in which to save the key (/home/you/.ssh/id_rsa): [ENTER]
Enter passphrase (empty for no passphrase): [EMPTY]
Enter same passphrase again: [EMPTY]
You will see two files id_rsa (private key) and id_rsa.pub (public key) in .ssh folder. The public key was added to a file called authorized_keys as following.
cd .ssh
cat id_rsa.pub >> authorized_keys
chmod 644 authorized_keys
Note that, by now, there is only a single machine but its image file will be copied shortly to be used as a slave machine. Therefore adding a public key to the authorized_keys file will be convenient.
Set up guest machines
I named the baked machine’s image file as spark-master.vdi and copied it as spark-slave.vdi. When I tried to create a virtual machine with the new image, the following error was encountered, which indicates duplicate UUIDs.
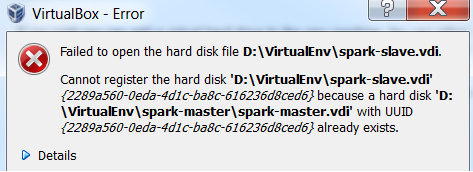
This was resolved by setting a differnet UUID using VBOXMANAGE.EXE. On my Windows (host) CMD, I did the following and it was possible to create a virtual machine from the copied image.
cd "C:\Program Files\Oracle\VirtualBox"
VBOXMANAGE.EXE internalcommands sethduuid "D:\VirtualEnv\spark-slave.vdi"
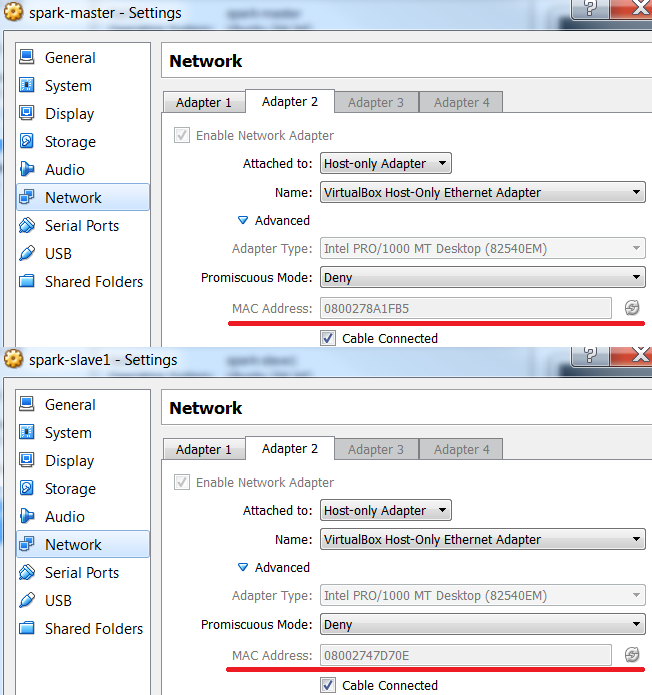
As in the previous post, I set up 2 network adapters - Bridged Adapter and Host-only Adapter. The latter lets a virtual machine to have a static IP. As the second image is copied from the first, both have the same IP address, which can be problematic. They can have different IP addresses by letting them have different MAC addresses. (Note the refresh button in the right.)
In my case, the master and slave machine’s IP addresses are set up to be 192.168.1.8 and 192.168.1.11.
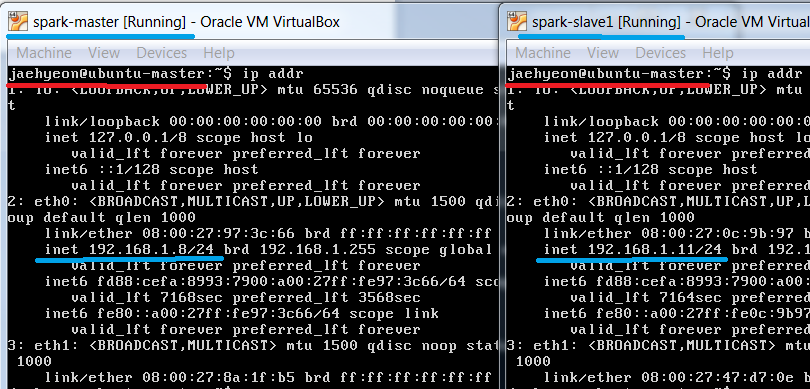
Also they have the same host name: ubuntu-master. It’d be necessary to change the slave machine’s host name. I modified the host name in /etc/hostname and /etc/hosts. Basically I changed any ubuntu-master in those files to ubuntu-slave1 and restarted the machine - see further details Note this requires root privilege.
The updated host name is shown below in the right.

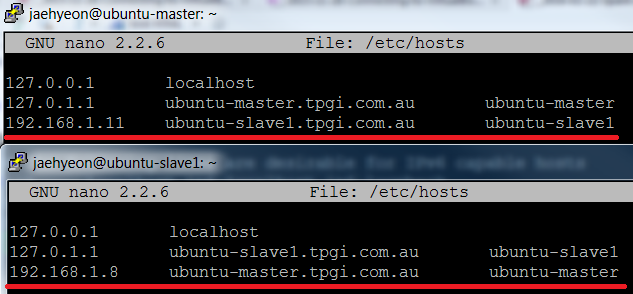
Finally I added slave’s host information to the master’s /etc/hosts and did the other way around to the slave’s file.
Standalone mode setup
Firstly I added the slave machine’s host name to the master’s slaves file in ~/spark/conf as following.
cd ~/spark/conf/
cp slaves.template slaves
I just commented localhost, which is in the last line and added the slave’s host name. i.e.
#localhost
ubuntu-slave1
Then I updated spark-env.sh file on each of the machines.
cp spark-env.sh.template spark-env.sh
And, for the master, I added the following
JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64
export SPARK_MASTER_IP=192.168.1.8
export SPARK_WORKER_CORES=1
export SPARK_WORKER_INSTANCES=1
export SPARK_MASTER_PORT=7077
export SPARK_WORKER_MEMORY=4g
export MASTER=spark://${SPARK_MASTER_IP}:${SPARK_MASTER_PORT}
export SPARK_LOCAL_IP=192.168.1.8
and, for the slave,
JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64
export SPARK_MASTER_IP=192.168.1.8
export SPARK_WORKER_CORES=1
export SPARK_WORKER_INSTANCES=1
export SPARK_MASTER_PORT=7077
export SPARK_WORKER_MEMORY=4g
export MASTER=spark://${SPARK_MASTER_IP}:${SPARK_MASTER_PORT}
export SPARK_LOCAL_IP=192.168.1.11
That’s it. By executing the following command, I was able to create a Spark cluster and to check the status of the cluster on the web UI.
~/spark/sbin/start-all.sh
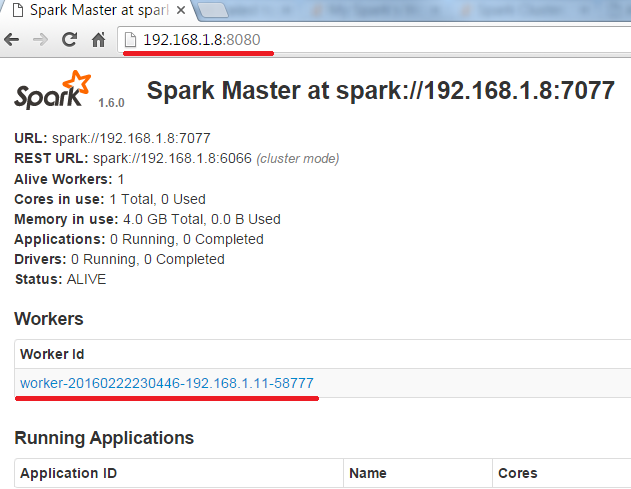
I hope this post is useful.
Comments