
While I’m looking into Apache Airflow, a workflow management tool, I thought it would be beneficial to get some understanding of how Celery works. To do so, I built a simple web service that sends tasks to Celery workers and collects the results from them. FastAPI is used for developing the web service and Redis is used for the message broker and result backend. During the development, I thought it would be possible to implement similar functionality in R with Rserve. Therefore a Rserve worker is added as an example as well. Coupling a web service with distributed task queue is beneficial on its own as it helps the service be more responsive by offloading heavyweight and long running processes to task workers.
In this post, it’ll be illustrated how a web service is created using FastAPI framework where tasks are sent to multiple workers. The workers are built with Celery and Rserve. Redis is used as a message broker/result backend for Celery and a key-value store for Rserve. Demos can be run in both Docker Compose and Kubernetes.
The following diagram shows how the apps work together and the source can be found in this GitHub repository.
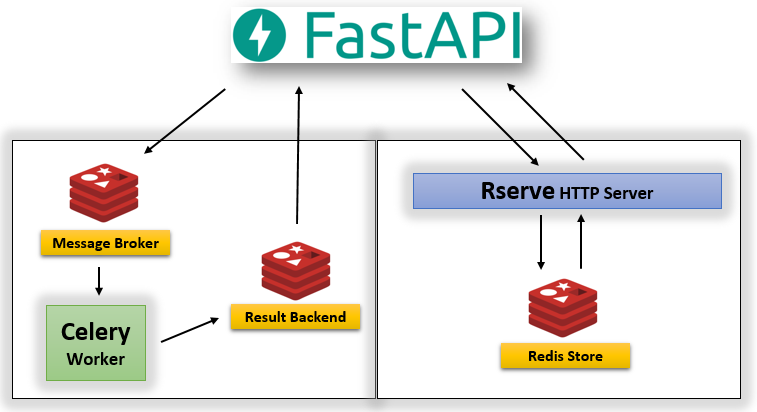
Celery Worker
The source of the Celery app and task is shown below - /queue_celery/tasks.py. The same Redis DB is used as the message broker and result backend. The task is nothing but iterating to total - the value is from a request. In each iteration, it updates its state (bind=True) followed by sleeping for 1 second and it is set that a task can be sent by referring to its name (name="long_task").
1import os
2import math
3import time
4from celery import Celery
5
6redis_url = "redis://{0}:{1}/{2}".format(
7 os.environ["REDIS_HOST"], os.environ["REDIS_PORT"], os.environ["REDIS_DB"]
8)
9
10app = Celery("tasks", backend=redis_url, broker=redis_url)
11app.conf.update(broker_transport_options={"visibility_timeout": 3600})
12
13
14@app.task(bind=True, name="long_task")
15def long_task(self, total):
16 message = ""
17 for i in range(total):
18 message = "Percentage completion {0} ...".format(math.ceil(i / total * 100))
19 self.update_state(state="PROGRESS", meta={"current": i, "total": total, "status": message})
20 time.sleep(1)
21 return {"current": total, "total": total, "status": "Task completed!", "result": total}
Rserve Worker
redux package, Redis client for R, and RSclient package, R-based client for Rserve, are used to set up the Rserve worker. The function RR() checks if a Redis DB is available and returns a hiredis object, which is an interface to Redis. The task (long_task()) is constructed to be similar to the Celery task. In order for the task to be executed asynchronously, a handler function (handle_long_task()) is used to receive a request from the main web service. Once called, the task function is sent to be evaluated by a Rserve client (RS.eval()) - note wait=FALSE and lazy=TRUE. Its evaluation is asynchronous as the task function is run by a separate forked process. Finally the status of a task can be obtained by get_task() and it pulls the status output from the Redis DB - note a R list is converted as binary. The source of the Rserve worker can be found in /queue_rserve/tasks.R.
1RR <- function(check_conn_only = FALSE) {
2 redis_host <- Sys.getenv("REDIS_HOST", "localhost")
3 redis_port <- Sys.getenv("REDIS_PORT", "6379")
4 redis_db <- Sys.getenv("REDIS_DB", "1")
5 info <- sprintf("host %s, port %s, db %s", redis_host, redis_port, redis_db)
6 ## check if redis is available
7 is_available = redis_available(host=redis_host, port=redis_port, db=redis_db)
8 if (is_available) {
9 flog.info(sprintf("Redis is available - %s", info))
10 } else {
11 flog.error(sprintf("Redis is not available - %s", info))
12 }
13 ## create an interface to redis
14 if (!check_conn_only) {
15 return(hiredis(host=redis_host, port=redis_port, db=redis_db))
16 }
17}
18
19
20long_task <- function(task_id, total) {
21 rr <- RR()
22 for (i in seq.int(total)) {
23 is_total <- i == max(seq.int(total))
24 state <- if (is_total) "SUCESS" else "PROGRESS"
25 msg <- sprintf("Percent completion %s ...", ceiling(i / total * 100))
26 val <- list(state = state, current = i, total = total, status = msg)
27 if (is_total) {
28 val <- append(val, list(result = total))
29 }
30 flog.info(sprintf("task id: %s, message: %s", task_id, msg))
31 rr$SET(task_id, object_to_bin(val))
32 Sys.sleep(1)
33 }
34}
35
36
37handle_long_task <- function(task_id, total) {
38 flog.info(sprintf("task started, task_id - %s, total - %s", task_id, total))
39 conn <- RS.connect()
40 RS.eval(conn, library(redux))
41 RS.eval(conn, library(futile.logger))
42 RS.eval(conn, setwd("/home/app"))
43 RS.eval(conn, source("./tasks.R"))
44 RS.assign(conn, task_id)
45 RS.assign(conn, total)
46 RS.eval(conn, long_task(task_id, total), wait=FALSE, lazy=TRUE)
47 RS.close(conn)
48 flog.info(sprintf("task executed, task_id - %s, total - %s", task_id, total))
49 list(task_id = task_id, status = "created")
50}
51
52get_task <- function(task_id) {
53 rr <- RR()
54 val <- bin_to_object(rr$GET(task_id))
55 flog.info(sprintf("task id - %s", task_id))
56 flog.info(val)
57 val
58}
Main Web Service
The main service has 2 methods for each of the workers - POST for executing a task and GET for collecting its status. To execute a task, a value named total is required in request body. As soon as a task is sent or requested, it returns the task ID and status value - ExecuteResp. A task’s status can be obtained by calling the associating collect method with its ID in query string. The response is defined by ResultResp. The source of the Rserve worker can be found in /main.py.
1import os
2import json
3import httpx
4from uuid import uuid4
5from fastapi import FastAPI, Body, HTTPException
6from pydantic import BaseModel, Schema
7
8from queue_celery.tasks import app as celery_app, long_task
9
10
11def set_rserve_url(fname):
12 return "http://{0}:{1}/{2}".format(
13 os.getenv("RSERVE_HOST", "localhost"), os.getenv("RSERVE_PORT", "8000"), fname
14 )
15
16
17app = FastAPI(title="FastAPI Job Queue Example", version="0.0.1")
18
19
20class ExecuteResp(BaseModel):
21 task_id: str
22 status: str
23
24
25class ResultResp(BaseModel):
26 current: int
27 total: int
28 status: str
29 result: int = None
30
31
32class ErrorResp(BaseModel):
33 detail: str
34
35
36@app.post("/celery/execute", response_model=ExecuteResp, status_code=202, tags=["celery"])
37async def execute_celery_task(total: int = Body(..., min=1, max=50, embed=True)):
38 task = celery_app.send_task("long_task", args=[total])
39 return {"task_id": task.id, "status": "created"}
40
41
42@app.get(
43 "/celery/collect",
44 response_model=ResultResp,
45 responses={500: {"model": ErrorResp}},
46 tags=["celery"],
47)
48async def collect_celery_result(task_id: str):
49 resp = long_task.AsyncResult(task_id)
50 if resp.status == "FAILURE":
51 raise HTTPException(status_code=500, detail="Fails to collect result")
52 return resp.result
53
54
55@app.post("/rserve/execute", response_model=ExecuteResp, status_code=202, tags=["rserve"])
56async def execute_rserve_task(total: int = Body(..., min=1, max=50, embed=True)):
57 jsn = json.dumps({"task_id": str(uuid4()), "total": total})
58 async with httpx.AsyncClient() as client:
59 r = await client.post(set_rserve_url("handle_long_task"), json=jsn)
60 return r.json()
61
62
63@app.get(
64 "/rserve/collect",
65 response_model=ResultResp,
66 responses={500: {"model": ErrorResp}},
67 tags=["rserve"],
68)
69async def collect_rserve_task(task_id: str):
70 jsn = json.dumps({"task_id": task_id})
71 async with httpx.AsyncClient() as client:
72 try:
73 r = await client.post(set_rserve_url("get_task"), json=jsn)
74 return {k: v for k, v in r.json().items() if k != "state"}
75 except Exception:
76 raise HTTPException(status_code=500, detail="Fails to collect result")
Docker Compose
The apps can be started with Docker Compose as following - the compose file can be found here.
1git clone https://github.com/jaehyeon-kim/k8s-job-queue.git
2cd k8s-job-queue
3docker-compose up -d
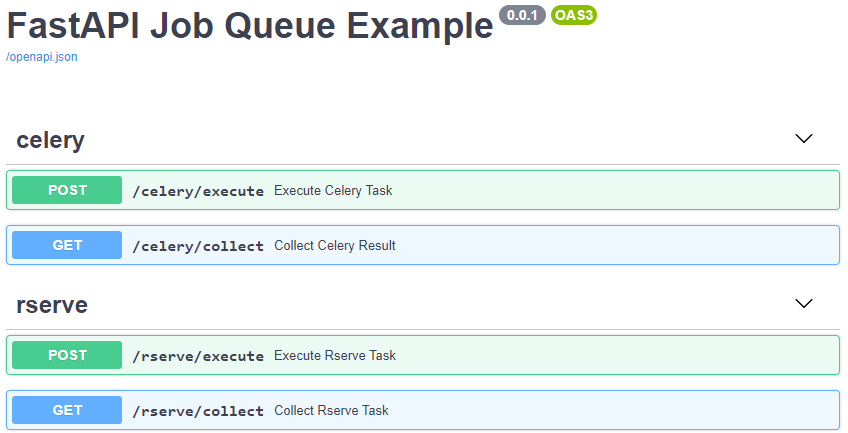
The swagger document of the main web service can be visited via http://localhost:9000/docs or http://<vm-ip-address>:9000 if it’s started in a VM.
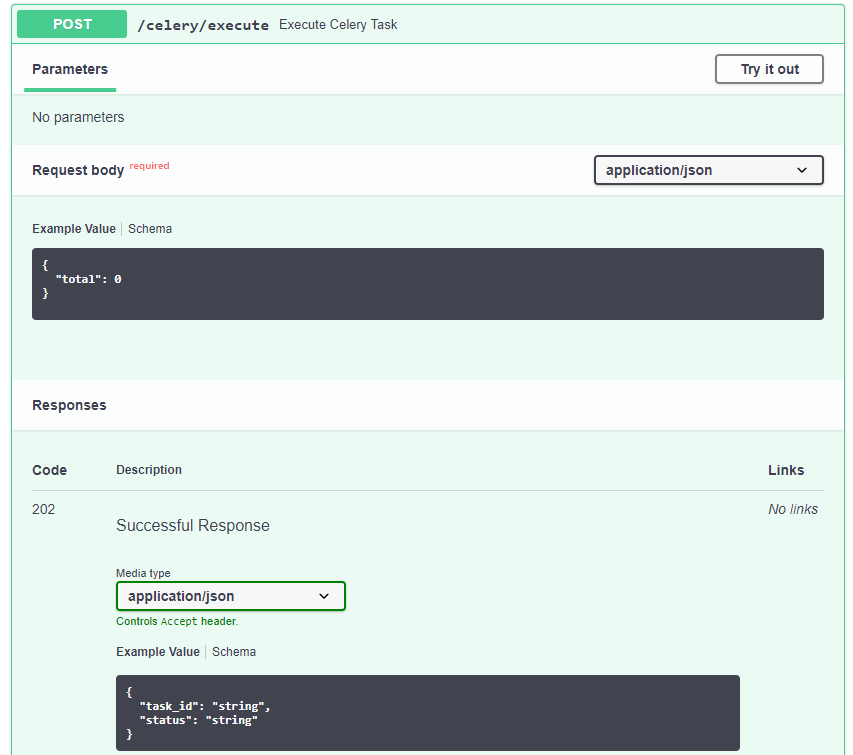
A task can be started by clicking the Try it out button, followed by clicking the Execute button. Any value between 1 and 50 can be set as the value total.
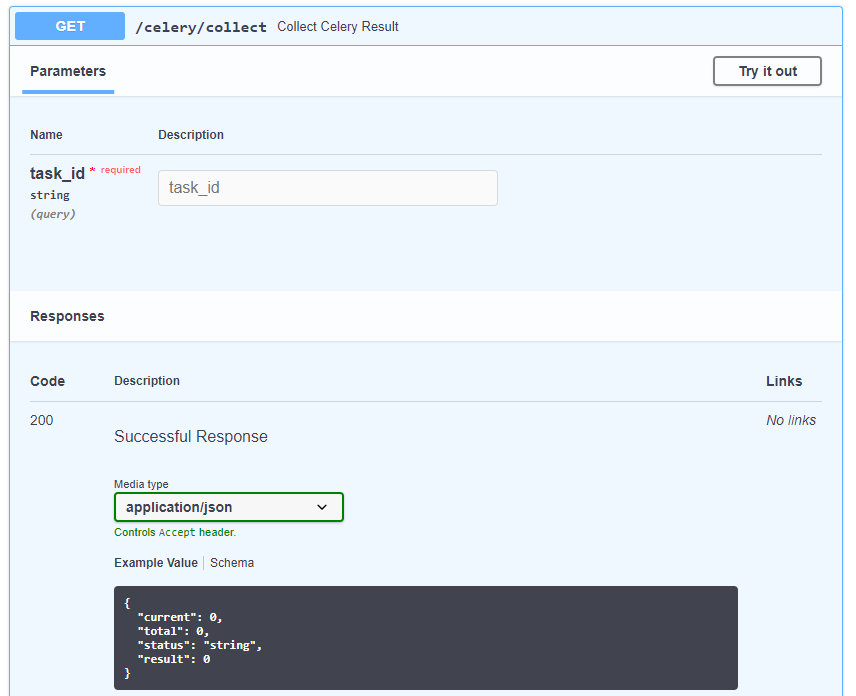
The status of a task can be checked by adding its ID to query string.
Kubernetes
4 groups of resources are necessary to run the apps in Kubernetes and they can be found in /manifests.
- webservice.yaml - main web service Deployment and Service
- queue_celery - Celery worker Deployment
- queue_rserve - Rserve worker Deployment and Service
- redis.yaml - Redis Deployment and Service
In Kubernetes, Pod is one or more containers that work together. Deployment handles a replica of Pod (ReplicaSet), update strategy and so on. And Service allows to connect to a set of Pods from within and outside a Kubernetes cluster. Note that the Celery worker doesn’t have a Service resource as it is accessed by the Redis message broker/result backend.
With kubectl apply, the following resources are created as shown below. Note only the main web service is accessible by a client outside the cluster. The service is mapped to a specific node port (30000). In Minikube, it can be accessed by http://<node-ip-address>:3000. The node IP address can be found by minikube ip command.
1## create resources
2kubectl apply -f manifests
3
4## get resources
5kubectl get po,rs,deploy,svc
6
7NAME READY STATUS RESTARTS AGE
8pod/celery-deployment-674d8fb968-2x97k 1/1 Running 0 25s
9pod/celery-deployment-674d8fb968-44lw4 1/1 Running 0 25s
10pod/main-deployment-79cf8fc5df-45w4p 1/1 Running 0 25s
11pod/main-deployment-79cf8fc5df-hkz6r 1/1 Running 0 25s
12pod/redis-deployment-5ff8646968-hcsbk 1/1 Running 0 25s
13pod/rserve-deployment-59dfbd955-db4v9 1/1 Running 0 25s
14pod/rserve-deployment-59dfbd955-fxfxn 1/1 Running 0 25s
15
16NAME DESIRED CURRENT READY AGE
17replicaset.apps/celery-deployment-674d8fb968 2 2 2 25s
18replicaset.apps/main-deployment-79cf8fc5df 2 2 2 25s
19replicaset.apps/redis-deployment-5ff8646968 1 1 1 25s
20replicaset.apps/rserve-deployment-59dfbd955 2 2 2 25s
21
22NAME READY UP-TO-DATE AVAILABLE AGE
23deployment.apps/celery-deployment 2/2 2 2 25s
24deployment.apps/main-deployment 2/2 2 2 25s
25deployment.apps/redis-deployment 1/1 1 1 25s
26deployment.apps/rserve-deployment 2/2 2 2 25s
27
28NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
29service/main-service NodePort 10.98.60.194 <none> 80:30000/TCP 25s
30service/redis-service ClusterIP 10.99.52.18 <none> 6379/TCP 25s
31service/rserve-service ClusterIP 10.105.249.199 <none> 8000/TCP 25s
The execute/collect pair of requests to the Celery worker are shown below. HttPie is used to make HTTP requests.
1echo '{"total": 30}' | http POST http://172.28.175.23:30000/celery/execute
2{
3 "status": "created",
4 "task_id": "87ae7a42-1ec0-4848-bf30-2f68175b38db"
5}
6
7export TASK_ID=87ae7a42-1ec0-4848-bf30-2f68175b38db
8http http://172.28.175.23:30000/celery/collect?task_id=$TASK_ID
9{
10 "current": 18,
11 "result": null,
12 "status": "Percentage completion 60 ...",
13 "total": 30
14}
15
16# after a while
17
18http http://172.28.175.23:30000/celery/collect?task_id=$TASK_ID
19{
20 "current": 30,
21 "result": 30,
22 "status": "Task completed!",
23 "total": 30
24}
The following shows the execute/collect pair of the Rserve worker.
1echo '{"total": 30}' | http POST http://172.28.175.23:30000/rserve/execute
2{
3 "status": "created",
4 "task_id": "f5d46986-1e89-4322-9d4e-7c1da6454534"
5}
6
7export TASK_ID=f5d46986-1e89-4322-9d4e-7c1da6454534
8http http://172.28.175.23:30000/rserve/collect?task_id=$TASK_ID
9{
10 "current": 16,
11 "result": null,
12 "status": "Percent completion 54 ...",
13 "total": 30
14}
15
16# after a while
17
18http http://172.28.175.23:30000/rserve/collect?task_id=$TASK_ID
19{
20 "current": 30,
21 "result": 30,
22 "status": "Percent completion 100 ...",
23 "total": 30
24}







Comments