
[UPDATE 2025-10-01]
Bitnami’s public Docker images have been moved to the Bitnami Legacy repository. To ensure continued access and compatibility, please update your Docker image references accordingly.
For example:
bitnami/kafka:2.8.1→bitnamilegacy/kafka:2.8.1bitnami/zookeeper:3.7.0→bitnamilegacy/zookeeper:3.7.0bitnami/python:3.9.0→bitnamilegacy/python:3.9.0
When we discussed a Change Data Capture (CDC) solution in one of the earlier posts, we used the JSON converter that comes with Kafka Connect. We optionally enabled the key and value schemas and the topic messages include those schemas together with payload. It seems to be convenient at first as the messages are saved into S3 on their own. However, it became cumbersome when we tried to use the DeltaStreamer utility. Specifically it requires the scheme of the files, but unfortunately we cannot use the schema that is generated by the default JSON converter - it returns the struct type, which is not supported by the Hudi utility. In order to handle this issue, we created a schema with the record type using the Confluent Avro converter and used it after saving on S3. However, as we aimed to manage a long-running process, generating a schema manually was not an optimal solution because, for example, we’re not able to handle schema evolution effectively. In this post, we’ll discuss an improved architecture that makes use of a schema registry that resides outside the Kafka cluster and allows the producers and consumers to reference the schemas externally.
- Part 1 Local Development (this post)
- Part 2 MSK Deployment
Architecture
Below shows an updated CDC architecture with a schema registry. The Debezium connector talks to the schema registry first and checks if the schema is available. If it doesn’t exist, it is registered and cached in the schema registry. Then the producer serializes the data with the schema and sends it to the topic with the schema ID. When the sink connector consumes the message, it’ll read the schema with the ID and deserializes it. The schema registry uses a PostgreSQL database as an artifact store where multiple versions of schemas are kept. In this post, we’ll build it locally using Docker Compose.
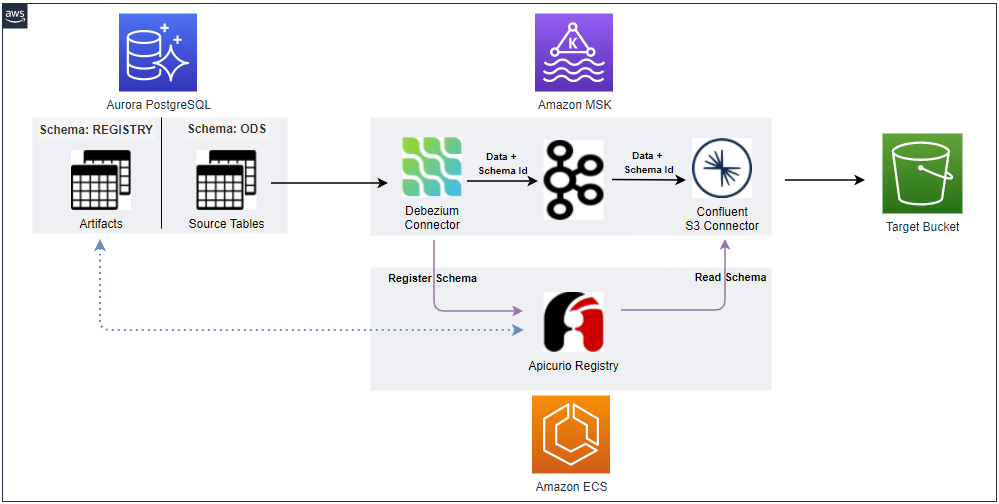
Local Services
Earlier we discussed a local development environment for a Change Data Capture (CDC) solution using the Confluent platform - see this post for details. While it provides a quick and easy way of developing Kafka locally, it doesn’t seem to match MSK well. For example, its docker image already includes the Avro converter and schema registry client libraries. Because of that, while Kafka connectors with Avro serialization work in the platform without modification, they’ll fail on MSK Connect if they are deployed with the same configuration. Therefore, it’ll be better to use docker images from other open source projects instead of the Confluent platform while we can still use docker-compose to build a local development environment. The associating docker-compose file can be found in the GitHub repository for this post.
Kafka Cluster
We can create a single node Kafka cluster as a docker-compose service with Zookeeper, which is used to store metadata about the cluster. The Bitnami images are used to build the services as shown below.
1# docker-compose.yml
2services:
3 zookeeper:
4 image: bitnami/zookeeper:3.7.0
5 container_name: zookeeper
6 ports:
7 - "2181:2181"
8 environment:
9 - ALLOW_ANONYMOUS_LOGIN=yes
10 kafka:
11 image: bitnami/kafka:2.8.1
12 container_name: kafka
13 ports:
14 - "9092:9092"
15 environment:
16 - KAFKA_CFG_ZOOKEEPER_CONNECT=zookeeper:2181
17 - ALLOW_PLAINTEXT_LISTENER=yes
18 depends_on:
19 - zookeeper
20 ...
Kafka Connect
The same Bitnami image can be used to create a Kafka connect service. It is set to run in the distributed mode so that multiple connectors can be deployed together. Three Kafka connector sources are mapped to the /opt/connectors folder of the container - Debezium, Confluent S3 Sink and Voluble. Note that this folder is added to the plugin path of the connector configuration file (connect-distributed.properties) so that they can be discovered when it is requested to create those. Also, a script is created to download the connector sources (and related libraries) to the connect/local/src folder - it’ll be illustrated below. Finally, my AWS account is configured by AWS SSO so that temporary AWS credentials are passed as environment variables - it is necessary for the S3 sink connector.
1# docker-compose.yml
2services:
3 ...
4 kafka-connect:
5 image: bitnami/kafka:2.8.1
6 container_name: connect
7 command: >
8 /opt/bitnami/kafka/bin/connect-distributed.sh
9 /opt/bitnami/kafka/config/connect-distributed.properties
10 ports:
11 - "8083:8083"
12 environment:
13 AWS_ACCESS_KEY_ID: $AWS_ACCESS_KEY_ID
14 AWS_SECRET_ACCESS_KEY: $AWS_SECRET_ACCESS_KEY
15 AWS_SESSION_TOKEN: $AWS_SESSION_TOKEN
16 volumes:
17 - "./connect/local/src/debezium-connector-postgres:/opt/connectors/debezium-postgres"
18 - "./connect/local/src/confluent-s3/lib:/opt/connectors/confluent-s3"
19 - "./connect/local/src/voluble/lib:/opt/connectors/voluble"
20 - "./connect/local/config/connect-distributed.properties:/opt/bitnami/kafka/config/connect-distributed.properties"
21 depends_on:
22 - zookeeper
23 - kafka
24 ...
When the script (download-connectors.sh) runs, it downloads connector sources from Maven Central and Confluent Hub and decompresses. And the Kafka Connect Avro Converter is packaged together with connector sources, which is necessary for Avro serialization of messages and schema registry integration. Note that, if we run our own Kafka connect, we’d add it to one of the folders of the connect service and update its plugin path to enable class discovery. However, we don’t have such control on MSK Connect, and we should add the converter source to the individual connectors.
1# connect/local/download-connectors.sh
2#!/usr/bin/env bash
3
4echo "Add avro converter? (Y/N)"
5read WITH_AVRO
6
7SCRIPT_DIR="$(cd $(dirname "$0"); pwd)"
8
9SRC_PATH=${SCRIPT_DIR}/src
10rm -rf ${SCRIPT_DIR}/src && mkdir -p ${SRC_PATH}
11
12## Debezium Source Connector
13echo "downloading debezium postgres connector..."
14DOWNLOAD_URL=https://repo1.maven.org/maven2/io/debezium/debezium-connector-postgres/1.8.1.Final/debezium-connector-postgres-1.8.1.Final-plugin.tar.gz
15
16curl -S -L ${DOWNLOAD_URL} | tar -C ${SRC_PATH} --warning=no-unknown-keyword -xzf -
17
18## Confluent S3 Sink Connector
19echo "downloading confluent s3 connector..."
20DOWNLOAD_URL=https://d1i4a15mxbxib1.cloudfront.net/api/plugins/confluentinc/kafka-connect-s3/versions/10.0.5/confluentinc-kafka-connect-s3-10.0.5.zip
21
22curl ${DOWNLOAD_URL} -o ${SRC_PATH}/confluent.zip \
23 && unzip -qq ${SRC_PATH}/confluent.zip -d ${SRC_PATH} \
24 && rm ${SRC_PATH}/confluent.zip \
25 && mv ${SRC_PATH}/$(ls ${SRC_PATH} | grep confluentinc-kafka-connect-s3) ${SRC_PATH}/confluent-s3
26
27## Voluble Source Connector
28echo "downloading voluble connector..."
29DOWNLOAD_URL=https://d1i4a15mxbxib1.cloudfront.net/api/plugins/mdrogalis/voluble/versions/0.3.1/mdrogalis-voluble-0.3.1.zip
30
31curl ${DOWNLOAD_URL} -o ${SRC_PATH}/voluble.zip \
32 && unzip -qq ${SRC_PATH}/voluble.zip -d ${SRC_PATH} \
33 && rm ${SRC_PATH}/voluble.zip \
34 && mv ${SRC_PATH}/$(ls ${SRC_PATH} | grep mdrogalis-voluble) ${SRC_PATH}/voluble
35
36if [ ${WITH_AVRO} == "Y" ]; then
37 echo "downloading kafka connect avro converter..."
38 DOWNLOAD_URL=https://d1i4a15mxbxib1.cloudfront.net/api/plugins/confluentinc/kafka-connect-avro-converter/versions/6.0.3/confluentinc-kafka-connect-avro-converter-6.0.3.zip
39
40 curl ${DOWNLOAD_URL} -o ${SRC_PATH}/avro.zip \
41 && unzip -qq ${SRC_PATH}/avro.zip -d ${SRC_PATH} \
42 && rm ${SRC_PATH}/avro.zip \
43 && mv ${SRC_PATH}/$(ls ${SRC_PATH} | grep confluentinc-kafka-connect-avro-converter) ${SRC_PATH}/avro
44
45 echo "copying to connectors..."
46 cp -r ${SRC_PATH}/avro/lib/* ${SRC_PATH}/debezium-connector-postgres
47 cp -r ${SRC_PATH}/avro/lib/* ${SRC_PATH}/confluent-s3/lib
48 cp -r ${SRC_PATH}/avro/lib/* ${SRC_PATH}/voluble/lib
49fi
Schema Registry
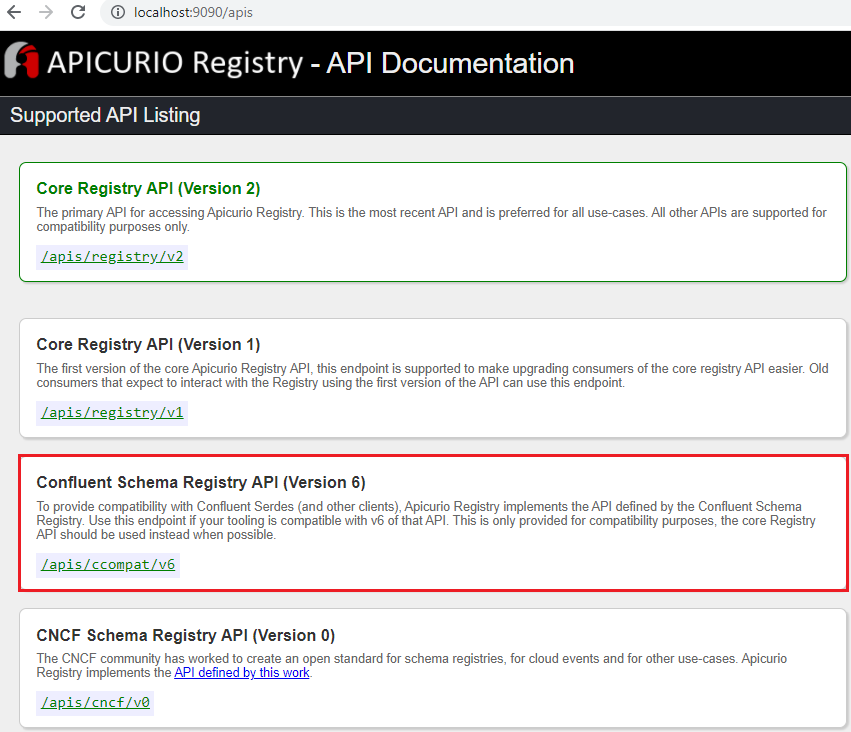
The Confluent schema registry uses Kafka as the storage backend, and it is not sure whether it supports IAM authentication. Therefore, the Apicurio Registry is used instead as it supports a SQL database as storage as well. It provides multiple APIs and one of them is compatible with the Confluent schema registry (/apis/ccompat/v6). We’ll use this API as we plan to use the Confluent version of Avro converter and schema registry client. The PostgreSQL database will be used for the artifact store of the registry as well as the source database of the Debezium connector. For Debezium, the pgoutput plugin is used so that logical replication is enabled (wal_level=logical). The NorthWind database is used as the source database - see this post for details. The registry service expects database connection details from environment variables, and it is set to wait until the source database is up and running.
1# docker-compose.yml
2services:
3 ...
4 postgres:
5 image: postgres:13
6 container_name: postgres
7 command: ["postgres", "-c", "wal_level=logical"]
8 ports:
9 - 5432:5432
10 volumes:
11 - ./connect/data/sql:/docker-entrypoint-initdb.d
12 environment:
13 - POSTGRES_DB=main
14 - POSTGRES_USER=master
15 - POSTGRES_PASSWORD=password
16 registry:
17 image: apicurio/apicurio-registry-sql:2.2.0.Final
18 container_name: registry
19 command: bash -c 'while !</dev/tcp/postgres/5432; do sleep 1; done; /usr/local/s2i/run'
20 ports:
21 - "9090:8080"
22 environment:
23 REGISTRY_DATASOURCE_URL: "jdbc:postgresql://postgres/main?currentSchema=registry"
24 REGISTRY_DATASOURCE_USERNAME: master
25 REGISTRY_DATASOURCE_PASSWORD: password
26 depends_on:
27 - zookeeper
28 - kafka
29 - postgres
30 ...
Once started, we see the Confluent schema registry compatible API from the API list, and we’ll use it for creating Kafka connectors.
Kafka UI
Having a good user interface can make development much easier and pleasant. The Kafka UI is an open source application where we can monitor and manage Kafka brokers, related objects and resources. It supports MSK IAM authentication as well, and it is a good choice for developing applications on MSK. It allows adding details of one or more Kafka clusters as environment variables. We only have a single Kafka cluster and details of the cluster and related resources are added as shown below.
1# docker-compose.yml
2services:
3 ...
4 kafka-ui:
5 image: provectuslabs/kafka-ui:0.3.3
6 container_name: kafka-ui
7 ports:
8 - "8080:8080"
9 environment:
10 KAFKA_CLUSTERS_0_NAME: local
11 KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS: kafka:9092
12 KAFKA_CLUSTERS_0_ZOOKEEPER: zookeeper:2181
13 KAFKA_CLUSTERS_0_SCHEMAREGISTRY: http://registry:8080/apis/ccompat/v6
14 KAFKA_CLUSTERS_0_KAFKACONNECT_0_NAME: local
15 KAFKA_CLUSTERS_0_KAFKACONNECT_0_ADDRESS: http://kafka-connect:8083
16 depends_on:
17 - zookeeper
18 - kafka
The UI is quite intuitive, and we can monitor (and manage) the Kafka cluster and related objects/resources comprehensively.

Create Connectors
The Debezium source connector can be created as shown below. The configuration details can be found in one of the earlier posts. Here the main difference is the key and value converters are set to the Confluent Avro converter in order for the key and value to be serialized into the Avro format. Note the Confluent compatible API is added to the registry URL.
1curl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" \
2 http://localhost:8083/connectors/ \
3 -d '{
4 "name": "orders-source",
5 "config": {
6 "connector.class": "io.debezium.connector.postgresql.PostgresConnector",
7 "tasks.max": "1",
8 "plugin.name": "pgoutput",
9 "publication.name": "cdc_publication",
10 "slot.name": "orders",
11 "database.hostname": "postgres",
12 "database.port": "5432",
13 "database.user": "master",
14 "database.password": "password",
15 "database.dbname": "main",
16 "database.server.name": "ord",
17 "schema.include": "ods",
18 "table.include.list": "ods.cdc_events",
19 "key.converter": "io.confluent.connect.avro.AvroConverter",
20 "key.converter.schema.registry.url": "http://registry:8080/apis/ccompat/v6",
21 "value.converter": "io.confluent.connect.avro.AvroConverter",
22 "value.converter.schema.registry.url": "http://registry:8080/apis/ccompat/v6",
23 "transforms": "unwrap",
24 "transforms.unwrap.type": "io.debezium.transforms.ExtractNewRecordState",
25 "transforms.unwrap.drop.tombstones": "false",
26 "transforms.unwrap.delete.handling.mode": "rewrite",
27 "transforms.unwrap.add.fields": "op,db,table,schema,lsn,source.ts_ms"
28 }
29 }'
The Confluent S3 sink connector is used instead of the Lenses S3 sink connector because the Lenses connector doesn’t work with the Kafka Connect Avro Converter. Here the key and value converters are updated to the Confluent Avro converter with the corresponding schema registry URL.
1curl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" \
2 http://localhost:8083/connectors/ \
3 -d '{
4 "name": "orders-sink",
5 "config": {
6 "connector.class": "io.confluent.connect.s3.S3SinkConnector",
7 "storage.class": "io.confluent.connect.s3.storage.S3Storage",
8 "format.class": "io.confluent.connect.s3.format.avro.AvroFormat",
9 "tasks.max": "1",
10 "topics":"ord.ods.cdc_events",
11 "s3.bucket.name": "analytics-data-590312749310-ap-southeast-2",
12 "s3.region": "ap-southeast-2",
13 "flush.size": "100",
14 "rotate.schedule.interval.ms": "60000",
15 "timezone": "Australia/Sydney",
16 "partitioner.class": "io.confluent.connect.storage.partitioner.DefaultPartitioner",
17 "key.converter": "io.confluent.connect.avro.AvroConverter",
18 "key.converter.schema.registry.url": "http://registry:8080/apis/ccompat/v6",
19 "value.converter": "io.confluent.connect.avro.AvroConverter",
20 "value.converter.schema.registry.url": "http://registry:8080/apis/ccompat/v6",
21 "errors.log.enable": "true"
22 }
23 }'
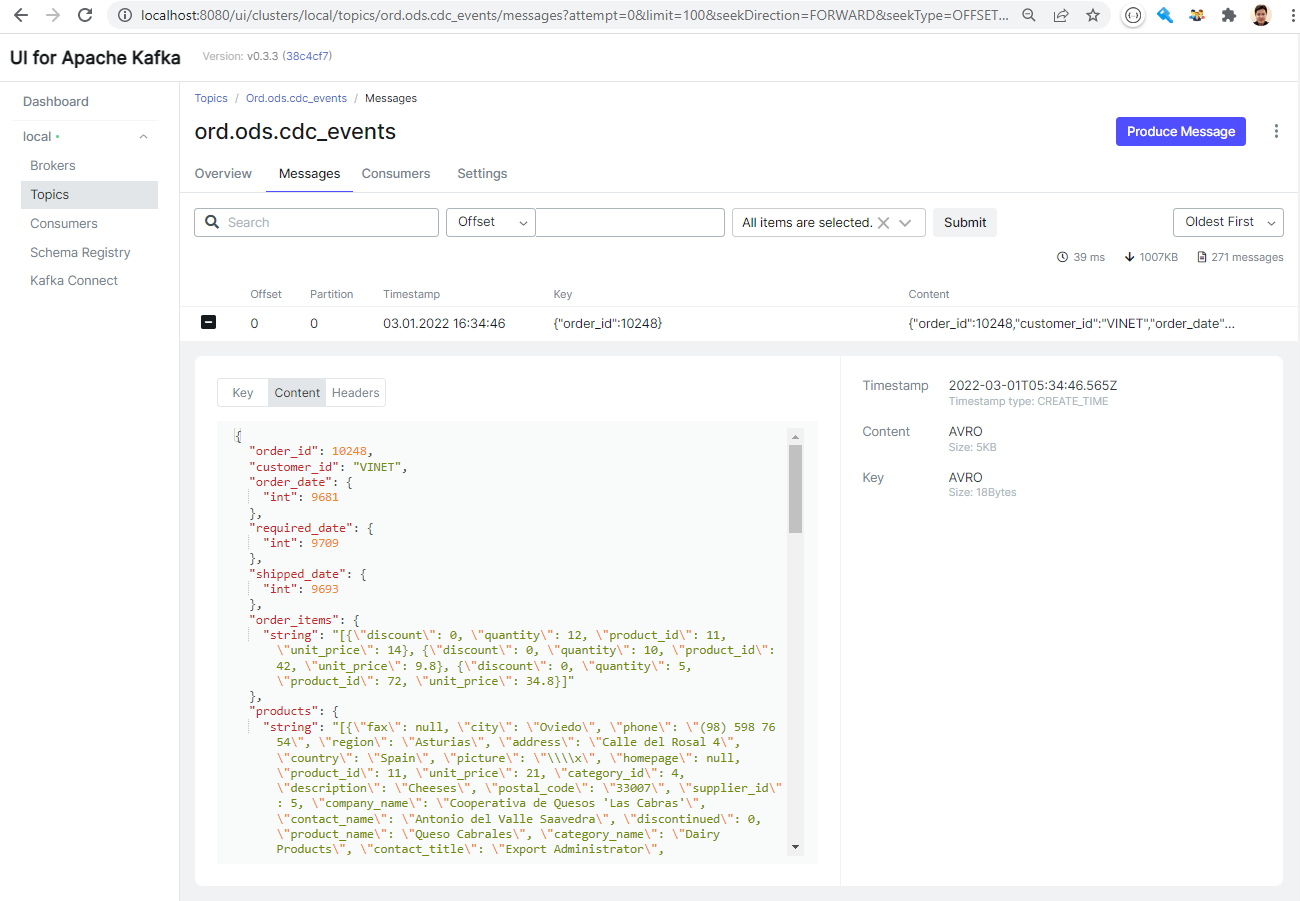
Once the source connector is created, we can check that the key and value schemas are created as shown below. Note we can check the details of the schemas by clicking the relevant items.

As we added the schema registry URL as an environment variable, we see the records (key and value) are properly deserialized within the UI.
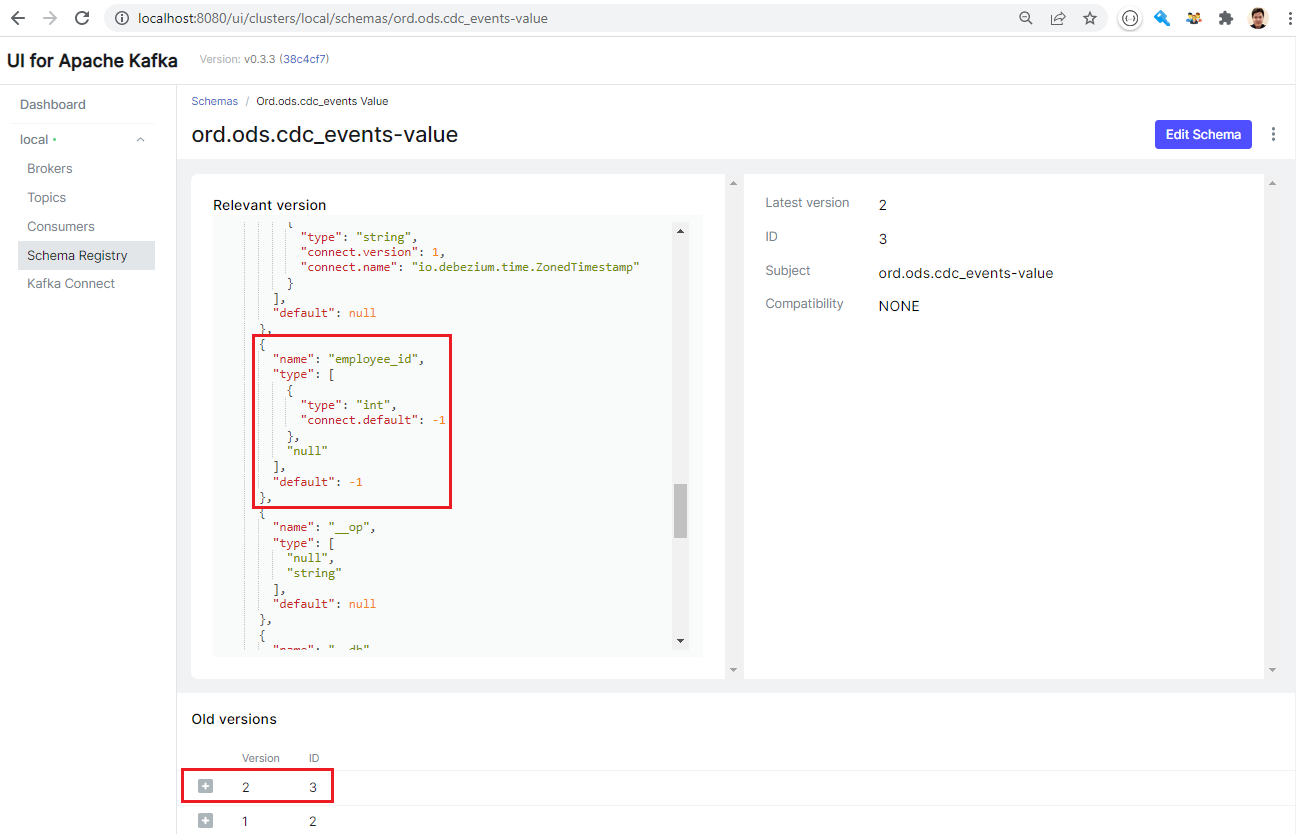
Schema Evolution
The schema registry keeps multiple versions of schemas and we can check it by adding a column to the table and updating records.
1--// add a column with a default value
2ALTER TABLE ods.cdc_events
3 ADD COLUMN employee_id int DEFAULT -1;
4
5--// update employee ID
6UPDATE ods.cdc_events
7 SET employee_id = (employee ->> 'employee_id')::INT
8WHERE customer_id = 'VINET'
Once the above queries are executed, we see a new version is added to the topic’s value schema, and it includes the new field.
Summary
In this post, we discussed an improved architecture of a Change Data Capture (CDC) solution with a schema registry. A local development environment is set up using Docker Compose. The Debezium and Confluent S3 connectors are deployed with the Confluent Avro converter and the Apicurio registry is used as the schema registry service. A quick example is shown to illustrate how schema evolution can be managed by the schema registry. In the next post, it’ll be deployed to AWS mainly using MSK Connect, Aurora PostgreSQL and ECS.










Comments