
AWS Lambda provides serverless computing capabilities, and it can be used for performing validation or light processing/transformation of data. Moreover, with its integration with more than 140 AWS services, it facilitates building complex systems employing event-driven architectures. There are many ways to build serverless applications and one of the most efficient ways is using specialised frameworks such as the AWS Serverless Application Model (SAM) and Serverless Framework. In this post, I’ll demonstrate how to build a serverless data processing application using SAM.
Architecture
When we create an application or pipeline with AWS Lambda, most likely we’ll include its event triggers and destinations. The AWS Serverless Application Model (SAM) facilitates building serverless applications by providing shorthand syntax with a number of custom resource types. Also, the AWS SAM CLI supports an execution environment that helps build, test, debug and deploy applications easily. Furthermore, the CLI can be integrated with full-pledged IaC tools such as the AWS Cloud Development Kit (CDK) and Terraform - note integration with the latter is in its roadmap. With the integration, serverless application development can be a lot easier with capabilities of local testing and building. An alternative tool is the Serverless Framework. It supports multiple cloud providers and broader event sources out-of-box but its integration with IaC tools is practically non-existent.
In this post, we’ll build a simple data pipeline using SAM where a Lambda function is triggered when an object (CSV file) is created in a S3 bucket. The Lambda function converts the object into parquet and AVRO files and saves to a destination S3 bucket. For simplicity, we’ll use a single bucket for the source and destination.
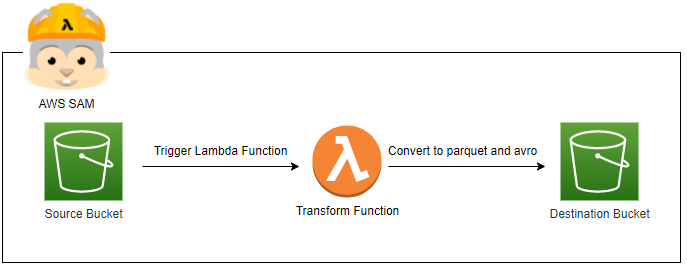
SAM Application
After installing the SAM CLI, I initialised an app with the Python 3.8 Lambda runtime from the hello world template (sam init --runtime python3.8). Then it is modified for the data pipeline app. The application is defined in the template.yaml and the source of the main Lambda function is placed in the _transform _folder. We need 3rd party packages for converting source files into the parquet and AVRO formats - AWS Data Wrangler and fastavro. Instead of packaging them together with the Lambda function, they are made available as Lambda layers. While using the AWS managed Lambda layer for the former, we only need to build the Lambda layer for the _fastavro _package, and it is located in the _fastavro _folder. The source of the app can be found in the GitHub repository of this post.
1fastavro
2└── requirements.txt
3transform
4├── __init__.py
5├── app.py
6└── requirements.txt
7tests
8├── __init__.py
9└── unit
10 ├── __init__.py
11 └── test_handler.py
12template.yaml
13requirements-dev.txt
14test.csv
In the resources section of the template, the Lambda layer for AVRO transformation (FastAvro), the main Lambda function (TransformFunction) and the source (and destination) S3 bucket (SourceBucket) are added. The layer can be built simply by adding the pip package name to the requirements.txt file. It is set to be compatible with Python 3.7 to 3.9. For the Lambda function, its source is configured to be built from the _transform _folder and the ARNs of the custom and AWS managed Lambda layers are added to the layers property. Also, an S3 bucket event is configured so that this Lambda function is triggered whenever a new object is created to the bucket. Finally, as it needs to have permission to read and write objects to the S3 bucket, its invocation policies are added from ready-made policy templates - _S3ReadPolicy _and S3WritePolicy.
1# template.yaml
2AWSTemplateFormatVersion: "2010-09-09"
3Transform: AWS::Serverless-2016-10-31
4Description: >
5 sam-for-data-professionals
6
7 Sample SAM Template for sam-for-data-professionals
8
9Globals:
10 Function:
11 MemorySize: 256
12 Timeout: 20
13
14Resources:
15 FastAvro:
16 Type: AWS::Serverless::LayerVersion
17 Properties:
18 LayerName: fastavro-layer-py3
19 ContentUri: fastavro/
20 CompatibleRuntimes:
21 - python3.7
22 - python3.8
23 - python3.9
24 Metadata:
25 BuildMethod: python3.8
26 TransformFunction:
27 Type: AWS::Serverless::Function
28 Properties:
29 CodeUri: transform/
30 Handler: app.lambda_handler
31 Runtime: python3.8
32 Layers:
33 - !Ref FastAvro
34 - arn:aws:lambda:ap-southeast-2:336392948345:layer:AWSDataWrangler-Python38:8
35 Policies:
36 - S3ReadPolicy:
37 BucketName: sam-for-data-professionals-cevo
38 - S3WritePolicy:
39 BucketName: sam-for-data-professionals-cevo
40 Events:
41 BucketEvent:
42 Type: S3
43 Properties:
44 Bucket: !Ref SourceBucket
45 Events:
46 - "s3:ObjectCreated:*"
47 SourceBucket:
48 Type: AWS::S3::Bucket
49 Properties:
50 BucketName: sam-for-data-professionals-cevo
51
52Outputs:
53 FastAvro:
54 Description: "ARN of fastavro-layer-py3"
55 Value: !Ref FastAvro
56 TransformFunction:
57 Description: "Transform Lambda Function ARN"
58 Value: !GetAtt TransformFunction.Arn
Lambda Function
The transform function reads an input file from the S3 bucket and saves the records as the parquet and AVRO formats. Thanks to the Lambda layers, we can access the necessary 3rd party packages as well as reduce the size of uploaded deployment packages and make it faster to deploy it.
1# transform/app.py
2import re
3import io
4from fastavro import writer, parse_schema
5import awswrangler as wr
6import pandas as pd
7import boto3
8
9s3 = boto3.client("s3")
10
11avro_schema = {
12 "doc": "User details",
13 "name": "User",
14 "namespace": "user",
15 "type": "record",
16 "fields": [{"name": "name", "type": "string"}, {"name": "age", "type": "int"}],
17}
18
19
20def check_fields(df: pd.DataFrame, schema: dict):
21 if schema.get("fields") is None:
22 raise Exception("missing fields in schema keys")
23 if len(set(df.columns) - set([f["name"] for f in schema["fields"]])) > 0:
24 raise Exception("missing columns in schema key of fields")
25
26
27def check_data_types(df: pd.DataFrame, schema: dict):
28 dtypes = df.dtypes.to_dict()
29 for field in schema["fields"]:
30 match_type = "object" if field["type"] == "string" else field["type"]
31 if re.search(match_type, str(dtypes[field["name"]])) is None:
32 raise Exception(f"incorrect column type - {field['name']}")
33
34
35def generate_avro_file(df: pd.DataFrame, schema: dict):
36 check_fields(df, schema)
37 check_data_types(df, schema)
38 buffer = io.BytesIO()
39 writer(buffer, parse_schema(schema), df.to_dict("records"))
40 buffer.seek(0)
41 return buffer
42
43
44def lambda_handler(event, context):
45 # get bucket and key values
46 record = next(iter(event["Records"]))
47 bucket = record["s3"]["bucket"]["name"]
48 key = record["s3"]["object"]["key"]
49 file_name = re.sub(".csv$", "", key.split("/")[-1])
50 # read input csv as a data frame
51 input_path = f"s3://{bucket}/{key}"
52 input_df = wr.s3.read_csv([input_path])
53 # write to s3 as a parquet file
54 wr.s3.to_parquet(df=input_df, path=f"s3://{bucket}/output/{file_name}.parquet")
55 # write to s3 as an avro file
56 s3.upload_fileobj(generate_avro_file(input_df, avro_schema), bucket, f"output/{file_name}.avro")
Unit Testing
We use a custom function to create AVRO files (generate_avro_file) while relying on the AWS Data Wrangler package for reading input files and writing to parquet files. Therefore, unit testing is performed for the custom function only. Mainly it tests whether the AVRO schema matches the input data fields and data types.
1# tests/unit/test_handler.py
2import pytest
3import pandas as pd
4from transform import app
5
6
7@pytest.fixture
8def input_df():
9 return pd.DataFrame.from_dict({"name": ["Vrinda", "Tracy"], "age": [22, 28]})
10
11
12def test_generate_avro_file_success(input_df):
13 avro_schema = {
14 "doc": "User details",
15 "name": "User",
16 "namespace": "user",
17 "type": "record",
18 "fields": [{"name": "name", "type": "string"}, {"name": "age", "type": "int"}],
19 }
20 app.generate_avro_file(input_df, avro_schema)
21 assert True
22
23
24def test_generate_avro_file_fail_missing_fields(input_df):
25 avro_schema = {
26 "doc": "User details",
27 "name": "User",
28 "namespace": "user",
29 "type": "record",
30 }
31 with pytest.raises(Exception) as e:
32 app.generate_avro_file(input_df, avro_schema)
33 assert "missing fields in schema keys" == str(e.value)
34
35
36def test_generate_avro_file_fail_missing_columns(input_df):
37 avro_schema = {
38 "doc": "User details",
39 "name": "User",
40 "namespace": "user",
41 "type": "record",
42 "fields": [{"name": "name", "type": "string"}],
43 }
44 with pytest.raises(Exception) as e:
45 app.generate_avro_file(input_df, avro_schema)
46 assert "missing columns in schema key of fields" == str(e.value)
47
48
49def test_generate_avro_file_fail_incorrect_age_type(input_df):
50 avro_schema = {
51 "doc": "User details",
52 "name": "User",
53 "namespace": "user",
54 "type": "record",
55 "fields": [{"name": "name", "type": "string"}, {"name": "age", "type": "string"}],
56 }
57 with pytest.raises(Exception) as e:
58 app.generate_avro_file(input_df, avro_schema)
59 assert f"incorrect column type - age" == str(e.value)
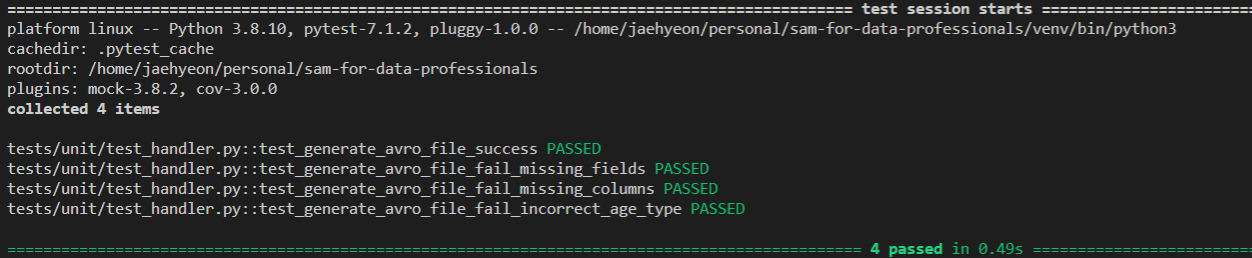
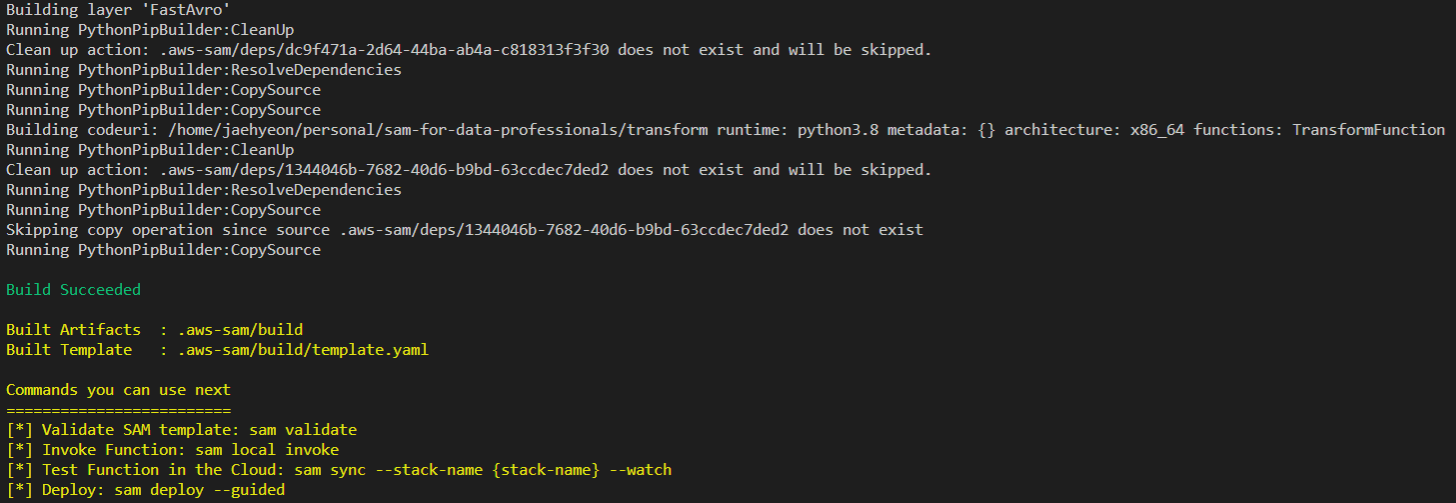
Build and Deploy
The app has to be built before deployment. It can be done by sam build.
The deployment can be done with and without a guide. For the latter, we need to specify additional parameters such as the Cloudformation stack name, capabilities (as we create an IAM role for Lambda) and a flag to automatically determine an S3 bucket to store build artifacts.
1sam deploy \
2 --stack-name sam-for-data-professionals \
3 --capabilities CAPABILITY_IAM \
4 --resolve-s3
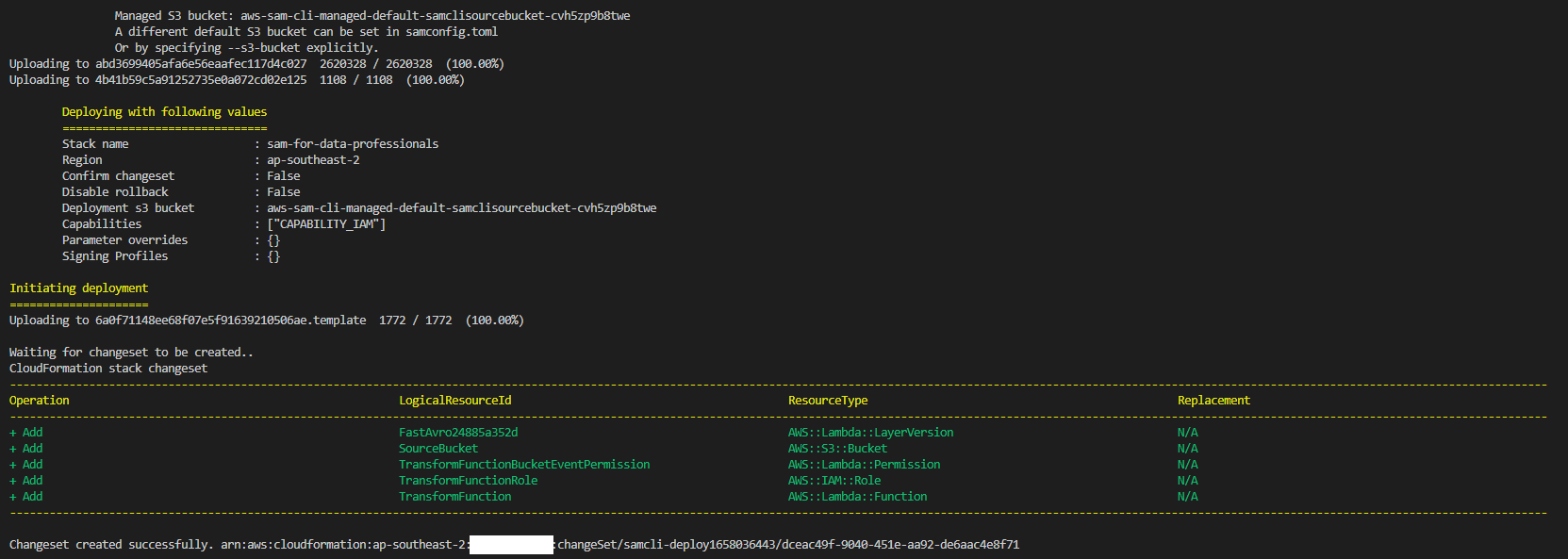

Trigger Lambda Function
We can simply trigger the Lambda function by uploading a source file to the S3 bucket. Once it is uploaded, we are able to see that the output parquet and AVRO files are saved as expected.
1$ aws s3 cp test.csv s3://sam-for-data-professionals-cevo/input/
2upload: ./test.csv to s3://sam-for-data-professionals-cevo/input/test.csv
3
4$ aws s3 ls s3://sam-for-data-professionals-cevo/output/
52022-07-17 17:33:21 403 test.avro
62022-07-17 17:33:21 2112 test.parquet
Summary
In this post, it is illustrated how to build a serverless data processing application using SAM. A Lambda function is developed, which is triggered whenever an object is created in a S3 bucket. It converts input CSV files into the parquet and AVRO formats before saving into the destination bucket. For the format conversion, it uses 3rd party packages, and they are made available by Lambda layers. The application is built and deployed and the function triggering is checked.










Comments