
The data build tool (dbt) is an effective data transformation tool and it supports key AWS analytics services - Redshift, Glue, EMR and Athena. In the previous posts, we discussed benefits of a common data transformation tool and the potential of dbt to cover a wide range of data projects from data warehousing to data lake to data lakehouse. Demo data projects that target Redshift Serverless, Glue and EMR on EC2 are illustrated as well. In part 4 of the dbt on AWS series, we discuss data transformation pipelines using dbt on Amazon EMR on EKS. As Spark Submit does not allow the spark thrift server to run in cluster mode on Kubernetes, a simple wrapper class is created to overcome the limitation and it makes the thrift server run indefinitely. Subsets of IMDb data are used as source and data models are developed in multiple layers according to the dbt best practices. A list of posts of this series can be found below.
Below shows an overview diagram of the scope of this dbt on AWS series. EMR is highlighted as it is discussed in this post.

Infrastructure
The main infrastructure hosting this solution leverages an Amazon EKS cluster and EMR virtual cluster. As discussed in one of the earlier posts, EMR job pods (controller, driver and executors) can be configured to be managed by Karpenter, which simplifies autoscaling by provisioning just-in-time capacity as well as reduces scheduling latency. While the infrastructure elements are discussed in depth in the earlier post and part 3, this section focuses on how to set up a long-running Thrift JDBC/ODBC server on EMR on EKS, which is a critical part of using the dbt-spark adapter. The source can be found in the GitHub repository of this post.
Thrift JDBC/ODBC Server
The Spark Submit does not allow the spark thrift server to run in cluster mode on Kubernetes. I have found a number of implementations that handle this issue. The first one is executing the thrift server start script in the container command, but it is not allowed in pod templates of EMR on EKS. Besides, it creates the driver and executors in a single pod, which is not scalable. The second example relies on Apache Kyuubi that manages Spark applications while providing JDBC connectivity. However, there is no dbt adapter that supports Kyuubi as well as I am concerned it could make dbt transformations more complicated. The last one is creating a wrapper class that makes the thrift server run indefinitely. It is an interesting approach to deploy the thrift server on EMR on EKS (and the spark kubernetes operator in general) with minimal effort. Following that example, a wrapper class is created in this post.
Spark Thrift Server Runner
The wrapper class (SparkThriftServerRunner) is created as shown below, and it makes the HiveThriftServer2 class run indefinitely. In this way, we are able to use the runner class as the entry point for a spark application.
1// emr-eks/hive-on-spark-in-kubernetes/examples/spark-thrift-server/src/main/java/io/jaehyeon/hive/SparkThriftServerRunner.java
2package io.jaehyeon.hive;
3
4public class SparkThriftServerRunner {
5
6 public static void main(String[] args) {
7 org.apache.spark.sql.hive.thriftserver.HiveThriftServer2.main(args);
8
9 while (true) {
10 try {
11 Thread.sleep(Long.MAX_VALUE);
12 } catch (Exception e) {
13 e.printStackTrace();
14 }
15 }
16 }
17}
While the reference implementation includes all of its dependent libraries when building the class, only the runner class itself is built for this post. It is because we do not have to include those as they are available in the EMR on EKS container image. To do so, the Project Object Model (POM) file is updated so that all the provided dependency scopes are changed into runtime except for spark-hive-thriftserver_2.12 - see pom.xml for details. The runner class can be built as shown below.
1cd emr-eks/hive-on-spark-in-kubernetes/examples/spark-thrift-server
2mvn -e -DskipTests=true clean install;
Once completed, the JAR file of the runner class can be found in the target folder - spark-thrift-server-1.0.0-SNAPSHOT.jar.
1$ tree target/ -L 1
2target/
3├── classes
4├── generated-sources
5├── maven-archiver
6├── maven-status
7├── spark-thrift-server-1.0.0-SNAPSHOT-sources.jar
8├── spark-thrift-server-1.0.0-SNAPSHOT.jar
9└── test-classes
10
115 directories, 2 files
Driver Template
We can expose the spark driver pod by a service. A label (app) is added to the driver pod template so that it can be selected by the service.
1# emr-eks/resources/driver-template.yaml
2apiVersion: v1
3kind: Pod
4metadata:
5 labels:
6 app: spark-thrift-server-driver
7spec:
8 nodeSelector:
9 type: karpenter
10 provisioner: spark-driver
11 tolerations:
12 - key: spark-driver
13 operator: Exists
14 effect: NoSchedule
15 containers:
16 - name: spark-kubernetes-driver
Spark Job Run
The wrapper class and (driver and executor) pod templates are referred from the default S3 bucket of this post. The runner class is specified as the entry point of the spark application and three executor instances with 2G of memory are configured to run. In the application configuration, the dynamic resource allocation is disabled and the AWS Glue Data Catalog is set to be used as the metastore for Spark SQL.
1# emr-eks/job-run.sh
2export VIRTUAL_CLUSTER_ID=$(terraform -chdir=./infra output --raw emrcontainers_virtual_cluster_id)
3export EMR_ROLE_ARN=$(terraform -chdir=./infra output --json emr_on_eks_role_arn | jq '.[0]' -r)
4export DEFAULT_BUCKET_NAME=$(terraform -chdir=./infra output --raw default_bucket_name)
5export AWS_REGION=$(aws ec2 describe-availability-zones --query 'AvailabilityZones[0].[RegionName]' --output text)
6
7aws emr-containers start-job-run \
8--virtual-cluster-id $VIRTUAL_CLUSTER_ID \
9--name thrift-server \
10--execution-role-arn $EMR_ROLE_ARN \
11--release-label emr-6.8.0-latest \
12--region $AWS_REGION \
13--job-driver '{
14 "sparkSubmitJobDriver": {
15 "entryPoint": "s3://'${DEFAULT_BUCKET_NAME}'/resources/jars/spark-thrift-server-1.0.0-SNAPSHOT.jar",
16 "sparkSubmitParameters": "--class io.jaehyeon.hive.SparkThriftServerRunner --jars s3://'${DEFAULT_BUCKET_NAME}'/resources/jars/spark-thrift-server-1.0.0-SNAPSHOT.jar --conf spark.executor.instances=3 --conf spark.executor.memory=2G --conf spark.executor.cores=1 --conf spark.driver.cores=1 --conf spark.driver.memory=2G"
17 }
18 }' \
19--configuration-overrides '{
20 "applicationConfiguration": [
21 {
22 "classification": "spark-defaults",
23 "properties": {
24 "spark.dynamicAllocation.enabled":"false",
25 "spark.kubernetes.executor.deleteOnTermination": "true",
26 "spark.kubernetes.driver.podTemplateFile":"s3://'${DEFAULT_BUCKET_NAME}'/resources/templates/driver-template.yaml",
27 "spark.kubernetes.executor.podTemplateFile":"s3://'${DEFAULT_BUCKET_NAME}'/resources/templates/executor-template.yaml",
28 "spark.hadoop.hive.metastore.client.factory.class":"com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory"
29 }
30 }
31 ]
32}'
Once it is started, we can check the spark job pods as shown below. A single driver and three executor pods are deployed as expected.
1$ kubectl get pod -n analytics
2NAME READY STATUS RESTARTS AGE
30000000310t0tkbcftg-nmzfh 2/2 Running 0 5m39s
4spark-0000000310t0tkbcftg-6385c0841d09d389-exec-1 1/1 Running 0 3m2s
5spark-0000000310t0tkbcftg-6385c0841d09d389-exec-2 1/1 Running 0 3m1s
6spark-0000000310t0tkbcftg-6385c0841d09d389-exec-3 1/1 Running 0 3m1s
7spark-0000000310t0tkbcftg-driver 2/2 Running 0 5m26s
Spark Thrift Server Service
As mentioned earlier, the driver pod is exposed by a service. The service manifest file uses a label selector to identify the spark driver pod. As EMR on EC2, the thrift server is mapped to port 10001 by default. Note that the container port is not allowed in the pod templates of EMR on EKS but the service can still access it.
1# emr-eks/resources/spark-thrift-server-service.yaml
2kind: Service
3apiVersion: v1
4metadata:
5 name: spark-thrift-server-service
6 namespace: analytics
7spec:
8 type: LoadBalancer
9 selector:
10 app: spark-thrift-server-driver
11 ports:
12 - name: jdbc-port
13 protocol: TCP
14 port: 10001
15 targetPort: 10001
The service can be deployed by kubectl apply -f resources/spark-thrift-server-service.yaml, and we can check the service details as shown below - we will use the hostname of the service (EXTERNAL-IP) later.

Similar to beeline, we can check the connection using the pyhive package.
1# emr-eks/resources/test_conn.py
2from pyhive import hive
3import pandas as pd
4
5conn = hive.connect(
6 host="<hostname-of-spark-thrift-server-service>",
7 port=10001,
8 username="hadoop",
9 auth=None
10 )
11print(pd.read_sql(con=conn, sql="show databases"))
12conn.close()
1$ python resources/test_conn.py
2 print(pd.read_sql(con=conn, sql="show databases"))
3 namespace
40 default
51 imdb
62 imdb_analytics
Project
We build a data transformation pipeline using subsets of IMDb data - seven titles and names related datasets are provided as gzipped, tab-separated-values (TSV) formatted files. The project ends up creating three tables that can be used for reporting and analysis.
Save Data to S3
The Axel download accelerator is used to download the data files locally followed by decompressing with the gzip utility. Note that simple retry logic is added as I see download failure from time to time. Finally, the decompressed files are saved into the project S3 bucket using the S3 sync command.
1# dbt-on-aws/emr-eks/upload-data.sh
2#!/usr/bin/env bash
3
4s3_bucket=$(terraform -chdir=./infra output --raw default_bucket_name)
5hostname="datasets.imdbws.com"
6declare -a file_names=(
7 "name.basics.tsv.gz" \
8 "title.akas.tsv.gz" \
9 "title.basics.tsv.gz" \
10 "title.crew.tsv.gz" \
11 "title.episode.tsv.gz" \
12 "title.principals.tsv.gz" \
13 "title.ratings.tsv.gz"
14 )
15
16rm -rf imdb-data
17
18for fn in "${file_names[@]}"
19do
20 download_url="https://$hostname/$fn"
21 prefix=$(echo ${fn::-7} | tr '.' '_')
22 echo "download imdb-data/$prefix/$fn from $download_url"
23 while true;
24 do
25 mkdir -p imdb-data/$prefix
26 axel -n 32 -a -o imdb-data/$prefix/$fn $download_url
27 gzip -d imdb-data/$prefix/$fn
28 num_files=$(ls imdb-data/$prefix | wc -l)
29 if [ $num_files == 1 ]; then
30 break
31 fi
32 rm -rf imdb-data/$prefix
33 done
34done
35
36aws s3 sync ./imdb-data s3://$s3_bucket
Setup dbt Project
We use the dbt-spark adapter to work with the EMR cluster. As connection is made by the Thrift JDBC/ODBC server, it is necessary to install the adapter with the PyHive package. I use Ubuntu 20.04 in WSL 2 and it needs to install the libsasl2-dev apt package, which is required for one of the dependent packages of PyHive (pure-sasl). After installing it, we can install the dbt packages as usual.
1$ sudo apt-get install libsasl2-dev
2$ python3 -m venv venv
3$ source venv/bin/activate
4$ pip install --upgrade pip
5$ pip install dbt-core "dbt-spark[PyHive]"
We can initialise a dbt project with the dbt init command. We are required to specify project details - project name, host, connection method, port, schema and the number of threads. Note dbt creates the project profile to .dbt/profile.yml of the user home directory by default.
1$ dbt init
205:29:39 Running with dbt=1.3.0
3Enter a name for your project (letters, digits, underscore): emr_eks
4Which database would you like to use?
5[1] spark
6
7(Don't see the one you want? https://docs.getdbt.com/docs/available-adapters)
8
9Enter a number: 1
10host (yourorg.sparkhost.com): <hostname-of-spark-thrift-server-service>
11[1] odbc
12[2] http
13[3] thrift
14Desired authentication method option (enter a number): 3
15port [443]: 10001
16schema (default schema that dbt will build objects in): imdb
17threads (1 or more) [1]: 3
1805:30:13 Profile emr_eks written to /home/<username>/.dbt/profiles.yml using target's profile_template.yml and your supplied values. Run 'dbt debug' to validate the connection.
1905:30:13
20Your new dbt project "emr_eks" was created!
21
22For more information on how to configure the profiles.yml file,
23please consult the dbt documentation here:
24
25 https://docs.getdbt.com/docs/configure-your-profile
26
27One more thing:
28
29Need help? Don't hesitate to reach out to us via GitHub issues or on Slack:
30
31 https://community.getdbt.com/
32
33Happy modeling!
dbt initialises a project in a folder that matches to the project name and generates project boilerplate as shown below. Some of the main objects are dbt_project.yml, and the model folder. The former is required because dbt doesn’t know if a folder is a dbt project without it. Also it contains information that tells dbt how to operate on the project. The latter is for including dbt models, which is basically a set of SQL select statements. See dbt documentation for more details.
1$ tree emr-eks/emr_eks/ -L 1
2emr-eks/emr_eks/
3├── README.md
4├── analyses
5├── dbt_packages
6├── dbt_project.yml
7├── logs
8├── macros
9├── models
10├── packages.yml
11├── seeds
12├── snapshots
13├── target
14└── tests
We can check connection to the EMR cluster with the dbt debug command as shown below.
1$ dbt debug
205:31:22 Running with dbt=1.3.0
3dbt version: 1.3.0
4python version: 3.8.10
5python path: <path-to-python-path>
6os info: Linux-5.4.72-microsoft-standard-WSL2-x86_64-with-glibc2.29
7Using profiles.yml file at /home/<username>/.dbt/profiles.yml
8Using dbt_project.yml file at <path-to-dbt-project>/dbt_project.yml
9
10Configuration:
11 profiles.yml file [OK found and valid]
12 dbt_project.yml file [OK found and valid]
13
14Required dependencies:
15 - git [OK found]
16
17Connection:
18 host: <hostname-of-spark-thrift-server-service>
19 port: 10001
20 cluster: None
21 endpoint: None
22 schema: imdb
23 organization: 0
24 Connection test: [OK connection ok]
25
26All checks passed!
After initialisation, the model configuration is updated. The project materialisation is specified as view although it is the default materialisation. Also tags are added to the entire model folder as well as folders of specific layers - staging, intermediate and marts. As shown below, tags can simplify model execution.
1# emr-eks/emr_eks/dbt_project.yml
2name: "emr_eks"
3
4...
5
6models:
7 dbt_glue_proj:
8 +materialized: view
9 +tags:
10 - "imdb"
11 staging:
12 +tags:
13 - "staging"
14 intermediate:
15 +tags:
16 - "intermediate"
17 marts:
18 +tags:
19 - "marts"
While we created source tables using Glue crawlers in part 2, they are created directly from S3 by the dbt_external_tables package in this post. Also the dbt_utils package is installed for adding tests to the final marts models. They can be installed by the dbt deps command.
1# emr-eks/emr_eks/packages.yml
2packages:
3 - package: dbt-labs/dbt_external_tables
4 version: 0.8.2
5 - package: dbt-labs/dbt_utils
6 version: 0.9.2
Create dbt Models
The models for this post are organised into three layers according to the dbt best practices - staging, intermediate and marts.
External Source
The seven tables that are loaded from S3 are dbt source tables and their details are declared in a YAML file (_imdb_sources.yml). Macros of the dbt_external_tables package parse properties of each table and execute SQL to create each of them. By doing so, we are able to refer to the source tables with the {{ source() }} function. Also, we can add tests to source tables. For example two tests (unique, not_null) are added to the tconst column of the title_basics table below and these tests can be executed by the dbt test command.
1# emr-eks/emr_eks/models/staging/imdb/_imdb__sources.yml
2version: 2
3
4sources:
5 - name: imdb
6 description: Subsets of IMDb data, which are available for access to customers for personal and non-commercial use
7 tables:
8 - name: title_basics
9 description: Table that contains basic information of titles
10 external:
11 location: "s3://<s3-bucket-name>/title_basics/"
12 row_format: >
13 serde 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
14 with serdeproperties (
15 'separatorChar'='\t'
16 )
17 table_properties: "('skip.header.line.count'='1')"
18 columns:
19 - name: tconst
20 data_type: string
21 description: alphanumeric unique identifier of the title
22 tests:
23 - unique
24 - not_null
25 - name: titletype
26 data_type: string
27 description: the type/format of the title (e.g. movie, short, tvseries, tvepisode, video, etc)
28 - name: primarytitle
29 data_type: string
30 description: the more popular title / the title used by the filmmakers on promotional materials at the point of release
31 - name: originaltitle
32 data_type: string
33 description: original title, in the original language
34 - name: isadult
35 data_type: string
36 description: flag that indicates whether it is an adult title or not
37 - name: startyear
38 data_type: string
39 description: represents the release year of a title. In the case of TV Series, it is the series start year
40 - name: endyear
41 data_type: string
42 description: TV Series end year. NULL for all other title types
43 - name: runtimeminutes
44 data_type: string
45 description: primary runtime of the title, in minutes
46 - name: genres
47 data_type: string
48 description: includes up to three genres associated with the title
The source tables can be created by dbt run-operation stage_external_sources. Note that the following SQL is executed for the _title_basics _table under the hood.
1create table imdb.title_basics (
2 tconst string,
3 titletype string,
4 primarytitle string,
5 originaltitle string,
6 isadult string,
7 startyear string,
8 endyear string,
9 runtimeminutes string,
10 genres string
11)
12row format serde 'org.apache.hadoop.hive.serde2.OpenCSVSerde' with serdeproperties (
13'separatorChar'='\t'
14)
15location 's3://<s3-bucket-name>/title_basics/'
16tblproperties ('skip.header.line.count'='1')
Interestingly the header rows of the source tables are not skipped when they are queried by spark while they are skipped by Athena. They have to be filtered out in the stage models of the dbt project as spark is the query engine.

Staging
Based on the source tables, staging models are created. They are created as views, which is the project’s default materialisation. In the SQL statements, column names and data types are modified mainly.
1# emr-eks/emr_eks/models/staging/imdb/stg_imdb__title_basics.sql
2with source as (
3
4 select * from {{ source('imdb', 'title_basics') }}
5
6),
7
8renamed as (
9
10 select
11 tconst as title_id,
12 titletype as title_type,
13 primarytitle as primary_title,
14 originaltitle as original_title,
15 cast(isadult as boolean) as is_adult,
16 cast(startyear as int) as start_year,
17 cast(endyear as int) as end_year,
18 cast(runtimeminutes as int) as runtime_minutes,
19 case when genres = 'N' then null else genres end as genres
20 from source
21 where tconst <> 'tconst'
22
23)
24
25select * from renamed
Below shows the file tree of the staging models. The staging models can be executed using the dbt run command. As we’ve added tags to the staging layer models, we can limit to execute only this layer by dbt run --select staging.
1$ tree emr-eks/emr_eks/models/staging/
2emr-eks/emr_eks/models/staging/
3└── imdb
4 ├── _imdb__models.yml
5 ├── _imdb__sources.yml
6 ├── stg_imdb__name_basics.sql
7 ├── stg_imdb__title_akas.sql
8 ├── stg_imdb__title_basics.sql
9 ├── stg_imdb__title_crews.sql
10 ├── stg_imdb__title_episodes.sql
11 ├── stg_imdb__title_principals.sql
12 └── stg_imdb__title_ratings.sql
Note that the model materialisation of the staging and intermediate models is view and the dbt project creates VIRTUAL_VIEW tables. Although we are able to reference those tables in other models, they cannot be queried by Athena.
1$ aws glue get-tables --database imdb \
2 --query "TableList[?Name=='stg_imdb__title_basics'].[Name, TableType, StorageDescriptor.Columns]" --output yaml
3- - stg_imdb__title_basics
4 - VIRTUAL_VIEW
5 - - Name: title_id
6 Type: string
7 - Name: title_type
8 Type: string
9 - Name: primary_title
10 Type: string
11 - Name: original_title
12 Type: string
13 - Name: is_adult
14 Type: boolean
15 - Name: start_year
16 Type: int
17 - Name: end_year
18 Type: int
19 - Name: runtime_minutes
20 Type: int
21 - Name: genres
22 Type: string
Instead we can use spark sql to query the tables. Below shows a query result of the title basics staging table in Glue Studio notebook.
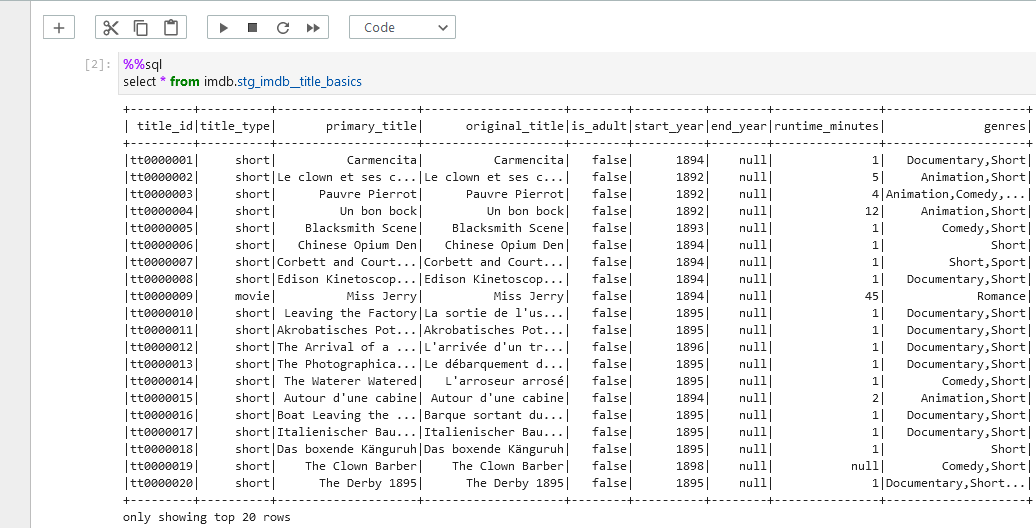
Intermediate
We can keep intermediate results in this layer so that the models of the final marts layer can be simplified. The source data includes columns where array values are kept as comma separated strings. For example, the genres column of the stg_imdb__title_basics model includes up to three genre values as shown in the previous screenshot. A total of seven columns in three models are columns of comma-separated strings, and it is better to flatten them in the intermediate layer. Also, in order to avoid repetition, a dbt macro (f_latten_fields_) is created to share the column-flattening logic.
1# emr-eks/emr_eks/macros/flatten_fields.sql
2{% macro flatten_fields(model, field_name, id_field_name) %}
3 select
4 {{ id_field_name }} as id,
5 explode(split({{ field_name }}, ',')) as field
6 from {{ model }}
7{% endmacro %}
The macro function can be added inside a common table expression (CTE) by specifying the relevant model, field name to flatten and ID field name.
1-- emr-eks/emr_eks/models/intermediate/title/int_genres_flattened_from_title_basics.sql
2with flattened as (
3 {{ flatten_fields(ref('stg_imdb__title_basics'), 'genres', 'title_id') }}
4)
5
6select
7 id as title_id,
8 field as genre
9from flattened
10order by id
The intermediate models are also materialised as views and we can check the array columns are flattened as expected.
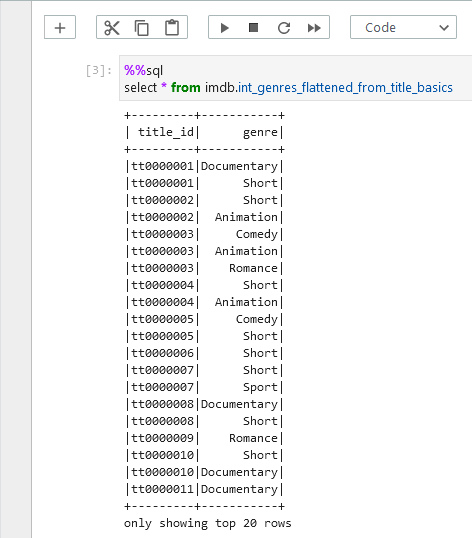
Below shows the file tree of the intermediate models. Similar to the staging models, the intermediate models can be executed by dbt run --select intermediate.
1$ tree emr-eks/emr_eks/models/intermediate/ emr-eks/emr_eks/macros/
2emr-eks/emr_eks/models/intermediate/
3├── name
4│ ├── _int_name__models.yml
5│ ├── int_known_for_titles_flattened_from_name_basics.sql
6│ └── int_primary_profession_flattened_from_name_basics.sql
7└── title
8 ├── _int_title__models.yml
9 ├── int_directors_flattened_from_title_crews.sql
10 ├── int_genres_flattened_from_title_basics.sql
11 └── int_writers_flattened_from_title_crews.sql
12
13emr-eks/emr_eks/macros/
14└── flatten_fields.sql
Marts
The models in the marts layer are configured to be materialised as tables in a custom schema. Their materialisation is set to table and the custom schema is specified as analytics while taking _parquet _as the file format. Note that the custom schema name becomes imdb_analytics according to the naming convention of dbt custom schemas. Models of both the staging and intermediate layers are used to create final models to be used for reporting and analytics.
1-- emr-eks/emr_eks/models/marts/analytics/titles.sql
2{{
3 config(
4 schema='analytics',
5 materialized='table',
6 file_format='parquet'
7 )
8}}
9
10with titles as (
11
12 select * from {{ ref('stg_imdb__title_basics') }}
13
14),
15
16principals as (
17
18 select
19 title_id,
20 count(name_id) as num_principals
21 from {{ ref('stg_imdb__title_principals') }}
22 group by title_id
23
24),
25
26names as (
27
28 select
29 title_id,
30 count(name_id) as num_names
31 from {{ ref('int_known_for_titles_flattened_from_name_basics') }}
32 group by title_id
33
34),
35
36ratings as (
37
38 select
39 title_id,
40 average_rating,
41 num_votes
42 from {{ ref('stg_imdb__title_ratings') }}
43
44),
45
46episodes as (
47
48 select
49 parent_title_id,
50 count(title_id) as num_episodes
51 from {{ ref('stg_imdb__title_episodes') }}
52 group by parent_title_id
53
54),
55
56distributions as (
57
58 select
59 title_id,
60 count(title) as num_distributions
61 from {{ ref('stg_imdb__title_akas') }}
62 group by title_id
63
64),
65
66final as (
67
68 select
69 t.title_id,
70 t.title_type,
71 t.primary_title,
72 t.original_title,
73 t.is_adult,
74 t.start_year,
75 t.end_year,
76 t.runtime_minutes,
77 t.genres,
78 p.num_principals,
79 n.num_names,
80 r.average_rating,
81 r.num_votes,
82 e.num_episodes,
83 d.num_distributions
84 from titles as t
85 left join principals as p on t.title_id = p.title_id
86 left join names as n on t.title_id = n.title_id
87 left join ratings as r on t.title_id = r.title_id
88 left join episodes as e on t.title_id = e.parent_title_id
89 left join distributions as d on t.title_id = d.title_id
90
91)
92
93select * from final
The details of the three models can be found in a YAML file (_analytics__models.yml). We can add tests to models and below we see tests of row count matching to their corresponding staging models.
1# emr-eks/emr_eks/models/marts/analytics/_analytics__models.yml
2version: 2
3
4models:
5 - name: names
6 description: Table that contains all names with additional details
7 tests:
8 - dbt_utils.equal_rowcount:
9 compare_model: ref('stg_imdb__name_basics')
10 - name: titles
11 description: Table that contains all titles with additional details
12 tests:
13 - dbt_utils.equal_rowcount:
14 compare_model: ref('stg_imdb__title_basics')
15 - name: genre_titles
16 description: Table that contains basic title details after flattening genres
The models of the marts layer can be tested using the dbt test command as shown below.
1$ dbt test --select marts
206:05:30 Running with dbt=1.3.0
306:05:30 Found 15 models, 17 tests, 0 snapshots, 0 analyses, 569 macros, 0 operations, 0 seed files, 7 sources, 0 exposures, 0 metrics
406:05:30
506:06:03 Concurrency: 3 threads (target='dev')
606:06:03
706:06:03 1 of 2 START test dbt_utils_equal_rowcount_names_ref_stg_imdb__name_basics_ .... [RUN]
806:06:03 2 of 2 START test dbt_utils_equal_rowcount_titles_ref_stg_imdb__title_basics_ .. [RUN]
906:06:57 1 of 2 PASS dbt_utils_equal_rowcount_names_ref_stg_imdb__name_basics_ .......... [PASS in 53.54s]
1006:06:59 2 of 2 PASS dbt_utils_equal_rowcount_titles_ref_stg_imdb__title_basics_ ........ [PASS in 56.40s]
1106:07:02
1206:07:02 Finished running 2 tests in 0 hours 1 minutes and 31.75 seconds (91.75s).
1306:07:02
1406:07:02 Completed successfully
1506:07:02
1606:07:02 Done. PASS=2 WARN=0 ERROR=0 SKIP=0 TOTAL=2
As with the other layers, the marts models can be executed by dbt run --select marts. While the transformation is performed, we can check the details from the spark history server. The SQL tab shows the three transformations in the marts layer.
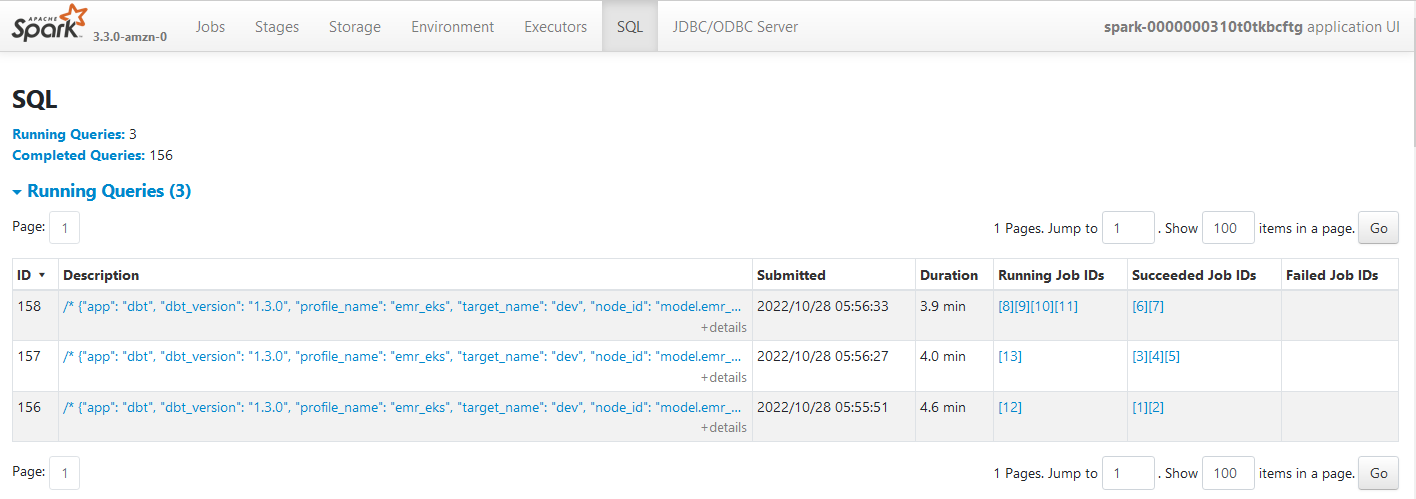
The file tree of the marts models can be found below.
1$ tree emr-eks/emr_eks/models/marts/
2emr-eks/emr_eks/models/marts/
3└── analytics
4 ├── _analytics__models.yml
5 ├── genre_titles.sql
6 ├── names.sql
7 └── titles.sql
Build Dashboard
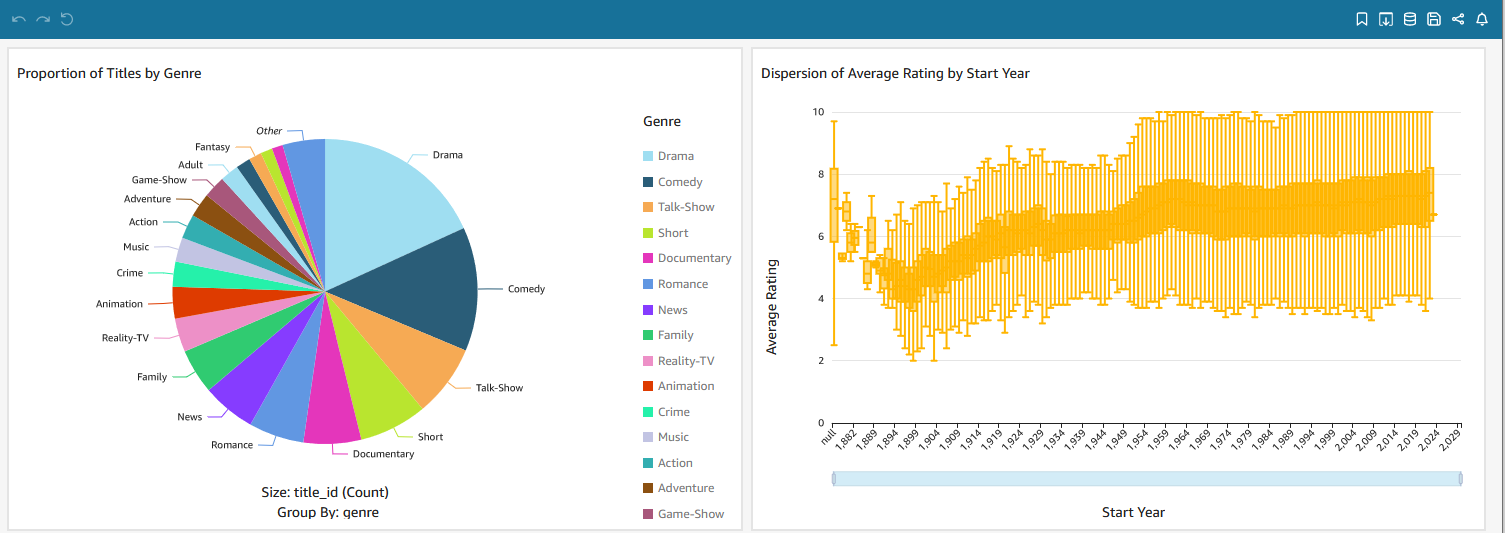
The models of the marts layer can be consumed by external tools such as Amazon QuickSight. Below shows an example dashboard. The pie chart on the left shows the proportion of titles by genre while the box plot on the right shows the dispersion of average rating by start year.
Generate dbt Documentation
A nice feature of dbt is documentation. It provides information about the project and the data warehouse, and it facilitates consumers as well as other developers to discover and understand the datasets better. We can generate the project documents and start a document server as shown below.
1$ dbt docs generate
2$ dbt docs serve
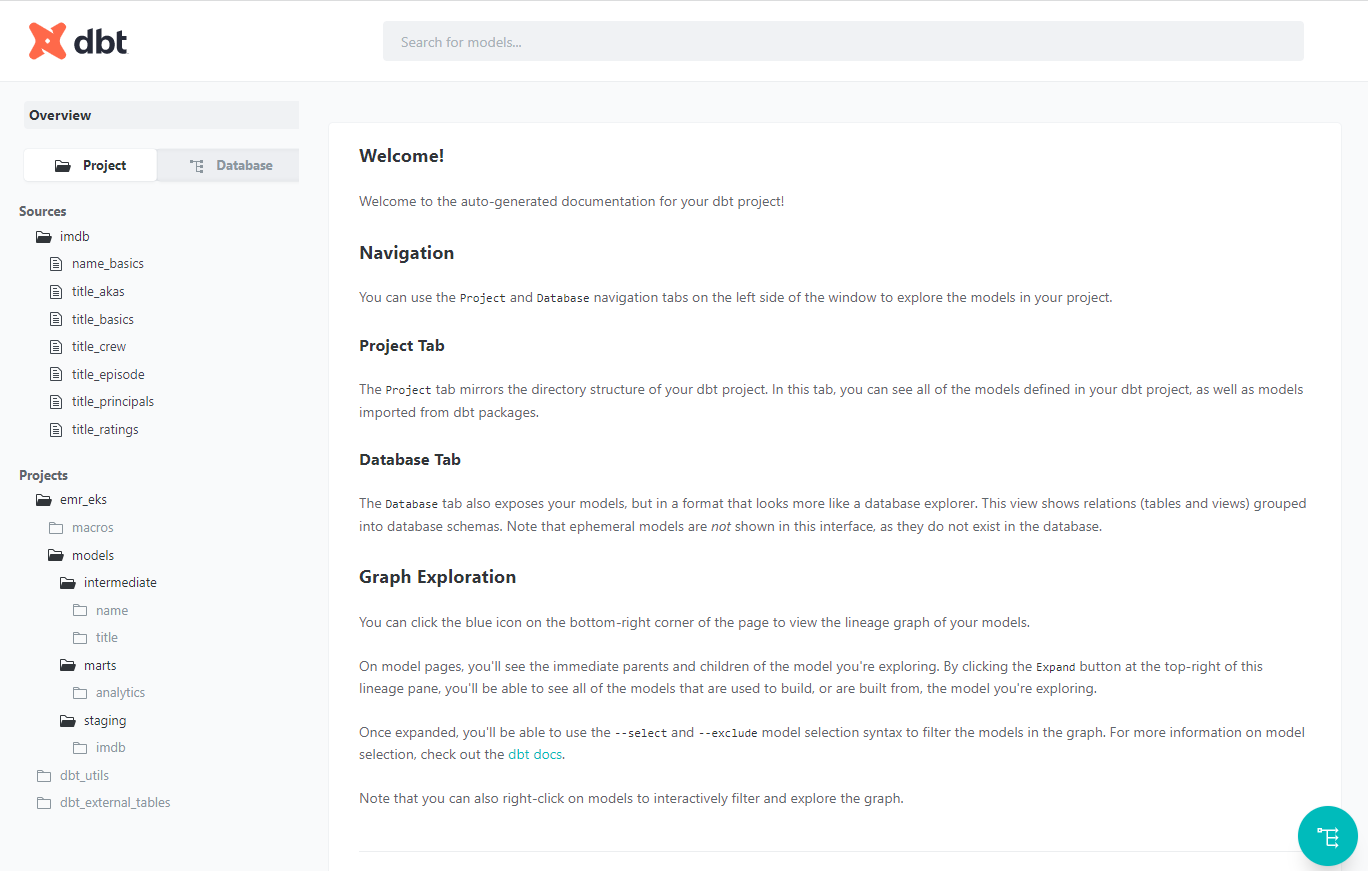
A very useful element of dbt documentation is data lineage, which provides an overall view about how data is transformed and consumed. Below we can see that the final titles model consumes all title-related stating models and an intermediate model from the name basics staging model.

Summary
In this post, we discussed how to build data transformation pipelines using dbt on Amazon EMR on EKS. As Spark Submit does not allow the spark thrift server to run in cluster mode on Kubernetes, a simple wrapper class was created that makes the thrift server run indefinitely. Subsets of IMDb data are used as source and data models are developed in multiple layers according to the dbt best practices. dbt can be used as an effective tool for data transformation in a wide range of data projects from data warehousing to data lake to data lakehouse, and it supports key AWS analytics services - Redshift, Glue, EMR and Athena. More examples of using dbt will be discussed in subsequent posts.










Comments