
[UPDATE 2025-10-01]
Bitnami’s public Docker images have been moved to the Bitnami Legacy repository. To ensure continued access and compatibility, please update your Docker image references accordingly.
For example:
bitnami/kafka:2.8.1→bitnamilegacy/kafka:2.8.1bitnami/zookeeper:3.7.0→bitnamilegacy/zookeeper:3.7.0bitnami/python:3.9.0→bitnamilegacy/python:3.9.0
Normally we consume Kafka messages from the beginning/end of a topic or last committed offsets. For backfilling or troubleshooting, however, we need to consume messages from a certain timestamp occasionally. If we know which topic partition to choose e.g. by assigning a topic partition, we can easily override the fetch offset to a specific timestamp. When we deploy multiple consumer instances together, however, we make them subscribe to a topic and topic partitions are dynamically assigned, which means we cannot determine which fetch offset to use for an instance. In this post, we develop Kafka producer and consumer applications using the kafka-python package and discuss how to configure the consumer instances to seek offsets to a specific timestamp where topic partitions are dynamically assigned by subscription.
Kafka Docker Environment
A single node Kafka cluster is created as a docker-compose service with Zookeeper, which is used to store the cluster metadata. Note that the Kafka and Zookeeper data directories are mapped to host directories so that Kafka topics and messages are preserved when the services are restarted. As discussed below, fake messages are published into a Kafka topic by a producer application, and it runs outside the docker network (kafkanet). In order for the producer to access the Kafka cluster, we need to add an external listener, and it is configured on port 9093. Finally, the Kafka UI is added for monitoring the Kafka broker and related resources. The source can be found in the GitHub repository for this post.
1# offset-seeking/compose-kafka.yml
2version: "3"
3
4services:
5 zookeeper:
6 image: bitnami/zookeeper:3.7.0
7 container_name: zookeeper
8 ports:
9 - "2181:2181"
10 networks:
11 - kafkanet
12 environment:
13 - ALLOW_ANONYMOUS_LOGIN=yes
14 volumes:
15 - ./.bitnami/zookeeper/data:/bitnami/zookeeper/data
16 kafka:
17 image: bitnami/kafka:2.8.1
18 container_name: kafka
19 expose:
20 - 9092
21 ports:
22 - "9093:9093"
23 networks:
24 - kafkanet
25 environment:
26 - ALLOW_PLAINTEXT_LISTENER=yes
27 - KAFKA_CFG_ZOOKEEPER_CONNECT=zookeeper:2181
28 - KAFKA_CFG_BROKER_ID=0
29 - KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CLIENT:PLAINTEXT,EXTERNAL:PLAINTEXT
30 - KAFKA_CFG_LISTENERS=CLIENT://:9092,EXTERNAL://:9093
31 - KAFKA_CFG_ADVERTISED_LISTENERS=CLIENT://kafka:9092,EXTERNAL://localhost:9093
32 - KAFKA_CFG_INTER_BROKER_LISTENER_NAME=CLIENT
33 volumes:
34 - ./.bitnami/kafka/data:/bitnami/kafka/data
35 - ./.bitnami/kafka/logs:/opt/bitnami/kafka/logs
36 depends_on:
37 - zookeeper
38 kafka-ui:
39 image: provectuslabs/kafka-ui:master
40 container_name: kafka-ui
41 ports:
42 - "8080:8080"
43 networks:
44 - kafkanet
45 environment:
46 KAFKA_CLUSTERS_0_NAME: local
47 KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS: kafka:9092
48 KAFKA_CLUSTERS_0_ZOOKEEPER: zookeeper:2181
49 depends_on:
50 - zookeeper
51 - kafka
52
53networks:
54 kafkanet:
55 name: kafka-network
Before we start the services, we need to create the directories that are used for volume-mapping and to update their permission. Then the services can be started as usual. A Kafka topic having two partitions is used in this post, and it is created manually as it is different from the default configuration.
1# create folders that will be volume-mapped and update permission
2$ mkdir -p .bitnami/zookeeper/data .bitnami/kafka/data .bitnami/kafka/logs \
3 && chmod 777 -R .bitnami
4
5# start docker services - zookeeper, kafka and kafka-ui
6$ docker-compose -f compose-kafka.yml up -d
7
8# create a topic named orders with 2 partitions
9$ docker exec -it kafka \
10 bash -c "/opt/bitnami/kafka/bin/kafka-topics.sh \
11 --create --topic orders --partitions 2 --bootstrap-server kafka:9092"
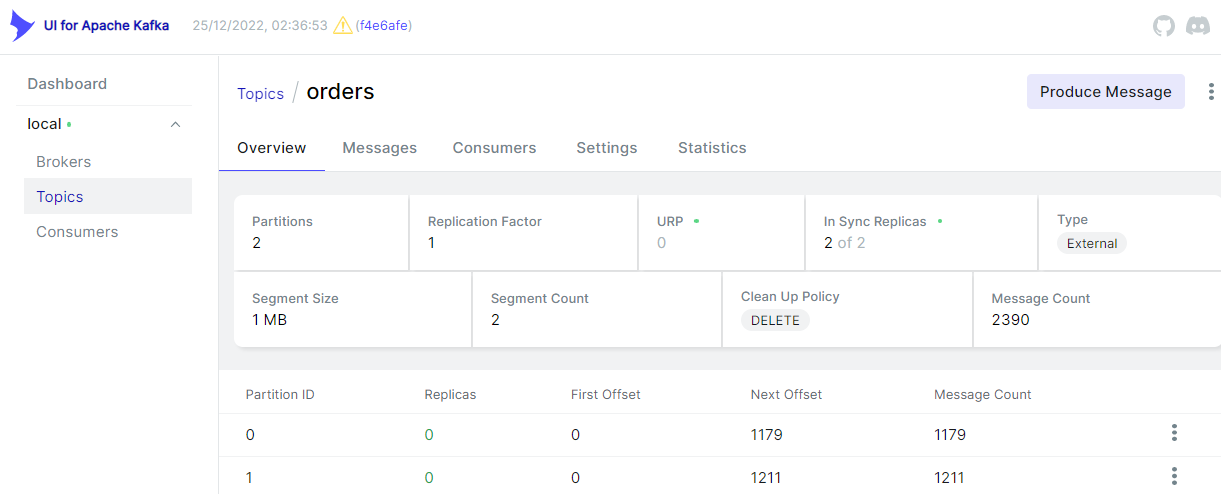
The topic can be checked in the Kafka UI as shown below.

Kafka Producer Application
A Kafka producer is created to send messages to the orders topic and fake messages are generated using the Faker package.
Order Data
The Order class generates one or more fake order records by the create method. An order record includes order ID, order timestamp, customer and order items.
1# offset-seeking/producer.py
2class Order:
3 def __init__(self, fake: Faker = None):
4 self.fake = fake or Faker()
5
6 def order(self):
7 return {"order_id": self.fake.uuid4(), "ordered_at": self.fake.date_time_this_decade()}
8
9 def items(self):
10 return [
11 {"product_id": self.fake.uuid4(), "quantity": self.fake.random_int(1, 10)}
12 for _ in range(self.fake.random_int(1, 4))
13 ]
14
15 def customer(self):
16 name = self.fake.name()
17 email = f'{re.sub(" ", "_", name.lower())}@{re.sub(r"^.*?@", "", self.fake.email())}'
18 return {
19 "user_id": self.fake.uuid4(),
20 "name": name,
21 "dob": self.fake.date_of_birth(),
22 "address": self.fake.address(),
23 "phone": self.fake.phone_number(),
24 "email": email,
25 }
26
27 def create(self, num: int):
28 return [
29 {**self.order(), **{"items": self.items(), "customer": self.customer()}}
30 for _ in range(num)
31 ]
A sample order record is shown below.
1{
2 "order_id": "567b3036-9ac4-440c-8849-ba4d263796db",
3 "ordered_at": "2022-11-09T21:24:55",
4 "items": [
5 {
6 "product_id": "7289ca92-eabf-4ebc-883c-530e16ecf9a3",
7 "quantity": 7
8 },
9 {
10 "product_id": "2ab8a155-bb15-4550-9ade-44d0bf2c730a",
11 "quantity": 5
12 },
13 {
14 "product_id": "81538fa2-6bc0-4903-a40f-a9303e5d3583",
15 "quantity": 3
16 }
17 ],
18 "customer": {
19 "user_id": "9a18e5f0-62eb-4b50-ae12-9f6f1bd1a80b",
20 "name": "David Boyle",
21 "dob": "1965-11-25",
22 "address": "8128 Whitney Branch\nNorth Brianmouth, MD 24870",
23 "phone": "843-345-1004",
24 "email": "david_boyle@example.org"
25 }
26}
Kafka Producer
The Kafka producer sends one or more order records. A message is made up of an order ID as the key and an order record as the value. Both the key and value are serialised as JSON. Once started, it sends order messages to the topic indefinitely and ten messages are sent in a loop. Note that the external listener (localhost:9093) is specified as the bootstrap server because it runs outside the docker network. We can run the producer app simply by python producer.py.
1# offset-seeking/producer.py
2class Producer:
3 def __init__(self, bootstrap_servers: list, topic: str):
4 self.bootstrap_servers = bootstrap_servers
5 self.topic = topic
6 self.producer = self.create()
7
8 def create(self):
9 return KafkaProducer(
10 bootstrap_servers=self.bootstrap_servers,
11 value_serializer=lambda v: json.dumps(v, default=self.serialize).encode("utf-8"),
12 key_serializer=lambda v: json.dumps(v, default=self.serialize).encode("utf-8"),
13 )
14
15 def send(self, orders: list):
16 for order in orders:
17 self.producer.send(self.topic, key={"order_id": order["order_id"]}, value=order)
18 self.producer.flush()
19
20 def serialize(self, obj):
21 if isinstance(obj, datetime.datetime):
22 return obj.isoformat()
23 if isinstance(obj, datetime.date):
24 return str(obj)
25 return obj
26
27
28if __name__ == "__main__":
29 fake = Faker()
30 # Faker.seed(1237)
31 producer = Producer(bootstrap_servers=["localhost:9093"], topic="orders")
32
33 while True:
34 orders = Order(fake).create(10)
35 producer.send(orders)
36 print("messages sent...")
37 time.sleep(5)
After a while, we can see that messages are sent to the orders topic. Out of 2390 messages, 1179 and 1211 messages are sent to the partition 0 and 1 respectively.
Kafka Consumer Application
Two consumer instances are deployed in the same consumer group. As the topic has two partitions, it is expected each instance is assigned to a single topic partition. A custom consumer rebalance listener is registered so that the fetch offset is overridden with an offset timestamp environment variable (offset_str) when a topic partition is assigned.
Custom Consumer Rebalance Listener
The consumer rebalancer listener is a callback interface that custom actions can be implemented when topic partitions are assigned or revoked. For each topic partition assigned, it obtains the earliest offset whose timestamp is greater than or equal to the given timestamp in the corresponding partition using the offsets_for_times method. Then it overrides the fetch offset using the seek method. Note that, as consumer instances can be rebalanced multiple times over time, the OFFSET_STR value is better to be stored in an external configuration store. In this way we can control whether to override fetch offsets by changing configuration externally.
1# offset-seeking/consumer.py
2class RebalanceListener(ConsumerRebalanceListener):
3 def __init__(self, consumer: KafkaConsumer, offset_str: str = None):
4 self.consumer = consumer
5 self.offset_str = offset_str
6
7 def on_partitions_revoked(self, revoked):
8 pass
9
10 def on_partitions_assigned(self, assigned):
11 ts = self.convert_to_ts(self.offset_str)
12 logging.info(f"offset_str - {self.offset_str}, timestamp - {ts}")
13 if ts is not None:
14 for tp in assigned:
15 logging.info(f"topic partition - {tp}")
16 self.seek_by_timestamp(tp.topic, tp.partition, ts)
17
18 def convert_to_ts(self, offset_str: str):
19 try:
20 dt = datetime.datetime.fromisoformat(offset_str)
21 return int(dt.timestamp() * 1000)
22 except Exception:
23 return None
24
25 def seek_by_timestamp(self, topic_name: str, partition: int, ts: int):
26 tp = TopicPartition(topic_name, partition)
27 offset_n_ts = self.consumer.offsets_for_times({tp: ts})
28 logging.info(f"offset and ts - {offset_n_ts}")
29 if offset_n_ts[tp] is not None:
30 offset = offset_n_ts[tp].offset
31 try:
32 self.consumer.seek(tp, offset)
33 except KafkaError:
34 logging.error("fails to seek offset")
35 else:
36 logging.warning("offset is not looked up")
Kafka Consumer
While it is a common practice to specify one or more Kafka topics in the Kafka consumer class when it is instantiated, the consumer omits them in the create method. It is in order to register the custom rebalance listener. In the process method, the consumer subscribes to the orders topic while registering the custom listener. After subscribing to the topic, it polls a single message at a time for ease of tracking.
1# offset-seeking/consumer.py
2class Consumer:
3 def __init__(
4 self, topics: list, group_id: str, bootstrap_servers: list, offset_str: str = None
5 ):
6 self.topics = topics
7 self.group_id = group_id
8 self.bootstrap_servers = bootstrap_servers
9 self.offset_str = offset_str
10 self.consumer = self.create()
11
12 def create(self):
13 return KafkaConsumer(
14 bootstrap_servers=self.bootstrap_servers,
15 auto_offset_reset="earliest",
16 enable_auto_commit=True,
17 group_id=self.group_id,
18 key_deserializer=lambda v: json.loads(v.decode("utf-8")),
19 value_deserializer=lambda v: json.loads(v.decode("utf-8")),
20 )
21
22 def process(self):
23 self.consumer.subscribe(
24 self.topics, listener=RebalanceListener(self.consumer, self.offset_str)
25 )
26 try:
27 while True:
28 msg = self.consumer.poll(timeout_ms=1000, max_records=1)
29 if msg is None:
30 continue
31 self.print_info(msg)
32 time.sleep(5)
33 except KafkaError as error:
34 logging.error(error)
35 finally:
36 self.consumer.close()
37
38 def print_info(self, msg: dict):
39 for _, v in msg.items():
40 for r in v:
41 ts = r.timestamp
42 dt = datetime.datetime.fromtimestamp(ts / 1000).isoformat()
43 logging.info(
44 f"topic - {r.topic}, partition - {r.partition}, offset - {r.offset}, ts - {ts}, dt - {dt})"
45 )
46
47
48if __name__ == "__main__":
49 consumer = Consumer(
50 topics=os.getenv("TOPICS", "orders").split(","),
51 group_id=os.getenv("GROUP_ID", "orders-group"),
52 bootstrap_servers=os.getenv("BOOTSTRAP_SERVERS", "localhost:9093").split(","),
53 offset_str=os.getenv("OFFSET_STR", None),
54 )
55 consumer.process()
Docker-compose is used to deploy multiple instances of the consumer. Note that the compose service uses the same docker network (kafkanet) so that it can use kafka:9092 as the bootstrap server address. The OFFSET_STR environment variable is used to override the fetch offset.
1# offset-seeking/compose-consumer.yml
2version: "3"
3
4services:
5 consumer:
6 image: bitnami/python:3.9
7 command: "sh -c 'pip install -r requirements.txt && python consumer.py'"
8 networks:
9 - kafkanet
10 environment:
11 TOPICS: orders
12 GROUP_ID: orders-group
13 BOOTSTRAP_SERVERS: kafka:9092
14 OFFSET_STR: "2023-01-06T19:00:00"
15 TZ: Australia/Sydney
16 volumes:
17 - .:/app
18networks:
19 kafkanet:
20 external: true
21 name: kafka-network
We can start two consumer instances by scaling the consumer service number to 2.
1# start 2 instances of kafka consumer
2$ docker-compose -f compose-consumer.yml up -d --scale consumer=2
Soon after the instances start to poll messages, we can see that their fetch offsets are updated as the current offset values are much higher than 0.

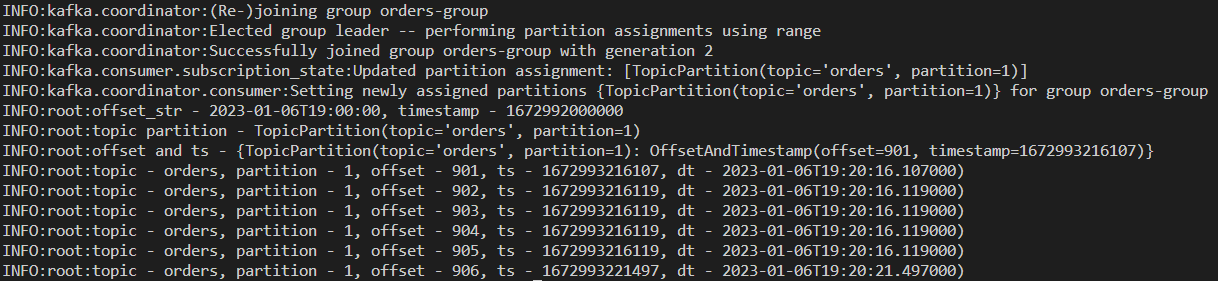
We can check logs of the consumer instances in order to check their behaviour further. Below shows the logs of one of the instances.
1# check logs of consumer instance 1
2$ docker logs offset-seeking-consumer-1
We see that the partition 1 is assigned to this instance. The offset 901 is taken to override and the message timestamp of that message is 2023-01-06T19:20:16.107000, which is later than the OFFSET_STR environment value.
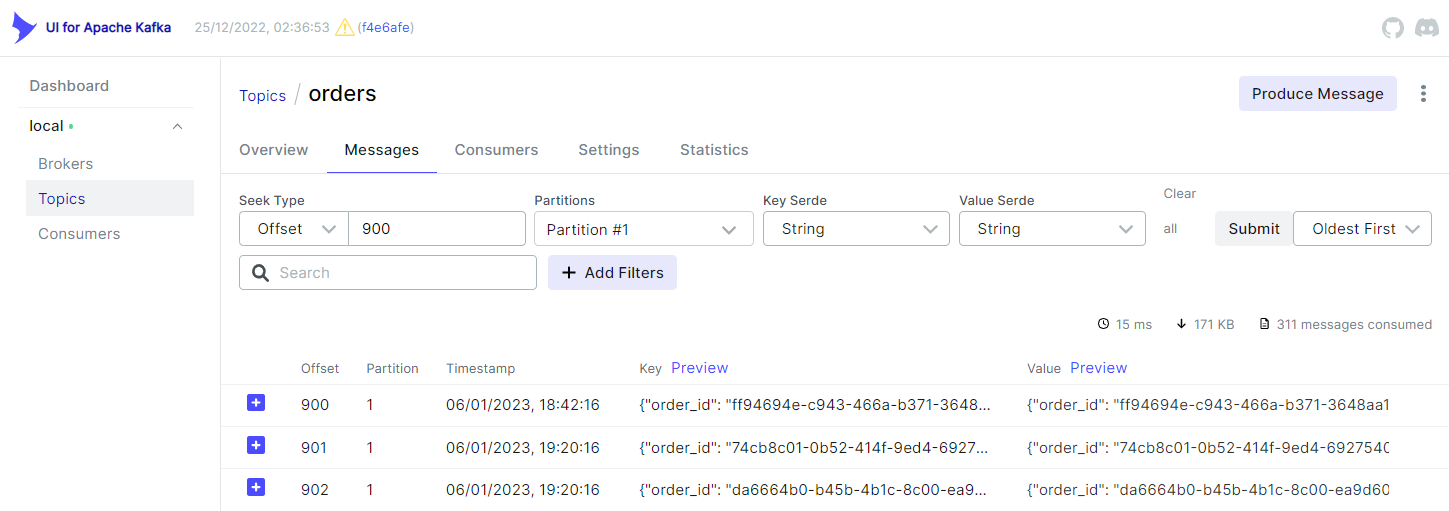
We can also check that the correct offset is obtained as the message timestamp of offset 900 is earlier than the OFFSET_STR value.
Summary
In this post, we discussed how to configure Kafka consumers to seek offsets by timestamp. A single node Kafka cluster was created using docker compose and a Kafka producer was used to send fake order messages. While subscribing to the orders topic, the consumer registered a custom consumer rebalance listener that overrides the fetch offsets by timestamp. Two consumer instances were deployed using docker compose and their behaviour was analysed in detail.










Comments