
In Part 1, we discussed a streaming ingestion solution using EventBridge, Lambda, MSK and Redshift Serverless. Athena provides the MSK connector to enable SQL queries on Apache Kafka topics directly, and it can also facilitate the extraction of insights without setting up an additional pipeline to store data into S3. In this post, we discuss how to update the streaming ingestion solution so that data in the Kafka topic can be queried by Athena instead of Redshift.
- Part 1 MSK and Redshift
- Part 2 MSK and Athena (this post)
Architecture
As Part 1, fake online order data is generated by multiple Lambda functions that are invoked by an EventBridge schedule rule. The schedule is set to run every minute and the associating rule has a configurable number (e.g. 5) of targets. Each target points to the same Kafka producer Lambda function. In this way we are able to generate test data using multiple Lambda functions according to the desired volume of messages. Once messages are sent to a Kafka topic, they can be consumed by the Athena MSK Connector, which is a Lambda function that can be installed from the AWS Serverless Application Repository. A new Athena data source needs to be created in order to deploy the connector and the schema of the topic should be registered with AWS Glue Schema Registry. The infrastructure is built by Terraform and the AWS SAM CLI is used to develop the producer Lambda function locally before deploying to AWS.

Infrastructure
The ingestion solution shares a large portion of infrastructure and only new resources are covered in this post. The source can be found in the GitHub repository of this post.
Glue Schema
The order data is JSON format, and it has 4 attributes - order_id, ordered_at, _user_id _and items. Although the items attribute keeps an array of objects that includes _product_id _and quantity, it is specified as VARCHAR because the MSK connector doesn’t support complex types.
1{
2 "topicName": "orders",
3 "message": {
4 "dataFormat": "json",
5 "fields": [
6 {
7 "name": "order_id",
8 "mapping": "order_id",
9 "type": "VARCHAR"
10 },
11 {
12 "name": "ordered_at",
13 "mapping": "ordered_at",
14 "type": "TIMESTAMP",
15 "formatHint": "yyyy-MM-dd HH:mm:ss.SSS"
16 },
17 {
18 "name": "user_id",
19 "mapping": "user_id",
20 "type": "VARCHAR"
21 },
22 {
23 "name": "items",
24 "mapping": "items",
25 "type": "VARCHAR"
26 }
27 ]
28 }
29}
The registry and schema can be created as shown below. Note the description should include the string {AthenaFederationMSK} as the marker string is required for AWS Glue Registries that you use with the Amazon Athena MSK connector.
1# integration-athena/infra/athena.tf
2resource "aws_glue_registry" "msk_registry" {
3 registry_name = "customer"
4 description = "{AthenaFederationMSK}"
5
6 tags = local.tags
7}
8
9resource "aws_glue_schema" "msk_schema" {
10 schema_name = "orders"
11 registry_arn = aws_glue_registry.msk_registry.arn
12 data_format = "JSON"
13 compatibility = "NONE"
14 schema_definition = jsonencode({ "topicName" : "orders", "message" : { "dataFormat" : "json", "fields" : [{ "name" : "order_id", "mapping" : "order_id", "type" : "VARCHAR" }, { "name" : "ordered_at", "mapping" : "ordered_at", "type" : "TIMESTAMP", "formatHint" : "yyyy-MM-dd HH:mm:ss.SSS" }, { "name" : "user_id", "mapping" : "user_id", "type" : "VARCHAR" }, { "name" : "items", "mapping" : "items", "type" : "VARCHAR" }] } })
15
16 tags = local.tags
17}
Athena MSK Connector
In Terraform, the MSK Connector Lambda function can be created by deploying the associated CloudFormation stack from the AWS Serverless Application Repository. The stack parameters are passed into environment variables of the function, and they are mostly used to establish connection to Kafka topics.
1# integration-athena/infra/athena.tf
2resource "aws_serverlessapplicationrepository_cloudformation_stack" "athena_msk_connector" {
3 name = "${local.name}-athena-msk-connector"
4 application_id = "arn:aws:serverlessrepo:us-east-1:292517598671:applications/AthenaMSKConnector"
5 semantic_version = "2023.8.3"
6 capabilities = [
7 "CAPABILITY_IAM",
8 "CAPABILITY_RESOURCE_POLICY",
9 ]
10 parameters = {
11 AuthType = "SASL_SSL_AWS_MSK_IAM"
12 KafkaEndpoint = aws_msk_cluster.msk_data_cluster.bootstrap_brokers_sasl_iam
13 LambdaFunctionName = "${local.name}-ingest-orders"
14 SpillBucket = aws_s3_bucket.default_bucket.id
15 SpillPrefix = "athena-spill"
16 SecurityGroupIds = aws_security_group.athena_connector.id
17 SubnetIds = join(",", module.vpc.private_subnets)
18 LambdaRoleARN = aws_iam_role.athena_connector_role.arn
19 }
20}
Lambda Execution Role
The AWS document doesn’t include the specific IAM permissions that are necessary for the connector function, and they are updated by making trials and errors. Therefore, some of them are too generous, and it should be refined later.
- First it needs permission to access an MSK cluster and topics, and they are copied from Part 1.
- Next access to the Glue registry and schema is required. I consider the required permission would have been more specific if a specific registry or schema could be specified to the connector Lambda function. Rather it searches applicable registries using a string marker and that requires an additional set of permissions.
- Then permission to the spill S3 bucket is added. I initially included a typical read/write permission on a specific bucket and objects, but the Lambda function complained by throwing 403 authorized errors. Therefore, I escalated the level of permissions, which is by no means acceptable in a strict environment. Further investigation is necessary for it.
- Finally, permission to get Athena query executions is added.
1# integration-athena/infra/athena.tf
2resource "aws_iam_role" "athena_connector_role" {
3 name = "${local.name}-athena-connector-role"
4
5 assume_role_policy = data.aws_iam_policy_document.athena_connector_assume_role_policy.json
6 managed_policy_arns = [
7 "arn:aws:iam::aws:policy/service-role/AWSLambdaVPCAccessExecutionRole",
8 aws_iam_policy.athena_connector_permission.arn
9 ]
10}
11
12data "aws_iam_policy_document" "athena_connector_assume_role_policy" {
13 statement {
14 actions = ["sts:AssumeRole"]
15
16 principals {
17 type = "Service"
18 identifiers = [
19 "lambda.amazonaws.com"
20 ]
21 }
22 }
23}
24
25resource "aws_iam_policy" "athena_connector_permission" {
26 name = "${local.name}-athena-connector-permission"
27
28 policy = jsonencode({
29 Version = "2012-10-17"
30 Statement = [
31 {
32 Sid = "PermissionOnCluster"
33 Action = [
34 "kafka-cluster:ReadData",
35 "kafka-cluster:DescribeTopic",
36 "kafka-cluster:Connect",
37 ]
38 Effect = "Allow"
39 Resource = [
40 "arn:aws:kafka:*:${data.aws_caller_identity.current.account_id}:cluster/*/*",
41 "arn:aws:kafka:*:${data.aws_caller_identity.current.account_id}:topic/*/*"
42 ]
43 },
44 {
45 Sid = "PermissionOnGroups"
46 Action = [
47 "kafka:GetBootstrapBrokers"
48 ]
49 Effect = "Allow"
50 Resource = "*"
51 },
52 {
53 Sid = "PermissionOnGlueSchema"
54 Action = [
55 "glue:*Schema*",
56 "glue:ListRegistries"
57 ]
58 Effect = "Allow"
59 Resource = "*"
60 },
61 {
62 Sid = "PermissionOnS3"
63 Action = ["s3:*"]
64 Effect = "Allow"
65 Resource = "arn:aws:s3:::*"
66 },
67 {
68 Sid = "PermissionOnAthenaQuery"
69 Action = [
70 "athena:GetQueryExecution"
71 ]
72 Effect = "Allow"
73 Resource = "*"
74 }
75 ]
76 })
77}
Security Group
The security group and rules are shown below. Although the outbound rule is set to allow all protocol and port ranges, only port 443 and 9098 with the TCP protocol would be sufficient. The former is to access the Glue schema registry while the latter is for an MSK cluster with IAM authentication.
1# integration-athena/infra/athena.tf
2resource "aws_security_group" "athena_connector" {
3 name = "${local.name}-athena-connector"
4 vpc_id = module.vpc.vpc_id
5
6 lifecycle {
7 create_before_destroy = true
8 }
9
10 tags = local.tags
11}
12
13resource "aws_security_group_rule" "athena_connector_msk_egress" {
14 type = "egress"
15 description = "allow outbound all"
16 security_group_id = aws_security_group.athena_connector.id
17 protocol = "-1"
18 from_port = 0
19 to_port = 0
20 cidr_blocks = ["0.0.0.0/0"]
21}
Athena Data Source
Unfortunately connecting to MSK from Athena is yet to be supported by CloudFormation or Terraform, and it is performed on AWS console as shown below. First we begin by clicking on the Create data source button.
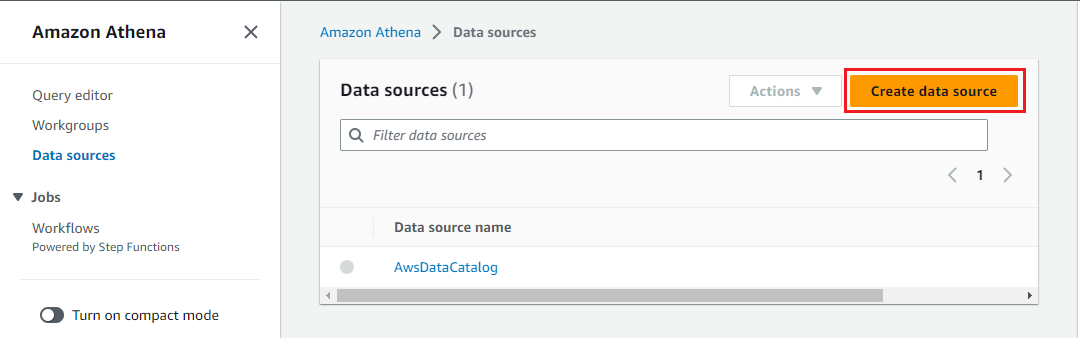
Then we can search the Amazon MSK data source and proceed by clicking on the _Next _button.

We can update data source details followed by selecting the connector Lambda function ARN in connection details.

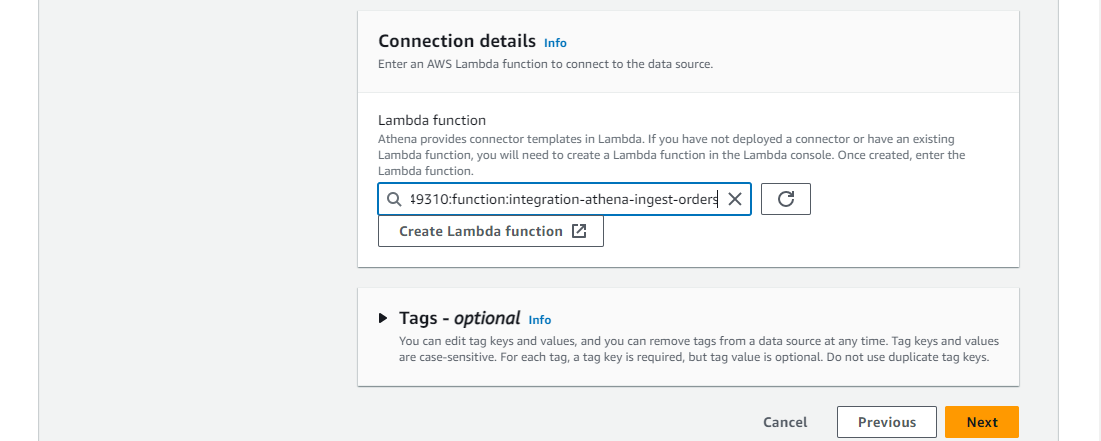
Once the data source connection is established, we are able to see the customer database we created earlier - the Glue registry name becomes the database name.

Also, we can check the table details from the Athena editor as shown below.
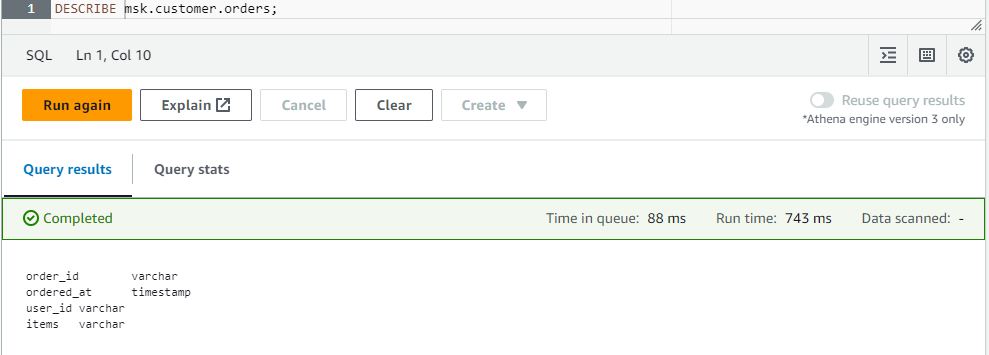
Kafka Producer
As in Part 1, the resources related to the Kafka producer Lambda function are managed in a separate Terraform stack. This is because it is easier to build the relevant resources iteratively. Note the SAM CLI builds the whole Terraform stack even for a small change of code, and it wouldn’t be convenient if the entire resources are managed in the same stack. The terraform stack of the producer is the same as Part 1, and it won’t be covered here. Only the producer Lambda function source is covered here as it is modified in order to comply with the MSK connector.
Producer Source
The Kafka producer is created to send messages to a topic named orders where fake order data is generated using the Faker package. The Order class generates one or more fake order records by the _create _method and an order record includes order ID, order timestamp, user ID and order items. Note order items are converted into string. It is because the MSK connector fails to parse them correctly. Actually the AWS document indicates the MSK connector interprets complex types as strings and I thought it would be converted into strings internally. However, it turned out the list items (or array of objects) cannot be queried by Athena. Therefore, it is converted into string in the first place. The Lambda function sends 100 records at a time followed by sleeping for 1 second. It repeats until it reaches MAX_RUN_SEC (e.g. 60) environment variable value. A Kafka message is made up of an order ID as the key and an order record as the value. Both the key and value are serialised as JSON. Note that the stable version of the kafka-python package does not support the IAM authentication method. Therefore, we need to install the package from a forked repository as discussed in this GitHub issue.
1# integration-athena/kafka_producer/src/app.py
2import os
3import re
4import datetime
5import string
6import json
7import time
8from kafka import KafkaProducer
9from faker import Faker
10
11
12class Order:
13 def __init__(self, fake: Faker = None):
14 self.fake = fake or Faker()
15
16 def order(self):
17 rand_int = self.fake.random_int(1, 1000)
18 user_id = "".join(
19 [string.ascii_lowercase[int(s)] if s.isdigit() else s for s in hex(rand_int)]
20 )[::-1]
21 return {
22 "order_id": self.fake.uuid4(),
23 "ordered_at": datetime.datetime.utcnow(),
24 "user_id": user_id,
25 }
26
27 def items(self):
28 return [
29 {
30 "product_id": self.fake.random_int(1, 9999),
31 "quantity": self.fake.random_int(1, 10),
32 }
33 for _ in range(self.fake.random_int(1, 4))
34 ]
35
36 def create(self, num: int):
37 return [{**self.order(), **{"items": json.dumps(self.items())}} for _ in range(num)]
38
39
40class Producer:
41 def __init__(self, bootstrap_servers: list, topic: str):
42 self.bootstrap_servers = bootstrap_servers
43 self.topic = topic
44 self.producer = self.create()
45
46 def create(self):
47 return KafkaProducer(
48 security_protocol="SASL_SSL",
49 sasl_mechanism="AWS_MSK_IAM",
50 bootstrap_servers=self.bootstrap_servers,
51 value_serializer=lambda v: json.dumps(v, default=self.serialize).encode("utf-8"),
52 key_serializer=lambda v: json.dumps(v, default=self.serialize).encode("utf-8"),
53 )
54
55 def send(self, orders: list):
56 for order in orders:
57 self.producer.send(self.topic, key={"order_id": order["order_id"]}, value=order)
58 self.producer.flush()
59
60 def serialize(self, obj):
61 if isinstance(obj, datetime.datetime):
62 return re.sub("T", " ", obj.isoformat(timespec="milliseconds"))
63 if isinstance(obj, datetime.date):
64 return str(obj)
65 return obj
66
67
68def lambda_function(event, context):
69 if os.getenv("BOOTSTRAP_SERVERS", "") == "":
70 return
71 fake = Faker()
72 producer = Producer(
73 bootstrap_servers=os.getenv("BOOTSTRAP_SERVERS").split(","), topic=os.getenv("TOPIC_NAME")
74 )
75 s = datetime.datetime.now()
76 ttl_rec = 0
77 while True:
78 orders = Order(fake).create(100)
79 producer.send(orders)
80 ttl_rec += len(orders)
81 print(f"sent {len(orders)} messages")
82 elapsed_sec = (datetime.datetime.now() - s).seconds
83 if elapsed_sec > int(os.getenv("MAX_RUN_SEC", "60")):
84 print(f"{ttl_rec} records are sent in {elapsed_sec} seconds ...")
85 break
86 time.sleep(1)
A sample order record is shown below.
1{
2 "order_id": "6049dc71-063b-49bd-8b68-f2326d1c8544",
3 "ordered_at": "2023-03-09 21:05:00.073",
4 "user_id": "febxa",
5 "items": "[{\"product_id\": 4793, \"quantity\": 8}]"
6}
Deployment
In this section, we skip shared steps except for local development with SAM and analytics query building. See Part 1 for other steps.
Local Testing with SAM
To simplify development, the Eventbridge permission is disabled by setting to_enable_trigger to false. Also, it is shortened to loop before it gets stopped by reducing msx_run_sec to 10.
1# integration-athena/kafka_producer/variables.tf
2locals {
3 producer = {
4 ...
5 to_enable_trigger = false
6 environment = {
7 topic_name = "orders"
8 max_run_sec = 10
9 }
10 }
11 ...
12}
The Lambda function can be built with the SAM build command while specifying the hook name as terraform and enabling beta features. Once completed, it stores the build artifacts and template in the .aws-sam folder.
1$ sam build --hook-name terraform --beta-features
2
3# Apply complete! Resources: 3 added, 0 changed, 0 destroyed.
4
5
6# Build Succeeded
7
8# Built Artifacts : .aws-sam/build
9# Built Template : .aws-sam/build/template.yaml
10
11# Commands you can use next
12# =========================
13# [*] Invoke Function: sam local invoke --hook-name terraform
14# [*] Emulate local Lambda functions: sam local start-lambda --hook-name terraform
We can invoke the Lambda function locally using the SAM local invoke command. The Lambda function is invoked in a Docker container and the invocation logs are printed in the terminal as shown below.
1$ sam local invoke --hook-name terraform module.kafka_producer_lambda.aws_lambda_function.this[0] --beta-features
2
3# Experimental features are enabled for this session.
4# Visit the docs page to learn more about the AWS Beta terms https://aws.amazon.com/service-terms/.
5
6# Skipped prepare hook. Current application is already prepared.
7# Invoking app.lambda_function (python3.8)
8# Skip pulling image and use local one: public.ecr.aws/sam/emulation-python3.8:rapid-1.70.0-x86_64.
9
10# Mounting .../kafka-pocs/integration-athena/kafka_producer/.aws-sam/build/ModuleKafkaProducerLambdaAwsLambdaFunctionThis069E06354 as /var/task:ro,delegated inside runtime container
11# START RequestId: d800173a-ceb5-4002-be0e-6f0d9628b639 Version: $LATEST
12# sent 100 messages
13# sent 100 messages
14# sent 100 messages
15# sent 100 messages
16# sent 100 messages
17# sent 100 messages
18# sent 100 messages
19# sent 100 messages
20# sent 100 messages
21# sent 100 messages
22# sent 100 messages
23# sent 100 messages
24# 1200 records are sent in 11 seconds ...
25# END RequestId: d800173a-ceb5-4002-be0e-6f0d9628b639
26# REPORT RequestId: d800173a-ceb5-4002-be0e-6f0d9628b639 Init Duration: 0.16 ms Duration: 12117.64 ms Billed Duration: 12118 ms Memory Size: 128 MB Max Memory Used: 128 MB
27# null
We can also check the messages using kafka-ui.
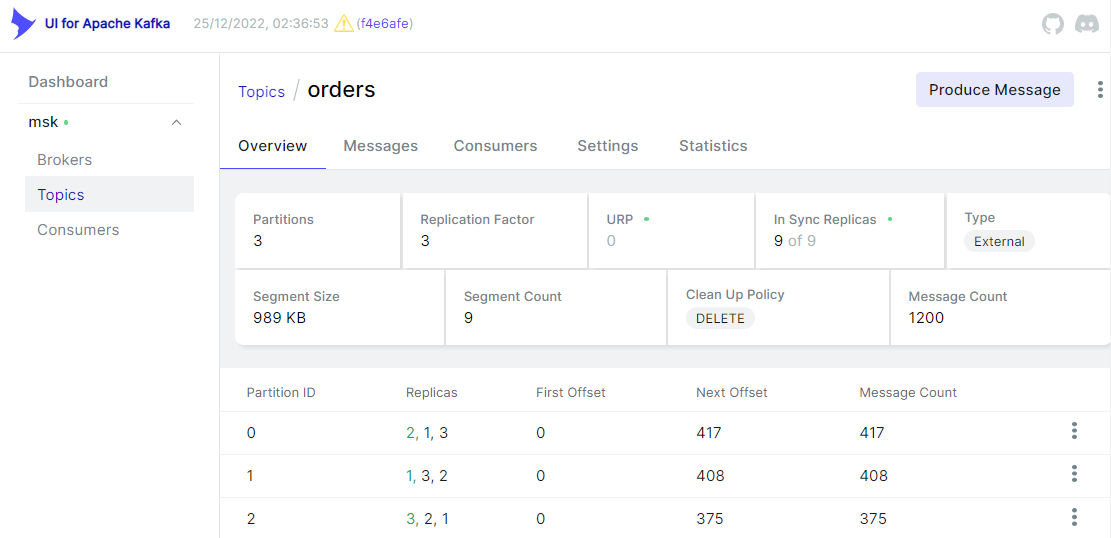
Order Items Query
Below shows the query result of the orders table. The _items _column is a JSON array but it is stored as string. In order to build analytics queries, we need to flatten the array elements into rows and it is discussed below.
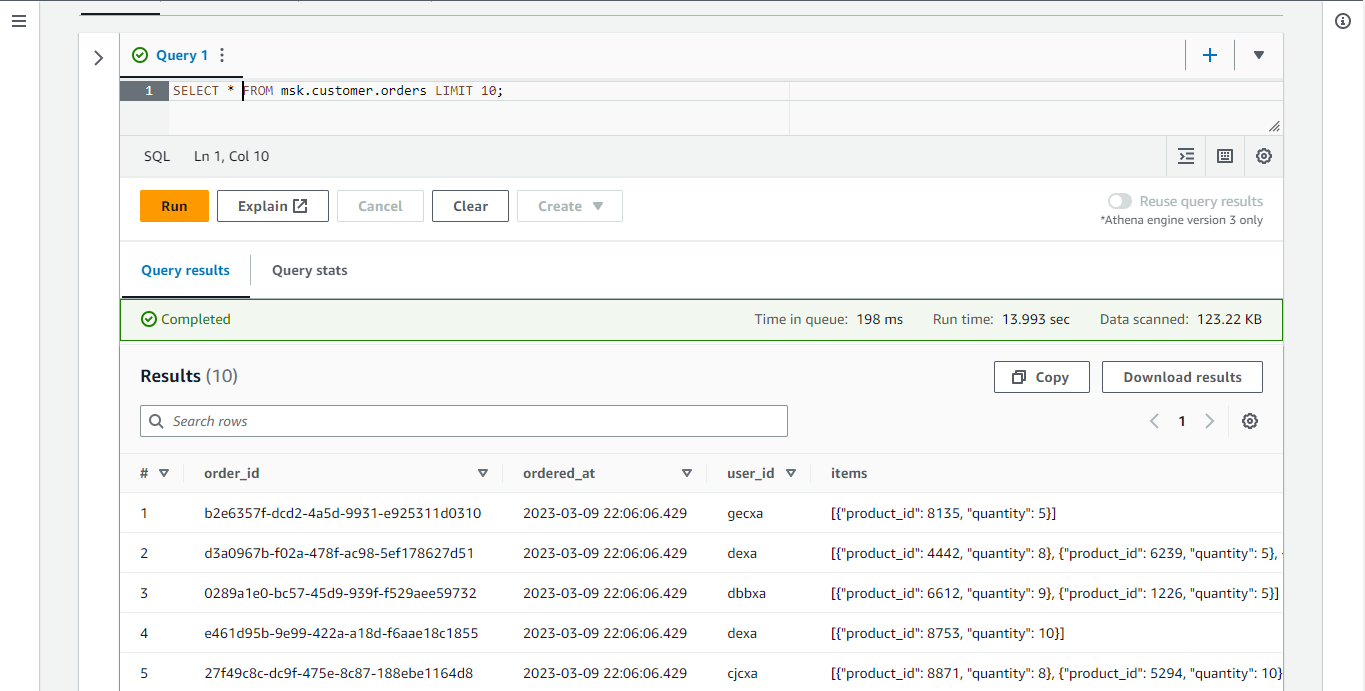
We can flatten the order items using the _UNNEST _function and CROSS JOIN. We first need to convert it into an array type, and it is implemented by parsing the column into JSON followed by type-casting it into an array in a CTE.
1WITH parsed AS (
2 SELECT
3 order_id,
4 ordered_at,
5 user_id,
6 CAST(json_parse(items) as ARRAY(ROW(product_id INT, quantity INT))) AS items
7 FROM msk.customer.orders
8)
9SELECT
10 order_id,
11 ordered_at,
12 user_id,
13 items_unnested.product_id,
14 items_unnested.quantity
15FROM parsed
16CROSS JOIN unnest(parsed.items) AS t(items_unnested)
We can see the flattened order items as shown below.

The remaining sections cover deploying the Kafka producer Lambda, producing messages and executing an analytics query. They are skipped in this post as they are exactly and/or almost the same. See Part 1 if you would like to check it.
Summary
Streaming ingestion to Redshift and Athena becomes much simpler thanks to new features. In this series of posts, we discussed those features by building a solution using EventBridge, Lambda, MSK, Redshift and Athena. We also covered AWS SAM integrated with Terraform for developing a Lambda function locally.










Comments