
[UPDATE 2025-10-01]
Bitnami’s public Docker images have been moved to the Bitnami Legacy repository. To ensure continued access and compatibility, please update your Docker image references accordingly.
For example:
bitnami/kafka:2.8.1→bitnamilegacy/kafka:2.8.1bitnami/zookeeper:3.7.0→bitnamilegacy/zookeeper:3.7.0bitnami/python:3.9.0→bitnamilegacy/python:3.9.0
As Kafka producer and consumer apps are decoupled, they operate on Kafka topics rather than communicating with each other directly. As described in the Confluent document, Schema Registry provides a centralized repository for managing and validating schemas for topic message data, and for serialization and deserialization of the data over the network. Producers and consumers to Kafka topics can use schemas to ensure data consistency and compatibility as schemas evolve. In AWS, the Glue Schema Registry supports features to manage and enforce schemas on data streaming applications using convenient integrations with Apache Kafka, Amazon Managed Streaming for Apache Kafka, Amazon Kinesis Data Streams, Amazon Kinesis Data Analytics for Apache Flink, and AWS Lambda. In this post, we will discuss how to integrate Python Kafka producer and consumer apps In AWS Lambda with the Glue Schema Registry.
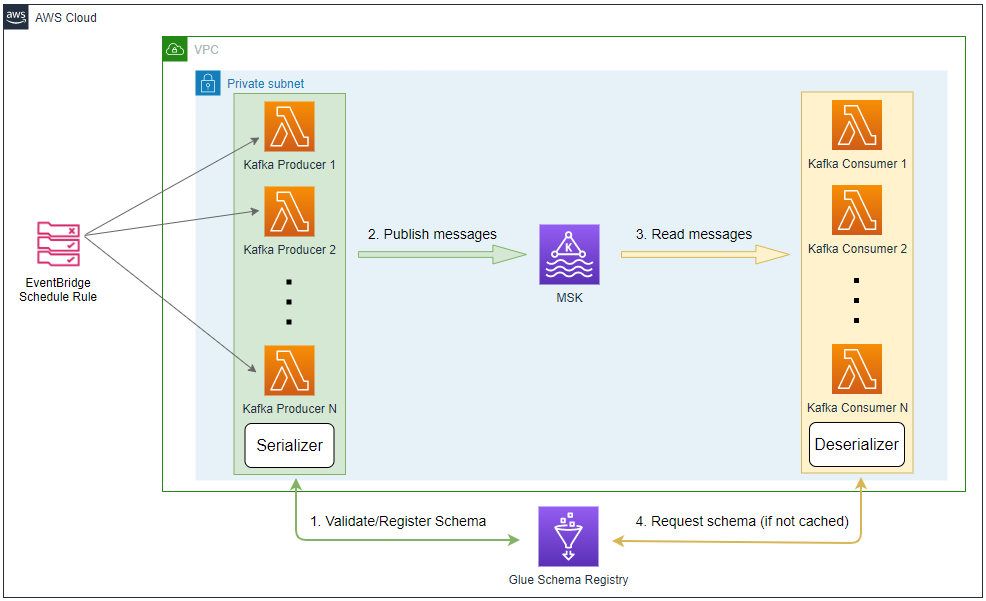
Architecture
Fake online order data is generated by multiple Lambda functions that are invoked by an EventBridge schedule rule. The schedule is set to run every minute and the associating rule has a configurable number (e.g. 5) of targets. Each target points to the same Kafka producer Lambda function. In this way we are able to generate test data using multiple Lambda functions according to the desired volume of messages. Note that, before sending a message, the producer validates the schema and registers a new one if it is not registered yet. Then it serializes the message and sends it to the cluster.
Once messages are sent to a Kafka topic, they can be consumed by Lambda where Amazon MSK is configured as an event source. The serialized record (message key or value) includes the schema ID so that the consumer can request the schema from the schema registry (if not cached) in order to deserialize it.
The infrastructure is built by Terraform and the AWS SAM CLI is used to develop the producer Lambda function locally before deploying to AWS.
Infrastructure
A VPC with 3 public and private subnets is created using the AWS VPC Terraform module (vpc.tf). Also, a SoftEther VPN server is deployed in order to access the resources in the private subnets from the developer machine (vpn.tf). It is particularly useful to monitor and manage the MSK cluster and Kafka topic as well as developing the Kafka producer Lambda function locally. The details about how to configure the VPN server can be found in an earlier post. The source can be found in the GitHub repository of this post.
MSK
An MSK cluster with 3 brokers is created. The broker nodes are deployed with the kafka.m5.large instance type in private subnets and IAM authentication is used for the client authentication method. Finally, additional server configurations are added such as enabling auto creation of topics and topic deletion.
1# glue-schema-registry/infra/variable.tf
2locals {
3 ...
4 msk = {
5 version = "3.3.1"
6 instance_size = "kafka.m5.large"
7 ebs_volume_size = 20
8 log_retention_ms = 604800000 # 7 days
9 }
10 ...
11}
12# glue-schema-registry/infra/msk.tf
13resource "aws_msk_cluster" "msk_data_cluster" {
14 cluster_name = "${local.name}-msk-cluster"
15 kafka_version = local.msk.version
16 number_of_broker_nodes = length(module.vpc.private_subnets)
17 configuration_info {
18 arn = aws_msk_configuration.msk_config.arn
19 revision = aws_msk_configuration.msk_config.latest_revision
20 }
21
22 broker_node_group_info {
23 instance_type = local.msk.instance_size
24 client_subnets = module.vpc.private_subnets
25 security_groups = [aws_security_group.msk.id]
26 storage_info {
27 ebs_storage_info {
28 volume_size = local.msk.ebs_volume_size
29 }
30 }
31 }
32
33 client_authentication {
34 sasl {
35 iam = true
36 }
37 }
38
39 logging_info {
40 broker_logs {
41 cloudwatch_logs {
42 enabled = true
43 log_group = aws_cloudwatch_log_group.msk_cluster_lg.name
44 }
45 s3 {
46 enabled = true
47 bucket = aws_s3_bucket.default_bucket.id
48 prefix = "logs/msk/cluster-"
49 }
50 }
51 }
52
53 tags = local.tags
54
55 depends_on = [aws_msk_configuration.msk_config]
56}
57
58resource "aws_msk_configuration" "msk_config" {
59 name = "${local.name}-msk-configuration"
60
61 kafka_versions = [local.msk.version]
62
63 server_properties = <<PROPERTIES
64 auto.create.topics.enable = true
65 delete.topic.enable = true
66 log.retention.ms = ${local.msk.log_retention_ms}
67 PROPERTIES
68}
Security Groups
Two security groups are created - one for the MSK cluster and the other for the Lambda apps.
The inbound/outbound rules of the former are created for accessing the cluster by
- Event Source Mapping (ESM) for Lambda
- This is for the Lambda consumer that subscribes the MSK cluster. As described in the AWS re:Post doc, when a Lambda function is configured with an Amazon MSK trigger or a self-managed Kafka trigger, an ESM resource is automatically created. An ESM is separate from the Lambda function, and it continuously polls records from the topic in the Kafka cluster. The ESM bundles those records into a payload. Then, it calls the Lambda Invoke API to deliver the payload to your Lambda function for processing. Note it doesn’t inherit the VPC network settings of the Lambda function but uses the subnet and security group settings that are configured on the target MSK cluster. Therefore, the MSK cluster’s security group must include a rule that grants ingress traffic from itself and egress traffic to itself. For us, the rules on port 9098 as the cluster only supports IAM authentication. Also, an additional egress rule is created to access the Glue Schema Registry.
- Other Resources
- Two ingress rules are created for the VPN server and Lambda. The latter is only for the Lambda producer because the consumer doesn’t rely on the Lambda network setting.
The second security group is created here, while the Lambda function is created in a different Terraform stack. This is for ease of adding it to the inbound rule of the MSK’s security group. Later we will discuss how to make use of it with the Lambda function. The outbound rule allows all outbound traffic although only port 9098 for the MSK cluster and 443 for the Glue Schema Registry would be sufficient.
1# glue-schema-registry/infra/msk.tf
2resource "aws_security_group" "msk" {
3 name = "${local.name}-msk-sg"
4 vpc_id = module.vpc.vpc_id
5
6 lifecycle {
7 create_before_destroy = true
8 }
9
10 tags = local.tags
11}
12
13# for lambda event source mapping
14resource "aws_security_group_rule" "msk_ingress_self_broker" {
15 type = "ingress"
16 description = "msk ingress self"
17 security_group_id = aws_security_group.msk.id
18 protocol = "tcp"
19 from_port = 9098
20 to_port = 9098
21 source_security_group_id = aws_security_group.msk.id
22}
23
24resource "aws_security_group_rule" "msk_egress_self_broker" {
25 type = "egress"
26 description = "msk egress self"
27 security_group_id = aws_security_group.msk.id
28 protocol = "tcp"
29 from_port = 9098
30 to_port = 9098
31 source_security_group_id = aws_security_group.msk.id
32}
33
34resource "aws_security_group_rule" "msk_all_outbound" {
35 type = "egress"
36 description = "allow outbound all"
37 security_group_id = aws_security_group.msk.id
38 protocol = "-1"
39 from_port = "0"
40 to_port = "0"
41 cidr_blocks = ["0.0.0.0/0"]
42}
43
44# for other resources
45resource "aws_security_group_rule" "msk_vpn_inbound" {
46 count = local.vpn.to_create ? 1 : 0
47 type = "ingress"
48 description = "VPN access"
49 security_group_id = aws_security_group.msk.id
50 protocol = "tcp"
51 from_port = 9098
52 to_port = 9098
53 source_security_group_id = aws_security_group.vpn[0].id
54}
55
56resource "aws_security_group_rule" "msk_lambda_inbound" {
57 type = "ingress"
58 description = "lambda access"
59 security_group_id = aws_security_group.msk.id
60 protocol = "tcp"
61 from_port = 9098
62 to_port = 9098
63 source_security_group_id = aws_security_group.kafka_app_lambda.id
64}
65
66...
67
68# lambda security group
69resource "aws_security_group" "kafka_app_lambda" {
70 name = "${local.name}-lambda-msk-access"
71 vpc_id = module.vpc.vpc_id
72
73 lifecycle {
74 create_before_destroy = true
75 }
76
77 tags = local.tags
78}
79
80resource "aws_security_group_rule" "kafka_app_lambda_msk_egress" {
81 type = "egress"
82 description = "allow outbound all"
83 security_group_id = aws_security_group.kafka_app_lambda.id
84 protocol = "-1"
85 from_port = 0
86 to_port = 0
87 cidr_blocks = ["0.0.0.0/0"]
88}
Kafka Apps
The resources related to the Kafka producer and consumer Lambda functions are managed in a separate Terraform stack. This is because it is easier to build the relevant resources iteratively. Note the SAM CLI builds the whole Terraform stack even for a small change of code, and it wouldn’t be convenient if the entire resources are managed in the same stack.
Producer App
Order Data
Fake order data is generated using the Faker package and the dataclasses_avroschema package is used to automatically generate the Avro schema according to its attributes. A mixin class called InjectCompatMixin is injected into the Order class, which specifies a schema compatibility mode into the generated schema. The auto() class method is used to instantiate the class automatically. Finally, the OrderMore class is created for the schema evolution demo, which will be discussed later.
1# glue-schema-registry/app/producer/src/order.py
2import datetime
3import string
4import json
5import typing
6import dataclasses
7import enum
8
9from faker import Faker
10from dataclasses_avroschema import AvroModel
11
12
13class Compatibility(enum.Enum):
14 NONE = "NONE"
15 DISABLED = "DISABLED"
16 BACKWARD = "BACKWARD"
17 BACKWARD_ALL = "BACKWARD_ALL"
18 FORWARD = "FORWARD"
19 FORWARD_ALL = "FORWARD_ALL"
20 FULL = "FULL"
21 FULL_ALL = "FULL_ALL"
22
23
24class InjectCompatMixin:
25 @classmethod
26 def updated_avro_schema_to_python(cls, compat: Compatibility = Compatibility.BACKWARD):
27 schema = cls.avro_schema_to_python()
28 schema["compatibility"] = compat.value
29 return schema
30
31 @classmethod
32 def updated_avro_schema(cls, compat: Compatibility = Compatibility.BACKWARD):
33 schema = cls.updated_avro_schema_to_python(compat)
34 return json.dumps(schema)
35
36
37@dataclasses.dataclass
38class OrderItem(AvroModel):
39 product_id: int
40 quantity: int
41
42
43@dataclasses.dataclass
44class Order(AvroModel, InjectCompatMixin):
45 "Online fake order item"
46 order_id: str
47 ordered_at: datetime.datetime
48 user_id: str
49 order_items: typing.List[OrderItem]
50
51 class Meta:
52 namespace = "Order V1"
53
54 def asdict(self):
55 return dataclasses.asdict(self)
56
57 @classmethod
58 def auto(cls, fake: Faker = Faker()):
59 rand_int = fake.random_int(1, 1000)
60 user_id = "".join(
61 [string.ascii_lowercase[int(s)] if s.isdigit() else s for s in hex(rand_int)]
62 )[::-1]
63 order_items = [
64 OrderItem(fake.random_int(1, 9999), fake.random_int(1, 10))
65 for _ in range(fake.random_int(1, 4))
66 ]
67 return cls(fake.uuid4(), datetime.datetime.utcnow(), user_id, order_items)
68
69 def create(self, num: int):
70 return [self.auto() for _ in range(num)]
71
72
73@dataclasses.dataclass
74class OrderMore(Order):
75 is_prime: bool
76
77 @classmethod
78 def auto(cls, fake: Faker = Faker()):
79 o = Order.auto()
80 return cls(o.order_id, o.ordered_at, o.user_id, o.order_items, fake.pybool())
The generated schema of the Order class can be found below.
1{
2 "doc": "Online fake order item",
3 "namespace": "Order V1",
4 "name": "Order",
5 "compatibility": "BACKWARD",
6 "type": "record",
7 "fields": [
8 {
9 "name": "order_id",
10 "type": "string"
11 },
12 {
13 "name": "ordered_at",
14 "type": {
15 "type": "long",
16 "logicalType": "timestamp-millis"
17 }
18 },
19 {
20 "name": "user_id",
21 "type": "string"
22 },
23 {
24 "name": "order_items",
25 "type": {
26 "type": "array",
27 "items": {
28 "type": "record",
29 "name": "OrderItem",
30 "fields": [
31 {
32 "name": "product_id",
33 "type": "long"
34 },
35 {
36 "name": "quantity",
37 "type": "long"
38 }
39 ]
40 },
41 "name": "order_item"
42 }
43 }
44 ]
45}
Below shows an example order record.
1{
2 "order_id": "53263c42-81b3-4a53-8067-fcdb44fa5479",
3 "ordered_at": 1680745813045,
4 "user_id": "dicxa",
5 "order_items": [
6 {
7 "product_id": 5947,
8 "quantity": 8
9 }
10 ]
11}
Producer
The aws-glue-schema-registry package is used serialize the value of order messages. It provides the KafkaSerializer class that validates, registers and serializes the relevant records. It supports Json and Avro schemas, and we can add it to the value_serializer argument of the KafkaProducer class. By default, the schemas are named as <topic>-key and <topic>-value and it can be changed by updating the schema_naming_strategy argument. Note that, when sending a message, the value should be a tuple of data and schema. Note also that the stable version of the kafka-python package does not support the IAM authentication method. Therefore, we need to install the package from a forked repository as discussed in this GitHub issue.
1# glue-schema-registry/app/producer/src/producer.py
2import os
3import datetime
4import json
5import typing
6
7import boto3
8import botocore.exceptions
9from kafka import KafkaProducer
10from aws_schema_registry import SchemaRegistryClient
11from aws_schema_registry.avro import AvroSchema
12from aws_schema_registry.adapter.kafka import KafkaSerializer
13from aws_schema_registry.exception import SchemaRegistryException
14
15from .order import Order
16
17
18class Producer:
19 def __init__(self, bootstrap_servers: list, topic: str, registry: str, is_local: bool = False):
20 self.bootstrap_servers = bootstrap_servers
21 self.topic = topic
22 self.registry = registry
23 self.glue_client = boto3.client(
24 "glue", region_name=os.getenv("AWS_DEFAULT_REGION", "ap-southeast-2")
25 )
26 self.is_local = is_local
27 self.producer = self.create()
28
29 @property
30 def serializer(self):
31 client = SchemaRegistryClient(self.glue_client, registry_name=self.registry)
32 return KafkaSerializer(client)
33
34 def create(self):
35 params = {
36 "bootstrap_servers": self.bootstrap_servers,
37 "key_serializer": lambda v: json.dumps(v, default=self.serialize).encode("utf-8"),
38 "value_serializer": self.serializer,
39 }
40 if not self.is_local:
41 params = {
42 **params,
43 **{"security_protocol": "SASL_SSL", "sasl_mechanism": "AWS_MSK_IAM"},
44 }
45 return KafkaProducer(**params)
46
47 def send(self, orders: typing.List[Order], schema: AvroSchema):
48 if not self.check_registry():
49 print(f"registry not found, create {self.registry}")
50 self.create_registry()
51
52 for order in orders:
53 data = order.asdict()
54 try:
55 self.producer.send(
56 self.topic, key={"order_id": data["order_id"]}, value=(data, schema)
57 )
58 except SchemaRegistryException as e:
59 raise RuntimeError("fails to send a message") from e
60 self.producer.flush()
61
62 def serialize(self, obj):
63 if isinstance(obj, datetime.datetime):
64 return obj.isoformat()
65 if isinstance(obj, datetime.date):
66 return str(obj)
67 return obj
68
69 def check_registry(self):
70 try:
71 self.glue_client.get_registry(RegistryId={"RegistryName": self.registry})
72 return True
73 except botocore.exceptions.ClientError as e:
74 if e.response["Error"]["Code"] == "EntityNotFoundException":
75 return False
76 else:
77 raise e
78
79 def create_registry(self):
80 try:
81 self.glue_client.create_registry(RegistryName=self.registry)
82 return True
83 except botocore.exceptions.ClientError as e:
84 if e.response["Error"]["Code"] == "AlreadyExistsException":
85 return True
86 else:
87 raise e
Lambda Handler
The Lambda function sends 100 records at a time followed by sleeping for 1 second. It repeats until it reaches MAX_RUN_SEC (e.g. 60) environment variable value. The last conditional block is for demonstrating a schema evolution example, which will be discussed later.
1# glue-schema-registry/app/producer/lambda_handler.py
2import os
3import datetime
4import time
5
6from aws_schema_registry.avro import AvroSchema
7
8from src.order import Order, OrderMore, Compatibility
9from src.producer import Producer
10
11
12def lambda_function(event, context):
13 producer = Producer(
14 bootstrap_servers=os.environ["BOOTSTRAP_SERVERS"].split(","),
15 topic=os.environ["TOPIC_NAME"],
16 registry=os.environ["REGISTRY_NAME"],
17 )
18 s = datetime.datetime.now()
19 ttl_rec = 0
20 while True:
21 orders = Order.auto().create(100)
22 schema = AvroSchema(Order.updated_avro_schema(Compatibility.BACKWARD))
23 producer.send(orders, schema)
24 ttl_rec += len(orders)
25 print(f"sent {len(orders)} messages")
26 elapsed_sec = (datetime.datetime.now() - s).seconds
27 if elapsed_sec > int(os.getenv("MAX_RUN_SEC", "60")):
28 print(f"{ttl_rec} records are sent in {elapsed_sec} seconds ...")
29 break
30 time.sleep(1)
31
32
33if __name__ == "__main__":
34 producer = Producer(
35 bootstrap_servers=os.environ["BOOTSTRAP_SERVERS"].split(","),
36 topic=os.environ["TOPIC_NAME"],
37 registry=os.environ["REGISTRY_NAME"],
38 is_local=True,
39 )
40 use_more = os.getenv("USE_MORE") is not None
41 if not use_more:
42 orders = Order.auto().create(1)
43 schema = AvroSchema(Order.updated_avro_schema(Compatibility.BACKWARD))
44 else:
45 orders = OrderMore.auto().create(1)
46 schema = AvroSchema(OrderMore.updated_avro_schema(Compatibility.BACKWARD))
47 print(orders)
48 producer.send(orders, schema)
Lambda Resource
The VPC, subnets, Lambda security group and MSK cluster are created in the infra Terraform stack, and they need to be obtained from the Kafka app stack. It can be achieved using the Terraform data sources as shown below. Note that the private subnets can be filtered by a specific tag (Tier: Private), which is added when creating them.
1# glue-schema-registry/infra/vpc.tf
2module "vpc" {
3 source = "terraform-aws-modules/vpc/aws"
4 version = "~> 3.14"
5
6 name = "${local.name}-vpc"
7 cidr = local.vpc.cidr
8
9 azs = local.vpc.azs
10 public_subnets = [for k, v in local.vpc.azs : cidrsubnet(local.vpc.cidr, 3, k)]
11 private_subnets = [for k, v in local.vpc.azs : cidrsubnet(local.vpc.cidr, 3, k + 3)]
12
13 ...
14
15 private_subnet_tags = {
16 "Tier" = "Private"
17 }
18
19 tags = local.tags
20}
21
22# glue-schema-registry/app/variables.tf
23data "aws_caller_identity" "current" {}
24
25data "aws_region" "current" {}
26
27data "aws_vpc" "selected" {
28 filter {
29 name = "tag:Name"
30 values = ["${local.infra_prefix}"]
31 }
32}
33
34data "aws_subnets" "private" {
35 filter {
36 name = "vpc-id"
37 values = [data.aws_vpc.selected.id]
38 }
39
40 tags = {
41 Tier = "Private"
42 }
43}
44
45data "aws_msk_cluster" "msk_data_cluster" {
46 cluster_name = "${local.infra_prefix}-msk-cluster"
47}
48
49data "aws_security_group" "kafka_producer_lambda" {
50 name = "${local.infra_prefix}-lambda-msk-access"
51}
52
53
54locals {
55 ...
56 infra_prefix = "glue-schema-registry"
57 ...
58}
The AWS Lambda Terraform module is used to create the producer Lambda function. Note that, in order to develop a Lambda function using AWS SAM, we need to create SAM metadata resource, which provides the AWS SAM CLI with the information it needs to locate Lambda functions and layers, along with their source code, build dependencies, and build logic from within your Terraform project. It is created by default by the Terraform module, which is convenient. Also, we need to give permission to the EventBridge rule to invoke the Lambda function, and it is given by the aws_lambda_permission resource.
1# glue-schema-registry/app/variables.tf
2locals {
3 name = local.infra_prefix
4 region = data.aws_region.current.name
5 environment = "dev"
6
7 infra_prefix = "glue-schema-registry"
8
9 producer = {
10 src_path = "producer"
11 function_name = "kafka_producer"
12 handler = "lambda_handler.lambda_function"
13 concurrency = 5
14 timeout = 90
15 memory_size = 128
16 runtime = "python3.8"
17 schedule_rate = "rate(1 minute)"
18 to_enable_trigger = true
19 environment = {
20 topic_name = "orders"
21 registry_name = "customer"
22 max_run_sec = 60
23 }
24 }
25
26 ...
27}
28
29# glue-schema-registry/app/main.tf
30module "kafka_producer_lambda" {
31 source = "terraform-aws-modules/lambda/aws"
32
33 function_name = local.producer.function_name
34 handler = local.producer.handler
35 runtime = local.producer.runtime
36 timeout = local.producer.timeout
37 memory_size = local.producer.memory_size
38 source_path = local.producer.src_path
39 vpc_subnet_ids = data.aws_subnets.private.ids
40 vpc_security_group_ids = [data.aws_security_group.kafka_app_lambda.id]
41 attach_network_policy = true
42 attach_policies = true
43 policies = [aws_iam_policy.msk_lambda_producer_permission.arn]
44 number_of_policies = 1
45 environment_variables = {
46 BOOTSTRAP_SERVERS = data.aws_msk_cluster.msk_data_cluster.bootstrap_brokers_sasl_iam
47 TOPIC_NAME = local.producer.environment.topic_name
48 REGISTRY_NAME = local.producer.environment.registry_name
49 MAX_RUN_SEC = local.producer.environment.max_run_sec
50 }
51
52 tags = local.tags
53}
54
55resource "aws_lambda_function_event_invoke_config" "kafka_producer_lambda" {
56 function_name = module.kafka_producer_lambda.lambda_function_name
57 maximum_retry_attempts = 0
58}
59
60resource "aws_lambda_permission" "allow_eventbridge" {
61 count = local.producer.to_enable_trigger ? 1 : 0
62 statement_id = "InvokeLambdaFunction"
63 action = "lambda:InvokeFunction"
64 function_name = local.producer.function_name
65 principal = "events.amazonaws.com"
66 source_arn = module.eventbridge.eventbridge_rule_arns["crons"]
67
68 depends_on = [
69 module.eventbridge
70 ]
71}
IAM Permission
The producer Lambda function needs permission to send messages to the orders topic of the MSK cluster. Also, it needs permission on the Glue schema registry and schema. The following IAM policy is added to the Lambda function.
1# glue-schema-registry/app/main.tf
2resource "aws_iam_policy" "msk_lambda_producer_permission" {
3 name = "${local.producer.function_name}-msk-lambda-producer-permission"
4
5 policy = jsonencode({
6 Version = "2012-10-17"
7 Statement = [
8 {
9 Sid = "PermissionOnCluster"
10 Action = [
11 "kafka-cluster:Connect",
12 "kafka-cluster:AlterCluster",
13 "kafka-cluster:DescribeCluster"
14 ]
15 Effect = "Allow"
16 Resource = "arn:aws:kafka:${local.region}:${data.aws_caller_identity.current.account_id}:cluster/${local.infra_prefix}-msk-cluster/*"
17 },
18 {
19 Sid = "PermissionOnTopics"
20 Action = [
21 "kafka-cluster:*Topic*",
22 "kafka-cluster:WriteData",
23 "kafka-cluster:ReadData"
24 ]
25 Effect = "Allow"
26 Resource = "arn:aws:kafka:${local.region}:${data.aws_caller_identity.current.account_id}:topic/${local.infra_prefix}-msk-cluster/*"
27 },
28 {
29 Sid = "PermissionOnGroups"
30 Action = [
31 "kafka-cluster:AlterGroup",
32 "kafka-cluster:DescribeGroup"
33 ]
34 Effect = "Allow"
35 Resource = "arn:aws:kafka:${local.region}:${data.aws_caller_identity.current.account_id}:group/${local.infra_prefix}-msk-cluster/*"
36 },
37 {
38 Sid = "PermissionOnGlueSchema"
39 Action = [
40 "glue:*Schema*",
41 "glue:GetRegistry",
42 "glue:CreateRegistry",
43 "glue:ListRegistries",
44 ]
45 Effect = "Allow"
46 Resource = "*"
47 }
48 ]
49 })
50}
EventBridge Rule
The AWS EventBridge Terraform module is used to create the EventBridge schedule rule and targets. Note that 5 targets that point to the Kafka producer Lambda function are created so that it is invoked concurrently every minute.
1module "eventbridge" {
2 source = "terraform-aws-modules/eventbridge/aws"
3
4 create_bus = false
5
6 rules = {
7 crons = {
8 description = "Kafka producer lambda schedule"
9 schedule_expression = local.producer.schedule_rate
10 }
11 }
12
13 targets = {
14 crons = [for i in range(local.producer.concurrency) : {
15 name = "lambda-target-${i}"
16 arn = module.kafka_producer_lambda.lambda_function_arn
17 }]
18 }
19
20 depends_on = [
21 module.kafka_producer_lambda
22 ]
23
24 tags = local.tags
25}
Consumer App
Lambda Handler
The Lambda event includes records, which is a dictionary where the key is a topic partition (topic_name-partiton_number) and the value is a list of consumer records. The consumer records include both the message metadata (topic, partition, offset, timestamp…), key and value. An example payload is shown below.
1{
2 "eventSource": "aws:kafka",
3 "eventSourceArn": "<msk-cluster-arn>",
4 "bootstrapServers": "<bootstrap-server-addresses>",
5 "records": {
6 "orders-2": [
7 {
8 "topic": "orders",
9 "partition": 2,
10 "offset": 10293,
11 "timestamp": 1680631941838,
12 "timestampType": "CREATE_TIME",
13 "key": "eyJvcmRlcl9pZCI6ICJkNmQ4ZDJjNi1hODYwLTQyNTYtYWY1Yi04ZjU3NDkxZmM4YWYifQ==",
14 "value": "AwDeD/rgjCxCeawN/ZaIO6VuSGQ2ZDhkMmM2LWE4NjAtNDI1Ni1hZjViLThmNTc0OTFmYzhhZu6pwtfpYQppYWJ4YQa8UBSEHgbkVAYA",
15 "headers": [],
16 }
17 ]
18 }
19}
The ConsumerRecord class parses/formats a consumer record. As the key and value are returned as base64 encoded string, it is decoded into bytes, followed by decoding or deserializing appropriately. The LambdaDeserializer class is created to deserialize the value. Also, the message timestamp is converted into the datetime object. The parse_record() method returns the consumer record with parsed/formatted values.
1# glue-schema-registry/app/consumer/lambda_handler.py
2import os
3import json
4import base64
5import datetime
6
7import boto3
8from aws_schema_registry import SchemaRegistryClient
9from aws_schema_registry.adapter.kafka import Deserializer, KafkaDeserializer
10
11
12class LambdaDeserializer(Deserializer):
13 def __init__(self, registry: str):
14 self.registry = registry
15
16 @property
17 def deserializer(self):
18 glue_client = boto3.client(
19 "glue", region_name=os.getenv("AWS_DEFAULT_REGION", "ap-southeast-2")
20 )
21 client = SchemaRegistryClient(glue_client, registry_name=self.registry)
22 return KafkaDeserializer(client)
23
24 def deserialize(self, topic: str, bytes_: bytes):
25 return self.deserializer.deserialize(topic, bytes_)
26
27
28class ConsumerRecord:
29 def __init__(self, record: dict):
30 self.topic = record["topic"]
31 self.partition = record["partition"]
32 self.offset = record["offset"]
33 self.timestamp = record["timestamp"]
34 self.timestamp_type = record["timestampType"]
35 self.key = record["key"]
36 self.value = record["value"]
37 self.headers = record["headers"]
38
39 def parse_key(self):
40 return base64.b64decode(self.key).decode()
41
42 def parse_value(self, deserializer: LambdaDeserializer):
43 parsed = deserializer.deserialize(self.topic, base64.b64decode(self.value))
44 return parsed.data
45
46 def format_timestamp(self, to_str: bool = True):
47 ts = datetime.datetime.fromtimestamp(self.timestamp / 1000)
48 if to_str:
49 return ts.isoformat()
50 return ts
51
52 def parse_record(
53 self, deserializer: LambdaDeserializer, to_str: bool = True, to_json: bool = True
54 ):
55 rec = {
56 **self.__dict__,
57 **{
58 "key": self.parse_key(),
59 "value": self.parse_value(deserializer),
60 "timestamp": self.format_timestamp(to_str),
61 },
62 }
63 if to_json:
64 return json.dumps(rec, default=self.serialize)
65 return rec
66
67 def serialize(self, obj):
68 if isinstance(obj, datetime.datetime):
69 return obj.isoformat()
70 if isinstance(obj, datetime.date):
71 return str(obj)
72 return obj
73
74
75def lambda_function(event, context):
76 deserializer = LambdaDeserializer(os.getenv("REGISTRY_NAME", "customer"))
77 for _, records in event["records"].items():
78 for record in records:
79 cr = ConsumerRecord(record)
80 print(cr.parse_record(deserializer))
Lambda Resource
The AWS Lambda Terraform module is used to create the consumer Lambda function as well. Lambda event source mapping is created so that it polls messages from the orders topic and invoke the consumer function. Also, we need to give permission to the MSK cluster to invoke the Lambda function, and it is given by the aws_lambda_permission resource.
1# glue-schema-registry/app/variables.tf
2locals {
3 name = local.infra_prefix
4 region = data.aws_region.current.name
5 environment = "dev"
6
7 infra_prefix = "glue-schema-registry"
8
9 ...
10
11 consumer = {
12 src_path = "consumer"
13 function_name = "kafka_consumer"
14 handler = "lambda_handler.lambda_function"
15 timeout = 90
16 memory_size = 128
17 runtime = "python3.8"
18 topic_name = "orders"
19 starting_position = "TRIM_HORIZON"
20 environment = {
21 registry_name = "customer"
22 }
23 }
24}
25
26# glue-schema-registry/app/main.tf
27module "kafka_consumer_lambda" {
28 source = "terraform-aws-modules/lambda/aws"
29
30 function_name = local.consumer.function_name
31 handler = local.consumer.handler
32 runtime = local.consumer.runtime
33 timeout = local.consumer.timeout
34 memory_size = local.consumer.memory_size
35 source_path = local.consumer.src_path
36 vpc_subnet_ids = data.aws_subnets.private.ids
37 vpc_security_group_ids = [data.aws_security_group.kafka_app_lambda.id]
38 attach_network_policy = true
39 attach_policies = true
40 policies = [aws_iam_policy.msk_lambda_consumer_permission.arn]
41 number_of_policies = 1
42 environment_variables = {
43 REGISTRY_NAME = local.producer.environment.registry_name
44 }
45
46 tags = local.tags
47}
48
49resource "aws_lambda_event_source_mapping" "kafka_consumer_lambda" {
50 event_source_arn = data.aws_msk_cluster.msk_data_cluster.arn
51 function_name = module.kafka_consumer_lambda.lambda_function_name
52 topics = [local.consumer.topic_name]
53 starting_position = local.consumer.starting_position
54 amazon_managed_kafka_event_source_config {
55 consumer_group_id = "${local.consumer.topic_name}-group-01"
56 }
57}
58
59resource "aws_lambda_permission" "allow_msk" {
60 statement_id = "InvokeLambdaFunction"
61 action = "lambda:InvokeFunction"
62 function_name = local.consumer.function_name
63 principal = "kafka.amazonaws.com"
64 source_arn = data.aws_msk_cluster.msk_data_cluster.arn
65}
IAM Permission
As the Lambda event source mapping uses the permission of the Lambda function, we need to add permission related to Kafka cluster, Kafka and networking - see the AWS documentation for details. Finally, permission on the Glue schema registry and schema is added as the consumer should be able to request relevant schemas.
1# glue-schema-registry/app/main.tf
2resource "aws_iam_policy" "msk_lambda_consumer_permission" {
3 name = "${local.consumer.function_name}-msk-lambda-consumer-permission"
4
5 policy = jsonencode({
6 Version = "2012-10-17"
7 Statement = [
8 {
9 Sid = "PermissionOnKafkaCluster"
10 Action = [
11 "kafka-cluster:Connect",
12 "kafka-cluster:DescribeGroup",
13 "kafka-cluster:AlterGroup",
14 "kafka-cluster:DescribeTopic",
15 "kafka-cluster:ReadData",
16 "kafka-cluster:DescribeClusterDynamicConfiguration"
17 ]
18 Effect = "Allow"
19 Resource = [
20 "arn:aws:kafka:${local.region}:${data.aws_caller_identity.current.account_id}:cluster/${local.infra_prefix}-msk-cluster/*",
21 "arn:aws:kafka:${local.region}:${data.aws_caller_identity.current.account_id}:topic/${local.infra_prefix}-msk-cluster/*",
22 "arn:aws:kafka:${local.region}:${data.aws_caller_identity.current.account_id}:group/${local.infra_prefix}-msk-cluster/*"
23 ]
24 },
25 {
26 Sid = "PermissionOnKafka"
27 Action = [
28 "kafka:DescribeCluster",
29 "kafka:GetBootstrapBrokers"
30 ]
31 Effect = "Allow"
32 Resource = "*"
33 },
34 {
35 Sid = "PermissionOnNetwork"
36 Action = [
37 # The first three actions also exist in netwrok policy attachment in lambda module
38 # "ec2:CreateNetworkInterface",
39 # "ec2:DescribeNetworkInterfaces",
40 # "ec2:DeleteNetworkInterface",
41 "ec2:DescribeVpcs",
42 "ec2:DescribeSubnets",
43 "ec2:DescribeSecurityGroups"
44 ]
45 Effect = "Allow"
46 Resource = "*"
47 },
48 {
49 Sid = "PermissionOnGlueSchema"
50 Action = [
51 "glue:*Schema*",
52 "glue:ListRegistries"
53 ]
54 Effect = "Allow"
55 Resource = "*"
56 }
57 ]
58 })
59}
Schema Evolution Demo
Before testing the Kafka applications, I’ll quickly demonstrate how the schema registry can be used for managing and validating schemas for topic message data. Each schema can have a compatibility mode (or disabled) and the scope of changes is restricted by it. For example, the default BACKWARD mode only allows to delete fields or add optional fields. (See the Confluent document for a quick summary.) Therefore, if we add a mandatory field to an existing schema, it will be not validated, and it fails to send a message to the topic. In order to illustrate it, I created a single node Kafka cluster using docker-compose as shown below.
1# glue-schema-registry/compose-demo.yml
2version: "3.5"
3
4services:
5 zookeeper:
6 image: docker.io/bitnami/zookeeper:3.8
7 container_name: zookeeper
8 ports:
9 - "2181"
10 networks:
11 - kafkanet
12 environment:
13 - ALLOW_ANONYMOUS_LOGIN=yes
14 volumes:
15 - zookeeper_data:/bitnami/zookeeper
16 kafka-0:
17 image: docker.io/bitnami/kafka:3.3
18 container_name: kafka-0
19 expose:
20 - 9092
21 ports:
22 - "9093:9093"
23 networks:
24 - kafkanet
25 environment:
26 - ALLOW_PLAINTEXT_LISTENER=yes
27 - KAFKA_CFG_ZOOKEEPER_CONNECT=zookeeper:2181
28 - KAFKA_CFG_BROKER_ID=0
29 - KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CLIENT:PLAINTEXT,EXTERNAL:PLAINTEXT
30 - KAFKA_CFG_LISTENERS=CLIENT://:9092,EXTERNAL://:9093
31 - KAFKA_CFG_ADVERTISED_LISTENERS=CLIENT://kafka-0:9092,EXTERNAL://localhost:9093
32 - KAFKA_CFG_INTER_BROKER_LISTENER_NAME=CLIENT
33 volumes:
34 - kafka_0_data:/bitnami/kafka
35 depends_on:
36 - zookeeper
37
38networks:
39 kafkanet:
40 name: kafka-network
41
42volumes:
43 zookeeper_data:
44 driver: local
45 kafka_0_data:
46 driver: local
Recall that the producer lambda handler has a conditional block, and it is executed when it is called as a script. If we don’t specify the environment variable of USE_MORE, it sends a messages based on the Order class. Otherwise, a message is created from the OrderMore class, which has an additional boolean attribute called is_prime. As the compatibility mode is set to be BACKWARD, we can expect the second round of execution will not be successful. As shown below, I executed the lambda handler twice and the second round failed with the following error, which indicates schema validation failure.
aws_schema_registry.exception.SchemaRegistryException: Schema Found but status is FAILURE
1export BOOTSTRAP_SERVERS=localhost:9093
2export TOPIC_NAME=demo
3export REGISTRY_NAME=customer
4
5cd glue-schema-registry/app/producer
6
7## Round 1 - send message from the Order class
8python lambda_handler.py
9
10## Round 2 - send message from the OrderMore class
11export USE_MORE=1
12
13python lambda_handler.py
We can see the details from the schema version and the second version is marked as failed.
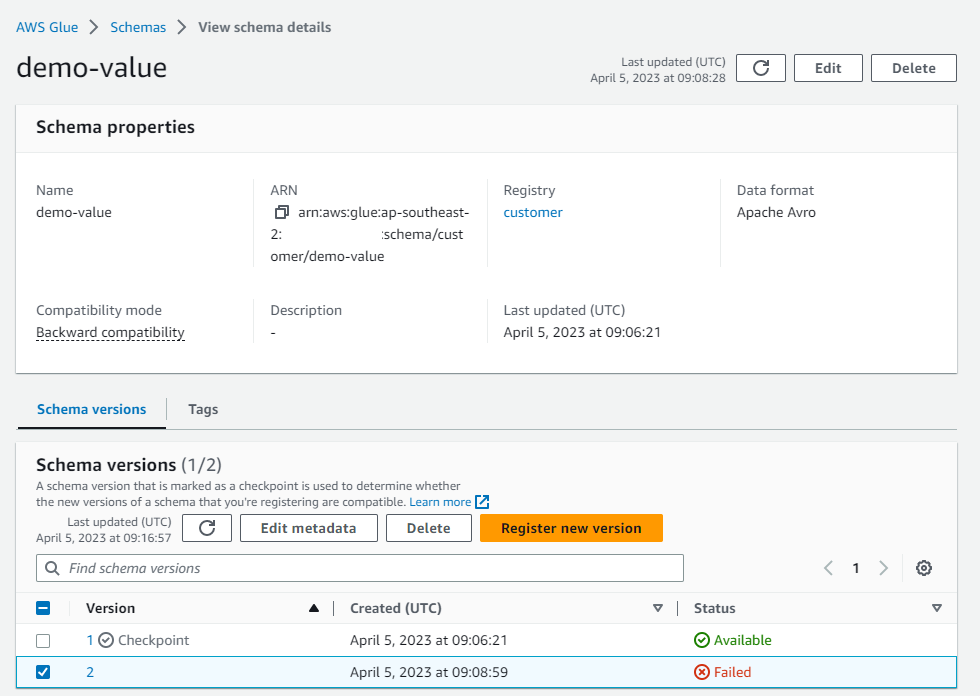
Note that schema versioning and validation would be more relevant to the clients that tightly link the schema and message records. However, it would still be important for a Python client in order to work together with those clients or Kafka connect.
Deployment
Topic Creation
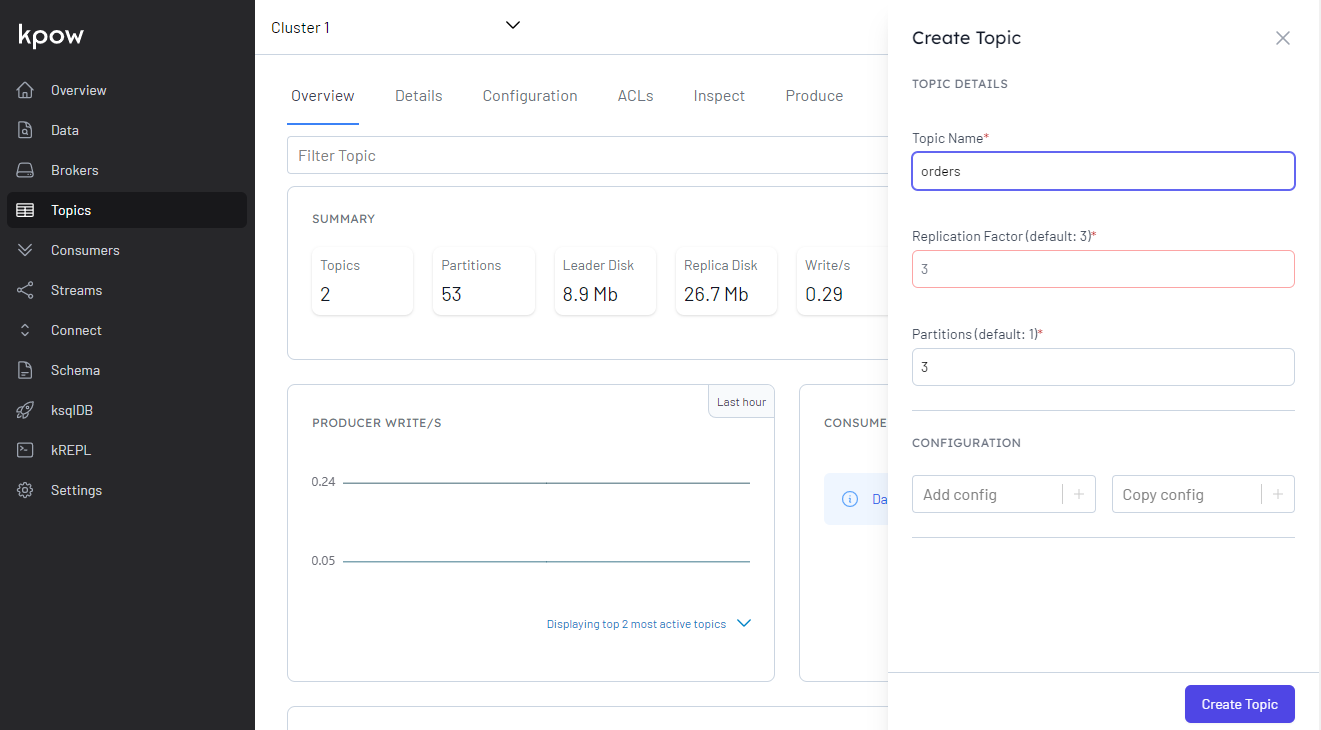
We plan to create the orders topic with multiple partitions. Although we can use the Kafka CLI tool, it can be performed easily using Kpow. It is a Kafka monitoring and management tool, which provides a web UI. Also, it supports the Glue Schema Registry and MSK Connect out-of-box, which is quite convenient. In the docker-compose file, we added environment variables for the MSK cluster, MSK Connect and Glue Schema Registry details. Note it fails to start if the schema registry does not exist. I created the registry while I demonstrated schema evolution, or it can be created simply as shown below.
1$ aws glue create-registry --registry-name customer
1# glue-schema-registry/docker-compose.yml
2version: "3.5"
3
4services:
5 kpow:
6 image: factorhouse/kpow-ce:91.2.1
7 container_name: kpow
8 ports:
9 - "3000:3000"
10 networks:
11 - kafkanet
12 environment:
13 AWS_ACCESS_KEY_ID: $AWS_ACCESS_KEY_ID
14 AWS_SECRET_ACCESS_KEY: $AWS_SECRET_ACCESS_KEY
15 AWS_SESSION_TOKEN: $AWS_SESSION_TOKEN
16 # kafka cluster
17 BOOTSTRAP: $BOOTSTRAP_SERVERS
18 SECURITY_PROTOCOL: SASL_SSL
19 SASL_MECHANISM: AWS_MSK_IAM
20 SASL_CLIENT_CALLBACK_HANDLER_CLASS: software.amazon.msk.auth.iam.IAMClientCallbackHandler
21 SASL_JAAS_CONFIG: software.amazon.msk.auth.iam.IAMLoginModule required;
22 # msk connect
23 CONNECT_AWS_REGION: $AWS_DEFAULT_REGION
24 # glue schema registry
25 SCHEMA_REGISTRY_ARN: $SCHEMA_REGISTRY_ARN
26 SCHEMA_REGISTRY_REGION: $AWS_DEFAULT_REGION
27
28networks:
29 kafkanet:
30 name: kafka-network
Once started, we can visit the UI on port 3000. The topic is created in the Topic menu by specifying the topic name and the number of partitions.
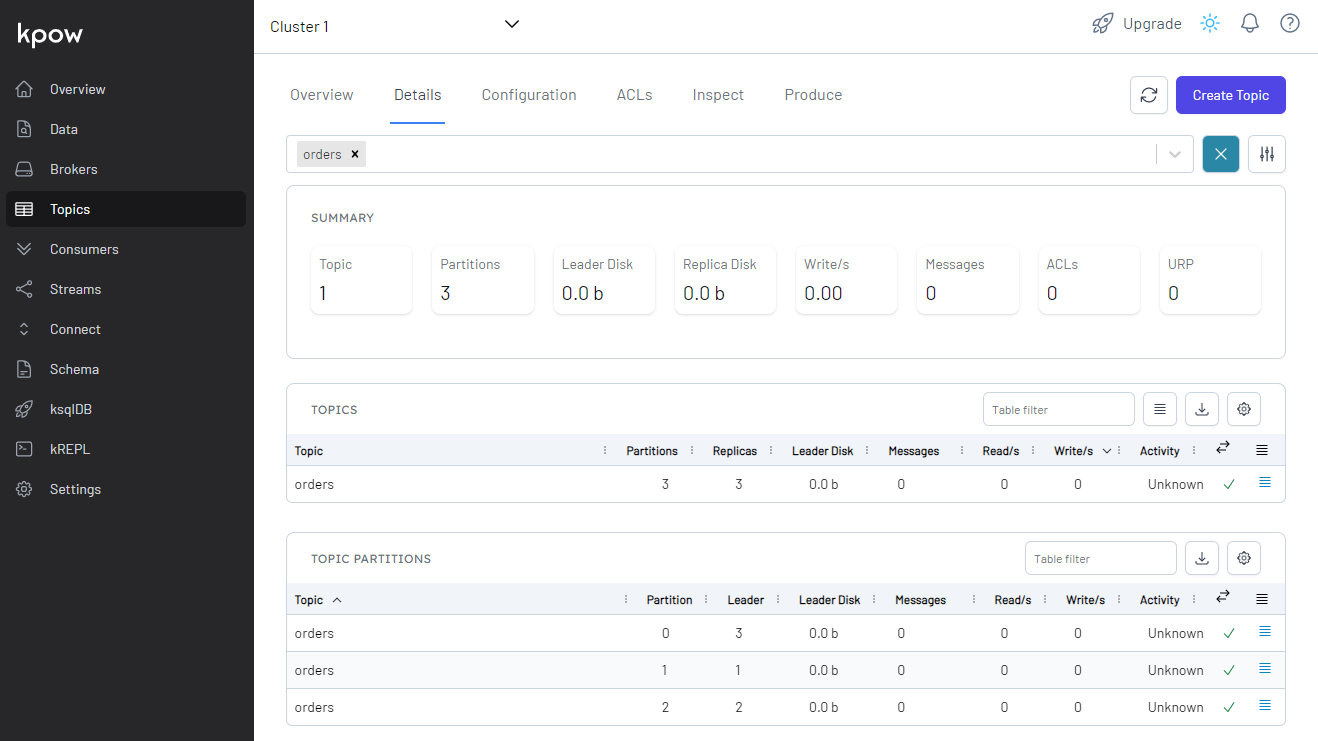
Once created, we can check details of the topic by selecting the topic from the drop-down menu.
Local Testing with SAM
To simplify development, the EventBridge permission is disabled by setting to_enable_trigger to false. Also, it is shortened to loop before it gets stopped by reducing max_run_sec to 10.
1# glue-schema-registry/app/variables.tf
2locals {
3 ...
4
5 producer = {
6 ...
7 to_enable_trigger = false
8 environment = {
9 topic_name = "orders"
10 registry_name = "customer"
11 max_run_sec = 10
12 }
13 }
14 ...
15}
The Lambda function can be built with the SAM build command while specifying the hook name as terraform and enabling beta features. Once completed, it stores the build artifacts and template in the .aws-sam folder.
1$ sam build --hook-name terraform --beta-features
2
3# Apply complete! Resources: 3 added, 0 changed, 0 destroyed.
4
5# Build Succeeded
6
7# Built Artifacts : .aws-sam/build
8# Built Template : .aws-sam/build/template.yaml
9
10# Commands you can use next
11# =========================
12# [*] Invoke Function: sam local invoke --hook-name terraform
13# [*] Emulate local Lambda functions: sam local start-lambda --hook-name terraform
14
15# SAM CLI update available (1.78.0); (1.70.0 installed)
16# To download: https://docs.aws.amazon.com/serverless-application-model/latest/developerguide/serverless-sam-cli-install.html
We can invoke the Lambda function locally using the SAM local invoke command. The Lambda function is invoked in a Docker container and the invocation logs are printed in the terminal as shown below. Note that we should be connected to the VPN server in order to send messages into the MSK cluster, which is deployed in private subnets.
1$ sam local invoke --hook-name terraform module.kafka_producer_lambda.aws_lambda_function.this[0] --beta-features
2
3# Experimental features are enabled for this session.
4# Visit the docs page to learn more about the AWS Beta terms https://aws.amazon.com/service-terms/.
5
6# Skipped prepare hook. Current application is already prepared.
7# Invoking lambda_handler.lambda_function (python3.8)
8# Skip pulling image and use local one: public.ecr.aws/sam/emulation-python3.8:rapid-1.70.0-x86_64.
9
10# Mounting /home/jaehyeon/personal/kafka-pocs/glue-schema-registry/app/.aws-sam/build/ModuleKafkaProducerLambdaAwsLambdaFunctionThis069E06354 as /var/task:ro,delegated inside runtime container
11# START RequestId: fdbba255-e5b0-4e21-90d3-fe0b2ebbf629 Version: $LATEST
12# sent 100 messages
13# sent 100 messages
14# sent 100 messages
15# sent 100 messages
16# sent 100 messages
17# sent 100 messages
18# sent 100 messages
19# sent 100 messages
20# sent 100 messages
21# sent 100 messages
22# 1000 records are sent in 11 seconds ...
23# END RequestId: fdbba255-e5b0-4e21-90d3-fe0b2ebbf629
24# REPORT RequestId: fdbba255-e5b0-4e21-90d3-fe0b2ebbf629 Init Duration: 0.22 ms Duration: 12146.61 ms Billed Duration: 12147 ms Memory Size: 128 MB Max Memory Used: 128 MB
25# null
Once completed, we can check the value schema (orders-value) is created in the Kpow UI as shown below.
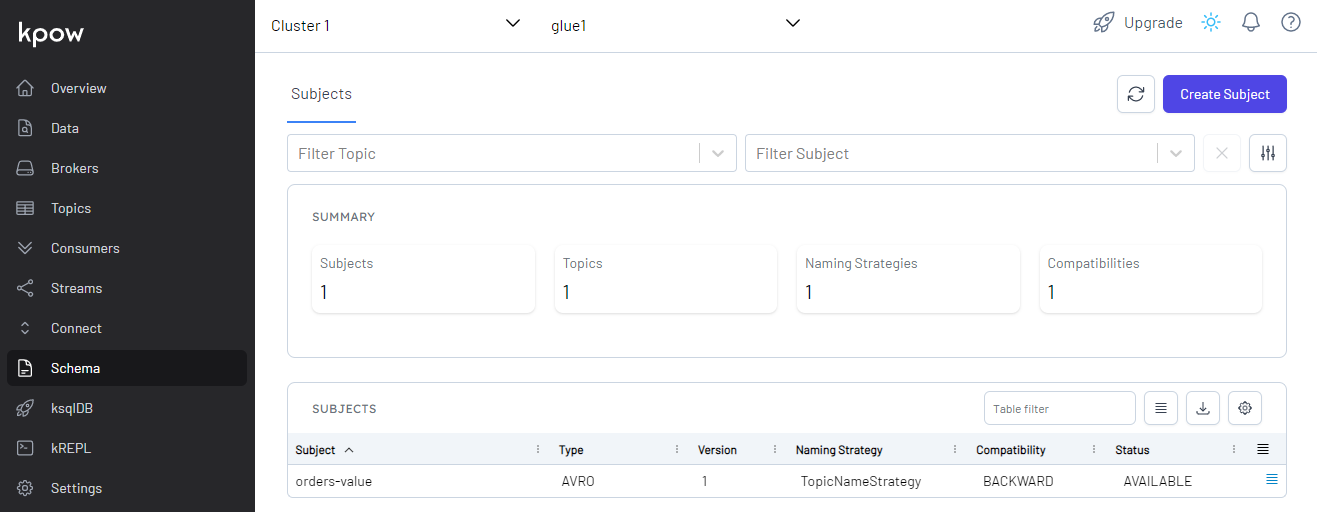
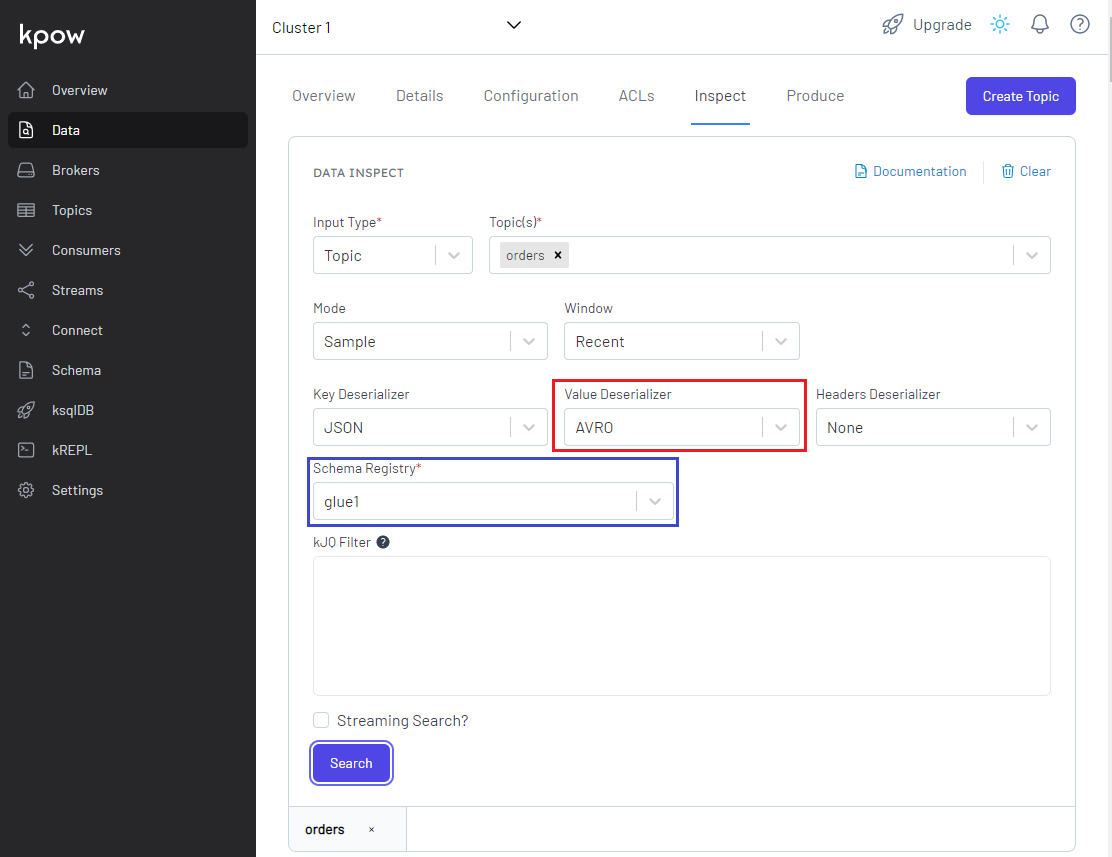
We can check the messages. In order to check them correctly, we need to select AVRO as the value deserializer and glue1 as the schema registry.
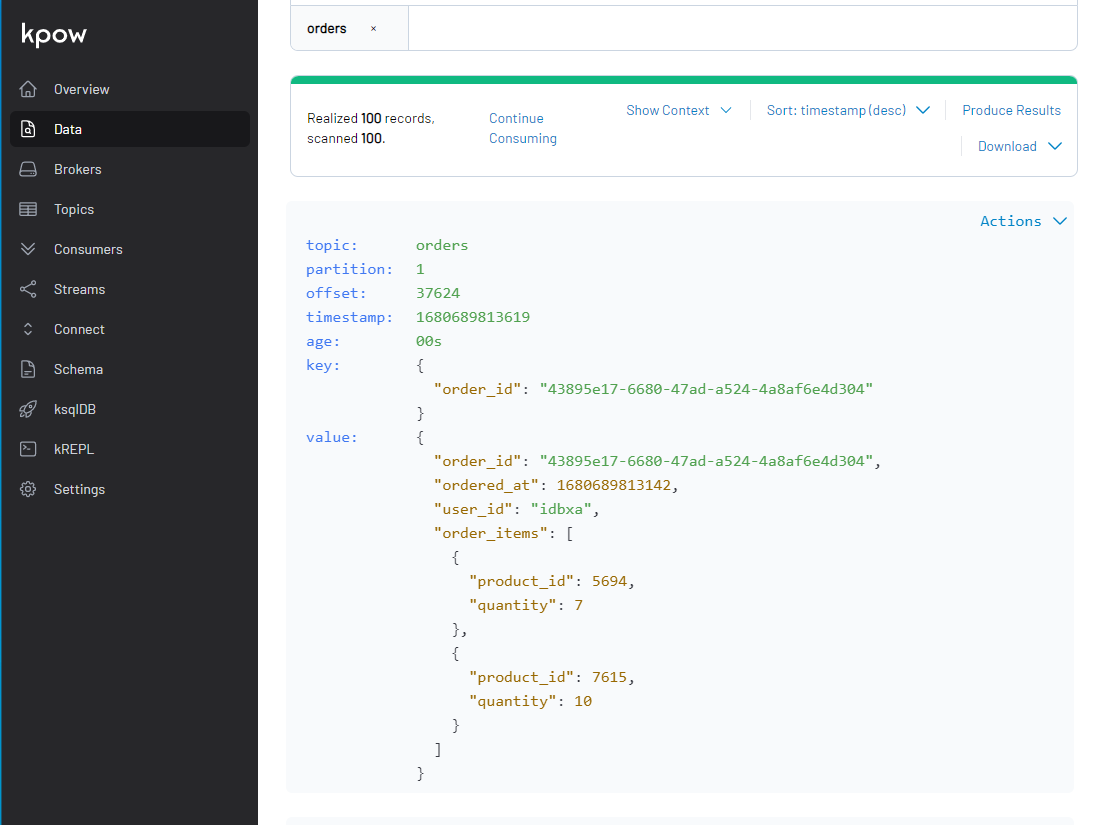
Kafka App Deployment
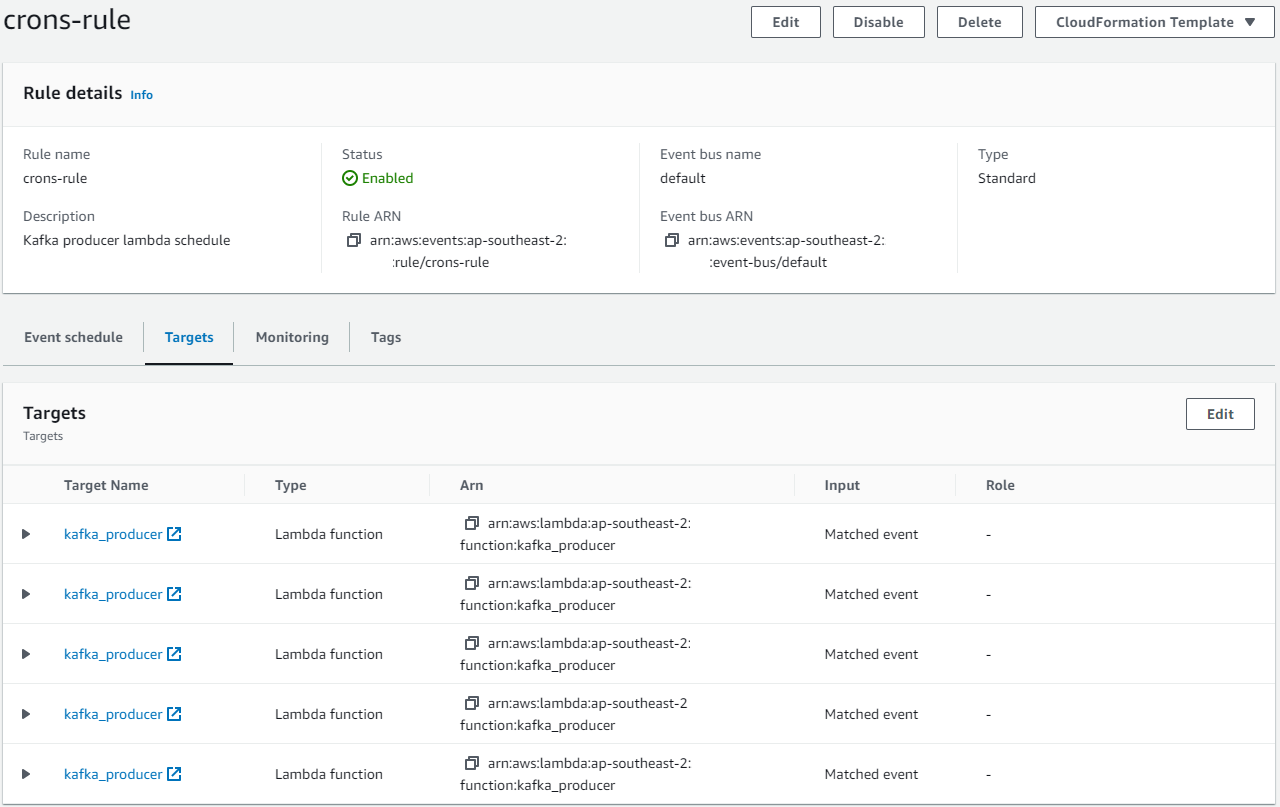
Now we can deploy the Kafka applications using Terraform as usual after resetting the configuration variables. Once deployed, we can see that the scheduler rule has 5 targets of the same Lambda function.
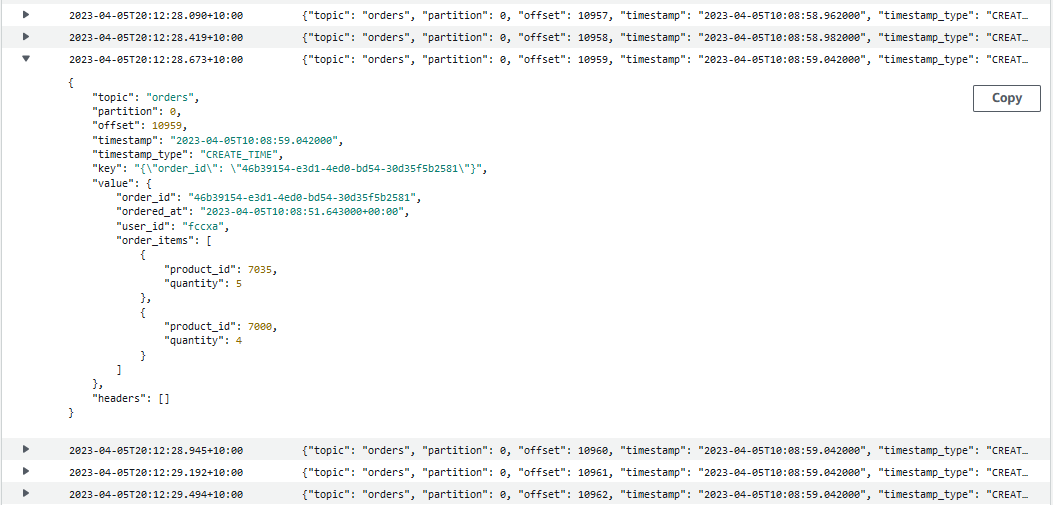
We can see the Lambda consumer parses the consumer records correctly in CloudWatch logs.
Summary
Schema registry provides a centralized repository for managing and validating schemas for topic message data. In AWS, the Glue Schema Registry supports features to manage and enforce schemas on data streaming applications using convenient integrations with a range of AWS services. In this post, we discussed how to integrate Python Kafka producer and consumer apps in AWS Lambda with the Glue Schema Registry.










Comments