
In the previous post, I illustrated how to create a topic and to produce/consume messages using the command utilities provided by Apache Kafka. It is not convenient, however, for example, when you consume serialised messages where their schemas are stored in a schema registry. Also, the utilities don’t support to browse or manage related resources such as connectors and schemas. Therefore, a Kafka management app can be a good companion for development, which helps monitor and manage resources on an easy-to-use user interface. An app can be more useful if it supports features that are desirable for Kafka development on AWS. Those features cover IAM access control of Amazon MSK and integration with Amazon MSK Connect and AWS Glue Schema Registry. In this post, I’ll introduce several management apps that meet those requirements.
- Part 1 Cluster Setup
- Part 2 Management App (this post)
- Part 3 Kafka Connect
- Part 4 Producer and Consumer
- Part 5 Glue Schema Registry
- Part 6 Kafka Connect with Glue Schema Registry
- Part 7 Producer and Consumer with Glue Schema Registry
- Part 8 SSL Encryption
- Part 9 SSL Authentication
- Part 10 SASL Authentication
- Part 11 Kafka Authorization
Overview of Kafka Management App
Generally good Kafka management apps support to monitor and manage one or more Kafka clusters. They also allow you to view and/or manage Kafka-related resources such as brokers, topics, consumer groups, connectors, schemas etc. Furthermore, they help produce, browse, and filter messages with default or custom serialisation/deserialisation methods.
While the majority of Kafka management apps share the features mentioned above, we need additional features for developing Kafka on AWS. They cover IAM access control of Amazon MSK and integration with Amazon MSK Connect and AWS Glue Schema Registry. As far as I’ve searched, there are 3 management apps that support these features.
UI for Apache Kafka (kafka-ui) is free and open-source, and multiple clusters can be registered to it. It supports IAM access control by default and Glue Schema Registry integration is partially implementation, which means it doesn’t seem to allow you to view/manage schemas while message deserialisation is implemented by custom serde registration. Besides, MSK Connect integration is yet to be in their roadmap. I believe these limitations are not critical as we can manage schemas/connectors on the associating AWS Console anyway.
Both Kpow and Conduktor Desktop support all the features out-of-box. However, their free editions are limited to a single cluster. Moreover, the latter has a more strict restriction, which is limited to a cluster having a single broker. Even we are not able to link our local Kafka cluster as it has 3 brokers. However, I find its paid edition is the most intuitive and feature-rich, and it should be taken seriously when deciding an app for your team.
Below shows a comparison of the 3 apps in terms of the features for Kafka development on AWS.
| Application | IAM Access Control | MSK Connect | Glue Schema Registry | Note |
|---|---|---|---|---|
| UI for Apache Kafka (kafka-ui) | ✔ | ❌ | ⚠ | UI for Apache Kafka is a free, open-source web UI to monitor and manage Apache Kafka clusters. It will remain free and open-source, without any paid features or subscription plans to be added in the future. |
| Kpow | ✔ | ✔ | ✔ | Kpow CE allows you to manage one Kafka Cluster, one Schema Registry, and one Connect Cluster, with the UI supporting a single user session at a time. |
| Conduktor Desktop | ✔ | ✔ | ✔ | The Free plan is limited to integrating 1 unsecure cluster (of a single broker) and restricted to browse 10 viewable topics. |
There are other popular Kafka management apps, and they can be useful if your development is not on AWS.
In the subsequent sections, I will introduce UI for Apache Kafka (kafka-ui) and Kpow. The source can be found in the GitHub repository of this post.
Start Management Apps
I assume the local Kafka cluster demonstrated in Part 1 is up and running, which can be run by docker-compose -f compose-kafka.yml up -d. I created a separate compose file for the management apps. The cluster details are configured by environment variables, and only the Kafka cluster details are added in this post - more complete examples will be covered in later posts. As kafka-ui supports multiple clusters, cluster config variables are indexed while only a single cluster config is allowed for Kpow CE. Note that, as the services share the same network to the Kafka cluster, they can use the inter broker listener, which means the bootstrap servers can be indicated as kafka-0:9092,kafka-1:9092,kafka-2:9092. The services can be started by docker-compose -f compose-ui.yml up -d, and kafka-ui and Kpow CE are accessible on port 8080 and 3000 respectively.
1# kafka-dev-with-docker/part-02/kafka-ui.yml
2version: "3.5"
3
4services:
5 kafka-ui:
6 image: provectuslabs/kafka-ui:master
7 container_name: kafka-ui
8 ports:
9 - "8080:8080"
10 networks:
11 - kafkanet
12 environment:
13 KAFKA_CLUSTERS_0_NAME: local
14 KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS: kafka-0:9092,kafka-1:9092,kafka-2:9092
15 KAFKA_CLUSTERS_0_ZOOKEEPER: zookeeper:2181
16 kpow:
17 image: factorhouse/kpow-ce:91.2.1
18 container_name: kpow
19 ports:
20 - "3000:3000"
21 networks:
22 - kafkanet
23 environment:
24 BOOTSTRAP: kafka-0:9092,kafka-1:9092,kafka-2:9092
25
26networks:
27 kafkanet:
28 external: true
29 name: kafka-network
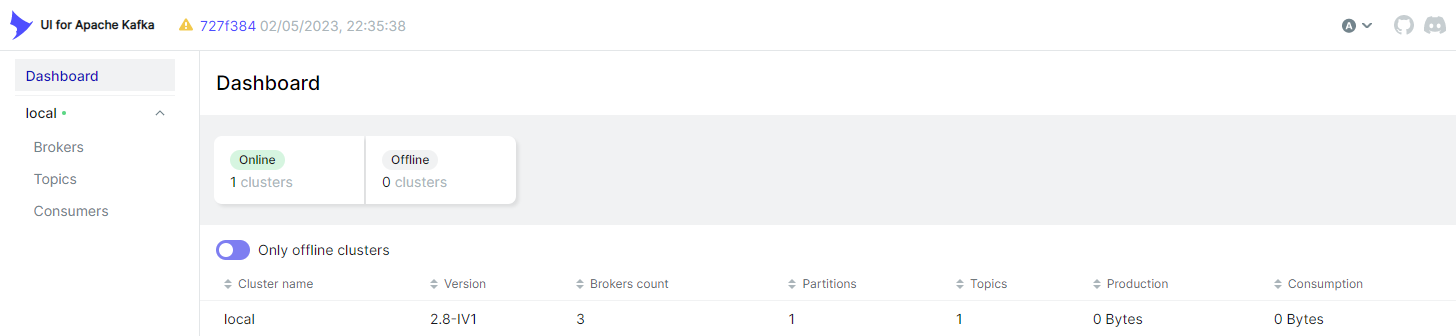
Below shows the landing page of kafka-ui. It shows details of the single cluster (local) and it allows you to check brokers, topics and consumers.
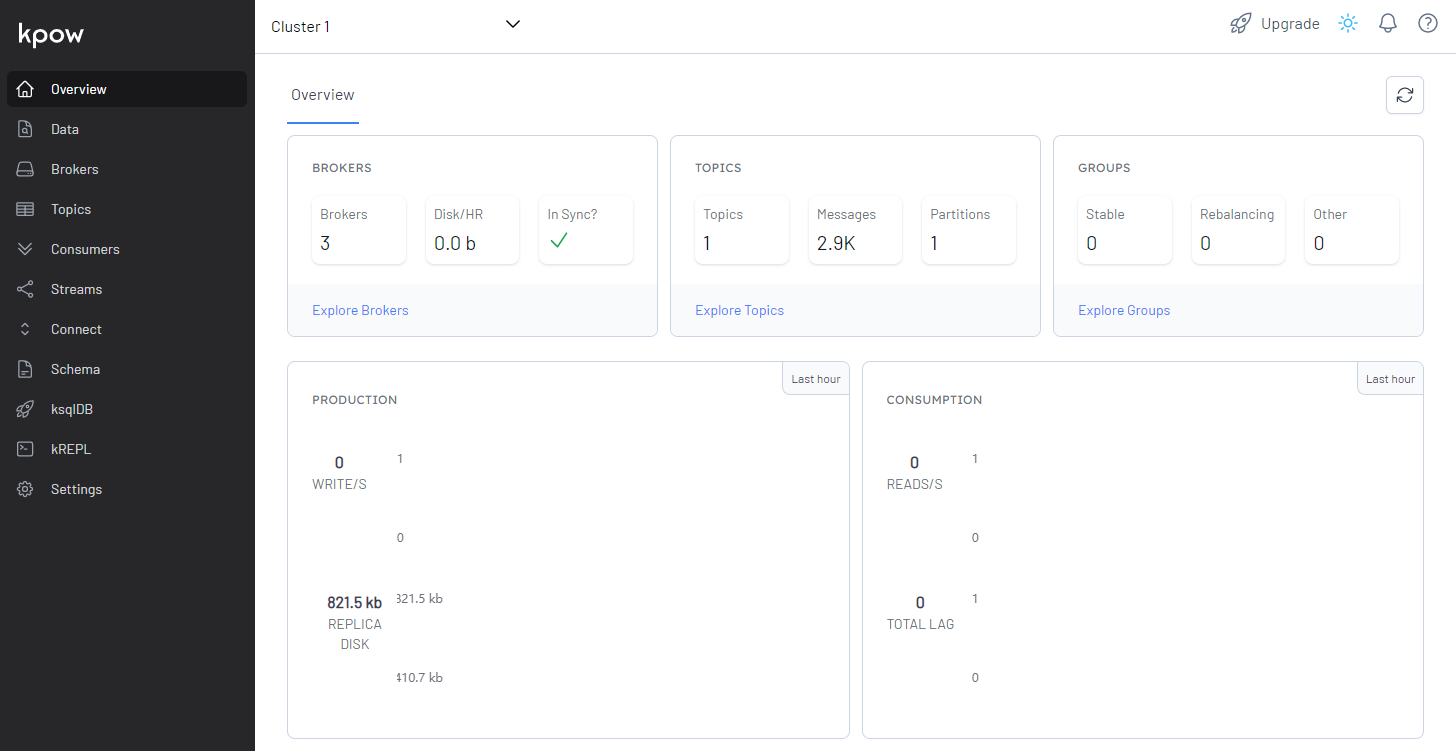
The overview section of Kpow CE shows more details by default, although we haven’t specified many of them (stream/connect cluster, schema registry …).
Create Topic
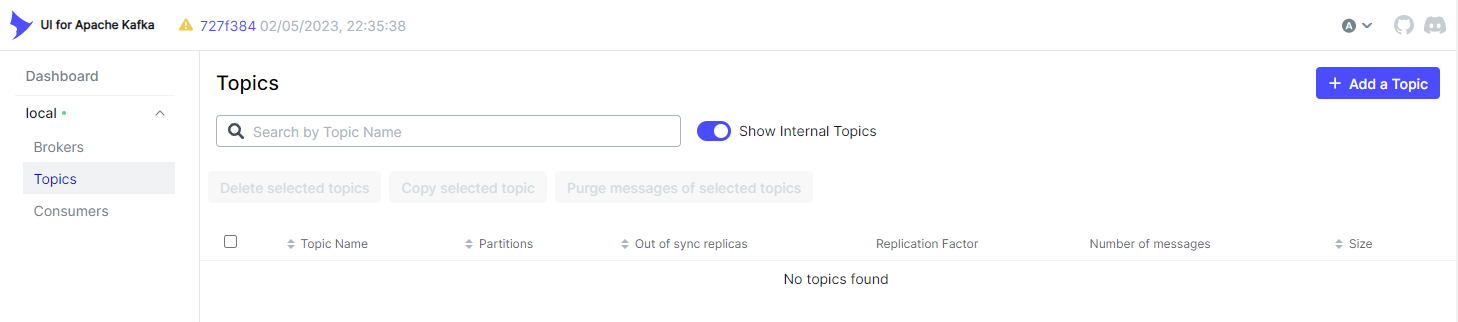
UI for Apache Kafka (kafka-ui)
In the Topics menu, we can click the Add a Topic button to begin creating a topic.
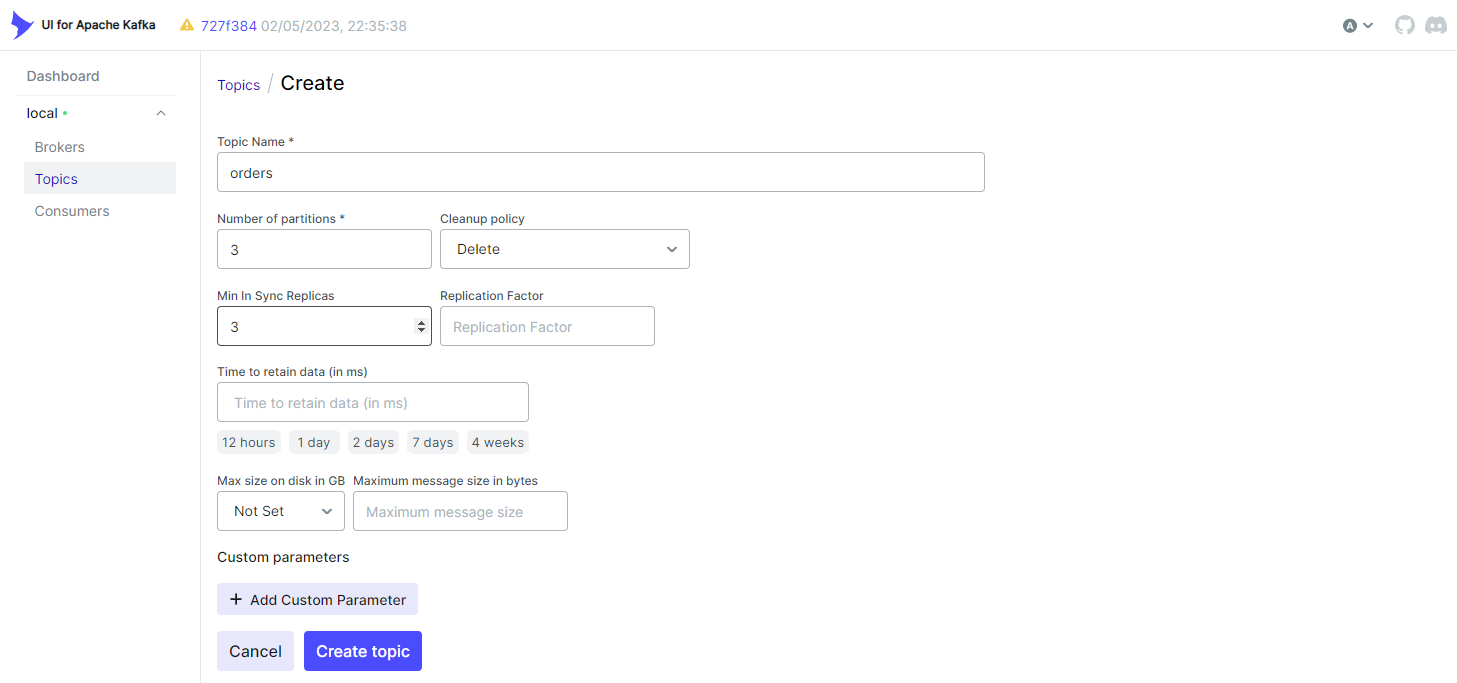
We can create a topic by clicking the Create topic button after entering the topic name, number of partitions, and additional configuration values. I created the topic named orders here, and it’ll be used later.
Kpow
Similarly, we can click the Create Topic button to begin creating a topic in the Topics menu.
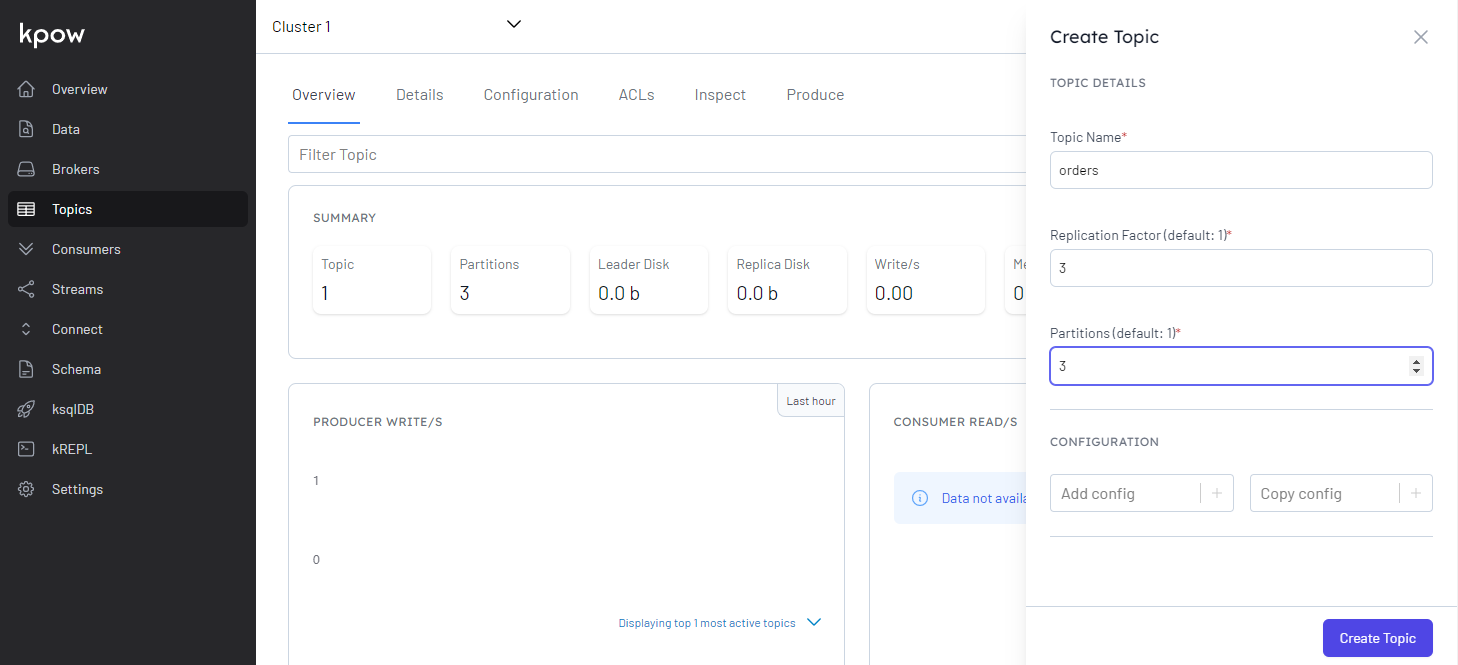
We can create a topic by clicking the Create Topic button after entering the topic name and additional configuration values.
Produce Messages
A Kafka producer is created to demonstrate how to browse and filter topic messages. It sends fake order data that is generated by the Faker package. The Order class generates one or more fake order records by the create method, and a record includes order ID, order timestamp, user ID and order items. Both the key and value are serialised as JSON. Note, as the producer runs outside the Docker network, the host name of the external listener (localhost:29092) is used as the bootstrap server address. It can run simply by python producer.py.
1# kafka-dev-with-docker/part-02/producer.py
2import os
3import datetime
4import time
5import json
6import typing
7import dataclasses
8
9from faker import Faker
10from kafka import KafkaProducer
11
12@dataclasses.dataclass
13class OrderItem:
14 product_id: int
15 quantity: int
16
17@dataclasses.dataclass
18class Order:
19 order_id: str
20 ordered_at: datetime.datetime
21 user_id: str
22 order_items: typing.List[OrderItem]
23
24 def asdict(self):
25 return dataclasses.asdict(self)
26
27 @classmethod
28 def auto(cls, fake: Faker = Faker()):
29 user_id = str(fake.random_int(1, 100)).zfill(3)
30 order_items = [
31 OrderItem(fake.random_int(1, 1000), fake.random_int(1, 10))
32 for _ in range(fake.random_int(1, 4))
33 ]
34 return cls(fake.uuid4(), datetime.datetime.utcnow(), user_id, order_items)
35
36 def create(self, num: int):
37 return [self.auto() for _ in range(num)]
38
39class Producer:
40 def __init__(self, bootstrap_servers: list, topic: str):
41 self.bootstrap_servers = bootstrap_servers
42 self.topic = topic
43 self.producer = self.create()
44
45 def create(self):
46 return KafkaProducer(
47 bootstrap_servers=self.bootstrap_servers,
48 value_serializer=lambda v: json.dumps(v, default=self.serialize).encode("utf-8"),
49 key_serializer=lambda v: json.dumps(v, default=self.serialize).encode("utf-8"),
50 )
51
52 def send(self, orders: typing.List[Order]):
53 for order in orders:
54 try:
55 self.producer.send(
56 self.topic, key={"order_id": order.order_id}, value=order.asdict()
57 )
58 except Exception as e:
59 raise RuntimeError("fails to send a message") from e
60 self.producer.flush()
61
62 def serialize(self, obj):
63 if isinstance(obj, datetime.datetime):
64 return obj.isoformat()
65 if isinstance(obj, datetime.date):
66 return str(obj)
67 return obj
68
69if __name__ == "__main__":
70 producer = Producer(
71 bootstrap_servers=os.getenv("BOOTSTRAP_SERVERS", "localhost:29092").split(","),
72 topic=os.getenv("TOPIC_NAME", "orders"),
73 )
74 max_run = int(os.getenv("MAX_RUN", "20"))
75 print(f"max run - {max_run}")
76 current_run = 0
77 while True:
78 current_run += 1
79 print(f"current run - {current_run}")
80 if current_run > max_run:
81 print(f"exceeds max run, finish")
82 producer.producer.close()
83 break
84 producer.send(Order.auto().create(100))
85 time.sleep(0.5)
Browse Messages
UI for Apache Kafka (kafka-ui)
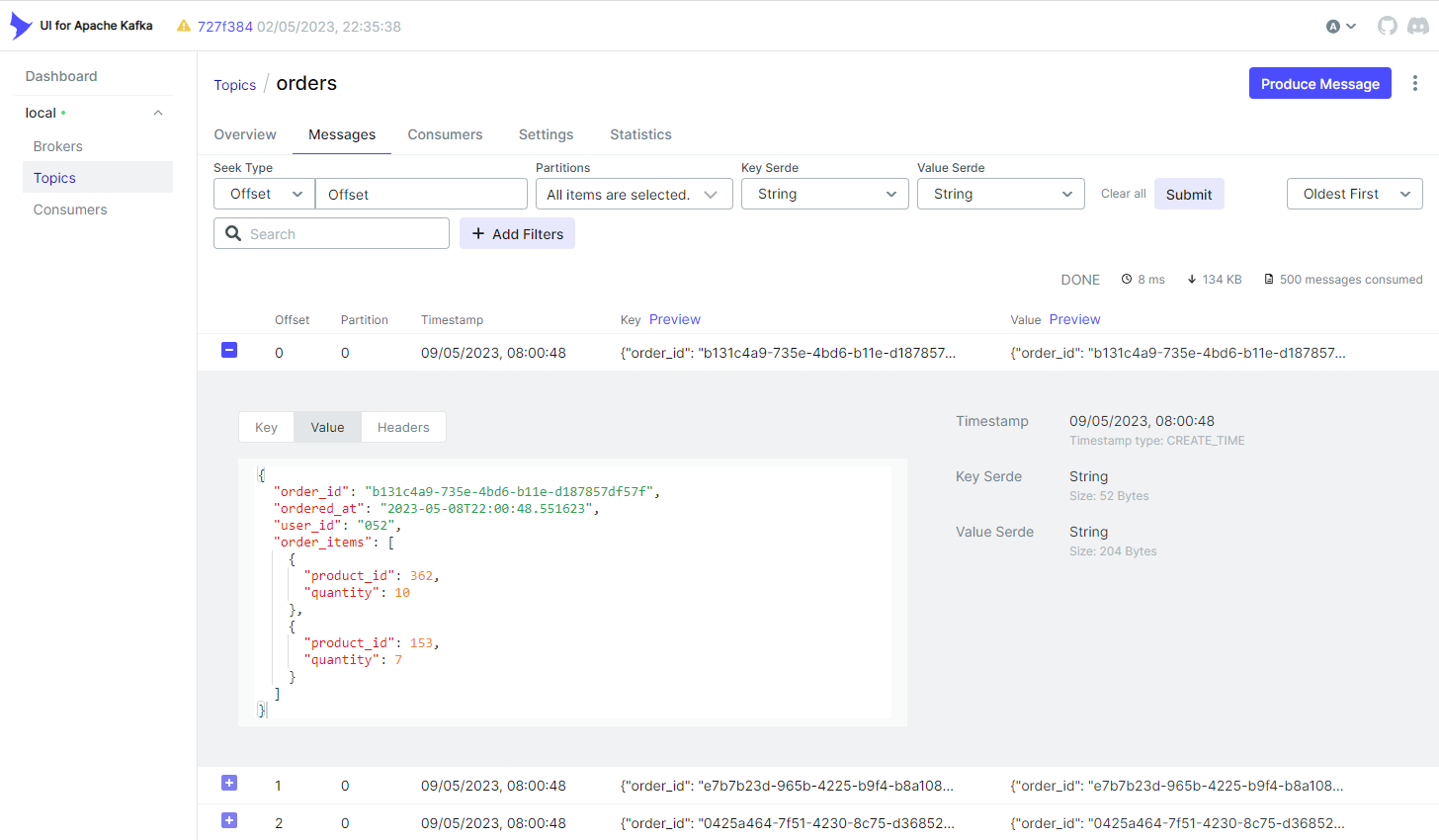
In the Messages tab of the orders topic, we can browse the order messages. Be default, it lists messages from the oldest one. It has options to filter messages by Seek Type (offset or timestamp) and Partitions. Also, it allows you to sort messages by timestamp - Oldest First or Newest First.
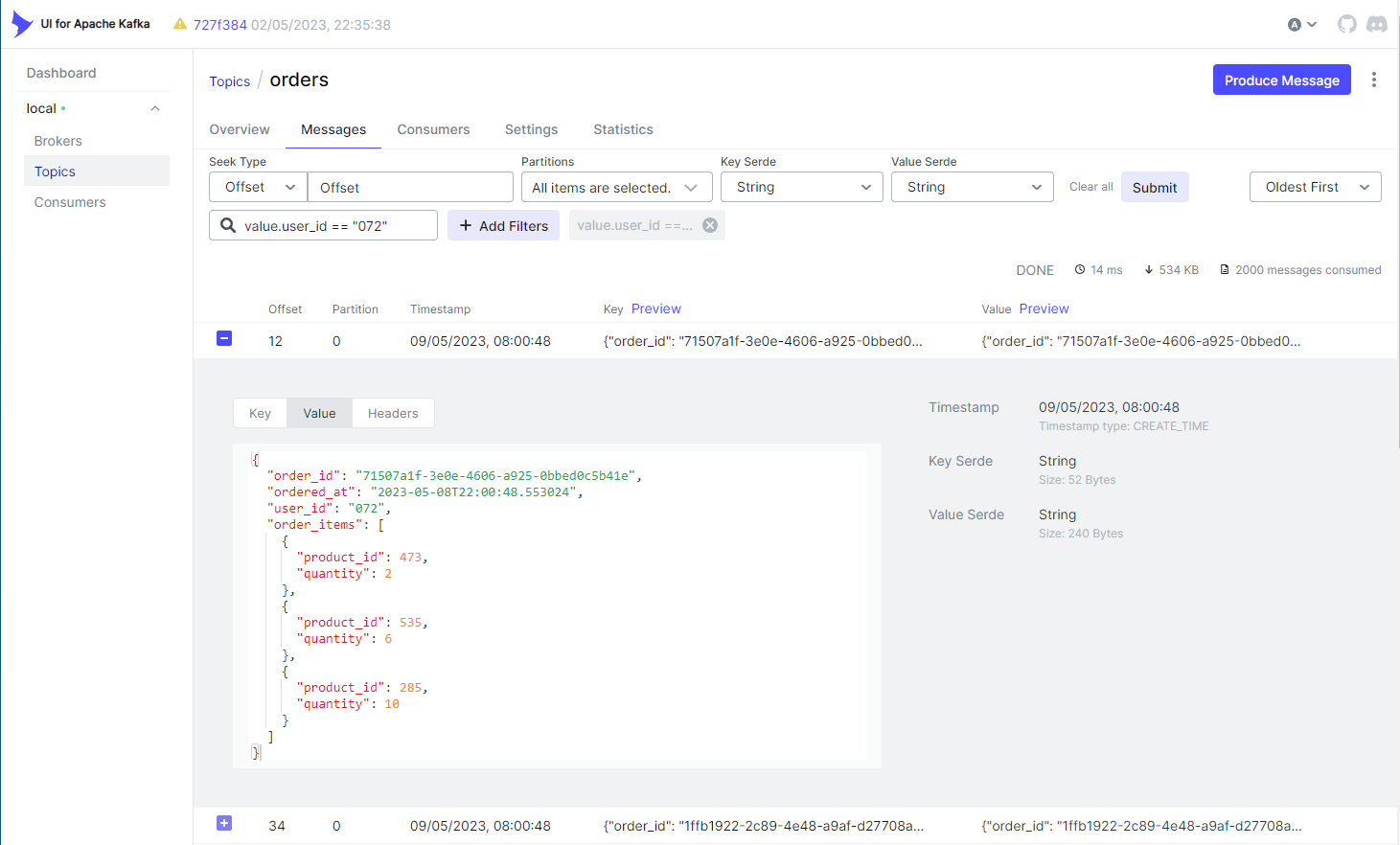
It also supports to filter messages by key or value. Below shows an example where messages are filtered by a specific user ID (072).
Kpow
In the Data menu, we can select one or more topics in order to browse messages. In Mode, we can select one of Sample, Partition and Key options - specific values should be entered if other than Sample is selected. In Window, it allows you to select the following conditions - Recent, Last minute, Last 15 minutes, Last hour, Last 24 hours, Earliest, Custom timestamp, and Custom datetime. Unlike kafka-ui, it requires to select the appropriate key/value serialisers and JSON is selected for both key and value.
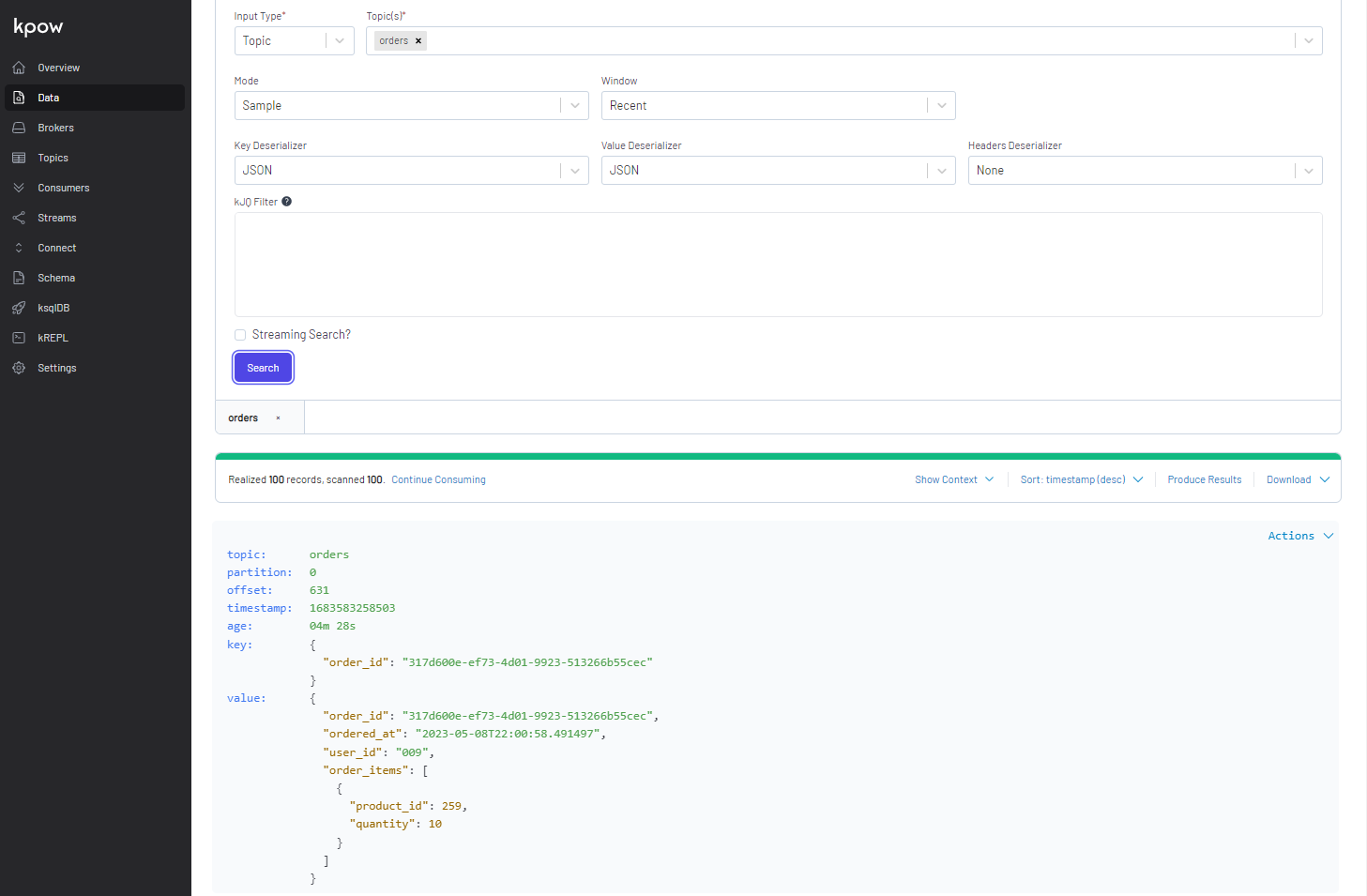
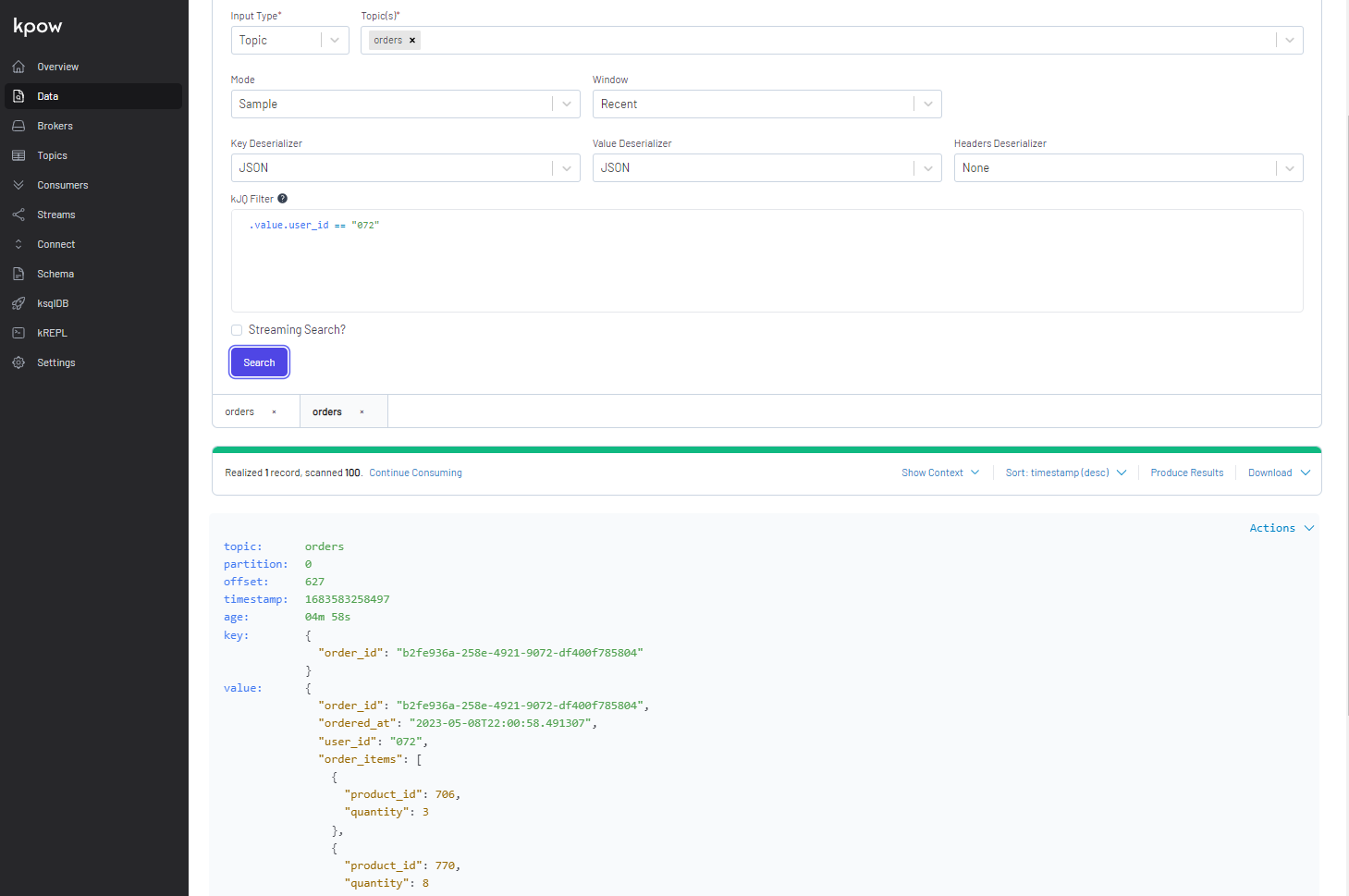
Similar to kafka-ui, it supports to filter messages by key or value. Below shows an example where messages are filtered by a specific user ID (072).
Summary
Several Kafka management apps are introduced in this post. On top of typical features of monitoring and managing Kafka-related resources, they support features that are desirable for Kafka development on AWS - IAM access control and integration with MSK Connect and Glue Schema Registry. More complete examples will be covered in later posts.










Comments