
[UPDATE 2025-10-01]
Bitnami’s public Docker images have been moved to the Bitnami Legacy repository. To ensure continued access and compatibility, please update your Docker image references accordingly.
For example:
bitnami/kafka:2.8.1→bitnamilegacy/kafka:2.8.1bitnami/zookeeper:3.7.0→bitnamilegacy/zookeeper:3.7.0bitnami/python:3.9.0→bitnamilegacy/python:3.9.0
In Part 3, we developed a data ingestion pipeline with fake online order data using Kafka Connect source and sink connectors. Schemas are not enabled on both of them as there was not an integrated schema registry. Later we discussed how producers and consumers to Kafka topics can use schemas to ensure data consistency and compatibility as schemas evolve in Part 5. In this post, I’ll demonstrate how to enhance the existing data ingestion pipeline by integrating AWS Glue Schema Registry.
- Part 1 Cluster Setup
- Part 2 Management App
- Part 3 Kafka Connect
- Part 4 Producer and Consumer
- Part 5 Glue Schema Registry
- Part 6 Kafka Connect with Glue Schema Registry (this post)
- Part 7 Producer and Consumer with Glue Schema Registry
- Part 8 SSL Encryption
- Part 9 SSL Authentication
- Part 10 SASL Authentication
- Part 11 Kafka Authorization
Kafka Connect Setup
We can use the same Docker image because Kafka Connect is included in the Kafka distribution. The Kafka Connect server runs as a separate docker compose service, and its key configurations are listed below.
- We’ll run it as the distributed mode, and it can be started by executing connect-distributed.sh on the Docker command.
- The startup script requires the properties file (connect-distributed.properties). It includes configurations such as Kafka broker server addresses - see below for details.
- The Connect server is accessible on port 8083, and we can manage connectors via a REST API as demonstrated below.
- The properties file, connector sources, and binary of Kafka Connect Avro converter are volume-mapped.
- AWS credentials are added to environment variables as the sink connector requires permission to write data into S3.
The source can be found in the GitHub repository of this post.
1# /kafka-dev-with-docker/part-06/compose-connect.yml
2version: "3.5"
3
4services:
5 kafka-connect:
6 image: bitnami/kafka:2.8.1
7 container_name: connect
8 command: >
9 /opt/bitnami/kafka/bin/connect-distributed.sh
10 /opt/bitnami/kafka/config/connect-distributed.properties
11 ports:
12 - "8083:8083"
13 networks:
14 - kafkanet
15 environment:
16 AWS_ACCESS_KEY_ID: $AWS_ACCESS_KEY_ID
17 AWS_SECRET_ACCESS_KEY: $AWS_SECRET_ACCESS_KEY
18 AWS_SESSION_TOKEN: $AWS_SESSION_TOKEN
19 volumes:
20 - "./configs/connect-distributed.properties:/opt/bitnami/kafka/config/connect-distributed.properties"
21 - "./connectors/confluent-s3/lib:/opt/connectors/confluent-s3"
22 - "./connectors/msk-datagen:/opt/connectors/msk-datagen"
23 - "./plugins/aws-glue-schema-registry-v.1.1.15/avro-kafkaconnect-converter/target:/opt/glue-schema-registry/avro"
24
25networks:
26 kafkanet:
27 external: true
28 name: kafka-network
Connect Properties File
The properties file includes configurations of the Connect server. Below shows key config values.
- Bootstrap Server
- I changed the Kafka bootstrap server addresses. As it shares the same Docker network, we can take the service names (e.g. kafka-0) on port 9092.
- Cluster group id
- In distributed mode, multiple worker processes use the same group.id, and they automatically coordinate to schedule execution of connectors and tasks across all available workers.
- Converter-related properties
- Converters are necessary to have a Kafka Connect deployment support a particular data format when writing to or reading from Kafka.
- By default, org.apache.kafka.connect.json.JsonConverter is set for both the key and value converters and schemas are enabled for both of them.
- As shown later, these properties can be overridden when creating a connector.
- Topics for offsets, configs, status
- Several topics are created to manage connectors by multiple worker processes.
- Plugin path
- Paths that contains plugins (connectors, converters, transformations) can be set to a list of filesystem paths separated by commas (,)
/opt/connectorsis added and connector sources will be volume-mapped to it./opt/glue-schema-registryis for the binary file of Kafka Connect Avro converter.
1# kafka-dev-with-docker/part-06/configs/connect-distributed.properties
2
3# A list of host/port pairs to use for establishing the initial connection to the Kafka cluster.
4bootstrap.servers=kafka-0:9092,kafka-1:9092,kafka-2:9092
5
6# unique name for the cluster, used in forming the Connect cluster group. Note that this must not conflict with consumer group IDs
7group.id=connect-cluster
8
9# The converters specify the format of data in Kafka and how to translate it into Connect data. Every Connect user will
10# need to configure these based on the format they want their data in when loaded from or stored into Kafka
11key.converter=org.apache.kafka.connect.json.JsonConverter
12value.converter=org.apache.kafka.connect.json.JsonConverter
13# Converter-specific settings can be passed in by prefixing the Converter's setting with the converter we want to apply
14# it to
15key.converter.schemas.enable=true
16value.converter.schemas.enable=true
17
18# Topic to use for storing offsets.
19offset.storage.topic=connect-offsets
20offset.storage.replication.factor=1
21#offset.storage.partitions=25
22
23# Topic to use for storing connector and task configurations.
24config.storage.topic=connect-configs
25config.storage.replication.factor=1
26
27# Topic to use for storing statuses.
28status.storage.topic=connect-status
29status.storage.replication.factor=1
30#status.storage.partitions=5
31
32...
33
34# Set to a list of filesystem paths separated by commas (,) to enable class loading isolation for plugins
35# (connectors, converters, transformations).
36plugin.path=/opt/connectors,/opt/glue-schema-registry
Download Connectors
The connector sources need to be downloaded into the respective host paths (./connectors/confluent-s3 and ./connectors/msk-datagen) so that they are volume-mapped to the container’s plugin path (/opt/connectors). The following script downloads them into the host paths. Not that it also downloads the serde binary of kafka-ui, and it’ll be used separately for the kafka-ui service.
1# /kafka-dev-with-docker/part-06/download.sh
2#!/usr/bin/env bash
3SCRIPT_DIR="$(cd $(dirname "$0"); pwd)"
4
5SRC_PATH=${SCRIPT_DIR}/connectors
6rm -rf ${SRC_PATH} && mkdir -p ${SRC_PATH}/msk-datagen
7
8## Confluent S3 Sink Connector
9echo "downloading confluent s3 connector..."
10DOWNLOAD_URL=https://d1i4a15mxbxib1.cloudfront.net/api/plugins/confluentinc/kafka-connect-s3/versions/10.4.3/confluentinc-kafka-connect-s3-10.4.3.zip
11
12curl -o ${SRC_PATH}/confluent.zip ${DOWNLOAD_URL} \
13 && unzip -qq ${SRC_PATH}/confluent.zip -d ${SRC_PATH} \
14 && rm ${SRC_PATH}/confluent.zip \
15 && mv ${SRC_PATH}/$(ls ${SRC_PATH} | grep confluentinc-kafka-connect-s3) ${SRC_PATH}/confluent-s3
16
17## MSK Data Generator Souce Connector
18echo "downloading msk data generator..."
19DOWNLOAD_URL=https://github.com/awslabs/amazon-msk-data-generator/releases/download/v0.4.0/msk-data-generator-0.4-jar-with-dependencies.jar
20
21curl -L -o ${SRC_PATH}/msk-datagen/msk-data-generator.jar ${DOWNLOAD_URL}
22
23## Kafka UI Glue SERDE
24echo "downloading kafka ui glue serde..."
25DOWNLOAD_URL=https://github.com/provectus/kafkaui-glue-sr-serde/releases/download/v1.0.3/kafkaui-glue-serde-v1.0.3-jar-with-dependencies.jar
26
27curl -L -o ${SCRIPT_DIR}/kafkaui-glue-serde-v1.0.3-jar-with-dependencies.jar ${DOWNLOAD_URL}
Below shows the folder structure after the connectors are downloaded successfully.
1$ tree connectors/ -d
2connectors/
3├── confluent-s3
4│ ├── assets
5│ ├── doc
6│ │ ├── licenses
7│ │ └── notices
8│ ├── etc
9│ └── lib
10└── msk-datagen
Build Glue Schema Registry Client
As demonstrated in Part 5, we need to build the Glue Schema Registry Client library as it provides serializers/deserializers and related functionalities. It can be built with the following script - see the previous post for details.
1# /kafka-dev-with-docker/part-06/build.sh
2#!/usr/bin/env bash
3SCRIPT_DIR="$(cd $(dirname "$0"); pwd)"
4
5SRC_PATH=${SCRIPT_DIR}/plugins
6rm -rf ${SRC_PATH} && mkdir ${SRC_PATH}
7
8## Dwonload and build glue schema registry
9echo "downloading glue schema registry..."
10VERSION=v.1.1.15
11DOWNLOAD_URL=https://github.com/awslabs/aws-glue-schema-registry/archive/refs/tags/$VERSION.zip
12SOURCE_NAME=aws-glue-schema-registry-$VERSION
13
14curl -L -o ${SRC_PATH}/$SOURCE_NAME.zip ${DOWNLOAD_URL} \
15 && unzip -qq ${SRC_PATH}/$SOURCE_NAME.zip -d ${SRC_PATH} \
16 && rm ${SRC_PATH}/$SOURCE_NAME.zip
17
18echo "building glue schema registry..."
19cd plugins/$SOURCE_NAME/build-tools \
20 && mvn clean install -DskipTests -Dcheckstyle.skip \
21 && cd .. \
22 && mvn clean install -DskipTests \
23 && mvn dependency:copy-dependencies
Once it is build successfully, we should be able to use the following binary files. We’ll only use the Avro converter in this post.
1## kafka connect
2plugins/aws-glue-schema-registry-v.1.1.15/avro-kafkaconnect-converter/target/
3├...
4├── schema-registry-kafkaconnect-converter-1.1.15.jar
5plugins/aws-glue-schema-registry-v.1.1.15/jsonschema-kafkaconnect-converter/target/
6├...
7├── jsonschema-kafkaconnect-converter-1.1.15.jar
8plugins/aws-glue-schema-registry-v.1.1.15/protobuf-kafkaconnect-converter/target/
9├...
10├── protobuf-kafkaconnect-converter-1.1.15.jar
11...
Kafka Management App
We should configure additional details in environment variables in order to integrate Glue Schema Registry. While both apps provide serializers/deserializers, kpow supports to manage schemas as well.
For kafka-ui, we can add one or more serialization plugins. I added the Glue registry serializer as a plugin and named it online-order*. It requires the plugin binary file path, class name, registry name and AWS region name. Another key configuration values are the key and value schema templates values, which are used for finding schema names. They are left unchanged because I will not enable schema for the key and the default template rule (%s) for the value matches the default naming convention of the client library. Note that those template properties are only applicable for message production on the UI, and we can leave them commented out if we don’t attempt that.
The configuration of kpow is simpler as it only requires the registry ARN and AWS region. Note that the app fails to start if the registry doesn’t exit. I created the registry named online-order before starting it.
1# /kafka-dev-with-docker/part-06/compose-ui.yml
2version: "3.5"
3
4services:
5 kafka-ui:
6 image: provectuslabs/kafka-ui:master
7 container_name: kafka-ui
8 ports:
9 - "8080:8080"
10 networks:
11 - kafkanet
12 environment:
13 AWS_ACCESS_KEY_ID: $AWS_ACCESS_KEY_ID
14 AWS_SECRET_ACCESS_KEY: $AWS_SECRET_ACCESS_KEY
15 AWS_SESSION_TOKEN: $AWS_SESSION_TOKEN
16 # kafka cluster
17 KAFKA_CLUSTERS_0_NAME: local
18 KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS: kafka-0:9092,kafka-1:9092,kafka-2:9092
19 KAFKA_CLUSTERS_0_ZOOKEEPER: zookeeper:2181
20 # kafka connect
21 KAFKA_CLUSTERS_0_KAFKACONNECT_0_NAME: local
22 KAFKA_CLUSTERS_0_KAFKACONNECT_0_ADDRESS: http://kafka-connect:8083
23 # glue schema registry serde
24 KAFKA_CLUSTERS_0_SERDE_0_NAME: online-order
25 KAFKA_CLUSTERS_0_SERDE_0_FILEPATH: /glue-serde/kafkaui-glue-serde-v1.0.3-jar-with-dependencies.jar
26 KAFKA_CLUSTERS_0_SERDE_0_CLASSNAME: com.provectus.kafka.ui.serdes.glue.GlueSerde
27 KAFKA_CLUSTERS_0_SERDE_0_PROPERTIES_REGION: $AWS_DEFAULT_REGION #required
28 KAFKA_CLUSTERS_0_SERDE_0_PROPERTIES_REGISTRY: online-order #required, name of Glue Schema Registry
29 # template that will be used to find schema name for topic key. Optional, default is null (not set).
30 # KAFKA_CLUSTERS_0_SERDE_0_PROPERTIES_KEYSCHEMANAMETEMPLATE: "%s-key"
31 # template that will be used to find schema name for topic value. Optional, default is '%s'
32 # KAFKA_CLUSTERS_0_SERDE_0_PROPERTIES_VALUESCHEMANAMETEMPLATE: "%s-value"
33 volumes:
34 - ./kafkaui-glue-serde-v1.0.3-jar-with-dependencies.jar:/glue-serde/kafkaui-glue-serde-v1.0.3-jar-with-dependencies.jar
35 kpow:
36 image: factorhouse/kpow-ce:91.2.1
37 container_name: kpow
38 ports:
39 - "3000:3000"
40 networks:
41 - kafkanet
42 environment:
43 AWS_ACCESS_KEY_ID: $AWS_ACCESS_KEY_ID
44 AWS_SECRET_ACCESS_KEY: $AWS_SECRET_ACCESS_KEY
45 AWS_SESSION_TOKEN: $AWS_SESSION_TOKEN
46 # kafka cluster
47 BOOTSTRAP: kafka-0:9092,kafka-1:9092,kafka-2:9092
48 # glue schema registry
49 SCHEMA_REGISTRY_ARN: $SCHEMA_REGISTRY_ARN
50 SCHEMA_REGISTRY_REGION: $AWS_DEFAULT_REGION
51 # kafka connect
52 CONNECT_REST_URL: http://kafka-connect:8083
53
54networks:
55 kafkanet:
56 external: true
57 name: kafka-network
Start Docker Compose Services
There are 3 docker compose files for the Kafka cluster, Kafka Connect and management applications. We can run the whole services by starting them in order. The order matters as the Connect server relies on the Kafka cluster and kpow in compose-ui.yml fails if the Connect server is not up and running.
1$ cd kafka-dev-with-docker/part-06
2# download connectors
3$ ./download.sh
4# build glue schema registry client library
5$ ./build.sh
6# starts 3 node kafka cluster
7$ docker-compose -f compose-kafka.yml up -d
8# starts kafka connect server in distributed mode
9$ docker-compose -f compose-connect.yml up -d
10# starts kafka-ui and kpow
11$ docker-compose -f compose-ui.yml up -d
Source Connector Creation
As mentioned earlier, Kafka Connect provides a REST API that manages connectors, and we can create a connector programmatically using it. The REST endpoint requires a JSON payload that includes connector configurations.
1$ cd kafka-dev-with-docker/part-06
2$ curl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" \
3 http://localhost:8083/connectors/ -d @configs/source.json
The connector class (connector.class) is required for any connector and I set it for the MSK Data Generator. Also, as many as two workers are allocated to the connector (tasks.max). As mentioned earlier, the converter-related properties are overridden. Specifically, the key converter is set to the string converter as the keys of both topics are set to be primitive values (genkp). Also, schema is not enabled for the key. On the other hand, schema is enabled for the value and the value converter is configured to the Avro converter of the Glue Schema Registry client library. The converter requires additional properties that cover AWS region, registry name, record type and flag to indicate whether to auto-generate schemas. Note that the generated schema name is the same to the topic name by default. Or we can configure a custom schema name by the schemaName property.
The remaining properties are specific to the source connectors. Basically it sends messages to two topics (customer and order). They are linked by the customer_id attribute of the order topic where the value is from the key of the customer topic. This is useful for practicing stream processing e.g. for joining two streams.
1// kafka-dev-with-docker/part-06/configs/source.json
2{
3 "name": "order-source",
4 "config": {
5 "connector.class": "com.amazonaws.mskdatagen.GeneratorSourceConnector",
6 "tasks.max": "2",
7 "key.converter": "org.apache.kafka.connect.storage.StringConverter",
8 "key.converter.schemas.enable": false,
9 "value.converter": "com.amazonaws.services.schemaregistry.kafkaconnect.AWSKafkaAvroConverter",
10 "value.converter.schemas.enable": true,
11 "value.converter.region": "ap-southeast-2",
12 "value.converter.schemaAutoRegistrationEnabled": true,
13 "value.converter.avroRecordType": "GENERIC_RECORD",
14 "value.converter.registry.name": "online-order",
15
16 "genkp.customer.with": "#{Code.isbn10}",
17 "genv.customer.name.with": "#{Name.full_name}",
18
19 "genkp.order.with": "#{Internet.uuid}",
20 "genv.order.product_id.with": "#{number.number_between '101','109'}",
21 "genv.order.quantity.with": "#{number.number_between '1','5'}",
22 "genv.order.customer_id.matching": "customer.key",
23
24 "global.throttle.ms": "500",
25 "global.history.records.max": "1000"
26 }
27}
Once created successfully, we can check the connector status as shown below.
1$ curl http://localhost:8083/connectors/order-source/status
1{
2 "name": "order-source",
3 "connector": {
4 "state": "RUNNING",
5 "worker_id": "172.19.0.6:8083"
6 },
7 "tasks": [
8 {
9 "id": 0,
10 "state": "RUNNING",
11 "worker_id": "172.19.0.6:8083"
12 },
13 {
14 "id": 1,
15 "state": "RUNNING",
16 "worker_id": "172.19.0.6:8083"
17 }
18 ],
19 "type": "source"
20}
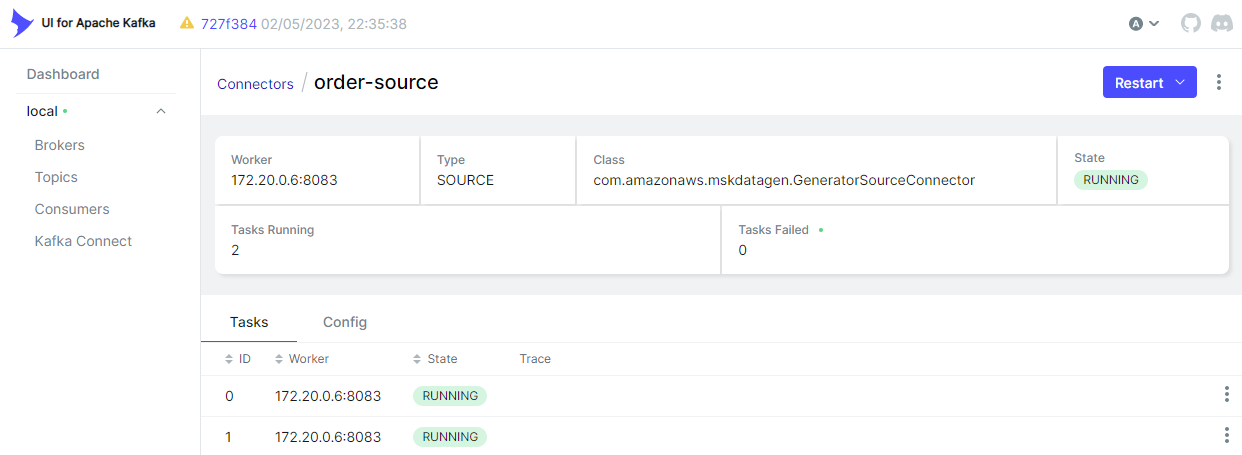
As we’ve added the connector URL, the Kafka Connect menu gets appeared on kafka-ui. We can check the details of the connector on the app as well.
Schemas
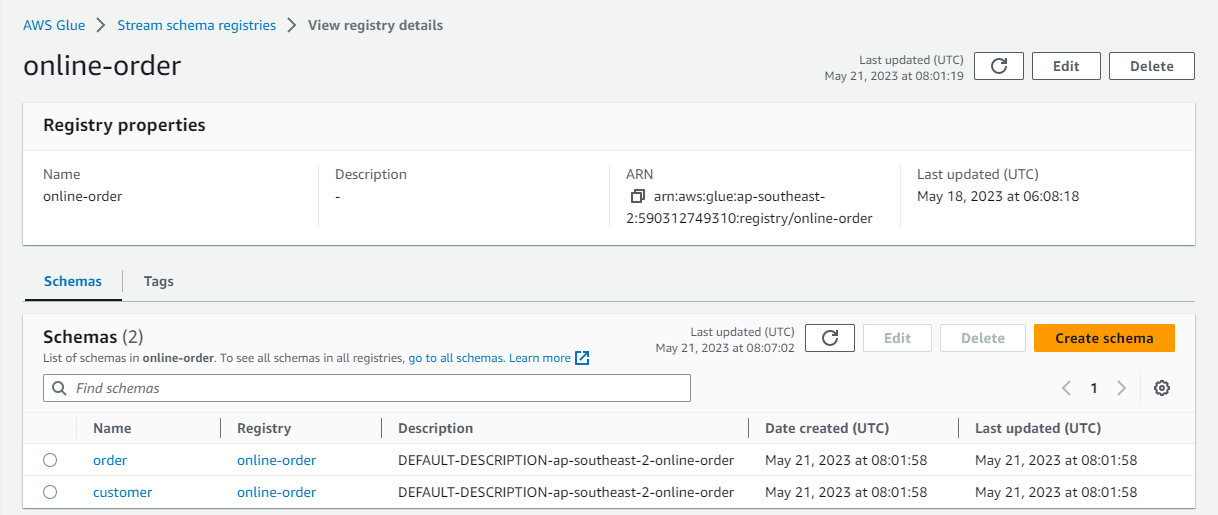
As we enabled auto-registration of schemas, the source connector generates two schemas. Below shows the schema for the order topic.
1// kafka-dev-with-docker/part-06/configs/order.avsc
2{
3 "type": "record",
4 "name": "Gen0",
5 "namespace": "com.amazonaws.mskdatagen",
6 "fields": [
7 {
8 "name": "quantity",
9 "type": ["null", "string"],
10 "default": null
11 },
12 {
13 "name": "product_id",
14 "type": ["null", "string"],
15 "default": null
16 },
17 {
18 "name": "customer_id",
19 "type": ["null", "string"],
20 "default": null
21 }
22 ],
23 "connect.name": "com.amazonaws.mskdatagen.Gen0"
24}
On AWS Console, we can check the schemas of the two topics are created.
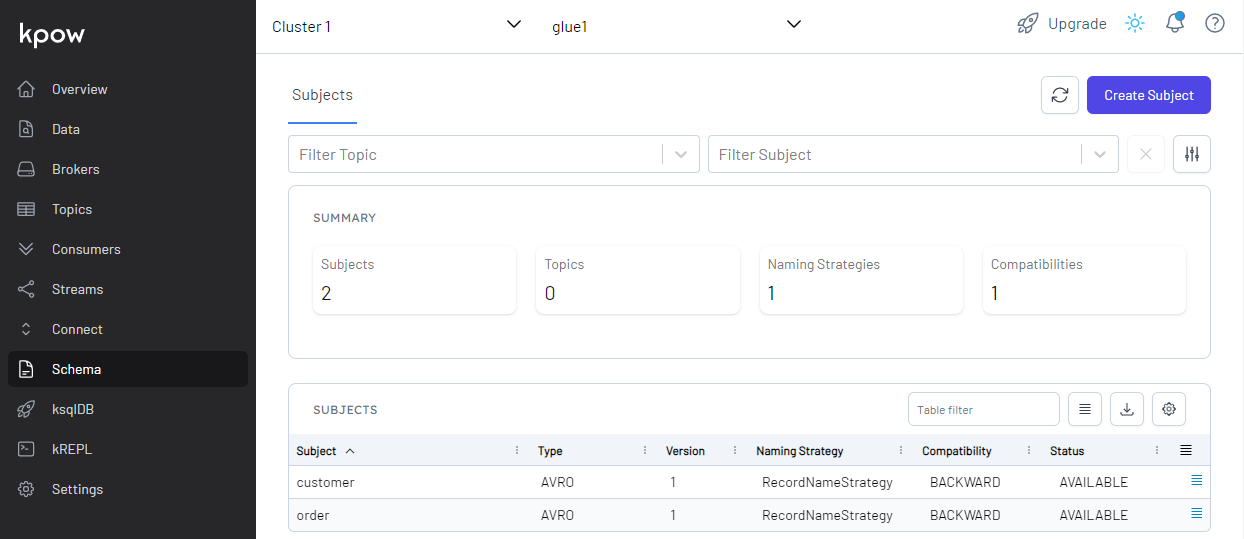
Also, we are able to see the schemas on kpow. The community edition only supports a single schema registry and its name is marked as glue1.
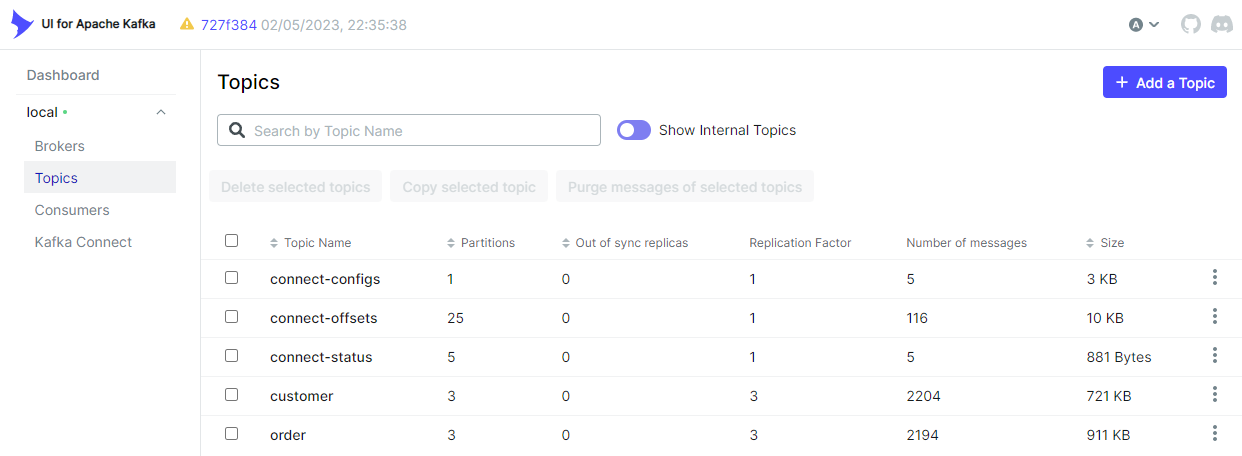
Kafka Topics
As configured, the source connector ingests messages to the customer and order topics.
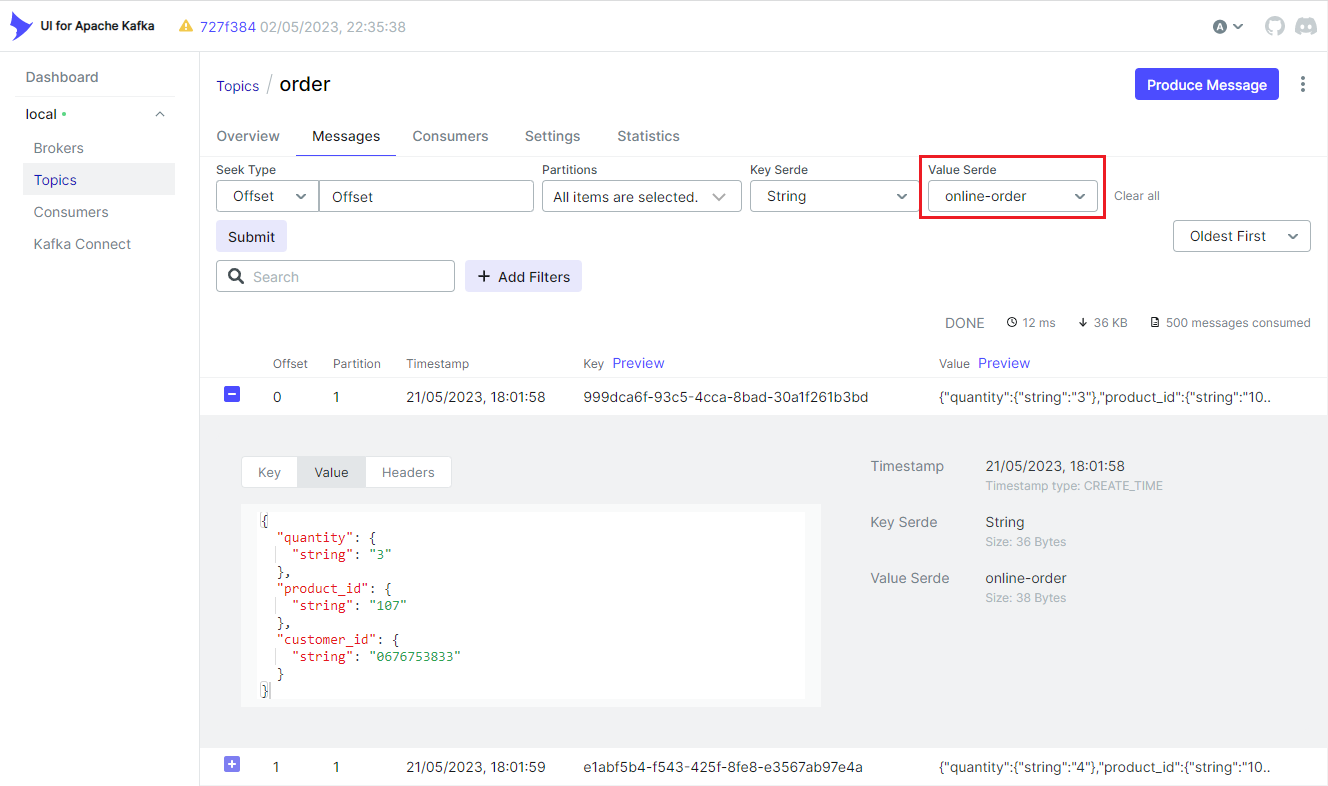
We can browse individual messages in the Messages tab. Note that we should select the Glue serializer plugin name (online-order) on the Value Serde drop down list. Otherwise, records won’t be deserialized correctly.
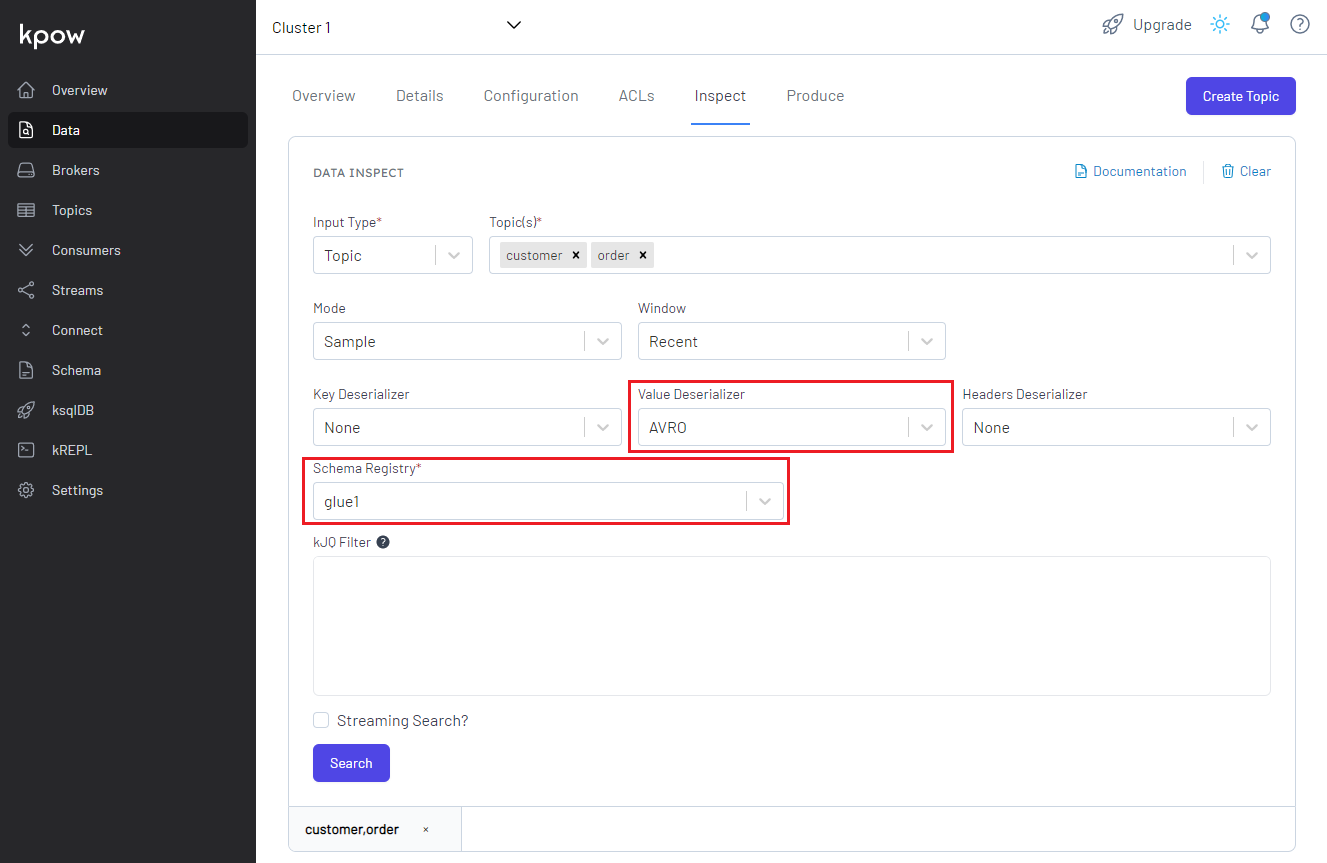
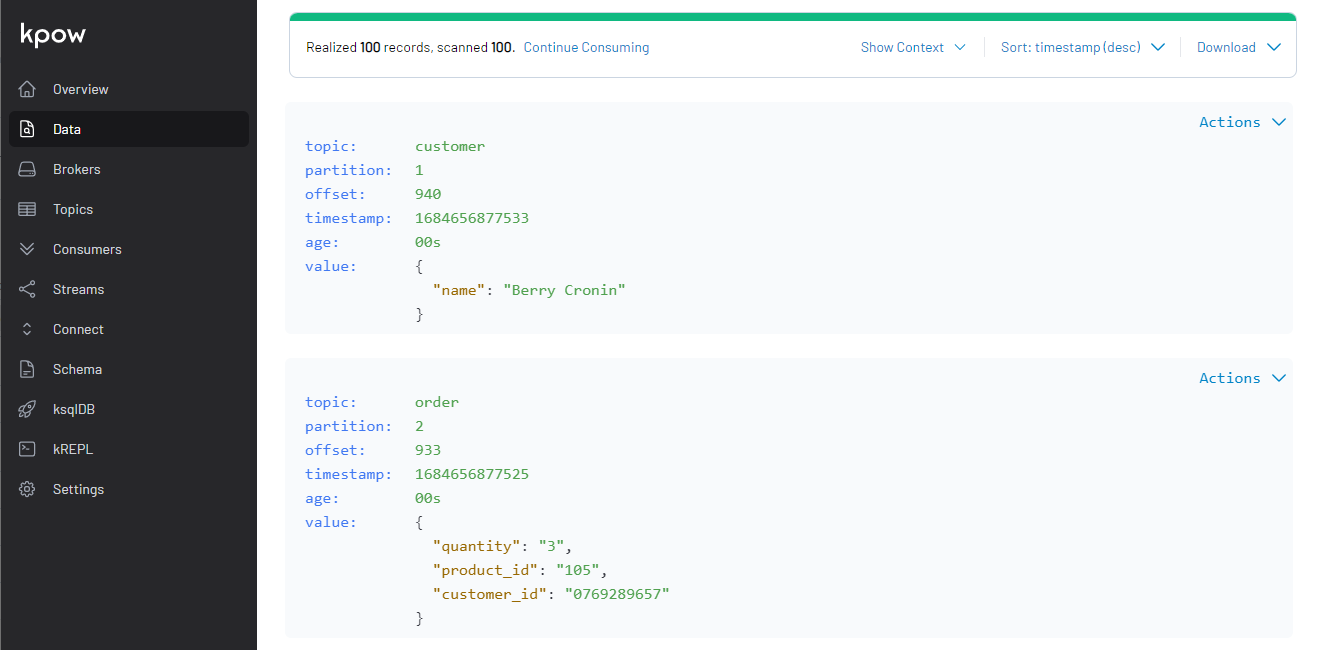
We can check the topic messages on kpow as well. If we select AVRO on the Value Deserializer drop down list, it requires to select the associating schema registry. We can select the pre-set schema registry name of glue1. Upon hitting the Search button, messages show up after being deserialized properly.
Sink Connector Creation
Similar to the source connector, we can create the sink connector using the REST API.
1$ cd kafka-dev-with-docker/part-06
2$ curl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" \
3 http://localhost:8083/connectors/ -d @configs/sink.json
The connector is configured to write messages from both the topics (topics) into a S3 bucket (s3.bucket.name) where files are prefixed by the partition number (DefaultPartitioner). Also, it invokes file commits every 60 seconds (rotate.schedule.interval.ms) or the number of messages reach 100 (flush.size). Like the source connector, it overrides the converter-related properties.
1// kafka-dev-with-docker/part-06/configs/sink.json
2{
3 "name": "order-sink",
4 "config": {
5 "connector.class": "io.confluent.connect.s3.S3SinkConnector",
6 "storage.class": "io.confluent.connect.s3.storage.S3Storage",
7 "format.class": "io.confluent.connect.s3.format.json.JsonFormat",
8 "tasks.max": "2",
9 "topics": "order,customer",
10 "s3.bucket.name": "kafka-dev-ap-southeast-2",
11 "s3.region": "ap-southeast-2",
12 "flush.size": "100",
13 "rotate.schedule.interval.ms": "60000",
14 "timezone": "Australia/Sydney",
15 "partitioner.class": "io.confluent.connect.storage.partitioner.DefaultPartitioner",
16 "key.converter": "org.apache.kafka.connect.storage.StringConverter",
17 "key.converter.schemas.enable": false,
18 "value.converter": "com.amazonaws.services.schemaregistry.kafkaconnect.AWSKafkaAvroConverter",
19 "value.converter.schemas.enable": true,
20 "value.converter.region": "ap-southeast-2",
21 "value.converter.avroRecordType": "GENERIC_RECORD",
22 "value.converter.registry.name": "online-order",
23 "errors.log.enable": "true"
24 }
25}
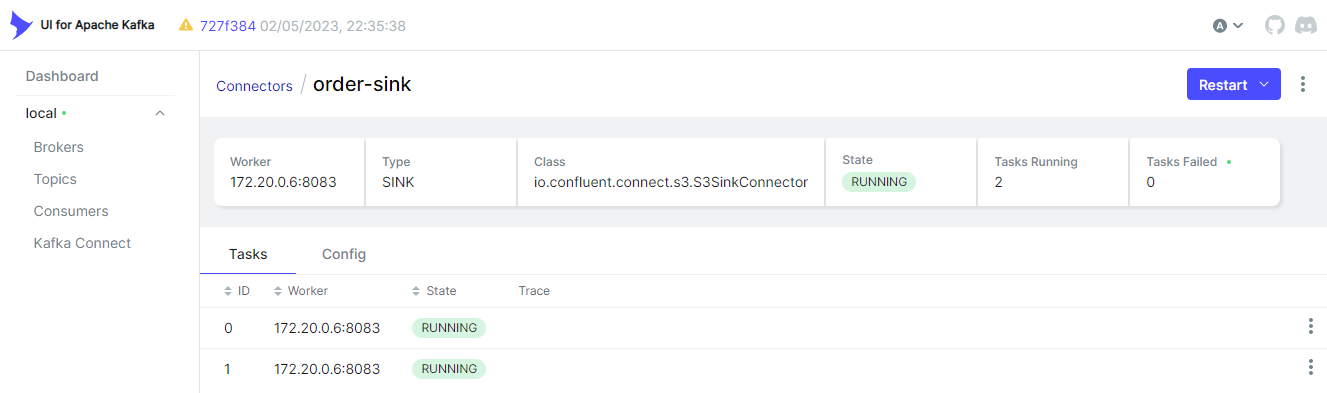
Below shows the sink connector details on kafka-ui.
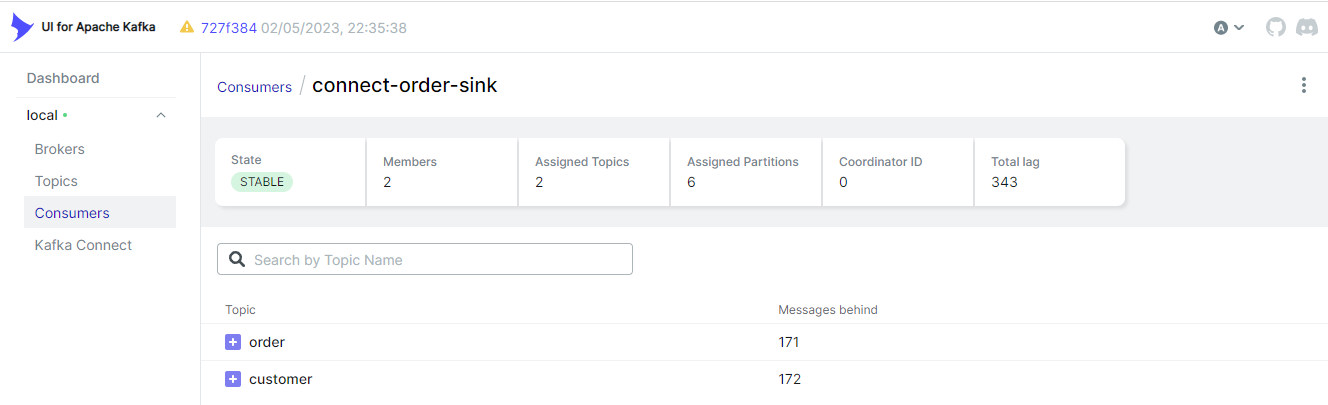
Kafka Consumers
The sink connector creates a Kafka consumer, and it is named as connect-order-sink. We see that it subscribes the two topics and is in the stable state. It has two members because it is configured to have as many as 2 tasks.
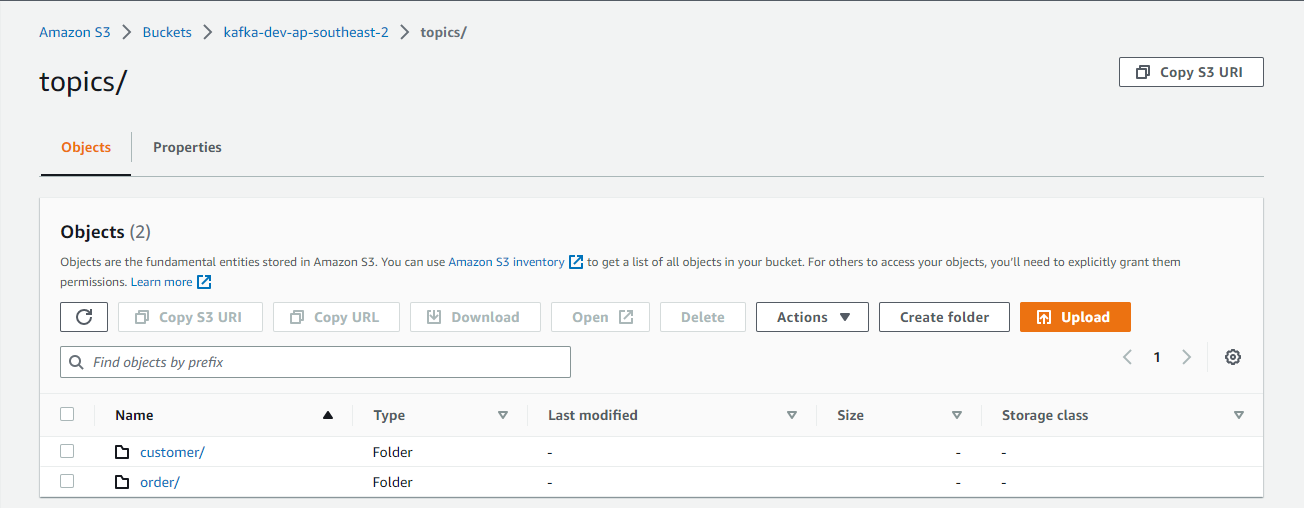
S3 Destination
The sink connector writes messages of the two topics (customer and order), and topic names are used as prefixes.
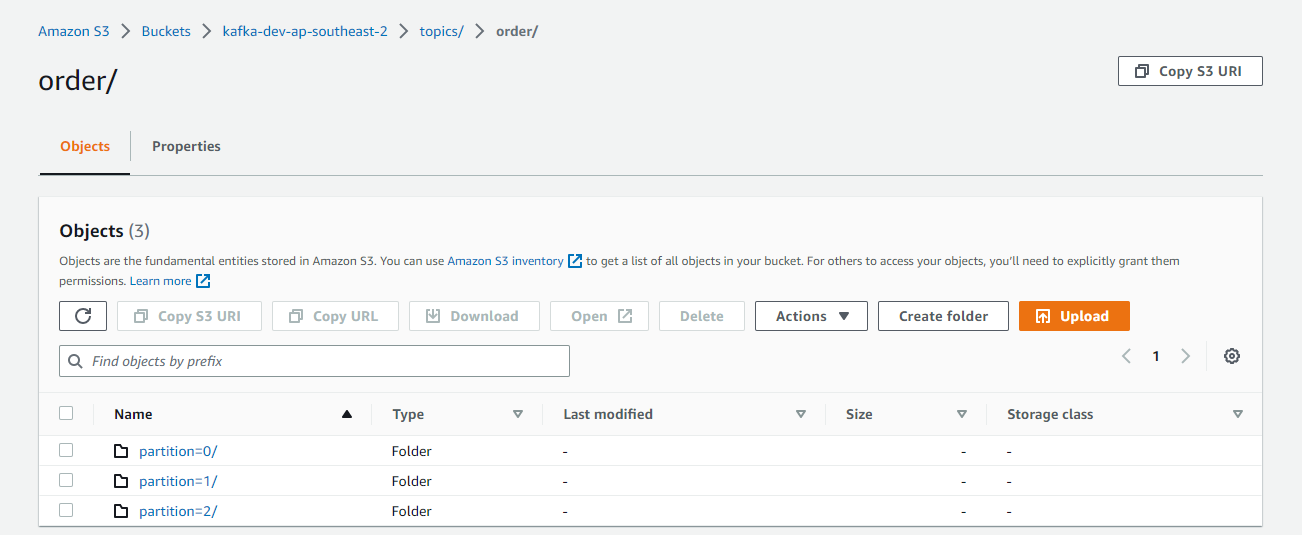
As mentioned, the default partitioner prefixes files further by the partition number, and it can be checked below.
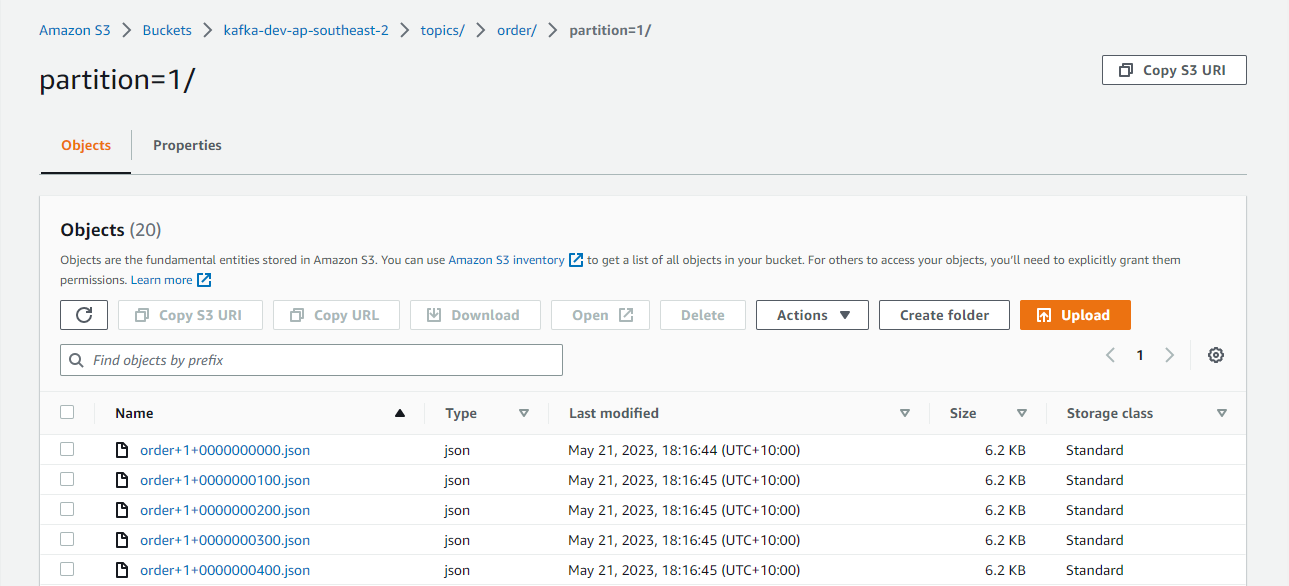
The files are generated by <topic>+<partiton>+<start-offset>.json. The sink connector’s format class is set to io.confluent.connect.s3.format.json.JsonFormat so that it writes to Json files.
Summary
In Part 3, we developed a data ingestion pipeline using Kafka Connect source and sink connectors without enabling schemas. Later we discussed the benefits of schema registry when developing Kafka applications in Part 5. In this post, I demonstrated how to enhance the existing data ingestion pipeline by integrating AWS Glue Schema Registry.










Comments