
As part of investigating how to utilize Kafka Connect effectively for AWS services integration, I demonstrated how to develop the Camel DynamoDB sink connector using Docker in Part 2. Fake order data was generated using the MSK Data Generator source connector, and the sink connector was configured to consume the topic messages to ingest them into a DynamoDB table. In this post, I will illustrate how to deploy the data ingestion applications using Amazon MSK and MSK Connect.
- Part 1 Introduction
- Part 2 Develop Camel DynamoDB Sink Connector
- Part 3 Deploy Camel DynamoDB Sink Connector (this post)
- Part 4 Develop Aiven OpenSearch Sink Connector
- Part 5 Deploy Aiven OpenSearch Sink Connector
Infrastructure
A VPC with 3 public and private subnets is created using the AWS VPC Terraform module (vpc.tf). Also, a SoftEther VPN server is deployed in order to access the resources in the private subnets from the developer machine (vpn.tf). It is particularly useful to monitor and manage the MSK cluster and Kafka topic locally. The details about how to configure the VPN server can be found in an earlier post. The source can be found in the GitHub repository of this post.
MSK
An MSK cluster with 3 brokers is created. The broker nodes are deployed with the kafka.m5.large instance type in private subnets and IAM authentication is used for the client authentication method. Finally, additional server configurations are added such as enabling auto creation of topics and topic deletion.
1# kafka-connect-for-aws/part-03/variable.tf
2locals {
3 ...
4 msk = {
5 version = "2.8.1"
6 instance_size = "kafka.m5.large"
7 ebs_volume_size = 20
8 log_retention_ms = 604800000 # 7 days
9 num_partitions = 3
10 default_replication_factor = 3
11 }
12 ...
13}
14# kafka-connect-for-aws/part-03/msk.tf
15resource "aws_msk_cluster" "msk_data_cluster" {
16 cluster_name = "${local.name}-msk-cluster"
17 kafka_version = local.msk.version
18 number_of_broker_nodes = length(module.vpc.private_subnets)
19 configuration_info {
20 arn = aws_msk_configuration.msk_config.arn
21 revision = aws_msk_configuration.msk_config.latest_revision
22 }
23
24 broker_node_group_info {
25 instance_type = local.msk.instance_size
26 client_subnets = module.vpc.private_subnets
27 security_groups = [aws_security_group.msk.id]
28 storage_info {
29 ebs_storage_info {
30 volume_size = local.msk.ebs_volume_size
31 }
32 }
33 }
34
35 client_authentication {
36 sasl {
37 iam = true
38 }
39 }
40
41 logging_info {
42 broker_logs {
43 cloudwatch_logs {
44 enabled = true
45 log_group = aws_cloudwatch_log_group.msk_cluster_lg.name
46 }
47 s3 {
48 enabled = true
49 bucket = aws_s3_bucket.default_bucket.id
50 prefix = "logs/msk/cluster/"
51 }
52 }
53 }
54
55 tags = local.tags
56
57 depends_on = [aws_msk_configuration.msk_config]
58}
59
60resource "aws_msk_configuration" "msk_config" {
61 name = "${local.name}-msk-configuration"
62
63 kafka_versions = [local.msk.version]
64
65 server_properties = <<PROPERTIES
66 auto.create.topics.enable = true
67 delete.topic.enable = true
68 log.retention.ms = ${local.msk.log_retention_ms}
69 num.partitions = ${local.msk.num_partitions}
70 default.replication.factor = ${local.msk.default_replication_factor}
71 PROPERTIES
72}
Security Group
The security group for the MSK cluster allows all inbound traffic from itself and all outbound traffic into all IP addresses. The Kafka connectors will use the same security group and the former is necessary. Both the rules are configured too generously, and we can limit the protocol and port ranges in production. The last inbound rule is for VPN access.
1# kafka-connect-for-aws/part-03/msk.tf
2resource "aws_security_group" "msk" {
3 name = "${local.name}-msk-sg"
4 vpc_id = module.vpc.vpc_id
5
6 lifecycle {
7 create_before_destroy = true
8 }
9
10 tags = local.tags
11}
12
13resource "aws_security_group_rule" "msk_self_inbound_all" {
14 type = "ingress"
15 description = "Allow ingress from itself - required for MSK Connect"
16 security_group_id = aws_security_group.msk.id
17 protocol = "-1"
18 from_port = "0"
19 to_port = "0"
20 source_security_group_id = aws_security_group.msk.id
21}
22
23resource "aws_security_group_rule" "msk_self_outbound_all" {
24 type = "egress"
25 description = "Allow outbound all"
26 security_group_id = aws_security_group.msk.id
27 protocol = "-1"
28 from_port = "0"
29 to_port = "0"
30 cidr_blocks = ["0.0.0.0/0"]
31}
32
33resource "aws_security_group_rule" "msk_vpn_inbound" {
34 count = local.vpn.to_create ? 1 : 0
35 type = "ingress"
36 description = "Allow VPN access"
37 security_group_id = aws_security_group.msk.id
38 protocol = "tcp"
39 from_port = 9098
40 to_port = 9098
41 source_security_group_id = aws_security_group.vpn[0].id
42}
DynamoDB
The destination table is named connect-for-aws-orders (${local.name}-orders), and it has the primary key where order_id and ordered_at are the hash and range key respectively. It also has a global secondary index where customer_id and ordered_at constitute the primary key. Note that ordered_at is not generated by the source connector as the Java faker library doesn’t have a method to generate a current timestamp. As illustrated below it’ll be created by the sink connector using SMTs. The table can be created using as shown below.
1# kafka-connect-for-aws/part-03/ddb.tf
2resource "aws_dynamodb_table" "orders_table" {
3 name = "${local.name}-orders"
4 billing_mode = "PROVISIONED"
5 read_capacity = 1
6 write_capacity = 1
7 hash_key = "order_id"
8 range_key = "ordered_at"
9
10 attribute {
11 name = "order_id"
12 type = "S"
13 }
14
15 attribute {
16 name = "customer_id"
17 type = "S"
18 }
19
20 attribute {
21 name = "ordered_at"
22 type = "S"
23 }
24
25 global_secondary_index {
26 name = "customer"
27 hash_key = "customer_id"
28 range_key = "ordered_at"
29 write_capacity = 1
30 read_capacity = 1
31 projection_type = "ALL"
32 }
33
34 tags = local.tags
35}
Kafka Management App
A Kafka management app can be a good companion for development as it helps monitor and manage resources on an easy-to-use user interface. We’ll use Kpow Community Edition (CE) in this post. It allows you to manage one Kafka Cluster, one Schema Registry, and one Connect Cluster, with the UI supporting a single user session at a time. In the following compose file, we added connection details of the MSK cluster and MSK Connect.
1# kafka-connect-for-aws/part-03/docker-compose.yml
2version: "3"
3
4services:
5 kpow:
6 image: factorhouse/kpow-ce:91.2.1
7 container_name: kpow
8 ports:
9 - "3000:3000"
10 networks:
11 - kafkanet
12 environment:
13 AWS_ACCESS_KEY_ID: $AWS_ACCESS_KEY_ID
14 AWS_SECRET_ACCESS_KEY: $AWS_SECRET_ACCESS_KEY
15 AWS_SESSION_TOKEN: $AWS_SESSION_TOKEN
16 # broker details
17 BOOTSTRAP: $BOOTSTRAP_SERVERS
18 # client authentication
19 SECURITY_PROTOCOL: SASL_SSL
20 SASL_MECHANISM: AWS_MSK_IAM
21 SASL_JAAS_CONFIG: software.amazon.msk.auth.iam.IAMLoginModule required;
22 SASL_CLIENT_CALLBACK_HANDLER_CLASS: software.amazon.msk.auth.iam.IAMClientCallbackHandler
23 # MSK connect
24 CONNECT_AWS_REGION: ap-southeast-2
25
26networks:
27 kafkanet:
28 name: kafka-network
Data Ingestion Pipeline
Connector Source Download
Before we deploy the connectors, their sources need to be downloaded into the ./connectors path so that they can be saved into S3 followed by being created as custom plugins. The MSK Data Generator is a single Jar file, and it can be kept it as is. On the other hand, the Camel DynamoDB sink connector is an archive file, and the contents should be compressed as the zip format.
1# kafka-connect-for-aws/part-03/download.sh
2#!/usr/bin/env bash
3SCRIPT_DIR="$(cd $(dirname "$0"); pwd)"
4
5SRC_PATH=${SCRIPT_DIR}/connectors
6rm -rf ${SRC_PATH} && mkdir ${SRC_PATH}
7
8## MSK Data Generator Souce Connector
9echo "downloading msk data generator..."
10DOWNLOAD_URL=https://github.com/awslabs/amazon-msk-data-generator/releases/download/v0.4.0/msk-data-generator-0.4-jar-with-dependencies.jar
11
12curl -L -o ${SRC_PATH}/msk-data-generator.jar ${DOWNLOAD_URL}
13
14## Download camel dynamodb sink connector
15echo "download camel dynamodb sink connector..."
16DOWNLOAD_URL=https://repo.maven.apache.org/maven2/org/apache/camel/kafkaconnector/camel-aws-ddb-sink-kafka-connector/3.20.3/camel-aws-ddb-sink-kafka-connector-3.20.3-package.tar.gz
17
18# decompress and zip contents to create custom plugin of msk connect later
19curl -o ${SRC_PATH}/camel-aws-ddb-sink-kafka-connector.tar.gz ${DOWNLOAD_URL} \
20 && tar -xvzf ${SRC_PATH}/camel-aws-ddb-sink-kafka-connector.tar.gz -C ${SRC_PATH} \
21 && cd ${SRC_PATH}/camel-aws-ddb-sink-kafka-connector \
22 && zip -r camel-aws-ddb-sink-kafka-connector.zip . \
23 && mv camel-aws-ddb-sink-kafka-connector.zip ${SRC_PATH} \
24 && rm ${SRC_PATH}/camel-aws-ddb-sink-kafka-connector.tar.gz
Below shows the connector sources that can be used to create custom plugins.
1$ tree connectors -I 'camel-aws-ddb-sink-kafka-connector|docs'
2connectors
3├── camel-aws-ddb-sink-kafka-connector.zip
4└── msk-data-generator.jar
Connector IAM Role
For simplicity, a single IAM role will be used for both the source and sink connectors. The custom managed policy has permission on MSK cluster resources (cluster, topic and group). It also has permission on S3 bucket and CloudWatch Log for logging. Also, an AWS managed policy for DynamoDB (AmazonDynamoDBFullAccess) is attached for the sink connector.
1# kafka-connect-for-aws/part-03/msk-connect.tf
2resource "aws_iam_role" "kafka_connector_role" {
3 name = "${local.name}-connector-role"
4
5 assume_role_policy = jsonencode({
6 Version = "2012-10-17"
7 Statement = [
8 {
9 Action = "sts:AssumeRole"
10 Effect = "Allow"
11 Sid = ""
12 Principal = {
13 Service = "kafkaconnect.amazonaws.com"
14 }
15 },
16 ]
17 })
18 managed_policy_arns = [
19 "arn:aws:iam::aws:policy/AmazonDynamoDBFullAccess",
20 aws_iam_policy.kafka_connector_policy.arn
21 ]
22}
23
24resource "aws_iam_policy" "kafka_connector_policy" {
25 name = "${local.name}-connector-policy"
26
27 policy = jsonencode({
28 Version = "2012-10-17"
29 Statement = [
30 {
31 Sid = "PermissionOnCluster"
32 Action = [
33 "kafka-cluster:Connect",
34 "kafka-cluster:AlterCluster",
35 "kafka-cluster:DescribeCluster"
36 ]
37 Effect = "Allow"
38 Resource = "arn:aws:kafka:${local.region}:${data.aws_caller_identity.current.account_id}:cluster/${local.name}-msk-cluster/*"
39 },
40 {
41 Sid = "PermissionOnTopics"
42 Action = [
43 "kafka-cluster:*Topic*",
44 "kafka-cluster:WriteData",
45 "kafka-cluster:ReadData"
46 ]
47 Effect = "Allow"
48 Resource = "arn:aws:kafka:${local.region}:${data.aws_caller_identity.current.account_id}:topic/${local.name}-msk-cluster/*"
49 },
50 {
51 Sid = "PermissionOnGroups"
52 Action = [
53 "kafka-cluster:AlterGroup",
54 "kafka-cluster:DescribeGroup"
55 ]
56 Effect = "Allow"
57 Resource = "arn:aws:kafka:${local.region}:${data.aws_caller_identity.current.account_id}:group/${local.name}-msk-cluster/*"
58 },
59 {
60 Sid = "PermissionOnDataBucket"
61 Action = [
62 "s3:ListBucket",
63 "s3:*Object"
64 ]
65 Effect = "Allow"
66 Resource = [
67 "${aws_s3_bucket.default_bucket.arn}",
68 "${aws_s3_bucket.default_bucket.arn}/*"
69 ]
70 },
71 {
72 Sid = "LoggingPermission"
73 Action = [
74 "logs:CreateLogStream",
75 "logs:CreateLogGroup",
76 "logs:PutLogEvents"
77 ]
78 Effect = "Allow"
79 Resource = "*"
80 },
81 ]
82 })
83}
Source Connector
The connector source will be uploaded into S3 and a custom plugin is created with it. Then the source connector will be created using the custom plugin.
In connector configuration, the connector class (connector.class) is required for any connector and I set it for the MSK Data Generator. Also, a single worker is allocated to the connector (tasks.max). As mentioned earlier, the converter-related properties are overridden. Specifically, the key converter is set to the string converter as the key of the topic is set to be primitive values (genkp). Also, schemas are not enabled for both the key and value.
Those properties in the middle are specific to the source connector. Basically it sends messages to a topic named order. The key is marked as to-replace as it will be replaced with the order_id attribute of the value - see below. The value has order_id, product_id, quantity, customer_id and customer_name attributes, and they are generated by the Java faker library.
It can be easier to manage messages if the same order ID is shared with the key and value. We can achieve it using single message transforms (SMTs). Specifically I used two transforms - ValueToKey and ExtractField to achieve it. As the name suggests, the former copies the order_id value into the key. The latter is used additionally because the key is set to have primitive string values. Finally, the last transform (Cast) is to change the quantity value into integer.
1# kafka-connect-for-aws/part-03/msk-connect.tf
2resource "aws_mskconnect_connector" "msk_data_generator" {
3 name = "${local.name}-order-source"
4
5 kafkaconnect_version = "2.7.1"
6
7 capacity {
8 provisioned_capacity {
9 mcu_count = 1
10 worker_count = 1
11 }
12 }
13
14 connector_configuration = {
15 # connector configuration
16 "connector.class" = "com.amazonaws.mskdatagen.GeneratorSourceConnector",
17 "tasks.max" = "1",
18 "key.converter" = "org.apache.kafka.connect.storage.StringConverter",
19 "key.converter.schemas.enable" = false,
20 "value.converter" = "org.apache.kafka.connect.json.JsonConverter",
21 "value.converter.schemas.enable" = false,
22 # msk data generator configuration
23 "genkp.order.with" = "to-replace",
24 "genv.order.order_id.with" = "#{Internet.uuid}",
25 "genv.order.product_id.with" = "#{Code.isbn10}",
26 "genv.order.quantity.with" = "#{number.number_between '1','5'}",
27 "genv.order.customer_id.with" = "#{number.number_between '100','199'}",
28 "genv.order.customer_name.with" = "#{Name.full_name}",
29 "global.throttle.ms" = "500",
30 "global.history.records.max" = "1000",
31 # single message transforms
32 "transforms" = "copyIdToKey,extractKeyFromStruct,cast",
33 "transforms.copyIdToKey.type" = "org.apache.kafka.connect.transforms.ValueToKey",
34 "transforms.copyIdToKey.fields" = "order_id",
35 "transforms.extractKeyFromStruct.type" = "org.apache.kafka.connect.transforms.ExtractField$Key",
36 "transforms.extractKeyFromStruct.field" = "order_id",
37 "transforms.cast.type" = "org.apache.kafka.connect.transforms.Cast$Value",
38 "transforms.cast.spec" = "quantity:int8"
39 }
40
41 kafka_cluster {
42 apache_kafka_cluster {
43 bootstrap_servers = aws_msk_cluster.msk_data_cluster.bootstrap_brokers_sasl_iam
44
45 vpc {
46 security_groups = [aws_security_group.msk.id]
47 subnets = module.vpc.private_subnets
48 }
49 }
50 }
51
52 kafka_cluster_client_authentication {
53 authentication_type = "IAM"
54 }
55
56 kafka_cluster_encryption_in_transit {
57 encryption_type = "TLS"
58 }
59
60 plugin {
61 custom_plugin {
62 arn = aws_mskconnect_custom_plugin.msk_data_generator.arn
63 revision = aws_mskconnect_custom_plugin.msk_data_generator.latest_revision
64 }
65 }
66
67 log_delivery {
68 worker_log_delivery {
69 cloudwatch_logs {
70 enabled = true
71 log_group = aws_cloudwatch_log_group.msk_data_generator.name
72 }
73 s3 {
74 enabled = true
75 bucket = aws_s3_bucket.default_bucket.id
76 prefix = "logs/msk/connect/msk-data-generator"
77 }
78 }
79 }
80
81 service_execution_role_arn = aws_iam_role.kafka_connector_role.arn
82}
83
84resource "aws_mskconnect_custom_plugin" "msk_data_generator" {
85 name = "${local.name}-msk-data-generator"
86 content_type = "JAR"
87
88 location {
89 s3 {
90 bucket_arn = aws_s3_bucket.default_bucket.arn
91 file_key = aws_s3_object.msk_data_generator.key
92 }
93 }
94}
95
96resource "aws_s3_object" "msk_data_generator" {
97 bucket = aws_s3_bucket.default_bucket.id
98 key = "plugins/msk-data-generator.jar"
99 source = "connectors/msk-data-generator.jar"
100
101 etag = filemd5("connectors/msk-data-generator.jar")
102}
103
104resource "aws_cloudwatch_log_group" "msk_data_generator" {
105 name = "/msk/connect/msk-data-generator"
106
107 retention_in_days = 1
108
109 tags = local.tags
110}
We can check the details of the connector on AWS Console as shown below.
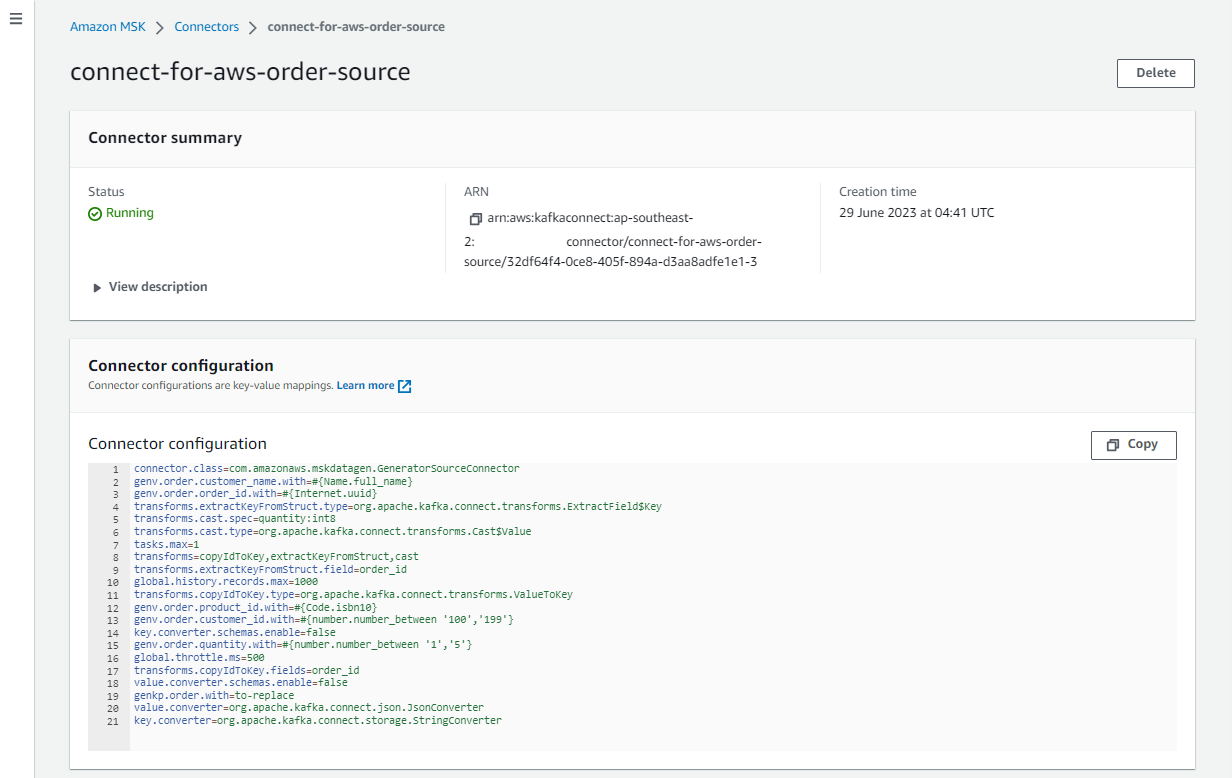
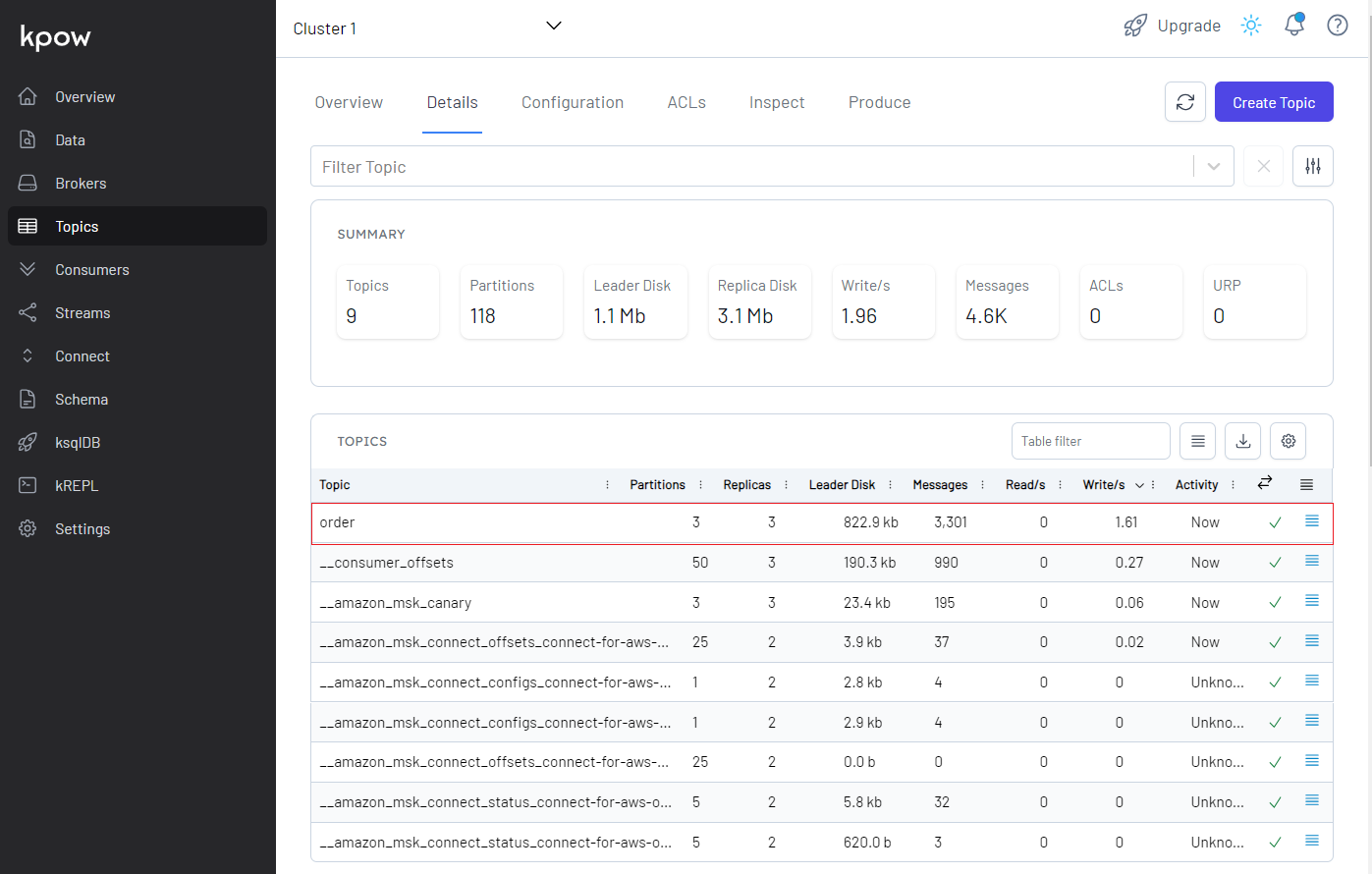
Kafka Topic
As configured, the source connector ingests messages to the order topic, and we can check it on kpow.
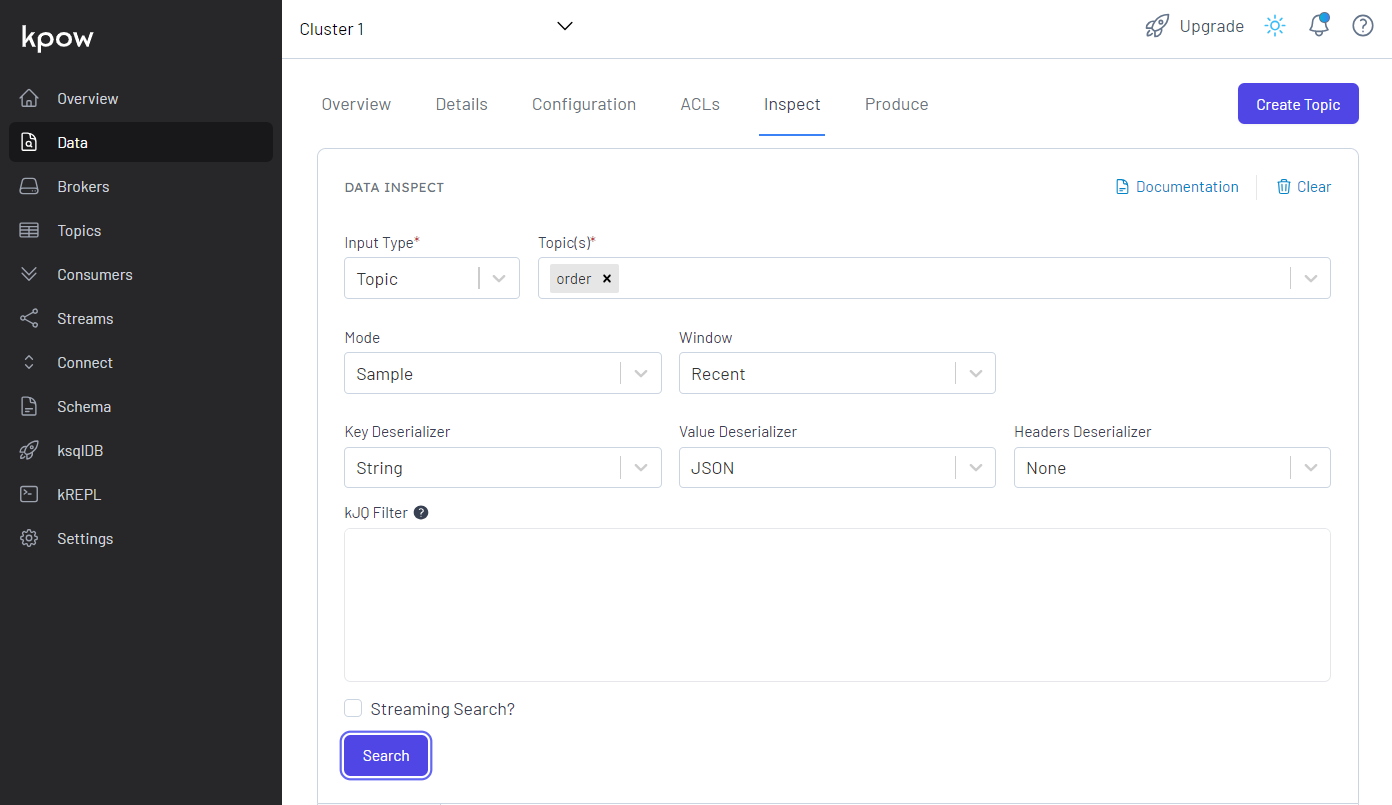
We can browse individual messages in the Inspect tab in the Data menu.

Sink Connector
The connector is configured to write messages from the order topic into the DynamoDB table created earlier. It requires to specify the table name, AWS region, operation, write capacity and whether to use the default credential provider - see the documentation for details. Note that, if you don’t use the default credential provider, you have to specify the access key id and secret access key. Note further that, although the current LTS version is v3.18.2, the default credential provider option didn’t work for me, and I was recommended to use v3.20.3 instead. Finally, the camel.sink.unmarshal option is to convert data from the internal java.util.HashMap type into the required java.io.InputStream type. Without this configuration, the connector fails with org.apache.camel.NoTypeConversionAvailableException error.
Although the destination table has ordered_at as the range key, it is not created by the source connector because the Java faker library doesn’t have a method to generate a current timestamp. Therefore, it is created by the sink connector using two SMTs - InsertField and TimestampConverter. Specifically they add a timestamp value to the order_at attribute, format the value as yyyy-MM-dd HH:mm:ss:SSS, and convert its type into string.
1# kafka-connect-for-aws/part-03/msk-connect.tf
2resource "aws_mskconnect_connector" "camel_ddb_sink" {
3 name = "${local.name}-order-sink"
4
5 kafkaconnect_version = "2.7.1"
6
7 capacity {
8 provisioned_capacity {
9 mcu_count = 1
10 worker_count = 1
11 }
12 }
13
14 connector_configuration = {
15 # connector configuration
16 "connector.class" = "org.apache.camel.kafkaconnector.awsddbsink.CamelAwsddbsinkSinkConnector",
17 "tasks.max" = "1",
18 "key.converter" = "org.apache.kafka.connect.storage.StringConverter",
19 "key.converter.schemas.enable" = false,
20 "value.converter" = "org.apache.kafka.connect.json.JsonConverter",
21 "value.converter.schemas.enable" = false,
22 # camel ddb sink configuration
23 "topics" = "order",
24 "camel.kamelet.aws-ddb-sink.table" = aws_dynamodb_table.orders_table.id,
25 "camel.kamelet.aws-ddb-sink.region" = local.region,
26 "camel.kamelet.aws-ddb-sink.operation" = "PutItem",
27 "camel.kamelet.aws-ddb-sink.writeCapacity" = 1,
28 "camel.kamelet.aws-ddb-sink.useDefaultCredentialsProvider" = true,
29 "camel.sink.unmarshal" = "jackson",
30 # single message transforms
31 "transforms" = "insertTS,formatTS",
32 "transforms.insertTS.type" = "org.apache.kafka.connect.transforms.InsertField$Value",
33 "transforms.insertTS.timestamp.field" = "ordered_at",
34 "transforms.formatTS.type" = "org.apache.kafka.connect.transforms.TimestampConverter$Value",
35 "transforms.formatTS.format" = "yyyy-MM-dd HH:mm:ss:SSS",
36 "transforms.formatTS.field" = "ordered_at",
37 "transforms.formatTS.target.type" = "string"
38 }
39
40 kafka_cluster {
41 apache_kafka_cluster {
42 bootstrap_servers = aws_msk_cluster.msk_data_cluster.bootstrap_brokers_sasl_iam
43
44 vpc {
45 security_groups = [aws_security_group.msk.id]
46 subnets = module.vpc.private_subnets
47 }
48 }
49 }
50
51 kafka_cluster_client_authentication {
52 authentication_type = "IAM"
53 }
54
55 kafka_cluster_encryption_in_transit {
56 encryption_type = "TLS"
57 }
58
59 plugin {
60 custom_plugin {
61 arn = aws_mskconnect_custom_plugin.camel_ddb_sink.arn
62 revision = aws_mskconnect_custom_plugin.camel_ddb_sink.latest_revision
63 }
64 }
65
66 log_delivery {
67 worker_log_delivery {
68 cloudwatch_logs {
69 enabled = true
70 log_group = aws_cloudwatch_log_group.camel_ddb_sink.name
71 }
72 s3 {
73 enabled = true
74 bucket = aws_s3_bucket.default_bucket.id
75 prefix = "logs/msk/connect/camel-ddb-sink"
76 }
77 }
78 }
79
80 service_execution_role_arn = aws_iam_role.kafka_connector_role.arn
81
82 depends_on = [
83 aws_mskconnect_connector.msk_data_generator
84 ]
85}
86
87resource "aws_mskconnect_custom_plugin" "camel_ddb_sink" {
88 name = "${local.name}-camel-ddb-sink"
89 content_type = "ZIP"
90
91 location {
92 s3 {
93 bucket_arn = aws_s3_bucket.default_bucket.arn
94 file_key = aws_s3_object.camel_ddb_sink.key
95 }
96 }
97}
98
99resource "aws_s3_object" "camel_ddb_sink" {
100 bucket = aws_s3_bucket.default_bucket.id
101 key = "plugins/camel-aws-ddb-sink-kafka-connector.zip"
102 source = "connectors/camel-aws-ddb-sink-kafka-connector.zip"
103
104 etag = filemd5("connectors/camel-aws-ddb-sink-kafka-connector.zip")
105}
106
107resource "aws_cloudwatch_log_group" "camel_ddb_sink" {
108 name = "/msk/connect/camel-ddb-sink"
109
110 retention_in_days = 1
111
112 tags = local.tags
113}
The sink connector can be checked on AWS Console as shown below.
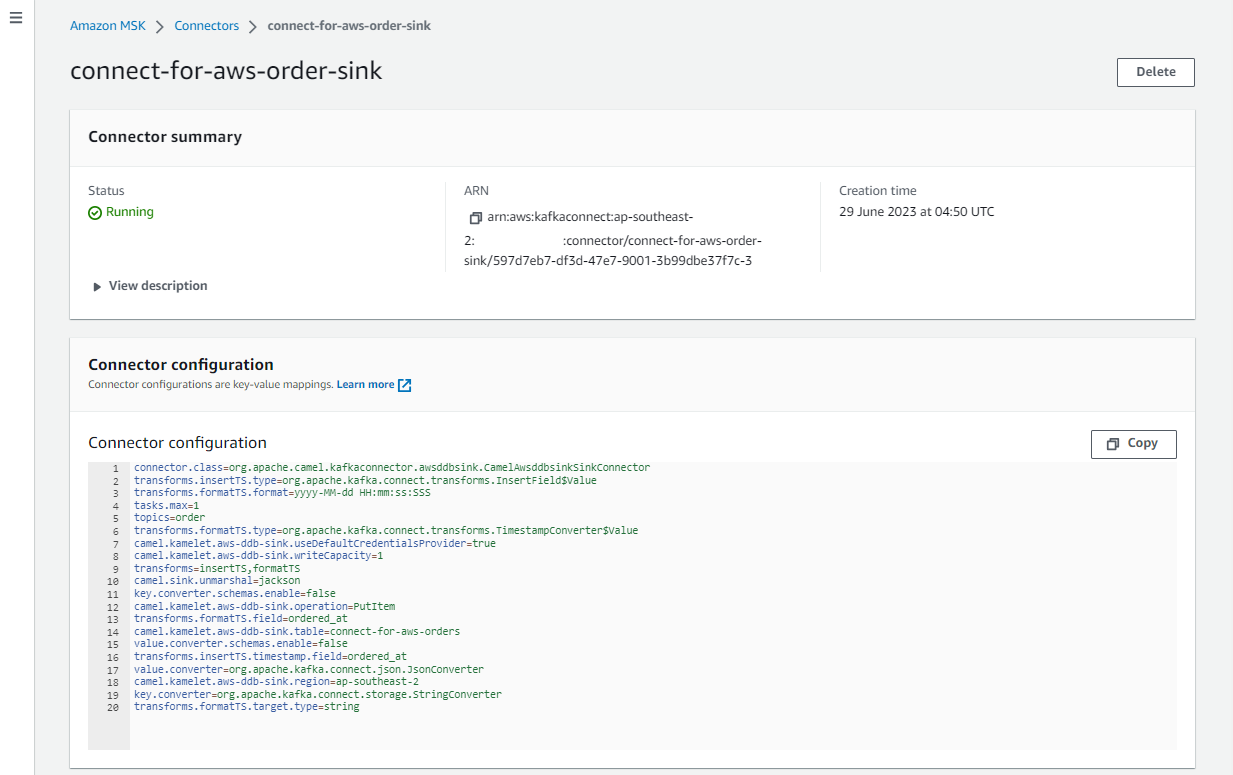
DynamoDB Destination
We can check the ingested records on the DynamoDB table items view. Below shows a list of scanned records. As expected, it has the order_id, ordered_at and other attributes.
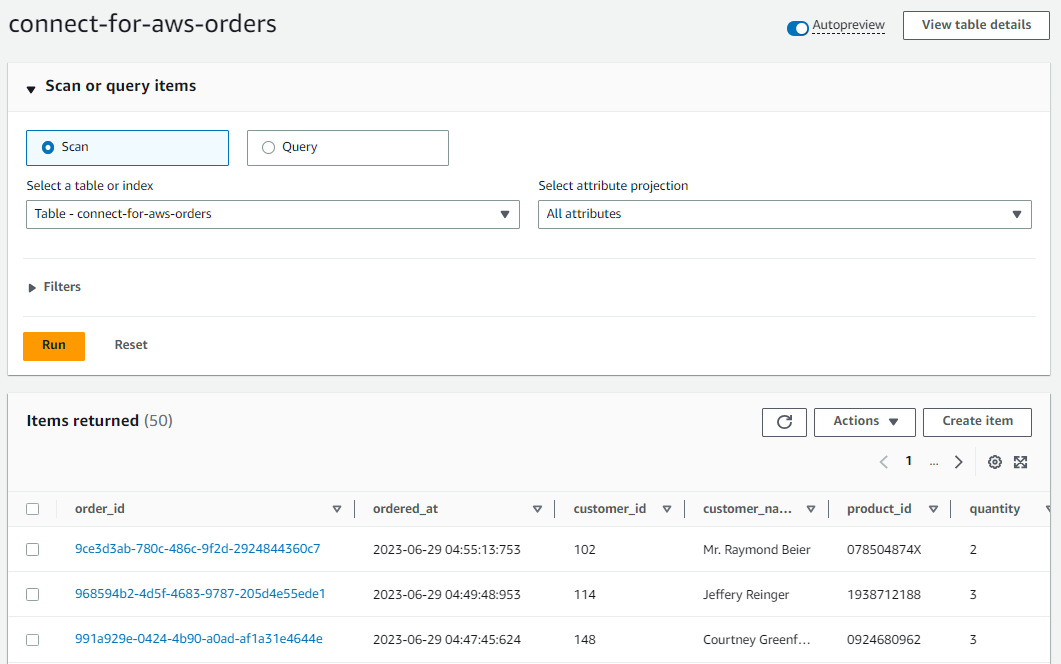
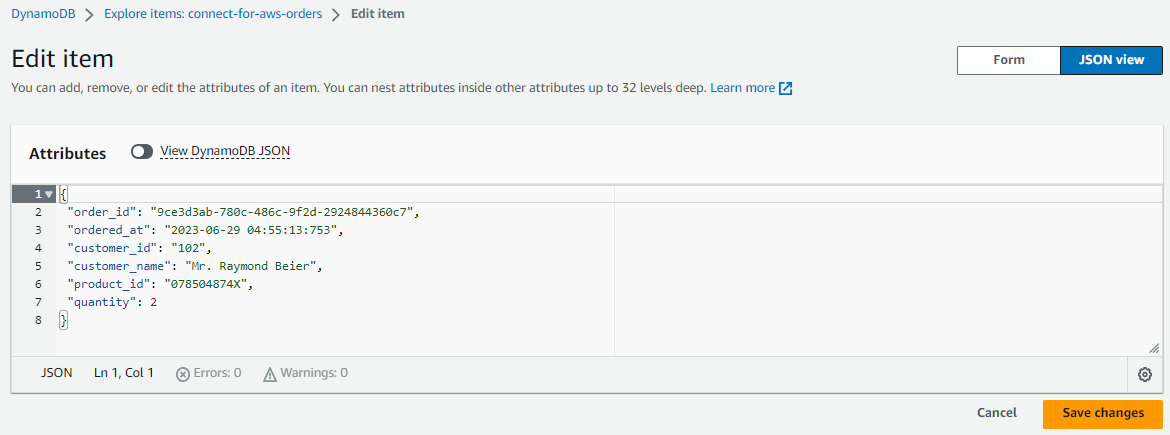
We can also obtain an individual Json record by clicking an order_id value as shown below.
Summary
As part of investigating how to utilize Kafka Connect effectively for AWS services integration, I demonstrated how to develop the Camel DynamoDB sink connector using Docker in Part 2. Fake order data was generated using the MSK Data Generator source connector, and the sink connector was configured to consume the topic messages to ingest them into a DynamoDB table. In this post, I illustrated how to deploy the data ingestion applications using Amazon MSK and MSK Connect.










Comments