
[UPDATE 2025-10-01]
Bitnami’s public Docker images have been moved to the Bitnami Legacy repository. To ensure continued access and compatibility, please update your Docker image references accordingly.
For example:
bitnami/kafka:2.8.1→bitnamilegacy/kafka:2.8.1bitnami/zookeeper:3.7.0→bitnamilegacy/zookeeper:3.7.0bitnami/python:3.9.0→bitnamilegacy/python:3.9.0
Apache Flink is an open-source, unified stream-processing and batch-processing framework. Its core is a distributed streaming data-flow engine that you can use to run real-time stream processing on high-throughput data sources. Currently, it is widely used to build applications for fraud/anomaly detection, rule-based alerting, business process monitoring, and continuous ETL to name a few. On AWS, we can deploy a Flink application via Amazon Kinesis Data Analytics (KDA), Amazon EMR and Amazon EKS. Among those, KDA is the easiest option as it provides the underlying infrastructure for your Apache Flink applications.
There are a number of AWS workshops and blog posts where we can learn Flink development on AWS and one of those is AWS Kafka and DynamoDB for real time fraud detection. While this workshop targets a Flink application on KDA, it would have been easier if it illustrated local development before moving into deployment via KDA. In this series of posts, we will re-implement the fraud detection application of the workshop for those who are new to Flink and KDA. Specifically the app will be developed locally using Docker in part 1, and it will be deployed via KDA in part 2.
[Update 2023-08-30] Amazon Kinesis Data Analytics is renamed into Amazon Managed Service for Apache Flink. In this post, Kinesis Data Analytics (KDA) and Amazon Managed Service for Apache Flink will be used interchangeably.
Architecture
There are two Python applications that send transaction and flagged account records into the corresponding topics - the transaction app sends records indefinitely in a loop. Both the topics are consumed by a Flink application, and it filters the transactions from the flagged accounts followed by sending them into an output topic of flagged transactions. Finally, the flagged transaction records are sent into a DynamoDB table by the Camel DynamoDB sink connector in order to serve real-time requests from an API.
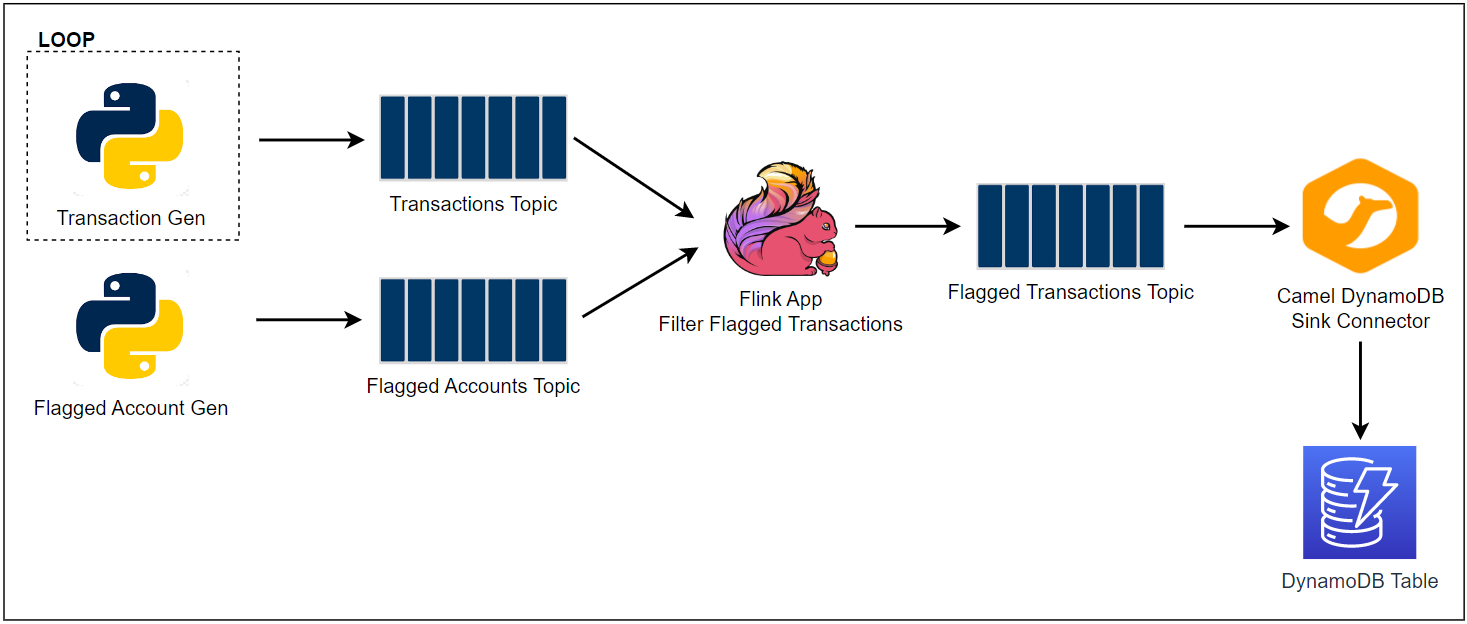
Infrastructure
The Kafka cluster, Kafka connect and management app (kpow) are created using Docker while the python apps including the Flink app run in a virtual environment. The source can be found in the GitHub repository of this post.
Preparation
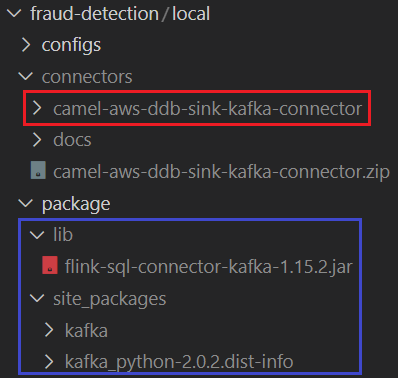
As discussed later, the Flink application needs the Kafka connector artifact (flink-sql-connector-kafka-1.15.2.jar) in order to connect a Kafka cluster. Also, the source of the Camel DynamoDB sink connector should be available in the Kafka connect service. They can be downloaded by executing the following script.
1# build.sh
2#!/usr/bin/env bash
3PKG_ALL="${PKG_ALL:-no}"
4
5SCRIPT_DIR="$(cd $(dirname "$0"); pwd)"
6
7#### Steps to package the flink app
8SRC_PATH=$SCRIPT_DIR/package
9rm -rf $SRC_PATH && mkdir -p $SRC_PATH/lib
10
11## Download flink sql connector kafka
12echo "download flink sql connector kafka..."
13VERSION=1.15.2
14FILE_NAME=flink-sql-connector-kafka-$VERSION
15FLINK_SRC_DOWNLOAD_URL=https://repo.maven.apache.org/maven2/org/apache/flink/flink-sql-connector-kafka/$VERSION/flink-sql-connector-kafka-$VERSION.jar
16curl -L -o $SRC_PATH/lib/$FILE_NAME.jar ${FLINK_SRC_DOWNLOAD_URL}
17
18## Install pip packages
19echo "install and zip pip packages..."
20pip3 install -r requirements.txt --target $SRC_PATH/site_packages
21
22if [ $PKG_ALL == "yes" ]; then
23 ## Package pyflink app
24 echo "package pyflink app"
25 zip -r kda-package.zip processor.py package/lib package/site_packages
26fi
27
28#### Steps to create the sink connector
29CONN_PATH=$SCRIPT_DIR/connectors
30rm -rf $CONN_PATH && mkdir $CONN_PATH
31
32## Download camel dynamodb sink connector
33echo "download camel dynamodb sink connector..."
34CONNECTOR_SRC_DOWNLOAD_URL=https://repo.maven.apache.org/maven2/org/apache/camel/kafkaconnector/camel-aws-ddb-sink-kafka-connector/3.20.3/camel-aws-ddb-sink-kafka-connector-3.20.3-package.tar.gz
35
36## decompress and zip contents to create custom plugin of msk connect later
37curl -o $CONN_PATH/camel-aws-ddb-sink-kafka-connector.tar.gz $CONNECTOR_SRC_DOWNLOAD_URL \
38 && tar -xvzf $CONN_PATH/camel-aws-ddb-sink-kafka-connector.tar.gz -C $CONN_PATH \
39 && cd $CONN_PATH/camel-aws-ddb-sink-kafka-connector \
40 && zip -r camel-aws-ddb-sink-kafka-connector.zip . \
41 && mv camel-aws-ddb-sink-kafka-connector.zip $CONN_PATH \
42 && rm $CONN_PATH/camel-aws-ddb-sink-kafka-connector.tar.gz
Once downloaded, they can be found in the corresponding folders as shown below. Although the Flink app doesn’t need the kafka-python package, it is included in the site_packages folder in order to check if --pyFiles option works in KDA - it’ll be checked in part 2.
Kafka and Related Services
A Kafka cluster with a single broker and zookeeper node is used in this post. The broker has two listeners and the port 9092 and 29092 are used for internal and external communication respectively. The default number of topic partitions is set to 2. Details about Kafka cluster setup can be found in this post.
A Kafka Connect service is configured to run in a distributed mode. The connect properties file and the source of the Camel DynamoDB sink connector are volume-mapped. Also AWS credentials are added to environment variables as it needs permission to put items into a DynamoDB table. Details about Kafka connect setup can be found in this post.
Finally, the Kpow CE is used for ease of monitoring Kafka topics and related resources. The bootstrap server address and connect REST URL are added as environment variables. See this post for details about Kafka management apps.
1# docker-compose.yml
2version: "3.5"
3
4services:
5 zookeeper:
6 image: bitnami/zookeeper:3.5
7 container_name: zookeeper
8 ports:
9 - "2181"
10 networks:
11 - kafkanet
12 environment:
13 - ALLOW_ANONYMOUS_LOGIN=yes
14 volumes:
15 - zookeeper_data:/bitnami/zookeeper
16 kafka-0:
17 image: bitnami/kafka:2.8.1
18 container_name: kafka-0
19 expose:
20 - 9092
21 ports:
22 - "29092:29092"
23 networks:
24 - kafkanet
25 environment:
26 - ALLOW_PLAINTEXT_LISTENER=yes
27 - KAFKA_CFG_ZOOKEEPER_CONNECT=zookeeper:2181
28 - KAFKA_CFG_BROKER_ID=0
29 - KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=INTERNAL:PLAINTEXT,EXTERNAL:PLAINTEXT
30 - KAFKA_CFG_LISTENERS=INTERNAL://:9092,EXTERNAL://:29092
31 - KAFKA_CFG_ADVERTISED_LISTENERS=INTERNAL://kafka-0:9092,EXTERNAL://localhost:29092
32 - KAFKA_CFG_INTER_BROKER_LISTENER_NAME=INTERNAL
33 - KAFKA_CFG_NUM_PARTITIONS=2
34 volumes:
35 - kafka_0_data:/bitnami/kafka
36 depends_on:
37 - zookeeper
38 kafka-connect:
39 image: bitnami/kafka:2.8.1
40 container_name: connect
41 command: >
42 /opt/bitnami/kafka/bin/connect-distributed.sh
43 /opt/bitnami/kafka/config/connect-distributed.properties
44 ports:
45 - "8083:8083"
46 networks:
47 - kafkanet
48 environment:
49 AWS_ACCESS_KEY_ID: $AWS_ACCESS_KEY_ID
50 AWS_SECRET_ACCESS_KEY: $AWS_SECRET_ACCESS_KEY
51 AWS_SESSION_TOKEN: $AWS_SESSION_TOKEN
52 volumes:
53 - "./configs/connect-distributed.properties:/opt/bitnami/kafka/config/connect-distributed.properties"
54 - "./connectors/camel-aws-ddb-sink-kafka-connector:/opt/connectors/camel-aws-ddb-sink-kafka-connector"
55 depends_on:
56 - zookeeper
57 - kafka-0
58 kpow:
59 image: factorhouse/kpow-ce:91.2.1
60 container_name: kpow
61 ports:
62 - "3000:3000"
63 networks:
64 - kafkanet
65 environment:
66 BOOTSTRAP: kafka-0:9092
67 CONNECT_REST_URL: http://kafka-connect:8083
68 depends_on:
69 - zookeeper
70 - kafka-0
71 - kafka-connect
72
73networks:
74 kafkanet:
75 name: kafka-network
76
77volumes:
78 zookeeper_data:
79 driver: local
80 name: zookeeper_data
81 kafka_0_data:
82 driver: local
83 name: kafka_0_data
DynamoDB Table
The destination table is named flagged-transactions, and it has the primary key where transaction_id and transaction_date are the hash and range key respectively. It also has a global secondary index (GSI) where account_id and transaction_date constitute the primary key. The purpose of the GSI is for ease of querying transactions by account ID. The table can be created using the AWS CLI as shown below.
1aws dynamodb create-table \
2 --cli-input-json file://configs/ddb.json
1// configs/ddb.json
2{
3 "TableName": "flagged-transactions",
4 "KeySchema": [
5 { "AttributeName": "transaction_id", "KeyType": "HASH" },
6 { "AttributeName": "transaction_date", "KeyType": "RANGE" }
7 ],
8 "AttributeDefinitions": [
9 { "AttributeName": "transaction_id", "AttributeType": "S" },
10 { "AttributeName": "account_id", "AttributeType": "N" },
11 { "AttributeName": "transaction_date", "AttributeType": "S" }
12 ],
13 "ProvisionedThroughput": {
14 "ReadCapacityUnits": 2,
15 "WriteCapacityUnits": 2
16 },
17 "GlobalSecondaryIndexes": [
18 {
19 "IndexName": "account",
20 "KeySchema": [
21 { "AttributeName": "account_id", "KeyType": "HASH" },
22 { "AttributeName": "transaction_date", "KeyType": "RANGE" }
23 ],
24 "Projection": { "ProjectionType": "ALL" },
25 "ProvisionedThroughput": {
26 "ReadCapacityUnits": 2,
27 "WriteCapacityUnits": 2
28 }
29 }
30 ]
31}
Virtual Environment
As mentioned earlier, all Python apps run in a virtual environment, and we need the following pip packages. We use the version 1.15.2 of the apache-flink package because it is the latest supported version by KDA. We also need the kafka-python package for source data generation. The pip packages can be installed by pip install -r requirements-dev.txt.
1# requirements.txt
2kafka-python==2.0.2
3
4# requirements-dev.txt
5-r requirements.txt
6apache-flink==1.15.2
7black==19.10b0
8pytest
9pytest-cov
Application
Source Data
A single Python script is created for the transaction and flagged account apps. They generate and send source data into Kafka topics. Each of the classes for the flagged account and transaction has the asdict, auto and create methods. The create method generates a list of records where each element is instantiated by the auto method. Those records are sent into the relevant Kafka topic after being converted into a dictionary by the asdict method.
A Kafka producer is created as an attribute of the Producer class. The source records are sent into the relevant topic by the send method. Note that both the key and value of the messages are serialized as json.
Whether to send flagged account or transaction records is determined by an environment variable called DATA_TYPE. We can run those apps as shown below.
- flagged account -
DATE_TYPE=account python producer.py - transaction -
DATE_TYPE=transaction python producer.py
1# producer.py
2import os
3import datetime
4import time
5import json
6import typing
7import random
8import logging
9import dataclasses
10
11from kafka import KafkaProducer
12
13logging.basicConfig(
14 level=logging.INFO,
15 format="%(asctime)s.%(msecs)03d:%(levelname)s:%(name)s:%(message)s",
16 datefmt="%Y-%m-%d %H:%M:%S",
17)
18
19
20@dataclasses.dataclass
21class FlagAccount:
22 account_id: int
23 flag_date: str
24
25 def asdict(self):
26 return dataclasses.asdict(self)
27
28 @classmethod
29 def auto(cls, account_id: int):
30 flag_date = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S.%f")
31 return cls(account_id, flag_date)
32
33 @staticmethod
34 def create():
35 return [FlagAccount.auto(account_id) for account_id in range(1000000001, 1000000010, 2)]
36
37
38@dataclasses.dataclass
39class Transaction:
40 account_id: int
41 customer_id: str
42 merchant_type: str
43 transaction_id: str
44 transaction_type: str
45 transaction_amount: float
46 transaction_date: str
47
48 def asdict(self):
49 return dataclasses.asdict(self)
50
51 @classmethod
52 def auto(cls):
53 account_id = random.randint(1000000001, 1000000010)
54 customer_id = f"C{str(account_id)[::-1]}"
55 merchant_type = random.choice(["Online", "In Store"])
56 transaction_id = "".join(random.choice("0123456789ABCDEF") for i in range(16))
57 transaction_type = random.choice(
58 [
59 "Grocery_Store",
60 "Gas_Station",
61 "Shopping_Mall",
62 "City_Services",
63 "HealthCare_Service",
64 "Food and Beverage",
65 "Others",
66 ]
67 )
68 transaction_amount = round(random.randint(100, 10000) * random.random(), 2)
69 transaction_date = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S.%f")
70 return cls(
71 account_id,
72 customer_id,
73 merchant_type,
74 transaction_id,
75 transaction_type,
76 transaction_amount,
77 transaction_date,
78 )
79
80 @staticmethod
81 def create(num: int):
82 return [Transaction.auto() for _ in range(num)]
83
84
85class Producer:
86 def __init__(self, bootstrap_servers: list, account_topic: str, transaction_topic: str):
87 self.bootstrap_servers = bootstrap_servers
88 self.account_topic = account_topic
89 self.transaction_topic = transaction_topic
90 self.producer = self.create()
91
92 def create(self):
93 return KafkaProducer(
94 bootstrap_servers=self.bootstrap_servers,
95 key_serializer=lambda v: json.dumps(v, default=self.serialize).encode("utf-8"),
96 value_serializer=lambda v: json.dumps(v, default=self.serialize).encode("utf-8"),
97 api_version=(2, 8, 1),
98 )
99
100 def send(self, records: typing.Union[typing.List[FlagAccount], typing.List[Transaction]]):
101 for record in records:
102 try:
103 key = {"account_id": record.account_id}
104 topic = self.account_topic
105 if hasattr(record, "transaction_id"):
106 key["transaction_id"] = record.transaction_id
107 topic = self.transaction_topic
108 self.producer.send(topic=topic, key=key, value=record.asdict())
109 except Exception as e:
110 raise RuntimeError("fails to send a message") from e
111 self.producer.flush()
112
113 def serialize(self, obj):
114 if isinstance(obj, datetime.datetime):
115 return obj.isoformat()
116 if isinstance(obj, datetime.date):
117 return str(obj)
118 return obj
119
120
121if __name__ == "__main__":
122 producer = Producer(
123 bootstrap_servers=os.getenv("BOOTSTRAP_SERVERS", "localhost:29092").split(","),
124 account_topic=os.getenv("CUSTOMER_TOPIC_NAME", "flagged-accounts"),
125 transaction_topic=os.getenv("TRANSACTION_TOPIC_NAME", "transactions"),
126 )
127 if os.getenv("DATE_TYPE", "account") == "account":
128 producer.send(FlagAccount.create())
129 producer.producer.close()
130 else:
131 max_run = int(os.getenv("MAX_RUN", "-1"))
132 logging.info(f"max run - {max_run}")
133 current_run = 0
134 while True:
135 current_run += 1
136 logging.info(f"current run - {current_run}")
137 if current_run - max_run == 0:
138 logging.info(f"reached max run, finish")
139 producer.producer.close()
140 break
141 producer.send(Transaction.create(5))
142 secs = random.randint(2, 5)
143 logging.info(f"messages sent... wait {secs} seconds")
144 time.sleep(secs)
Once we start the apps, we can check the topics for the source data are created and messages are ingested in Kpow.
Output Data
The Flink application is built using the Table API. We have two Kafka source topics and one output topic. Simply put, we can query the records of the topics as tables of unbounded real-time streams with the Table API. In order to read/write records from/to a Kafka topic, we need to specify the Kafka connector artifact that we downloaded earlier as the pipeline jar. Note we only need to configure the connector jar when we develop the app locally as the jar file will be specified by the --jarfile option for KDA. We also need the application properties file (application_properties.json) in order to be comparable with KDA. The file contains the Flink runtime options in KDA as well as application specific properties. All the properties should be specified when deploying via KDA and, for local development, we keep them as a json file and only the application specific properties are used.
The tables for the source and output topics can be created using SQL with options that are related to the Kafka connector. Key options cover the connector name (connector), topic name (topic), bootstrap server address (properties.bootstrap.servers) and format (format). See the connector document for more details about the connector configuration. When it comes to inserting flagged transaction records into the output topic, we use a function written in SQL as well - insert_into_stmt.
In the main method, we create all the source and sink tables after mapping relevant application properties. Then the output records are inserted into the output Kafka topic. Note that the output records are printed in the terminal additionally when the app is running locally for ease of checking them. We can run the app as following - RUNTIME_ENV=LOCAL python processor.py
1# processor.py
2import os
3import json
4import logging
5
6import kafka # check if --pyFiles works
7from pyflink.table import EnvironmentSettings, TableEnvironment
8
9logging.basicConfig(
10 level=logging.INFO,
11 format="%(asctime)s.%(msecs)03d:%(levelname)s:%(name)s:%(message)s",
12 datefmt="%Y-%m-%d %H:%M:%S",
13)
14
15RUNTIME_ENV = os.environ.get("RUNTIME_ENV", "KDA") # KDA, LOCAL
16logging.info(f"runtime environment - {RUNTIME_ENV}...")
17
18env_settings = EnvironmentSettings.in_streaming_mode()
19table_env = TableEnvironment.create(env_settings)
20
21APPLICATION_PROPERTIES_FILE_PATH = (
22 "/etc/flink/application_properties.json" # on kda or docker-compose
23 if RUNTIME_ENV != "LOCAL"
24 else "application_properties.json"
25)
26
27if RUNTIME_ENV != "KDA":
28 # on non-KDA, multiple jar files can be passed after being delimited by a semicolon
29 CURRENT_DIR = os.path.dirname(os.path.realpath(__file__))
30 PIPELINE_JAR = "flink-sql-connector-kafka-1.15.2.jar"
31 table_env.get_config().set(
32 "pipeline.jars", f"file://{os.path.join(CURRENT_DIR, 'package', 'lib', PIPELINE_JAR)}"
33 )
34logging.info(f"app properties file path - {APPLICATION_PROPERTIES_FILE_PATH}")
35
36def get_application_properties():
37 if os.path.isfile(APPLICATION_PROPERTIES_FILE_PATH):
38 with open(APPLICATION_PROPERTIES_FILE_PATH, "r") as file:
39 contents = file.read()
40 properties = json.loads(contents)
41 return properties
42 else:
43 raise RuntimeError(f"A file at '{APPLICATION_PROPERTIES_FILE_PATH}' was not found")
44
45def property_map(props: dict, property_group_id: str):
46 for prop in props:
47 if prop["PropertyGroupId"] == property_group_id:
48 return prop["PropertyMap"]
49
50def create_flagged_account_source_table(
51 table_name: str, topic_name: str, bootstrap_servers: str, startup_mode: str
52):
53 stmt = f"""
54 CREATE TABLE {table_name} (
55 account_id BIGINT,
56 flag_date TIMESTAMP(3)
57 )
58 WITH (
59 'connector' = 'kafka',
60 'topic' = '{topic_name}',
61 'properties.bootstrap.servers' = '{bootstrap_servers}',
62 'properties.group.id' = 'flagged-account-source-group',
63 'format' = 'json',
64 'scan.startup.mode' = '{startup_mode}'
65 )
66 """
67 logging.info("flagged account source table statement...")
68 logging.info(stmt)
69 return stmt
70
71def create_transaction_source_table(
72 table_name: str, topic_name: str, bootstrap_servers: str, startup_mode: str
73):
74 stmt = f"""
75 CREATE TABLE {table_name} (
76 account_id BIGINT,
77 customer_id VARCHAR(15),
78 merchant_type VARCHAR(8),
79 transaction_id VARCHAR(16),
80 transaction_type VARCHAR(20),
81 transaction_amount DECIMAL(10,2),
82 transaction_date TIMESTAMP(3)
83 )
84 WITH (
85 'connector' = 'kafka',
86 'topic' = '{topic_name}',
87 'properties.bootstrap.servers' = '{bootstrap_servers}',
88 'properties.group.id' = 'transaction-source-group',
89 'format' = 'json',
90 'scan.startup.mode' = '{startup_mode}'
91 )
92 """
93 logging.info("transaction source table statement...")
94 logging.info(stmt)
95 return stmt
96
97def create_flagged_transaction_sink_table(table_name: str, topic_name: str, bootstrap_servers: str):
98 stmt = f"""
99 CREATE TABLE {table_name} (
100 account_id BIGINT,
101 customer_id VARCHAR(15),
102 merchant_type VARCHAR(8),
103 transaction_id VARCHAR(16),
104 transaction_type VARCHAR(20),
105 transaction_amount DECIMAL(10,2),
106 transaction_date TIMESTAMP(3)
107 )
108 WITH (
109 'connector' = 'kafka',
110 'topic' = '{topic_name}',
111 'properties.bootstrap.servers' = '{bootstrap_servers}',
112 'format' = 'json',
113 'key.format' = 'json',
114 'key.fields' = 'account_id;transaction_id',
115 'properties.allow.auto.create.topics' = 'true'
116 )
117 """
118 logging.info("transaction sink table statement...")
119 logging.info(stmt)
120 return stmt
121
122def create_print_table(table_name: str):
123 return f"""
124 CREATE TABLE {table_name} (
125 account_id BIGINT,
126 customer_id VARCHAR(15),
127 merchant_type VARCHAR(8),
128 transaction_id VARCHAR(16),
129 transaction_type VARCHAR(20),
130 transaction_amount DECIMAL(10,2),
131 transaction_date TIMESTAMP(3)
132 )
133 WITH (
134 'connector' = 'print'
135 )
136 """
137
138def insert_into_stmt(insert_from_tbl: str, compare_with_tbl: str, insert_into_tbl: str):
139 return f"""
140 INSERT INTO {insert_into_tbl}
141 SELECT l.*
142 FROM {insert_from_tbl} AS l
143 JOIN {compare_with_tbl} AS r
144 ON l.account_id = r.account_id
145 AND l.transaction_date > r.flag_date
146 """
147
148def main():
149 ## map consumer/producer properties
150 props = get_application_properties()
151 # consumer for flagged account
152 consumer_0_property_group_key = "consumer.config.0"
153 consumer_0_properties = property_map(props, consumer_0_property_group_key)
154 consumer_0_table_name = consumer_0_properties["table.name"]
155 consumer_0_topic_name = consumer_0_properties["topic.name"]
156 consumer_0_bootstrap_servers = consumer_0_properties["bootstrap.servers"]
157 consumer_0_startup_mode = consumer_0_properties["startup.mode"]
158 # consumer for transactions
159 consumer_1_property_group_key = "consumer.config.1"
160 consumer_1_properties = property_map(props, consumer_1_property_group_key)
161 consumer_1_table_name = consumer_1_properties["table.name"]
162 consumer_1_topic_name = consumer_1_properties["topic.name"]
163 consumer_1_bootstrap_servers = consumer_1_properties["bootstrap.servers"]
164 consumer_1_startup_mode = consumer_1_properties["startup.mode"]
165 # producer
166 producer_0_property_group_key = "producer.config.0"
167 producer_0_properties = property_map(props, producer_0_property_group_key)
168 producer_0_table_name = producer_0_properties["table.name"]
169 producer_0_topic_name = producer_0_properties["topic.name"]
170 producer_0_bootstrap_servers = producer_0_properties["bootstrap.servers"]
171 # print
172 print_table_name = "sink_print"
173 ## create the source table for flagged accounts
174 table_env.execute_sql(
175 create_flagged_account_source_table(
176 consumer_0_table_name,
177 consumer_0_topic_name,
178 consumer_0_bootstrap_servers,
179 consumer_0_startup_mode,
180 )
181 )
182 table_env.from_path(consumer_0_table_name).print_schema()
183 ## create the source table for transactions
184 table_env.execute_sql(
185 create_transaction_source_table(
186 consumer_1_table_name,
187 consumer_1_topic_name,
188 consumer_1_bootstrap_servers,
189 consumer_1_startup_mode,
190 )
191 )
192 table_env.from_path(consumer_1_table_name).print_schema()
193 ## create sink table for flagged accounts
194 table_env.execute_sql(
195 create_flagged_transaction_sink_table(
196 producer_0_table_name, producer_0_topic_name, producer_0_bootstrap_servers
197 )
198 )
199 table_env.from_path(producer_0_table_name).print_schema()
200 table_env.execute_sql(create_print_table("sink_print"))
201 ## insert into sink tables
202 if RUNTIME_ENV == "LOCAL":
203 statement_set = table_env.create_statement_set()
204 statement_set.add_insert_sql(
205 insert_into_stmt(consumer_1_table_name, consumer_0_table_name, producer_0_table_name)
206 )
207 statement_set.add_insert_sql(
208 insert_into_stmt(consumer_1_table_name, consumer_0_table_name, print_table_name)
209 )
210 statement_set.execute().wait()
211 else:
212 table_result = table_env.execute_sql(
213 insert_into_stmt(consumer_1_table_name, consumer_0_table_name, producer_0_table_name)
214 )
215 logging.info(table_result.get_job_client().get_job_status())
216
217
218if __name__ == "__main__":
219 main()
1// application_properties.json
2[
3 {
4 "PropertyGroupId": "kinesis.analytics.flink.run.options",
5 "PropertyMap": {
6 "python": "processor.py",
7 "jarfile": "package/lib/flink-sql-connector-kinesis-1.15.2.jar",
8 "pyFiles": "package/site_packages/"
9 }
10 },
11 {
12 "PropertyGroupId": "consumer.config.0",
13 "PropertyMap": {
14 "table.name": "flagged_accounts",
15 "topic.name": "flagged-accounts",
16 "bootstrap.servers": "localhost:29092",
17 "startup.mode": "earliest-offset"
18 }
19 },
20 {
21 "PropertyGroupId": "consumer.config.1",
22 "PropertyMap": {
23 "table.name": "transactions",
24 "topic.name": "transactions",
25 "bootstrap.servers": "localhost:29092",
26 "startup.mode": "earliest-offset"
27 }
28 },
29 {
30 "PropertyGroupId": "producer.config.0",
31 "PropertyMap": {
32 "table.name": "flagged_transactions",
33 "topic.name": "flagged-transactions",
34 "bootstrap.servers": "localhost:29092"
35 }
36 }
37]
The terminal on the right-hand side shows the output records of the Flink app while the left-hand side records logs of the transaction app. We see that the account IDs end with all odd numbers, which matches transactions from flagged accounts.
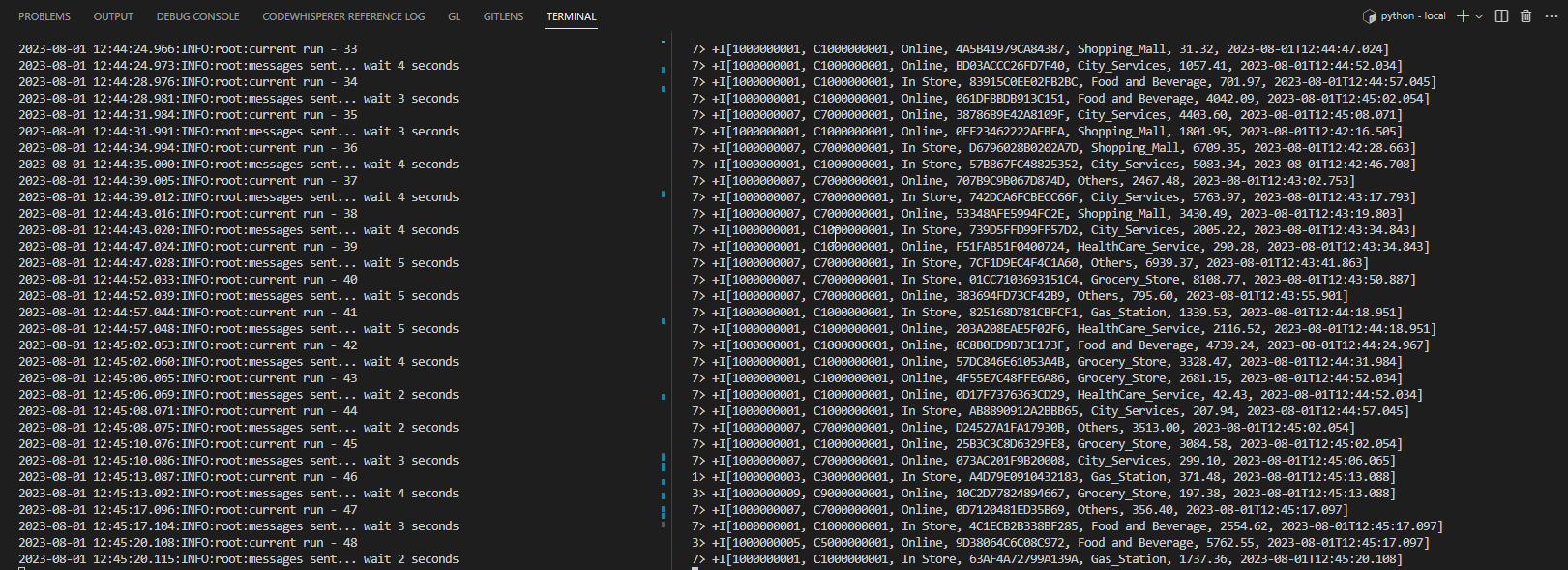
We can also see details of all the topics in Kpow as shown below.
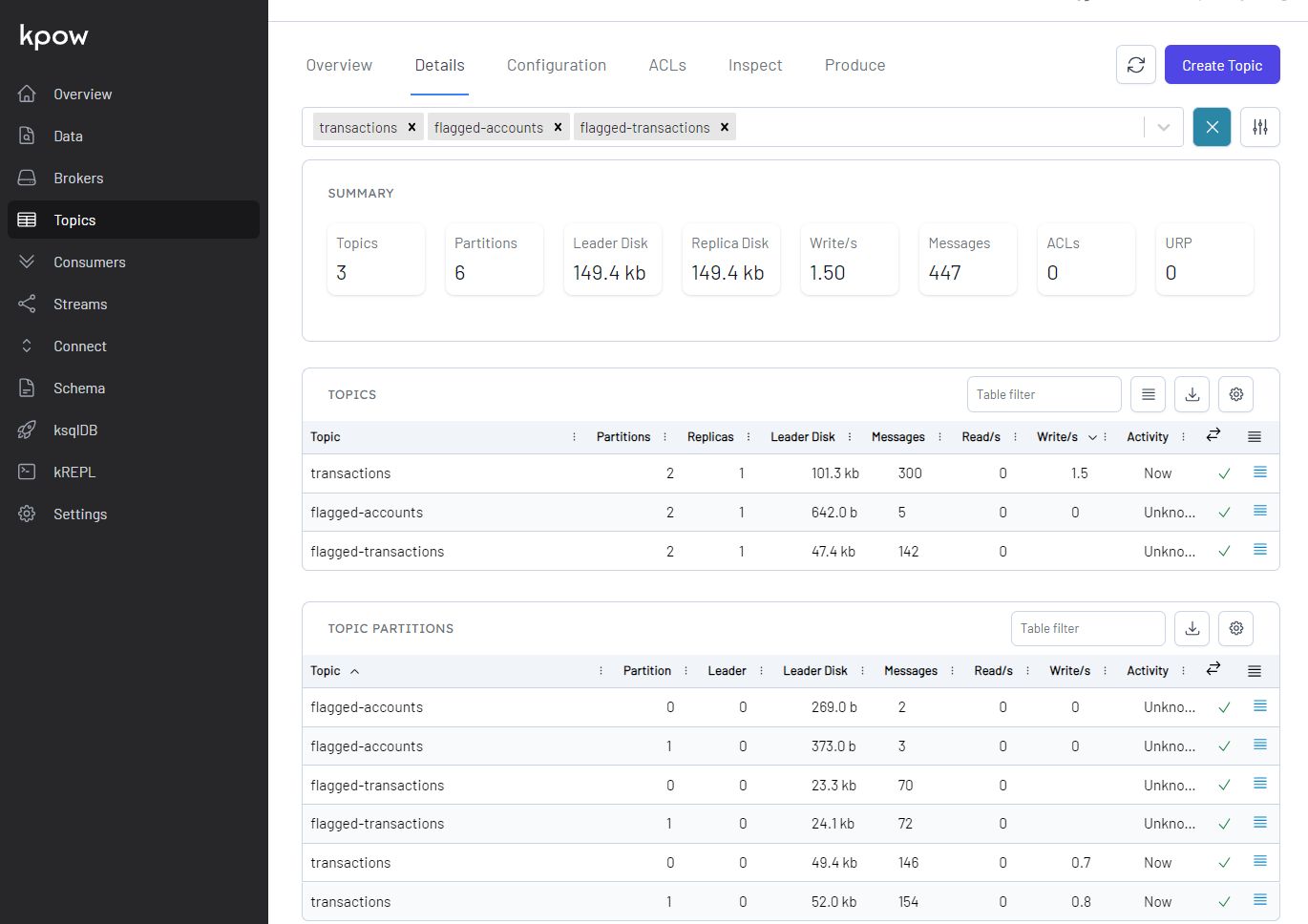
Sink Output Data
Kafka Connect provides a REST API that manages connectors, and we can create a connector programmatically using it. The REST endpoint requires a JSON payload that includes connector configurations.
1$ curl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" \
2 http://localhost:8083/connectors/ -d @configs/sink.json
The connector is configured to write messages from the flagged-transactions topic into the DynamoDB table created earlier. It requires to specify the table name, AWS region, operation, write capacity and whether to use the default credential provider - see the documentation for details. Note that, if you don’t use the default credential provider, you have to specify the access key id and secret access key. Note further that, although the current LTS version is v3.18.2, the default credential provider option didn’t work for me, and I was recommended to use v3.20.3 instead. Finally, the camel.sink.unmarshal option is to convert data from the internal java.util.HashMap type into the required java.io.InputStream type. Without this configuration, the connector fails with org.apache.camel.NoTypeConversionAvailableException error.
1// configs/sink.json
2{
3 "name": "transactions-sink",
4 "config": {
5 "connector.class": "org.apache.camel.kafkaconnector.awsddbsink.CamelAwsddbsinkSinkConnector",
6 "tasks.max": "2",
7 "key.converter": "org.apache.kafka.connect.json.JsonConverter",
8 "key.converter.schemas.enable": false,
9 "value.converter": "org.apache.kafka.connect.json.JsonConverter",
10 "value.converter.schemas.enable": false,
11 "topics": "flagged-transactions",
12
13 "camel.kamelet.aws-ddb-sink.table": "flagged-transactions",
14 "camel.kamelet.aws-ddb-sink.region": "ap-southeast-2",
15 "camel.kamelet.aws-ddb-sink.operation": "PutItem",
16 "camel.kamelet.aws-ddb-sink.writeCapacity": 1,
17 "camel.kamelet.aws-ddb-sink.useDefaultCredentialsProvider": true,
18 "camel.sink.unmarshal": "jackson"
19 }
20}
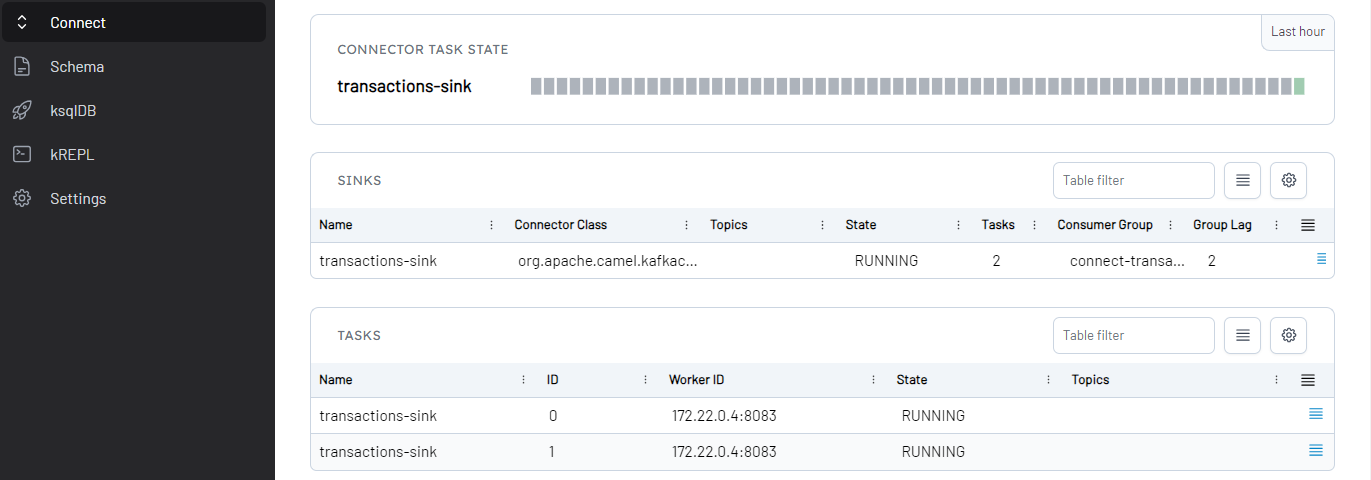
Below shows the sink connector details on Kpow.
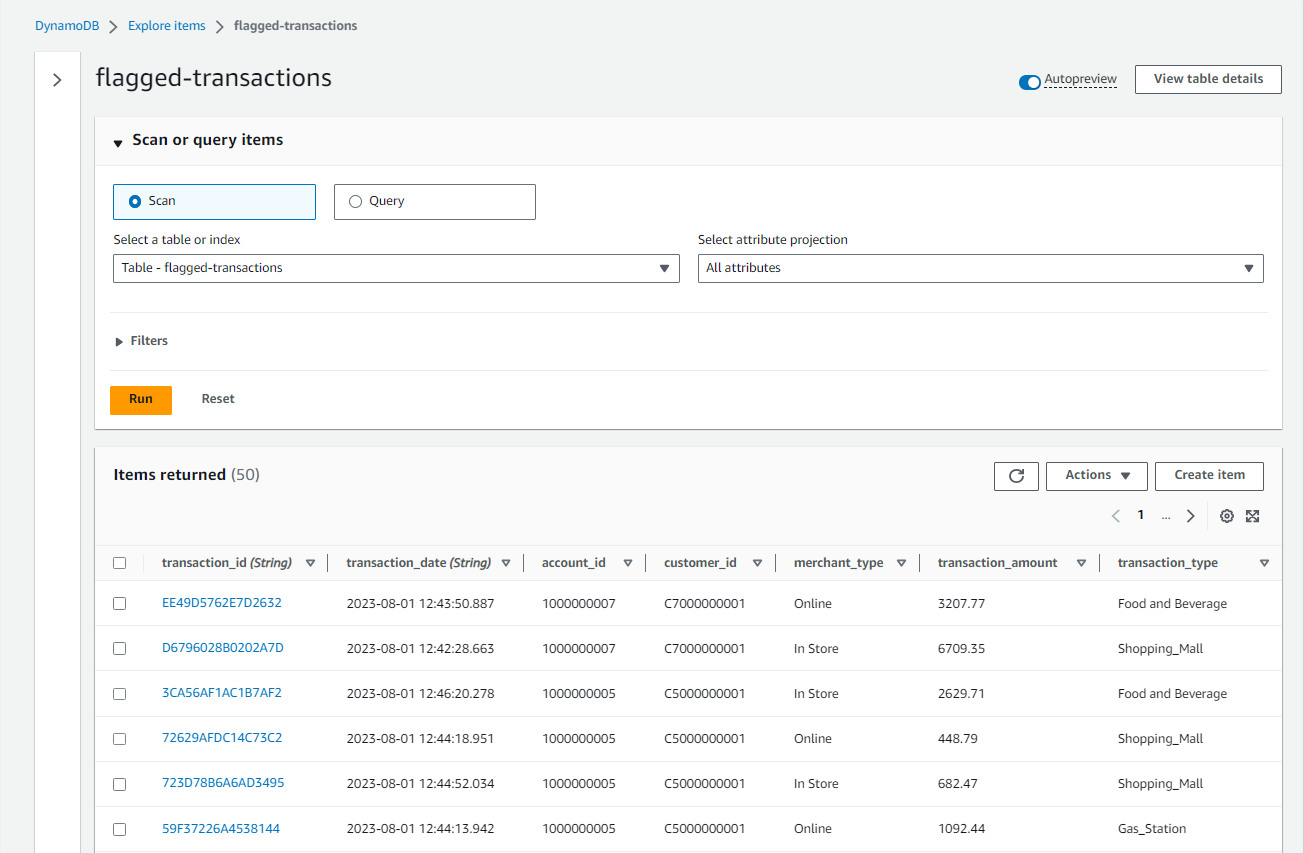
We can check the ingested records on the DynamoDB table items view. Below shows a list of scanned records.
Summary
Apache Flink is widely used for building real-time stream processing applications. On AWS, Kinesis Data Analytics (KDA) is the easiest option to develop a Flink app as it provides the underlying infrastructure. Re-implementing a solution from an AWS workshop, this series of posts discuss how to develop and deploy a fraud detection app using Kafka, Flink and DynamoDB. In this post, we covered local development using Docker, and deployment via KDA will be discussed in part 2.










Comments