
In this series of posts, we discuss a Flink (Pyflink) application that reads/writes from/to Kafka topics. In the previous posts, I demonstrated a Pyflink app that targets a local Kafka cluster as well as a Kafka cluster on Amazon MSK. The app was executed in a virtual environment as well as in a local Flink cluster for improved monitoring. In this post, the app will be deployed via Amazon Managed Service for Apache Flink, which is the easiest option to run Flink applications on AWS.
- Part 1 Local Flink and Local Kafka
- Part 2 Local Flink and MSK
- Part 3 AWS Managed Flink and MSK (this post)
[Update 2023-08-30] Amazon Kinesis Data Analytics is renamed into Amazon Managed Service for Apache Flink. In this post, Kinesis Data Analytics (KDA) and Amazon Managed Service for Apache Flink will be used interchangeably.
Architecture
The Python source data generator sends random stock price records into a Kafka topic. The messages in the source topic are consumed by a Flink application, and it just writes those messages into a different sink topic. As the Kafka cluster is deployed in private subnets, a VPN server is used to generate records from the developer machine. This is the simplest application of the Pyflink getting started guide from AWS, and you may try other examples if interested.
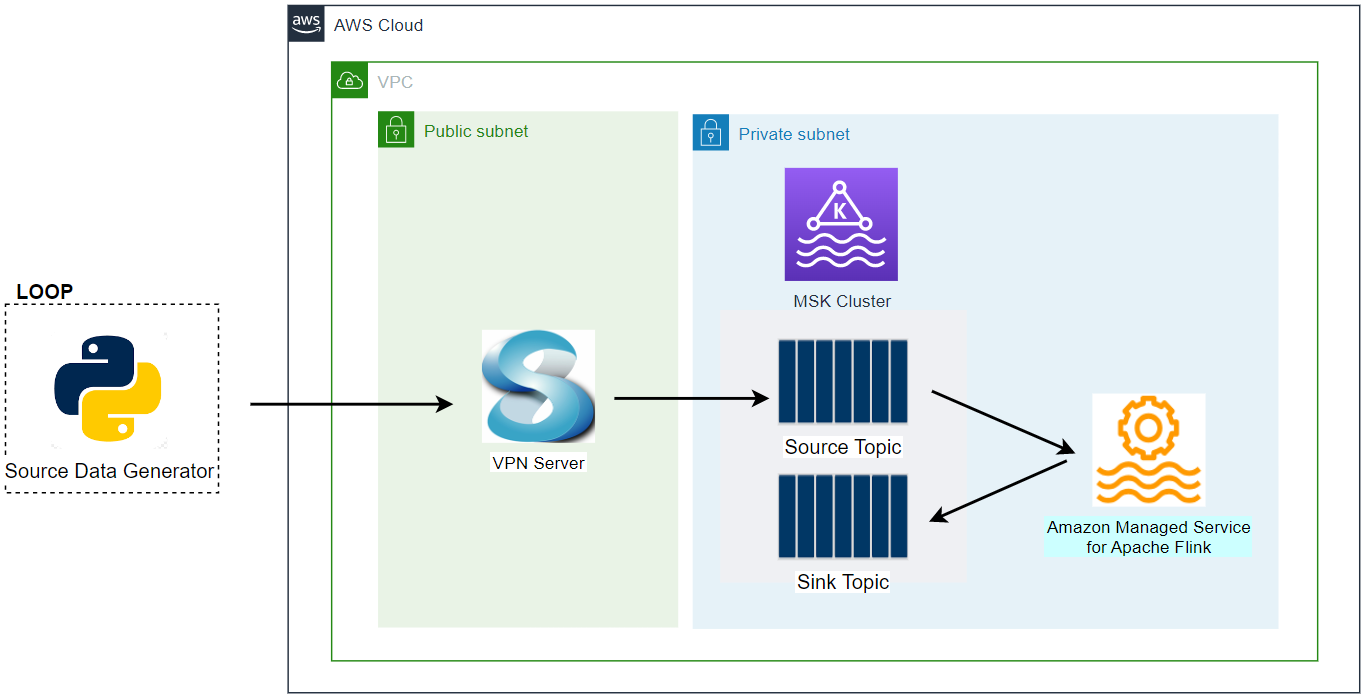
Infrastructure
A Kafka cluster is created on Amazon MSK using Terraform, and the cluster is secured by IAM access control. Unlike the previous posts, the Pyflink app is deployed via Kinesis Data Analytics (KDA). The source can be found in the GitHub repository of this post.
Preparation
Application Package
As discussed in part 2, the app has multiple jar dependencies, and they have to be combined into a single Uber jar file. This is because KDA does not allow you to specify multiple pipeline jar files. The details about how to create the custom jar file can be found in part 2.
The following script (build.sh) builds to create the Uber Jar file for this post, followed by downloading the kafka-python package and creating a zip file that can be used to deploy the Flink app via KDA. Although the Flink app does not need the kafka-python package, it is added in order to check if --pyFiles option works when deploying the app via KDA. The zip package file will be used for KDA deployment in this post.
1# build.sh
2#!/usr/bin/env bash
3SCRIPT_DIR="$(cd $(dirname "$0"); pwd)"
4SRC_PATH=$SCRIPT_DIR/package
5
6# remove contents under $SRC_PATH (except for uber-jar-for-pyflink) and kda-package.zip file
7shopt -s extglob
8rm -rf $SRC_PATH/!(uber-jar-for-pyflink) kda-package.zip
9
10## Generate Uber Jar for PyFlink app for MSK cluster with IAM authN
11echo "generate Uber jar for PyFlink app..."
12mkdir $SRC_PATH/lib
13mvn clean install -f $SRC_PATH/uber-jar-for-pyflink/pom.xml \
14 && mv $SRC_PATH/uber-jar-for-pyflink/target/pyflink-getting-started-1.0.0.jar $SRC_PATH/lib \
15 && rm -rf $SRC_PATH/uber-jar-for-pyflink/target
16
17## Install pip packages
18echo "install and zip pip packages..."
19pip install -r requirements.txt --target $SRC_PATH/site_packages
20
21## Package pyflink app
22echo "package pyflink app"
23zip -r kda-package.zip processor.py package/lib package/site_packages
Once completed, we can check the following contents are included in the application package file.
- Flink application - processor.py
- Pipeline jar file - package/lib/pyflink-getting-started-1.0.0.jar
- kafka-python package - package/site_packages/kafka
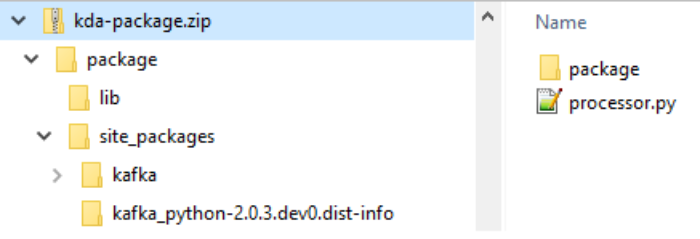
Kafka Management App
The Kpow CE is used for ease of monitoring Kafka topics and related resources. The bootstrap server address, security configuration for IAM authentication and AWS credentials are added as environment variables. See this post for details about Kafka management apps.
1# compose-ui.yml
2version: "3"
3
4services:
5 kpow:
6 image: factorhouse/kpow-ce:91.2.1
7 container_name: kpow
8 ports:
9 - "3000:3000"
10 networks:
11 - appnet
12 environment:
13 AWS_ACCESS_KEY_ID: $AWS_ACCESS_KEY_ID
14 AWS_SECRET_ACCESS_KEY: $AWS_SECRET_ACCESS_KEY
15 AWS_SESSION_TOKEN: $AWS_SESSION_TOKEN
16 # kafka cluster
17 BOOTSTRAP: $BOOTSTRAP_SERVERS
18 SECURITY_PROTOCOL: SASL_SSL
19 SASL_MECHANISM: AWS_MSK_IAM
20 SASL_CLIENT_CALLBACK_HANDLER_CLASS: software.amazon.msk.auth.iam.IAMClientCallbackHandler
21 SASL_JAAS_CONFIG: software.amazon.msk.auth.iam.IAMLoginModule required;
22
23networks:
24 appnet:
25 name: app-network
VPC and VPN
A VPC with 3 public and private subnets is created using the AWS VPC Terraform module (infra/vpc.tf). Also, a SoftEther VPN server is deployed in order to access the resources in the private subnets from the developer machine (infra/vpn.tf). It is particularly useful to monitor and manage the MSK cluster and Kafka topic locally. The details about how to configure the VPN server can be found in an earlier post.
MSK Cluster
An MSK cluster with 2 brokers is created. The broker nodes are deployed with the kafka.m5.large instance type in private subnets and IAM authentication is used for the client authentication method. Finally, additional server configurations are added such as enabling auto creation of topics and topic deletion. Note that the Flink application needs to have access to the Kafka brokers, and it is allowed by adding an inbound connection from the KDA app into the brokers on port 9098.
1# infra/variable.tf
2locals {
3 ...
4 msk = {
5 version = "2.8.1"
6 instance_size = "kafka.m5.large"
7 ebs_volume_size = 20
8 log_retention_ms = 604800000 # 7 days
9 num_partitions = 2
10 default_replication_factor = 2
11 }
12 ...
13}
14# infra/msk.tf
15resource "aws_msk_cluster" "msk_data_cluster" {
16 cluster_name = "${local.name}-msk-cluster"
17 kafka_version = local.msk.version
18 number_of_broker_nodes = local.msk.number_of_broker_nodes
19 configuration_info {
20 arn = aws_msk_configuration.msk_config.arn
21 revision = aws_msk_configuration.msk_config.latest_revision
22 }
23
24 broker_node_group_info {
25 instance_type = local.msk.instance_size
26 client_subnets = slice(module.vpc.private_subnets, 0, local.msk.number_of_broker_nodes)
27 security_groups = [aws_security_group.msk.id]
28 storage_info {
29 ebs_storage_info {
30 volume_size = local.msk.ebs_volume_size
31 }
32 }
33 }
34
35 client_authentication {
36 sasl {
37 iam = true
38 }
39 }
40
41 logging_info {
42 broker_logs {
43 cloudwatch_logs {
44 enabled = true
45 log_group = aws_cloudwatch_log_group.msk_cluster_lg.name
46 }
47 s3 {
48 enabled = true
49 bucket = aws_s3_bucket.default_bucket.id
50 prefix = "logs/msk/cluster/"
51 }
52 }
53 }
54
55 tags = local.tags
56
57 depends_on = [aws_msk_configuration.msk_config]
58}
59
60resource "aws_msk_configuration" "msk_config" {
61 name = "${local.name}-msk-configuration"
62
63 kafka_versions = [local.msk.version]
64
65 server_properties = <<PROPERTIES
66 auto.create.topics.enable = true
67 delete.topic.enable = true
68 log.retention.ms = ${local.msk.log_retention_ms}
69 num.partitions = ${local.msk.num_partitions}
70 default.replication.factor = ${local.msk.default_replication_factor}
71 PROPERTIES
72}
73
74resource "aws_security_group" "msk" {
75 name = "${local.name}-msk-sg"
76 vpc_id = module.vpc.vpc_id
77
78 lifecycle {
79 create_before_destroy = true
80 }
81
82 tags = local.tags
83}
84
85...
86
87resource "aws_security_group_rule" "msk_kda_inbound" {
88 count = local.kda.to_create ? 1 : 0
89 type = "ingress"
90 description = "Allow KDA access"
91 security_group_id = aws_security_group.msk.id
92 protocol = "tcp"
93 from_port = 9098
94 to_port = 9098
95 source_security_group_id = aws_security_group.kda_sg[0].id
96}
KDA Application
The runtime environment and service execution role are required to create a Flink app. The latest supported Flink version (1.15.2) is specified for the former and an IAM role is created for the latter - it’ll be discussed more in a later section. Furthermore, we need to specify more configurations that are related to the Flink application and CloudWatch logging, and they will be covered below in detail as well.
1# infra/variable.tf
2locals {
3 ...
4 kda = {
5 to_create = true
6 runtime_env = "FLINK-1_15"
7 package_name = "kda-package.zip"
8 }
9 ...
10}
11
12resource "aws_kinesisanalyticsv2_application" "kda_app" {
13 count = local.kda.to_create ? 1 : 0
14
15 name = "${local.name}-kda-app"
16 runtime_environment = local.kda.runtime_env # FLINK-1_15
17 service_execution_role = aws_iam_role.kda_app_role[0].arn
18
19 ...
20}
Application Configuration
In the application configuration section, we can specify details of the application code, VPC, environment properties, and application itself.
Application Code Configuration
The application package (kda-package.zip) is uploaded into the default S3 bucket using the aws_s3_object Terraform resource. Then it can be used as the code content by specifying the bucket and key names.
1# infra/kda.tf
2resource "aws_kinesisanalyticsv2_application" "kda_app" {
3
4 ...
5
6 application_configuration {
7 application_code_configuration {
8 code_content {
9 s3_content_location {
10 bucket_arn = aws_s3_bucket.default_bucket.arn
11 file_key = aws_s3_object.kda_package[0].key
12 }
13 }
14
15 code_content_type = "ZIPFILE"
16 }
17
18 ...
19
20 }
21
22 ...
23
24}
25
26...
27
28resource "aws_s3_object" "kda_package" {
29 count = local.kda.to_create ? 1 : 0
30
31 bucket = aws_s3_bucket.default_bucket.id
32 key = "package/${local.kda.package_name}"
33 source = "${dirname(path.cwd)}/${local.kda.package_name}"
34
35 etag = filemd5("${dirname(path.cwd)}/${local.kda.package_name}")
36}
VPC Configuration
The app can be deployed in the private subnets as it doesn’t need to be connected from outside. Note that an outbound rule that permits connection on port 9098 is created in its security group because it should be able to access the Kafka brokers.
1# infra/kda.tf
2resource "aws_kinesisanalyticsv2_application" "kda_app" {
3
4 ...
5
6 application_configuration {
7
8 ...
9
10 vpc_configuration {
11 security_group_ids = [aws_security_group.kda_sg[0].id]
12 subnet_ids = module.vpc.private_subnets
13 }
14
15 ...
16
17 }
18
19 ...
20
21}
22
23...
24
25resource "aws_security_group" "kda_sg" {
26 count = local.kda.to_create ? 1 : 0
27
28 name = "${local.name}-kda-sg"
29 vpc_id = module.vpc.vpc_id
30
31 egress {
32 from_port = 9098
33 to_port = 9098
34 protocol = "tcp"
35 cidr_blocks = ["0.0.0.0/0"]
36 }
37
38 lifecycle {
39 create_before_destroy = true
40 }
41
42 tags = local.tags
43}
Environment Properties
In environment properties, we first add Flink CLI options in the kinesis.analytics.flink.run.options group. The values of the Pyflink app (python), pipeline jar (jarfile) and 3rd-party python package location (pyFiles) should match those in the application package (kda-package.zip). The other property groups are related to the Kafka source/sink table options, and they will be read by the application.
1# infra/kda.tf
2resource "aws_kinesisanalyticsv2_application" "kda_app" {
3
4 ...
5
6 application_configuration {
7
8 ...
9
10 environment_properties {
11 property_group {
12 property_group_id = "kinesis.analytics.flink.run.options"
13
14 property_map = {
15 python = "processor.py"
16 jarfile = "package/lib/pyflink-getting-started-1.0.0.jar"
17 pyFiles = "package/site_packages/"
18 }
19 }
20
21 property_group {
22 property_group_id = "consumer.config.0"
23
24 property_map = {
25 "table.name" = "source_table"
26 "topic.name" = "stocks-in"
27 "bootstrap.servers" = aws_msk_cluster.msk_data_cluster.bootstrap_brokers_sasl_iam
28 "startup.mode" = "earliest-offset"
29 }
30 }
31
32 property_group {
33 property_group_id = "producer.config.0"
34
35 property_map = {
36 "table.name" = "sink_table"
37 "topic.name" = "stocks-out"
38 "bootstrap.servers" = aws_msk_cluster.msk_data_cluster.bootstrap_brokers_sasl_iam
39 }
40 }
41 }
42
43 ...
44
45 }
46
47 ...
48
49}
Flink Application Configuration
The Flink application configurations constitute of the following.
- Checkpoints - Checkpoints are backups of application state that Managed Service for Apache Flink automatically creates periodically and uses to restore from faults. By default, the following values are configured.
- CheckpointingEnabled: true
- CheckpointInterval: 60000
- MinPauseBetweenCheckpoints: 5000
- Monitoring - The metrics level determines which metrics are created to CloudWatch - see this page for details. The supported values are APPLICATION, OPERATOR, PARALLELISM, and TASK. Here APPLICATION is selected as the metrics level value.
- Parallelism - We can configure the parallel execution of tasks and the allocation of resources to implement scaling. The parallelism indicates the initial number of parallel tasks that an application can perform while the parallelism_per_kpu is the number of parallel tasks that an application can perform per Kinesis Processing Unit (KPU). The application parallelism can be updated by enabling auto-scaling.
1# infra/kda.tf
2resource "aws_kinesisanalyticsv2_application" "kda_app" {
3
4 ...
5
6 application_configuration {
7
8 ...
9
10 flink_application_configuration {
11 checkpoint_configuration {
12 configuration_type = "DEFAULT"
13 }
14
15 monitoring_configuration {
16 configuration_type = "CUSTOM"
17 log_level = "INFO"
18 metrics_level = "APPLICATION"
19 }
20
21 parallelism_configuration {
22 configuration_type = "CUSTOM"
23 auto_scaling_enabled = true
24 parallelism = 1
25 parallelism_per_kpu = 1
26 }
27 }
28 }
29
30 ...
31
32}
Cloudwatch Logging Options
We can add a CloudWatch log stream ARN to the CloudWatch logging options. Note that, when I missed it at first, I saw a CloudWatch log group and log stream are created automatically, but logging was not enabled. It was only when I specified a custom log stream ARN that logging was enabled and log messages were ingested.
1# infra/kda.tf
2resource "aws_kinesisanalyticsv2_application" "kda_app" {
3
4 ...
5
6 cloudwatch_logging_options {
7 log_stream_arn = aws_cloudwatch_log_stream.kda_ls[0].arn
8 }
9
10 ...
11
12}
13
14...
15
16resource "aws_cloudwatch_log_group" "kda_lg" {
17 count = local.kda.to_create ? 1 : 0
18
19 name = "/${local.name}-kda-log-group"
20}
21
22resource "aws_cloudwatch_log_stream" "kda_ls" {
23 count = local.kda.to_create ? 1 : 0
24
25 name = "/${local.name}-kda-log-stream"
26
27 log_group_name = aws_cloudwatch_log_group.kda_lg[0].name
28}
IAM Role
The service execution role has the following permissions.
- Full access to CloudWatch, CloudWatch Log and Amazon Kinesis Data Analytics. It is given by AWS managed policies for logging, metrics generation etc. However, it is by no means recommended and should be updated according to the least privilege principle for production.
- 3 inline policies for connecting to the MSK cluster (kda-msk-access) in private subnets (kda-vpc-access) as well as giving access to the application package in S3 (kda-s3-access).
1# infra/kda.tf
2resource "aws_iam_role" "kda_app_role" {
3 count = local.kda.to_create ? 1 : 0
4
5 name = "${local.name}-kda-role"
6
7 assume_role_policy = jsonencode({
8 Version = "2012-10-17"
9 Statement = [
10 {
11 Action = "sts:AssumeRole"
12 Effect = "Allow"
13 Sid = ""
14 Principal = {
15 Service = "kinesisanalytics.amazonaws.com"
16 }
17 },
18 ]
19 })
20
21 managed_policy_arns = [
22 "arn:aws:iam::aws:policy/CloudWatchFullAccess",
23 "arn:aws:iam::aws:policy/CloudWatchLogsFullAccess",
24 "arn:aws:iam::aws:policy/AmazonKinesisAnalyticsFullAccess"
25 ]
26
27 inline_policy {
28 name = "kda-msk-access"
29
30 policy = jsonencode({
31 Version = "2012-10-17"
32 Statement = [
33 {
34 Sid = "PermissionOnCluster"
35 Action = [
36 "kafka-cluster:Connect",
37 "kafka-cluster:AlterCluster",
38 "kafka-cluster:DescribeCluster"
39 ]
40 Effect = "Allow"
41 Resource = "arn:aws:kafka:${local.region}:${data.aws_caller_identity.current.account_id}:cluster/${local.name}-msk-cluster/*"
42 },
43 {
44 Sid = "PermissionOnTopics"
45 Action = [
46 "kafka-cluster:*Topic*",
47 "kafka-cluster:WriteData",
48 "kafka-cluster:ReadData"
49 ]
50 Effect = "Allow"
51 Resource = "arn:aws:kafka:${local.region}:${data.aws_caller_identity.current.account_id}:topic/${local.name}-msk-cluster/*"
52 },
53 {
54 Sid = "PermissionOnGroups"
55 Action = [
56 "kafka-cluster:AlterGroup",
57 "kafka-cluster:DescribeGroup"
58 ]
59 Effect = "Allow"
60 Resource = "arn:aws:kafka:${local.region}:${data.aws_caller_identity.current.account_id}:group/${local.name}-msk-cluster/*"
61 }
62 ]
63 })
64 }
65
66 inline_policy {
67 name = "kda-vpc-access"
68 # https://docs.aws.amazon.com/kinesisanalytics/latest/java/vpc-permissions.html
69
70 policy = jsonencode({
71 Version = "2012-10-17"
72 Statement = [
73 {
74 Sid = "VPCReadOnlyPermissions"
75 Action = [
76 "ec2:DescribeVpcs",
77 "ec2:DescribeSubnets",
78 "ec2:DescribeSecurityGroups",
79 "ec2:DescribeDhcpOptions"
80 ]
81 Effect = "Allow"
82 Resource = "*"
83 },
84 {
85 Sid = "ENIReadWritePermissions"
86 Action = [
87 "ec2:CreateNetworkInterface",
88 "ec2:CreateNetworkInterfacePermission",
89 "ec2:DescribeNetworkInterfaces",
90 "ec2:DeleteNetworkInterface"
91 ]
92 Effect = "Allow"
93 Resource = "*"
94 }
95
96 ]
97 })
98 }
99
100 inline_policy {
101 name = "kda-s3-access"
102
103 policy = jsonencode({
104 Version = "2012-10-17"
105 Statement = [
106 {
107 Sid = "ListObjectsInBucket"
108 Action = ["s3:ListBucket"]
109 Effect = "Allow"
110 Resource = "arn:aws:s3:::${aws_s3_bucket.default_bucket.id}"
111 },
112 {
113 Sid = "AllObjectActions"
114 Action = ["s3:*Object"]
115 Effect = "Allow"
116 Resource = "arn:aws:s3:::${aws_s3_bucket.default_bucket.id}/*"
117 },
118 ]
119 })
120 }
121
122 tags = local.tags
123}
Once deployed, we can see the application on AWS console, and it stays in the ready status.
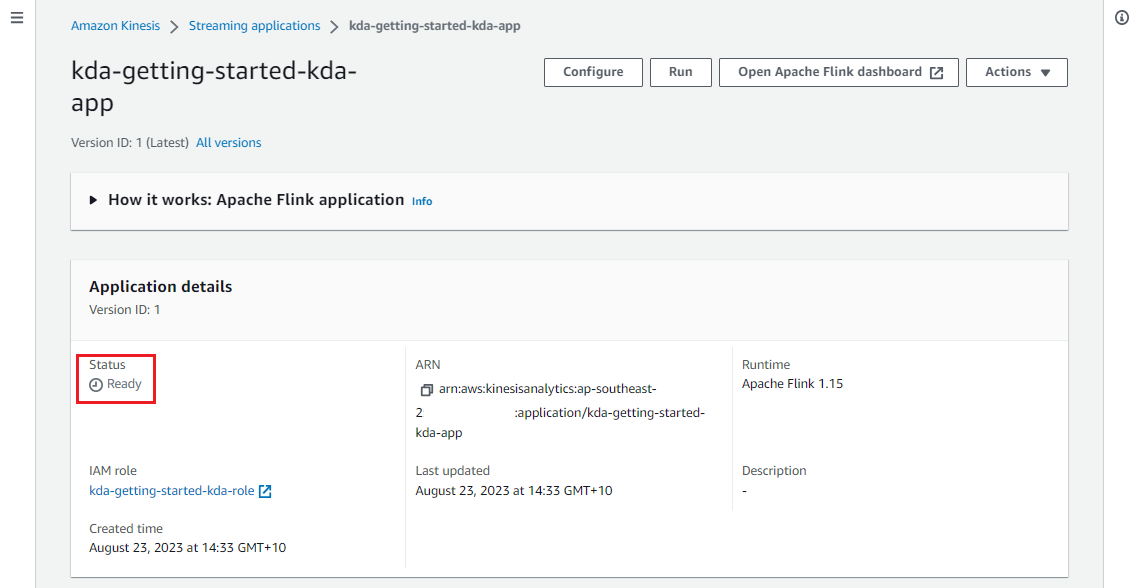
Run Application
We first need to create records in the source Kafka topic. It is done by executing the data generator app (producer.py). See part 2 for details about the generator app and how to execute it. Note that we should connect to the VPN server in order to create records from the developer machine.
Once executed, we can check the source topic is created and messages are ingested.
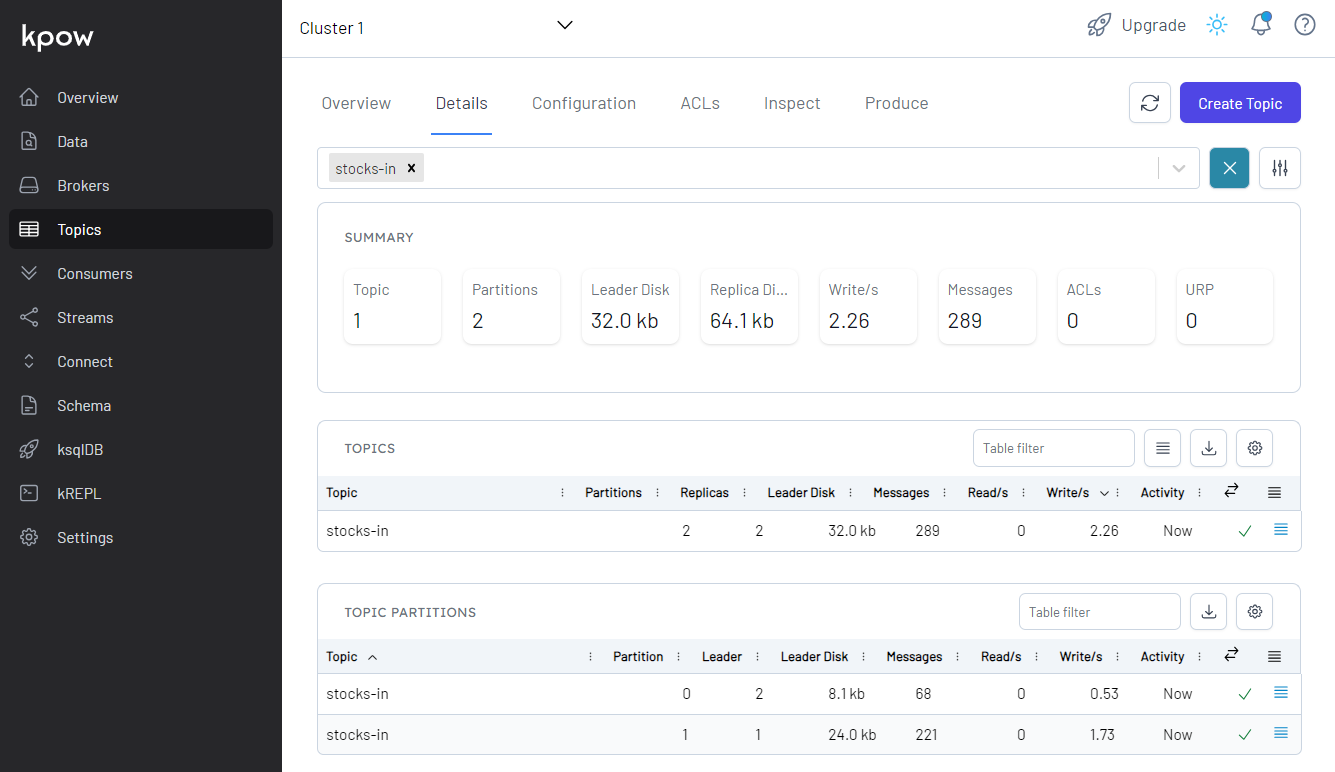
Monitoring on Flink Web UI
We can run the Flink application on AWS console with the Run without snapshot option as we haven’t enabled snapshots.
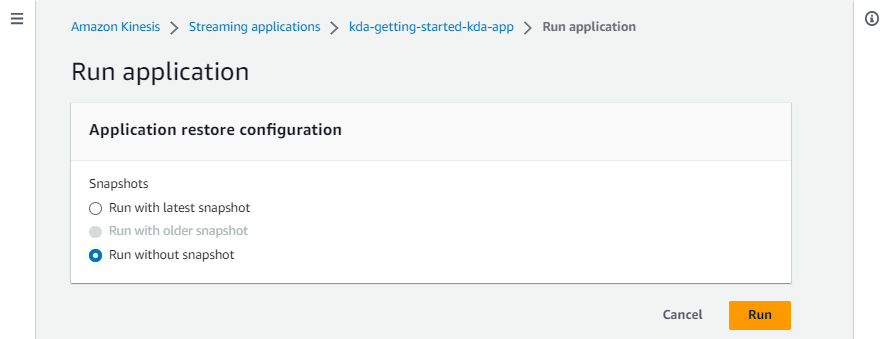
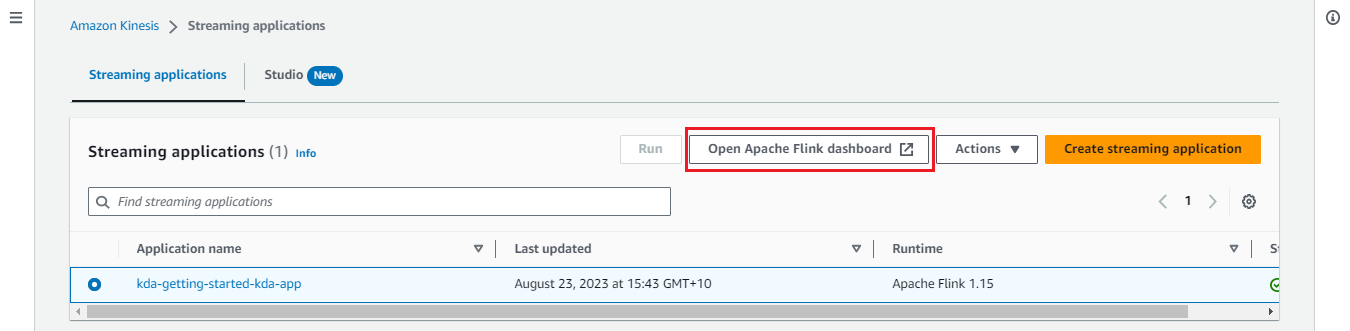
Once the app is running, we can monitor it on the Flink Web UI available on AWS Console.
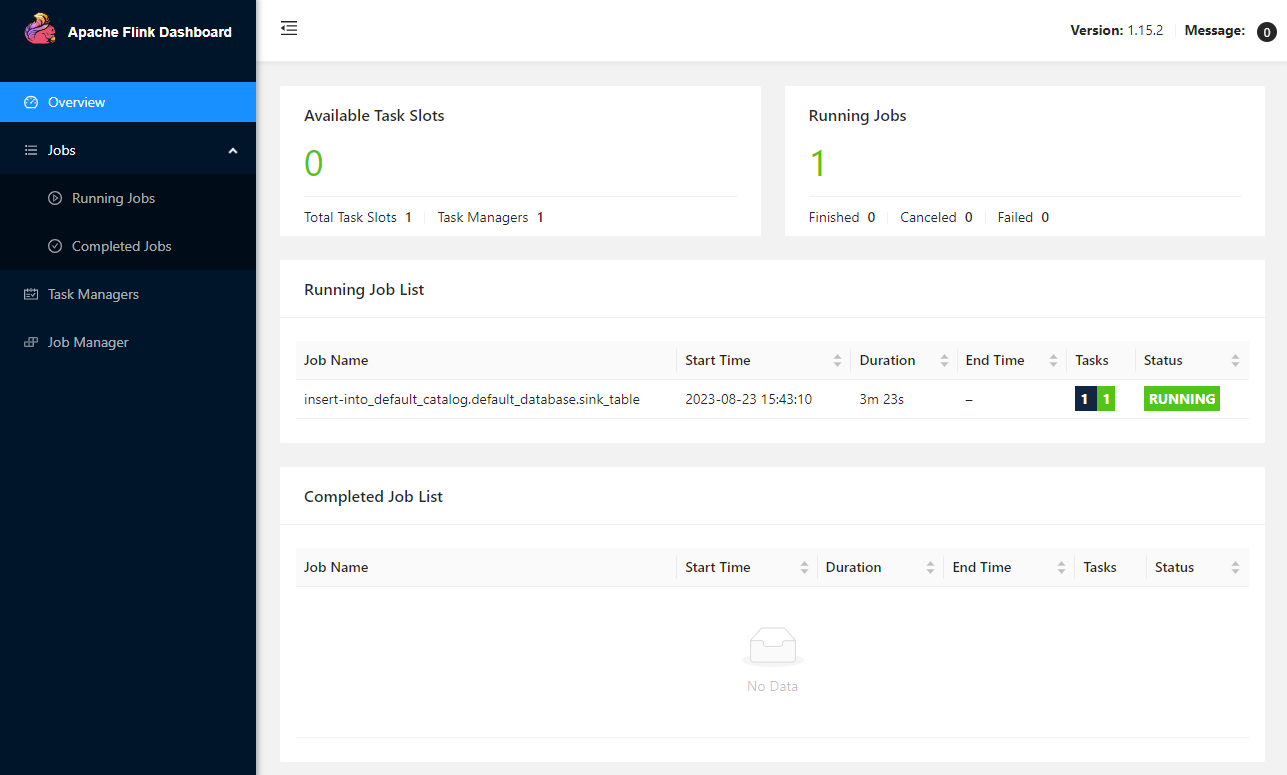
In the Overview section, it shows the available task slots, running jobs and completed jobs.
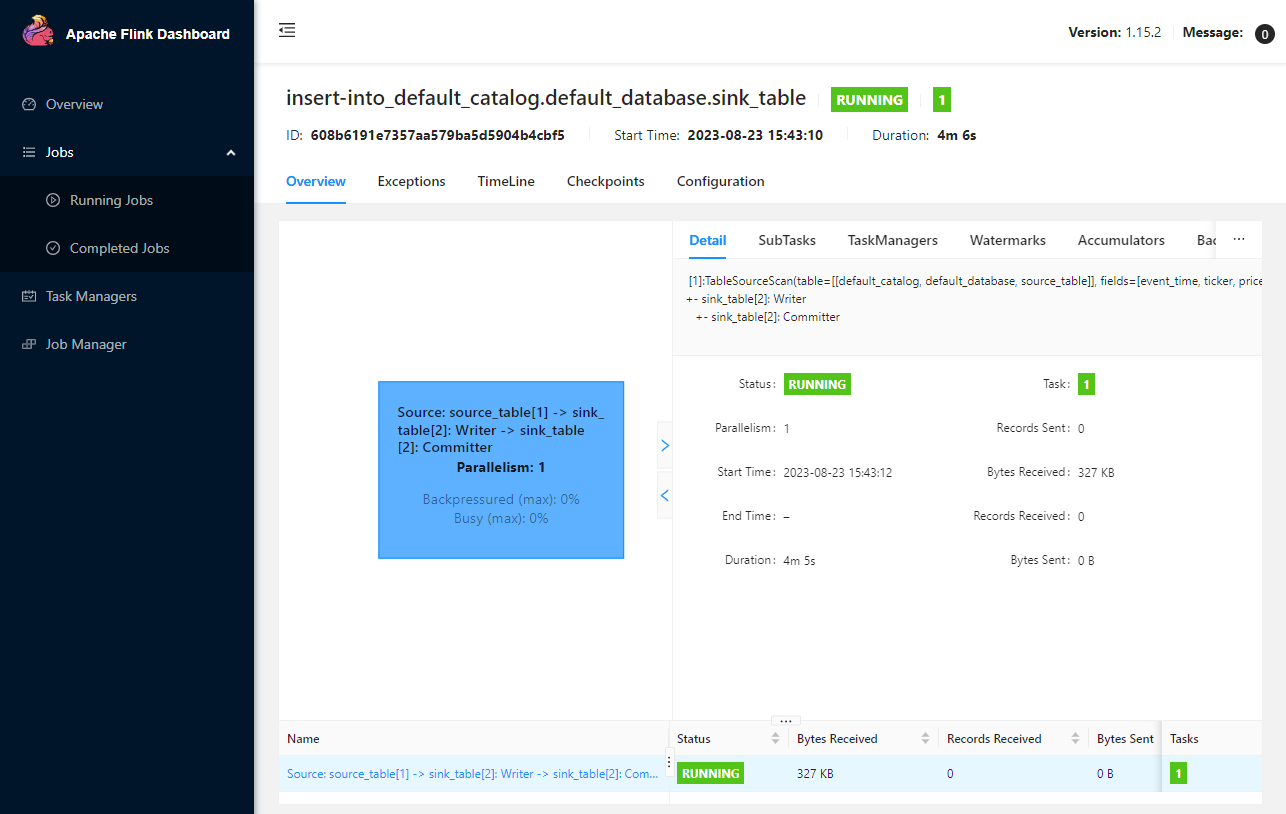
We can inspect an individual job in the Jobs menu. It shows key details about a job execution in Overview, Exceptions, TimeLine, Checkpoints and Configuration tabs.
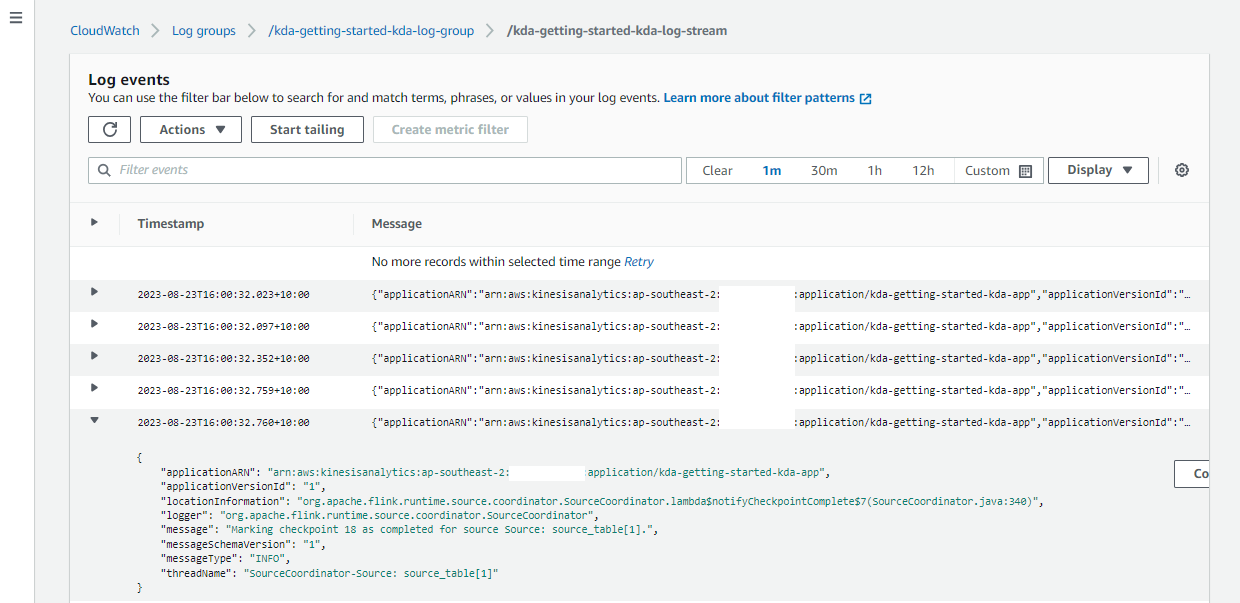
CloudWatch Logging
The application log messages can be checked in the CloudWatch Console, and it gives additional capability to debug the application.
Application Output
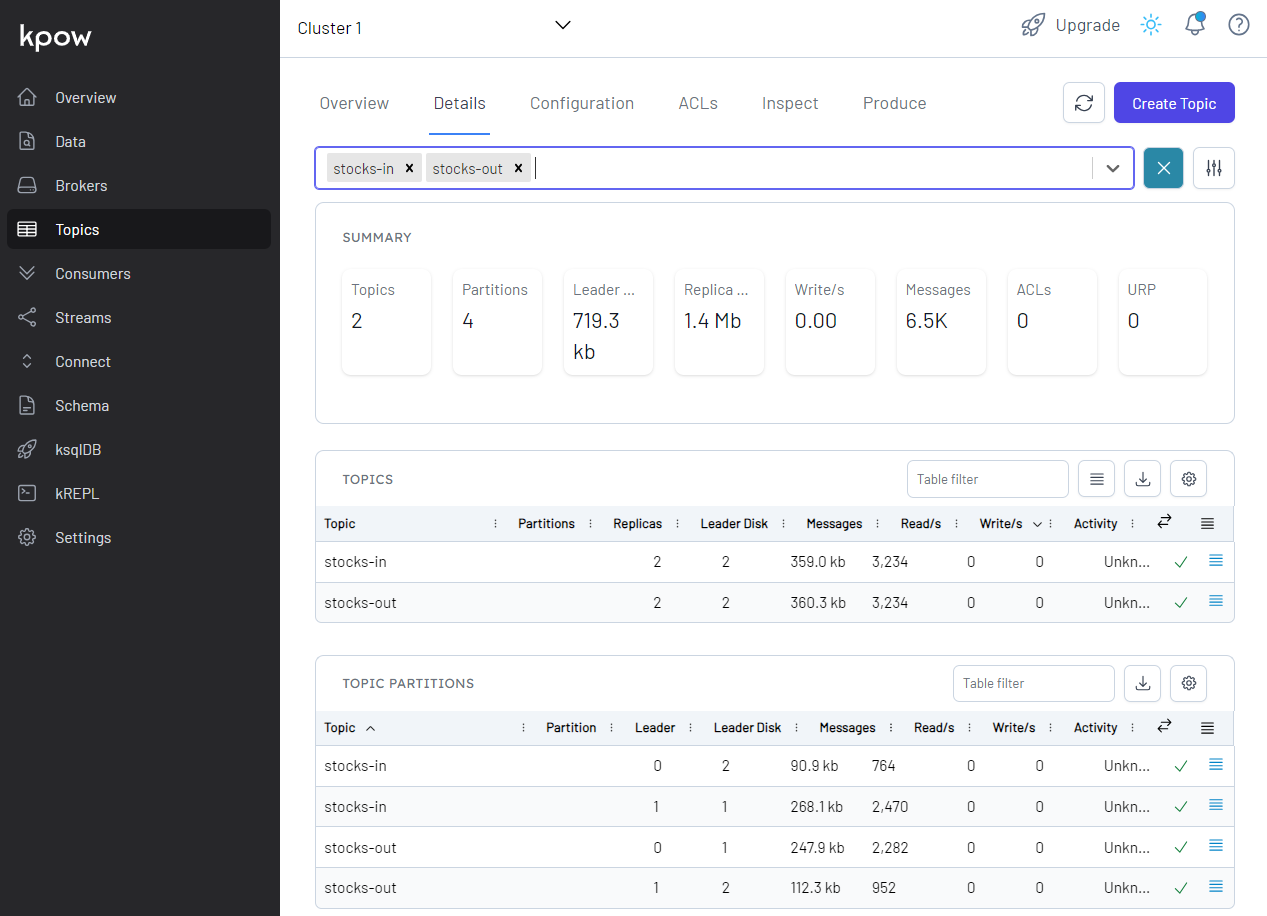
We can see details of all the topics in Kpow. The total number of messages matches between the source and output topics but not within partitions.
Summary
In this series of posts, we discussed a Flink (Pyflink) application that reads/writes from/to Kafka topics. In the previous posts, I demonstrated a Pyflink app that targets a local Kafka cluster as well as a Kafka cluster on Amazon MSK. The app was executed in a virtual environment as well as in a local Flink cluster for improved monitoring. In this post, the app was deployed via Amazon Managed Service for Apache Flink, which is the easiest option to run Flink applications on AWS.










Comments