
Building Apache Flink Applications in Java is a course to introduce Apache Flink through a series of hands-on exercises, and it is provided by Confluent. Utilising the Flink DataStream API, the course develops three Flink applications that populate multiple source data sets, collect them into a standardised data set, and aggregate it to produce usage statistics. As part of learning the Flink DataStream API in Pyflink, I converted the Java apps into Python equivalent while performing the course exercises in Pyflink. This post summarises the progress of the conversion and shows the final output.
Architecture
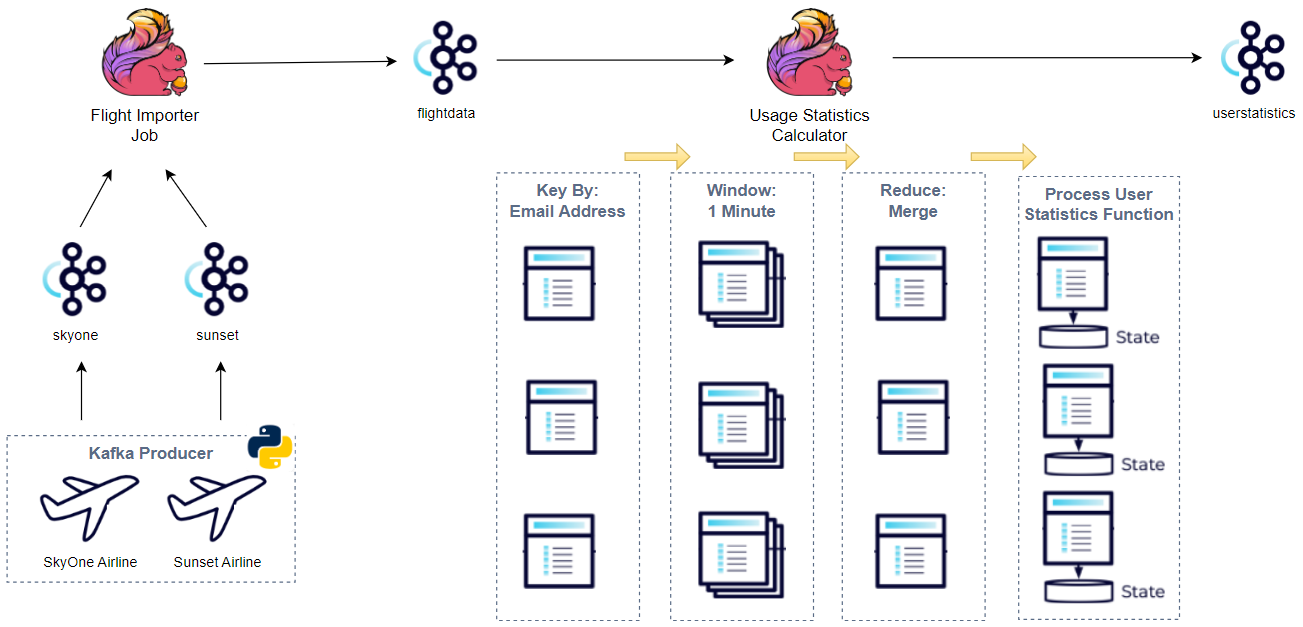
There are two airlines (SkyOne and Sunset) and they have their own flight data in different schemas. While the course ingests the source data into corresponding topics using a Flink application that makes use of the DataGen DataStream Connector, we use a Kafka producer application here because the DataGen connector is not available for python.
The flight importer job reads the messages from the source topics, standardises them into the flight data schema, and pushed into another Kafka topic, called flightdata. It is developed using Pyflink.
The usage statistics calculator sources the flightdata topic and calculates usage statistics over a one-minute window, which is grouped by email address. Moreover, while accessing the global state, it produces cumulative usage statistics, which carries information from one window to the next. It is developed using Pyflink as well.
Course Contents
Below describes course contents. ✅ and ☑️ indicate exercises and course materials respectively. The lesson 3 covers how to set up Kafka and Flink clusters using Docker Compose. The Kafka producer app is created as the lesson 5 exercise. The final versions of the flight importer job and usage statistics calculator can be found as exercises of the lesson 16 and 20 respectively.
- Apache Flink with Java - An Introduction
- Datastream Programming
- ✅ How to Start Flink and Get Setup (Exercise)
- Built Kafka and Flink clusters using Docker
- Bitnami images are used for the Kafka cluster - see this page for details.
- A custom Docker image (building-pyflink-apps:1.17.1) is created to install Python and the Pyflink package as well as to save dependent Jar files
- See the Dockerfile, and it can be built by
docker build -t=building-pyflink-apps:1.17.1 .
- See the Dockerfile, and it can be built by
- See the docker-compose.yml and the clusters can be started by
docker-compose up -d
- ☑️ The Flink Job Lifecycle
- A minimal example of executing a Pyflink app is added.
- See course content(s) below
- ✅ Running a Flink Job (Exercise)
- Pyflink doesn’t have the DataGen DataStream connector. Used a Kafka producer instead to create topics and send messages.
- 4 topics are created (skyone, sunset, flightdata and userstatistics) and messages are sent to the first two topics.
- See course content(s) below
- s05_data_gen.py
- Topics are created by a flag argument so add it if it is the first time running it. i.e.
python src/s05_data_gen.py --create. Basically it deletes the topics if exits and creates them.
- Topics are created by a flag argument so add it if it is the first time running it. i.e.
- s05_data_gen.py
- Pyflink doesn’t have the DataGen DataStream connector. Used a Kafka producer instead to create topics and send messages.
- Anatomy of a Stream
- Flink Data Sources
- ✅ Creating a Flink Data Source (Exercise)
- It reads from the skyone topic and prints the values. The values are deserialized as string in this exercise.
- This and all the other Pyflink applications can be executed locally or run in the Flink cluster. See the script for details.
- See course content(s) below
- Serializers & Deserializers
- ✅ Deserializing Messages in Flink (Exercise)
- The skyone message values are deserialized as Json string and they are returned as the named Row type. As the Flink type is not convenient for processing, it is converted into a Python object, specifically Data Classes.
- See course content(s) below
- ☑️ Transforming Data in Flink
- Map, FlatMap, Filter and Reduce transformations are illustrated using built-in operators and process functions.
- See course content(s) below
- ✅ Flink Data Transformations (Exercise)
- The source data is transformed into the flight data. Later data from skyone and sunset will be converted into this schema for merging them.
- The transformation is performed in a function called define_workflow for being tested. This function will be updated gradually.
- See course content(s) below
- s12_transformation.py
- test_s12_transformation.py
- Expected to run testing scripts individually eg)
pytest src/test_s12_transformation.py -svv
- Expected to run testing scripts individually eg)
- Flink Data Sinks
- ✅ Creating a Flink Data Sink (Exercise)
- The converted data from skyone will be pushed into a Kafka topic (flightdata).
- Note that, as the Python Data Classes cannot be serialized, records are converted into the named Row type before being sent.
- See course content(s) below
- ☑️ Creating Branching Data Streams in Flink
- Various branching methods are illustrated, which covers Union, CoProcessFunction, CoMapFunction, CoFlatMapFunction, and Side Outputs.
- See course content(s) below
- ✅ Merging Flink Data Streams (Exercise)
- Records from the skyone and sunset topics are merged and sent into the flightdata topic after being converted into the flight data.
- See course content(s) below
- Windowing and Watermarks in Flink
- ✅ Aggregating Flink Data using Windowing (Exercise)
- Usage statistics (total flight duration and number of flights) are calculated by email address, and they are sent into the userstatistics topic.
- Note the transformation is stateless in a sense that aggregation is entirely within a one-minute tumbling window.
- See course content(s) below
- Working with Keyed State in Flink
- ✅ Managing State in Flink (Exercise)
- The transformation gets stateful so that usage statistics are continuously updated by accessing the state values.
- The reduce function includes a window function that allows you to access the global state. The window function takes the responsibility to keep updating the global state and to return updated values.
- See course content(s) below
- Closing Remarks
Start Applications
After creating the Kafka and Flink clusters using Docker Compose, we need to start the Python producer in one terminal. Then we can submit the other Pyflink applications in another terminal.
1#### build docker image for Pyflink
2docker build -t=building-pyflink-apps:1.17.1 .
3
4#### create kafka and flink clusters and kafka-ui
5docker-compose up -d
6
7#### start kafka producer in one terminal
8python -m venv venv
9source venv/bin/activate
10# upgrade pip (optional)
11pip install pip --upgrade
12# install required packages
13pip install -r requirements-dev.txt
14## start with --create flag to create topics before sending messages
15python src/s05_data_gen.py --create
16
17#### submit pyflink apps in another terminal
18## flight importer
19docker exec jobmanager /opt/flink/bin/flink run \
20 --python /tmp/src/s16_merge.py \
21 --pyFiles file:///tmp/src/models.py,file:///tmp/src/utils.py \
22 -d
23
24## usage calculator
25docker exec jobmanager /opt/flink/bin/flink run \
26 --python /tmp/src/s20_manage_state.py \
27 --pyFiles file:///tmp/src/models.py,file:///tmp/src/utils.py \
28 -d
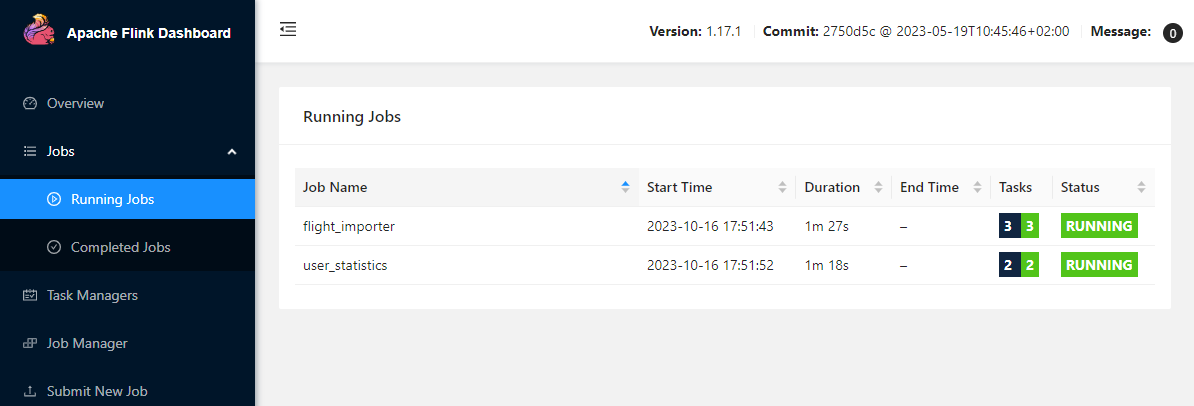
We can check the Pyflink jobs are running on the Flink Dashboard via localhost:8081.
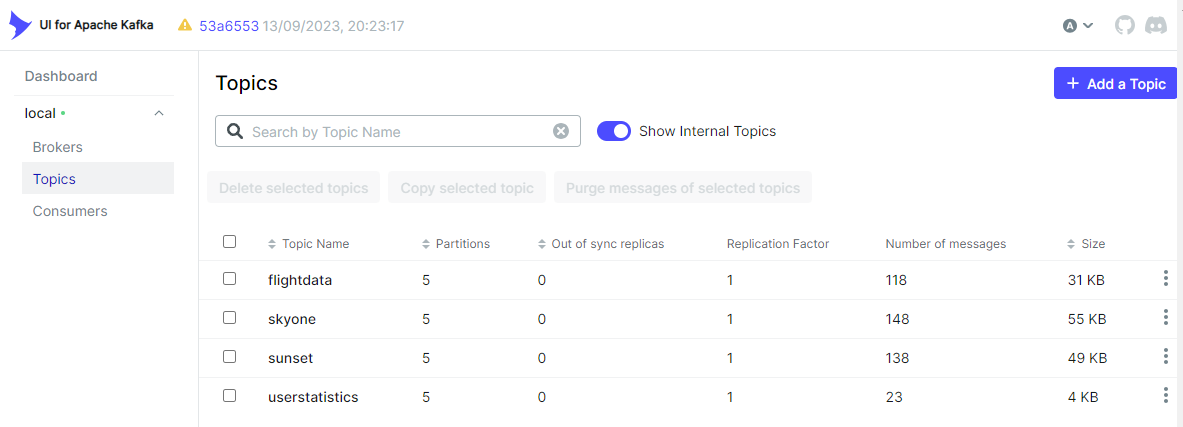
Also, we can check the Kafka topics on kafka-ui via localhost:8080.
Unit Testing
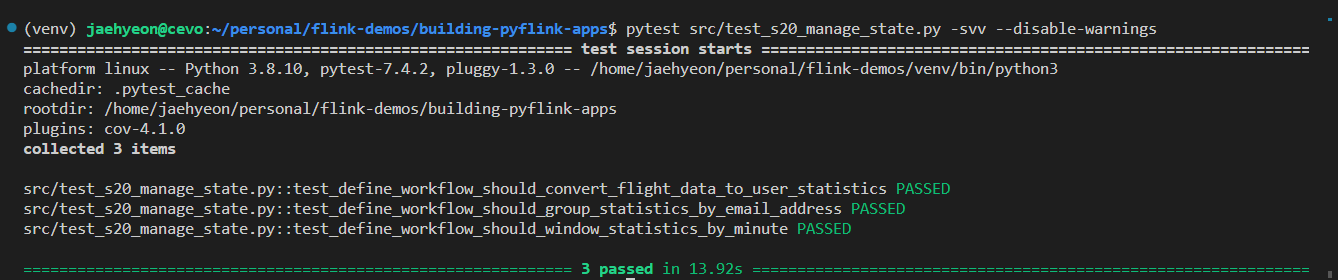
Four lessons have unit testing cases, and they are expected to run separately by specifying a testing script. For example, below shows running unit testing cases of the final usage statistics calculator job.










Comments