
In the previous post, we discussed how to develop a data pipeline from Apache Kafka into OpenSearch locally using Docker. The pipeline will be deployed on AWS using Amazon MSK, Amazon MSK Connect and Amazon OpenSearch Service using Terraform in this post. First the infrastructure will be deployed that covers a Virtual Private Cloud (VPC), Virtual Private Network (VPN) server, MSK Cluster and OpenSearch domain. Then Kafka source and sink connectors will be deployed on MSK Connect, followed by performing quick data analysis.
- Part 1 Introduction
- Part 2 Develop Camel DynamoDB Sink Connector
- Part 3 Deploy Camel DynamoDB Sink Connector
- Part 4 Develop Aiven OpenSearch Sink Connector
- Part 5 Deploy Aiven OpenSearch Sink Connector (this post)
Architecture
Fake impressions and clicks events are generated by the Amazon MSK Data Generator, and they are pushed into the corresponding Kafka topics. The topic records are ingested into OpenSearch indexes with the same names for near real-time analysis using the Aiven’s OpenSearch Connector for Apache Kafka. Note that, as the Kafka cluster and OpenSearch Service domain are deployed in private subnets, a VPN server is used to access them from the developer machine.
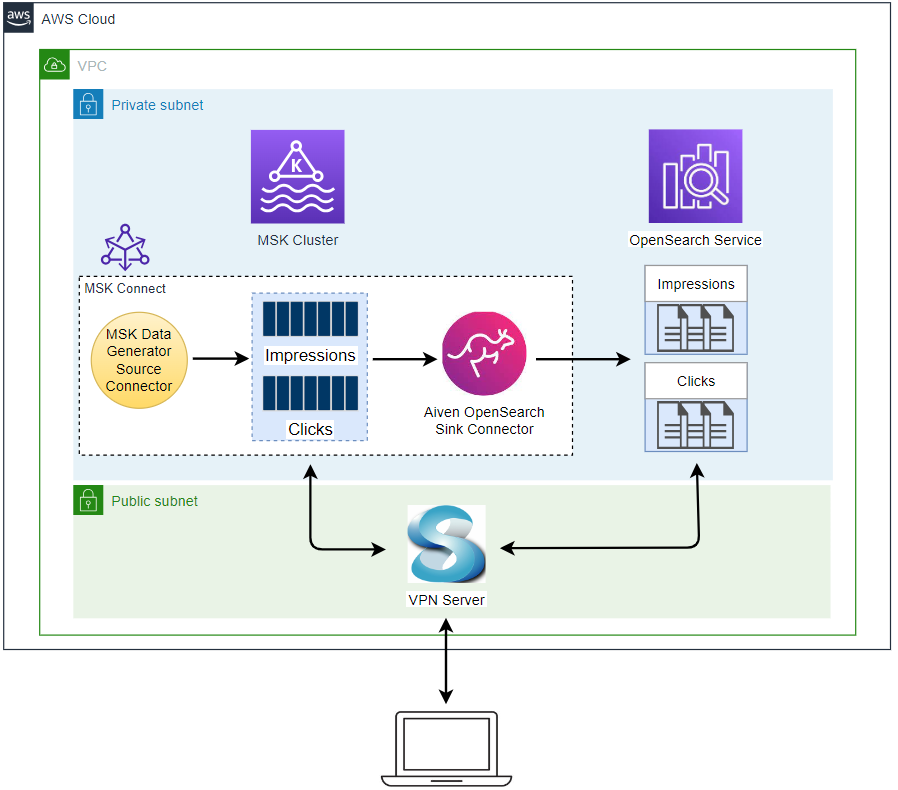
Infrastructure
The infrastructure is created using Terraform and the source can be found in the GitHub repository of this post.
VPC and VPN
A VPC with 3 public and private subnets is created using the AWS VPC Terraform module (vpc.tf). Also, a SoftEther VPN server is deployed in order to access the resources in the private subnets from the developer machine (vpn.tf). The details about how to configure the VPN server can be found in this post.
OpenSearch Cluster
An OpenSearch domain that has two instances is created. It is deployed with the m5.large.search instance type in private subnets. For simplicity, anonymous authentication is enabled so that we don’t have to specify user credentials when making an HTTP request. Overall only network-level security is enforced on the OpenSearch domain.
1# variable.tf
2locals {
3 ...
4 opensearch = {
5 engine_version = "2.7"
6 instance_type = "m5.large.search"
7 instance_count = 2
8 }
9 ...
10}
11
12# opensearch.tf
13resource "aws_opensearch_domain" "opensearch" {
14 domain_name = local.name
15 engine_version = "OpenSearch_${local.opensearch.engine_version}"
16
17 cluster_config {
18 dedicated_master_enabled = false
19 instance_type = local.opensearch.instance_type # m5.large.search
20 instance_count = local.opensearch.instance_count # 2
21 zone_awareness_enabled = true
22 }
23
24 advanced_security_options {
25 enabled = false
26 anonymous_auth_enabled = true
27 internal_user_database_enabled = true
28 }
29
30 domain_endpoint_options {
31 enforce_https = true
32 tls_security_policy = "Policy-Min-TLS-1-2-2019-07"
33 custom_endpoint_enabled = false
34 }
35
36 ebs_options {
37 ebs_enabled = true
38 volume_size = 10
39 }
40
41 log_publishing_options {
42 cloudwatch_log_group_arn = aws_cloudwatch_log_group.opensearch_log_group_index_slow_logs.arn
43 log_type = "INDEX_SLOW_LOGS"
44 }
45
46 vpc_options {
47 subnet_ids = slice(module.vpc.private_subnets, 0, local.opensearch.instance_count)
48 security_group_ids = [aws_security_group.opensearch.id]
49 }
50
51 access_policies = jsonencode({
52 Version = "2012-10-17"
53 Statement = [
54 {
55 Action = "es:*",
56 Principal = "*",
57 Effect = "Allow",
58 Resource = "arn:aws:es:${data.aws_region.current.name}:${data.aws_caller_identity.current.account_id}:domain/${local.name}/*"
59 }
60 ]
61 })
62}
OpenSearch Security Group
The security group of the OpenSearch domain has inbound rules that allow connection from the security groups of the MSK cluster and VPN server. Only port 443 and 9200 are open for accessing the OpenSearch Dashboards and making HTTP requests.
1# opensearch.tf
2resource "aws_security_group" "opensearch" {
3 name = "${local.name}-opensearch-sg"
4 vpc_id = module.vpc.vpc_id
5
6 lifecycle {
7 create_before_destroy = true
8 }
9
10 tags = local.tags
11}
12
13resource "aws_security_group_rule" "opensearch_msk_inbound_https" {
14 type = "ingress"
15 description = "Allow inbound traffic for OpenSearch Dashboard from MSK"
16 security_group_id = aws_security_group.opensearch.id
17 protocol = "tcp"
18 from_port = 443
19 to_port = 443
20 source_security_group_id = aws_security_group.msk.id
21}
22
23resource "aws_security_group_rule" "opensearch_msk_inbound_rest" {
24 type = "ingress"
25 description = "Allow inbound traffic for OpenSearch REST API from MSK"
26 security_group_id = aws_security_group.opensearch.id
27 protocol = "tcp"
28 from_port = 9200
29 to_port = 9200
30 source_security_group_id = aws_security_group.msk.id
31}
32
33resource "aws_security_group_rule" "opensearch_vpn_inbound_https" {
34 count = local.vpn.to_create ? 1 : 0
35 type = "ingress"
36 description = "Allow inbound traffic for OpenSearch Dashboard from VPN"
37 security_group_id = aws_security_group.opensearch.id
38 protocol = "tcp"
39 from_port = 443
40 to_port = 443
41 source_security_group_id = aws_security_group.vpn[0].id
42}
43
44resource "aws_security_group_rule" "opensearch_vpn_inbound_rest" {
45 count = local.vpn.to_create ? 1 : 0
46 type = "ingress"
47 description = "Allow inbound traffic for OpenSearch REST API from VPN"
48 security_group_id = aws_security_group.opensearch.id
49 protocol = "tcp"
50 from_port = 9200
51 to_port = 9200
52 source_security_group_id = aws_security_group.vpn[0].id
53}
MSK Cluster
An MSK cluster with 2 brokers is created. The broker nodes are deployed with the kafka.m5.large instance type in private subnets and IAM authentication is used for the client authentication method. Finally, additional server configurations are added such as enabling auto creation of topics and topic deletion.
1# variable.tf
2locals {
3 ...
4 msk = {
5 version = "2.8.1"
6 instance_size = "kafka.m5.large"
7 ebs_volume_size = 20
8 log_retention_ms = 604800000 # 7 days
9 number_of_broker_nodes = 2
10 num_partitions = 2
11 default_replication_factor = 2
12 }
13 ...
14}
15
16# msk.tf
17resource "aws_msk_cluster" "msk_data_cluster" {
18 cluster_name = "${local.name}-msk-cluster"
19 kafka_version = local.msk.version
20 number_of_broker_nodes = local.msk.number_of_broker_nodes
21 configuration_info {
22 arn = aws_msk_configuration.msk_config.arn
23 revision = aws_msk_configuration.msk_config.latest_revision
24 }
25
26 broker_node_group_info {
27 instance_type = local.msk.instance_size
28 client_subnets = slice(module.vpc.private_subnets, 0, local.msk.number_of_broker_nodes)
29 security_groups = [aws_security_group.msk.id]
30 storage_info {
31 ebs_storage_info {
32 volume_size = local.msk.ebs_volume_size
33 }
34 }
35 }
36
37 client_authentication {
38 sasl {
39 iam = true
40 }
41 }
42
43 logging_info {
44 broker_logs {
45 cloudwatch_logs {
46 enabled = true
47 log_group = aws_cloudwatch_log_group.msk_cluster_lg.name
48 }
49 s3 {
50 enabled = true
51 bucket = aws_s3_bucket.default_bucket.id
52 prefix = "logs/msk/cluster/"
53 }
54 }
55 }
56
57 tags = local.tags
58
59 depends_on = [aws_msk_configuration.msk_config]
60}
61
62resource "aws_msk_configuration" "msk_config" {
63 name = "${local.name}-msk-configuration"
64
65 kafka_versions = [local.msk.version]
66
67 server_properties = <<PROPERTIES
68 auto.create.topics.enable = true
69 delete.topic.enable = true
70 log.retention.ms = ${local.msk.log_retention_ms}
71 num.partitions = ${local.msk.num_partitions}
72 default.replication.factor = ${local.msk.default_replication_factor}
73 PROPERTIES
74}
MSK Security Group
The security group of the MSK cluster allows all inbound traffic from itself and all outbound traffic into all IP addresses. The Kafka connectors will use the same security group and the former is necessary. Both the rules are configured too generously, however, we can limit the protocol and port ranges in production. Also, the security group has an additional inbound rule that permits it to connect on port 9098 from the security group of the VPN server.
1resource "aws_security_group" "msk" {
2 name = "${local.name}-msk-sg"
3 vpc_id = module.vpc.vpc_id
4
5 lifecycle {
6 create_before_destroy = true
7 }
8
9 tags = local.tags
10}
11
12resource "aws_security_group_rule" "msk_self_inbound_all" {
13 type = "ingress"
14 description = "Allow ingress from itself - required for MSK Connect"
15 security_group_id = aws_security_group.msk.id
16 protocol = "-1"
17 from_port = "0"
18 to_port = "0"
19 source_security_group_id = aws_security_group.msk.id
20}
21
22resource "aws_security_group_rule" "msk_self_outbound_all" {
23 type = "egress"
24 description = "Allow outbound all"
25 security_group_id = aws_security_group.msk.id
26 protocol = "-1"
27 from_port = "0"
28 to_port = "0"
29 cidr_blocks = ["0.0.0.0/0"]
30}
31
32resource "aws_security_group_rule" "msk_vpn_inbound" {
33 count = local.vpn.to_create ? 1 : 0
34 type = "ingress"
35 description = "Allow VPN access"
36 security_group_id = aws_security_group.msk.id
37 protocol = "tcp"
38 from_port = 9098
39 to_port = 9098
40 source_security_group_id = aws_security_group.vpn[0].id
41}
Deploy Infrastructure
To separate infrastructure deployment from Kafka connector creation, I added a Terraform variable called to_create_connector. As can be seen below, if we set the value to false, the Terraform resources will be created without MSK connectors. Below shows how to deploy the infrastructure.
1$ terraform init
2$ terraform plan -var to_create_connector=false
3$ terraform apply --auto-approve=true -var to_create_connector=false
Once completed, we can check the two key resources on AWS Console - OpenSearch domain and MSK cluster.
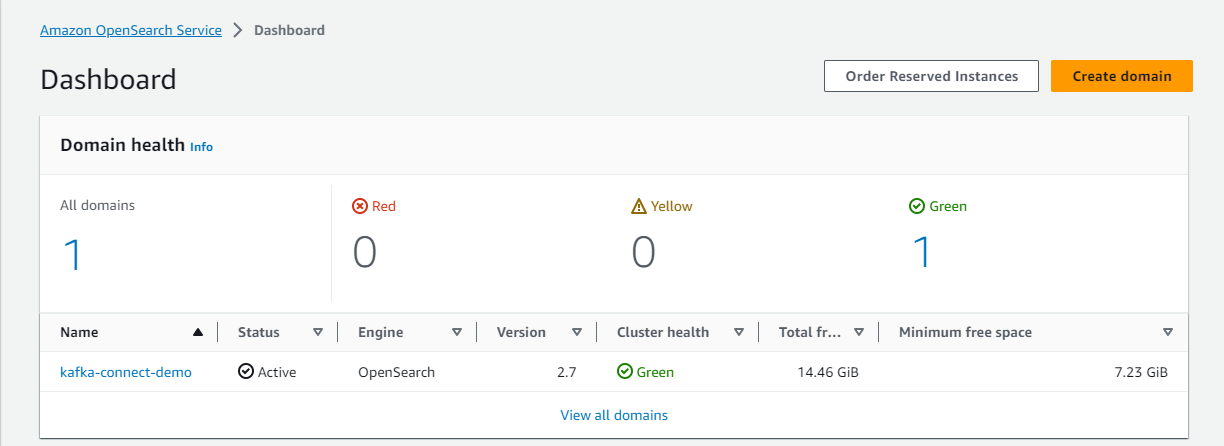
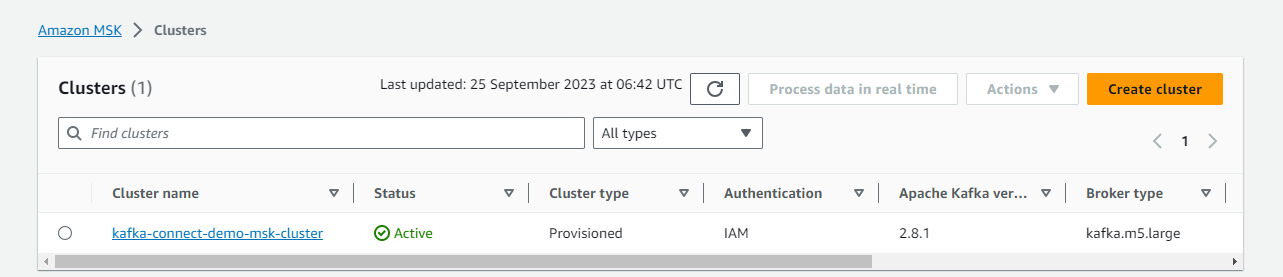
Kafka Management App
A Kafka management app can be a good companion for development as it helps monitor and manage resources on an easy-to-use user interface. We’ll use Kpow Community Edition in this post, and we can link a single Kafka cluster, Kafka connect server and schema registry. Note that the community edition is valid for 12 months and the license can be requested in this page. Once requested, the license details will be emailed, and they can be added as an environment file (env_file).
The app needs additional configurations in environment variables because the Kafka cluster on Amazon MSK is authenticated by IAM. The bootstrap server address can be found on AWS Console or executing the following Terraform command.
1$ terraform output -json | jq -r '.msk_bootstrap_brokers_sasl_iam.value'
It also requires AWS credentials and SASL security configurations for IAM Authentication. Finally, I added an environment variable that indicates in which AWS region the MSK connectors are deployed. For further details, see the Kpow documentation.
1# docker-compose.yml
2version: "3"
3
4services:
5 kpow:
6 image: factorhouse/kpow-ce:91.2.1
7 container_name: kpow
8 ports:
9 - "3000:3000"
10 networks:
11 - appnet
12 environment:
13 AWS_ACCESS_KEY_ID: $AWS_ACCESS_KEY_ID
14 AWS_SECRET_ACCESS_KEY: $AWS_SECRET_ACCESS_KEY
15 AWS_SESSION_TOKEN: $AWS_SESSION_TOKEN
16 # MSK cluster
17 BOOTSTRAP: $BOOTSTRAP_SERVERS
18 SECURITY_PROTOCOL: SASL_SSL
19 SASL_MECHANISM: AWS_MSK_IAM
20 SASL_CLIENT_CALLBACK_HANDLER_CLASS: software.amazon.msk.auth.iam.IAMClientCallbackHandler
21 SASL_JAAS_CONFIG: software.amazon.msk.auth.iam.IAMLoginModule required;
22 # MSK connect
23 CONNECT_AWS_REGION: $AWS_DEFAULT_REGION
24
25networks:
26 appnet:
27 name: app-network
Data Pipeline
Preparation
Download Connector Sources
The connector sources need to be downloaded into the ./connectors path so that they can be volume-mapped to the container’s plugin path (/opt/connectors). The MSK Data Generator is a single Jar file, and it can be kept as it is. On the other hand, the Aiven OpenSearch sink connector is an archive file, and it should be decompressed. Note the zip file will be used to create a custom plugin of MSK Connect in the next post. The following script downloads the connector sources into the host path.
1# download.sh
2#!/usr/bin/env bash
3shopt -s extglob
4
5SCRIPT_DIR="$(cd $(dirname "$0"); pwd)"
6
7SRC_PATH=${SCRIPT_DIR}/connectors
8rm -rf ${SRC_PATH} && mkdir ${SRC_PATH}
9
10## Avien opensearch sink connector
11echo "downloading opensearch sink connector..."
12DOWNLOAD_URL=https://github.com/Aiven-Open/opensearch-connector-for-apache-kafka/releases/download/v3.1.0/opensearch-connector-for-apache-kafka-3.1.0.zip
13
14curl -L -o ${SRC_PATH}/tmp.zip ${DOWNLOAD_URL} \
15 && unzip -qq ${SRC_PATH}/tmp.zip -d ${SRC_PATH} \
16 && rm -rf $SRC_PATH/!(opensearch-connector-for-apache-kafka-3.1.0) \
17 && mv $SRC_PATH/opensearch-connector-for-apache-kafka-3.1.0 $SRC_PATH/opensearch-connector \
18 && cd $SRC_PATH/opensearch-connector \
19 && zip ../opensearch-connector.zip *
20
21## MSK Data Generator Souce Connector
22echo "downloading msk data generator..."
23DOWNLOAD_URL=https://github.com/awslabs/amazon-msk-data-generator/releases/download/v0.4.0/msk-data-generator-0.4-jar-with-dependencies.jar
24
25mkdir ${SRC_PATH}/msk-datagen \
26 && curl -L -o ${SRC_PATH}/msk-datagen/msk-data-generator.jar ${DOWNLOAD_URL}
Below shows the folder structure after the connectors are downloaded successfully.
1$ tree connectors/
2connectors/
3├── msk-datagen
4│ └── msk-data-generator.jar
5├── opensearch-connector
6
7...
8
9│ ├── opensearch-2.6.0.jar
10│ ├── opensearch-cli-2.6.0.jar
11│ ├── opensearch-common-2.6.0.jar
12│ ├── opensearch-connector-for-apache-kafka-3.1.0.jar
13│ ├── opensearch-core-2.6.0.jar
14
15...
16
17└── opensearch-connector.zip
18
192 directories, 56 files
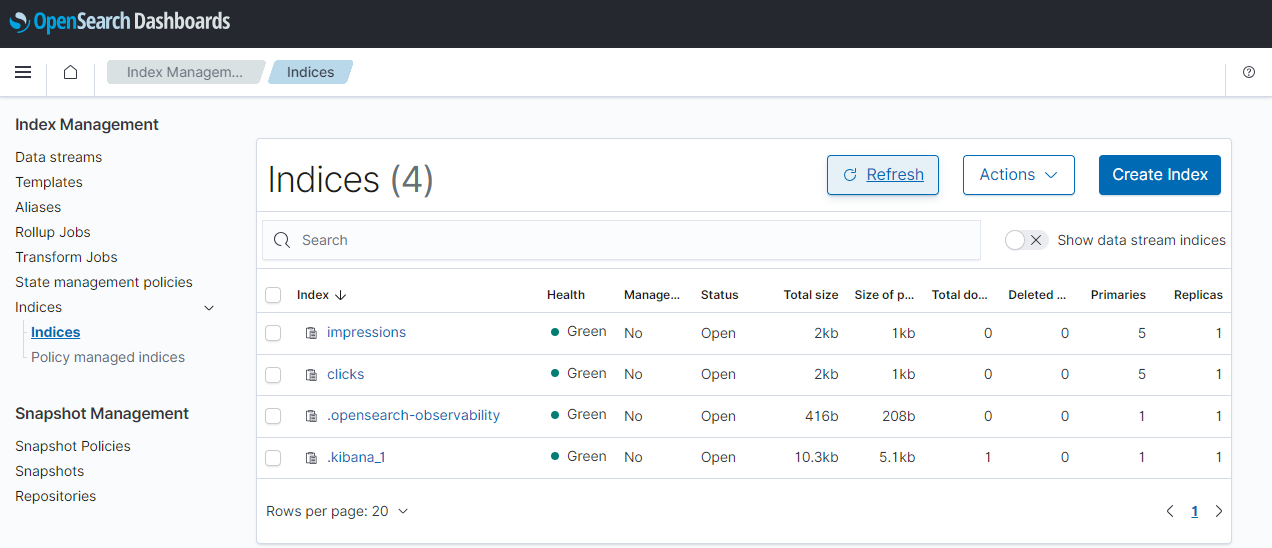
Create Index Mappings
The topic messages include a timestamp field (created_at), but its type is not identified correctly via dynamic mapping. Instead, indexes are created explicitly as shown below. Note that we don’t have to specify user credentials because anonymous authentication is enabled. Make sure to connect to the VPN server before executing this script.
1# configs/create-index-mappings.sh
2#!/usr/bin/env bash
3OPENSEARCH_ENDPOINT=$(terraform output -json | jq -r '.opensearch_domain_endpoint.value')
4echo "OpenSearch endpoint - $OPENSEARCH_ENDPOINT ..."
5
6echo "Create impressions index and field mapping"
7curl -X PUT "https://$OPENSEARCH_ENDPOINT/impressions" -H 'Content-Type: application/json' -d'
8{
9 "mappings": {
10 "properties": {
11 "bid_id": {
12 "type": "text"
13 },
14 "created_at": {
15 "type": "date",
16 "format": "yyyy-MM-dd HH:mm:ss"
17 },
18 "campaign_id": {
19 "type": "text"
20 },
21 "creative_details": {
22 "type": "keyword"
23 },
24 "country_code": {
25 "type": "keyword"
26 }
27 }
28 }
29}'
30
31echo
32echo "Create clicks index and field mapping"
33curl -X PUT "https://$OPENSEARCH_ENDPOINT/clicks" -H 'Content-Type: application/json' -d'
34{
35 "mappings": {
36 "properties": {
37 "correlation_id": {
38 "type": "text"
39 },
40 "created_at": {
41 "type": "date",
42 "format": "yyyy-MM-dd HH:mm:ss"
43 },
44 "tracker": {
45 "type": "text"
46 }
47 }
48 }
49}'
50
51echo
Once created, we can check them in the OpenSearch Dashboards where its endpoint can be found by executing the following Terraform command.
1$ terraform output -json | jq -r '.opensearch_domain_dashboard_endpoint.value'
Connector IAM Role
For simplicity, a single IAM role will be used for both the source and sink connectors. The custom managed policy has permission on MSK cluster resources (cluster, topic and group). It also has permission on S3 bucket and CloudWatch Log for logging.
1# msk-connect.tf
2resource "aws_iam_role" "kafka_connector_role" {
3 name = "${local.name}-connector-role"
4
5 assume_role_policy = jsonencode({
6 Version = "2012-10-17"
7 Statement = [
8 {
9 Action = "sts:AssumeRole"
10 Effect = "Allow"
11 Sid = ""
12 Principal = {
13 Service = "kafkaconnect.amazonaws.com"
14 }
15 },
16 ]
17 })
18 managed_policy_arns = [
19 "arn:aws:iam::aws:policy/AmazonDynamoDBFullAccess",
20 aws_iam_policy.kafka_connector_policy.arn
21 ]
22}
23
24resource "aws_iam_policy" "kafka_connector_policy" {
25 name = "${local.name}-connector-policy"
26
27 policy = jsonencode({
28 Version = "2012-10-17"
29 Statement = [
30 {
31 Sid = "PermissionOnCluster"
32 Action = [
33 "kafka-cluster:Connect",
34 "kafka-cluster:AlterCluster",
35 "kafka-cluster:DescribeCluster"
36 ]
37 Effect = "Allow"
38 Resource = "arn:aws:kafka:${local.region}:${data.aws_caller_identity.current.account_id}:cluster/${local.name}-msk-cluster/*"
39 },
40 {
41 Sid = "PermissionOnTopics"
42 Action = [
43 "kafka-cluster:*Topic*",
44 "kafka-cluster:WriteData",
45 "kafka-cluster:ReadData"
46 ]
47 Effect = "Allow"
48 Resource = "arn:aws:kafka:${local.region}:${data.aws_caller_identity.current.account_id}:topic/${local.name}-msk-cluster/*"
49 },
50 {
51 Sid = "PermissionOnGroups"
52 Action = [
53 "kafka-cluster:AlterGroup",
54 "kafka-cluster:DescribeGroup"
55 ]
56 Effect = "Allow"
57 Resource = "arn:aws:kafka:${local.region}:${data.aws_caller_identity.current.account_id}:group/${local.name}-msk-cluster/*"
58 },
59 {
60 Sid = "PermissionOnDataBucket"
61 Action = [
62 "s3:ListBucket",
63 "s3:*Object"
64 ]
65 Effect = "Allow"
66 Resource = [
67 "${aws_s3_bucket.default_bucket.arn}",
68 "${aws_s3_bucket.default_bucket.arn}/*"
69 ]
70 },
71 {
72 Sid = "LoggingPermission"
73 Action = [
74 "logs:CreateLogStream",
75 "logs:CreateLogGroup",
76 "logs:PutLogEvents"
77 ]
78 Effect = "Allow"
79 Resource = "*"
80 },
81 ]
82 })
83}
Source Connector
The connector source will be uploaded into S3 followed by creating a customer plugin. Then the source connector will be created using the custom plugin and deployed in private subnets.
When it comes to the connector configuration, the first six attributes are in relation to general configurations. The connector class (connector.class) is required for any connector and I set it for the MSK Data Generator. Also, two tasks are allocated to it (tasks.max). The message key is set to be converted into string (key.converter) while the value to json (value.converter). The former is because the keys are configured to have string primitive values (genkp) by the source connector. Finally, schemas are not enabled for both the key and value.
The remaining attributes are for the MSK Data Generator. Two topics named impressions and clicks will be created, and the messages attributes are generated by the Java faker library. Interestingly the bid ID of the impression message and the correlation ID of the click message share the same value sometimes. This is because only a fraction of impressions results in clicks in practice.
1resource "aws_mskconnect_connector" "msk_data_generator" {
2 count = var.to_create_connector ? 1 : 0
3 name = "${local.name}-ad-tech-source"
4
5 kafkaconnect_version = "2.7.1"
6
7 capacity {
8 provisioned_capacity {
9 mcu_count = 1
10 worker_count = 1
11 }
12 }
13
14 connector_configuration = {
15 # connector configuration
16 "connector.class" = "com.amazonaws.mskdatagen.GeneratorSourceConnector",
17 "tasks.max" = "2",
18 "key.converter" = "org.apache.kafka.connect.storage.StringConverter",
19 "key.converter.schemas.enable" = false,
20 "value.converter" = "org.apache.kafka.connect.json.JsonConverter",
21 "value.converter.schemas.enable" = false,
22 # msk data generator configuration
23 "genkp.impressions.with" = "#{Code.isbn10}"
24 "genv.impressions.bid_id.with" = "#{Code.isbn10}"
25 "genv.impressions.campaign_id.with" = "#{Code.isbn10}"
26 "genv.impressions.creative_details.with" = "#{Color.name}"
27 "genv.impressions.country_code.with" = "#{Address.countryCode}"
28 "genkp.clicks.with" = "#{Code.isbn10}"
29 "genv.clicks.correlation_id.sometimes.matching" = "impressions.value.bid_id"
30 "genv.clicks.correlation_id.sometimes.with" = "NA"
31 "genv.clicks.tracker.with" = "#{Lorem.characters '15'}"
32 "global.throttle.ms" = "500"
33 "global.history.records.max" = "1000"
34 }
35
36 kafka_cluster {
37 apache_kafka_cluster {
38 bootstrap_servers = aws_msk_cluster.msk_data_cluster.bootstrap_brokers_sasl_iam
39
40 vpc {
41 security_groups = [aws_security_group.msk.id]
42 subnets = module.vpc.private_subnets
43 }
44 }
45 }
46
47 kafka_cluster_client_authentication {
48 authentication_type = "IAM"
49 }
50
51 kafka_cluster_encryption_in_transit {
52 encryption_type = "TLS"
53 }
54
55 plugin {
56 custom_plugin {
57 arn = aws_mskconnect_custom_plugin.msk_data_generator.arn
58 revision = aws_mskconnect_custom_plugin.msk_data_generator.latest_revision
59 }
60 }
61
62 log_delivery {
63 worker_log_delivery {
64 cloudwatch_logs {
65 enabled = true
66 log_group = aws_cloudwatch_log_group.msk_data_generator.name
67 }
68 s3 {
69 enabled = true
70 bucket = aws_s3_bucket.default_bucket.id
71 prefix = "logs/msk/connect/msk-data-generator"
72 }
73 }
74 }
75
76 service_execution_role_arn = aws_iam_role.kafka_connector_role.arn
77}
78
79resource "aws_mskconnect_custom_plugin" "msk_data_generator" {
80 name = "${local.name}-msk-data-generator"
81 content_type = "JAR"
82
83 location {
84 s3 {
85 bucket_arn = aws_s3_bucket.default_bucket.arn
86 file_key = aws_s3_object.msk_data_generator.key
87 }
88 }
89}
90
91resource "aws_s3_object" "msk_data_generator" {
92 bucket = aws_s3_bucket.default_bucket.id
93 key = "plugins/msk-data-generator.jar"
94 source = "connectors/msk-datagen/msk-data-generator.jar"
95
96 etag = filemd5("connectors/msk-datagen/msk-data-generator.jar")
97}
98
99resource "aws_cloudwatch_log_group" "msk_data_generator" {
100 name = "/msk/connect/msk-data-generator"
101
102 retention_in_days = 1
103
104 tags = local.tags
105}
Sink Connector
Similar to the source connector, the sink connector will be deployed using a customer plugin where its source is uploaded into S3. It is marked to depend on the source connector so that it will be created only after the source connector is deployed successfully.
For connector configuration, it is configured to write messages from the impressions and clicks topics into the OpenSearch indexes created earlier. It uses the same key and value converters to the source connector, and schemas are not enabled for both the key and value.
The OpenSearch domain endpoint is added to the connection URL attribute (connection.url), and this is the only necessary attribute for making HTTP requests thanks to anonymous authentication. Also, as the topics are append-only logs, we can set the document ID to be [topic-name].[partition].[offset] by setting key.ignore to true. See the connector configuration document for more details.
Having an event timestamp attribute can be useful for performing temporal analysis. As I don’t find a comprehensive way to set it up in the source connector, a new field called created_at is added using single message transforms (SMTs). Specifically I added two transforms - insertTS and formatTS. As the name suggests, the former inserts the system timestamp value while it is formatted into yyyy-MM-dd HH:mm:ss by the latter.
1resource "aws_mskconnect_connector" "opensearch_sink" {
2 count = var.to_create_connector ? 1 : 0
3 name = "${local.name}-ad-tech-sink"
4
5 kafkaconnect_version = "2.7.1"
6
7 capacity {
8 provisioned_capacity {
9 mcu_count = 1
10 worker_count = 1
11 }
12 }
13
14 connector_configuration = {
15 # connector configuration
16 "connector.class" = "io.aiven.kafka.connect.opensearch.OpensearchSinkConnector",
17 "tasks.max" = "2",
18 "topics" = "impressions,clicks",
19 "key.converter" = "org.apache.kafka.connect.storage.StringConverter",
20 "key.converter.schemas.enable" = false,
21 "value.converter" = "org.apache.kafka.connect.json.JsonConverter",
22 "value.converter.schemas.enable" = false,
23 # opensearch sink configuration
24 "connection.url" = "https://${aws_opensearch_domain.opensearch.endpoint}",
25 "schema.ignore" = true,
26 "key.ignore" = true,
27 "type.name" = "_doc",
28 "behavior.on.malformed.documents" = "fail",
29 "behavior.on.null.values" = "ignore",
30 "behavior.on.version.conflict" = "ignore",
31 # dead-letter-queue configuration
32 "errors.deadletterqueue.topic.name" = "ad-tech-dl",
33 "errors.tolerance" = "all",
34 "errors.deadletterqueue.context.headers.enable" = true,
35 "errors.deadletterqueue.topic.replication.factor" = "1",
36 # single message transforms
37 "transforms" = "insertTS,formatTS",
38 "transforms.insertTS.type" = "org.apache.kafka.connect.transforms.InsertField$Value",
39 "transforms.insertTS.timestamp.field" = "created_at",
40 "transforms.formatTS.type" = "org.apache.kafka.connect.transforms.TimestampConverter$Value",
41 "transforms.formatTS.format" = "yyyy-MM-dd HH:mm:ss",
42 "transforms.formatTS.field" = "created_at",
43 "transforms.formatTS.target.type" = "string"
44 }
45
46 kafka_cluster {
47 apache_kafka_cluster {
48 bootstrap_servers = aws_msk_cluster.msk_data_cluster.bootstrap_brokers_sasl_iam
49
50 vpc {
51 security_groups = [aws_security_group.msk.id]
52 subnets = module.vpc.private_subnets
53 }
54 }
55 }
56
57 kafka_cluster_client_authentication {
58 authentication_type = "IAM"
59 }
60
61 kafka_cluster_encryption_in_transit {
62 encryption_type = "TLS"
63 }
64
65 plugin {
66 custom_plugin {
67 arn = aws_mskconnect_custom_plugin.opensearch_sink.arn
68 revision = aws_mskconnect_custom_plugin.opensearch_sink.latest_revision
69 }
70 }
71
72 log_delivery {
73 worker_log_delivery {
74 cloudwatch_logs {
75 enabled = true
76 log_group = aws_cloudwatch_log_group.opensearch_sink.name
77 }
78 s3 {
79 enabled = true
80 bucket = aws_s3_bucket.default_bucket.id
81 prefix = "logs/msk/connect/opensearch-sink"
82 }
83 }
84 }
85
86 service_execution_role_arn = aws_iam_role.kafka_connector_role.arn
87
88 depends_on = [
89 aws_mskconnect_connector.msk_data_generator
90 ]
91}
92
93resource "aws_mskconnect_custom_plugin" "opensearch_sink" {
94 name = "${local.name}-opensearch-sink"
95 content_type = "ZIP"
96
97 location {
98 s3 {
99 bucket_arn = aws_s3_bucket.default_bucket.arn
100 file_key = aws_s3_object.opensearch_sink.key
101 }
102 }
103}
104
105resource "aws_s3_object" "opensearch_sink" {
106 bucket = aws_s3_bucket.default_bucket.id
107 key = "plugins/opensearch-connector.zip"
108 source = "connectors/opensearch-connector.zip"
109
110 etag = filemd5("connectors/opensearch-connector.zip")
111}
112
113resource "aws_cloudwatch_log_group" "opensearch_sink" {
114 name = "/msk/connect/opensearch-sink"
115
116 retention_in_days = 1
117
118 tags = local.tags
119}
Deploy Connectors
The connectors can be deployed while setting the value of to_create_connector to true as shown below.
1$ terraform plan -var to_create_connector=true
2$ terraform apply --auto-approve=true -var to_create_connector=true
Once completed, we can check the source and sink connectors on AWS Console as following.
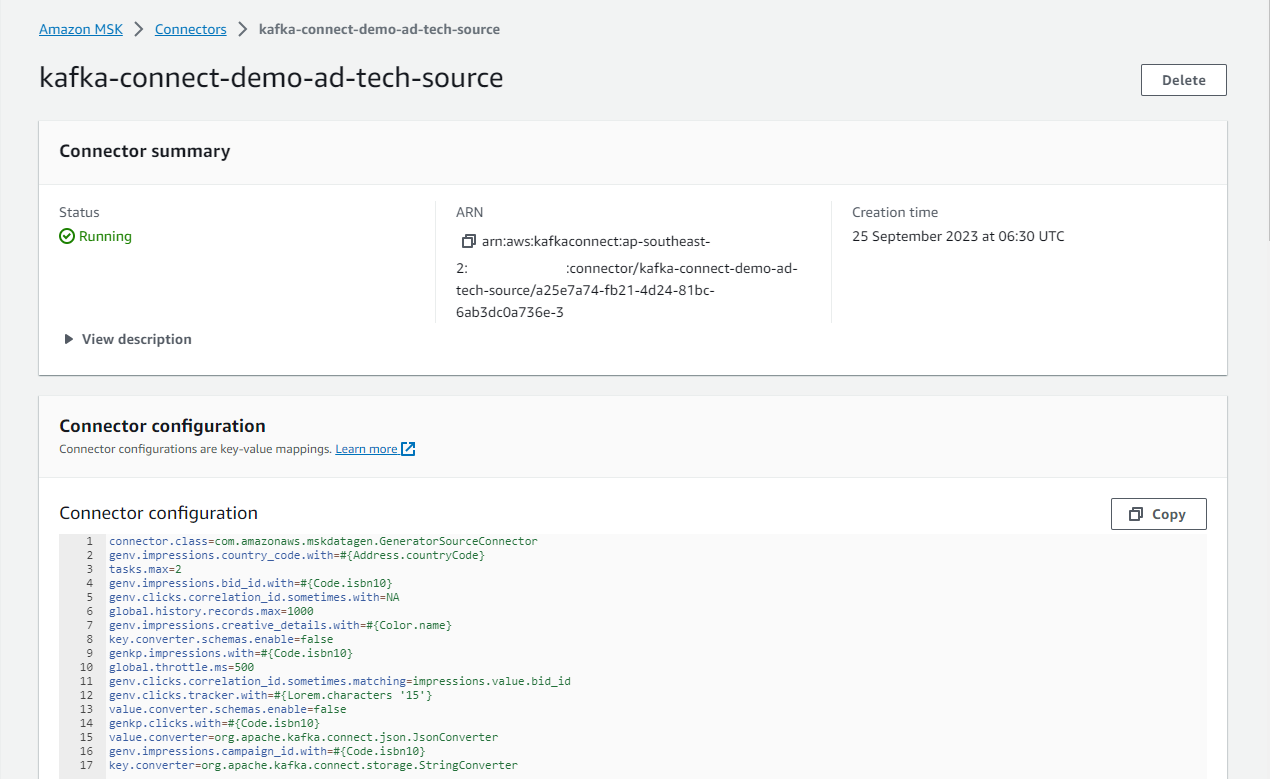
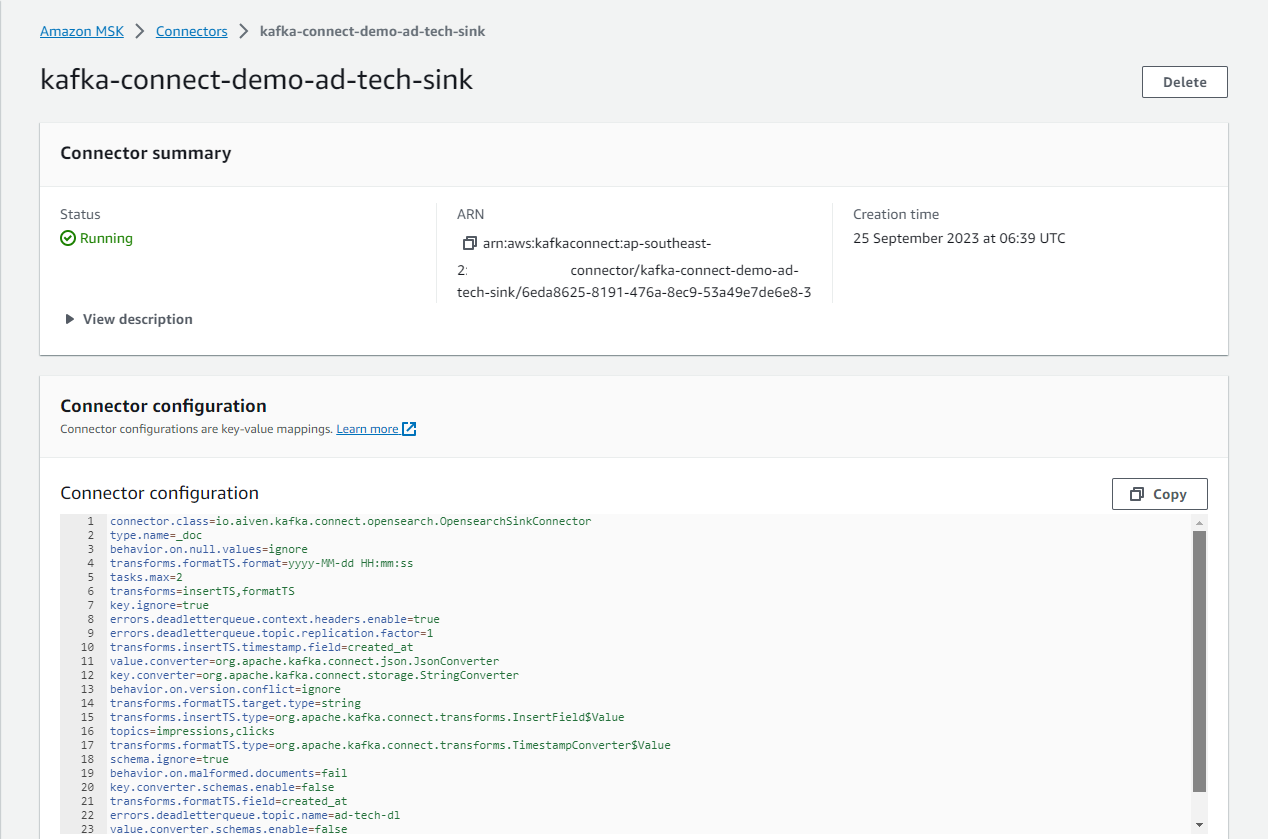
Source Data
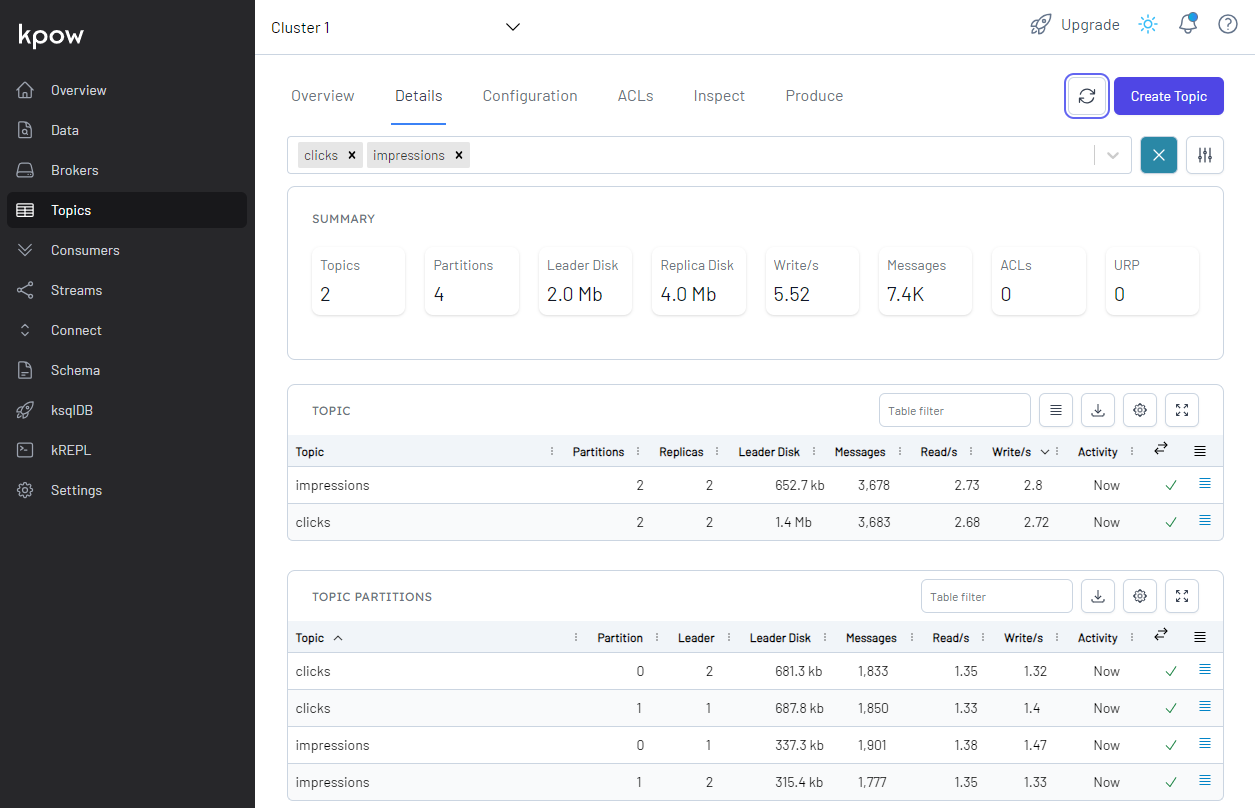
We can use Kpow to see the details of the impressions and clicks topics on localhost:3000. Make sure to connect to the VPN server, or it fails to access the MSK cluster.
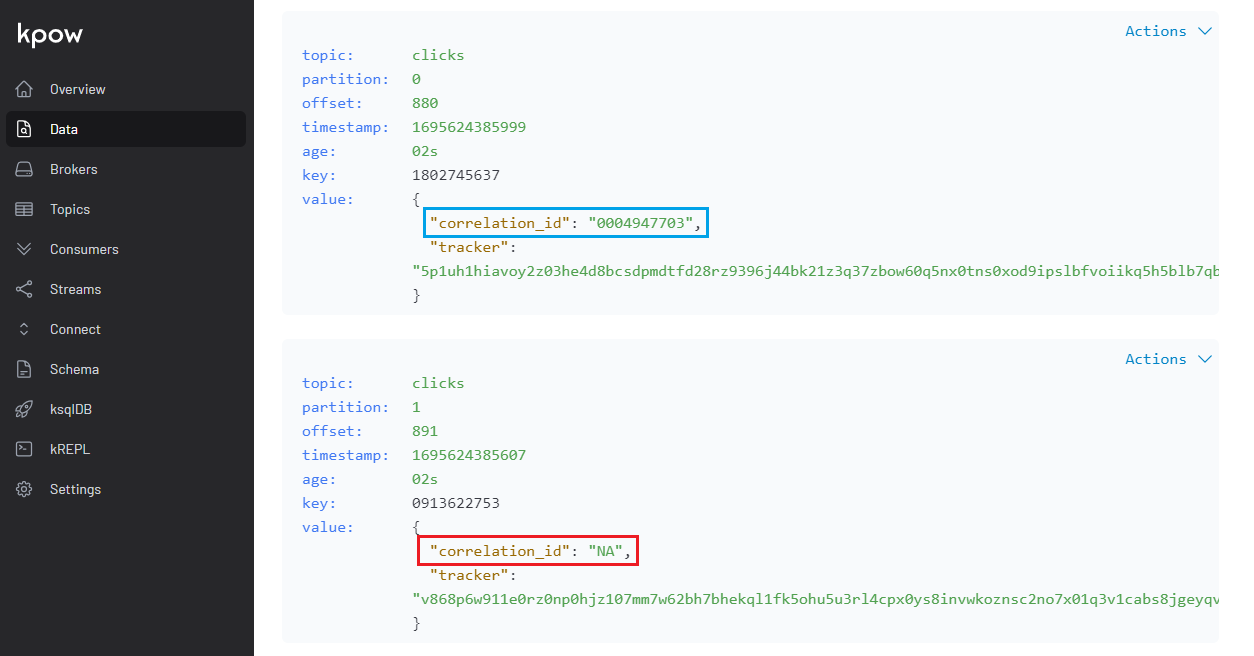
As mentioned earlier, only a fraction of correlation IDs of the click messages has actual values, and we can see that by inspecting the messages of the clicks topic.
OpenSearch Dashboard
In OpenSearch Dashboards, we can search clicks that are associated with impressions. As expected, only a small portion of clicks are searched.
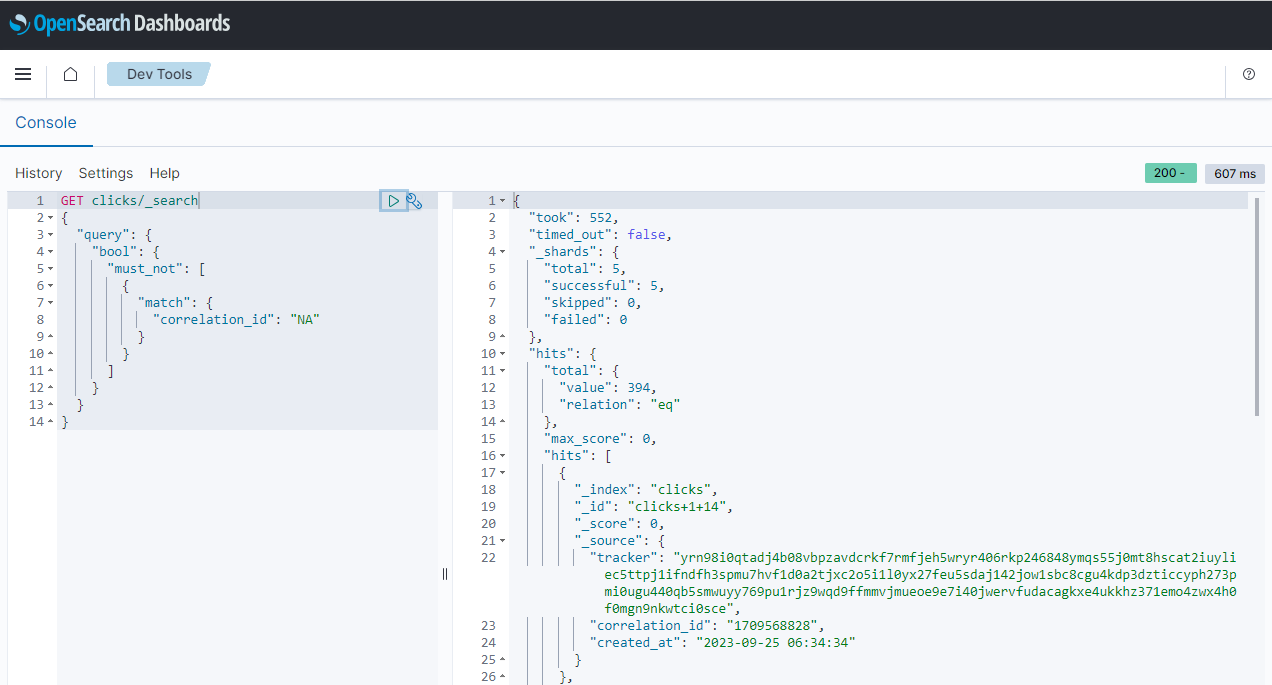
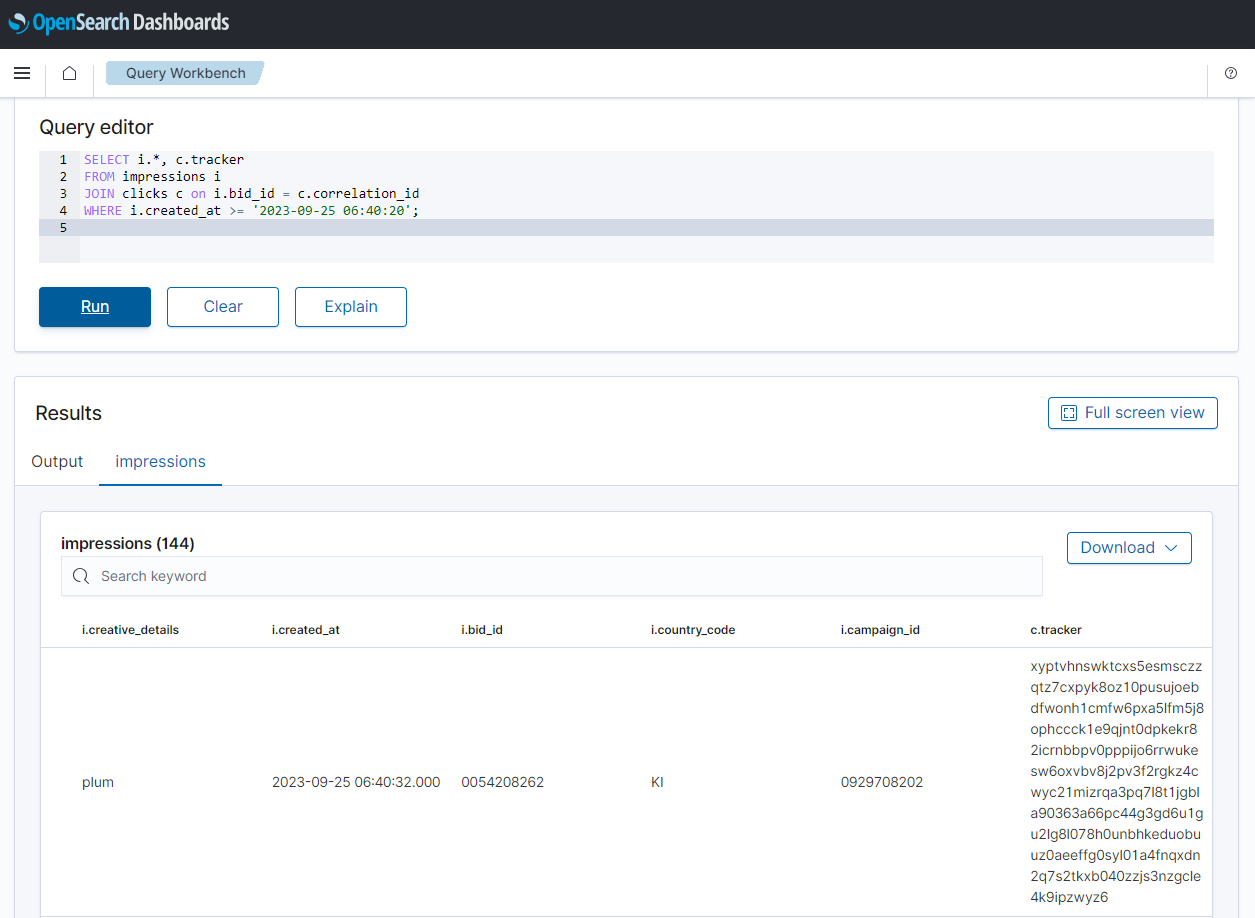
Moreover, we can join correlated impressions and clicks quickly using the Query Workbench. Below shows a simple SQL query that joins impressions and associating clicks that are created after a certain time point.
Destroy Resources
As all resources are created by Terraform, they can be destroyed by a single command as shown below.
1$ terraform destroy --auto-approve=true -var to_create_connector=true
Summary
In the previous post, we discussed how to develop a data pipeline from Apache Kafka into OpenSearch locally using Docker. The pipeline was deployed on AWS using Amazon MSK, Amazon MSK Connect and Amazon OpenSearch Service using Terraform in this post. First the infrastructure was deployed that covers a Virtual Private Cloud (VPC), Virtual Private Network (VPN) server, MSK Cluster and OpenSearch domain. Then Kafka source and sink connectors were deployed on MSK Connect, followed by performing quick data analysis. It turns out that Kafka Connect can be effective for ingesting data from Kafka into OpenSearch.










Comments