
Stream processing technology is becoming more and more popular with companies big and small because it provides superior solutions for many established use cases such as data analytics, ETL, and transactional applications, but also facilitates novel applications, software architectures, and business opportunities. Beginning with traditional data infrastructures and application/data development patterns, this post introduces stateful stream processing and demonstrates to what extent it can improve the traditional development patterns. A consulting company can partner with her clients on their journeys of adopting stateful stream processing, and it can bring huge opportunities. Those opportunities are summarised at the end.
Note Section 1 and 2 are based on Stream Processing with Apache Flink by Fabian Hueske and Vasiliki Kalavri (O’Reilly). You can see the original article on the publisher website.
1. Traditional Data Infrastructures
1.1 Transactional Processing
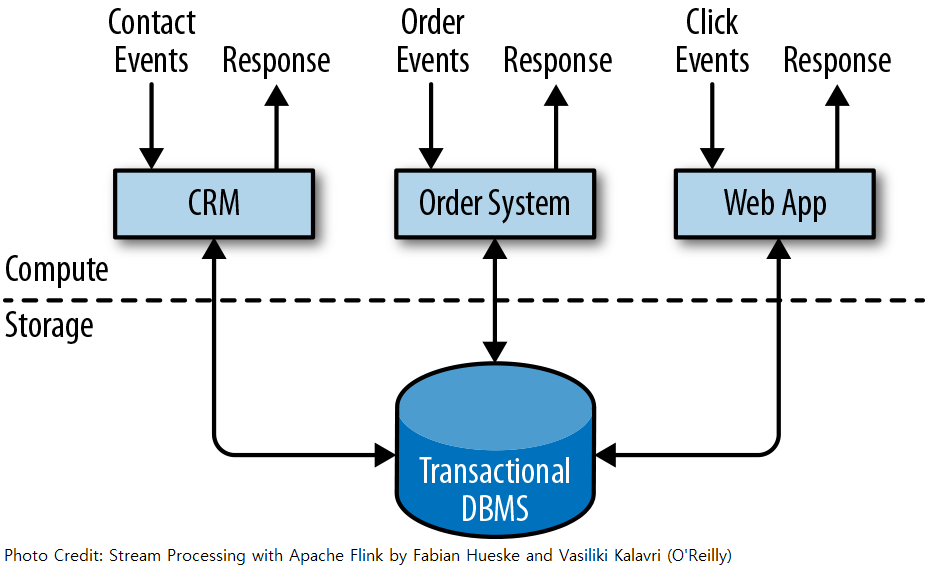
Applications are usually connected to external services or face human users and continuously process incoming events such as orders, email, or clicks on a website. When an event is processed, an application reads its state or updates it by running transactions against the remote database system. Often, a database system serves multiple applications that sometimes access the same databases or tables. Since multiple applications might work on the same data representation or share the same infrastructure, changing the schema of a table or scaling a database system requires careful planning and a lot of effort.
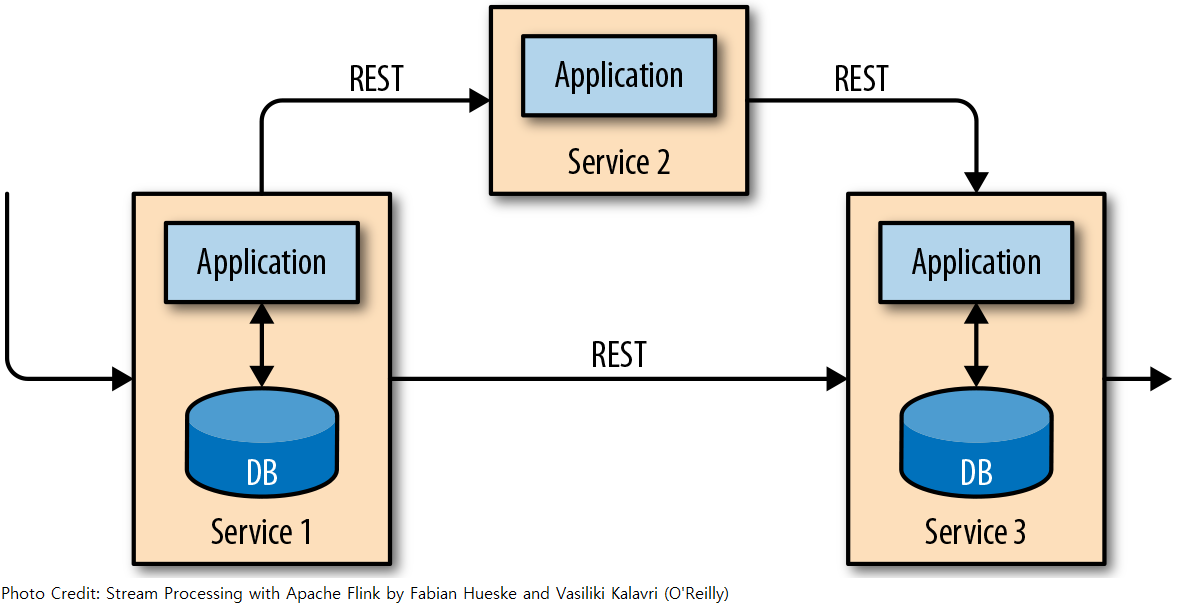
A recent approach to overcoming the tight bundling of applications is the microservices design pattern. Microservices are designed as small, self-contained, and independent applications. More complex applications are built by connecting several microservices with each other that only communicate over standardised interfaces such as RESTful HTTP or gRPC connections.
1.2 Analytical Processing
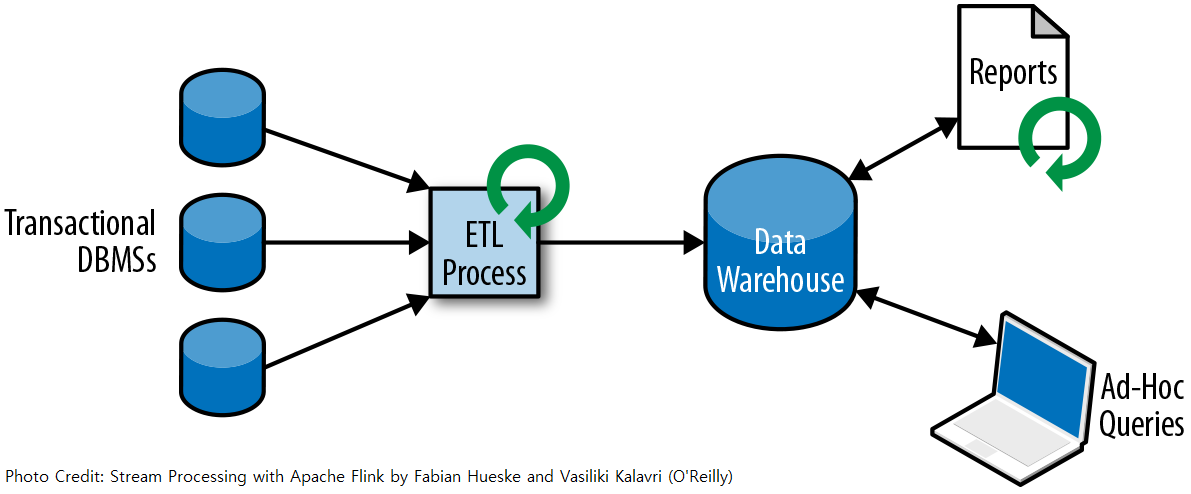
Transactional data is often distributed across several disconnected database systems and is more valuable when it can be jointly analysed. Moreover, the data often needs to be transformed into a common format. Therefore the data is typically replicated to a data warehouse, a dedicated datastore for analytical query workloads.
An ETL process extracts data from a transactional database, transforms it into a common representation that might include validation, value normalisation, encoding, deduplication, and schema transformation, and finally loads it into the analytical database. ETL processes can be quite complex and often require technically sophisticated solutions to meet performance requirements. ETL processes need to run periodically to keep the data in the data warehouse synchronised.
2. Stateful Stream Processing
Stateful stream processing is an application design pattern for processing unbounded streams of events and is applicable to many different use cases in the IT infrastructure of a company.
Stateful stream processing applications often ingest their incoming events from an event log. An event log stores and distributes event streams. Events are written to a durable, append-only log, which means that the order of written events cannot be changed. A stream that is written to an event log can be read many times by the same or different consumers. Due to the append-only property of the log, events are always published to all consumers in exactly the same order.
2.1 Event-Driven Applications
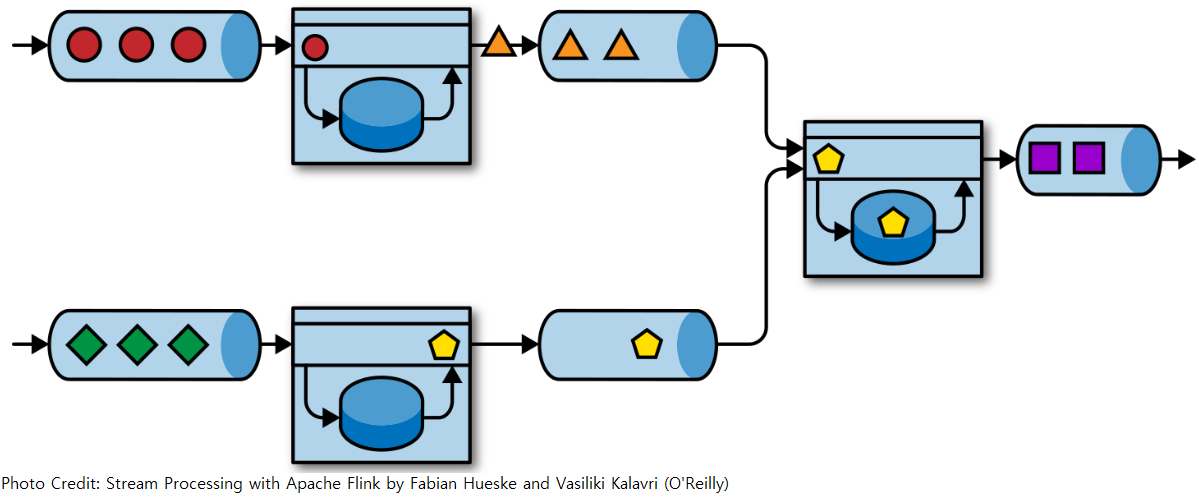
Event-driven applications are stateful streaming applications that ingest event streams and process the events with application-specific business logic. Depending on the business logic, an event-driven application can trigger actions such as sending an alert or an email or write events to an outgoing event stream to be consumed by another event-driven application.
Typical use cases for event-driven applications include
- Real-time recommendations (e.g., for recommending products while customers browse a retailer’s website)
- Pattern detection or complex event processing (e.g., for fraud detection in credit card transactions)
- Anomaly detection (e.g., to detect attempts to intrude a computer network)
Event-driven applications are an evolution of microservices. They communicate via event logs instead of REST or gRPC calls and hold application data as local state instead of writing it to and reading it from an external datastore, such as a relational database or key-value store.
Event logs decouple senders and receivers and provide asynchronous, non-blocking event transfer. Applications can be stateful and can locally manage their own state without accessing external datastores. Also, they can be individually operated and scaled.
Event-driven applications offer several benefits compared to transactional applications or microservices. Local state access provides very good performance compared to reading and writing queries against remote datastores. Scaling and fault tolerance are handled by the stream processor, and, by leveraging an event log as the input source, the complete input of an application is reliably stored and can be deterministically replayed.
2.2 Data Pipelines
Today’s IT architectures include many different datastores, such as relational and special-purpose database systems, event logs, distributed filesystems, in-memory caches, and search indexes.
A traditional approach to synchronise data in different storage systems is periodic ETL jobs. However, they do not meet the latency requirements for many of today’s use cases. An alternative is to use an event log to distribute updates. The updates are written to and distributed by the event log. Consumers of the log incorporate the updates into the affected data stores. Depending on the use case, the transferred data may need to be normalised, enriched with external data, or aggregated before it is ingested by the target data store.
Ingesting, transforming, and inserting data with low latency is another common use case for stateful stream processing applications. This type of application is called a data pipeline. Data pipelines must be able to process large amounts of data in a short time. A stream processor that operates a data pipeline should also feature many source and sink connectors to read data from and write data to various storage systems.
2.3 Streaming Analytics
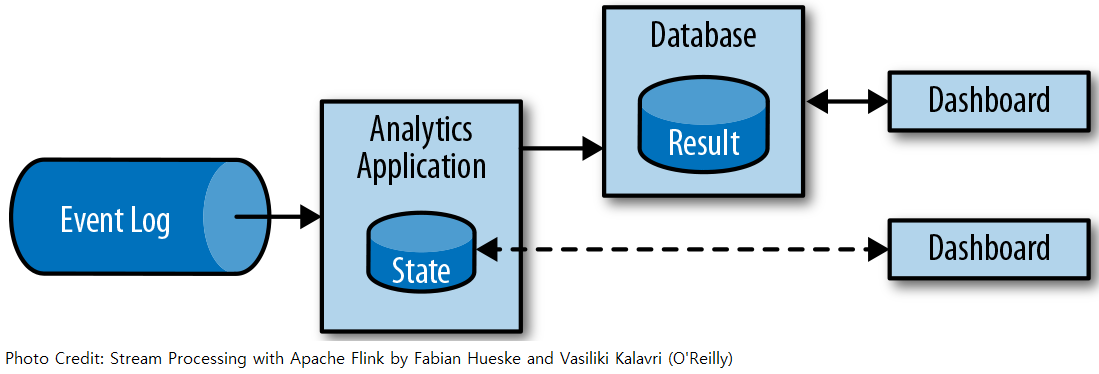
ETL jobs periodically import data into a datastore and the data is processed by ad-hoc or scheduled queries, which adds considerable latency to the analytics pipeline.
Instead of waiting to be periodically triggered, a streaming analytics application continuously ingests streams of events and updates its result by incorporating the latest events with low latency. Typically, streaming applications store their result in an external data store that supports efficient updates, such as a database, key-value store or search engine. The live updated results of a streaming analytics application can be used to power dashboard applications.
Streaming analytics applications are commonly used for:
- Monitoring the quality of cellphone networks
- Analysing user behaviour in mobile applications
- Ad-hoc analysis of live data in consumer technology
3. Opportunities of Stateful Stream Processing
Each of the application areas of the stateful stream processing pattern mentioned above can bring opportunities and it falls into either application modernisation and data engineering.
Event-driven application is in relation to application modernisation. On AWS, I don’t see many examples of implementing stateful stream processing in event-driven application development. Rather they focus on how to make use of their serverless services (EventBridge, Step Functions, SQS, SNS and Lambda) together, but it could miss some benefits of stateful stream processing such as local state access and deterministic replay of complete input. I find application architecture can be simpler with stateful stream processing than combining a wide range of AWS services, and it would bring value to customers.
Data pipeline and streaming analytics are key opportunities in data engineering. The former is already popular especially thanks to Change Data Capture (CDC) and I see many customers implement it already or are highly interested in it. I still don’t see wide-spread adoption of streaming analytics among customers. However, as the latest generation of stream processors including Apache Flink provide accurate stream processing with high throughput and low latency at scale, I consider it is a matter of time until streaming analytics plays a central role for serving analytical processing needs.
Building and maintaining stream processing infrastructure for clients can be an opportunity in application modernisation as well. First of all, Apache Kafka can be used as a distributed event store and it plays a key role because stream processing applications tend to read from or write to an event store. Kafka Connect can also be important as a tool for streaming data between Apache Kafka and other data systems by connectors in a scalable and reliable way. On AWS, there are multiple options and some of them cover Amazon MSK, Confluent Platform via Amazon Marketplace and self-managed cluster on Amazon EKS. Secondly, Apache Flink can be used as the main stream processor as it supports key requirements - state handling, event-time processing, exactly-once state consistency, recovery from failure to name a few. On AWS, Amazon Managed Service for Apache Flink is the easiest option. Moreover EMR on EKS supports Flink workloads (in preview) and self-managed applications can run on Amazon EKS. Lastly, Amazon EKS can be beneficial for deploying applications and workloads related to stateful stream processing in a more efficient manner.










Comments