
[UPDATE 2025-10-01]
Bitnami’s public Docker images have been moved to the Bitnami Legacy repository. To ensure continued access and compatibility, please update your Docker image references accordingly.
For example:
bitnami/kafka:2.8.1→bitnamilegacy/kafka:2.8.1bitnami/zookeeper:3.7.0→bitnamilegacy/zookeeper:3.7.0bitnami/python:3.9.0→bitnamilegacy/python:3.9.0
In this lab, we will create a Pyflink application that exports Kafka topic messages into a S3 bucket. The app enriches the records by adding a new column using a user defined function and writes them via the FileSystem SQL connector. This allows us to achieve a simpler architecture compared to the original lab where the records are sent into Amazon Kinesis Data Firehose, enriched by a separate Lambda function and written to a S3 bucket afterwards. While the records are being written to the S3 bucket, a Glue table will be created to query them on Amazon Athena.
- Introduction
- Lab 1 Produce data to Kafka using Lambda
- Lab 2 Write data to Kafka from S3 using Flink
- Lab 3 Transform and write data to S3 from Kafka using Flink (this post)
- Lab 4 Clean, Aggregate, and Enrich Events with Flink
- Lab 5 Write data to DynamoDB using Kafka Connect
- Lab 6 Consume data from Kafka using Lambda
[Update 2023-11-22] Amazon MSK now supports fully managed data delivery to Amazon S3 using Kinesis Data Firehose, and you may consider this feature rather than relying on a Flink application. See this page for details.
Architecture
Fake taxi ride data is sent to a Kafka topic by the Kafka producer application that is discussed in Lab 1. The records are read by a Pyflink application, and it writes them into a S3 bucket. The app enriches the records by adding a new column named source using a user defined function. The records in the S3 bucket can be queried on Amazon Athena after creating an external table that sources the bucket.
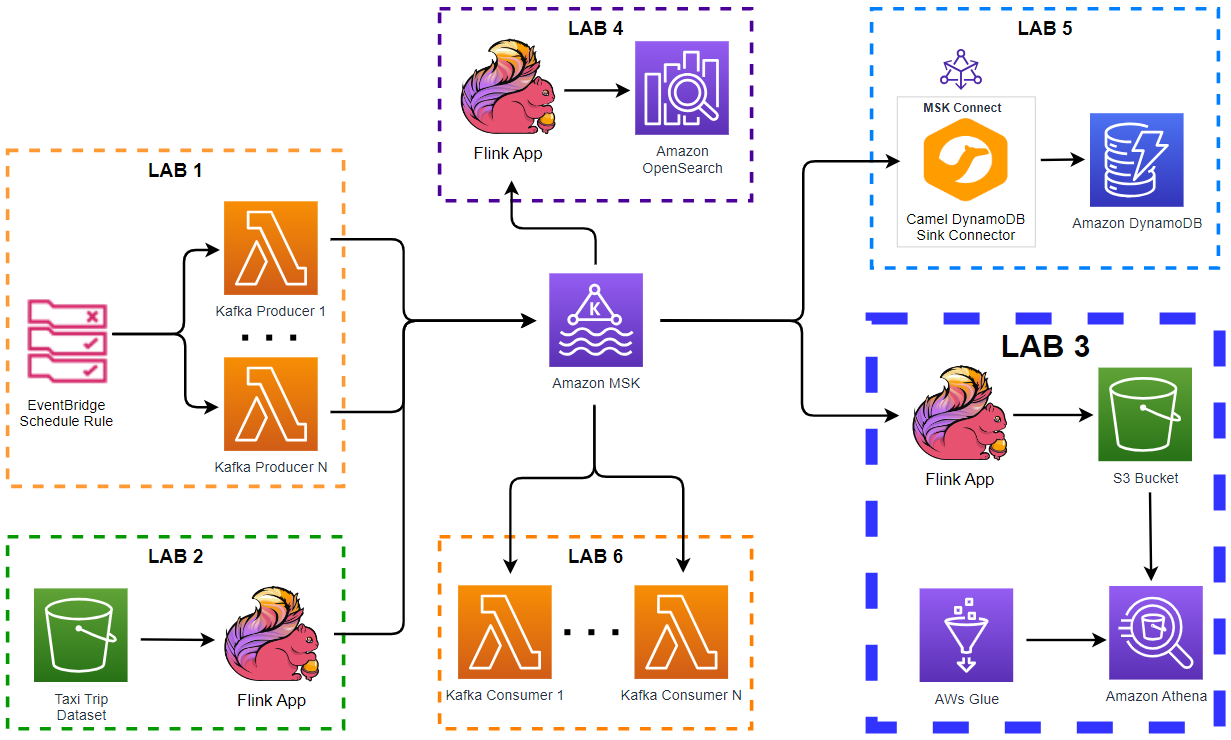
Infrastructure
AWS Infrastructure
The AWS infrastructure is created using Terraform and the source can be found in the GitHub repository of this post - see this earlier post for details about how to create the resources. The infrastructure can be deployed (as well as destroyed) using Terraform CLI as shown below.
1# initialize
2terraform init
3# create an execution plan
4terraform plan -var 'producer_to_create=true'
5# execute the actions proposed in a Terraform plan
6terraform apply -auto-approve=true -var 'producer_to_create=true'
7
8# destroy all remote objects
9# terraform destroy -auto-approve=true -var 'producer_to_create=true'
Note that deploying the AWS infrastructure is optional because we can create a local Kafka and Flink cluster on Docker for testing easily. We will not use a Kafka cluster deployed on MSK in this post.
Kafka and Flink Cluster on Docker Compose
In the previous post, we discussed how to create a local Flink cluster on Docker. We can add additional Docker Compose services (zookeeper and kafka-0) for a Kafka cluster and the updated compose file can be found below. See this post for details how to set up a Kafka cluster on Docker.
1# compose-local-kafka.yml
2# see compose-msk.yml for an msk cluster instead of a local kafka cluster
3version: "3.5"
4
5services:
6 jobmanager:
7 image: real-time-streaming-aws:1.17.1
8 command: jobmanager
9 container_name: jobmanager
10 ports:
11 - "8081:8081"
12 networks:
13 - appnet
14 volumes:
15 - ./:/etc/flink
16 environment:
17 - BOOTSTRAP_SERVERS=kafka-0:9092
18 - RUNTIME_ENV=DOCKER
19 - AWS_ACCESS_KEY_ID=$AWS_ACCESS_KEY_ID
20 - AWS_SECRET_ACCESS_KEY=$AWS_SECRET_ACCESS_KEY
21 # - AWS_SESSION_TOKEN=$AWS_SESSION_TOKEN
22 - |
23 FLINK_PROPERTIES=
24 jobmanager.rpc.address: jobmanager
25 state.backend: filesystem
26 state.checkpoints.dir: file:///tmp/flink-checkpoints
27 heartbeat.interval: 1000
28 heartbeat.timeout: 5000
29 rest.flamegraph.enabled: true
30 web.backpressure.refresh-interval: 10000
31 taskmanager:
32 image: real-time-streaming-aws:1.17.1
33 command: taskmanager
34 container_name: taskmanager
35 networks:
36 - appnet
37 volumes:
38 - flink_data:/tmp/
39 - ./:/etc/flink
40 environment:
41 - BOOTSTRAP_SERVERS=kafka-0:9092
42 - RUNTIME_ENV=DOCKER
43 - AWS_ACCESS_KEY_ID=$AWS_ACCESS_KEY_ID
44 - AWS_SECRET_ACCESS_KEY=$AWS_SECRET_ACCESS_KEY
45 # - AWS_SESSION_TOKEN=$AWS_SESSION_TOKEN
46 - |
47 FLINK_PROPERTIES=
48 jobmanager.rpc.address: jobmanager
49 taskmanager.numberOfTaskSlots: 5
50 state.backend: filesystem
51 state.checkpoints.dir: file:///tmp/flink-checkpoints
52 heartbeat.interval: 1000
53 heartbeat.timeout: 5000
54 depends_on:
55 - jobmanager
56 zookeeper:
57 image: bitnami/zookeeper:3.5
58 container_name: zookeeper
59 ports:
60 - "2181"
61 networks:
62 - appnet
63 environment:
64 - ALLOW_ANONYMOUS_LOGIN=yes
65 volumes:
66 - zookeeper_data:/bitnami/zookeeper
67 kafka-0:
68 image: bitnami/kafka:2.8.1
69 container_name: kafka-0
70 expose:
71 - 9092
72 ports:
73 - "29092:29092"
74 networks:
75 - appnet
76 environment:
77 - ALLOW_PLAINTEXT_LISTENER=yes
78 - KAFKA_CFG_ZOOKEEPER_CONNECT=zookeeper:2181
79 - KAFKA_CFG_BROKER_ID=0
80 - KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=INTERNAL:PLAINTEXT,EXTERNAL:PLAINTEXT
81 - KAFKA_CFG_LISTENERS=INTERNAL://:9092,EXTERNAL://:29092
82 - KAFKA_CFG_ADVERTISED_LISTENERS=INTERNAL://kafka-0:9092,EXTERNAL://localhost:29092
83 - KAFKA_CFG_INTER_BROKER_LISTENER_NAME=INTERNAL
84 - KAFKA_CFG_NUM_PARTITIONS=5
85 - KAFKA_CFG_DEFAULT_REPLICATION_FACTOR=1
86 - KAFKA_CFG_AUTO_CREATE_TOPICS_ENABLE=true
87 volumes:
88 - kafka_0_data:/bitnami/kafka
89 depends_on:
90 - zookeeper
91 kpow:
92 image: factorhouse/kpow-ce:91.5.1
93 container_name: kpow
94 ports:
95 - "3000:3000"
96 networks:
97 - appnet
98 environment:
99 BOOTSTRAP: kafka-0:9092
100 env_file: # https://kpow.io/get-started/#individual
101 - ./kpow.env
102 depends_on:
103 - zookeeper
104 - kafka-0
105
106networks:
107 appnet:
108 name: app-network
109
110volumes:
111 zookeeper_data:
112 driver: local
113 name: zookeeper_data
114 kafka_0_data:
115 driver: local
116 name: kafka_0_data
117 flink_data:
118 driver: local
119 name: flink_data
The Docker Compose services can be deployed as shown below.
1$ docker-compose -f compose-local-kafka.yml up -d
Pyflink Application
Flink Pipeline Jar
The application has multiple dependencies and a single Jar file is created so that it can be specified in the --jarfile option. Note that we have to build the Jar file based on the Apache Kafka Connector instead of the Apache Kafka SQL Connector because the MSK IAM Auth library is not compatible with the latter due to shade relocation. The dependencies can be grouped as shown below.
- Flink Connectors
- flink-connector-base
- flink-connector-files
- flink-connector-kafka
- Each of them can be placed in the Flink library folder (/opt/flink/lib)
- Parquet Format
- flink-parquet
- hadoop dependencies
- parquet-hadoop
- hadoop-common
- hadoop-mapreduce-client-core
- All of them can be combined as a single Jar file and be placed in the Flink library folder (/opt/flink/lib)
- Kafka Communication and IAM Authentication
- kafka-clients
- for communicating with a Kafka cluster
- It can be placed in the Flink library folder (/opt/flink/lib)
- aws-msk-iam-auth
- for IAM authentication
- It can be placed in the Flink library folder (/opt/flink/lib)
- kafka-clients
A single Jar file is created in this post as the app may need to be deployed via Amazon Managed Flink potentially. If we do not have to deploy on it, however, they can be added to the Flink library folder separately, which is a more comprehensive way of managing dependency in my opinion. I added comments about how they may be placed into the Flink library folder in the dependencies list above. Note that the S3 file system Jar file (flink-s3-fs-hadoop-1.17.1.jar) is placed under the plugins (/opt/flink/plugins/s3-fs-hadoop) folder of the custom Docker image according to the Flink documentation.
The single Uber jar file is created by the following POM file and the Jar file is named as lab3-pipeline-1.0.0.jar.
1<!-- package/lab3-pipeline/pom.xml -->
2<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
3 xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
4 <modelVersion>4.0.0</modelVersion>
5
6 <groupId>com.amazonaws.services.kinesisanalytics</groupId>
7 <artifactId>lab3-pipeline</artifactId>
8 <version>1.0.0</version>
9 <packaging>jar</packaging>
10
11 <name>Uber Jar for Lab 3</name>
12
13 <properties>
14 <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
15 <flink.version>1.17.1</flink.version>
16 <target.java.version>1.11</target.java.version>
17 <jdk.version>11</jdk.version>
18 <scala.binary.version>2.12</scala.binary.version>
19 <kda.connectors.version>2.0.0</kda.connectors.version>
20 <kda.runtime.version>1.2.0</kda.runtime.version>
21 <kafka.clients.version>3.2.3</kafka.clients.version>
22 <hadoop.version>3.2.4</hadoop.version>
23 <flink.format.parquet.version>1.12.3</flink.format.parquet.version>
24 <log4j.version>2.17.1</log4j.version>
25 <aws-msk-iam-auth.version>1.1.7</aws-msk-iam-auth.version>
26 </properties>
27
28 <repositories>
29 <repository>
30 <id>apache.snapshots</id>
31 <name>Apache Development Snapshot Repository</name>
32 <url>https://repository.apache.org/content/repositories/snapshots/</url>
33 <releases>
34 <enabled>false</enabled>
35 </releases>
36 <snapshots>
37 <enabled>true</enabled>
38 </snapshots>
39 </repository>
40 </repositories>
41
42 <dependencies>
43
44 <!-- Flink Connectors -->
45
46 <dependency>
47 <groupId>org.apache.flink</groupId>
48 <artifactId>flink-connector-base</artifactId>
49 <version>${flink.version}</version>
50 </dependency>
51
52 <dependency>
53 <groupId>org.apache.flink</groupId>
54 <artifactId>flink-connector-kafka</artifactId>
55 <version>${flink.version}</version>
56 </dependency>
57
58 <dependency>
59 <groupId>org.apache.flink</groupId>
60 <artifactId>flink-connector-files</artifactId>
61 <version>${flink.version}</version>
62 </dependency>
63
64 <!-- Parquet -->
65 <!-- See https://github.com/apache/flink/blob/release-1.17/flink-formats/flink-parquet/pom.xml -->
66
67 <dependency>
68 <groupId>org.apache.flink</groupId>
69 <artifactId>flink-parquet</artifactId>
70 <version>${flink.version}</version>
71 </dependency>
72
73 <!-- Hadoop is needed by Parquet -->
74
75 <dependency>
76 <groupId>org.apache.parquet</groupId>
77 <artifactId>parquet-hadoop</artifactId>
78 <version>${flink.format.parquet.version}</version>
79 <exclusions>
80 <exclusion>
81 <groupId>org.xerial.snappy</groupId>
82 <artifactId>snappy-java</artifactId>
83 </exclusion>
84 <exclusion>
85 <groupId>commons-cli</groupId>
86 <artifactId>commons-cli</artifactId>
87 </exclusion>
88 </exclusions>
89 </dependency>
90
91 <dependency>
92 <groupId>org.apache.hadoop</groupId>
93 <artifactId>hadoop-common</artifactId>
94 <version>${hadoop.version}</version>
95 <exclusions>
96 <exclusion>
97 <groupId>com.google.protobuf</groupId>
98 <artifactId>protobuf-java</artifactId>
99 </exclusion>
100 <exclusion>
101 <groupId>ch.qos.reload4j</groupId>
102 <artifactId>reload4j</artifactId>
103 </exclusion>
104 <exclusion>
105 <groupId>org.slf4j</groupId>
106 <artifactId>slf4j-reload4j</artifactId>
107 </exclusion>
108 <exclusion>
109 <groupId>commons-cli</groupId>
110 <artifactId>commons-cli</artifactId>
111 </exclusion>
112 </exclusions>
113 </dependency>
114
115 <dependency>
116 <groupId>org.apache.hadoop</groupId>
117 <artifactId>hadoop-mapreduce-client-core</artifactId>
118 <version>${hadoop.version}</version>
119 <exclusions>
120 <exclusion>
121 <groupId>com.google.protobuf</groupId>
122 <artifactId>protobuf-java</artifactId>
123 </exclusion>
124 <exclusion>
125 <groupId>ch.qos.reload4j</groupId>
126 <artifactId>reload4j</artifactId>
127 </exclusion>
128 <exclusion>
129 <groupId>org.slf4j</groupId>
130 <artifactId>slf4j-reload4j</artifactId>
131 </exclusion>
132 <exclusion>
133 <groupId>commons-cli</groupId>
134 <artifactId>commons-cli</artifactId>
135 </exclusion>
136 </exclusions>
137 </dependency>
138
139 <!-- Kafka Client and MSK IAM Auth Lib -->
140
141 <dependency>
142 <groupId>org.apache.kafka</groupId>
143 <artifactId>kafka-clients</artifactId>
144 <version>${kafka.clients.version}</version>
145 </dependency>
146
147 <dependency>
148 <groupId>software.amazon.msk</groupId>
149 <artifactId>aws-msk-iam-auth</artifactId>
150 <version>${aws-msk-iam-auth.version}</version>
151 </dependency>
152
153 <!-- Add logging framework, to produce console output when running in the IDE. -->
154 <!-- These dependencies are excluded from the application JAR by default. -->
155 <dependency>
156 <groupId>org.apache.logging.log4j</groupId>
157 <artifactId>log4j-slf4j-impl</artifactId>
158 <version>${log4j.version}</version>
159 <scope>runtime</scope>
160 </dependency>
161 <dependency>
162 <groupId>org.apache.logging.log4j</groupId>
163 <artifactId>log4j-api</artifactId>
164 <version>${log4j.version}</version>
165 <scope>runtime</scope>
166 </dependency>
167 <dependency>
168 <groupId>org.apache.logging.log4j</groupId>
169 <artifactId>log4j-core</artifactId>
170 <version>${log4j.version}</version>
171 <scope>runtime</scope>
172 </dependency>
173 </dependencies>
174
175 <build>
176 <plugins>
177
178 <!-- Java Compiler -->
179 <plugin>
180 <groupId>org.apache.maven.plugins</groupId>
181 <artifactId>maven-compiler-plugin</artifactId>
182 <version>3.8.0</version>
183 <configuration>
184 <source>${jdk.version}</source>
185 <target>${jdk.version}</target>
186 </configuration>
187 </plugin>
188
189 <!-- We use the maven-shade plugin to create a fat jar that contains all necessary dependencies. -->
190 <!-- Change the value of <mainClass>...</mainClass> if your program entry point changes. -->
191 <plugin>
192 <groupId>org.apache.maven.plugins</groupId>
193 <artifactId>maven-shade-plugin</artifactId>
194 <version>3.4.1</version>
195 <executions>
196 <!-- Run shade goal on package phase -->
197 <execution>
198 <phase>package</phase>
199 <goals>
200 <goal>shade</goal>
201 </goals>
202 <configuration>
203 <artifactSet>
204 <excludes>
205 <exclude>org.apache.flink:force-shading</exclude>
206 <exclude>com.google.code.findbugs:jsr305</exclude>
207 <exclude>org.slf4j:*</exclude>
208 <exclude>org.apache.logging.log4j:*</exclude>
209 </excludes>
210 </artifactSet>
211 <filters>
212 <filter>
213 <!-- Do not copy the signatures in the META-INF folder.
214 Otherwise, this might cause SecurityExceptions when using the JAR. -->
215 <artifact>*:*</artifact>
216 <excludes>
217 <exclude>META-INF/*.SF</exclude>
218 <exclude>META-INF/*.DSA</exclude>
219 <exclude>META-INF/*.RSA</exclude>
220 </excludes>
221 </filter>
222 </filters>
223 <transformers>
224 <transformer implementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer"/>
225 </transformers>
226 </configuration>
227 </execution>
228 </executions>
229 </plugin>
230 </plugins>
231
232 <pluginManagement>
233 <plugins>
234
235 <!-- This improves the out-of-the-box experience in Eclipse by resolving some warnings. -->
236 <plugin>
237 <groupId>org.eclipse.m2e</groupId>
238 <artifactId>lifecycle-mapping</artifactId>
239 <version>1.0.0</version>
240 <configuration>
241 <lifecycleMappingMetadata>
242 <pluginExecutions>
243 <pluginExecution>
244 <pluginExecutionFilter>
245 <groupId>org.apache.maven.plugins</groupId>
246 <artifactId>maven-shade-plugin</artifactId>
247 <versionRange>[3.1.1,)</versionRange>
248 <goals>
249 <goal>shade</goal>
250 </goals>
251 </pluginExecutionFilter>
252 <action>
253 <ignore/>
254 </action>
255 </pluginExecution>
256 <pluginExecution>
257 <pluginExecutionFilter>
258 <groupId>org.apache.maven.plugins</groupId>
259 <artifactId>maven-compiler-plugin</artifactId>
260 <versionRange>[3.1,)</versionRange>
261 <goals>
262 <goal>testCompile</goal>
263 <goal>compile</goal>
264 </goals>
265 </pluginExecutionFilter>
266 <action>
267 <ignore/>
268 </action>
269 </pluginExecution>
270 </pluginExecutions>
271 </lifecycleMappingMetadata>
272 </configuration>
273 </plugin>
274 </plugins>
275 </pluginManagement>
276 </build>
277</project>
The Uber Jar file can be built using the following script (build.sh).
1# build.sh
2#!/usr/bin/env bash
3SCRIPT_DIR="$(cd $(dirname "$0"); pwd)"
4SRC_PATH=$SCRIPT_DIR/package
5
6# remove contents under $SRC_PATH (except for the folders beginging with lab)
7shopt -s extglob
8rm -rf $SRC_PATH/!(lab*)
9
10## Generate Uber jar file for individual labs
11echo "generate Uber jar for PyFlink app..."
12mkdir $SRC_PATH/lib
13mvn clean install -f $SRC_PATH/lab2-pipeline/pom.xml \
14 && mv $SRC_PATH/lab2-pipeline/target/lab2-pipeline-1.0.0.jar $SRC_PATH/lib \
15 && rm -rf $SRC_PATH/lab2-pipeline/target
16
17mvn clean install -f $SRC_PATH/lab3-pipeline/pom.xml \
18 && mv $SRC_PATH/lab3-pipeline/target/lab3-pipeline-1.0.0.jar $SRC_PATH/lib \
19 && rm -rf $SRC_PATH/lab3-pipeline/target
Application Source
Although the Pyflink application uses the Table API, the FileSystem connector completes file writing when checkpointing is enabled. Therefore, the app creates a DataStream stream execution environment and enables checkpointing every 60 seconds. Then it creates a table environment, and the source and sink tables are created on it. An additional field named source is added to the sink table, and it is obtained by a user defined function (add_source). The sink table is partitioned by year, month, date and hour.
In the main method, we create all the source and sink tables after mapping relevant application properties. Then the output records are written to a S3 bucket. Note that the output records are printed in the terminal additionally when the app is running locally for ease of checking them.
1# exporter/processor.py
2import os
3import re
4import json
5
6from pyflink.datastream import StreamExecutionEnvironment, RuntimeExecutionMode
7from pyflink.table import StreamTableEnvironment
8from pyflink.table.udf import udf
9
10RUNTIME_ENV = os.environ.get("RUNTIME_ENV", "LOCAL") # LOCAL or DOCKER
11BOOTSTRAP_SERVERS = os.environ.get("BOOTSTRAP_SERVERS") # overwrite app config
12
13
14env = StreamExecutionEnvironment.get_execution_environment()
15env.set_runtime_mode(RuntimeExecutionMode.STREAMING)
16env.enable_checkpointing(60000)
17
18if RUNTIME_ENV == "LOCAL":
19 CURRENT_DIR = os.path.dirname(os.path.realpath(__file__))
20 PARENT_DIR = os.path.dirname(CURRENT_DIR)
21 APPLICATION_PROPERTIES_FILE_PATH = os.path.join(
22 CURRENT_DIR, "application_properties.json"
23 )
24 JAR_FILES = ["lab3-pipeline-1.0.0.jar"]
25 JAR_PATHS = tuple(
26 [f"file://{os.path.join(PARENT_DIR, 'jars', name)}" for name in JAR_FILES]
27 )
28 print(JAR_PATHS)
29 env.add_jars(*JAR_PATHS)
30else:
31 APPLICATION_PROPERTIES_FILE_PATH = "/etc/flink/exporter/application_properties.json"
32
33table_env = StreamTableEnvironment.create(stream_execution_environment=env)
34table_env.create_temporary_function(
35 "add_source", udf(lambda: "NYCTAXI", result_type="STRING")
36)
37
38
39def get_application_properties():
40 if os.path.isfile(APPLICATION_PROPERTIES_FILE_PATH):
41 with open(APPLICATION_PROPERTIES_FILE_PATH, "r") as file:
42 contents = file.read()
43 properties = json.loads(contents)
44 return properties
45 else:
46 raise RuntimeError(
47 f"A file at '{APPLICATION_PROPERTIES_FILE_PATH}' was not found"
48 )
49
50
51def property_map(props: dict, property_group_id: str):
52 for prop in props:
53 if prop["PropertyGroupId"] == property_group_id:
54 return prop["PropertyMap"]
55
56
57def inject_security_opts(opts: dict, bootstrap_servers: str):
58 if re.search("9098$", bootstrap_servers):
59 opts = {
60 **opts,
61 **{
62 "properties.security.protocol": "SASL_SSL",
63 "properties.sasl.mechanism": "AWS_MSK_IAM",
64 "properties.sasl.jaas.config": "software.amazon.msk.auth.iam.IAMLoginModule required;",
65 "properties.sasl.client.callback.handler.class": "software.amazon.msk.auth.iam.IAMClientCallbackHandler",
66 },
67 }
68 return ", ".join({f"'{k}' = '{v}'" for k, v in opts.items()})
69
70
71def create_source_table(table_name: str, topic_name: str, bootstrap_servers: str):
72 opts = {
73 "connector": "kafka",
74 "topic": topic_name,
75 "properties.bootstrap.servers": bootstrap_servers,
76 "properties.group.id": "soruce-group",
77 "format": "json",
78 "scan.startup.mode": "latest-offset",
79 }
80
81 stmt = f"""
82 CREATE TABLE {table_name} (
83 id VARCHAR,
84 vendor_id INT,
85 pickup_date VARCHAR,
86 pickup_datetime AS TO_TIMESTAMP(REPLACE(pickup_date, 'T', ' ')),
87 dropoff_date VARCHAR,
88 dropoff_datetime AS TO_TIMESTAMP(REPLACE(dropoff_date, 'T', ' ')),
89 passenger_count INT,
90 pickup_longitude VARCHAR,
91 pickup_latitude VARCHAR,
92 dropoff_longitude VARCHAR,
93 dropoff_latitude VARCHAR,
94 store_and_fwd_flag VARCHAR,
95 gc_distance INT,
96 trip_duration INT,
97 google_distance INT,
98 google_duration INT
99 ) WITH (
100 {inject_security_opts(opts, bootstrap_servers)}
101 )
102 """
103 print(stmt)
104 return stmt
105
106
107def create_sink_table(table_name: str, file_path: str):
108 stmt = f"""
109 CREATE TABLE {table_name} (
110 id VARCHAR,
111 vendor_id INT,
112 pickup_datetime TIMESTAMP,
113 dropoff_datetime TIMESTAMP,
114 passenger_count INT,
115 pickup_longitude VARCHAR,
116 pickup_latitude VARCHAR,
117 dropoff_longitude VARCHAR,
118 dropoff_latitude VARCHAR,
119 store_and_fwd_flag VARCHAR,
120 gc_distance INT,
121 trip_duration INT,
122 google_distance INT,
123 google_duration INT,
124 source VARCHAR,
125 `year` VARCHAR,
126 `month` VARCHAR,
127 `date` VARCHAR,
128 `hour` VARCHAR
129 ) PARTITIONED BY (`year`, `month`, `date`, `hour`) WITH (
130 'connector'= 'filesystem',
131 'path' = '{file_path}',
132 'format' = 'parquet',
133 'sink.partition-commit.delay'='1 h',
134 'sink.partition-commit.policy.kind'='success-file'
135 )
136 """
137 print(stmt)
138 return stmt
139
140
141def create_print_table(table_name: str):
142 stmt = f"""
143 CREATE TABLE {table_name} (
144 id VARCHAR,
145 vendor_id INT,
146 pickup_datetime TIMESTAMP,
147 dropoff_datetime TIMESTAMP,
148 passenger_count INT,
149 pickup_longitude VARCHAR,
150 pickup_latitude VARCHAR,
151 dropoff_longitude VARCHAR,
152 dropoff_latitude VARCHAR,
153 store_and_fwd_flag VARCHAR,
154 gc_distance INT,
155 trip_duration INT,
156 google_distance INT,
157 google_duration INT,
158 source VARCHAR,
159 `year` VARCHAR,
160 `month` VARCHAR,
161 `date` VARCHAR,
162 `hour` VARCHAR
163 ) WITH (
164 'connector'= 'print'
165 )
166 """
167 print(stmt)
168 return stmt
169
170
171def set_insert_sql(source_table_name: str, sink_table_name: str):
172 stmt = f"""
173 INSERT INTO {sink_table_name}
174 SELECT
175 id,
176 vendor_id,
177 pickup_datetime,
178 dropoff_datetime,
179 passenger_count,
180 pickup_longitude,
181 pickup_latitude,
182 dropoff_longitude,
183 dropoff_latitude,
184 store_and_fwd_flag,
185 gc_distance,
186 trip_duration,
187 google_distance,
188 google_duration,
189 add_source() AS source,
190 DATE_FORMAT(pickup_datetime, 'yyyy') AS `year`,
191 DATE_FORMAT(pickup_datetime, 'MM') AS `month`,
192 DATE_FORMAT(pickup_datetime, 'dd') AS `date`,
193 DATE_FORMAT(pickup_datetime, 'HH') AS `hour`
194 FROM {source_table_name}
195 """
196 print(stmt)
197 return stmt
198
199
200def main():
201 #### map source/sink properties
202 props = get_application_properties()
203 ## source
204 source_property_group_key = "source.config.0"
205 source_properties = property_map(props, source_property_group_key)
206 print(">> source properties")
207 print(source_properties)
208 source_table_name = source_properties["table.name"]
209 source_topic_name = source_properties["topic.name"]
210 source_bootstrap_servers = (
211 BOOTSTRAP_SERVERS or source_properties["bootstrap.servers"]
212 )
213 ## sink
214 sink_property_group_key = "sink.config.0"
215 sink_properties = property_map(props, sink_property_group_key)
216 print(">> sink properties")
217 print(sink_properties)
218 sink_table_name = sink_properties["table.name"]
219 sink_file_path = sink_properties["file.path"]
220 ## print
221 print_table_name = "sink_print"
222 #### create tables
223 table_env.execute_sql(
224 create_source_table(
225 source_table_name, source_topic_name, source_bootstrap_servers
226 )
227 )
228 table_env.execute_sql(create_sink_table(sink_table_name, sink_file_path))
229 table_env.execute_sql(create_print_table(print_table_name))
230 #### insert into sink tables
231 if RUNTIME_ENV == "LOCAL":
232 statement_set = table_env.create_statement_set()
233 statement_set.add_insert_sql(set_insert_sql(source_table_name, sink_table_name))
234 statement_set.add_insert_sql(set_insert_sql(print_table_name, sink_table_name))
235 statement_set.execute().wait()
236 else:
237 table_result = table_env.execute_sql(
238 set_insert_sql(source_table_name, sink_table_name)
239 )
240 print(table_result.get_job_client().get_job_status())
241
242
243if __name__ == "__main__":
244 main()
1// exporter/application_properties.json
2[
3 {
4 "PropertyGroupId": "kinesis.analytics.flink.run.options",
5 "PropertyMap": {
6 "python": "processor.py",
7 "jarfile": "package/lib/lab3-pipeline-1.0.0.jar"
8 }
9 },
10 {
11 "PropertyGroupId": "source.config.0",
12 "PropertyMap": {
13 "table.name": "taxi_rides_src",
14 "topic.name": "taxi-rides",
15 "bootstrap.servers": "localhost:29092"
16 }
17 },
18 {
19 "PropertyGroupId": "sink.config.0",
20 "PropertyMap": {
21 "table.name": "taxi_rides_sink",
22 "file.path": "s3://<s3-bucket-name-to-replace>/taxi-rides/"
23 }
24 }
25]
Run Application
Execute on Local Flink Cluster
We can run the application in the Flink cluster on Docker and the steps are shown below. Either the Kafka cluster on Amazon MSK or a local Kafka cluster can be used depending on which Docker Compose file we use. In either way, we can check the job details on the Flink web UI on localhost:8081. Note that, if we use the local Kafka cluster option, we have to start the producer application in a different terminal.
1## prep - update s3 bucket name in loader/application_properties.json
2
3## set aws credentials environment variables
4export AWS_ACCESS_KEY_ID=<aws-access-key-id>
5export AWS_SECRET_ACCESS_KEY=<aws-secret-access-key>
6# export AWS_SESSION_TOKEN=<aws-session-token>
7
8## run docker compose service
9# with local kafka cluster
10docker-compose -f compose-local-kafka.yml up -d
11# # or with msk cluster
12# docker-compose -f compose-msk.yml up -d
13
14## run the producer application in another terminal
15# python producer/app.py
16
17## submit pyflink application
18docker exec jobmanager /opt/flink/bin/flink run \
19 --python /etc/flink/exporter/processor.py \
20 --jarfile /etc/flink/package/lib/lab3-pipeline-1.0.0.jar \
21 -d
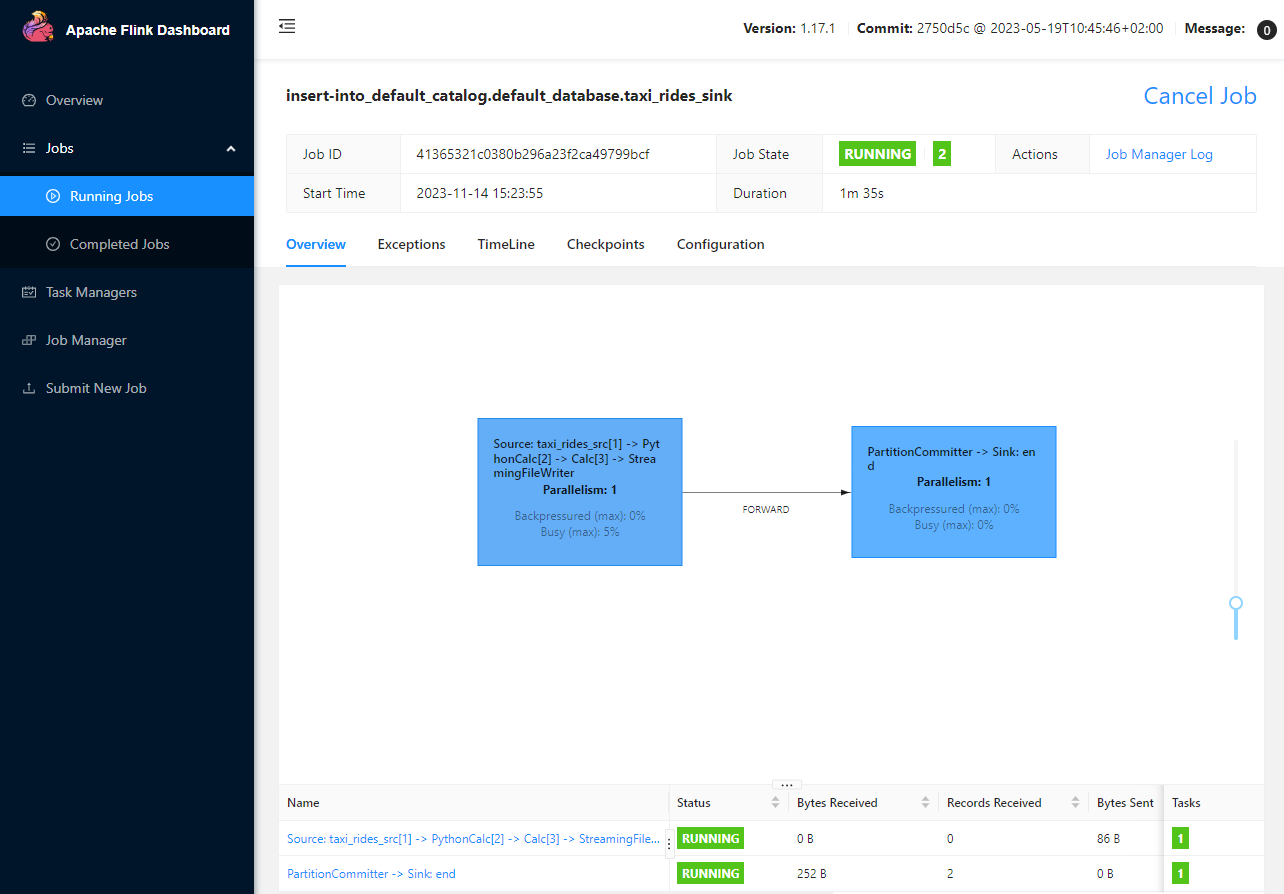
Application Result
Kafka Topic
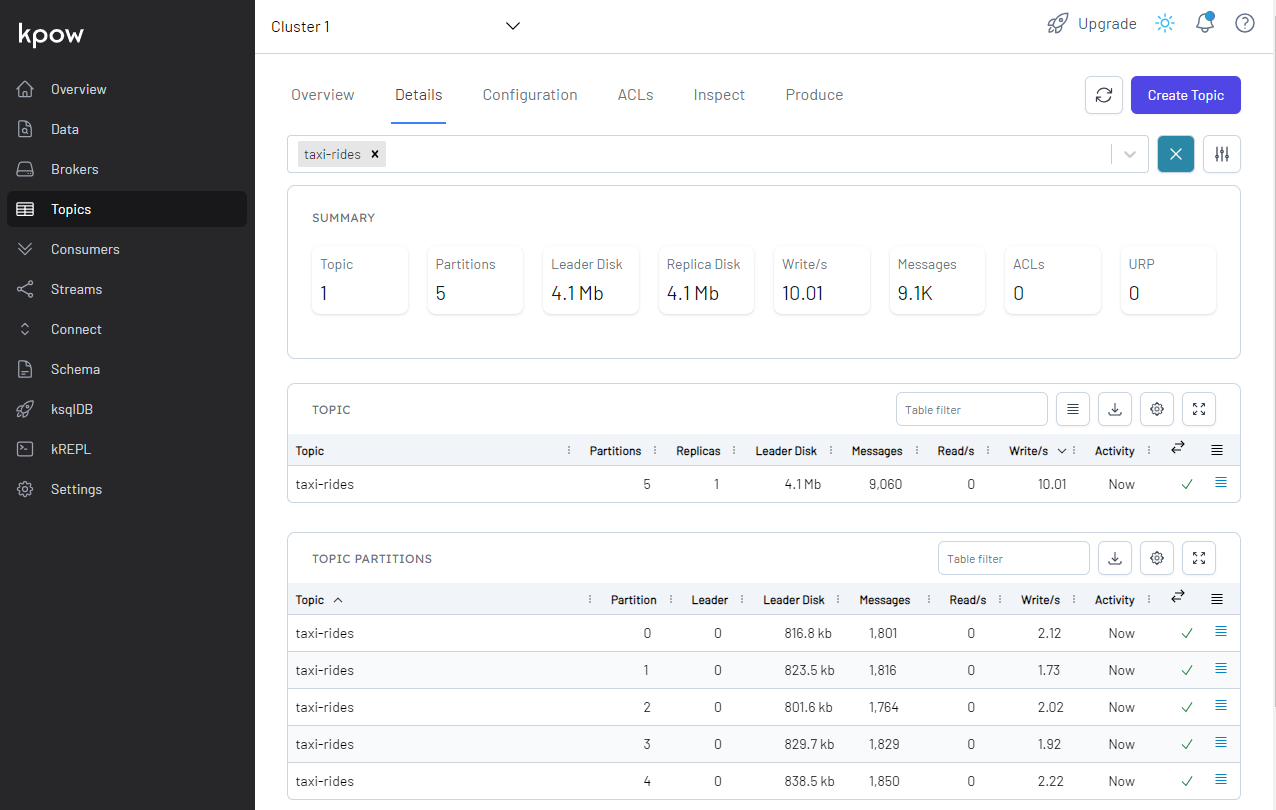
We can see the topic (taxi-rides) is created, and the details of the topic can be found on the Topics menu on localhost:3000.
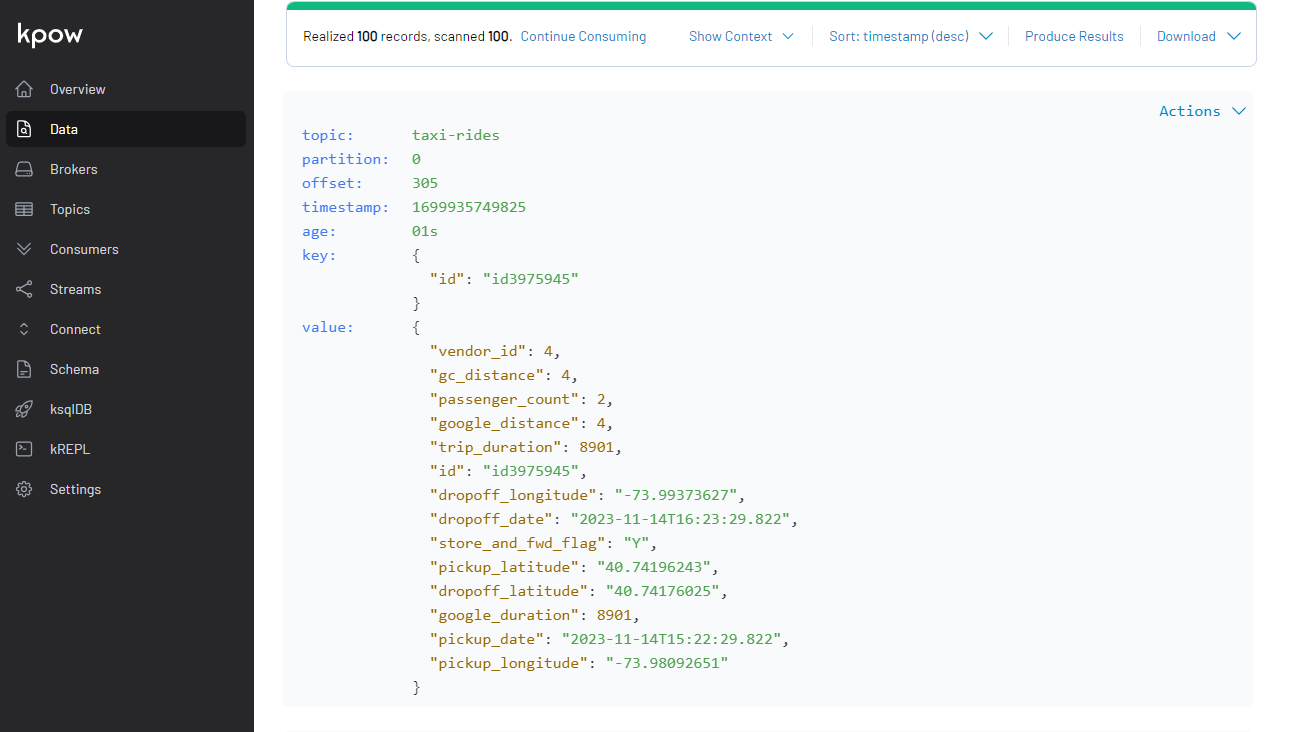
Also, we can inspect topic messages in the Data tab as shown below.
S3 Files
We can see the Pyflink app writes the records into the S3 bucket as expected. The files are written in Apache Hive style partitions and only completed files are found. Note that, when I tested the sink connector on the local file system, the file names of in-progress and pending files begin with dot (.) and the dot is removed when they are completed. I don’t see those incomplete files in the S3 bucket, and it seems that only completed files are moved. Note also that, as the checkpoint interval is set to 60 seconds, new files are created every minute. We can adjust the interval if it creates too many small files.
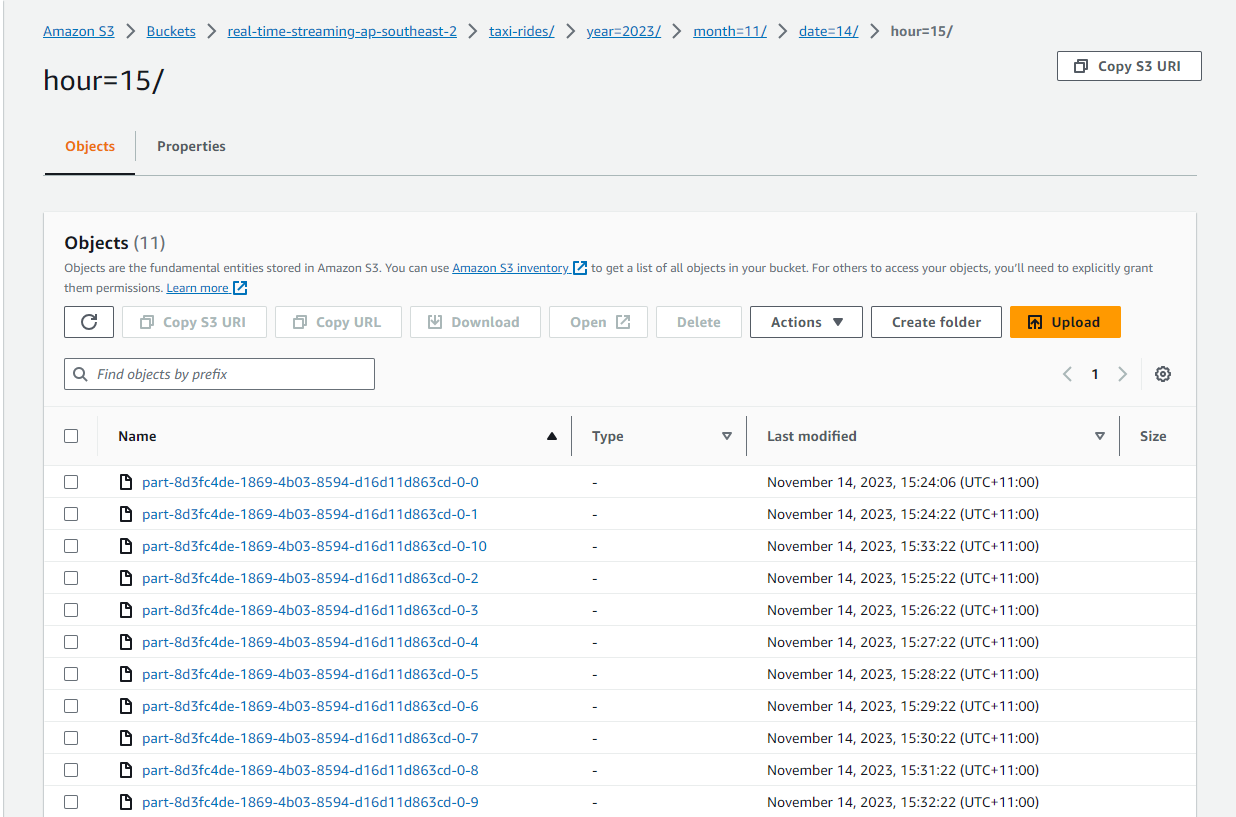
Athena Table
To query the output records, we can create a partitioned table on Amazon Athena by specifying the S3 location. It can be created by executing the following SQL statement.
1CREATE EXTERNAL TABLE taxi_rides (
2 id STRING,
3 vendor_id INT,
4 pickup_datetime TIMESTAMP,
5 dropoff_datetime TIMESTAMP,
6 passenger_count INT,
7 pickup_longitude STRING,
8 pickup_latitude STRING,
9 dropoff_longitude STRING,
10 dropoff_latitude STRING,
11 store_and_fwd_flag STRING,
12 gc_distance INT,
13 trip_duration INT,
14 google_distance INT,
15 google_duration INT,
16 source STRING
17)
18PARTITIONED BY (year STRING, month STRING, date STRING, hour STRING)
19STORED AS parquet
20LOCATION 's3://real-time-streaming-ap-southeast-2/taxi-rides/';
Then we can add the existing partition by updating the metadata in the catalog i.e. run MSCK REPAIR TABLE taxi_rides;.
1Partitions not in metastore: taxi_rides:year=2023/month=11/date=14/hour=15
2Repair: Added partition to metastore taxi_rides:year=2023/month=11/date=14/hour=15
After the partition is added, we can query the records as shown below.
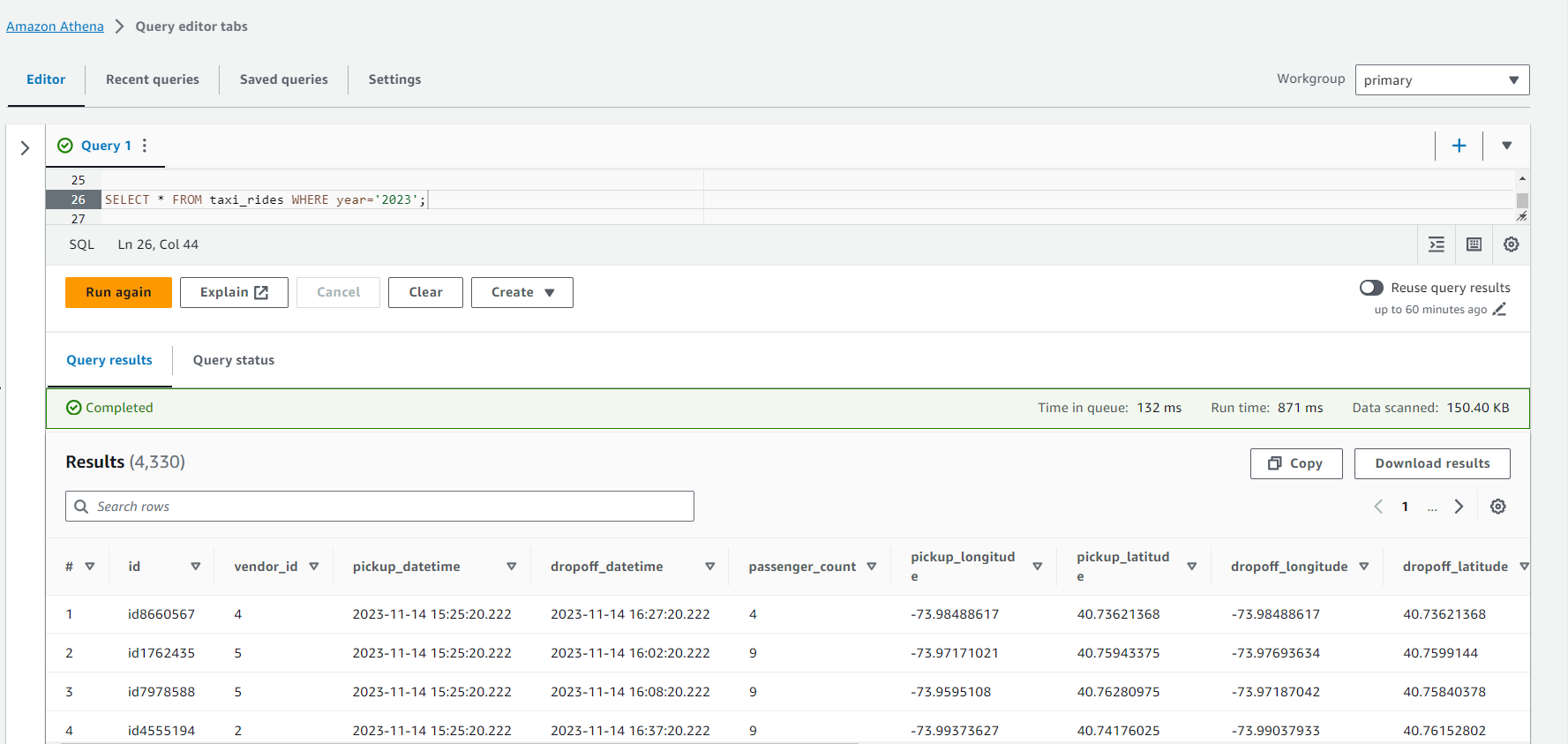
Summary
In this lab, we created a Pyflink application that exports Kafka topic messages into a S3 bucket. The app enriched the records by adding a new column using a user defined function and wrote them via the FileSystem SQL connector. While the records were being written to the S3 bucket, a Glue table was created to query them on Amazon Athena.










Comments