
[UPDATE 2025-10-01]
Bitnami’s public Docker images have been moved to the Bitnami Legacy repository. To ensure continued access and compatibility, please update your Docker image references accordingly.
For example:
bitnami/kafka:2.8.1→bitnamilegacy/kafka:2.8.1bitnami/zookeeper:3.7.0→bitnamilegacy/zookeeper:3.7.0bitnami/python:3.9.0→bitnamilegacy/python:3.9.0
Apache Flink became generally available for Amazon EMR on EKS from the EMR 6.15.0 releases, and we are able to pull the Flink (as well as Spark) container images from the ECR Public Gallery. As both of them can be integrated with the Glue Data Catalog, it can be particularly useful if we develop real time data ingestion/processing via Flink and build analytical queries using Spark (or any other tools or services that can access to the Glue Data Catalog).
In this post, we will discuss how to set up a local development environment for Apache Flink and Spark using the EMR container images. For the former, a custom Docker image will be created, which downloads dependent connector Jar files into the Flink library folder, fixes process startup issues, and updates Hadoop configurations for Glue Data Catalog integration. For the latter, instead of creating a custom image, the EMR image is used to launch the Spark container where the required configuration updates are added at runtime via volume-mapping. After illustrating the environment setup, we will discuss a solution where data ingestion/processing is performed in real time using Apache Flink and the processed data is consumed by Apache Spark for analysis.
Architecture
A PyFlink application produces messages into a Kafka topic and those messages are read and processed by another Flink application. For simplicity, the processor just buffers the messages and writes into S3 in Apache Hive style partitions. The sink (target) table is registered in the Glue Data Catalog for sharing the table details with other tools and services. A PySpark application is used to consume the processed data, which queries the Glue table using Spark SQL.
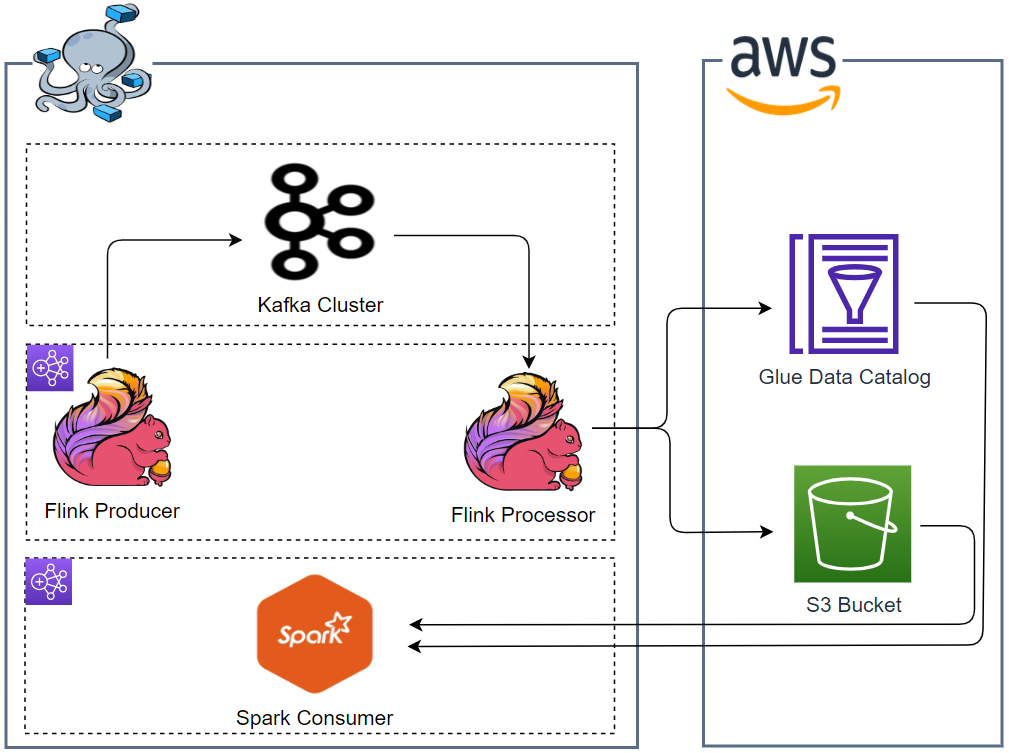
Infrastructure
We create a Flink cluster, Spark container, Kafka cluster and Kafka management app. They are deployed using Docker Compose and the source can be found in the GitHub repository of this post.
Flink Setup
Custom Docker Image
Flink 1.17.1 is installed in the EMR Flink image (public.ecr.aws/emr-on-eks/flink/emr-6.15.0-flink:latest) and a custom Docker image is created, which extends it. It begins with downloading dependent Jar files into the Flink library folder (/usr/lib/flink/lib), which are in relation to the Kafka and Flink Faker connectors.
When I started to run the Flink SQL client, I encountered a number of process startup issues. First, I had a runtime exception whose error message is java.lang.RuntimeException: Could not find a free permitted port on the machine. When it gets started, it reserves a port and writes the port details into a folder via the getAvailablePort method of the NetUtils class. Unlike the official Flink Docker image where the details are written to the /tmp folder, the EMR image writes into the /mnt/tmp folder, and it throws an error due to insufficient permission. I was able to fix the issue by creating the /mnt/tmp folder beforehand. Secondly, I also had additional issues that were caused by the NoClassDefFoundError, and they were fixed by adding the Javax Inject and AOP Alliance Jar files into the Flink library folder.
For Glue Data Catalog integration, we need Hadoop configuration. The EMR image keeps core-site.xml in the /glue/confs/hadoop/conf folder, and I had to update the file. Specifically I updated the credentials providers from WebIdentityTokenCredentialsProvider to EnvironmentVariableCredentialsProvider. In this way, we are able to access AWS services with AWS credentials in environment variables - the updated Hadoop configuration file can be found below. I also created the /mnt/s3 folder as it is specified as the S3 buffer directory in core-site.xml.
1# dockers/flink/Dockerfile
2FROM public.ecr.aws/emr-on-eks/flink/emr-6.15.0-flink:latest
3
4ARG FLINK_VERSION
5ENV FLINK_VERSION=${FLINK_VERSION:-1.17.1}
6ARG KAFKA_VERSION
7ENV KAFKA_VERSION=${KAFKA_VERSION:-3.2.3}
8ARG FAKER_VERSION
9ENV FAKER_VERSION=${FAKER_VERSION:-0.5.3}
10
11##
12## add connectors (Kafka and flink faker) and related dependencies
13##
14RUN curl -o /usr/lib/flink/lib/flink-connector-kafka-${FLINK_VERSION}.jar \
15 https://repo.maven.apache.org/maven2/org/apache/flink/flink-connector-kafka/${FLINK_VERSION}/flink-connector-kafka-${FLINK_VERSION}.jar \
16 && curl -o /usr/lib/flink/lib/kafka-clients-${KAFKA_VERSION}.jar \
17 https://repo.maven.apache.org/maven2/org/apache/kafka/kafka-clients/${KAFKA_VERSION}/kafka-clients-${KAFKA_VERSION}.jar \
18 && curl -o /usr/lib/flink/lib/flink-sql-connector-kafka-${FLINK_VERSION}.jar \
19 https://repo.maven.apache.org/maven2/org/apache/flink/flink-sql-connector-kafka/${FLINK_VERSION}/flink-sql-connector-kafka-${FLINK_VERSION}.jar \
20 && curl -L -o /usr/lib/flink/lib/flink-faker-${FAKER_VERSION}.jar \
21 https://github.com/knaufk/flink-faker/releases/download/v${FAKER_VERSION}/flink-faker-${FAKER_VERSION}.jar
22
23##
24## fix process startup issues
25##
26# should be able to write a file in /mnt/tmp as getAvailablePort() in NetUtils class writes to /mnt/tmp instead of /tmp
27# see https://stackoverflow.com/questions/77539526/fail-to-start-flink-sql-client-on-emr-on-eks-docker-image
28RUN mkdir -p /mnt/tmp
29
30## add missing jar files
31RUN curl -L -o /usr/lib/flink/lib/javax.inject-1.jar \
32 https://repo1.maven.org/maven2/javax/inject/javax.inject/1/javax.inject-1.jar \
33 && curl -L -o /usr/lib/flink/lib/aopalliance-1.0.jar \
34 https://repo1.maven.org/maven2/aopalliance/aopalliance/1.0/aopalliance-1.0.jar
35
36##
37## update hadoop configuration for Glue data catalog integration
38##
39## create /mnt/s3 (value of fs.s3.buffer.dir) beforehand
40RUN mkdir -p /mnt/s3
41
42## copy updated core-site.xml
43## update credentials providers and value of fs.s3.buffer.dir to /mnt/s3 only
44USER root
45
46COPY ./core-site.xml /glue/confs/hadoop/conf/core-site.xml
47
48USER flink
Here is the updated Hadoop configuration file that is baked into the custom Docker image.
1<!-- dockers/flink/core-site.xml -->
2<configuration>
3 <property>
4 <name>fs.s3a.aws.credentials.provider</name>
5 <value>com.amazonaws.auth.EnvironmentVariableCredentialsProvider</value>
6 </property>
7
8 <property>
9 <name>fs.s3.customAWSCredentialsProvider</name>
10 <value>com.amazonaws.auth.EnvironmentVariableCredentialsProvider</value>
11 </property>
12
13 <property>
14 <name>fs.s3.impl</name>
15 <value>com.amazon.ws.emr.hadoop.fs.EmrFileSystem</value>
16 </property>
17
18 <property>
19 <name>fs.s3n.impl</name>
20 <value>com.amazon.ws.emr.hadoop.fs.EmrFileSystem</value>
21 </property>
22
23 <property>
24 <name>fs.AbstractFileSystem.s3.impl</name>
25 <value>org.apache.hadoop.fs.s3.EMRFSDelegate</value>
26 </property>
27
28 <property>
29 <name>fs.s3.buffer.dir</name>
30 <value>/mnt/s3</value>
31 <final>true</final>
32 </property>
33</configuration>
The Docker image can be built using the following command.
1$ docker build -t emr-6.15.0-flink:local dockers/flink/.
Docker Compose Services
The Flink cluster is made up of a single master container (jobmanager) and one task container (taskmanager). The master container opens up the port 8081, and we are able to access the Flink Web UI on localhost:8081. Also, the current folder is volume-mapped into the /home/flink/project folder, and it allows us to submit a Flink application in the host folder to the Flink cluster.
Other than the environment variables of the Kafka bootstrap server addresses and AWS credentials, the following environment variables are important for deploying the Flink cluster and running Flink jobs without an issue.
- K8S_FLINK_GLUE_ENABLED
- If this environment variable exists, the container entrypoint file (docker-entrypoint.sh) configures Apache Hive. It moves the Hive/Glue related dependencies into the Flink library folder (/usr/lib/flink/lib) for setting up Hive Catalog, which is integrated with the Glue Data Catalog.
- K8S_FLINK_LOG_URL_STDERR and K8S_FLINK_LOG_URL_STDOUT
- The container entrypoint file (docker-entrypoint.sh) creates these folders, but I had an error due to insufficient permission. Therefore, I changed the values of those folders within the /tmp folder.
- HADOOP_CONF_DIR
- This variable is required when setting up a Hive catalog, or we can add it as an option when creating a catalog (hadoop-config-dir).
- FLINK_PROPERTIES
- The properties will be appended into the Flink configuration file (/usr/lib/flink/conf/flink-conf.yaml). Among those, jobmanager.memory.process.size and taskmanager.memory.process.size are mandatory for the containers run without failure.
1# docker-compose.yml
2version: "3.5"
3
4services:
5 jobmanager:
6 image: emr-6.15.0-flink:local
7 container_name: jobmanager
8 command: jobmanager
9 ports:
10 - "8081:8081"
11 networks:
12 - appnet
13 volumes:
14 - ./:/home/flink/project
15 environment:
16 - RUNTIME_ENV=DOCKER
17 - BOOTSTRAP_SERVERS=kafka-0:9092
18 - AWS_ACCESS_KEY_ID=${AWS_ACCESS_KEY_ID:-not_set}
19 - AWS_SECRET_ACCESS_KEY=${AWS_SECRET_ACCESS_KEY:-not_set}
20 - AWS_REGION=${AWS_REGION:-not_set}
21 - K8S_FLINK_GLUE_ENABLED=true
22 - K8S_FLINK_LOG_URL_STDERR=/tmp/stderr
23 - K8S_FLINK_LOG_URL_STDOUT=/tmp/stdout
24 - HADOOP_CONF_DIR=/glue/confs/hadoop/conf
25 - |
26 FLINK_PROPERTIES=
27 jobmanager.rpc.address: jobmanager
28 state.backend: filesystem
29 state.checkpoints.dir: file:///tmp/flink-checkpoints
30 heartbeat.interval: 1000
31 heartbeat.timeout: 5000
32 rest.flamegraph.enabled: true
33 web.backpressure.refresh-interval: 10000
34 jobmanager.memory.process.size: 1600m
35 taskmanager.memory.process.size: 1728m
36 taskmanager:
37 image: emr-6.15.0-flink:local
38 container_name: taskmanager
39 command: taskmanager
40 networks:
41 - appnet
42 volumes:
43 - ./:/home/flink/project
44 - flink_data:/tmp/
45 environment:
46 - RUNTIME_ENV=DOCKER
47 - BOOTSTRAP_SERVERS=kafka-0:9092
48 - AWS_ACCESS_KEY_ID=${AWS_ACCESS_KEY_ID:-not_set}
49 - AWS_SECRET_ACCESS_KEY=${AWS_SECRET_ACCESS_KEY:-not_set}
50 - AWS_REGION=${AWS_REGION:-not_set}
51 - K8S_FLINK_GLUE_ENABLED=true
52 - K8S_FLINK_LOG_URL_STDERR=/tmp/stderr
53 - K8S_FLINK_LOG_URL_STDOUT=/tmp/stdout
54 - HADOOP_CONF_DIR=/glue/confs/hadoop/conf
55 - |
56 FLINK_PROPERTIES=
57 jobmanager.rpc.address: jobmanager
58 taskmanager.numberOfTaskSlots: 5
59 state.backend: filesystem
60 state.checkpoints.dir: file:///tmp/flink-checkpoints
61 heartbeat.interval: 1000
62 heartbeat.timeout: 5000
63 jobmanager.memory.process.size: 1600m
64 taskmanager.memory.process.size: 1728m
65 depends_on:
66 - jobmanager
67
68 ...
69
70networks:
71 appnet:
72 name: app-network
73
74volumes:
75 flink_data:
76 driver: local
77 name: flink_data
78 ...
Spark Setup
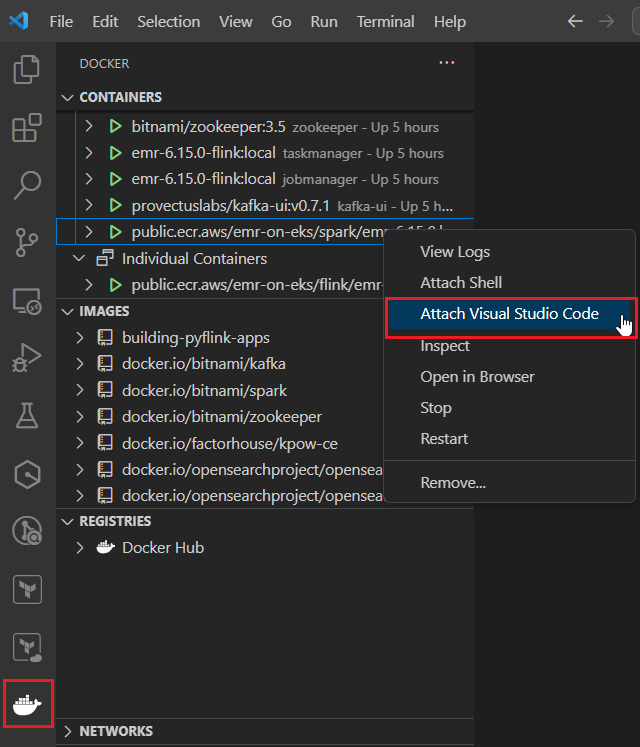
In an earlier post, I illustrated how to set up a local development environment using an EMR container image. That post is based the Dev Containers extension of VS Code, and it is assumed that development takes place after attaching the project folder into a Docker container. Thanks to the Docker extension, however, we no longer have to attach the project folder into a container always because the extension allows us to do so with just a few mouse clicks if necessary - see the screenshot below. Moreover, as Spark applications developed in the host folder can easily be submitted to the Spark container via volume-mapping, we can simplify Spark setup dramatically without creating a custom Docker image. Therefore, Spark will be set up using the EMR image where updated Spark configuration files and the project folder are volume-mapped to the container. Also, the Spark History Server will be running in the container, which allows us to monitor completed and running Spark applications.
Configuration Updates
Same to Flink Hadoop configuration updates, we need to update credentials providers from WebIdentityTokenCredentialsProvider to EnvironmentVariableCredentialsProvider to access AWS services with AWS credentials in environment variables. Also, we should specify the catalog implementation to hive and set AWSGlueDataCatalogHiveClientFactory as the Hive metastore factory class.
1# dockers/spark/spark-defaults.conf
2
3...
4
5##
6## Update credentials providers
7##
8spark.hadoop.fs.s3.customAWSCredentialsProvider com.amazonaws.auth.EnvironmentVariableCredentialsProvider
9spark.hadoop.dynamodb.customAWSCredentialsProvider com.amazonaws.auth.EnvironmentVariableCredentialsProvider
10# spark.authenticate true
11
12##
13## Update to use Glue catalog
14##
15spark.sql.catalogImplementation hive
16spark.hadoop.hive.metastore.client.factory.class com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory
Besides, I updated the log properties so that the log level of the root logger is set to be warn and warning messages due to EC2 metadata access failure are not logged.
1# dockers/spark/log4j2.properties
2
3...
4
5# Set everything to be logged to the console
6rootLogger.level = warn
7
8...
9
10## Ignore warn messages related to EC2 metadata access failure
11logger.InstanceMetadataServiceResourceFetcher.name = com.amazonaws.internal.InstanceMetadataServiceResourceFetcher
12logger.InstanceMetadataServiceResourceFetcher.level = fatal
13logger.EC2MetadataUtils.name = com.amazonaws.util.EC2MetadataUtils
14logger.EC2MetadataUtils.level = fatal
Docker Compose Service
Spark 3.4.1 is installed in the EMR image (public.ecr.aws/emr-on-eks/spark/emr-6.15.0:latest) and the Spark container is created with it. It starts the Spark History Server, which provides an interface to debug and diagnose completed and running Spark applications. Note that the server is configured to run in foreground (SPARK_NO_DAEMONIZE=true) in order for the container to keep alive. As mentioned, the updated Spark configuration files and the project folder are volume-mapped.
1# docker-compose.yml
2version: "3.5"
3
4services:
5
6 ...
7
8 spark:
9 image: public.ecr.aws/emr-on-eks/spark/emr-6.15.0:latest
10 container_name: spark
11 command: /usr/lib/spark/sbin/start-history-server.sh
12 ports:
13 - "18080:18080"
14 networks:
15 - appnet
16 environment:
17 - BOOTSTRAP_SERVERS=kafka-0:9092
18 - AWS_ACCESS_KEY_ID=${AWS_ACCESS_KEY_ID:-not_set}
19 - AWS_SECRET_ACCESS_KEY=${AWS_SECRET_ACCESS_KEY:-not_set}
20 - AWS_REGION=${AWS_REGION:-not_set}
21 - SPARK_NO_DAEMONIZE=true
22 volumes:
23 - ./:/home/hadoop/project
24 - ./dockers/spark/spark-defaults.conf:/usr/lib/spark/conf/spark-defaults.conf
25 - ./dockers/spark/log4j2.properties:/usr/lib/spark/conf/log4j2.properties
26
27 ...
28
29networks:
30 appnet:
31 name: app-network
32
33 ...
Kafka Setup
Docker Compose Services
A Kafka cluster with a single broker and zookeeper node is used in this post. The broker has two listeners and the port 9092 and 29092 are used for internal and external communication respectively. The default number of topic partitions is set to 3. More details about Kafka cluster setup can be found in this post.
The UI for Apache Kafka (kafka-ui) is used for monitoring Kafka topics and related resources. The bootstrap server address and zookeeper access url are added as environment variables. See this post for details about Kafka management apps.
1# docker-compose.yml
2version: "3.5"
3
4services:
5
6 ...
7
8 zookeeper:
9 image: bitnami/zookeeper:3.5
10 container_name: zookeeper
11 ports:
12 - "2181"
13 networks:
14 - appnet
15 environment:
16 - ALLOW_ANONYMOUS_LOGIN=yes
17 volumes:
18 - zookeeper_data:/bitnami/zookeeper
19 kafka-0:
20 image: bitnami/kafka:2.8.1
21 container_name: kafka-0
22 expose:
23 - 9092
24 ports:
25 - "29092:29092"
26 networks:
27 - appnet
28 environment:
29 - ALLOW_PLAINTEXT_LISTENER=yes
30 - KAFKA_CFG_ZOOKEEPER_CONNECT=zookeeper:2181
31 - KAFKA_CFG_BROKER_ID=0
32 - KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=INTERNAL:PLAINTEXT,EXTERNAL:PLAINTEXT
33 - KAFKA_CFG_LISTENERS=INTERNAL://:9092,EXTERNAL://:29092
34 - KAFKA_CFG_ADVERTISED_LISTENERS=INTERNAL://kafka-0:9092,EXTERNAL://localhost:29092
35 - KAFKA_CFG_INTER_BROKER_LISTENER_NAME=INTERNAL
36 - KAFKA_CFG_NUM_PARTITIONS=3
37 - KAFKA_CFG_DEFAULT_REPLICATION_FACTOR=1
38 volumes:
39 - kafka_0_data:/bitnami/kafka
40 depends_on:
41 - zookeeper
42 kafka-ui:
43 image: provectuslabs/kafka-ui:v0.7.1
44 container_name: kafka-ui
45 ports:
46 - "8080:8080"
47 networks:
48 - appnet
49 environment:
50 KAFKA_CLUSTERS_0_NAME: local
51 KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS: kafka-0:9092
52 KAFKA_CLUSTERS_0_ZOOKEEPER: zookeeper:2181
53 depends_on:
54 - zookeeper
55 - kafka-0
56
57networks:
58 appnet:
59 name: app-network
60
61volumes:
62 ...
63 zookeeper_data:
64 driver: local
65 name: zookeeper_data
66 kafka_0_data:
67 driver: local
68 name: kafka_0_data
Applications
Flink Producer
A PyFlink application is created for data ingesting in real time. The app begins with generating timestamps using the DataGen SQL Connector where three records are generated per second. Then extra values (id and value) are added to the records using Python user defined functions and the updated records are ingested into a Kafka topic named orders. Note that the output records are printed in the terminal additionally when the app is running locally for ease of checking them.
1# apps/flink/producer.py
2import os
3import uuid
4import random
5
6from pyflink.datastream import StreamExecutionEnvironment, RuntimeExecutionMode
7from pyflink.table import StreamTableEnvironment
8from pyflink.table.udf import udf
9
10def _qry_source_table():
11 stmt = """
12 CREATE TABLE seeds (
13 ts AS PROCTIME()
14 ) WITH (
15 'connector' = 'datagen',
16 'rows-per-second' = '3'
17 )
18 """
19 print(stmt)
20 return stmt
21
22def _qry_sink_table(table_name: str, topic_name: str, bootstrap_servers: str):
23 stmt = f"""
24 CREATE TABLE {table_name} (
25 `id` VARCHAR,
26 `value` INT,
27 `ts` TIMESTAMP(3)
28 ) WITH (
29 'connector' = 'kafka',
30 'topic' = '{topic_name}',
31 'properties.bootstrap.servers' = '{bootstrap_servers}',
32 'format' = 'json',
33 'key.format' = 'json',
34 'key.fields' = 'id',
35 'properties.allow.auto.create.topics' = 'true'
36 )
37 """
38 print(stmt)
39 return stmt
40
41
42def _qry_print_table():
43 stmt = """
44 CREATE TABLE print (
45 `id` VARCHAR,
46 `value` INT,
47 `ts` TIMESTAMP(3)
48
49 ) WITH (
50 'connector' = 'print'
51 )
52 """
53 print(stmt)
54 return stmt
55
56def _qry_insert(target_table: str):
57 stmt = f"""
58 INSERT INTO {target_table}
59 SELECT
60 add_id(),
61 add_value(),
62 ts
63 FROM seeds
64 """
65 print(stmt)
66 return stmt
67
68if __name__ == "__main__":
69 RUNTIME_ENV = os.environ.get("RUNTIME_ENV", "LOCAL") # DOCKER or LOCAL
70 BOOTSTRAP_SERVERS = os.environ.get("BOOTSTRAP_SERVERS", "localhost:29092") # overwrite app config
71
72 env = StreamExecutionEnvironment.get_execution_environment()
73 env.set_runtime_mode(RuntimeExecutionMode.STREAMING)
74 if RUNTIME_ENV == "LOCAL":
75 SRC_DIR = os.path.dirname(os.path.realpath(__file__))
76 JAR_FILES = ["flink-sql-connector-kafka-1.17.1.jar"] # should exist where producer.py exists
77 JAR_PATHS = tuple(
78 [f"file://{os.path.join(SRC_DIR, name)}" for name in JAR_FILES]
79 )
80 env.add_jars(*JAR_PATHS)
81 print(JAR_PATHS)
82
83 t_env = StreamTableEnvironment.create(stream_execution_environment=env)
84 t_env.get_config().set_local_timezone("Australia/Sydney")
85 t_env.create_temporary_function(
86 "add_id", udf(lambda: str(uuid.uuid4()), result_type="STRING")
87 )
88 t_env.create_temporary_function(
89 "add_value", udf(lambda: random.randrange(0, 1000), result_type="INT")
90 )
91 ## create source and sink tables
92 SINK_TABLE_NAME = "orders_table"
93 t_env.execute_sql(_qry_source_table())
94 t_env.execute_sql(_qry_sink_table(SINK_TABLE_NAME, "orders", BOOTSTRAP_SERVERS))
95 t_env.execute_sql(_qry_print_table())
96 ## insert into sink table
97 if RUNTIME_ENV == "LOCAL":
98 statement_set = t_env.create_statement_set()
99 statement_set.add_insert_sql(_qry_insert(SINK_TABLE_NAME))
100 statement_set.add_insert_sql(_qry_insert("print"))
101 statement_set.execute().wait()
102 else:
103 table_result = t_env.execute_sql(_qry_insert(SINK_TABLE_NAME))
104 print(table_result.get_job_client().get_job_status())
The application can be submitted into the Flink cluster as shown below. Note that the dependent Jar files for the Kafka connector exist in the Flink library folder (/usr/lib/flink/lib) and we don’t have to specify them separately.
1docker exec jobmanager /usr/lib/flink/bin/flink run \
2 --python /home/flink/project/apps/flink/producer.py \
3 -d
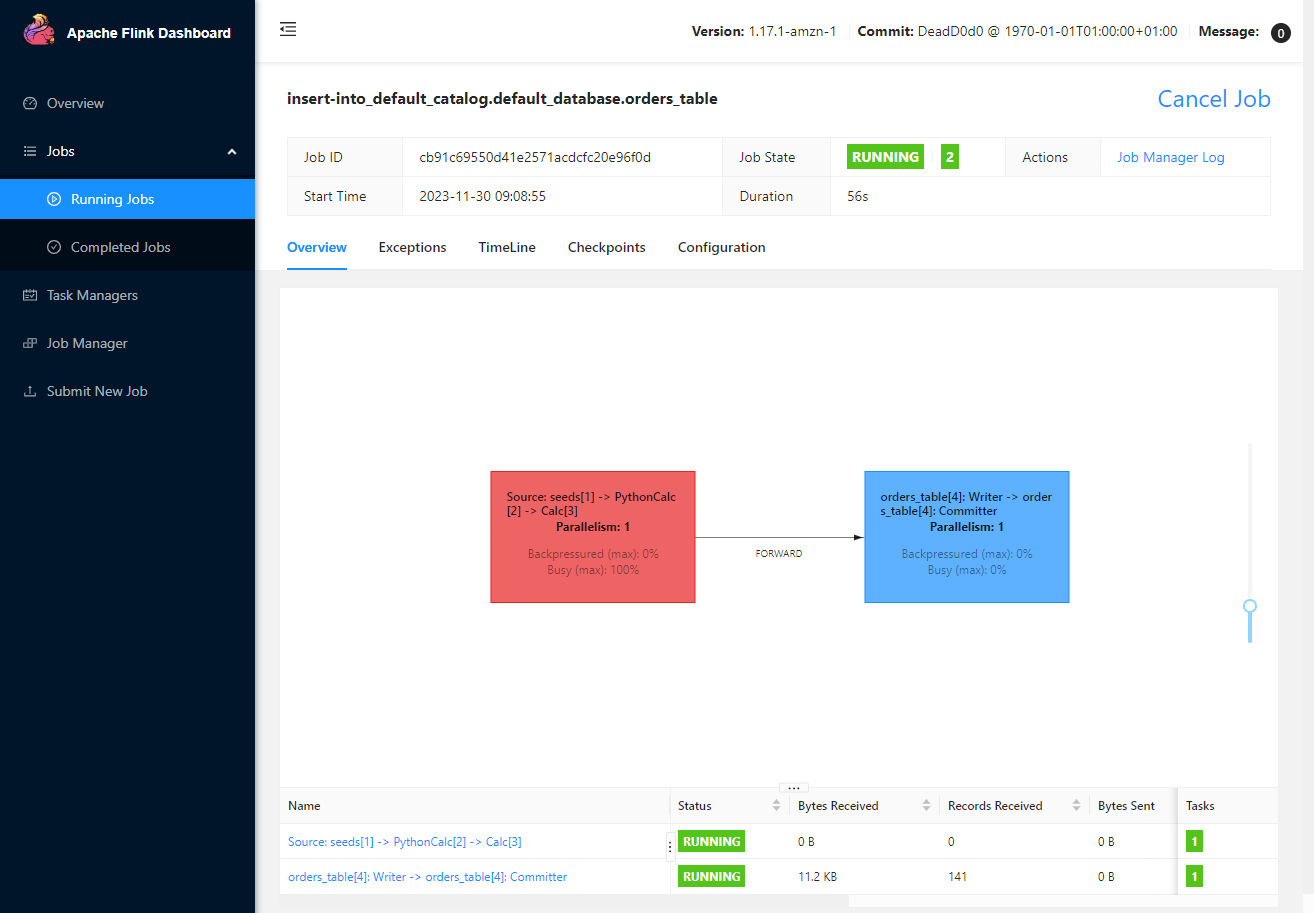
Once the app runs, we can see the status of the Flink job on the Flink Web UI (localhost:8081).
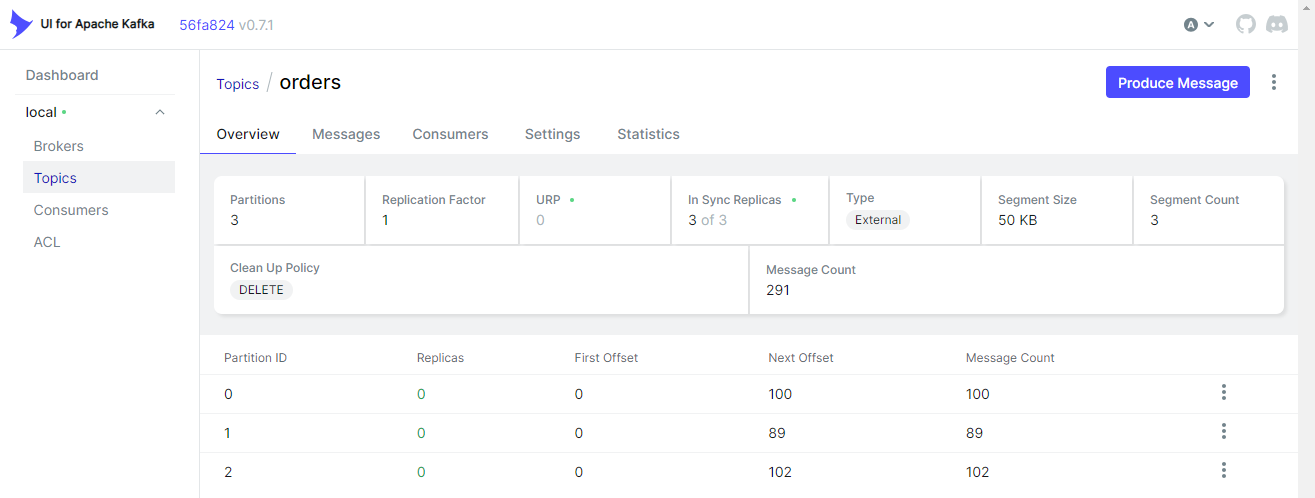
Also, we can check the topic (orders) is created and messages are ingested on kafka-ui (localhost:8080).
Flink Processor
The Flink processor application is created using Flink SQL on the Flink SQL client. The SQL client can be started by executing docker exec -it jobmanager ./bin/sql-client.sh.
Source Table in Default Catalog
We first create a source table that reads messages from the orders topic of the Kafka cluster. As the table is not necessarily be shared by other tools or services, it is created on the default catalog, not on the Glue catalog.
1-- apps/flink/processor.sql
2-- // create the source table, metadata not registered in glue datalog
3CREATE TABLE source_tbl(
4 `id` STRING,
5 `value` INT,
6 `ts` TIMESTAMP(3)
7) WITH (
8 'connector' = 'kafka',
9 'topic' = 'orders',
10 'properties.bootstrap.servers' = 'kafka-0:9092',
11 'properties.group.id' = 'orders-source',
12 'format' = 'json',
13 'scan.startup.mode' = 'latest-offset'
14);
Sink Table in Glue Catalog
We create the sink table on the Glue Data Catalog because it needs to be accessed by a Spark application. First, we create a Hive catalog named glue_catalog with the Hive configuration that integrates with the Glue Data Catalog. The EMR Flink image includes the required Hive configuration file, and we can specify the corresponding path in the container (/glue/confs/hive/conf).
1-- apps/flink/processor.sql
2--// create a hive catalogs that integrates with the glue catalog
3CREATE CATALOG glue_catalog WITH (
4 'type' = 'hive',
5 'default-database' = 'default',
6 'hive-conf-dir' = '/glue/confs/hive/conf'
7);
8
9-- Flink SQL> show catalogs;
10-- +-----------------+
11-- | catalog name |
12-- +-----------------+
13-- | default_catalog |
14-- | glue_catalog |
15-- +-----------------+
Below shows the Hive configuration file (/glue/confs/hive/conf/hive-site.xml). Same as the Spark configuration, AWSGlueDataCatalogHiveClientFactory is specified as the Hive metastore factory class, which enables to use the Glue Data Catalog as the metastore of Hive databases and tables.
1<configuration>
2 <property>
3 <name>hive.metastore.client.factory.class</name>
4 <value>com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory</value>
5 </property>
6
7 <property>
8 <name>hive.metastore.uris</name>
9 <value>thrift://dummy:9083</value>
10 </property>
11</configuration>
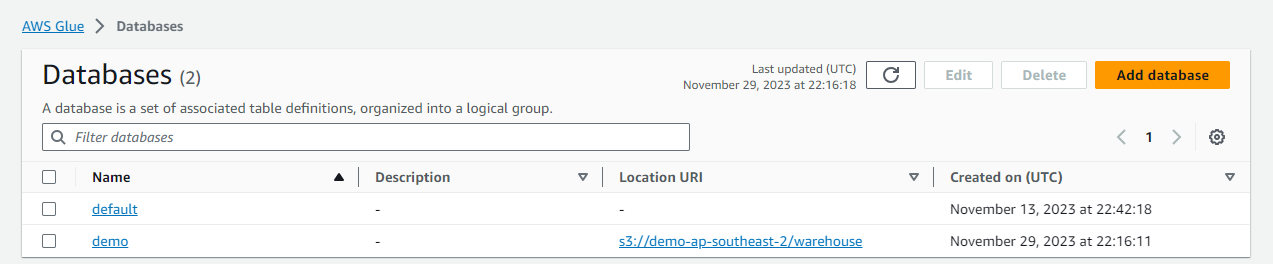
Secondly, we create a database named demo by specifying the S3 location URI - s3://demo-ap-southeast-2/warehouse/.
1-- apps/flink/processor.sql
2-- // create a database named demo
3CREATE DATABASE IF NOT EXISTS glue_catalog.demo
4 WITH ('hive.database.location-uri'= 's3://demo-ap-southeast-2/warehouse/');
Once succeeded, we are able to see the database is created in the Glue Data Catalog.
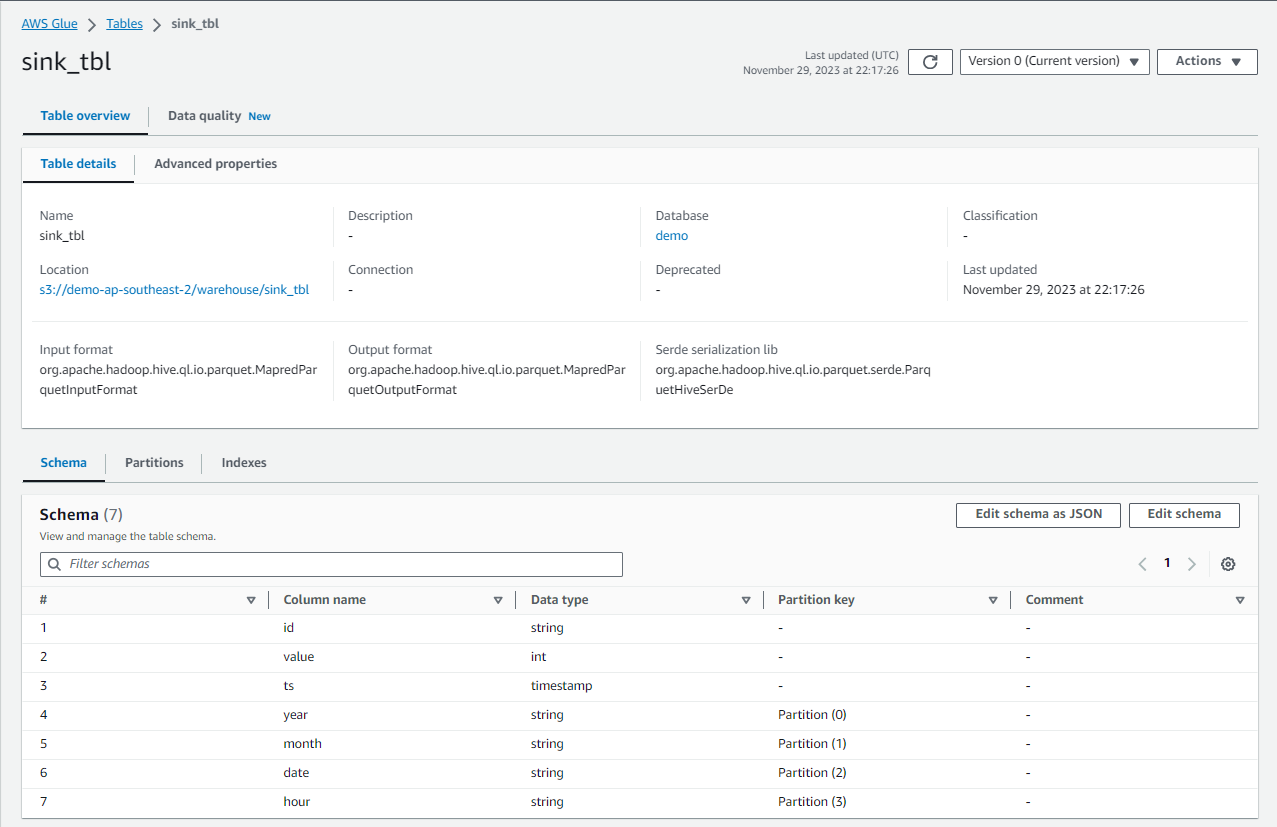
Finally, we create the sink table in the Glue database. The Hive SQL dialect is used to create the table, and it is partitioned by year, month, date and hour.
1-- apps/flink/processor.sql
2-- // create the sink table using hive dialect
3SET table.sql-dialect=hive;
4CREATE TABLE glue_catalog.demo.sink_tbl(
5 `id` STRING,
6 `value` INT,
7 `ts` TIMESTAMP(9)
8)
9PARTITIONED BY (`year` STRING, `month` STRING, `date` STRING, `hour` STRING)
10STORED AS parquet
11TBLPROPERTIES (
12 'partition.time-extractor.timestamp-pattern'='$year-$month-$date $hour:00:00',
13 'sink.partition-commit.trigger'='partition-time',
14 'sink.partition-commit.delay'='1 h',
15 'sink.partition-commit.policy.kind'='metastore,success-file'
16);
We can check the sink table is created in the Glue database on AWS Console as shown below.
Flink Job
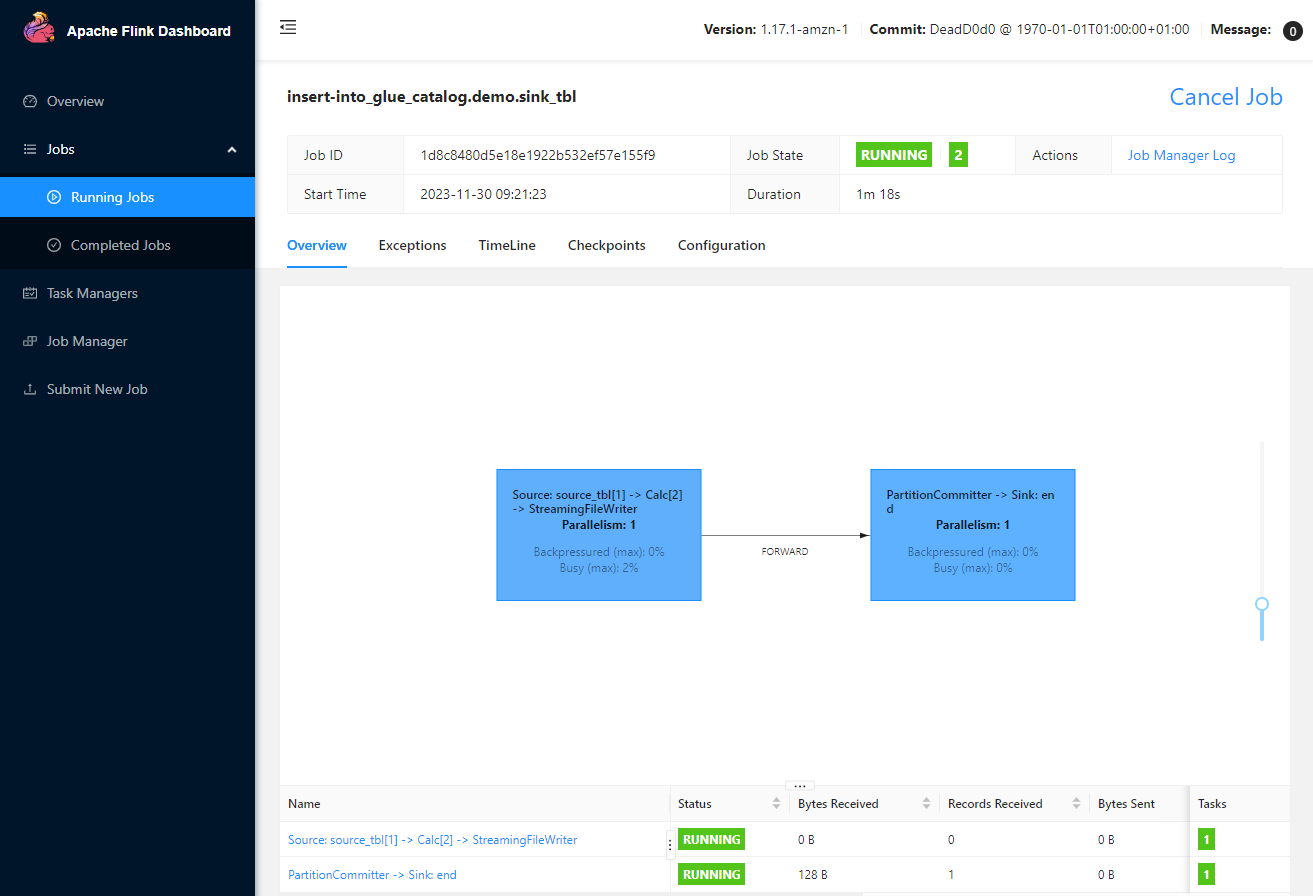
The Flink processor job gets submitted when we execute the INSERT statement on the SQL client. Note that the checkpoint interval is set to 60 seconds to simplify monitoring, and it is expected that a new file is added per minute.
1-- apps/flink/processor.sql
2SET 'state.checkpoints.dir' = 'file:///tmp/checkpoints/';
3SET 'execution.checkpointing.interval' = '60000';
4
5SET table.sql-dialect=hive;
6-- // insert into the sink table
7INSERT INTO TABLE glue_catalog.demo.sink_tbl
8SELECT
9 `id`,
10 `value`,
11 `ts`,
12 DATE_FORMAT(`ts`, 'yyyy') AS `year`,
13 DATE_FORMAT(`ts`, 'MM') AS `month`,
14 DATE_FORMAT(`ts`, 'dd') AS `date`,
15 DATE_FORMAT(`ts`, 'HH') AS `hour`
16FROM source_tbl;
Once the Flink app is submitted, we can check the Flink job on the Flink Web UI (localhost:8081).
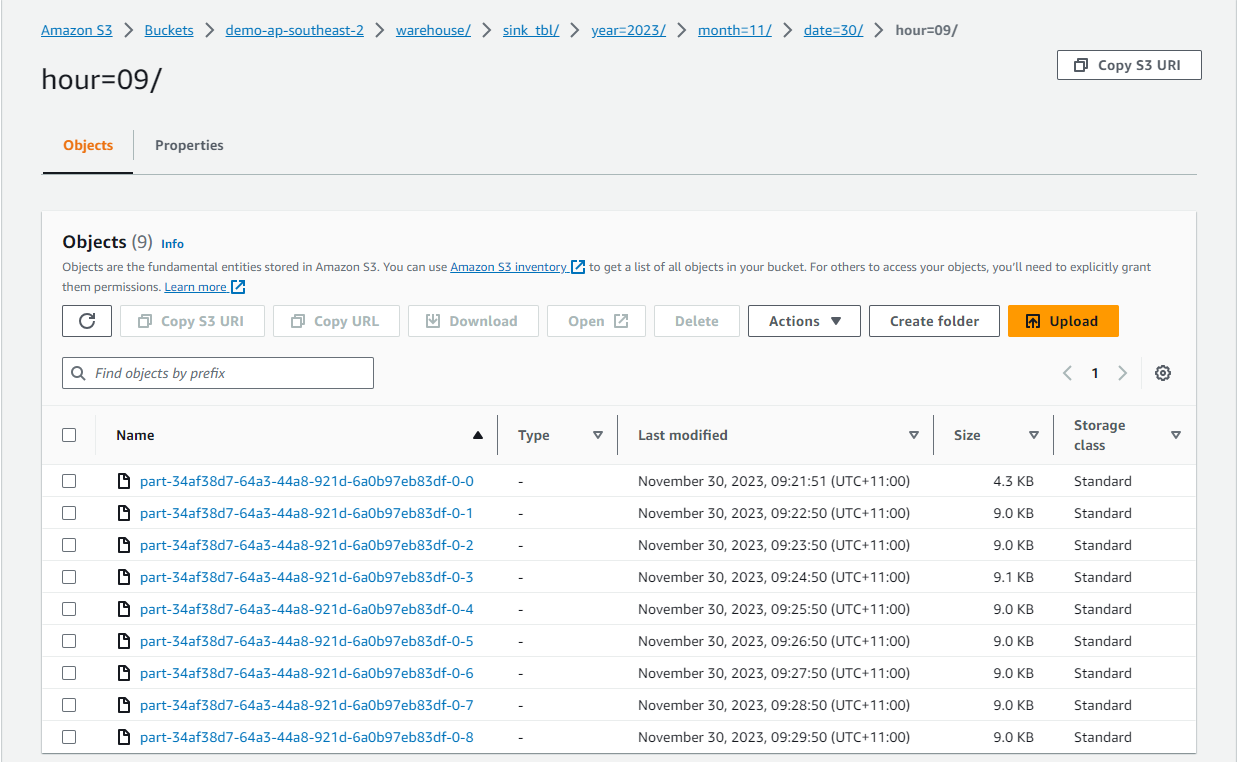
As expected, the output files are written into S3 in Apache Hive style partitions, and they are created in one minute interval.
Spark Consumer
A simple PySpark application is created to query the output table. Note that, as the partitions are not added dynamically, MSCK REPAIR TABLE command is executed before querying the table.
1# apps/spark/consumer.py
2from pyspark.sql import SparkSession
3
4if __name__ == "__main__":
5 spark = SparkSession.builder.appName("Consume Orders").getOrCreate()
6 spark.sparkContext.setLogLevel("FATAL")
7 spark.sql("MSCK REPAIR TABLE demo.sink_tbl")
8 spark.sql("SELECT * FROM demo.sink_tbl").show()
The Spark app can be submitted as shown below. Note that the application is accessible in the container because the project folder is volume-mapped to the container folder (/home/hadoop/project).
1## spark submit
2docker exec spark spark-submit \
3 --master local[*] \
4 --deploy-mode client \
5 /home/hadoop/project/apps/spark/consumer.py
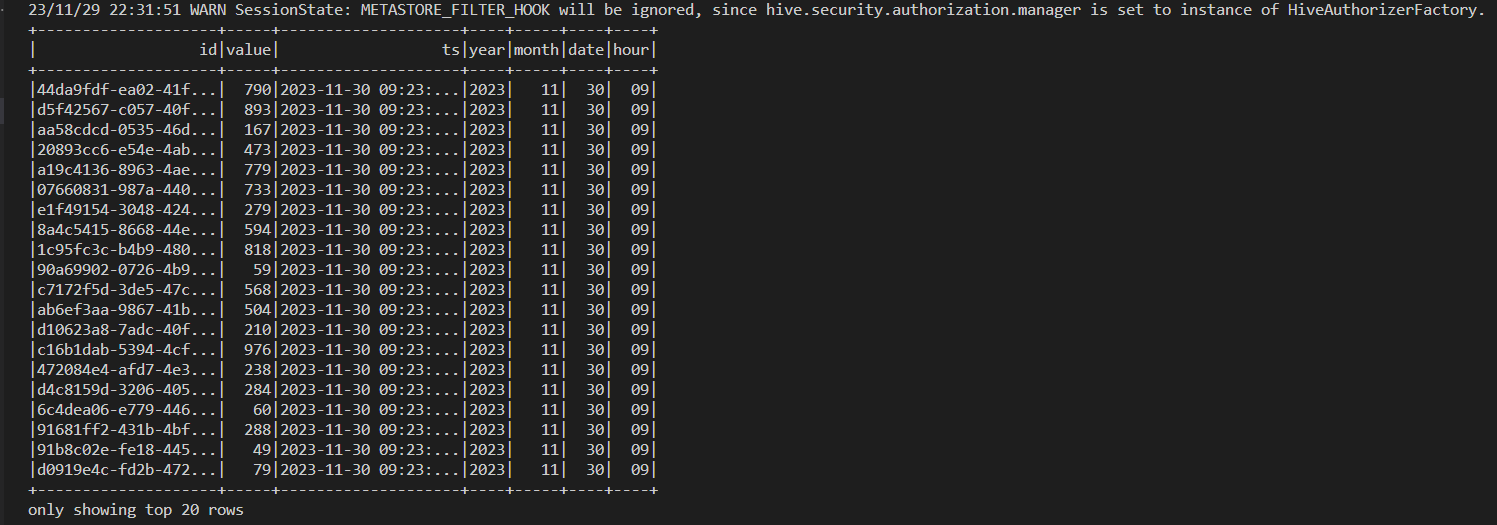
The app queries the output table successfully and shows the result as expected.
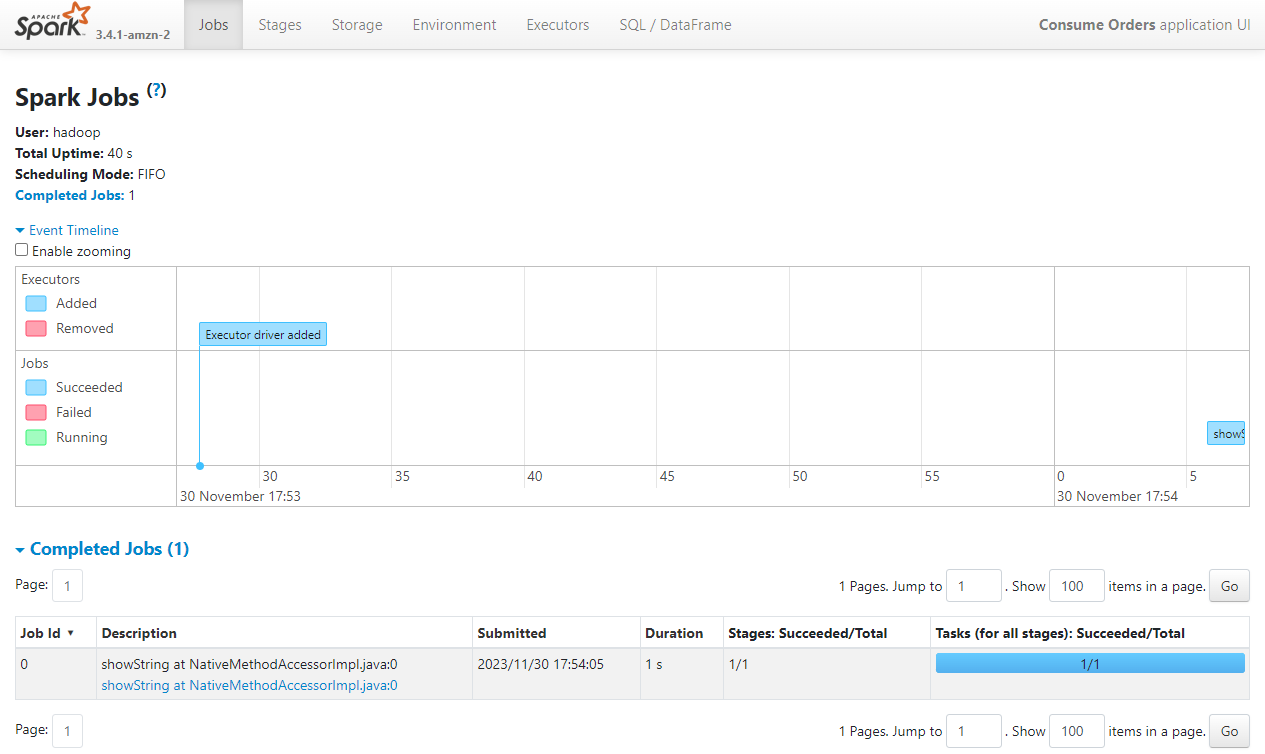
We can check the performance of the Spark application on the Spark History Server (localhost:18080).
Summary
In this post, we discussed how to set up a local development environment for Apache Flink and Spark using the EMR container images. For the former, a custom Docker image was created, which downloads dependent connector Jar files into the Flink library folder, fixes process startup issues, and updates Hadoop configurations for Glue Data Catalog integration. For the latter, instead of creating a custom image, the EMR image was used to launch the Spark container where the required configuration updates are added at runtime via volume-mapping. After illustrating the environment setup, we discussed a solution where data ingestion/processing is performed in real time using Apache Flink and the processed data is consumed by Apache Spark for analysis.










Comments