
Apache Kafka is one of the key technologies for implementing data streaming architectures. Strimzi provides a way to run an Apache Kafka cluster and related resources on Kubernetes in various deployment configurations. In this series of posts, we will discuss how to create a Kafka cluster, to develop Kafka client applications in Python and to build a data pipeline using Kafka connectors on Kubernetes.
Setup Kafka Cluster
The Kafka cluster is deployed using the Strimzi Operator on a Minikube cluster. We install Strimzi version 0.27.1 and Kubernetes version 1.24.7 as we use Kafka version 2.8.1 - see this page for details about Kafka version compatibility. Once the Minikube CLI and Docker are installed, a Minikube cluster can be created by specifying the desired Kubernetes version as shown below.
1minikube start --cpus='max' --memory=10240 --addons=metrics-server --kubernetes-version=v1.24.7
Deploy Strimzi Operator
The project repository keeps manifest files that can be used to deploy the Strimzi Operator and related resources. We can download the relevant manifest file by specifying the desired version. By default, the manifest file assumes the resources are deployed in the myproject namespace. As we deploy them in the default namespace, however, we need to change the resource namespace accordingly using sed.
The resources that are associated with the Strimzi Operator can be deployed using the kubectl create command. Note that over 20 resources are deployed from the manifest file including Kafka-related custom resources. Among those, we use the Kafka, KafkaConnect and KafkaConnector custom resources in this series.
1## download and update strimzi oeprator manifest
2STRIMZI_VERSION="0.27.1"
3DOWNLOAD_URL=https://github.com/strimzi/strimzi-kafka-operator/releases/download/$STRIMZI_VERSION/strimzi-cluster-operator-$STRIMZI_VERSION.yaml
4curl -L -o manifests/strimzi-cluster-operator-$STRIMZI_VERSION.yaml ${DOWNLOAD_URL}
5# update namespace from myproject to default
6sed -i 's/namespace: .*/namespace: default/' manifests/strimzi-cluster-operator-$STRIMZI_VERSION.yaml
7
8## deploy strimzi cluster operator
9kubectl create -f manifests/strimzi-cluster-operator-$STRIMZI_VERSION.yaml
We can check the Strimzi Operator runs as a Deployment.
1kubectl get deploy,rs,po
2# NAME READY UP-TO-DATE AVAILABLE AGE
3# deployment.apps/strimzi-cluster-operator 1/1 1 1 3m44s
4
5# NAME DESIRED CURRENT READY AGE
6# replicaset.apps/strimzi-cluster-operator-7cc4b5759c 1 1 1 3m44s
7
8# NAME READY STATUS RESTARTS AGE
9# pod/strimzi-cluster-operator-7cc4b5759c-q45nv 1/1 Running 0 3m43s
Deploy Kafka Cluster
We deploy a Kafka cluster with two brokers and one Zookeeper node. It has both internal and external listeners on port 9092 and 29092 respectively. Note that the external listener is configured as the nodeport type so that the associating service can be accessed from the host machine. Also, the cluster is configured to allow automatic creation of topics (auto.create.topics.enable: “true”) and the default number of partition is set to 3 (num.partitions: 3).
1# manifests/kafka-cluster.yaml
2apiVersion: kafka.strimzi.io/v1beta2
3kind: Kafka
4metadata:
5 name: demo-cluster
6spec:
7 kafka:
8 replicas: 2
9 version: 2.8.1
10 listeners:
11 - name: plain
12 port: 9092
13 type: internal
14 tls: false
15 - name: external
16 port: 29092
17 type: nodeport
18 tls: false
19 storage:
20 type: jbod
21 volumes:
22 - id: 0
23 type: persistent-claim
24 size: 20Gi
25 deleteClaim: true
26 config:
27 offsets.topic.replication.factor: 1
28 transaction.state.log.replication.factor: 1
29 transaction.state.log.min.isr: 1
30 default.replication.factor: 1
31 min.insync.replicas: 1
32 inter.broker.protocol.version: 2.8
33 auto.create.topics.enable: "true"
34 num.partitions: 3
35 zookeeper:
36 replicas: 1
37 storage:
38 type: persistent-claim
39 size: 10Gi
40 deleteClaim: true
The Kafka cluster can be deployed using the kubectl create command as shown below.
1kubectl create -f manifests/kafka-cluster.yaml
The Kafka and Zookeeper nodes are deployed as StatefulSets as it provides guarantees about the ordering and uniqueness of the associating Pods. It also creates multiple services, and we use the following services in this series.
- communication within Kubernetes cluster
- demo-cluster-kafka-bootstrap - to access Kafka brokers from the client and management apps
- demo-cluster-zookeeper-client - to access Zookeeper node from the management app
- communication from host
- demo-cluster-kafka-external-bootstrap - to access Kafka brokers from the client apps
1kubectl get all -l app.kubernetes.io/instance=demo-cluster
2# NAME READY STATUS RESTARTS AGE
3# pod/demo-cluster-kafka-0 1/1 Running 0 67s
4# pod/demo-cluster-kafka-1 1/1 Running 0 67s
5# pod/demo-cluster-zookeeper-0 1/1 Running 0 109s
6
7# NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
8# service/demo-cluster-kafka-bootstrap ClusterIP 10.106.148.7 <none> 9091/TCP,9092/TCP 67s
9# service/demo-cluster-kafka-brokers ClusterIP None <none> 9090/TCP,9091/TCP,9092/TCP 67s
10# service/demo-cluster-kafka-external-0 NodePort 10.109.118.191 <none> 29092:31733/TCP 67s
11# service/demo-cluster-kafka-external-1 NodePort 10.105.36.159 <none> 29092:31342/TCP 67s
12# service/demo-cluster-kafka-external-bootstrap NodePort 10.97.88.48 <none> 29092:30247/TCP 67s
13# service/demo-cluster-zookeeper-client ClusterIP 10.97.131.183 <none> 2181/TCP 109s
14# service/demo-cluster-zookeeper-nodes ClusterIP None <none> 2181/TCP,2888/TCP,3888/TCP 109s
15
16# NAME READY AGE
17# statefulset.apps/demo-cluster-kafka 2/2 67s
18# statefulset.apps/demo-cluster-zookeeper 1/1 109s
Update 2024-07-11
In later versions of the Strimzi operator manage the Kafka and Zookeeper nodes using the StrimziPodSet custom resource. Check this post for details about how to deploy a Kafka cluster using Strimzi 0.39.0.
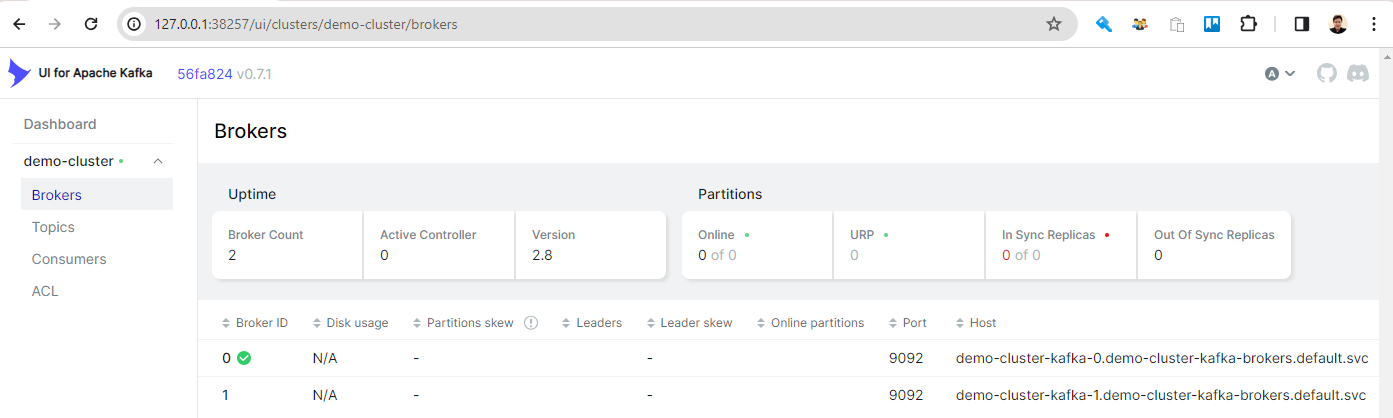
Deploy Kafka UI
UI for Apache Kafka (kafka-ui) is a free and open-source Kafka management application, and it is deployed as a Kubernetes Deployment. The Deployment is configured to have a single instance, and the Kafka cluster access details are specified as environment variables. The app is associated by a service of the NodePort type for external access.
1# manifests/kafka-ui.yaml
2apiVersion: v1
3kind: Service
4metadata:
5 labels:
6 app: kafka-ui
7 name: kafka-ui
8spec:
9 type: NodePort
10 ports:
11 - port: 8080
12 targetPort: 8080
13 selector:
14 app: kafka-ui
15---
16apiVersion: apps/v1
17kind: Deployment
18metadata:
19 labels:
20 app: kafka-ui
21 name: kafka-ui
22spec:
23 replicas: 1
24 selector:
25 matchLabels:
26 app: kafka-ui
27 template:
28 metadata:
29 labels:
30 app: kafka-ui
31 spec:
32 containers:
33 - image: provectuslabs/kafka-ui:v0.7.1
34 name: kafka-ui-container
35 ports:
36 - containerPort: 8080
37 env:
38 - name: KAFKA_CLUSTERS_0_NAME
39 value: demo-cluster
40 - name: KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS
41 value: demo-cluster-kafka-bootstrap:9092
42 - name: KAFKA_CLUSTERS_0_ZOOKEEPER
43 value: demo-cluster-zookeeper-client:2181
44 resources: {}
The Kafka management app (kafka-ui) can be deployed using the kubectl create command as shown below.
1kubectl create -f manifests/kafka-ui.yaml
2
3kubectl get all -l app=kafka-ui
4# NAME READY STATUS RESTARTS AGE
5# pod/kafka-ui-6d55c756b8-tznlp 1/1 Running 0 54s
6
7# NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
8# service/kafka-ui NodePort 10.99.20.37 <none> 8080:31119/TCP 54s
9
10# NAME READY UP-TO-DATE AVAILABLE AGE
11# deployment.apps/kafka-ui 1/1 1 1 54s
12
13# NAME DESIRED CURRENT READY AGE
14# replicaset.apps/kafka-ui-6d55c756b8 1 1 1 54s
We can use the minikube service command to obtain the Kubernetes URL for the kafka-ui service.
1minikube service kafka-ui --url
2# http://127.0.0.1:38257
3# ❗ Because you are using a Docker driver on linux, the terminal needs to be open to run it.
Produce and Consume Messages
We can produce and consume messages with Kafka command utilities by creating two Pods in separate terminals. The Pods start the producer (kafka-console-producer.sh) and consumer (kafka-console-consumer.sh) scripts respectively while specifying necessary arguments such as the bootstrap server address and topic name. We can see that the records created by the producer are appended in the consumer terminal.
1kubectl run kafka-producer --image=quay.io/strimzi/kafka:0.27.1-kafka-2.8.1 --rm -it --restart=Never \
2 -- bin/kafka-console-producer.sh --bootstrap-server demo-cluster-kafka-bootstrap:9092 --topic demo-topic
3
4# >product: apples, quantity: 5
5# >product: lemons, quantity: 7
1kubectl run kafka-consumer --image=quay.io/strimzi/kafka:0.27.1-kafka-2.8.1 --rm -it --restart=Never \
2 -- bin/kafka-console-consumer.sh --bootstrap-server demo-cluster-kafka-bootstrap:9092 --topic demo-topic --from-beginning
3
4# product: apples, quantity: 5
5# product: lemons, quantity: 7
We can also check the messages in the management app as shown below.
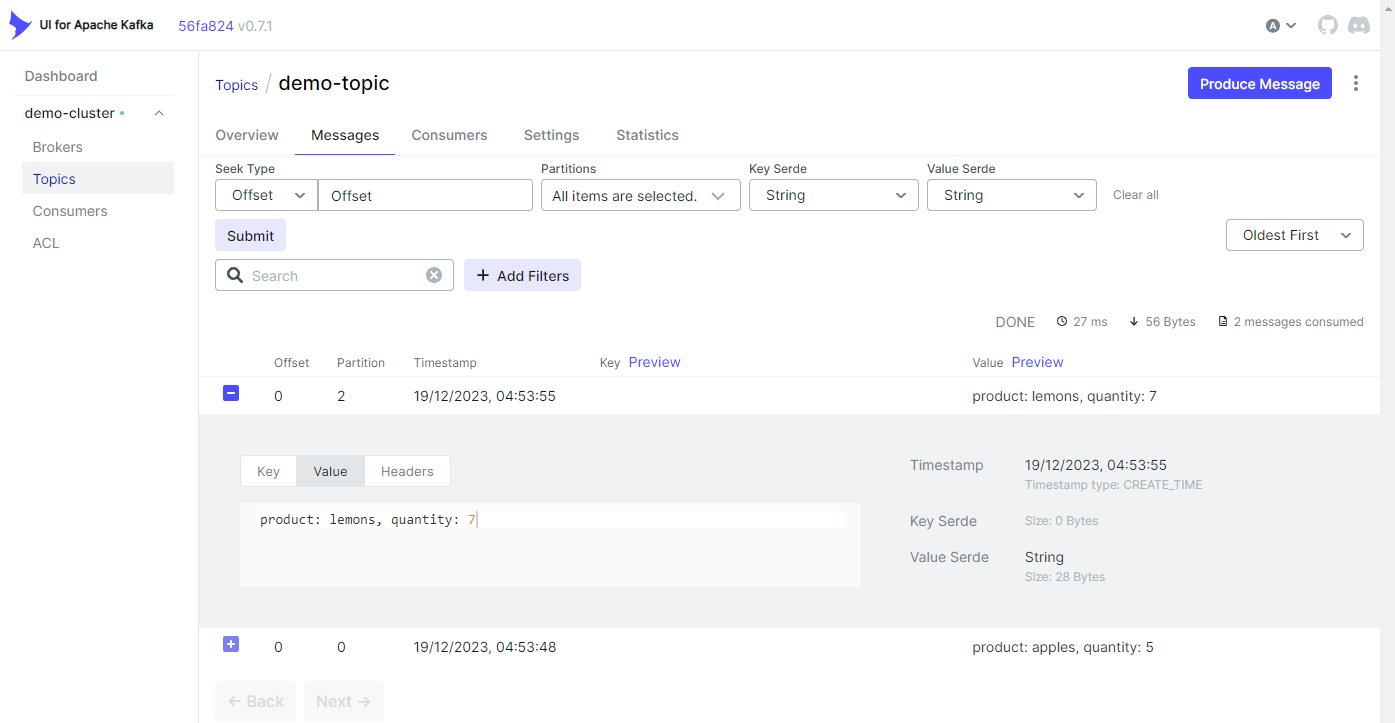
Delete Resources
The Kubernetes resources and Minikube cluster can be removed by the kubectl delete and minikube delete commands respectively.
1## delete resources
2kubectl delete -f manifests/kafka-cluster.yaml
3kubectl delete -f manifests/kafka-ui.yaml
4kubectl delete -f manifests/strimzi-cluster-operator-$STRIMZI_VERSION.yaml
5
6## delete minikube
7minikube delete
Summary
Apache Kafka is one of the key technologies for implementing data streaming architectures. Strimzi provides a way to run an Apache Kafka cluster and related resources on Kubernetes in various deployment configurations. In this post, we discussed how to deploy a Kafka cluster on a Minikube cluster using the Strimzi Operator. Also, it is demonstrated how to produce and consume messages using the Kafka command line utilities.










Comments