
In this series of posts, we discuss data warehouse/lakehouse examples using data build tool (dbt) including ETL orchestration with Apache Airflow. In Part 1, we developed a dbt project on PostgreSQL with fictional pizza shop data. Two dimension tables that keep product and user records are created as Type 2 slowly changing dimension (SCD Type 2) tables, and one transactional fact table is built to keep pizza orders. In this post, we discuss how to set up an ETL process on the project using Apache Airflow.
- Part 1 Modelling on PostgreSQL
- Part 2 ETL on PostgreSQL via Airflow (this post)
- Part 3 Modelling on BigQuery
- Part 4 ETL on BigQuery via Airflow
- Part 5 Modelling on Amazon Athena
- Part 6 ETL on Amazon Athena via Airflow
Infrastructure
Apache Airflow and PostgreSQL are used in this post, and they are deployed locally using Docker Compose. The source can be found in the GitHub repository of this post.
Database
As Part 1, a PostgreSQL server is deployed using Docker Compose. See the previous post for details about (1) how fictional pizza shop data sets are made available, and (2) how the database is bootstrapped using a script (bootstrap.sql), which creates necessary schemas/tables as well as loads initial records to the tables. Note that the database cluster is shared with Airflow and thus a database and role named airflow are created for it - see below for details.
1# compose-orchestration.yml
2...
3services:
4 postgres:
5 image: postgres:13
6 container_name: postgres
7 ports:
8 - 5432:5432
9 networks:
10 - appnet
11 environment:
12 POSTGRES_USER: devuser
13 POSTGRES_PASSWORD: password
14 POSTGRES_DB: devdb
15 TZ: Australia/Sydney
16 volumes:
17 - ./initdb/scripts:/docker-entrypoint-initdb.d
18 - ./initdb/data:/tmp
19 - postgres_data:/var/lib/postgresql/data
20...
1-- initdb/scripts/bootstrap.sql
2
3...
4
5CREATE DATABASE airflow;
6CREATE ROLE airflow
7LOGIN
8PASSWORD 'airflow';
9GRANT ALL ON DATABASE airflow TO airflow;
Airflow
Airflow is simplified by using the Local Executor where both scheduling and task execution are handled by the airflow scheduler service - i.e. AIRFLOW__CORE__EXECUTOR: LocalExecutor. Also, it is configured to be able to run the dbt project (see Part 1 for details) within the scheduler service by
- installing the dbt-postgre package as an additional pip package, and
- volume-mapping folders that keep the dbt project and dbt project profile
1# compose-orchestration.yml
2version: "3"
3x-airflow-common: &airflow-common
4 image: ${AIRFLOW_IMAGE_NAME:-apache/airflow:2.8.0}
5 networks:
6 - appnet
7 environment: &airflow-common-env
8 AIRFLOW__CORE__EXECUTOR: LocalExecutor
9 AIRFLOW__DATABASE__SQL_ALCHEMY_CONN: postgresql+psycopg2://airflow:airflow@postgres/airflow
10 # For backward compatibility, with Airflow <2.3
11 AIRFLOW__CORE__SQL_ALCHEMY_CONN: postgresql+psycopg2://airflow:airflow@postgres/airflow
12 AIRFLOW__CORE__FERNET_KEY: ""
13 AIRFLOW__CORE__DAGS_ARE_PAUSED_AT_CREATION: "true"
14 AIRFLOW__CORE__LOAD_EXAMPLES: "false"
15 AIRFLOW__API__AUTH_BACKENDS: "airflow.api.auth.backend.basic_auth"
16 # install dbt-postgres==1.7.4
17 _PIP_ADDITIONAL_REQUIREMENTS: ${_PIP_ADDITIONAL_REQUIREMENTS:- dbt-postgres==1.7.4 pendulum}
18 volumes:
19 - ./airflow/dags:/opt/airflow/dags
20 - ./airflow/plugins:/opt/airflow/plugins
21 - ./airflow/logs:/opt/airflow/logs
22 - ./pizza_shop:/tmp/pizza_shop # dbt project
23 - ./airflow/dbt-profiles:/opt/airflow/dbt-profiles # dbt profiles
24 user: "${AIRFLOW_UID:-50000}:0"
25 depends_on: &airflow-common-depends-on
26 postgres:
27 condition: service_healthy
28
29services:
30 postgres:
31 image: postgres:13
32 container_name: postgres
33 ports:
34 - 5432:5432
35 networks:
36 - appnet
37 environment:
38 POSTGRES_USER: devuser
39 POSTGRES_PASSWORD: password
40 POSTGRES_DB: devdb
41 TZ: Australia/Sydney
42 volumes:
43 - ./initdb/scripts:/docker-entrypoint-initdb.d
44 - ./initdb/data:/tmp
45 - postgres_data:/var/lib/postgresql/data
46 healthcheck:
47 test: ["CMD", "pg_isready", "-U", "airflow"]
48 interval: 5s
49 retries: 5
50
51 airflow-webserver:
52 <<: *airflow-common
53 container_name: webserver
54 command: webserver
55 ports:
56 - 8080:8080
57 depends_on:
58 <<: *airflow-common-depends-on
59 airflow-init:
60 condition: service_completed_successfully
61
62 airflow-scheduler:
63 <<: *airflow-common
64 command: scheduler
65 container_name: scheduler
66 environment:
67 <<: *airflow-common-env
68 depends_on:
69 <<: *airflow-common-depends-on
70 airflow-init:
71 condition: service_completed_successfully
72
73 airflow-init:
74 <<: *airflow-common
75 container_name: init
76 entrypoint: /bin/bash
77 command:
78 - -c
79 - |
80 mkdir -p /sources/logs /sources/dags /sources/plugins
81 chown -R "${AIRFLOW_UID}:0" /sources/{logs,dags,plugins}
82 exec /entrypoint airflow version
83 environment:
84 <<: *airflow-common-env
85 _AIRFLOW_DB_UPGRADE: "true"
86 _AIRFLOW_WWW_USER_CREATE: "true"
87 _AIRFLOW_WWW_USER_USERNAME: ${_AIRFLOW_WWW_USER_USERNAME:-airflow}
88 _AIRFLOW_WWW_USER_PASSWORD: ${_AIRFLOW_WWW_USER_PASSWORD:-airflow}
89 _PIP_ADDITIONAL_REQUIREMENTS: ""
90 user: "0:0"
91 volumes:
92 - .:/sources
93
94volumes:
95 airflow_log_volume:
96 driver: local
97 name: airflow_log_volume
98 postgres_data:
99 driver: local
100 name: postgres_data
101
102networks:
103 appnet:
104 name: app-network
The Airflow and PostgreSQL services can be deployed as shown below. Note that it is recommended to specify the host user’s ID as the AIRFLOW_UID value. Otherwise, Airflow can fail to launch due to insufficient permission to write logs.
1$ AIRFLOW_UID=$(id -u) docker-compose -f compose-orchestration.yml up -d
Once started, we can visit the Airflow web server on http://localhost:8080.
ETL Job
A simple ETL job (demo_etl) is created, which updates source records (update_records) followed by running and testing the dbt project. Note that the dbt project and profile are accessible as they are volume-mapped to the Airflow scheduler container.
1# airflow/dags/operators.py
2import pendulum
3from airflow.models.dag import DAG
4from airflow.operators.bash import BashOperator
5from airflow.operators.python import PythonOperator
6
7import update_records
8
9with DAG(
10 dag_id="demo_etl",
11 schedule=None,
12 start_date=pendulum.datetime(2024, 1, 1, tz="Australia/Sydney"),
13 catchup=False,
14 tags=["pizza"],
15):
16 task_records_update = PythonOperator(
17 task_id="update_records", python_callable=update_records.main
18 )
19
20 task_dbt_run = BashOperator(
21 task_id="dbt_run",
22 bash_command="dbt run --profiles-dir /opt/airflow/dbt-profiles --project-dir /tmp/pizza_shop",
23 )
24
25 task_dbt_test = BashOperator(
26 task_id="dbt_test",
27 bash_command="dbt test --profiles-dir /opt/airflow/dbt-profiles --project-dir /tmp/pizza_shop",
28 )
29
30 task_records_update >> task_dbt_run >> task_dbt_test
Update Records
As dbt takes care of data transformation only, we should create a task that updates source records. As shown below, the task updates as many as a half of records of the dimension tables (products and users) and appends 5,000 order records in a single run.
1# airflow/dags/update_records.py
2import os
3import json
4import dataclasses
5import random
6import string
7
8import psycopg2
9import psycopg2.extras
10
11
12class DbHelper:
13 def __init__(self) -> None:
14 self.conn = self.connect_db()
15
16 def connect_db(self):
17 conn = psycopg2.connect(
18 host=os.getenv("DB_HOST", "postgres"),
19 database=os.getenv("DB_NAME", "devdb"),
20 user=os.getenv("DB_USER", "devuser"),
21 password=os.getenv("DB_PASSWORD", "password"),
22 )
23 conn.autocommit = False
24 return conn
25
26 def get_connection(self):
27 if (self.conn is None) or (self.conn.closed):
28 self.conn = self.connect_db()
29
30 def fetch_records(self, stmt: str):
31 self.get_connection()
32 with self.conn.cursor(cursor_factory=psycopg2.extras.RealDictCursor) as cur:
33 cur.execute(stmt)
34 return cur.fetchall()
35
36 def update_records(self, stmt: str, records: list, to_fetch: bool = True):
37 self.get_connection()
38 with self.conn.cursor() as cur:
39 values = psycopg2.extras.execute_values(cur, stmt, records, fetch=to_fetch)
40 self.conn.commit()
41 if to_fetch:
42 return values
43
44 def commit(self):
45 if not self.conn.closed:
46 self.conn.commit()
47
48 def close(self):
49 if self.conn and (not self.conn.closed):
50 self.conn.close()
51
52
53@dataclasses.dataclass
54class Product:
55 id: int
56 name: int
57 description: int
58 price: float
59 category: str
60 image: str
61
62 def __hash__(self) -> int:
63 return self.id
64
65 @classmethod
66 def from_json(cls, r: dict):
67 return cls(**r)
68
69 @staticmethod
70 def load(db: DbHelper):
71 stmt = """
72 WITH windowed AS (
73 SELECT
74 *,
75 ROW_NUMBER() OVER (PARTITION BY id ORDER BY created_at DESC) AS rn
76 FROM staging.products
77 )
78 SELECT id, name, description, price, category, image
79 FROM windowed
80 WHERE rn = 1;
81 """
82 return [Product.from_json(r) for r in db.fetch_records(stmt)]
83
84 @staticmethod
85 def update(db: DbHelper, percent: float = 0.5):
86 stmt = "INSERT INTO staging.products(id, name, description, price, category, image) VALUES %s RETURNING id, price"
87 products = Product.load(db)
88 records = set(random.choices(products, k=int(len(products) * percent)))
89 for r in records:
90 r.price = r.price + 10
91 values = db.update_records(
92 stmt, [list(dataclasses.asdict(r).values()) for r in records], True
93 )
94 return values
95
96
97@dataclasses.dataclass
98class User:
99 id: int
100 first_name: str
101 last_name: str
102 email: str
103 residence: str
104 lat: float
105 lon: float
106
107 def __hash__(self) -> int:
108 return self.id
109
110 @classmethod
111 def from_json(cls, r: dict):
112 return cls(**r)
113
114 @staticmethod
115 def load(db: DbHelper):
116 stmt = """
117 WITH windowed AS (
118 SELECT
119 *,
120 ROW_NUMBER() OVER (PARTITION BY id ORDER BY created_at DESC) AS rn
121 FROM staging.users
122 )
123 SELECT id, first_name, last_name, email, residence, lat, lon
124 FROM windowed
125 WHERE rn = 1;
126 """
127 return [User.from_json(r) for r in db.fetch_records(stmt)]
128
129 @staticmethod
130 def update(db: DbHelper, percent: float = 0.5):
131 stmt = "INSERT INTO staging.users(id, first_name, last_name, email, residence, lat, lon) VALUES %s RETURNING id, email"
132 users = User.load(db)
133 records = set(random.choices(users, k=int(len(users) * percent)))
134 for r in records:
135 r.email = f"{''.join(random.choices(string.ascii_letters, k=5)).lower()}@email.com"
136 values = db.update_records(
137 stmt, [list(dataclasses.asdict(r).values()) for r in records], True
138 )
139 return values
140
141
142@dataclasses.dataclass
143class Order:
144 user_id: int
145 items: str
146
147 @classmethod
148 def create(cls):
149 order_items = [
150 {"product_id": id, "quantity": random.randint(1, 5)}
151 for id in set(random.choices(range(1, 82), k=random.randint(1, 10)))
152 ]
153 return cls(
154 user_id=random.randint(1, 10000),
155 items=json.dumps([item for item in order_items]),
156 )
157
158 @staticmethod
159 def append(db: DbHelper, num_orders: int = 5000):
160 stmt = "INSERT INTO staging.orders(user_id, items) VALUES %s RETURNING id"
161 records = [Order.create() for _ in range(num_orders)]
162 values = db.update_records(
163 stmt, [list(dataclasses.asdict(r).values()) for r in records], True
164 )
165 return values
166
167
168def main():
169 db = DbHelper()
170 ## update product and user records
171 print(f"{len(Product.update(db))} product records updated")
172 print(f"{len(User.update(db))} user records updated")
173 ## created order records
174 print(f"{len(Order.append(db))} order records created")
The details of the ETL job can be found on the Airflow web server as shown below.
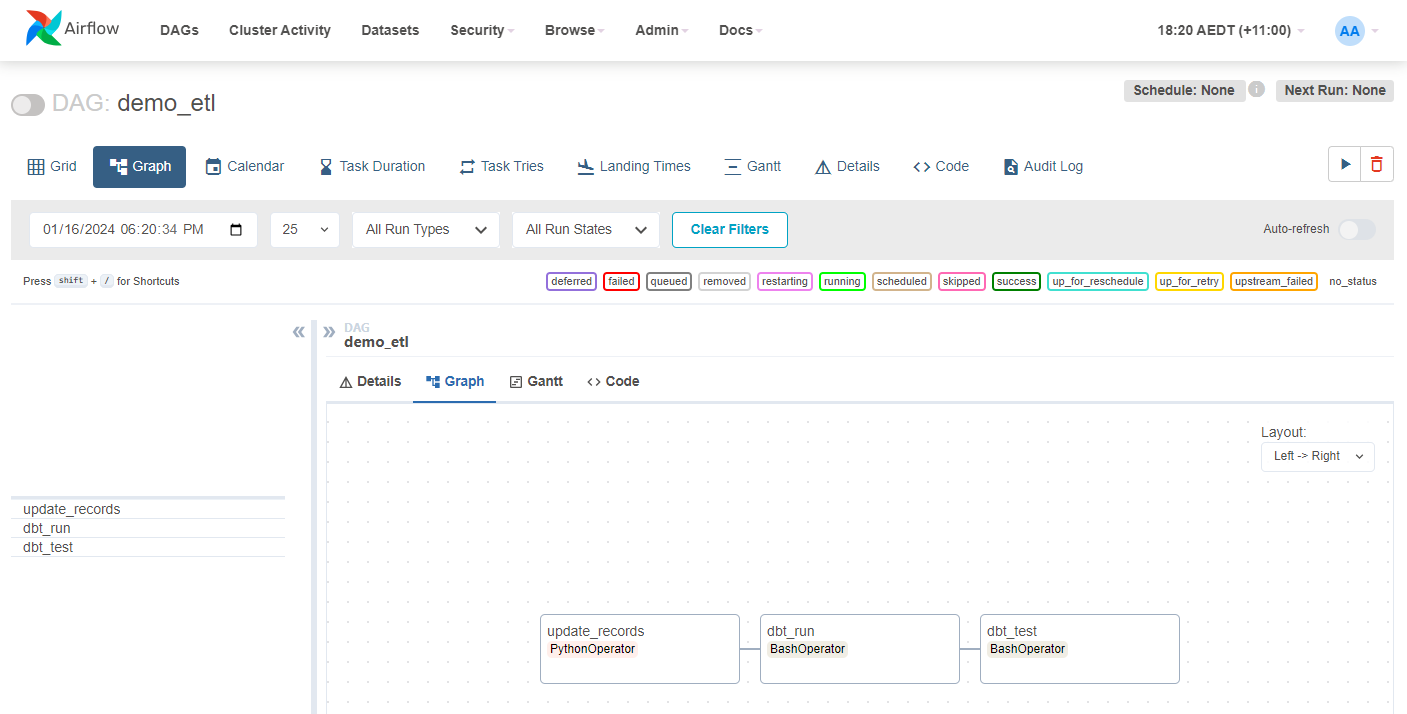
Run ETL
Below shows example product dimension records after the ETL job is completed twice. The product is updated in the second job and a new surrogate key is assigned as well as the valid_from and valid_to column values are updated accordingly.
1SELECT product_key, price, created_at, valid_from, valid_to
2FROM dev.dim_products
3WHERE product_id = 61
4
5product_key |price|created_at |valid_from |valid_to |
6--------------------------------+-----+-------------------+-------------------+-------------------+
76a326183ce19f0db7f4af2ab779cc2dd|185.0|2024-01-16 18:18:12|2024-01-16 18:18:12|2024-01-16 18:22:19|
8d2e27002c0f474d507c60772161673aa|195.0|2024-01-16 18:22:19|2024-01-16 18:22:19|2199-12-31 00:00:00|
When I query the fact table for orders with the same product ID, I can check correct product key values are mapped - note value_to is not inclusive.
1SELECT o.order_key, o.product_key, o.product_id, p.price, o.created_at
2FROM dev.fct_orders o
3JOIN dev.dim_products p ON o.product_key = p.product_key
4WHERE o.product_id = 61 AND order_id IN (5938, 28146)
5
6order_key |product_key |product_id|price|created_at |
7--------------------------------+--------------------------------+----------+-----+-------------------+
8cb650e3bb22e3be1d112d59a44482560|6a326183ce19f0db7f4af2ab779cc2dd| 61|185.0|2024-01-16 18:18:12|
9470c2fa24f97a2a8dfac2510cc49f942|d2e27002c0f474d507c60772161673aa| 61|195.0|2024-01-16 18:22:19|
Summary
In this series of posts, we discuss data warehouse/lakehouse examples using data build tool (dbt) including ETL orchestration with Apache Airflow. In this post, we discussed how to set up an ETL process on the dbt project developed in Part 1 using Airflow. A demo ETL job was created that updates records followed by running and testing the dbt project. Finally, the result of ETL job was validated by checking sample records.










Comments