
In Part 1 and Part 3, we developed data build tool (dbt) projects that target PostgreSQL and BigQuery using fictional pizza shop data. The data is modelled by SCD type 2 dimension tables and one transactional fact table. While the order records should be joined with dimension tables to get complete details for PostgreSQL, the fact table is denormalized using nested and repeated fields to improve query performance for BigQuery.
Open Table Formats such as Apache Iceberg bring a new opportunity that implements data warehousing features in a data lake (i.e. data lakehouse) and Amazon Athena is probably the easiest way to perform such tasks on AWS. In this post, we create a new dbt project that targets Apache Iceberg where transformations are performed on Amazon Athena. Data modelling is similar to the BigQuery project where the dimension tables are modelled by the SCD type 2 approach and the fact table is denormalized using the array and struct data types.
- Part 1 Modelling on PostgreSQL
- Part 2 ETL on PostgreSQL via Airflow
- Part 3 Modelling on BigQuery
- Part 4 ETL on BigQuery via Airflow
- Part 5 Modelling on Amazon Athena (this post)
- Part 6 ETL on Amazon Athena via Airflow
Setup Amazon Athena
Amazon Athena is used in the post, and the source can be found in the GitHub repository of this post.
Prepare Data
Fictional pizza shop data from Building Real-Time Analytics Systems is used in this post. There are three data sets - products, users and orders. The first two data sets are copied from the book’s GitHub repository and saved into the setup/data folder. The last order data set is generated by the following Python script.
1# setup/generate_orders.py
2import os
3import csv
4import dataclasses
5import random
6import json
7
8
9@dataclasses.dataclass
10class Order:
11 user_id: int
12 items: str
13
14 @classmethod
15 def create(self):
16 order_items = [
17 {"product_id": id, "quantity": random.randint(1, 5)}
18 for id in set(random.choices(range(1, 82), k=random.randint(1, 10)))
19 ]
20 return Order(
21 user_id=random.randint(1, 10000),
22 items=json.dumps([item for item in order_items]),
23 )
24
25
26if __name__ == "__main__":
27 """
28 Generate random orders given by the NUM_ORDERS environment variable.
29 - orders.csv will be written to ./data folder
30
31 Example:
32 python generate_orders.py
33 NUM_ORDERS=10000 python generate_orders.py
34 """
35 NUM_ORDERS = int(os.getenv("NUM_ORDERS", "20000"))
36 CURRENT_DIR = os.path.dirname(os.path.realpath(__file__))
37 orders = [Order.create() for _ in range(NUM_ORDERS)]
38
39 filepath = os.path.join(CURRENT_DIR, "data", "orders.csv")
40 if os.path.exists(filepath):
41 os.remove(filepath)
42
43 with open(os.path.join(CURRENT_DIR, "data", "orders.csv"), "w") as f:
44 writer = csv.writer(f)
45 writer.writerow(["user_id", "items"])
46 for order in orders:
47 writer.writerow(dataclasses.asdict(order).values())
Below shows sample order records generated by the script. It includes user ID and order items.
1user_id,items
22911,"[{""product_id"": 57, ""quantity"": 3}, {""product_id"": 66, ""quantity"": 4}, {""product_id"": 27, ""quantity"": 4}]"
34483,"[{""product_id"": 13, ""quantity"": 3}]"
4894,"[{""product_id"": 59, ""quantity"": 1}, {""product_id"": 22, ""quantity"": 5}]"
The folder structure of source data sets and order generation script can be found below.
1$ tree setup/ -P "*.csv|generate*"
2setup/
3├── data
4│ ├── orders.csv
5│ ├── products.csv
6│ └── users.csv
7└── generate_orders.py
Insert Source Data
The source data is inserted using the AWS SDK for pandas (awswrangler) package. It is a simple process that reads records from the source data files as Pandas DataFrame, adds incremental ID/creation datetime and inserts to S3. Upon successful insertion, we can check the source records are saved into S3 and their table metadata is registered in a Glue database named pizza_shop.
1# setup/insert_records.py
2import os
3import datetime
4
5import boto3
6import botocore
7import pandas as pd
8import awswrangler as wr
9
10
11class QueryHelper:
12 def __init__(self, db_name: str, bucket_name: str, current_dir: str = None):
13 self.db_name = db_name
14 self.bucket_name = bucket_name
15 self.current_dir = current_dir or os.path.dirname(os.path.realpath(__file__))
16 self.glue_client = boto3.client(
17 "glue", region_name=os.getenv("AWS_REGION", "ap-southeast-2")
18 )
19
20 def check_db(self):
21 try:
22 self.glue_client.get_database(Name=self.db_name)
23 return True
24 except botocore.exceptions.ClientError as err:
25 if err.response["Error"]["Code"] == "EntityNotFoundException":
26 return False
27 else:
28 raise err
29
30 def create_db(self):
31 try:
32 self.glue_client.create_database(
33 DatabaseInput={
34 "Name": self.db_name,
35 }
36 )
37 return True
38 except botocore.exceptions.ClientError as err:
39 if err.response["Error"]["Code"] == "AlreadyExistsException":
40 return True
41 else:
42 raise err
43
44 def read_source(self, file_name: str):
45 df = pd.read_csv(os.path.join(self.current_dir, "data", file_name))
46 df.insert(0, "id", range(1, len(df) + 1))
47 df.insert(
48 df.shape[1],
49 "created_at",
50 datetime.datetime.now(),
51 )
52 return df
53
54 def load_source(self, df: pd.DataFrame, obj_name: str):
55 if obj_name not in ["users", "products", "orders"]:
56 raise ValueError("object name should be one of users, products, orders")
57 wr.s3.to_parquet(
58 df=df,
59 path=f"s3://{self.bucket_name}/staging/{obj_name}/",
60 dataset=True,
61 database=self.db_name,
62 table=f"staging_{obj_name}",
63 boto3_session=boto3.Session(
64 region_name=os.getenv("AWS_REGION", "ap-southeast-2")
65 ),
66 )
67
68
69if __name__ == "__main__":
70 query_helper = QueryHelper(db_name="pizza_shop", bucket_name="dbt-pizza-shop-demo")
71 if not query_helper.check_db():
72 query_helper.create_db()
73 print("inserting products...")
74 products = query_helper.read_source("products.csv")
75 query_helper.load_source(products, "products")
76 print("inserting users...")
77 users = query_helper.read_source("users.csv")
78 query_helper.load_source(users, "users")
79 print("inserting orders...")
80 orders = query_helper.read_source("orders.csv")
81 query_helper.load_source(orders, "orders")
Setup DBT Project
A dbt project named pizza_shop is created using the dbt-athena-community package (dbt-athena-community==1.7.1). Specifically, it is created using the dbt init command, and it bootstraps the project in the pizza_shop folder as well as adds the project profile to the dbt profiles file. See this page for details about how to set up Amazon Athena for a dbt project.
1# $HOME/.dbt/profiles.yml
2pizza_shop:
3 outputs:
4 dev:
5 type: athena
6 database: awsdatacatalog
7 schema: pizza_shop
8 region_name: ap-southeast-2
9 s3_data_dir: s3://dbt-pizza-shop-demo/dbt-data/
10 s3_staging_dir: s3://dbt-pizza-shop-demo/dbt-staging/
11 threads: 4
12 target: dev
Project Sources
Recall that three staging tables are created earlier, and they are used as sources of the project. Their details are kept in sources.yml to be referred easily in other models.
1# pizza_shop/models/sources.yml
2version: 2
3
4sources:
5 - name: raw
6 schema: pizza_shop
7 tables:
8 - name: users
9 identifier: staging_users
10 - name: products
11 identifier: staging_products
12 - name: orders
13 identifier: staging_orders
Using the raw sources, three models are created by performing simple transformations such as adding surrogate keys using the dbt_utils package and changing column names. Note that, as the products and users dimension tables are kept by Type 2 slowly changing dimension (SCD type 2), the surrogate keys are used to uniquely identify relevant dimension records.
1-- pizza_shop/models/src/src_products.sql
2WITH raw_products AS (
3 SELECT * FROM {{ source('raw', 'products') }}
4)
5SELECT
6 {{ dbt_utils.generate_surrogate_key(['name', 'description', 'price', 'category', 'image']) }} as product_key,
7 id AS product_id,
8 name,
9 description,
10 price,
11 category,
12 image,
13 created_at
14FROM raw_products
1-- pizza_shop/models/src/src_users.sql
2WITH raw_users AS (
3 SELECT * FROM {{ source('raw', 'users') }}
4)
5SELECT
6 {{ dbt_utils.generate_surrogate_key(['first_name', 'last_name', 'email', 'residence', 'lat', 'lon']) }} as user_key,
7 id AS user_id,
8 first_name,
9 last_name,
10 email,
11 residence,
12 lat AS latitude,
13 lon AS longitude,
14 created_at
15FROM raw_users
1-- pizza_shop/models/src/src_orders.sql
2WITH raw_orders AS (
3 SELECT * FROM {{ source('raw', 'orders') }}
4)
5SELECT
6 id AS order_id,
7 user_id,
8 items,
9 created_at
10FROM raw_orders
Data Modelling
The dimension tables are materialized as table where the table type is chosen as iceberg. Also, for SCD type 2, two additional columns are created - valid_from and valid_to. The extra columns are for setting up a time range where a record is applicable, and they are used to map a relevant record in the fact table when there are multiple dimension records, having the same natural key. Note that SCD type 2 tables can also be maintained by dbt snapshots.
1-- pizza_shop/models/dim/dim_products.sql
2{{
3 config(
4 materialized = 'table',
5 table_type='iceberg',
6 format='parquet',
7 table_properties={
8 'optimize_rewrite_delete_file_threshold': '2'
9 })
10}}
11WITH src_products AS (
12 SELECT
13 product_key,
14 product_id,
15 name,
16 description,
17 price,
18 category,
19 image,
20 CAST(created_at AS TIMESTAMP(6)) AS created_at
21 FROM {{ ref('src_products') }}
22)
23SELECT
24 *,
25 created_at AS valid_from,
26 COALESCE(
27 LEAD(created_at, 1) OVER (PARTITION BY product_id ORDER BY created_at),
28 CAST('2199-12-31' AS TIMESTAMP(6))
29 ) AS valid_to
30FROM src_products
1-- pizza_shop/models/dim/dim_users.sql
2{{
3 config(
4 materialized = 'table',
5 table_type='iceberg',
6 format='parquet',
7 table_properties={
8 'optimize_rewrite_delete_file_threshold': '2'
9 })
10}}
11WITH src_users AS (
12 SELECT
13 user_key,
14 user_id,
15 first_name,
16 last_name,
17 email,
18 residence,
19 latitude,
20 longitude,
21 CAST(created_at AS TIMESTAMP(6)) AS created_at
22 FROM {{ ref('src_users') }}
23)
24SELECT
25 *,
26 created_at AS valid_from,
27 COALESCE(
28 LEAD(created_at, 1) OVER (PARTITION BY user_id ORDER BY created_at),
29 CAST('2199-12-31' AS TIMESTAMP(6))
30 ) AS valid_to
31FROM src_users
When it comes to the transactional fact table, its materialization and incremental strategy are chosen to be incremental and append respectively as only new records need to be added to it. Also, it is created as a partitioned table for improving query performance by applying the partition transform of day on the created_at column. Finally, the user and order items records are pre-joined from the relevant dimension tables. As can be seen later, the order items (product) and user fields are converted into an array of struct and struct data types.
1-- pizza_shop/models/fct/fct_orders.sql
2{{
3 config(
4 materialized = 'incremental',
5 table_type='iceberg',
6 format='parquet',
7 partitioned_by=['day(created_at)'],
8 incremental_strategy='append',
9 unique_key='order_id',
10 table_properties={
11 'optimize_rewrite_delete_file_threshold': '2'
12 })
13}}
14WITH dim_products AS (
15 SELECT * FROM {{ ref('dim_products') }}
16), dim_users AS (
17 SELECT * FROM {{ ref('dim_users') }}
18), expanded_orders AS (
19 SELECT
20 o.order_id,
21 o.user_id,
22 row.product_id,
23 row.quantity,
24 CAST(created_at AS TIMESTAMP(6)) AS created_at
25 FROM {{ ref('src_orders') }} AS o
26 CROSS JOIN UNNEST(CAST(JSON_PARSE(o.items) as ARRAY(ROW(product_id INTEGER, quantity INTEGER)))) as t(row)
27)
28SELECT
29 o.order_id,
30 ARRAY_AGG(
31 CAST(
32 ROW(p.product_key, o.product_id, p.name, p.price, o.quantity, p.description, p.category, p.image)
33 AS ROW(key VARCHAR, id BIGINT, name VARCHAR, price DOUBLE, quantity INTEGER, description VARCHAR, category VARCHAR, image VARCHAR))
34 ) AS product,
35 CAST(
36 ROW(u.user_key, o.user_id, u.first_name, u.last_name, u.email, u.residence, u.latitude, u.longitude)
37 AS ROW(key VARCHAR, id BIGINT, first_name VARCHAR, last_name VARCHAR, email VARCHAR, residence VARCHAR, latitude DOUBLE, longitude DOUBLE)) AS user,
38 o.created_at
39FROM expanded_orders o
40JOIN dim_products p
41 ON o.product_id = p.product_id
42 AND o.created_at >= p.valid_from
43 AND o.created_at < p.valid_to
44JOIN dim_users u
45 ON o.user_id = u.user_id
46 AND o.created_at >= u.valid_from
47 AND o.created_at < u.valid_to
48{% if is_incremental() %}
49 WHERE o.created_at > (SELECT max(created_at) from {{ this }})
50{% endif %}
51GROUP BY
52 o.order_id,
53 u.user_key,
54 o.user_id,
55 u.first_name,
56 u.last_name,
57 u.email,
58 u.residence,
59 u.latitude,
60 u.longitude,
61 o.created_at
We can keep the final models in a separate YAML file for testing and enhanced documentation.
1# pizza_shop/models/schema.yml
2version: 2
3
4models:
5 - name: dim_products
6 description: Products table, which is converted into SCD Type 2
7 columns:
8 - name: product_key
9 description: |
10 Primary key of the table
11 Surrogate key, which is generated by md5 hash using the following columns
12 - name, description, price, category, image
13 tests:
14 - not_null
15 - unique
16 - name: product_id
17 description: Natural key of products
18 - name: name
19 description: Porduct name
20 - name: description
21 description: Product description
22 - name: price
23 description: Product price
24 - name: category
25 description: Product category
26 - name: image
27 description: Product image
28 - name: created_at
29 description: Timestamp when the record is loaded
30 - name: valid_from
31 description: Effective start timestamp of the corresponding record (inclusive)
32 - name: valid_to
33 description: Effective end timestamp of the corresponding record (exclusive)
34 - name: dim_users
35 description: Users table, which is converted into SCD Type 2
36 columns:
37 - name: user_key
38 description: |
39 Primary key of the table
40 Surrogate key, which is generated by md5 hash using the following columns
41 - first_name, last_name, email, residence, lat, lon
42 tests:
43 - not_null
44 - unique
45 - name: user_id
46 description: Natural key of users
47 - name: first_name
48 description: First name
49 - name: last_name
50 description: Last name
51 - name: email
52 description: Email address
53 - name: residence
54 description: User address
55 - name: latitude
56 description: Latitude of user address
57 - name: longitude
58 description: Longitude of user address
59 - name: created_at
60 description: Timestamp when the record is loaded
61 - name: valid_from
62 description: Effective start timestamp of the corresponding record (inclusive)
63 - name: valid_to
64 description: Effective end timestamp of the corresponding record (exclusive)
65 - name: fct_orders
66 description: Orders fact table. Order items are exploded into rows
67 columns:
68 - name: order_id
69 description: Natural key of orders
70 - name: product
71 description: |
72 Array of products in an order.
73 A product is an array of struct where the following attributes are pre-joined from the dim_products table:
74 key (product_key), id (product_id), name, price, quantity, description, category, and image
75 - name: user
76 description: |
77 A struct where the following attributes are pre-joined from the dim_users table:
78 key (user_key), id (user_id), first_name, last_name, email, residence, latitude, and longitude
79 - name: created_at
80 description: Timestamp when the record is loaded
The project can be executed using the dbt run command as shown below.
1$ dbt run
208:55:00 Running with dbt=1.7.9
308:55:00 Registered adapter: athena=1.7.1
408:55:00 Found 6 models, 4 tests, 3 sources, 0 exposures, 0 metrics, 537 macros, 0 groups, 0 semantic models
508:55:00
608:55:02 Concurrency: 4 threads (target='dev')
708:55:02
808:55:02 1 of 6 START sql view model pizza_shop.src_orders .............................. [RUN]
908:55:02 2 of 6 START sql view model pizza_shop.src_products ............................ [RUN]
1008:55:02 3 of 6 START sql view model pizza_shop.src_users ............................... [RUN]
1108:55:05 1 of 6 OK created sql view model pizza_shop.src_orders ......................... [OK -1 in 3.28s]
1208:55:05 3 of 6 OK created sql view model pizza_shop.src_users .......................... [OK -1 in 3.27s]
1308:55:05 2 of 6 OK created sql view model pizza_shop.src_products ....................... [OK -1 in 3.28s]
1408:55:05 4 of 6 START sql table model pizza_shop.dim_users .............................. [RUN]
1508:55:05 5 of 6 START sql table model pizza_shop.dim_products ........................... [RUN]
1608:55:10 5 of 6 OK created sql table model pizza_shop.dim_products ...................... [OK 81 in 5.18s]
1708:55:11 4 of 6 OK created sql table model pizza_shop.dim_users ......................... [OK 10000 in 6.16s]
1808:55:11 6 of 6 START sql incremental model pizza_shop.fct_orders ....................... [RUN]
1908:55:22 6 of 6 OK created sql incremental model pizza_shop.fct_orders .................. [OK 20000 in 10.23s]
2008:55:22
2108:55:22 Finished running 3 view models, 2 table models, 1 incremental model in 0 hours 0 minutes and 21.41 seconds (21.41s).
2208:55:22
2308:55:22 Completed successfully
2408:55:22
2508:55:22 Done. PASS=6 WARN=0 ERROR=0 SKIP=0 TOTAL=6
Also, the project can be tested using the dbt test command.
1$ dbt test
208:55:29 Running with dbt=1.7.9
308:55:30 Registered adapter: athena=1.7.1
408:55:30 Found 6 models, 4 tests, 3 sources, 0 exposures, 0 metrics, 537 macros, 0 groups, 0 semantic models
508:55:30
608:55:31 Concurrency: 4 threads (target='dev')
708:55:31
808:55:31 1 of 4 START test not_null_dim_products_product_key ............................ [RUN]
908:55:31 2 of 4 START test not_null_dim_users_user_key .................................. [RUN]
1008:55:31 3 of 4 START test unique_dim_products_product_key .............................. [RUN]
1108:55:31 4 of 4 START test unique_dim_users_user_key .................................... [RUN]
1208:55:33 3 of 4 PASS unique_dim_products_product_key .................................... [PASS in 2.17s]
1308:55:33 2 of 4 PASS not_null_dim_users_user_key ........................................ [PASS in 2.23s]
1408:55:34 4 of 4 PASS unique_dim_users_user_key .......................................... [PASS in 3.16s]
1508:55:34 1 of 4 PASS not_null_dim_products_product_key .................................. [PASS in 3.20s]
1608:55:34
1708:55:34 Finished running 4 tests in 0 hours 0 minutes and 4.37 seconds (4.37s).
1808:55:34
1908:55:34 Completed successfully
2008:55:34
2108:55:34 Done. PASS=4 WARN=0 ERROR=0 SKIP=0 TOTAL=4
Fact Table Structure
The schema of the fact table can be found below. The product and user are marked as the array and struct type respectively.
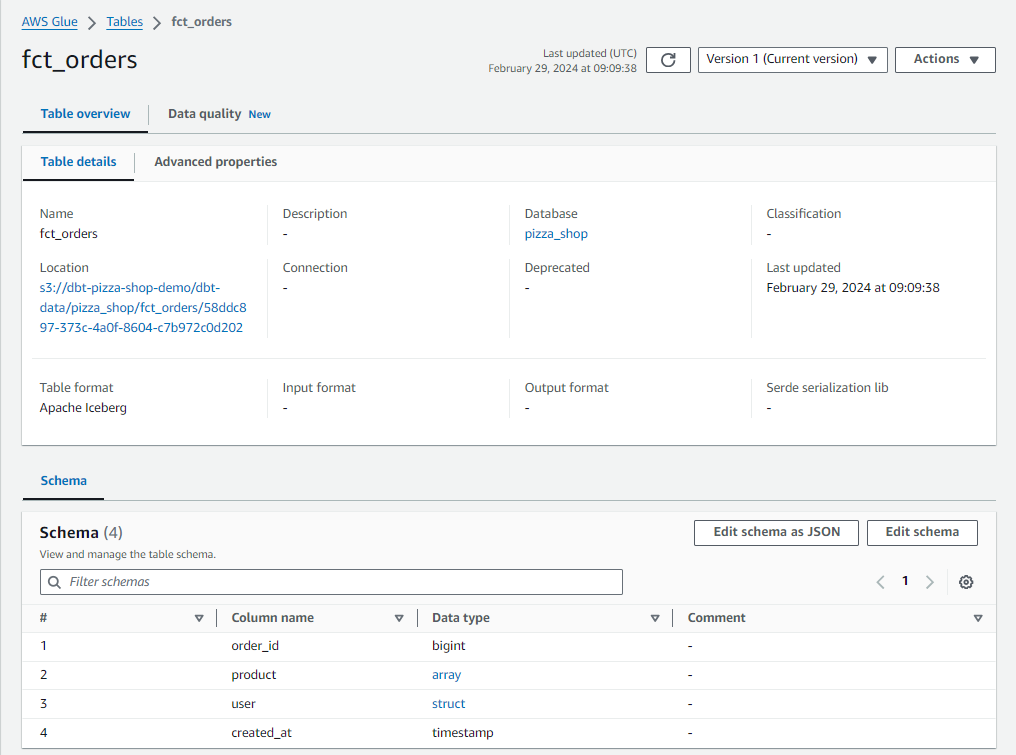
When we click an individual link, its detailed schema appears in a pop-up window as shown below.
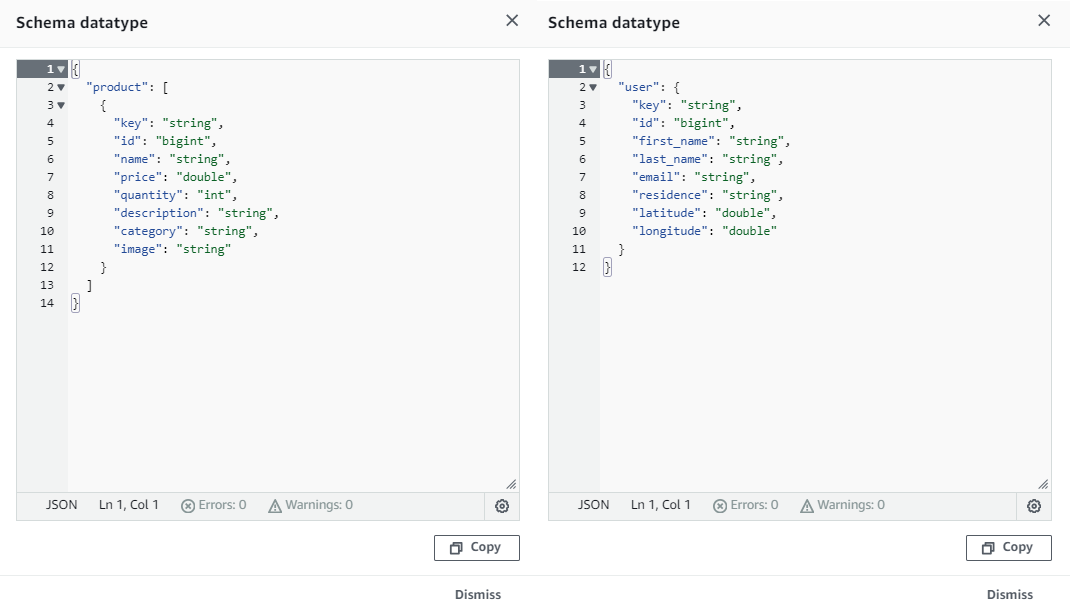
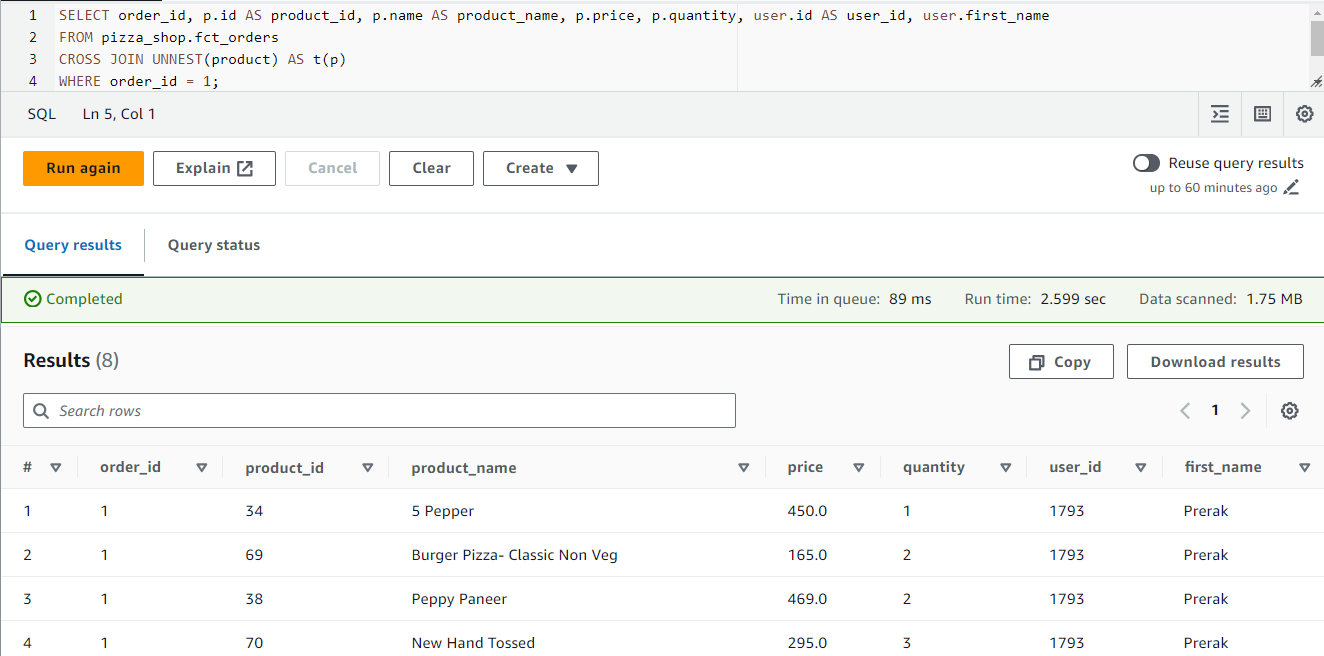
In Athena, we can flatten the product array into multiple rows by using CROSS JOIN in conjunction with the UNNEST operator.
Update Records
Although we will discuss ETL orchestration with Apache Airflow in the next post, here I illustrate how the dimension and fact tables change when records are updated.
Product
First, a new record is inserted into the staging_products table, and the price is set to increase by 10.
1-- // update a product record
2INSERT INTO pizza_shop.staging_products (id, name, description, price, category, image, created_at)
3 SELECT 1, name, description, price + 10, category, image, CAST(date_add('hour', 11, CURRENT_TIMESTAMP) AS TIMESTAMP)
4 FROM pizza_shop.staging_products
5 WHERE id = 1;
6
7SELECT id, name, price, category, created_at
8FROM pizza_shop.staging_products
9WHERE id = 1
10ORDER BY created_at;
11
12# id name price category created_at
131 1 Moroccan Spice Pasta Pizza - Veg 335.0 veg pizzas 2024-02-29 19:54:03.999
142 1 Moroccan Spice Pasta Pizza - Veg 345.0 veg pizzas 2024-02-29 20:02:17.304
When we execute the dbt run command again, we see the corresponding dimension table reflects the change by adding a new record and updating valid_from and valid_to columns accordingly. With this change, any later order record that has this product should be mapped into the new product record.
1SELECT product_key, price, created_at, valid_from, valid_to
2FROM pizza_shop.dim_products
3WHERE product_id = 1
4ORDER BY created_at;
5
6# product_key price created_at valid_from valid_to
71 b8c187845db8b7e55626659cfbb8aea1 335.0 2024-02-29 19:54:03.999000 2024-02-29 19:54:03.999000 2024-02-29 20:02:17.304000
82 590d4eb8831d78ae84f44b90e930d2f3 345.0 2024-02-29 20:02:17.304000 2024-02-29 20:02:17.304000 2199-12-31 00:00:00.000000
User
Also, a new record is inserted into the staging_users table while modifying the email address.
1-- // update a user record
2INSERT INTO pizza_shop.staging_users (id, first_name, last_name, email, residence, lat, lon, created_at)
3 SELECT 1, first_name, last_name, 'john.doe@example.com', residence, lat, lon, CAST(date_add('hour', 11, CURRENT_TIMESTAMP) AS TIMESTAMP)
4 FROM pizza_shop.staging_users
5 WHERE id = 1;
6
7SELECT id, first_name, last_name, email, created_at
8FROM pizza_shop.staging_users
9WHERE id = 1
10ORDER BY created_at;
11
12# id first_name last_name email created_at
131 1 Kismat Shroff drishyamallick@hotmail.com 2024-02-29 19:54:04.846
142 1 Kismat Shroff john.doe@example.com 2024-02-29 20:04:05.915
Again the corresponding dimension table reflects the change by adding a new record and updating valid_from and valid_to columns accordingly.
1SELECT user_key, email, valid_from, valid_to
2FROM pizza_shop.dim_users
3WHERE user_id = 1
4ORDER BY created_at;
5
6# user_key email valid_from valid_to
71 48afd277176d7aed4e0d03ab15033f28 drishyamallick@hotmail.com 2024-02-29 19:54:04.846000 2024-02-29 20:04:05.915000
82 ee798a3c387582d3581a6f907c25af98 john.doe@example.com 2024-02-29 20:04:05.915000 2199-12-31 00:00:00.000000
Order
We insert a new order record that has two items where the IDs of the first and second products are 1 and 2 respectively. In this example, we expect the first product maps to the updated product record while the record of the second product remains the same. We can check it by querying the new order record together with an existing record that has corresponding products. As expected, the query result shows the product record is updated only in the new order record.
1-- // add an order record
2INSERT INTO pizza_shop.staging_orders(id, user_id, items, created_at)
3VALUES (
4 20001,
5 1,
6 '[{"product_id": 1, "quantity": 2}, {"product_id": 2, "quantity": 3}]',
7 CAST(date_add('hour', 11, CURRENT_TIMESTAMP) AS TIMESTAMP)
8);
9
10SELECT o.order_id, p.key, p.id, p.price, p.quantity, o.created_at
11FROM pizza_shop.fct_orders AS o
12CROSS JOIN UNNEST(o.product) as t(p)
13WHERE o.order_id in (11146, 20001) AND p.id IN (1, 2)
14ORDER BY o.order_id;
15
16# order_id key id price quantity created_at
171 11146 * b8c187845db8b7e55626659cfbb8aea1 1 335.0 1 2024-02-29 19:54:05.803000
182 11146 8311b52111a924582c0fe5cb566cfa9a 2 60.0 2 2024-02-29 19:54:05.803000
193 20001 * 590d4eb8831d78ae84f44b90e930d2f3 1 345.0 2 2024-02-29 20:08:32.756000
204 20001 8311b52111a924582c0fe5cb566cfa9a 2 60.0 3 2024-02-29 20:08:32.756000
Summary
In this series, we discuss practical examples of data warehouse and lakehouse development where data transformation is performed by the data build tool (dbt) and ETL is managed by Apache Airflow. Open Table Formats such as Apache Iceberg bring a new opportunity that implements data warehousing features in a data lake (i.e. data lakehouse). In this post, we created a new dbt project that targets Apache Iceberg where transformations are performed on Amazon Athena. Data modelling was similar to the BigQuery project in Part 3 where the dimension tables were modelled by the SCD type 2 approach and the fact table was denormalized using the array and struct data types. Finally, impacts of record updates were discussed in detail.










Comments