
Apache Beam and Apache Flink are open-source frameworks for parallel, distributed data processing at scale. Flink has DataStream and Table/SQL APIs and the former has more capacity to develop sophisticated data streaming applications. The DataStream API of PyFlink, Flink’s Python API, however, is not as complete as its Java counterpart, and it doesn’t provide enough capability to extend when there are missing features in Python. Recently I had a chance to look through Apache Beam and found it supports more possibility to extend and/or customise its features.
In this series of posts, we discuss local development of Apache Beam pipelines using Python. In Part 1, a basic Beam pipeline is introduced, followed by demonstrating how to utilise Jupyter notebooks for interactive development. Several notebook examples are covered including Beam SQL and Beam DataFrames. Batch pipelines will be developed in Part 2, and we use pipelines from GCP Python DataFlow Quest while modifying them to access local resources only. Each batch pipeline has two versions with/without SQL. Beam doesn’t have its own processing engine and Beam pipelines are executed on a runner such as Apache Flink, Apache Spark, or Google Cloud Dataflow instead. We will use the Flink Runner for deploying streaming pipelines as it supports a wide range of features especially in streaming context. In Part 3, we will discuss how to set up a local Flink cluster as well as a local Kafka cluster for data source and sink. A streaming pipeline with/without Beam SQL will be built in Part 4, and this series concludes with illustrating unit testing of existing pipelines in Part 5.
- Part 1 Pipeline, Notebook, SQL and DataFrame (this post)
- Part 2 Batch Pipelines
- Part 3 Flink Runner
- Part 4 Streaming Pipelines
- Part 5 Testing Pipelines
Prerequisites
We need to install Java, Docker and GraphViz.
- Java 11 to launch a local Flink cluster
- Docker for Kafka connection/executing Beam SQL as well as deploying a Kafka cluster
- GraphViz to visualize pipeline DAGs
1$ java --version
2openjdk 11.0.22 2024-01-16
3OpenJDK Runtime Environment (build 11.0.22+7-post-Ubuntu-0ubuntu220.04.1)
4OpenJDK 64-Bit Server VM (build 11.0.22+7-post-Ubuntu-0ubuntu220.04.1, mixed mode, sharing)
5
6$ docker --version
7Docker version 24.0.6, build ed223bc
8
9$ dot -V
10dot - graphviz version 2.43.0 (0)
Also, I use Python 3.10.13 and Beam 2.53.0 - supported Python versions are 3.8, 3.9, 3.10, 3.11. The following list shows key dependent packages.
- apache-beam[gcp,aws,azure,test,docs,interactive]==2.53.0
- jupyterlab==4.1.2
- kafka-python
- faker
- geocoder
The source of this post can be found in the GitHub repository.
Data Generator
Website visit log is used as source data for both batch and streaming data pipelines. It begins with creating a configurable number of users and simulates their website visit history. When the source argument is batch, it writes the records into a folder named inputs while those are sent to a Kafka topic named website-visit if the source is streaming - we will talk further about streaming source generation in Part 3. Below shows how to execute the script for batch and streaming sources respectively.
1# Batch example:
2python datagen/generate_data.py --source batch --num_users 20 --num_events 10000 --max_lag_seconds 60
3
4# Streaming example:
5python datagen/generate_data.py --source streaming --num_users 5 --delay_seconds 0.5
1# datagen/generate_data.py
2import os
3import json
4import uuid
5import argparse
6import datetime
7import time
8import math
9from faker import Faker
10import geocoder
11import random
12from kafka import KafkaProducer
13
14
15class EventGenerator:
16 def __init__(
17 self,
18 source: str,
19 num_users: int,
20 num_events: int,
21 max_lag_seconds: int,
22 delay_seconds: float,
23 bootstrap_servers: list,
24 topic_name: str,
25 file_name: str = str(uuid.uuid4()),
26 ):
27 self.source = source
28 self.num_users = num_users
29 self.num_events = num_events
30 self.max_lag_seconds = max_lag_seconds
31 self.delay_seconds = delay_seconds
32 self.bootstrap_servers = bootstrap_servers
33 self.topic_name = topic_name
34 self.file_name = file_name
35 self.user_pool = self.create_user_pool()
36 if self.source == "streaming":
37 self.kafka_producer = self.create_producer()
38
39 def create_user_pool(self):
40 """
41 Returns a list of user instances given the max number of users.
42 Each user instances is a dictionary that has the following attributes:
43 ip, id, lat, lng, user_agent, age_bracket, opted_into_marketing
44 """
45 init_fields = [
46 "ip",
47 "id",
48 "lat",
49 "lng",
50 "user_agent",
51 "age_bracket",
52 "opted_into_marketing",
53 ]
54 user_pool = []
55 for _ in range(self.num_users):
56 user_pool.append(dict(zip(init_fields, self.set_initial_values())))
57 return user_pool
58
59 def create_producer(self):
60 """
61 Returns a KafkaProducer instance
62 """
63 return KafkaProducer(
64 bootstrap_servers=self.bootstrap_servers,
65 value_serializer=lambda v: json.dumps(v).encode("utf-8"),
66 key_serializer=lambda v: json.dumps(v).encode("utf-8"),
67 )
68
69 def set_initial_values(self, faker=Faker()):
70 """
71 Returns initial user attribute values using Faker
72 """
73 ip = faker.ipv4()
74 lookup = geocoder.ip(ip)
75 try:
76 lat, lng = lookup.latlng
77 except Exception:
78 lat, lng = "", ""
79 id = str(hash(f"{ip}{lat}{lng}"))
80 user_agent = random.choice(
81 [
82 faker.firefox,
83 faker.chrome,
84 faker.safari,
85 faker.internet_explorer,
86 faker.opera,
87 ]
88 )()
89 age_bracket = random.choice(["18-25", "26-40", "41-55", "55+"])
90 opted_into_marketing = random.choice([True, False])
91 return ip, id, lat, lng, user_agent, age_bracket, opted_into_marketing
92
93 def set_req_info(self):
94 """
95 Returns a tuple of HTTP request information - http_request, http_response, file_size_bytes
96 """
97 uri = random.choice(
98 [
99 "home.html",
100 "archea.html",
101 "archaea.html",
102 "bacteria.html",
103 "eucharya.html",
104 "protozoa.html",
105 "amoebozoa.html",
106 "chromista.html",
107 "cryptista.html",
108 "plantae.html",
109 "coniferophyta.html",
110 "fungi.html",
111 "blastocladiomycota.html",
112 "animalia.html",
113 "acanthocephala.html",
114 ]
115 )
116 file_size_bytes = random.choice(range(100, 500))
117 http_request = f"{random.choice(['GET'])} {uri} HTTP/1.0"
118 http_response = random.choice([200])
119 return http_request, http_response, file_size_bytes
120
121 def append_to_file(self, event: dict):
122 """
123 Appends a website visit event record into an event output file.
124 """
125 parent_dir = os.path.dirname(os.path.dirname(os.path.realpath(__file__)))
126 with open(
127 os.path.join(parent_dir, "inputs", f"{self.file_name}.out"), "a"
128 ) as fp:
129 fp.write(f"{json.dumps(event)}\n")
130
131 def send_to_kafka(self, event: dict):
132 """
133 Sends a website visit event record into a Kafka topic.
134 """
135 try:
136 self.kafka_producer.send(
137 self.topic_name,
138 key={"event_id": event["id"], "event_ts": event["event_ts"]},
139 value=event,
140 )
141 self.kafka_producer.flush()
142 except Exception as e:
143 raise RuntimeError("fails to send a message") from e
144
145 def generate_events(self):
146 """
147 Generate webstie visit events as per the max number events.
148 Events are either saved to an output file (batch) or sent to a Kafka topic (streaming).
149 """
150 num_events = 0
151 while True:
152 num_events += 1
153 if num_events > self.num_events:
154 break
155 event_ts = datetime.datetime.utcnow() + datetime.timedelta(
156 seconds=random.uniform(0, self.max_lag_seconds)
157 )
158 req_info = dict(
159 zip(
160 ["http_request", "http_response", "file_size_bytes"],
161 self.set_req_info(),
162 )
163 )
164 event = {
165 **random.choice(self.user_pool),
166 **req_info,
167 **{
168 "event_datetime": event_ts.isoformat(timespec="milliseconds"),
169 "event_ts": int(event_ts.timestamp() * 1000),
170 },
171 }
172 divide_by = 100 if self.source == "batch" else 10
173 if num_events % divide_by == 0:
174 print(f"{num_events} events created so far...")
175 print(event)
176 if self.source == "batch":
177 self.append_to_file(event)
178 else:
179 self.send_to_kafka(event)
180 time.sleep(self.delay_seconds or 0)
181
182
183if __name__ == "__main__":
184 """
185 Batch example:
186 python datagen/generate_data.py --source batch --num_users 20 --num_events 10000 --max_lag_seconds 60
187 Streaming example:
188 python datagen/generate_data.py --source streaming --num_users 5 --delay_seconds 0.5
189 """
190 parser = argparse.ArgumentParser(__file__, description="Web Server Data Generator")
191 parser.add_argument(
192 "--source",
193 "-s",
194 type=str,
195 default="batch",
196 choices=["batch", "streaming"],
197 help="The data source - batch or streaming",
198 )
199 parser.add_argument(
200 "--num_users",
201 "-u",
202 type=int,
203 default=50,
204 help="The number of users to create",
205 )
206 parser.add_argument(
207 "--num_events",
208 "-e",
209 type=int,
210 default=math.inf,
211 help="The number of events to create.",
212 )
213 parser.add_argument(
214 "--max_lag_seconds",
215 "-l",
216 type=int,
217 default=0,
218 help="The maximum seconds that a record can be lagged.",
219 )
220 parser.add_argument(
221 "--delay_seconds",
222 "-d",
223 type=float,
224 default=None,
225 help="The amount of time that a record should be delayed. Only applicable to streaming.",
226 )
227
228 args = parser.parse_args()
229 source = args.source
230 num_users = args.num_users
231 num_events = args.num_events
232 max_lag_seconds = args.max_lag_seconds
233 delay_seconds = args.delay_seconds
234
235 gen = EventGenerator(
236 source,
237 num_users,
238 num_events,
239 max_lag_seconds,
240 delay_seconds,
241 os.getenv("BOOTSTRAP_SERVERS", "localhost:29092"),
242 os.getenv("TOPIC_NAME", "website-visit"),
243 )
244 gen.generate_events()
Once we execute the script for generating batch pipeline data, we see a new file is created in the inputs folder as shown below.
1$ python datagen/generate_data.py --source batch --num_users 20 --num_events 10000 --max_lag_seconds 60
2...
3$ head -n 3 inputs/4b1dba74-d970-4c67-a631-e0d7f52ad00e.out
4{"ip": "74.236.125.208", "id": "-5227372761963790049", "lat": 26.3587, "lng": -80.0831, "user_agent": "Mozilla/5.0 (Windows; U; Windows NT 5.1) AppleWebKit/534.23.4 (KHTML, like Gecko) Version/4.0.5 Safari/534.23.4", "age_bracket": "26-40", "opted_into_marketing": true, "http_request": "GET eucharya.html HTTP/1.0", "http_response": 200, "file_size_bytes": 115, "event_datetime": "2024-03-25T04:26:55.473", "event_ts": 1711301215473}
5{"ip": "75.153.216.235", "id": "5836835583895516006", "lat": 49.2302, "lng": -122.9952, "user_agent": "Mozilla/5.0 (Android 6.0.1; Mobile; rv:11.0) Gecko/11.0 Firefox/11.0", "age_bracket": "41-55", "opted_into_marketing": true, "http_request": "GET acanthocephala.html HTTP/1.0", "http_response": 200, "file_size_bytes": 358, "event_datetime": "2024-03-25T04:27:01.930", "event_ts": 1711301221930}
6{"ip": "134.157.0.190", "id": "-5123638115214052647", "lat": 48.8534, "lng": 2.3488, "user_agent": "Mozilla/5.0 (X11; Linux i686) AppleWebKit/534.2 (KHTML, like Gecko) Chrome/23.0.825.0 Safari/534.2", "age_bracket": "55+", "opted_into_marketing": true, "http_request": "GET bacteria.html HTTP/1.0", "http_response": 200, "file_size_bytes": 402, "event_datetime": "2024-03-25T04:27:16.037", "event_ts": 1711301236037}
Basic Pipeline
Below shows a basic Beam pipeline. It (1) reads one or more files that match a file name pattern, (2) parses lines of Json string into Python dictionaries, (3) filters records where opted_into_marketing is TRUE, (4) selects a subset of attributes and finally (5) writes the updated records into a folder named outputs. It uses the Direct Runner by default, and we can also try a different runner by specifying the runner name (eg python section1/basic.py --runner FlinkRunner).
1# section1/basic.py
2import os
3import datetime
4import argparse
5import json
6import logging
7
8import apache_beam as beam
9from apache_beam.options.pipeline_options import PipelineOptions
10from apache_beam.options.pipeline_options import StandardOptions
11
12
13def run():
14 parser = argparse.ArgumentParser(description="Beam pipeline arguments")
15 parser.add_argument(
16 "--inputs",
17 default="inputs",
18 help="Specify folder name that event records are saved",
19 )
20 parser.add_argument(
21 "--runner", default="DirectRunner", help="Specify Apache Beam Runner"
22 )
23 opts = parser.parse_args()
24 PARENT_DIR = os.path.dirname(os.path.dirname(os.path.realpath(__file__)))
25
26 options = PipelineOptions()
27 options.view_as(StandardOptions).runner = opts.runner
28
29 p = beam.Pipeline(options=options)
30 (
31 p
32 | "Read from files"
33 >> beam.io.ReadFromText(
34 file_pattern=os.path.join(PARENT_DIR, opts.inputs, "*.out")
35 )
36 | "Parse Json" >> beam.Map(lambda line: json.loads(line))
37 | "Filter status" >> beam.Filter(lambda d: d["opted_into_marketing"] is True)
38 | "Select columns"
39 >> beam.Map(
40 lambda d: {
41 k: v
42 for k, v in d.items()
43 if k in ["ip", "id", "lat", "lng", "age_bracket"]
44 }
45 )
46 | "Write to file"
47 >> beam.io.WriteToText(
48 file_path_prefix=os.path.join(
49 PARENT_DIR,
50 "outputs",
51 f"{int(datetime.datetime.now().timestamp() * 1000)}",
52 ),
53 file_name_suffix=".out",
54 )
55 )
56
57 logging.getLogger().setLevel(logging.INFO)
58 logging.info("Building pipeline ...")
59
60 p.run().wait_until_finish()
61
62
63if __name__ == "__main__":
64 run()
Once executed, we can check the output records in the outputs folder.
1$ python section1/basic.py
2INFO:root:Building pipeline ...
3INFO:apache_beam.runners.portability.fn_api_runner.translations:==================== <function annotate_downstream_side_inputs at 0x7f1d24906050> ====================
4INFO:apache_beam.runners.portability.fn_api_runner.translations:==================== <function fix_side_input_pcoll_coders at 0x7f1d24906170> ====================
5INFO:apache_beam.runners.portability.fn_api_runner.translations:==================== <function pack_combiners at 0x7f1d24906680> ====================
6INFO:apache_beam.runners.portability.fn_api_runner.translations:==================== <function lift_combiners at 0x7f1d24906710> ====================
7INFO:apache_beam.runners.portability.fn_api_runner.translations:==================== <function expand_sdf at 0x7f1d249068c0> ====================
8INFO:apache_beam.runners.portability.fn_api_runner.translations:==================== <function expand_gbk at 0x7f1d24906950> ====================
9INFO:apache_beam.runners.portability.fn_api_runner.translations:==================== <function sink_flattens at 0x7f1d24906a70> ====================
10INFO:apache_beam.runners.portability.fn_api_runner.translations:==================== <function greedily_fuse at 0x7f1d24906b00> ====================
11INFO:apache_beam.runners.portability.fn_api_runner.translations:==================== <function read_to_impulse at 0x7f1d24906b90> ====================
12INFO:apache_beam.runners.portability.fn_api_runner.translations:==================== <function impulse_to_input at 0x7f1d24906c20> ====================
13INFO:apache_beam.runners.portability.fn_api_runner.translations:==================== <function sort_stages at 0x7f1d24906e60> ====================
14INFO:apache_beam.runners.portability.fn_api_runner.translations:==================== <function add_impulse_to_dangling_transforms at 0x7f1d24906f80> ====================
15INFO:apache_beam.runners.portability.fn_api_runner.translations:==================== <function setup_timer_mapping at 0x7f1d24906dd0> ====================
16INFO:apache_beam.runners.portability.fn_api_runner.translations:==================== <function populate_data_channel_coders at 0x7f1d24906ef0> ====================
17INFO:apache_beam.runners.worker.statecache:Creating state cache with size 104857600
18INFO:apache_beam.runners.portability.fn_api_runner.worker_handlers:Created Worker handler <apache_beam.runners.portability.fn_api_runner.worker_handlers.EmbeddedWorkerHandler object at 0x7f1d2c548550> for environment ref_Environment_default_environment_1 (beam:env:embedded_python:v1, b'')
19INFO:apache_beam.io.filebasedsink:Starting finalize_write threads with num_shards: 1 (skipped: 0), batches: 1, num_threads: 1
20INFO:apache_beam.io.filebasedsink:Renamed 1 shards in 0.01 seconds.
1$ head -n 3 outputs/1711341025220-00000-of-00001.out
2{'ip': '74.236.125.208', 'id': '-5227372761963790049', 'lat': 26.3587, 'lng': -80.0831, 'age_bracket': '26-40'}
3{'ip': '75.153.216.235', 'id': '5836835583895516006', 'lat': 49.2302, 'lng': -122.9952, 'age_bracket': '41-55'}
4{'ip': '134.157.0.190', 'id': '-5123638115214052647', 'lat': 48.8534, 'lng': 2.3488, 'age_bracket': '55+'}
Interactive Beam
Interactive Beam is aimed at integrating Apache Beam with Jupyter notebook to make pipeline prototyping and data exploration much faster and easier. It provides nice features such as graphical representation of pipeline DAGs and PCollection elements, fetching PCollections as pandas DataFrame and faster execution/re-execution of pipelines.
We can start a Jupyter server while enabling Jupyter Lab and ignoring authentication as shown below. Once started, it can be accessed on http://localhost:8888.
1$ JUPYTER_ENABLE_LAB=yes jupyter lab --ServerApp.token='' --ServerApp.password=''
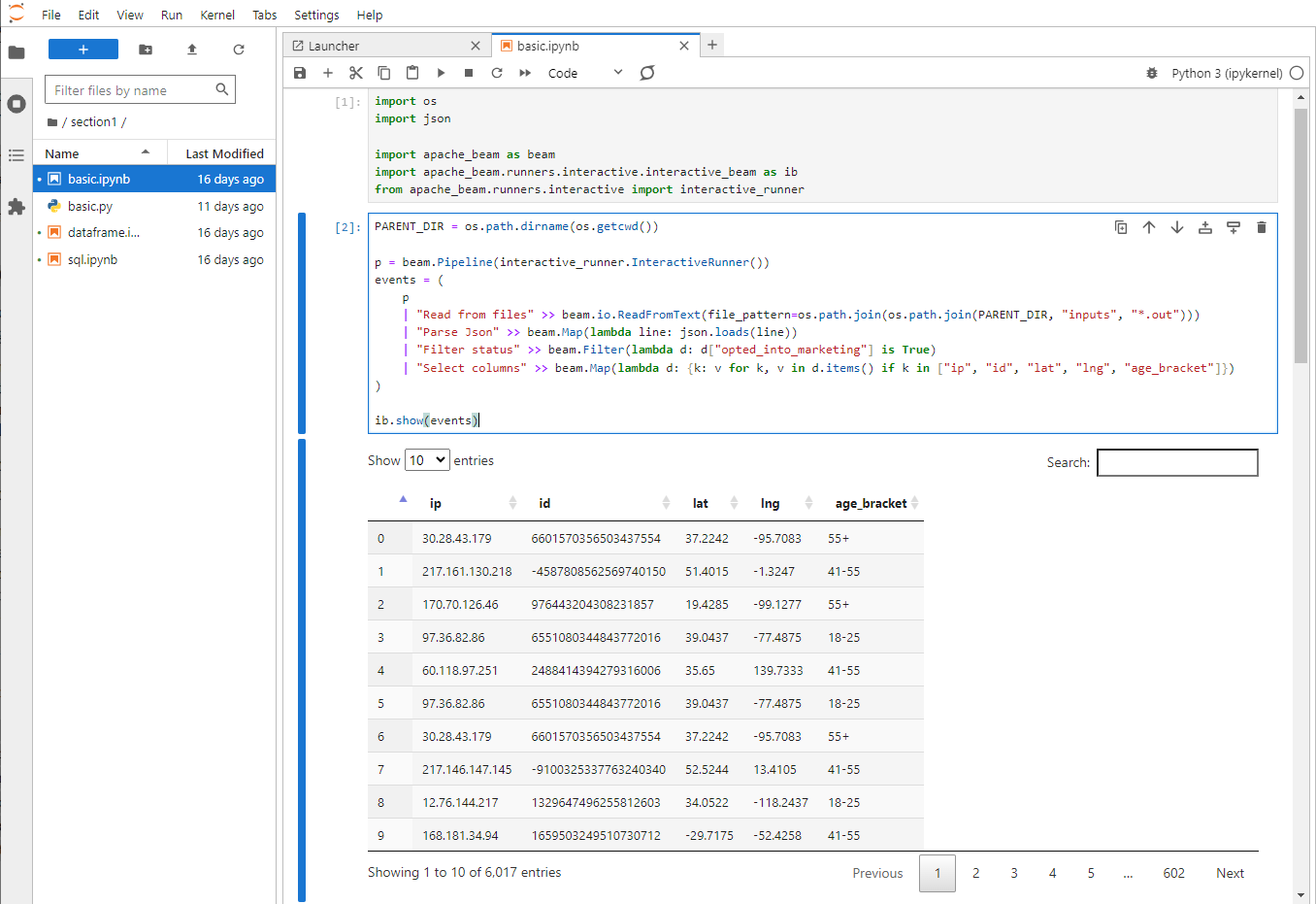
The basic pipeline is recreated in section1/basic.ipynb. The InteractiveRunner is used for the pipeline and, by default, the Python Direct Runner is taken as the underlying runner. When we run the first two cells, we can show the output records in a data table.
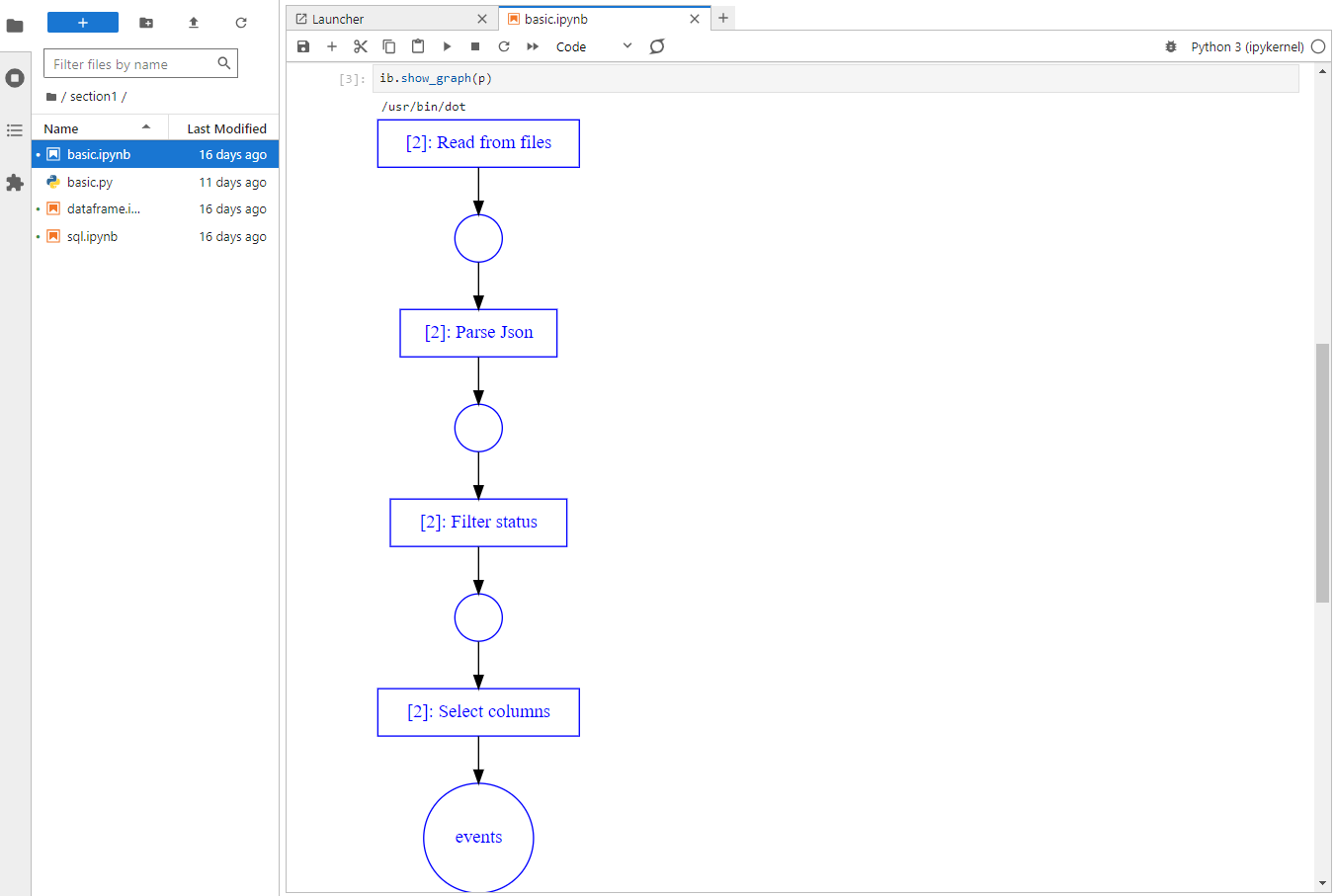
The pipeline DAG can be visualized using the show_graph method as shown below. It helps identify or share how a pipeline is executed more effectively.
Beam SQL
Beam SQL allows a Beam user (currently only available in Beam Java and Python) to query bounded and unbounded PCollections with SQL statements. An SQL query is translated to a PTransform, and it can be particularly useful for joining multiple PCollections.
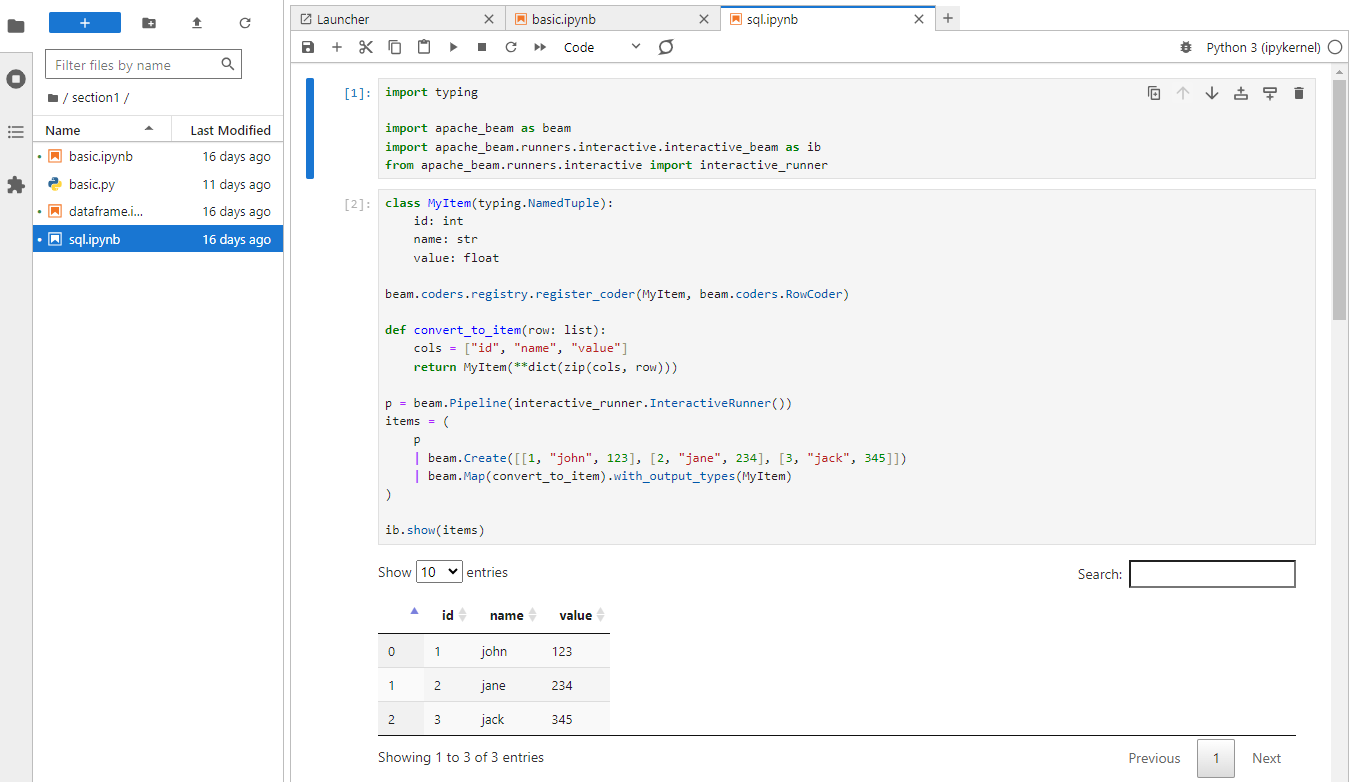
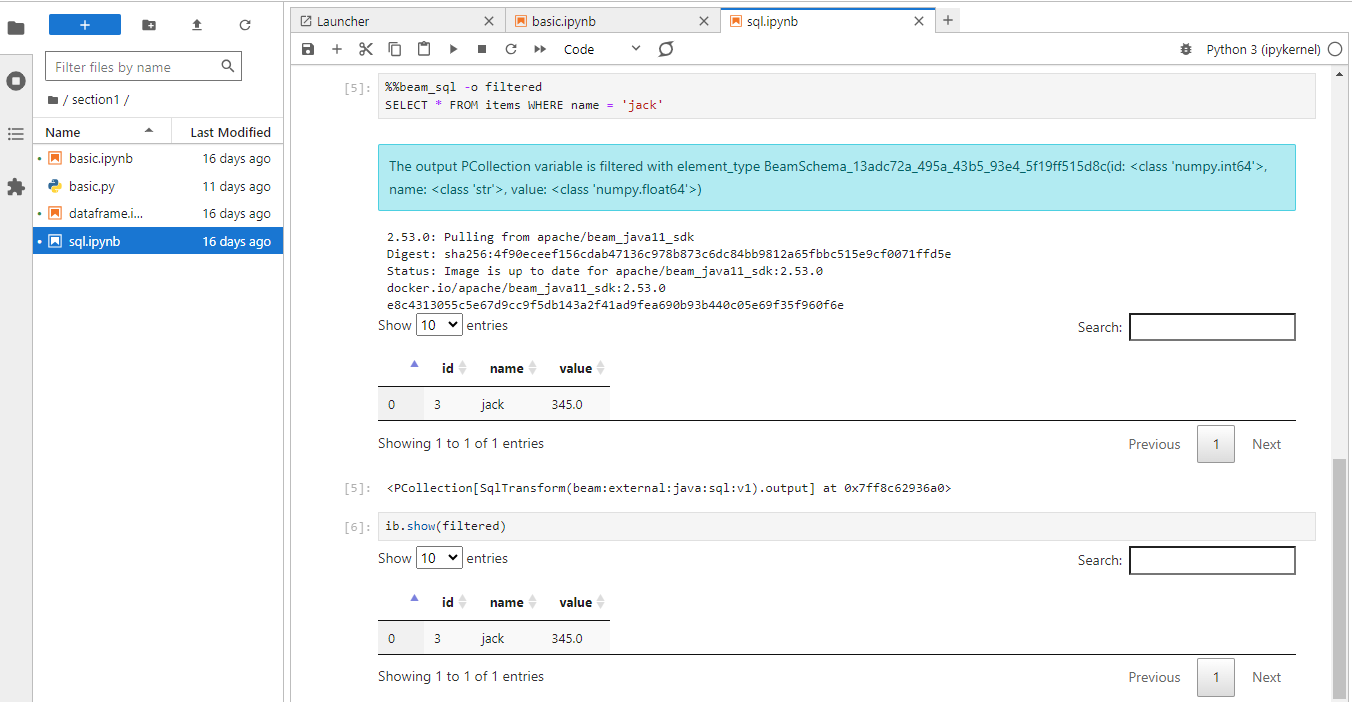
In section1/sql.ipynb, we first create a PCollection of 3 elements that can be used as source data.
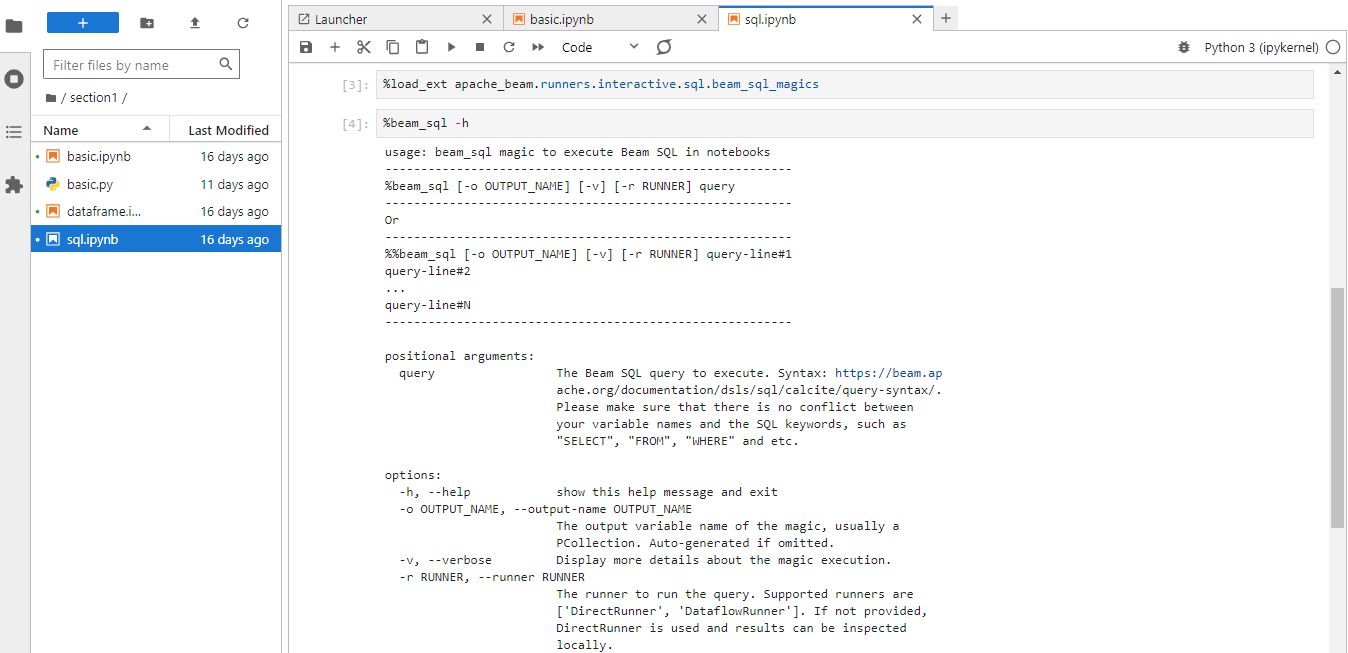
Beam SQL is executed as an IPython extension, and it should be loaded before being used. The magic function requires query, and we can optionally specify the output name (OUTPUT_NAME) and runner (RUNNER).
After the extension is loaded, we execute a SQL query, optionally specifying the output PCollection name (filtered). We can use the existing PCollection named items as the source.
There are several notes about Beam SQL on a notebook.
- The SQL query is executed in a separate Docker container and data is processed via the Java SDK.
- Currently it only supports the Direct Runner and Dataflow Runner.
- The output PCollection is accessible in the entire notebook, and we can use it in another cell.
- While Beam SQL supports both Calcite SQL and ZetaSQL, the magic function doesn’t allow us to select which dialect to choose. Only the default Calcite SQL will be used on a notebook.
Beam DataFrames
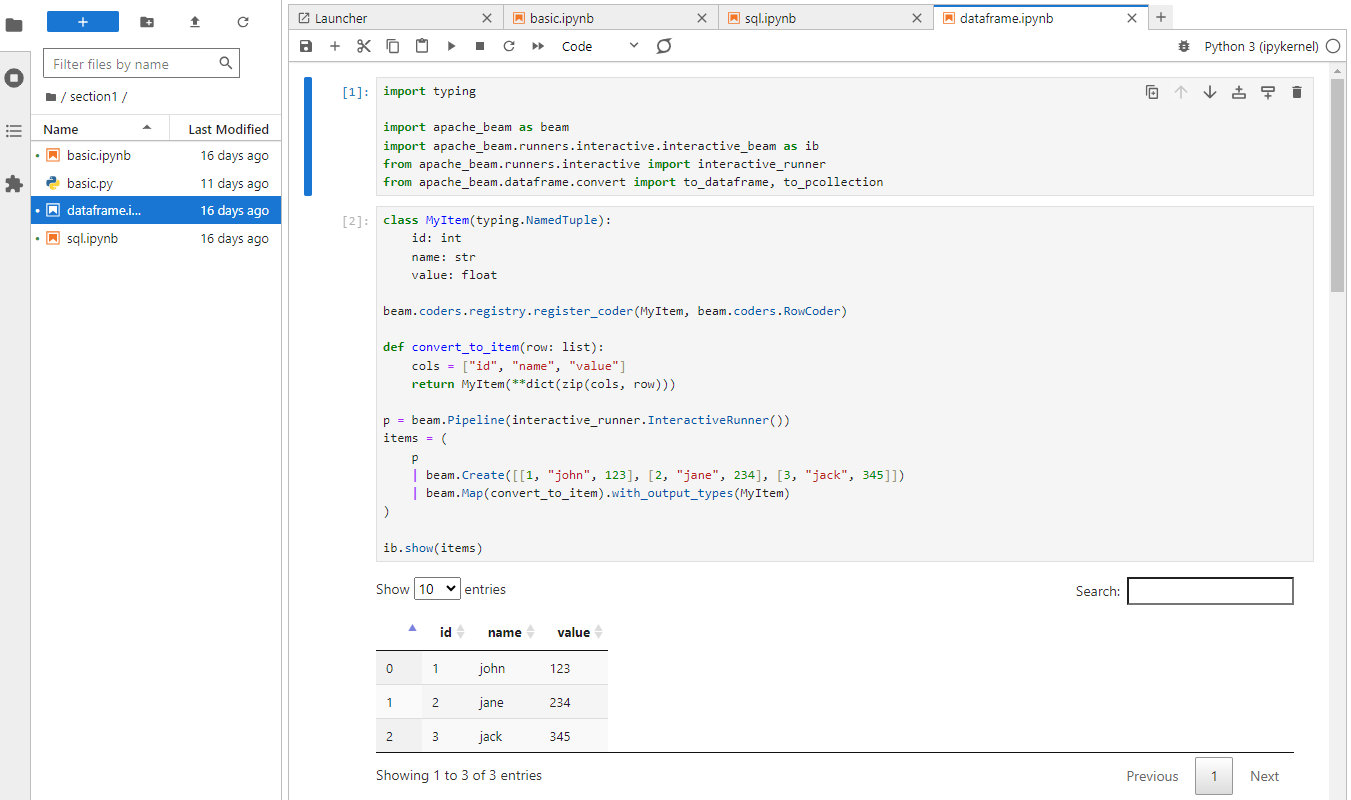
The Apache Beam Python SDK provides a DataFrame API for working with pandas-like DataFrame objects. This feature lets you convert a PCollection to a DataFrame and then interact with the DataFrame using the standard methods available on the pandas DataFrame API.
In section1/dataframe.ipynb, we also create a PCollection of 3 elements as the Beam SQL example.
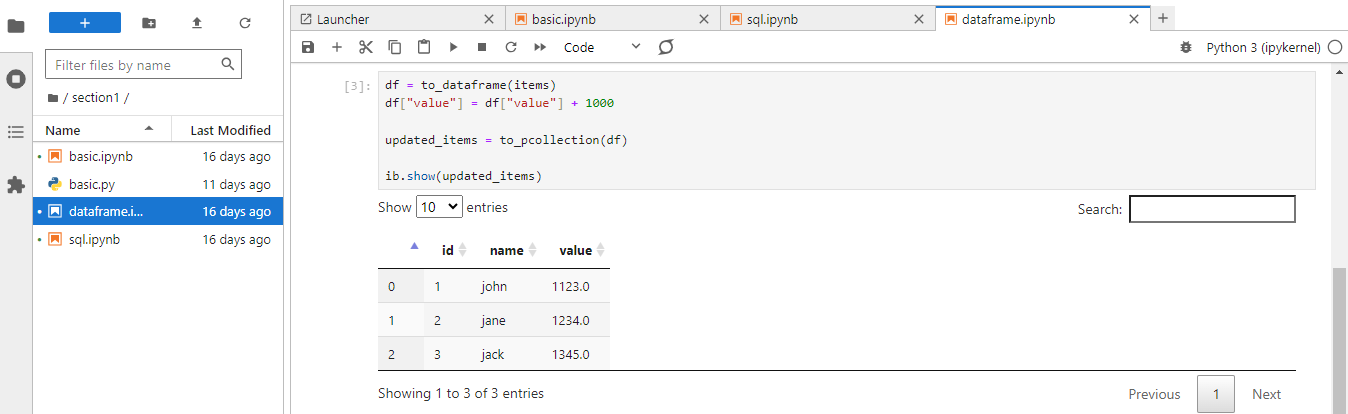
Subsequently we convert the source PCollection into a pandas DataFrame using the to_dataframe method, process data via pandas API and return to PCollection using the to_pcollection method.
Summary
Apache Beam and Apache Flink are open-source frameworks for parallel, distributed data processing at scale. While PyFlink, Flink’s Python API, is limited to build sophisticated data streaming applications, Apache Beam’s Python SDK has potential as it supports more capacity to extend and/or customise its features. In this series of posts, we discuss local development of Apache Beam pipelines using Python. In Part 1, a basic Beam pipeline was introduced, followed by demonstrating how to utilise Jupyter notebooks for interactive development. We also covered Beam SQL and Beam DataFrames examples on notebooks.










Comments