
In this series, we discuss local development of Apache Beam pipelines using Python. A basic Beam pipeline was introduced in Part 1, followed by demonstrating how to utilise Jupyter notebooks, Beam SQL and Beam DataFrames. In this post, we discuss Batch pipelines that aggregate website visit log by user and time. The pipelines are developed with and without Beam SQL. Additionally, each pipeline is implemented on a Jupyter notebook for demonstration.
- Part 1 Pipeline, Notebook, SQL and DataFrame
- Part 2 Batch Pipelines (this post)
- Part 3 Flink Runner
- Part 4 Streaming Pipelines
- Part 5 Testing Pipelines
Data Generation
We first need to generate website visit log data. As the second pipeline aggregates data by time, the max lag seconds (--max_lag_seconds) is set to 300 so that records are spread over 5 minutes period. See Part 1 for details about the data generation script and the source of this post can be found in the GitHub repository.
1$ python datagen/generate_data.py --source batch --num_users 20 --num_events 10000 --max_lag_seconds 300
2...
3$ head -n 3 inputs/d919cc9e-dade-44be-872e-86598a4d0e47.out
4{"ip": "81.112.193.168", "id": "-7450326752843155888", "lat": 41.8919, "lng": 12.5113, "user_agent": "Opera/8.29.(Windows CE; hi-IN) Presto/2.9.160 Version/10.00", "age_bracket": "18-25", "opted_into_marketing": false, "http_request": "GET eucharya.html HTTP/1.0", "http_response": 200, "file_size_bytes": 131, "event_datetime": "2024-04-02T04:30:18.999", "event_ts": 1711992618999}
5{"ip": "204.14.50.181", "id": "3385356383147784679", "lat": 47.7918, "lng": -122.2243, "user_agent": "Opera/9.77.(Windows NT 5.01; ber-DZ) Presto/2.9.166 Version/12.00", "age_bracket": "55+", "opted_into_marketing": true, "http_request": "GET coniferophyta.html HTTP/1.0", "http_response": 200, "file_size_bytes": 229, "event_datetime": "2024-04-02T04:28:13.144", "event_ts": 1711992493144}
6{"ip": "11.32.249.163", "id": "8764514706569354597", "lat": 37.2242, "lng": -95.7083, "user_agent": "Opera/8.45.(Windows NT 4.0; xh-ZA) Presto/2.9.177 Version/10.00", "age_bracket": "26-40", "opted_into_marketing": false, "http_request": "GET protozoa.html HTTP/1.0", "http_response": 200, "file_size_bytes": 373, "event_datetime": "2024-04-02T04:30:12.612", "event_ts": 1711992612612}
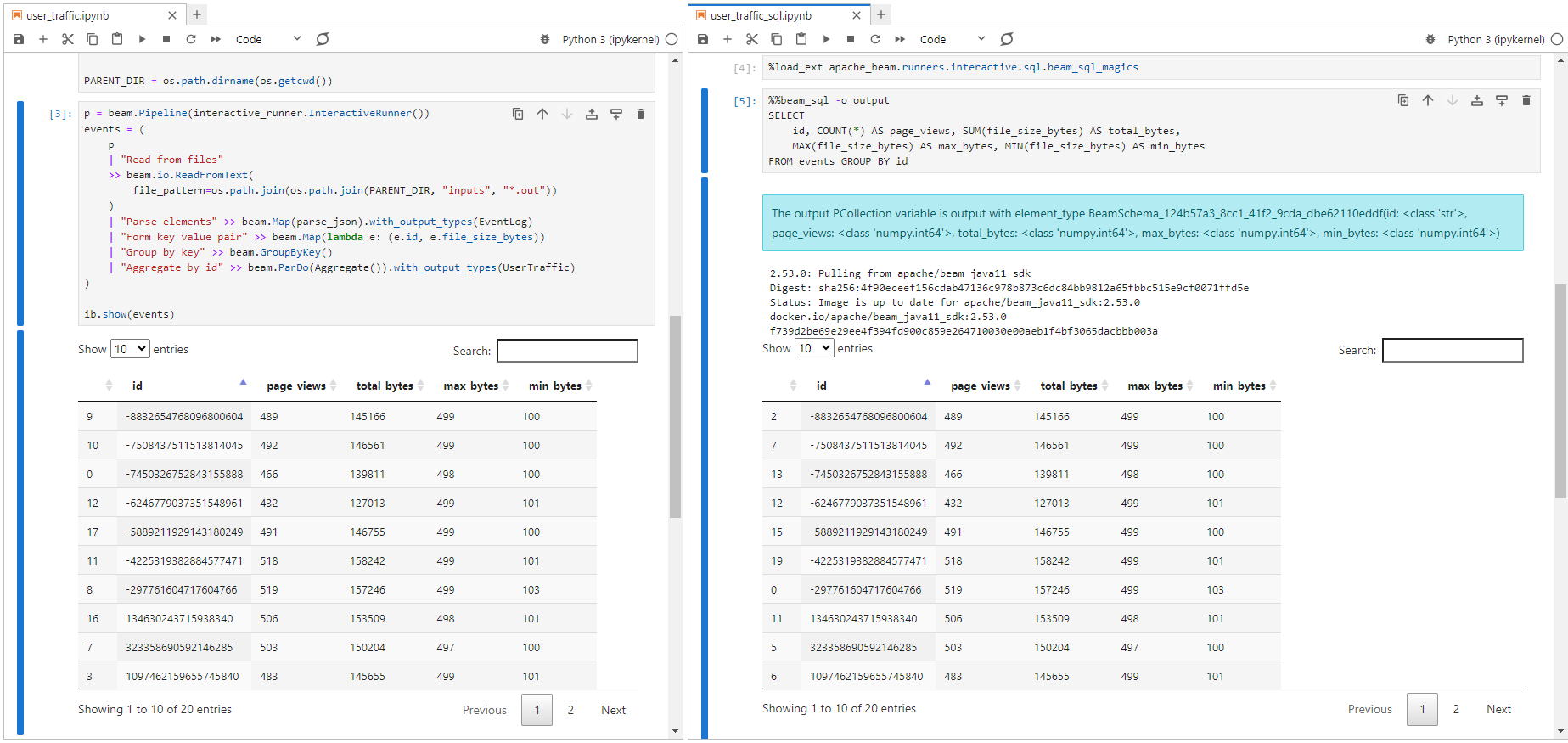
User Traffic
This pipeline basically calculates the number of website visits and distribution of traffic consumption by user.
Beam Pipeline
The pipeline begins with reading data from a folder named inputs and parses the Json lines. Then it creates a key-value pair where the key is the user ID (id) and the value is the file size bytes (file_size_bytes). After that, the records are grouped by the key and aggregated to obtain website visit count and traffic consumption distribution using a ParDo transform. Finally, the output records are written to a folder named outputs after being converted into dictionary.
Note that custom types are created for the input and output elements using element schema (EventLog and UserTraffic), and transformations become more expressive using them. Also, the custom types are registered to the coder registry so that they are encoded/decoded appropriately - see the transformations that specify the output types via with_output_types.
[Update 2024-04-30] Note the coders for the custom types are registered, but it is not required because we don’t have a cross-language transformation that deals with them.
1# section2/user_traffic.py
2import os
3import datetime
4import argparse
5import json
6import logging
7import typing
8
9import apache_beam as beam
10from apache_beam.options.pipeline_options import PipelineOptions
11from apache_beam.options.pipeline_options import StandardOptions
12
13
14class EventLog(typing.NamedTuple):
15 ip: str
16 id: str
17 lat: float
18 lng: float
19 user_agent: str
20 age_bracket: str
21 opted_into_marketing: bool
22 http_request: str
23 http_response: int
24 file_size_bytes: int
25 event_datetime: str
26 event_ts: int
27
28
29class UserTraffic(typing.NamedTuple):
30 id: str
31 page_views: int
32 total_bytes: int
33 max_bytes: int
34 min_bytes: int
35
36
37beam.coders.registry.register_coder(EventLog, beam.coders.RowCoder)
38beam.coders.registry.register_coder(UserTraffic, beam.coders.RowCoder)
39
40
41def parse_json(element: str):
42 row = json.loads(element)
43 # lat/lng sometimes empty string
44 if not row["lat"] or not row["lng"]:
45 row = {**row, **{"lat": -1, "lng": -1}}
46 return EventLog(**row)
47
48
49class Aggregate(beam.DoFn):
50 def process(self, element: typing.Tuple[str, typing.Iterable[int]]):
51 key, values = element
52 yield UserTraffic(
53 id=key,
54 page_views=len(values),
55 total_bytes=sum(values),
56 max_bytes=max(values),
57 min_bytes=min(values),
58 )
59
60
61def run():
62 parser = argparse.ArgumentParser(description="Beam pipeline arguments")
63 parser.add_argument(
64 "--inputs",
65 default="inputs",
66 help="Specify folder name that event records are saved",
67 )
68 parser.add_argument(
69 "--runner", default="DirectRunner", help="Specify Apache Beam Runner"
70 )
71 opts = parser.parse_args()
72 PARENT_DIR = os.path.dirname(os.path.dirname(os.path.realpath(__file__)))
73
74 options = PipelineOptions()
75 options.view_as(StandardOptions).runner = opts.runner
76
77 p = beam.Pipeline(options=options)
78 (
79 p
80 | "Read from files"
81 >> beam.io.ReadFromText(
82 file_pattern=os.path.join(PARENT_DIR, opts.inputs, "*.out")
83 )
84 | "Parse elements" >> beam.Map(parse_json).with_output_types(EventLog)
85 | "Form key value pair" >> beam.Map(lambda e: (e.id, e.file_size_bytes))
86 | "Group by key" >> beam.GroupByKey()
87 | "Aggregate by id" >> beam.ParDo(Aggregate()).with_output_types(UserTraffic)
88 | "To dict" >> beam.Map(lambda e: e._asdict())
89 | "Write to file"
90 >> beam.io.WriteToText(
91 file_path_prefix=os.path.join(
92 PARENT_DIR,
93 "outputs",
94 f"{int(datetime.datetime.now().timestamp() * 1000)}",
95 ),
96 file_name_suffix=".out",
97 )
98 )
99
100 logging.getLogger().setLevel(logging.INFO)
101 logging.info("Building pipeline ...")
102
103 p.run().wait_until_finish()
104
105
106if __name__ == "__main__":
107 run()
Once we execute the pipeline, we can check the output records by reading the output file. By default, the pipeline runs via the Direct Runner.
1$ python section2/user_traffic.py
2...
3$ cat outputs/1712032400886-00000-of-00001.out
4{'id': '-7450326752843155888', 'page_views': 466, 'total_bytes': 139811, 'max_bytes': 498, 'min_bytes': 100}
5{'id': '3385356383147784679', 'page_views': 471, 'total_bytes': 142846, 'max_bytes': 499, 'min_bytes': 103}
6{'id': '8764514706569354597', 'page_views': 498, 'total_bytes': 152005, 'max_bytes': 499, 'min_bytes': 101}
7{'id': '1097462159655745840', 'page_views': 483, 'total_bytes': 145655, 'max_bytes': 499, 'min_bytes': 101}
8{'id': '5107076440238203196', 'page_views': 520, 'total_bytes': 155475, 'max_bytes': 499, 'min_bytes': 100}
9{'id': '3817299155409964875', 'page_views': 515, 'total_bytes': 155516, 'max_bytes': 498, 'min_bytes': 100}
10{'id': '4396740364429657096', 'page_views': 534, 'total_bytes': 159351, 'max_bytes': 499, 'min_bytes': 101}
11{'id': '323358690592146285', 'page_views': 503, 'total_bytes': 150204, 'max_bytes': 497, 'min_bytes': 100}
12{'id': '-297761604717604766', 'page_views': 519, 'total_bytes': 157246, 'max_bytes': 499, 'min_bytes': 103}
13{'id': '-8832654768096800604', 'page_views': 489, 'total_bytes': 145166, 'max_bytes': 499, 'min_bytes': 100}
14{'id': '-7508437511513814045', 'page_views': 492, 'total_bytes': 146561, 'max_bytes': 499, 'min_bytes': 100}
15{'id': '-4225319382884577471', 'page_views': 518, 'total_bytes': 158242, 'max_bytes': 499, 'min_bytes': 101}
16{'id': '-6246779037351548961', 'page_views': 432, 'total_bytes': 127013, 'max_bytes': 499, 'min_bytes': 101}
17{'id': '7514213899672341122', 'page_views': 515, 'total_bytes': 154753, 'max_bytes': 498, 'min_bytes': 100}
18{'id': '8063196327933870504', 'page_views': 526, 'total_bytes': 159395, 'max_bytes': 499, 'min_bytes': 101}
19{'id': '4927182384805166657', 'page_views': 501, 'total_bytes': 151023, 'max_bytes': 498, 'min_bytes': 100}
20{'id': '134630243715938340', 'page_views': 506, 'total_bytes': 153509, 'max_bytes': 498, 'min_bytes': 101}
21{'id': '-5889211929143180249', 'page_views': 491, 'total_bytes': 146755, 'max_bytes': 499, 'min_bytes': 100}
22{'id': '3809491485105813594', 'page_views': 518, 'total_bytes': 155992, 'max_bytes': 499, 'min_bytes': 100}
23{'id': '4086706052291208999', 'page_views': 503, 'total_bytes': 154038, 'max_bytes': 499, 'min_bytes': 100}
We can run the pipeline using a different runner e.g. by specifying the Flink Runner in the runner argument. Interestingly it completes the pipeline by multiple tasks.
1$ python section2/user_traffic.py --runner FlinkRunner
2...
3$ ls outputs/ | grep 1712032503940
41712032503940-00000-of-00005.out
51712032503940-00003-of-00005.out
61712032503940-00002-of-00005.out
71712032503940-00004-of-00005.out
81712032503940-00001-of-00005.out
Beam SQL
The pipeline that calculates user statistic can also be developed using SqlTransform, which translates a SQL query into PTransforms. The following pipeline creates the same output to the previous pipeline.
1# section2/user_traffic_sql.py
2import os
3import datetime
4import argparse
5import json
6import logging
7import typing
8
9import apache_beam as beam
10from apache_beam.transforms.sql import SqlTransform
11from apache_beam.options.pipeline_options import PipelineOptions
12from apache_beam.options.pipeline_options import StandardOptions
13
14
15class EventLog(typing.NamedTuple):
16 ip: str
17 id: str
18 lat: float
19 lng: float
20 user_agent: str
21 age_bracket: str
22 opted_into_marketing: bool
23 http_request: str
24 http_response: int
25 file_size_bytes: int
26 event_datetime: str
27 event_ts: int
28
29
30beam.coders.registry.register_coder(EventLog, beam.coders.RowCoder)
31
32
33def parse_json(element: str):
34 row = json.loads(element)
35 # lat/lng sometimes empty string
36 if not row["lat"] or not row["lng"]:
37 row = {**row, **{"lat": -1, "lng": -1}}
38 return EventLog(**row)
39
40
41def run():
42 parser = argparse.ArgumentParser(description="Beam pipeline arguments")
43 parser.add_argument(
44 "--inputs",
45 default="inputs",
46 help="Specify folder name that event records are saved",
47 )
48 parser.add_argument(
49 "--runner", default="DirectRunner", help="Specify Apache Beam Runner"
50 )
51 opts = parser.parse_args()
52 PARENT_DIR = os.path.dirname(os.path.dirname(os.path.realpath(__file__)))
53
54 options = PipelineOptions()
55 options.view_as(StandardOptions).runner = opts.runner
56
57 query = """
58 SELECT
59 id,
60 COUNT(*) AS page_views,
61 SUM(file_size_bytes) AS total_bytes,
62 MAX(file_size_bytes) AS max_bytes,
63 MIN(file_size_bytes) AS min_bytes
64 FROM PCOLLECTION
65 GROUP BY id
66 """
67
68 p = beam.Pipeline(options=options)
69 (
70 p
71 | "Read from files"
72 >> beam.io.ReadFromText(
73 file_pattern=os.path.join(PARENT_DIR, opts.inputs, "*.out")
74 )
75 | "Parse elements" >> beam.Map(parse_json).with_output_types(EventLog)
76 | "Aggregate by user" >> SqlTransform(query)
77 | "To Dict" >> beam.Map(lambda e: e._asdict())
78 | "Write to file"
79 >> beam.io.WriteToText(
80 file_path_prefix=os.path.join(
81 PARENT_DIR,
82 "outputs",
83 f"{int(datetime.datetime.now().timestamp() * 1000)}",
84 ),
85 file_name_suffix=".out",
86 )
87 )
88
89 logging.getLogger().setLevel(logging.INFO)
90 logging.info("Building pipeline ...")
91
92 p.run().wait_until_finish()
93
94
95if __name__ == "__main__":
96 run()
When we execute the pipeline script, we see that a Docker container is launched and actual transformations are performed within it via the Java SDK. The container exits when the pipeline completes.
1$ python section2/user_traffic_sql.py
2...
3
4$ docker ps -a --format "table {{.ID}}\t{{.Image}}\t{{.Status}}"
5CONTAINER ID IMAGE STATUS
6c7d7bad6b1e9 apache/beam_java11_sdk:2.53.0 Exited (137) 5 minutes ago
7
8$ cat outputs/1712032675637-00000-of-00001.out
9{'id': '-297761604717604766', 'page_views': 519, 'total_bytes': 157246, 'max_bytes': 499, 'min_bytes': 103}
10{'id': '3817299155409964875', 'page_views': 515, 'total_bytes': 155516, 'max_bytes': 498, 'min_bytes': 100}
11{'id': '-8832654768096800604', 'page_views': 489, 'total_bytes': 145166, 'max_bytes': 499, 'min_bytes': 100}
12{'id': '4086706052291208999', 'page_views': 503, 'total_bytes': 154038, 'max_bytes': 499, 'min_bytes': 100}
13{'id': '3809491485105813594', 'page_views': 518, 'total_bytes': 155992, 'max_bytes': 499, 'min_bytes': 100}
14{'id': '323358690592146285', 'page_views': 503, 'total_bytes': 150204, 'max_bytes': 497, 'min_bytes': 100}
15{'id': '1097462159655745840', 'page_views': 483, 'total_bytes': 145655, 'max_bytes': 499, 'min_bytes': 101}
16{'id': '-7508437511513814045', 'page_views': 492, 'total_bytes': 146561, 'max_bytes': 499, 'min_bytes': 100}
17{'id': '7514213899672341122', 'page_views': 515, 'total_bytes': 154753, 'max_bytes': 498, 'min_bytes': 100}
18{'id': '8764514706569354597', 'page_views': 498, 'total_bytes': 152005, 'max_bytes': 499, 'min_bytes': 101}
19{'id': '5107076440238203196', 'page_views': 520, 'total_bytes': 155475, 'max_bytes': 499, 'min_bytes': 100}
20{'id': '134630243715938340', 'page_views': 506, 'total_bytes': 153509, 'max_bytes': 498, 'min_bytes': 101}
21{'id': '-6246779037351548961', 'page_views': 432, 'total_bytes': 127013, 'max_bytes': 499, 'min_bytes': 101}
22{'id': '-7450326752843155888', 'page_views': 466, 'total_bytes': 139811, 'max_bytes': 498, 'min_bytes': 100}
23{'id': '4927182384805166657', 'page_views': 501, 'total_bytes': 151023, 'max_bytes': 498, 'min_bytes': 100}
24{'id': '-5889211929143180249', 'page_views': 491, 'total_bytes': 146755, 'max_bytes': 499, 'min_bytes': 100}
25{'id': '8063196327933870504', 'page_views': 526, 'total_bytes': 159395, 'max_bytes': 499, 'min_bytes': 101}
26{'id': '3385356383147784679', 'page_views': 471, 'total_bytes': 142846, 'max_bytes': 499, 'min_bytes': 103}
27{'id': '4396740364429657096', 'page_views': 534, 'total_bytes': 159351, 'max_bytes': 499, 'min_bytes': 101}
28{'id': '-4225319382884577471', 'page_views': 518, 'total_bytes': 158242, 'max_bytes': 499, 'min_bytes': 101}
When we develop a pipeline, Interactive Beam on a Jupyter notebook can be convenient. The user traffic pipelines are implemented using notebooks, and they can be found in section2/user_traffic.ipynb and section2/user_traffic_sql.ipynb respectively. We can start a Jupyter server while enabling Jupyter Lab and ignoring authentication as shown below. Once started, it can be accessed on http://localhost:8888.
1$ JUPYTER_ENABLE_LAB=yes jupyter lab --ServerApp.token='' --ServerApp.password=''
Minute Traffic
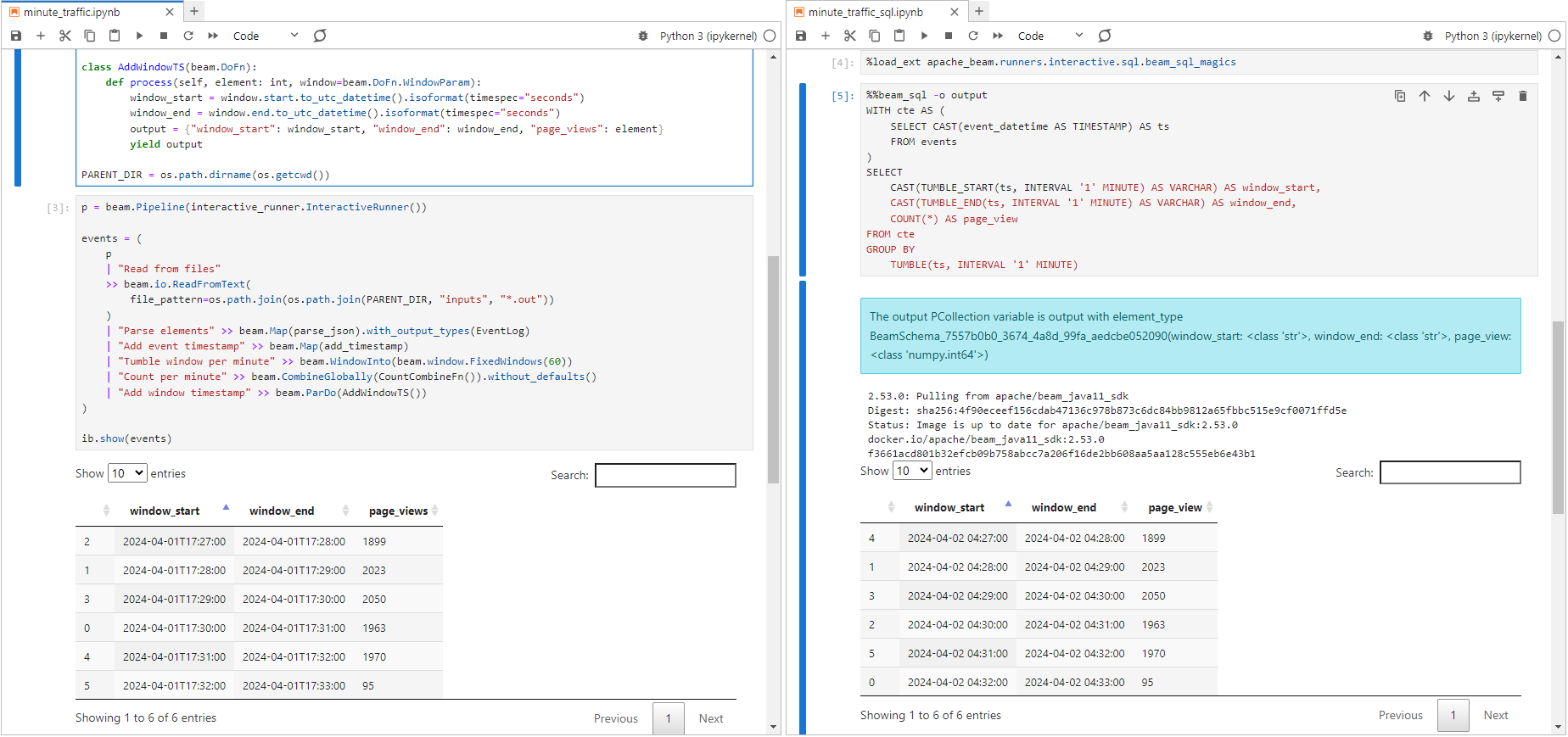
This pipeline aggregates the number of website visits in fixed time windows over 60 seconds.
Beam Pipeline
As the user traffic pipeline, it begins with reading data from a folder named inputs and parses the Json lines. Then it adds timestamp to elements by parsing the event_datetime attribute, defines fixed time windows over 60 seconds, and counts the number of records within the windows. Finally, it writes the aggregated records into a folder named outputs after adding window_start and window_end timestamp attributes.
[Update 2024-04-30] Note the coder for the custom type is registered, but it is not required because we don’t have a cross-language transformation that deals with it.
1# section2/minute_traffic.py
2import os
3import datetime
4import argparse
5import json
6import logging
7import typing
8
9import apache_beam as beam
10from apache_beam.transforms.combiners import CountCombineFn
11from apache_beam.options.pipeline_options import PipelineOptions
12from apache_beam.options.pipeline_options import StandardOptions
13
14
15class EventLog(typing.NamedTuple):
16 ip: str
17 id: str
18 lat: float
19 lng: float
20 user_agent: str
21 age_bracket: str
22 opted_into_marketing: bool
23 http_request: str
24 http_response: int
25 file_size_bytes: int
26 event_datetime: str
27 event_ts: int
28
29
30beam.coders.registry.register_coder(EventLog, beam.coders.RowCoder)
31
32
33def parse_json(element: str):
34 row = json.loads(element)
35 # lat/lng sometimes empty string
36 if not row["lat"] or not row["lng"]:
37 row = {**row, **{"lat": -1, "lng": -1}}
38 return EventLog(**row)
39
40
41def add_timestamp(element: EventLog):
42 ts = datetime.datetime.strptime(
43 element.event_datetime, "%Y-%m-%dT%H:%M:%S.%f"
44 ).timestamp()
45 return beam.window.TimestampedValue(element, ts)
46
47
48class AddWindowTS(beam.DoFn):
49 def process(self, element: int, window=beam.DoFn.WindowParam):
50 window_start = window.start.to_utc_datetime().isoformat(timespec="seconds")
51 window_end = window.end.to_utc_datetime().isoformat(timespec="seconds")
52 output = {
53 "window_start": window_start,
54 "window_end": window_end,
55 "page_views": element,
56 }
57 yield output
58
59
60def run():
61 parser = argparse.ArgumentParser(description="Beam pipeline arguments")
62 parser.add_argument(
63 "--inputs",
64 default="inputs",
65 help="Specify folder name that event records are saved",
66 )
67 parser.add_argument(
68 "--runner", default="DirectRunner", help="Specify Apache Beam Runner"
69 )
70 opts = parser.parse_args()
71 PARENT_DIR = os.path.dirname(os.path.dirname(os.path.realpath(__file__)))
72
73 options = PipelineOptions()
74 options.view_as(StandardOptions).runner = opts.runner
75
76 p = beam.Pipeline(options=options)
77 (
78 p
79 | "Read from files"
80 >> beam.io.ReadFromText(
81 file_pattern=os.path.join(os.path.join(PARENT_DIR, "inputs", "*.out"))
82 )
83 | "Parse elements" >> beam.Map(parse_json).with_output_types(EventLog)
84 | "Add event timestamp" >> beam.Map(add_timestamp)
85 | "Tumble window per minute" >> beam.WindowInto(beam.window.FixedWindows(60))
86 | "Count per minute"
87 >> beam.CombineGlobally(CountCombineFn()).without_defaults()
88 | "Add window timestamp" >> beam.ParDo(AddWindowTS())
89 | "Write to file"
90 >> beam.io.WriteToText(
91 file_path_prefix=os.path.join(
92 PARENT_DIR,
93 "outputs",
94 f"{int(datetime.datetime.now().timestamp() * 1000)}",
95 ),
96 file_name_suffix=".out",
97 )
98 )
99
100 logging.getLogger().setLevel(logging.INFO)
101 logging.info("Building pipeline ...")
102
103 p.run().wait_until_finish()
104
105
106if __name__ == "__main__":
107 run()
As mentioned earlier, we set the max lag seconds (--max_lag_seconds) to 300 so that records are spread over 5 minutes period. Therefore, we can see that website visit counts are found in multiple time windows.
1$ python section2/minute_traffic.py
2...
3$ cat outputs/1712033031226-00000-of-00001.out
4{'window_start': '2024-04-01T17:30:00', 'window_end': '2024-04-01T17:31:00', 'page_views': 1963}
5{'window_start': '2024-04-01T17:28:00', 'window_end': '2024-04-01T17:29:00', 'page_views': 2023}
6{'window_start': '2024-04-01T17:27:00', 'window_end': '2024-04-01T17:28:00', 'page_views': 1899}
7{'window_start': '2024-04-01T17:29:00', 'window_end': '2024-04-01T17:30:00', 'page_views': 2050}
8{'window_start': '2024-04-01T17:31:00', 'window_end': '2024-04-01T17:32:00', 'page_views': 1970}
9{'window_start': '2024-04-01T17:32:00', 'window_end': '2024-04-01T17:33:00', 'page_views': 95}
Beam SQL
The traffic by fixed time window can also be obtained using SqlTransform. As mentioned in Part 1, Beam SQL supports two dialects - Calcite SQL and ZetaSQL. The following pipeline creates output files using both the dialects.
1# section2/minute_traffic_sql.py
2import os
3import datetime
4import argparse
5import json
6import logging
7import typing
8
9import apache_beam as beam
10from apache_beam.transforms.sql import SqlTransform
11from apache_beam.options.pipeline_options import PipelineOptions
12from apache_beam.options.pipeline_options import StandardOptions
13
14
15class EventLog(typing.NamedTuple):
16 ip: str
17 id: str
18 lat: float
19 lng: float
20 user_agent: str
21 age_bracket: str
22 opted_into_marketing: bool
23 http_request: str
24 http_response: int
25 file_size_bytes: int
26 event_datetime: str
27 event_ts: int
28
29
30beam.coders.registry.register_coder(EventLog, beam.coders.RowCoder)
31
32
33def parse_json(element: str):
34 row = json.loads(element)
35 # lat/lng sometimes empty string
36 if not row["lat"] or not row["lng"]:
37 row = {**row, **{"lat": -1, "lng": -1}}
38 return EventLog(**row)
39
40
41def format_timestamp(element: EventLog):
42 event_ts = datetime.datetime.fromisoformat(element.event_datetime)
43 temp_dict = element._asdict()
44 temp_dict["event_datetime"] = datetime.datetime.strftime(
45 event_ts, "%Y-%m-%d %H:%M:%S"
46 )
47 return EventLog(**temp_dict)
48
49
50def run():
51 parser = argparse.ArgumentParser(description="Beam pipeline arguments")
52 parser.add_argument(
53 "--inputs",
54 default="inputs",
55 help="Specify folder name that event records are saved",
56 )
57 parser.add_argument(
58 "--runner", default="DirectRunner", help="Specify Apache Beam Runner"
59 )
60 opts = parser.parse_args()
61 PARENT_DIR = os.path.dirname(os.path.dirname(os.path.realpath(__file__)))
62
63 options = PipelineOptions()
64 options.view_as(StandardOptions).runner = opts.runner
65
66 calcite_query = """
67 WITH cte AS (
68 SELECT CAST(event_datetime AS TIMESTAMP) AS ts
69 FROM PCOLLECTION
70 )
71 SELECT
72 CAST(TUMBLE_START(ts, INTERVAL '1' MINUTE) AS VARCHAR) AS window_start,
73 CAST(TUMBLE_END(ts, INTERVAL '1' MINUTE) AS VARCHAR) AS window_end,
74 COUNT(*) AS page_view
75 FROM cte
76 GROUP BY
77 TUMBLE(ts, INTERVAL '1' MINUTE)
78 """
79
80 zeta_query = """
81 SELECT
82 STRING(window_start) AS start_time,
83 STRING(window_end) AS end_time,
84 COUNT(*) AS page_views
85 FROM
86 TUMBLE(
87 (SELECT TIMESTAMP(event_datetime) AS ts FROM PCOLLECTION),
88 DESCRIPTOR(ts),
89 'INTERVAL 1 MINUTE')
90 GROUP BY
91 window_start, window_end
92 """
93
94 p = beam.Pipeline(options=options)
95 transformed = (
96 p
97 | "Read from files"
98 >> beam.io.ReadFromText(
99 file_pattern=os.path.join(os.path.join(PARENT_DIR, "inputs", "*.out"))
100 )
101 | "Parse elements" >> beam.Map(parse_json).with_output_types(EventLog)
102 | "Format timestamp" >> beam.Map(format_timestamp).with_output_types(EventLog)
103 )
104
105 ## calcite sql output
106 (
107 transformed
108 | "Count per minute via Caltice" >> SqlTransform(calcite_query)
109 | "To Dict via Caltice" >> beam.Map(lambda e: e._asdict())
110 | "Write to file via Caltice"
111 >> beam.io.WriteToText(
112 file_path_prefix=os.path.join(
113 PARENT_DIR,
114 "outputs",
115 f"{int(datetime.datetime.now().timestamp() * 1000)}-calcite",
116 ),
117 file_name_suffix=".out",
118 )
119 )
120
121 ## zeta sql output
122 (
123 transformed
124 | "Count per minute via Zeta" >> SqlTransform(zeta_query, dialect="zetasql")
125 | "To Dict via Zeta" >> beam.Map(lambda e: e._asdict())
126 | "Write to file via Zeta"
127 >> beam.io.WriteToText(
128 file_path_prefix=os.path.join(
129 PARENT_DIR,
130 "outputs",
131 f"{int(datetime.datetime.now().timestamp() * 1000)}-zeta",
132 ),
133 file_name_suffix=".out",
134 )
135 )
136
137 logging.getLogger().setLevel(logging.INFO)
138 logging.info("Building pipeline ...")
139
140 p.run().wait_until_finish()
141
142
143if __name__ == "__main__":
144 run()
As expected, both the SQL dialects produce the same output.
1$ python section2/minute_traffic_sql.py
2...
3$ cat outputs/1712033090583-calcite-00000-of-00001.out
4{'window_start': '2024-04-02 04:32:00', 'window_end': '2024-04-02 04:33:00', 'page_view': 95}
5{'window_start': '2024-04-02 04:28:00', 'window_end': '2024-04-02 04:29:00', 'page_view': 2023}
6{'window_start': '2024-04-02 04:30:00', 'window_end': '2024-04-02 04:31:00', 'page_view': 1963}
7{'window_start': '2024-04-02 04:29:00', 'window_end': '2024-04-02 04:30:00', 'page_view': 2050}
8{'window_start': '2024-04-02 04:27:00', 'window_end': '2024-04-02 04:28:00', 'page_view': 1899}
9{'window_start': '2024-04-02 04:31:00', 'window_end': '2024-04-02 04:32:00', 'page_view': 1970}
10
11$ cat outputs/1712033101760-zeta-00000-of-00001.out
12{'start_time': '2024-04-02 04:30:00+00', 'end_time': '2024-04-02 04:31:00+00', 'page_views': 1963}
13{'start_time': '2024-04-02 04:29:00+00', 'end_time': '2024-04-02 04:30:00+00', 'page_views': 2050}
14{'start_time': '2024-04-02 04:31:00+00', 'end_time': '2024-04-02 04:32:00+00', 'page_views': 1970}
15{'start_time': '2024-04-02 04:32:00+00', 'end_time': '2024-04-02 04:33:00+00', 'page_views': 95}
16{'start_time': '2024-04-02 04:28:00+00', 'end_time': '2024-04-02 04:29:00+00', 'page_views': 2023}
17{'start_time': '2024-04-02 04:27:00+00', 'end_time': '2024-04-02 04:28:00+00', 'page_views': 1899}
Jupyter notebooks are created for the minute traffic pipelines, and they can be found in section2/minute_traffic.ipynb and section2/minute_traffic_sql.ipynb respectively.
Summary
As part of discussing local development of Apache Beam pipelines using Python, we developed Batch pipelines that aggregate website visit log by user and time in this post. The pipelines were developed with and without Beam SQL. Additionally, each pipeline was implemented on a Jupyter notebook for demonstration.










Comments