
[UPDATE 2025-10-01]
Bitnami’s public Docker images have been moved to the Bitnami Legacy repository. To ensure continued access and compatibility, please update your Docker image references accordingly.
For example:
bitnami/kafka:2.8.1→bitnamilegacy/kafka:2.8.1bitnami/zookeeper:3.7.0→bitnamilegacy/zookeeper:3.7.0bitnami/python:3.9.0→bitnamilegacy/python:3.9.0
In this series, we discuss local development of Apache Beam pipelines using Python. In the previous posts, we mainly talked about Batch pipelines with/without Beam SQL. Beam pipelines are portable between batch and streaming semantics, and we will discuss streaming pipeline development in this and the next posts. While there are multiple Beam Runners, not every Runner supports Python or some Runners have too limited features in streaming semantics - see Beam Capability Matrix for details. So far, the Apache Flink and Google Cloud Dataflow Runners are the best options, and we will use the Flink Runner in this series. This post begins with demonstrating the portability layer of Apache Beam as it helps understand (1) how a pipeline developed by the Python SDK can be executed in the Flink Runner that only understands Java JAR and (2) how multiple SDKs can be used in a single pipeline. Then we discuss how to start up/tear down local Flink and Kafka clusters using bash scripts. Finally, we end up demonstrating a simple streaming pipeline, which reads and writes website visit logs from and to Kafka topics.
- Part 1 Pipeline, Notebook, SQL and DataFrame
- Part 2 Batch Pipelines
- Part 3 Flink Runner (this post)
- Part 4 Streaming Pipelines
- Part 5 Testing Pipelines
Portability Layer
Apache Beam Pipelines are portable on several layers between (1) Beam Runners, (2) batch/streaming semantics and (3) programming languages.
The portability between programming languages are achieved by the portability layer, and it has two components - Apache Beam components and Runner components. Essentially the Beam Runners (Apache Flink, Apache Spark, Google Cloud Datafolow …) don’t have to understand a Beam SDK but are able to execute pipelines built by it regardless.
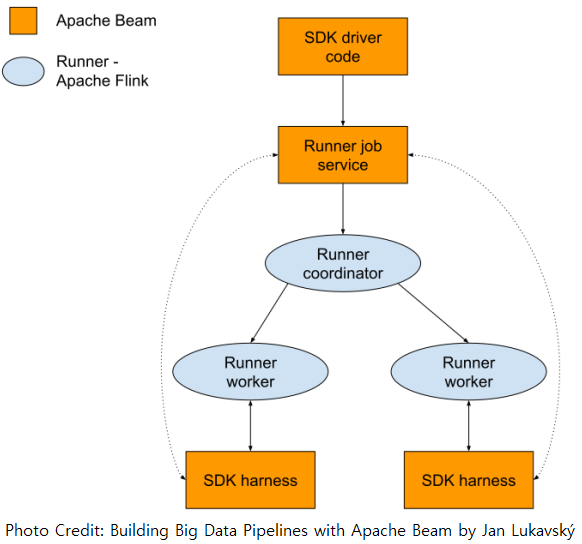
Each Runner typically has a coordinator that needs to receive a job submission and creates tasks for worker nodes according to the submission. For example, the coordinator of the Flink Runner is the Flink JobManager, and it receives a Java JAR file for job execution along with the Directed Acyclic Graph (DAG) of transforms, serialized user code and so on.
Then there are two problems to solve.
- How can a non-Java SDK converts a Beam pipeline into a Java JAR that the Flink Runner understands?
- How can the Runner’s worker nodes execute non-Java user code?
These problems are tackled down by (1) portable pipeline representation, (2) Job Service, and (3) SDK harness.
Portable pipeline representation
A non-Java SDK converts a Beam pipeline into a portable representation, which mainly includes the Directed Acyclic Graph (DAG) of transforms and serialized user-defined functions (UDFs)/user code - eg beam.Map(…). Protocol buffers are used for this representation, and it is submitted to Job Service once created.
Job Service
This component receives a portable representation of a pipeline and converts it into a format that a Runner can understand. Note that, when it creates a job, it replaces calls to UDFs with calls to the SDK harness process in which the UDFs are actually executed for the Runner. Also, it instructs the Runner coordinator to create a SDK harness process for each worker.
SDK harness
As mentioned, calls to UDFs on a Runner worker are delegated to calls in the SDK harness process, and the UDFs are executed using the same SDK that they are created. Note that communication between the Runner worker and the SDK harness process is made by gRPC - an HTTP/2 based protocol that relies on protocol buffers as its serialization mechanism. The harness is specific to SDK and, for the Python SDK, there are multiple options.
- DOCKER (default): User code is executed within a container started on each worker node.
- PROCESS: User code is executed by processes that are automatically started by the runner on each worker node.
- EXTERNAL: User code is dispatched to an external service.
- LOOPBACK: User code is executed within the same process that submitted the pipeline and is useful for local testing.
Cross-language Pipelines
The portability layer can be extended to cross-language pipelines where transforms are mixed from multiple SDKs. A typical example is the Kafka Connector I/O for the Python SDK where the ReadFromKafka and WriteToKafka transforms are made by the Java SDK. Also, the SQL transform (SqlTransform) of Beam SQL is performed by the Java SDK.
Here the challenge is how to make a non-Java SDK to be able to serialize data for a Java SDK so that its portable pipeline representation can be created! This challenge is handled by the expansion service. Simply put, when a source SDK wants to submit a pipeline to a Runner, it creates its portable pipeline representation. During this process, if it sees an external (cross-language) transform, it sends a request to the expansion service, asking it to expand the transform into a portable representation. Then, the expansion service creates/returns the portable representation, and it is inserted into the complete pipeline representation. For the Python SDK, the expansion service gets started automatically, or we can customize it, for example, to change the SDK harness from DOCKER to PROCESS.
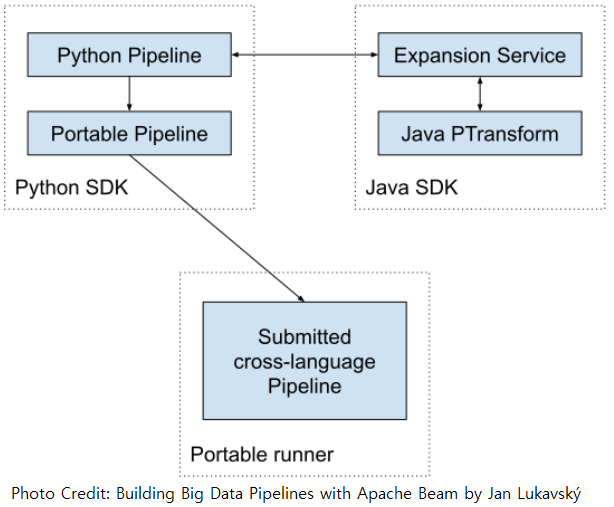
Note this section is based on Building Big Data Pipelines with Apache Beam by Jan Lukavský and you can check more details in the book!
Manage Streaming Environment
The streaming development environment requires local Apache Flink and Apache Kafka clusters. Initially I was going to create a Flink cluster on Docker, but I had an issue that the Kafka Connect I/O fails to resolve Kafka bootstrap addresses. Specifically, for the Kafka I/O, a docker container is launched by the Flink TaskManager with the host network (--network host) - remind that the default SDK harness option is DOCKER. Then the SDK harness container looks for Kafka bootstrap addresses in its host, which is the Flink TaskManager container, not the Docker host machine. Therefore, the address resolution fails because the Kafka cluster doesn’t run there. It would work with other SDH harness options, but I thought it requires too much setup for local development. On the other hand, the issue no longer applies if we launch a Flink cluster locally, and we will use this approach instead. The source of this post can be found in this GitHub repository.
Flink Cluster
The latest supported version of Apache Flink is 1.16 as of writing this post, and we can download and unpack it in a dedicated folder named setup as shown below. Note that some scripts in the bin folder should be executable, and their permission is changed at the end.
1$ mkdir setup && cd setup
2$ wget https://dlcdn.apache.org/flink/flink-1.16.3/flink-1.16.3-bin-scala_2.12.tgz
3$ tar -zxf flink-1.16.3-bin-scala_2.12.tgz
4$ chmod -R +x flink-1.16.3/bin/
Next, Flink configuration is updated so that the Flink UI is accessible and the number of tasks slots is increased to 10.
1# setup/flink-1.16.3/config/flink-conf.yaml
2 rest.port: 8081 # uncommented
3 rest.address: localhost # kept as is
4 rest.bind-address: 0.0.0.0 # changed from localhost
5 taskmanager.numberOfTaskSlots: 10 # updated from 1
Kafka Cluster
A Kafka cluster with 1 broker and 1 Zookeeper node is used for this post together with a Kafka management app (kafka-ui). The details of setting up the resources can be found in my Kafka Development with Docker series.
Those resources are deployed using Docker Compose with the following configuration file.
1# setup/docker-compose.yml
2version: "3.5"
3
4services:
5 zookeeper:
6 image: bitnami/zookeeper:3.5
7 container_name: zookeeper
8 expose:
9 - 2181
10 networks:
11 - appnet
12 environment:
13 - ALLOW_ANONYMOUS_LOGIN=yes
14 volumes:
15 - zookeeper_data:/bitnami/zookeeper
16 kafka-0:
17 image: bitnami/kafka:2.8.1
18 container_name: kafka-0
19 expose:
20 - 9092
21 ports:
22 - "29092:29092"
23 networks:
24 - appnet
25 environment:
26 - ALLOW_PLAINTEXT_LISTENER=yes
27 - KAFKA_CFG_ZOOKEEPER_CONNECT=zookeeper:2181
28 - KAFKA_CFG_BROKER_ID=0
29 - KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=INTERNAL:PLAINTEXT,EXTERNAL:PLAINTEXT
30 - KAFKA_CFG_LISTENERS=INTERNAL://:9092,EXTERNAL://:29092
31 - KAFKA_CFG_ADVERTISED_LISTENERS=INTERNAL://kafka-0:9092,EXTERNAL://localhost:29092
32 - KAFKA_CFG_INTER_BROKER_LISTENER_NAME=INTERNAL
33 - KAFKA_CFG_NUM_PARTITIONS=3
34 - KAFKA_CFG_DEFAULT_REPLICATION_FACTOR=1
35 volumes:
36 - kafka_0_data:/bitnami/kafka
37 depends_on:
38 - zookeeper
39 kafka-ui:
40 image: provectuslabs/kafka-ui:v0.7.1
41 container_name: kafka-ui
42 ports:
43 - "8080:8080"
44 networks:
45 - appnet
46 environment:
47 KAFKA_CLUSTERS_0_NAME: local
48 KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS: kafka-0:9092
49 KAFKA_CLUSTERS_0_ZOOKEEPER: zookeeper:2181
50 depends_on:
51 - zookeeper
52 - kafka-0
53
54networks:
55 appnet:
56 name: app-network
57
58volumes:
59 zookeeper_data:
60 driver: local
61 name: zookeeper_data
62 kafka_0_data:
63 driver: local
64 name: kafka_0_data
Note that the bootstrap server is exposed on port 29092, and it can be accessed via localhost:29092 from the Docker host machine and host.docker.internal:29092 from a Docker container that is launched with the host network. Note further that, for the latter to work, we have to update the /etc/hosts file by adding an entry for host.docker.internal as shown below.
1$ cat /etc/hosts | grep host.docker.internal
2# 127.0.0.1 host.docker.internal
Manage Flink/Kafka Clusters
The Flink and Kafka clusters are managed by bash scripts. They accept three arguments: -k or -f to launch a Kafka or Flink cluster individually or -a to launch both of them. Below shows the startup script, and it creates a Kafka cluster on Docker followed by starting a Flink cluster if conditions are met.
1# setup/start-flink-env.sh
2#!/usr/bin/env bash
3
4while [[ "$#" -gt 0 ]]; do
5 case $1 in
6 -k|--kafka) start_kafka=true;;
7 -f|--flink) start_flink=true;;
8 -a|--all) start_all=true;;
9 *) echo "Unknown parameter passed: $1"; exit 1 ;;
10 esac
11 shift
12done
13
14if [ ! -z $start_all ] && [ $start_all = true ]; then
15 start_kafka=true
16 start_flink=true
17fi
18
19SCRIPT_DIR=$(dirname "$(readlink -f "$0")")
20
21#### start kafka cluster on docker
22if [ ! -z $start_kafka ] && [ $start_kafka = true ]; then
23 docker-compose -f ${SCRIPT_DIR}/docker-compose.yml up -d
24fi
25
26#### start local flink cluster
27if [ ! -z $start_flink ] && [ $start_flink = true ]; then
28 ${SCRIPT_DIR}/flink-1.16.3/bin/start-cluster.sh
29fi
The teardown script is structured to stop/remove the Kafka-related containers and Docker volumes, stop the Flink cluster and remove unused containers. The last pruning is for cleaning up containers that are created by Java SDK harness processes.
1# setup/stop-flink-env.sh
2#!/usr/bin/env bash
3
4while [[ "$#" -gt 0 ]]; do
5 case $1 in
6 -k|--kafka) stop_kafka=true;;
7 -f|--flink) stop_flink=true;;
8 -a|--all) stop_all=true;;
9 *) echo "Unknown parameter passed: $1"; exit 1 ;;
10 esac
11 shift
12done
13
14if [ ! -z $stop_all ] && [ $stop_all = true ]; then
15 stop_kafka=true
16 stop_flink=true
17fi
18
19SCRIPT_DIR=$(dirname "$(readlink -f "$0")")
20
21#### stop kafka cluster in docker
22if [ ! -z $stop_kafka ] && [ $stop_kafka = true ]; then
23 docker-compose -f ${SCRIPT_DIR}/docker-compose.yml down -v
24fi
25
26#### stop local flink cluster
27if [ ! -z $stop_flink ] && [ $stop_flink = true ]; then
28 ${SCRIPT_DIR}/flink-1.16.3/bin/stop-cluster.sh
29fi
30
31#### remove all stopped containers
32docker container prune -f
Steaming Pipeline
The streaming pipeline is really simple in this post that it just (1) reads/decodes messages from an input Kafka topic named website-visit, (2) parses the elements into a pre-defined type of EventLog and (3) encodes/sends them into an output Kafka topic named website-out.
The pipeline has a number of notable options as shown below. Those that are specific to the Flink Runner are marked in bold, and they can be checked further in the Flink Runner document.
- runner - The name of the Beam Runner, default to FlinkRunner.
- job_name - The pipeline job name that can be checked eg on the Flink UI.
- environment_type - The SDK harness environment type. LOOPBACK is selected for development, so that user code is executed within the same process that submitted the pipeline.
- streaming - The flag whether to enforce streaming mode or not.
- parallelism - The degree of parallelism to be used when distributing operations onto workers.
- experiments > use_deprecated_read - Use the depreciated read mode for the Kafka IO to work. See BEAM-11998 for details.
- checkpointing_interval - The interval in milliseconds at which to trigger checkpoints of the running pipeline.
- flink_master - The address of the Flink Master where the pipeline should be executed. It is automatically set as localhost:8081 if the use_own argument is included. Otherwise, the pipeline runs with an embedded Flink cluster.
1# section3/kafka_io.py
2import os
3import argparse
4import json
5import logging
6import typing
7
8import apache_beam as beam
9from apache_beam.io import kafka
10from apache_beam.options.pipeline_options import PipelineOptions
11from apache_beam.options.pipeline_options import SetupOptions
12
13
14class EventLog(typing.NamedTuple):
15 ip: str
16 id: str
17 lat: float
18 lng: float
19 user_agent: str
20 age_bracket: str
21 opted_into_marketing: bool
22 http_request: str
23 http_response: int
24 file_size_bytes: int
25 event_datetime: str
26 event_ts: int
27
28
29beam.coders.registry.register_coder(EventLog, beam.coders.RowCoder)
30
31
32def decode_message(kafka_kv: tuple):
33 return kafka_kv[1].decode("utf-8")
34
35
36def create_message(element: EventLog):
37 key = {"event_id": element.id, "event_ts": element.event_ts}
38 value = element._asdict()
39 print(key)
40 return json.dumps(key).encode("utf-8"), json.dumps(value).encode("utf-8")
41
42
43def parse_json(element: str):
44 row = json.loads(element)
45 # lat/lng sometimes empty string
46 if not row["lat"] or not row["lng"]:
47 row = {**row, **{"lat": -1, "lng": -1}}
48 return EventLog(**row)
49
50
51def run():
52 parser = argparse.ArgumentParser(description="Beam pipeline arguments")
53 parser.add_argument(
54 "--runner", default="FlinkRunner", help="Specify Apache Beam Runner"
55 )
56 parser.add_argument(
57 "--use_own",
58 action="store_true",
59 default="Flag to indicate whether to use an own local cluster",
60 )
61 opts = parser.parse_args()
62
63 pipeline_opts = {
64 "runner": opts.runner,
65 "job_name": "kafka-io",
66 "environment_type": "LOOPBACK",
67 "streaming": True,
68 "parallelism": 3,
69 "experiments": [
70 "use_deprecated_read"
71 ], ## https://github.com/apache/beam/issues/20979
72 "checkpointing_interval": "60000",
73 }
74 if opts.use_own is True:
75 pipeline_opts = {**pipeline_opts, **{"flink_master": "localhost:8081"}}
76 print(pipeline_opts)
77 options = PipelineOptions([], **pipeline_opts)
78 # Required, else it will complain that when importing worker functions
79 options.view_as(SetupOptions).save_main_session = True
80
81 p = beam.Pipeline(options=options)
82 (
83 p
84 | "Read from Kafka"
85 >> kafka.ReadFromKafka(
86 consumer_config={
87 "bootstrap.servers": os.getenv(
88 "BOOTSTRAP_SERVERS",
89 "host.docker.internal:29092",
90 ),
91 "auto.offset.reset": "earliest",
92 # "enable.auto.commit": "true",
93 "group.id": "kafka-io",
94 },
95 topics=["website-visit"],
96 )
97 | "Decode messages" >> beam.Map(decode_message)
98 | "Parse elements" >> beam.Map(parse_json).with_output_types(EventLog)
99 | "Create messages"
100 >> beam.Map(create_message).with_output_types(typing.Tuple[bytes, bytes])
101 | "Write to Kafka"
102 >> kafka.WriteToKafka(
103 producer_config={
104 "bootstrap.servers": os.getenv(
105 "BOOTSTRAP_SERVERS",
106 "host.docker.internal:29092",
107 )
108 },
109 topic="website-out",
110 )
111 )
112
113 logging.getLogger().setLevel(logging.INFO)
114 logging.info("Building pipeline ...")
115
116 p.run().wait_until_finish()
117
118
119if __name__ == "__main__":
120 run()
Start Flink/Kafka Clusters
To run the pipeline, we need to launch a Kafka cluster and optionally a Flink cluster. They can be created using the startup script with the -a or -k option. We create both the clusters for the example pipeline of this post.
1# start both flink and kafka cluster
2$ ./setup/start-flink-env.sh -a
3
4# start only kafka cluster
5# ./setup/start-flink-env.sh -k
Once the clusters are launched, we can check the Kafka resources on localhost:8080.
And the Flink web UI is accessible on localhost:8081.
Generate Data
For streaming data generation, we can use the website visit log generator that was introduced in Part 1. We can execute the script while specifying the source argument to streaming. Below shows an example of generating Kafka messages for the streaming pipeline.
1$ python datagen/generate_data.py --source streaming --num_users 5 --delay_seconds 0.5
2# 10 events created so far...
3# {'ip': '126.1.20.79', 'id': '-2901668335848977108', 'lat': 35.6895, 'lng': 139.6917, 'user_agent': 'Mozilla/5.0 (Windows; U; Windows NT 5.1) AppleWebKit/533.44.1 (KHTML, like Gecko) Version/4.0.2 Safari/533.44.1', 'age_bracket': '26-40', 'opted_into_marketing': True, 'http_request': 'GET chromista.html HTTP/1.0', 'http_response': 200, 'file_size_bytes': 316, 'event_datetime': '2024-04-14T21:51:33.042', 'event_ts': 1713095493042}
4# 20 events created so far...
5# {'ip': '126.1.20.79', 'id': '-2901668335848977108', 'lat': 35.6895, 'lng': 139.6917, 'user_agent': 'Mozilla/5.0 (Windows; U; Windows NT 5.1) AppleWebKit/533.44.1 (KHTML, like Gecko) Version/4.0.2 Safari/533.44.1', 'age_bracket': '26-40', 'opted_into_marketing': True, 'http_request': 'GET archaea.html HTTP/1.0', 'http_response': 200, 'file_size_bytes': 119, 'event_datetime': '2024-04-14T21:51:38.090', 'event_ts': 1713095498090}
6# ...
Run Pipeline
The streaming pipeline can be executed as shown below. As mentioned, we use the local Flink cluster by specifying the use_own argument.
1$ python section3/kafka_io.py --use_own
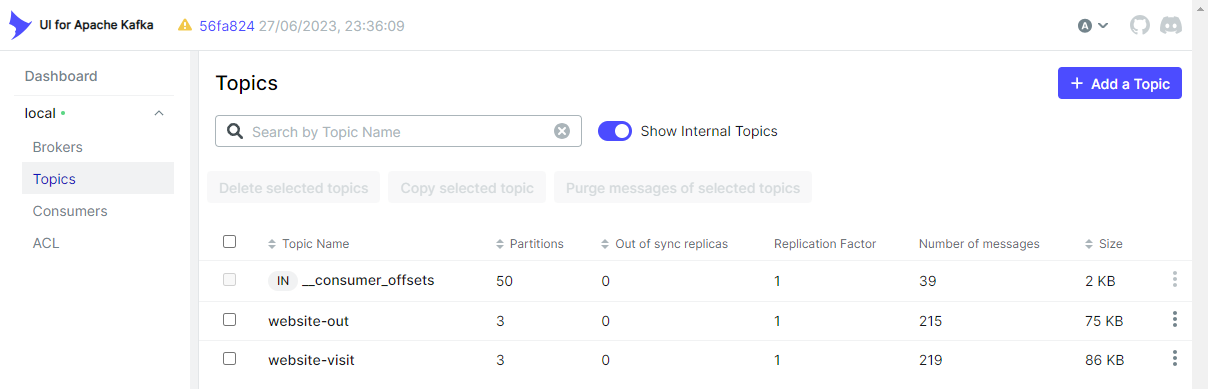
After a while, we can check both the input and output topics in the Topics section of kafka-ui.
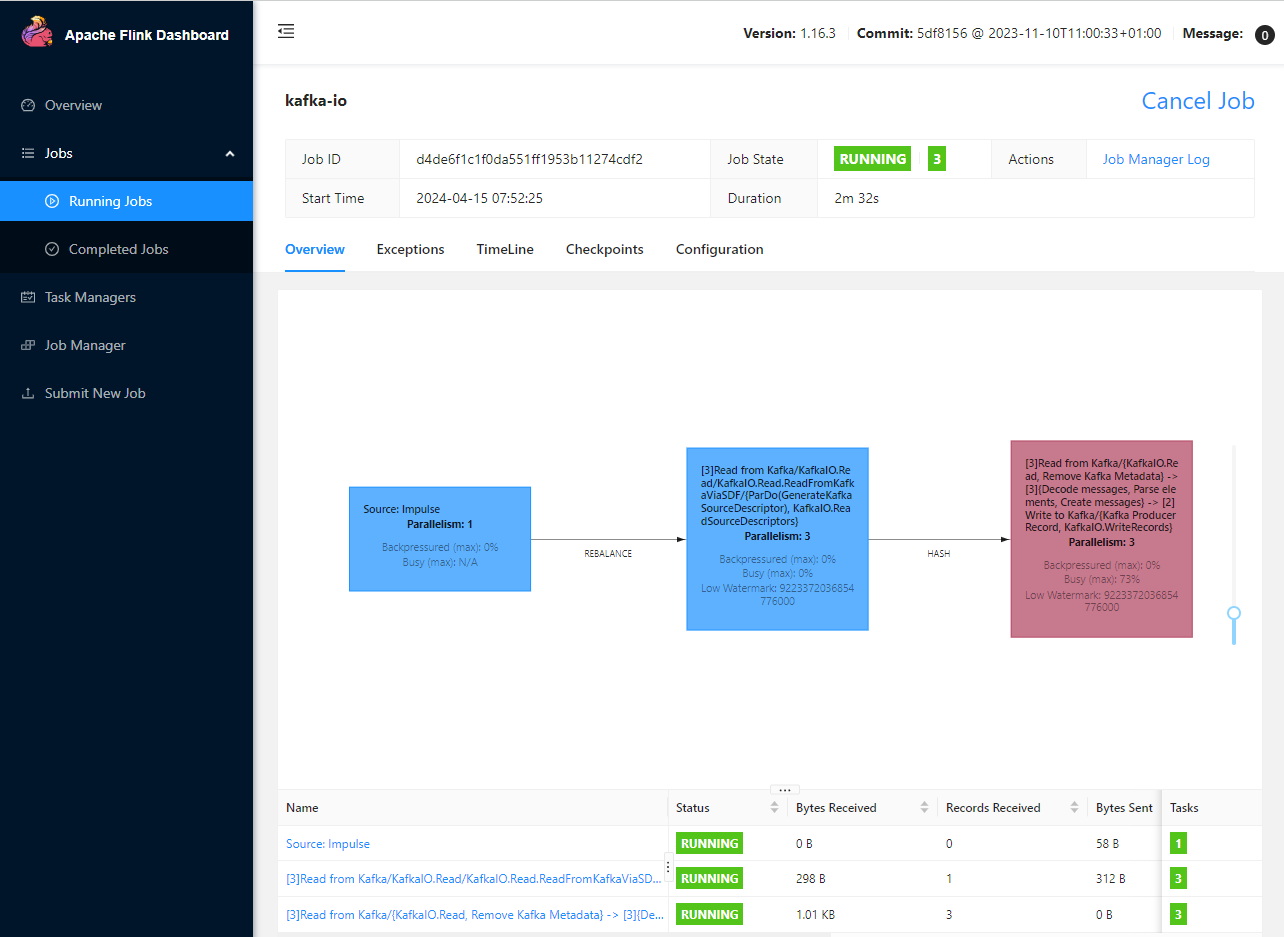
We can use the Flink web UI to monitor the pipeline as a Flink job. When we click the kafka-io job in the Running Jobs section, we see 3 operations are linked in the Overview tab. The first two operations are polling and reading Kafka source description while the actual pipeline runs in the last operation.
Note that, although the main pipeline’s SDK harness is set to LOOPBACK, the Kafka I/O runs on the Java SDK, and it associates with its own SDK harness, which defaults to DOCKER. We can check the Kafka I/O’s SDK harness process is launched in a container as following.
1$ docker ps -a --format "table {{.ID}}\t{{.Image}}\t{{.Command}}\t{{.Status}}"
2CONTAINER ID IMAGE COMMAND STATUS
33cd5a628a970 apache/beam_java11_sdk:2.53.0 "/opt/apache/beam/bo…" Up 4 minutes
Stop Flink/Kafka Clusters
After we stop the pipeline and data generation scripts, we can tear down the Flink and Kafka clusters using the bash script that was explained earlier with -a or -k arguments.
1# stop both flink and kafka cluster
2$ ./setup/stop-flink-env.sh -a
3
4# stop only kafka cluster
5# ./setup/stop-flink-env.sh -k
Summary
The Apache Flink Runner supports Python, and it has good features that allow us to develop streaming pipelines effectively. We first discussed the portability layer of Apache Beam as it helps understand (1) how a pipeline developed by the Python SDK can be executed in the Flink Runner that only understands Java JAR and (2) how multiple SDKs can be used in a single pipeline. Then we moved on to how to manage local Flink and Kafka clusters using bash scripts. Finally, we ended up illustrating a simple streaming pipeline, which reads and writes website visit logs from and to Kafka topics.










Comments