
In this series, we develop Apache Beam Python pipelines. The majority of them are from Building Big Data Pipelines with Apache Beam by Jan Lukavský. Mainly relying on the Java SDK, the book teaches fundamentals of Apache Beam using hands-on tasks, and we convert those tasks using the Python SDK. We focus on streaming pipelines, and they are deployed on a local (or embedded) Apache Flink cluster using the Apache Flink Runner. Beginning with setting up the development environment, we build two pipelines that obtain top K most frequent words and the word that has the longest word length in this post.
- Part 1 Calculate K Most Frequent Words and Max Word Length (this post)
- Part 2 Calculate Average Word Length with/without Fixed Look back
- Part 3 Build Sport Activity Tracker with/without SQL
- Part 4 Call RPC Service for Data Augmentation
- Part 5 Call RPC Service in Batch using Stateless DoFn
- Part 6 Call RPC Service in Batch with Defined Batch Size using Stateful DoFn
- Part 7 Separate Droppable Data into Side Output
- Part 8 Enhance Sport Activity Tracker with Runner Motivation
- Part 9 Develop Batch File Reader and PiSampler using Splittable DoFn
- Part 10 Develop Streaming File Reader using Splittable DoFn
[UPDATE 2025-10-01]
Bitnami’s public Docker images have been moved to the Bitnami Legacy repository. To ensure continued access and compatibility, please update your Docker image references accordingly.
For example:
bitnami/kafka:2.8.1→bitnamilegacy/kafka:2.8.1bitnami/zookeeper:3.7.0→bitnamilegacy/zookeeper:3.7.0bitnami/python:3.9.0→bitnamilegacy/python:3.9.0
Development Environment
The development environment has an Apache Flink cluster, Apache Kafka cluster and gRPC Server. The gRPC server will be used in Part 4 to 6. For Flink, we can use either an embedded cluster or a local cluster while Docker Compose is used for the rest. The source of this post can be found in this GitHub repository.
Flink Cluster
To set up a local Flink cluster, we should download a supported Flink release (e.g. 1.16.3, 1.17.2 or 1.18.1) - we use Flink 1.18.1 with Apache Beam 2.57.0 in this series. Once downloaded, we need to update the Flink configuration file, for example, to enable the Flink UI and to make the Flink binaries to be executable. The steps can be found below.
1mkdir -p setup && cd setup
2## 1. download flink binary and decompress in the same folder
3FLINK_VERSION=1.18.1 # change flink version eg) 1.16.3, 1.17.2, 1.18.1 ...
4wget https://dlcdn.apache.org/flink/flink-${FLINK_VERSION}/flink-${FLINK_VERSION}-bin-scala_2.12.tgz
5tar -zxf flink-${FLINK_VERSION}-bin-scala_2.12.tgz
6## 2. update flink configuration in eg) ./flink-${FLINK_VERSION}/conf/flink-conf.yaml
7## rest.port: 8081 # uncommented
8## rest.address: localhost # kept as is
9## rest.bind-address: 0.0.0.0 # changed from localhost
10## taskmanager.numberOfTaskSlots: 10 # updated from 1
11## 3. make flink binaries to be executable
12chmod -R +x flink-${FLINK_VERSION}/bin
Kafka Cluster
A Kafka cluster with 1 broker and 1 Zookeeper node is used together with a Kafka management app (kafka-ui). The details of setting up the resources can be found in my Kafka Development with Docker series: Part 1 Cluster Setup and Part 2 Management App.
Those resources are deployed using Docker Compose with the following configuration file.
1# setup/docker-compose.yml
2version: "3.5"
3
4services:
5 zookeeper:
6 image: bitnami/zookeeper:3.5
7 container_name: zookeeper
8 expose:
9 - 2181
10 networks:
11 - appnet
12 environment:
13 - ALLOW_ANONYMOUS_LOGIN=yes
14 volumes:
15 - zookeeper_data:/bitnami/zookeeper
16 kafka-0:
17 image: bitnami/kafka:2.8.1
18 container_name: kafka-0
19 expose:
20 - 9092
21 ports:
22 - "29092:29092"
23 networks:
24 - appnet
25 environment:
26 - ALLOW_PLAINTEXT_LISTENER=yes
27 - KAFKA_CFG_ZOOKEEPER_CONNECT=zookeeper:2181
28 - KAFKA_CFG_BROKER_ID=0
29 - KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=INTERNAL:PLAINTEXT,EXTERNAL:PLAINTEXT
30 - KAFKA_CFG_LISTENERS=INTERNAL://:9092,EXTERNAL://:29092
31 - KAFKA_CFG_ADVERTISED_LISTENERS=INTERNAL://kafka-0:9092,EXTERNAL://localhost:29092
32 - KAFKA_CFG_INTER_BROKER_LISTENER_NAME=INTERNAL
33 - KAFKA_CFG_NUM_PARTITIONS=3
34 - KAFKA_CFG_DEFAULT_REPLICATION_FACTOR=1
35 volumes:
36 - kafka_0_data:/bitnami/kafka
37 depends_on:
38 - zookeeper
39 kafka-ui:
40 image: provectuslabs/kafka-ui:v0.7.1
41 container_name: kafka-ui
42 ports:
43 - "8080:8080"
44 networks:
45 - appnet
46 environment:
47 KAFKA_CLUSTERS_0_NAME: local
48 KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS: kafka-0:9092
49 KAFKA_CLUSTERS_0_ZOOKEEPER: zookeeper:2181
50 depends_on:
51 - zookeeper
52 - kafka-0
53
54networks:
55 appnet:
56 name: app-network
57
58volumes:
59 zookeeper_data:
60 driver: local
61 name: zookeeper_data
62 kafka_0_data:
63 driver: local
64 name: kafka_0_data
Note that the Kafka bootstrap server is accessible on port 29092 outside the Docker network, and it can be accessed on localhost:29092 from the Docker host machine and on host.docker.internal:29092 from a Docker container that is launched with the host network. We use both types of the bootstrap server address - the former is used by the Kafka producer app and the latter by a Java IO expansion service, which is launched in a Docker container. Note further that, for the latter to work, we have to update the /etc/hosts file by adding an entry for host.docker.internal as shown below.
1cat /etc/hosts | grep host.docker.internal
2# 127.0.0.1 host.docker.internal
gRPC Server
We develop several pipelines that call an external RPC service for data enrichment in later posts. A gRPC server is required for those pipelines, and it is created using Docker Compose. The details of developing the underlying service will be discussed in Part 4.
1# setup/docker-compose-grpc.yml
2version: "3.5"
3
4services:
5 grpc-server:
6 build:
7 context: .
8 image: grpc-server
9 container_name: grpc-server
10 command: ["python", "/app/server.py"]
11 ports:
12 - 50051:50051
13 networks:
14 - appnet
15 environment:
16 PYTHONUNBUFFERED: "1"
17 INSECURE_PORT: 0.0.0.0:50051
18 volumes:
19 - ../chapter3:/app
20
21networks:
22 appnet:
23 name: grpc-network
Manage Resources
The Flink and Kafka clusters and gRPC server are managed by bash scripts. Those scripts accept four flags: -f, -k and -g to start/stop individual resources or -a to manage all of them. We can add multiple flags to start/stop relevant resources. Note that the scripts assume Flink 1.18.1 by default, and we can specify a specific Flink version if it is different from it e.g. FLINK_VERSION=1.17.2 ./setup/start-flink-env.sh.
1# setup/start-flink-env.sh
2#!/usr/bin/env bash
3
4while [[ "$#" -gt 0 ]]; do
5 case $1 in
6 -k|--kafka) start_kafka=true;;
7 -f|--flink) start_flink=true;;
8 -g|--grpc) start_grpc=true;;
9 -a|--all) start_all=true;;
10 *) echo "Unknown parameter passed: $1"; exit 1 ;;
11 esac
12 shift
13done
14
15if [ ! -z $start_all ] && [ $start_all = true ]; then
16 start_kafka=true
17 start_flink=true
18 start_grpc=true
19fi
20
21SCRIPT_DIR=$(dirname "$(readlink -f "$0")")
22
23#### start kafka cluster in docker
24if [ ! -z $start_kafka ] && [ $start_kafka = true ]; then
25 echo "start kafka..."
26 docker-compose -f ${SCRIPT_DIR}/docker-compose.yml up -d
27fi
28
29#### start grpc server in docker
30if [ ! -z $start_grpc ] && [ $start_grpc = true ]; then
31 echo "start grpc server..."
32 docker-compose -f ${SCRIPT_DIR}/docker-compose-grpc.yml up -d
33fi
34
35#### start local flink cluster
36if [ ! -z $start_flink ] && [ $start_flink = true ]; then
37 FLINK_VERSION=${FLINK_VERSION:-1.18.1}
38 echo "start flink ${FLINK_VERSION}..."
39 ${SCRIPT_DIR}/flink-${FLINK_VERSION}/bin/start-cluster.sh
40fi
The teardown script stops applicable resources followed by removing all stopped containers. Comment out the container prune command if necessary (docker container prune -f).
1# setup/stop-flink-env.sh
2#!/usr/bin/env bash
3
4while [[ "$#" -gt 0 ]]; do
5 case $1 in
6 -k|--kafka) stop_kafka=true;;
7 -f|--flink) stop_flink=true;;
8 -g|--grpc) stop_grpc=true;;
9 -a|--all) stop_all=true;;
10 *) echo "Unknown parameter passed: $1"; exit 1 ;;
11 esac
12 shift
13done
14
15if [ ! -z $stop_all ] && [ $stop_all = true ]; then
16 stop_kafka=true
17 stop_flink=true
18 stop_grpc=true
19fi
20
21SCRIPT_DIR=$(dirname "$(readlink -f "$0")")
22
23#### stop kafka cluster in docker
24if [ ! -z $stop_kafka ] && [ $stop_kafka = true ]; then
25 echo "stop kafka..."
26 docker-compose -f ${SCRIPT_DIR}/docker-compose.yml down -v
27fi
28
29#### stop grpc server in docker
30if [ ! -z $stop_grpc ] && [ $stop_grpc = true ]; then
31 echo "stop grpc server..."
32 docker-compose -f ${SCRIPT_DIR}/docker-compose-grpc.yml down
33fi
34
35#### stop local flink cluster
36if [ ! -z $stop_flink ] && [ $stop_flink = true ]; then
37 FLINK_VERSION=${FLINK_VERSION:-1.18.1}
38 echo "stop flink ${FLINK_VERSION}..."
39 ${SCRIPT_DIR}/flink-${FLINK_VERSION}/bin/stop-cluster.sh
40fi
41
42#### remove all stopped containers
43docker container prune -f
Below shows how to start resources using the start-up script. We need to launch both the Flink and Kafka clusters if we deploy a Beam pipeline on a local Flink cluster. Otherwise, we can start the Kafka cluster only.
1## start a local flink can kafka cluster
2./setup/start-flink-env.sh -f -k
3# start kafka...
4# [+] Running 6/6
5# ⠿ Network app-network Created 0.0s
6# ⠿ Volume "zookeeper_data" Created 0.0s
7# ⠿ Volume "kafka_0_data" Created 0.0s
8# ⠿ Container zookeeper Started 0.3s
9# ⠿ Container kafka-0 Started 0.5s
10# ⠿ Container kafka-ui Started 0.8s
11# start flink 1.18.1...
12# Starting cluster.
13# Starting standalonesession daemon on host <hostname>.
14# Starting taskexecutor daemon on host <hostname>.
15
16## start a local kafka cluster only
17./setup/start-flink-env.sh -k
18# start kafka...
19# [+] Running 6/6
20# ⠿ Network app-network Created 0.0s
21# ⠿ Volume "zookeeper_data" Created 0.0s
22# ⠿ Volume "kafka_0_data" Created 0.0s
23# ⠿ Container zookeeper Started 0.3s
24# ⠿ Container kafka-0 Started 0.5s
25# ⠿ Container kafka-ui Started 0.8s
Kafka Text Producer
We create a Kafka producer using the kafka-python package. It generates text messages with the Faker package and sends them to an input topic. Note that message creation timestamp is shifted back randomly to simulate late messages. We can run the producer simply by executing the producer script.
1# utils/faker_gen.py
2import time
3import argparse
4
5from faker import Faker
6from producer import TextProducer
7
8if __name__ == "__main__":
9 parser = argparse.ArgumentParser(__file__, description="Fake Text Data Generator")
10 parser.add_argument(
11 "--bootstrap_servers",
12 "-b",
13 type=str,
14 default="localhost:29092",
15 help="Comma separated string of Kafka bootstrap addresses",
16 )
17 parser.add_argument(
18 "--topic_name",
19 "-t",
20 type=str,
21 default="input-topic",
22 help="Kafka topic name",
23 )
24 parser.add_argument(
25 "--delay_seconds",
26 "-d",
27 type=float,
28 default=1,
29 help="The amount of time that a record should be delayed.",
30 )
31 args = parser.parse_args()
32
33 producer = TextProducer(args.bootstrap_servers, args.topic_name)
34 fake = Faker()
35
36 num_events = 0
37 while True:
38 num_events += 1
39 text = fake.text()
40 producer.send_to_kafka(text)
41 if num_events % 10 == 0:
42 print(f"{num_events} text sent. current - {text}")
43 time.sleep(args.delay_seconds)
The second producer accepts text inputs by user, and it can be used for controlling text messages as well as message creation timestamps. The latter feature is useful for testing late arrival data.
1# utils/interactive_gen.py
2import re
3import time
4import argparse
5
6from producer import TextProducer
7
8
9def get_digit(shift: str, pattern: str = None):
10 try:
11 return int(re.sub(pattern, "", shift).strip())
12 except (TypeError, ValueError):
13 return 1
14
15
16def get_ts_shift(shift: str):
17 current = int(time.time() * 1000)
18 multiplier = 1
19 if shift.find("m") > 0:
20 multiplier = 60 * 1000
21 digit = get_digit(shift, r"m.+")
22 elif shift.find("s") > 0:
23 multiplier = 1000
24 digit = get_digit(shift, r"s.+")
25 else:
26 digit = get_digit(shift)
27 return {
28 "current": current,
29 "shift": int(digit) * multiplier,
30 "shifted": current + int(digit) * multiplier,
31 }
32
33
34def parse_user_input(user_input: str):
35 if len(user_input.split(";")) == 2:
36 shift, text = tuple(user_input.split(";"))
37 shift_info = get_ts_shift(shift)
38 msg = " | ".join(
39 [f"{k}: {v}" for k, v in {**{"text": text.strip()}, **shift_info}.items()]
40 )
41 print(f">> {msg}")
42 return {"text": text.strip(), "timestamp_ms": shift_info["shifted"]}
43 print(f">> text: {user_input}")
44 return {"text": user_input}
45
46
47if __name__ == "__main__":
48 parser = argparse.ArgumentParser(
49 __file__, description="Interactive Text Data Generator"
50 )
51 parser.add_argument(
52 "--bootstrap_servers",
53 "-b",
54 type=str,
55 default="localhost:29092",
56 help="Comma separated string of Kafka bootstrap addresses",
57 )
58 parser.add_argument(
59 "--topic_name",
60 "-t",
61 type=str,
62 default="input-topic",
63 help="Kafka topic name",
64 )
65 args = parser.parse_args()
66
67 producer = TextProducer(args.bootstrap_servers, args.topic_name)
68
69 while True:
70 user_input = input("ENTER TEXT: ")
71 args = parse_user_input(user_input)
72 producer.send_to_kafka(**args)
By default, the message creation timestamp is not shifted. We can do so by appending shift details (digit and scale) (e.g. 1 minute or 10 sec). Below shows some usage examples.
1python utils/interactive_gen.py
2# ENTER TEXT: By default, message creation timestamp is not shifted!
3# >> text: By default, message creation timestamp is not shifted!
4# ENTER TEXT: -10 sec;Add time digit and scale to shift back. should be separated by semi-colon
5# >> text: Add time digit and scale to shift back. should be separated by semi-colon | current: 1719891195495 | shift: -10000 | shifted: 1719891185495
6# ENTER TEXT: -10s;We don't have to keep a blank.
7# >> text: We don't have to keep a blank. | current: 1719891203698 | shift: 1000 | shifted: 1719891204698
8# ENTER TEXT: 1 min;We can shift to the future but is it realistic?
9# >> text: We can shift to the future but is it realistic? | current: 1719891214039 | shift: 60000 | shifted: 1719891274039
Both the producer apps send text messages using the following Kafka producer class.
1# utils/producer.py
2from kafka import KafkaProducer
3
4
5class TextProducer:
6 def __init__(self, bootstrap_servers: list, topic_name: str) -> None:
7 self.bootstrap_servers = bootstrap_servers
8 self.topic_name = topic_name
9 self.kafka_producer = self.create_producer()
10
11 def create_producer(self):
12 """
13 Returns a KafkaProducer instance
14 """
15 return KafkaProducer(
16 bootstrap_servers=self.bootstrap_servers,
17 value_serializer=lambda v: v.encode("utf-8"),
18 )
19
20 def send_to_kafka(self, text: str, timestamp_ms: int = None):
21 """
22 Sends text to a Kafka topic.
23 """
24 try:
25 args = {"topic": self.topic_name, "value": text}
26 if timestamp_ms is not None:
27 args = {**args, **{"timestamp_ms": timestamp_ms}}
28 self.kafka_producer.send(**args)
29 self.kafka_producer.flush()
30 except Exception as e:
31 raise RuntimeError("fails to send a message") from e
Beam Pipelines
We develop two pipelines that obtain top K most frequent words and the word that has the longest word length.
Shared Transforms
Both the pipelines read text messages from an input Kafka topic and write outputs to an output topic. Therefore, the data source and sink transforms are refactored into a utility module as shown below.
1# chapter2/word_process_utils.py
2import re
3import typing
4
5import apache_beam as beam
6from apache_beam import pvalue
7from apache_beam.io import kafka
8
9
10def decode_message(kafka_kv: tuple):
11 print(kafka_kv)
12 return kafka_kv[1].decode("utf-8")
13
14
15def tokenize(element: str):
16 return re.findall(r"[A-Za-z\']+", element)
17
18
19class ReadWordsFromKafka(beam.PTransform):
20 def __init__(
21 self,
22 bootstrap_servers: str,
23 topics: typing.List[str],
24 group_id: str,
25 deprecated_read: bool,
26 verbose: bool = False,
27 label: str | None = None,
28 ) -> None:
29 super().__init__(label)
30 self.boostrap_servers = bootstrap_servers
31 self.topics = topics
32 self.group_id = group_id
33 self.verbose = verbose
34 self.expansion_service = None
35 if deprecated_read:
36 self.expansion_service = kafka.default_io_expansion_service(
37 ["--experiments=use_deprecated_read"]
38 )
39
40 def expand(self, input: pvalue.PBegin):
41 return (
42 input
43 | "ReadFromKafka"
44 >> kafka.ReadFromKafka(
45 consumer_config={
46 "bootstrap.servers": self.boostrap_servers,
47 "auto.offset.reset": "latest",
48 # "enable.auto.commit": "true",
49 "group.id": self.group_id,
50 },
51 topics=self.topics,
52 timestamp_policy=kafka.ReadFromKafka.create_time_policy,
53 commit_offset_in_finalize=True,
54 expansion_service=self.expansion_service,
55 )
56 | "DecodeMessage" >> beam.Map(decode_message)
57 )
58
59
60class WriteProcessOutputsToKafka(beam.PTransform):
61 def __init__(
62 self,
63 bootstrap_servers: str,
64 topic: str,
65 deprecated_read: bool, # TO DO: remove as it applies only to ReadFromKafka
66 label: str | None = None,
67 ) -> None:
68 super().__init__(label)
69 self.boostrap_servers = bootstrap_servers
70 self.topic = topic
71 # TO DO: remove as it applies only to ReadFromKafka
72 self.expansion_service = None
73 if deprecated_read:
74 self.expansion_service = kafka.default_io_expansion_service(
75 ["--experiments=use_deprecated_read"]
76 )
77
78 def expand(self, pcoll: pvalue.PCollection):
79 return pcoll | "WriteToKafka" >> kafka.WriteToKafka(
80 producer_config={"bootstrap.servers": self.boostrap_servers},
81 topic=self.topic,
82 expansion_service=self.expansion_service,
83 )
Calculate the K most frequent words
The main transform of this pipeline (CalculateTopKWords) performs
Windowing: assigns input text messages into a fixed time window of configurable length - 10 seconds by default.Tokenize: tokenizes (or converts) text into words.CountPerWord: counts occurrence of each word.TopKWords: selects top k words - 3 by default.Flatten: flattens a list of words into individual words.
Also, it adds the window start and end timestamps when creating output messages (CreateMessags).
1# chapter2/top_k_words.py
2import os
3import argparse
4import json
5import re
6import typing
7import logging
8
9import apache_beam as beam
10from apache_beam import pvalue
11from apache_beam.transforms.window import FixedWindows
12from apache_beam.options.pipeline_options import PipelineOptions
13from apache_beam.options.pipeline_options import SetupOptions
14
15from word_process_utils import tokenize, ReadWordsFromKafka, WriteProcessOutputsToKafka
16
17
18class CalculateTopKWords(beam.PTransform):
19 def __init__(
20 self, window_length: int, top_k: int, label: str | None = None
21 ) -> None:
22 self.window_length = window_length
23 self.top_k = top_k
24 super().__init__(label)
25
26 def expand(self, pcoll: pvalue.PCollection):
27 return (
28 pcoll
29 | "Windowing" >> beam.WindowInto(FixedWindows(size=self.window_length))
30 | "Tokenize" >> beam.FlatMap(tokenize)
31 | "CountPerWord" >> beam.combiners.Count.PerElement()
32 | "TopKWords"
33 >> beam.combiners.Top.Of(self.top_k, lambda e: e[1]).without_defaults()
34 | "Flatten" >> beam.FlatMap(lambda e: e)
35 )
36
37
38def create_message(element: typing.Tuple[str, str, str, int]):
39 msg = json.dumps(dict(zip(["window_start", "window_end", "word", "freq"], element)))
40 print(msg)
41 return "".encode("utf-8"), msg.encode("utf-8")
42
43
44class AddWindowTS(beam.DoFn):
45 def process(self, top_k: typing.Tuple[str, int], win_param=beam.DoFn.WindowParam):
46 yield (
47 win_param.start.to_rfc3339(),
48 win_param.end.to_rfc3339(),
49 top_k[0],
50 top_k[1],
51 )
52
53
54class CreateMessags(beam.PTransform):
55 def expand(self, pcoll: pvalue.PCollection):
56 return (
57 pcoll
58 | "AddWindowTS" >> beam.ParDo(AddWindowTS())
59 | "CreateMessages"
60 >> beam.Map(create_message).with_output_types(typing.Tuple[bytes, bytes])
61 )
62
63
64def run(argv=None, save_main_session=True):
65 parser = argparse.ArgumentParser(description="Beam pipeline arguments")
66 parser.add_argument(
67 "--bootstrap_servers",
68 default="host.docker.internal:29092",
69 help="Kafka bootstrap server addresses",
70 )
71 parser.add_argument("--input_topic", default="input-topic", help="Input topic")
72 parser.add_argument(
73 "--output_topic",
74 default=re.sub("_", "-", re.sub(".py$", "", os.path.basename(__file__))),
75 help="Output topic",
76 )
77 parser.add_argument("--window_length", default="10", type=int, help="Window length")
78 parser.add_argument("--top_k", default="3", type=int, help="Top k")
79 parser.add_argument(
80 "--deprecated_read",
81 action="store_true",
82 default="Whether to use a deprecated read. See https://github.com/apache/beam/issues/20979",
83 )
84 parser.set_defaults(deprecated_read=False)
85
86 known_args, pipeline_args = parser.parse_known_args(argv)
87
88 # # We use the save_main_session option because one or more DoFn's in this
89 # # workflow rely on global context (e.g., a module imported at module level).
90 pipeline_options = PipelineOptions(pipeline_args)
91 pipeline_options.view_as(SetupOptions).save_main_session = save_main_session
92 print(f"known args - {known_args}")
93 print(f"pipeline options - {pipeline_options.display_data()}")
94
95 with beam.Pipeline(options=pipeline_options) as p:
96 (
97 p
98 | "ReadInputsFromKafka"
99 >> ReadWordsFromKafka(
100 bootstrap_servers=known_args.bootstrap_servers,
101 topics=[known_args.input_topic],
102 group_id=f"{known_args.output_topic}-group",
103 deprecated_read=known_args.deprecated_read,
104 )
105 | "CalculateTopKWords"
106 >> CalculateTopKWords(
107 window_length=known_args.window_length,
108 top_k=known_args.top_k,
109 )
110 | "CreateMessags" >> CreateMessags()
111 | "WriteOutputsToKafka"
112 >> WriteProcessOutputsToKafka(
113 bootstrap_servers=known_args.bootstrap_servers,
114 topic=known_args.output_topic,
115 deprecated_read=known_args.deprecated_read,
116 )
117 )
118
119 logging.getLogger().setLevel(logging.WARN)
120 logging.info("Building pipeline ...")
121
122
123if __name__ == "__main__":
124 run()
Pipeline Test
As described in this documentation, we can test a Beam pipeline as following.
- Create a
TestPipeline. - Create some static, known test input data.
- Create a
PCollectionof input data using theCreatetransform (if bounded source) or aTestStream(if unbounded source) - Apply the transform to the input
PCollectionand save the resulting outputPCollection. - Use
PAssertand its subclasses (or testing utils in Python) to verify that the outputPCollectioncontains the elements that you expect.
We configure the first three lines to be delivered in 2 seconds and the remaining two lines after 10 seconds. Therefore, the whole elements are split into two fixed time windows, given the window length of 10 seconds. We can check the top 3 words are line, first and the in the first window while line, in and window are the top 3 words in the second window. Then, we can create the expected output as a list of tuples of word and number of occurrences and compare it with the pipeline output.
1# chapter2/top_k_words_test.py
2import unittest
3
4from apache_beam.coders import coders
5from apache_beam.utils.timestamp import Timestamp
6from apache_beam.testing.test_pipeline import TestPipeline
7from apache_beam.testing.util import assert_that, equal_to
8from apache_beam.testing.test_stream import TestStream
9from apache_beam.transforms.window import TimestampedValue
10from apache_beam.options.pipeline_options import PipelineOptions, StandardOptions
11
12from top_k_words import CalculateTopKWords
13
14
15class TopKWordsTest(unittest.TestCase):
16 def test_windowing_behaviour(self):
17 options = PipelineOptions()
18 options.view_as(StandardOptions).streaming = True
19 with TestPipeline(options=options) as p:
20 test_stream = (
21 TestStream(coder=coders.StrUtf8Coder())
22 .with_output_types(str)
23 .add_elements(
24 [
25 TimestampedValue("This is the first line.", Timestamp.of(0)),
26 TimestampedValue(
27 "This is second line in the first window", Timestamp.of(1)
28 ),
29 TimestampedValue(
30 "Last line in the first window", Timestamp.of(2)
31 ),
32 TimestampedValue(
33 "This is another line, but in different window.",
34 Timestamp.of(10),
35 ),
36 TimestampedValue(
37 "Last line, in the same window as previous line.",
38 Timestamp.of(11),
39 ),
40 ]
41 )
42 .advance_watermark_to_infinity()
43 )
44
45 output = (
46 p
47 | test_stream
48 | "CalculateTopKWords"
49 >> CalculateTopKWords(
50 window_length=10,
51 top_k=3,
52 )
53 )
54
55 EXPECTED_OUTPUT = [
56 ("line", 3),
57 ("first", 3),
58 ("the", 3),
59 ("line", 3),
60 ("in", 2),
61 ("window", 2),
62 ]
63
64 assert_that(output, equal_to(EXPECTED_OUTPUT))
65
66
67if __name__ == "__main__":
68 unittest.main()
We can execute the pipeline test as shown below.
1python chapter2/top_k_words_test.py -v
2test_windowing_behaviour (__main__.TopKWordsTest) ... ok
3
4----------------------------------------------------------------------
5Ran 1 test in 0.354s
6
7OK
Pipeline Execution
Below shows an example of executing the pipeline by specifying pipeline arguments only while accepting default values of the known arguments (bootstrap_servers, input_topic, …). Note that, we deploy the pipeline on a local Flink cluster by specifying the flink master argument (--flink_master=localhost:8081). Alternatively, we can use an embedded Flink cluster if we exclude that argument. Do not forget to update the /etc/hosts file by adding an entry for host.docker.internal as mentioned earlier.
1## start the beam pipeline
2## exclude --flink_master if using an embedded cluster
3python chapter2/top_k_words.py --job_name=top-k-words \
4 --runner FlinkRunner --flink_master=localhost:8081 \
5 --streaming --environment_type=LOOPBACK --parallelism=3 \
6 --checkpointing_interval=10000 --experiment=use_deprecated_read
On Flink UI, we see the pipeline polls messages and performs the main transform in multiple tasks while keeping Kafka offset commit as a separate task. Note that, although I added a flag (use_deprecated_read) to use the legacy read (ReadFromKafkaViaUnbounded), the splittable DoFn based read (ReadFromKafkaViaSDF) is used. It didn’t happen when I used Flink 1.16.3, and I’m looking into it. It looks okay to go through the example pipelines, but check this issue before deciding which read to use in production.
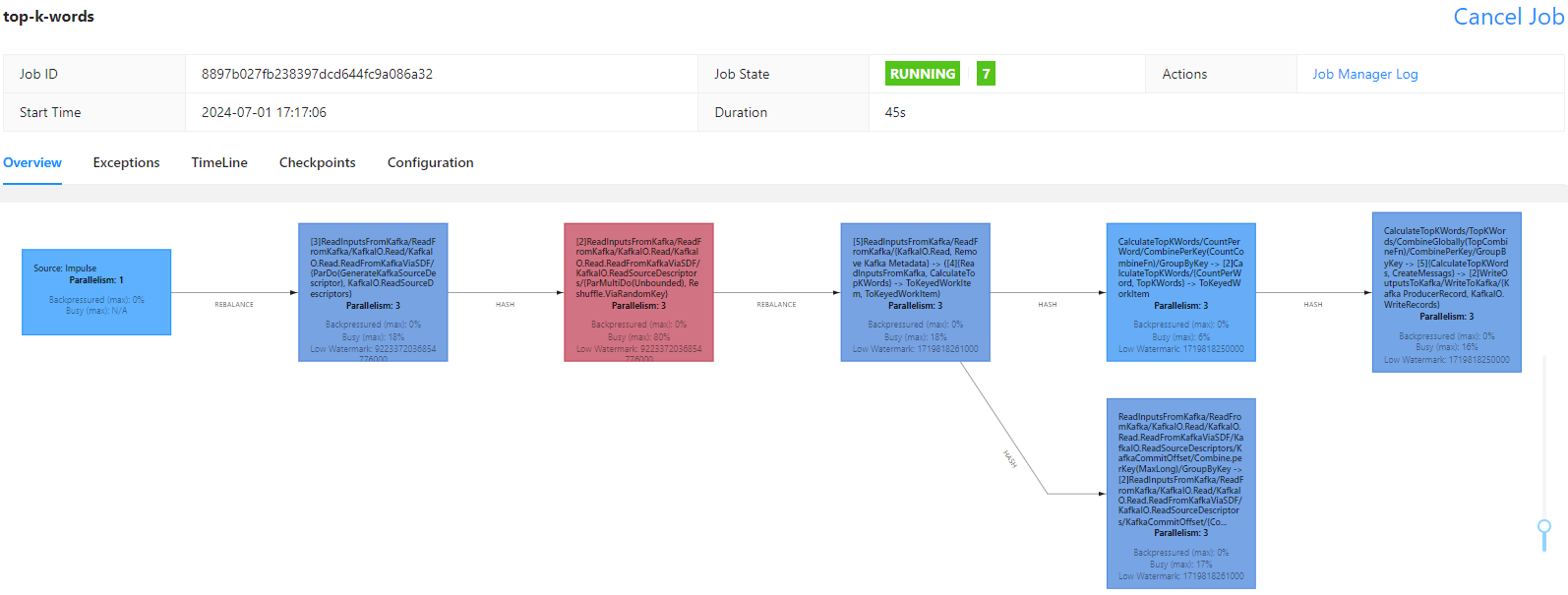
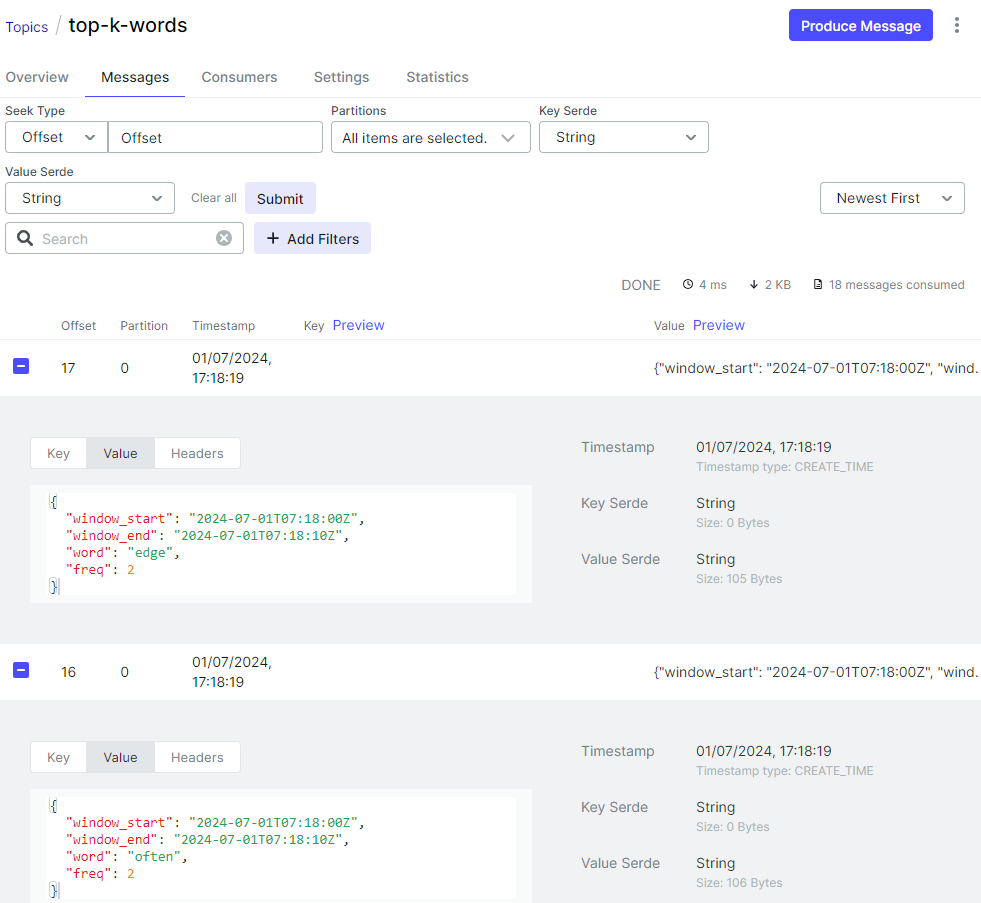
On Kafka UI, we can check the output message includes frequent word details as well as window start/end timestamps.
Update on 2024-07-11
I made a mistake to add the use_deprecated_read option to the pipeline argument. For the Python SDK to work, it should be specified in the default IO expansion service directly - see below.
1kafka.default_io_expansion_service(
2 ["--experiments=use_deprecated_read"]
3)
I updated the source and the pipeline should be executed as follows.
1## exclude --flink_master if using an embedded cluster
2python chapter2/top_k_words.py --deprecated_read \
3 --job_name=top-k-words --runner FlinkRunner --flink_master=localhost:8081 \
4 --streaming --environment_type=LOOPBACK --parallelism=3 --checkpointing_interval=10000
We can check the legacy read (ReadFromKafkaViaUnbounded) is used in the pipeline DAG.
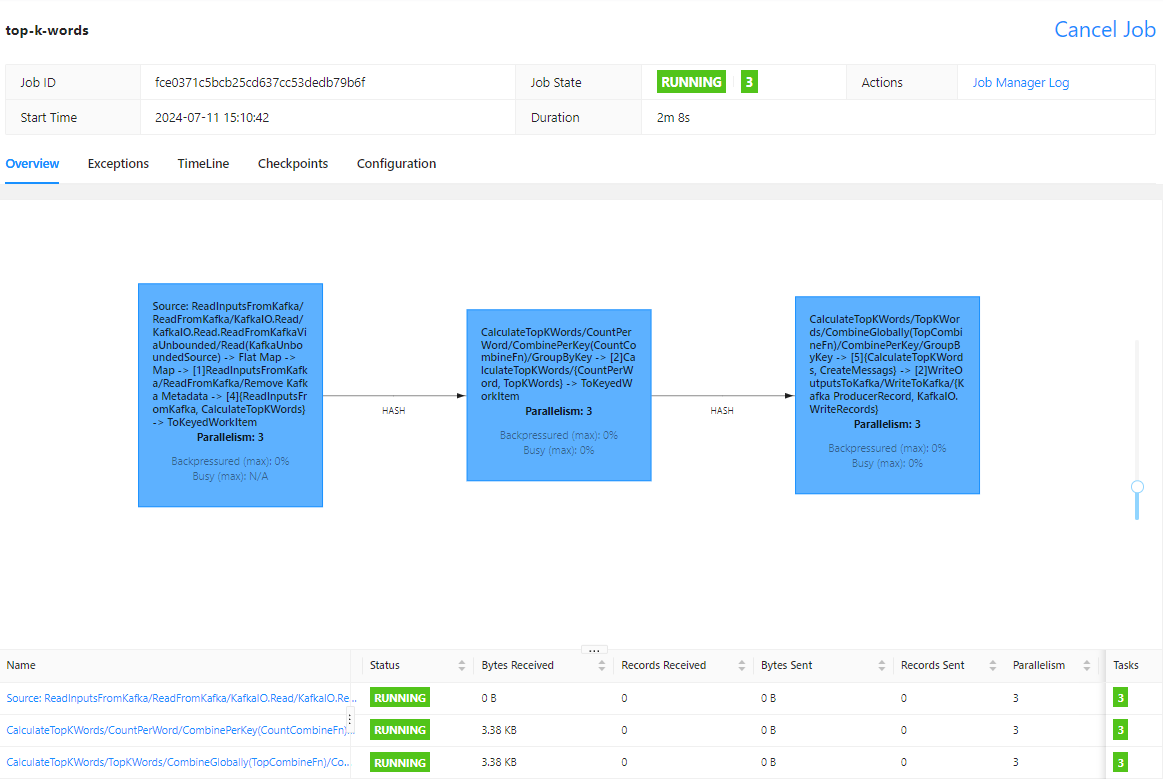
Calculate the maximal word length
The main transform of this pipeline (CalculateMaxWordLength) performs
Windowing: assigns input text messages into a global window and emits (or triggers) the result for every new input message with the following configuration.- Disallows Late data (
allowed_lateness=0) - Assigns the output timestamp from the latest input timestamp (
timestamp_combiner=TimestampCombiner.OUTPUT_AT_LATEST) - Keeps the previous elements that were already fired (
accumulation_mode=AccumulationMode.ACCUMULATING)
- Disallows Late data (
Tokenize: tokenizes (or converts) text into words.GetLongestWord: selects top 1 word that has the longest length.Flatten: flattens a list of words into a word.
Also, the output timestamp is added when creating output messages (CreateMessags).
1# chapter2/max_word_length_with_ts.py
2import os
3import argparse
4import json
5import re
6import logging
7import typing
8
9import apache_beam as beam
10from apache_beam import pvalue
11from apache_beam.transforms.window import GlobalWindows, TimestampCombiner
12from apache_beam.transforms.trigger import AfterCount, AccumulationMode, AfterWatermark
13from apache_beam.transforms.util import Reify
14from apache_beam.options.pipeline_options import PipelineOptions
15from apache_beam.options.pipeline_options import SetupOptions
16
17
18from word_process_utils import tokenize, ReadWordsFromKafka, WriteProcessOutputsToKafka
19
20
21class CalculateMaxWordLength(beam.PTransform):
22 def expand(self, pcoll: pvalue.PCollection):
23 return (
24 pcoll
25 | "Windowing"
26 >> beam.WindowInto(
27 GlobalWindows(),
28 trigger=AfterWatermark(early=AfterCount(1)),
29 allowed_lateness=0,
30 timestamp_combiner=TimestampCombiner.OUTPUT_AT_LATEST,
31 accumulation_mode=AccumulationMode.ACCUMULATING,
32 )
33 | "Tokenize" >> beam.FlatMap(tokenize)
34 | "GetLongestWord" >> beam.combiners.Top.Of(1, key=len).without_defaults()
35 | "Flatten" >> beam.FlatMap(lambda e: e)
36 )
37
38
39def create_message(element: typing.Tuple[str, str]):
40 msg = json.dumps(dict(zip(["created_at", "word"], element)))
41 print(msg)
42 return "".encode("utf-8"), msg.encode("utf-8")
43
44
45class AddTS(beam.DoFn):
46 def process(self, word: str, ts_param=beam.DoFn.TimestampParam):
47 yield ts_param.to_rfc3339(), word
48
49
50class CreateMessags(beam.PTransform):
51 def expand(self, pcoll: pvalue.PCollection):
52 return (
53 pcoll
54 | "ReifyTimestamp" >> Reify.Timestamp()
55 | "AddTimestamp" >> beam.ParDo(AddTS())
56 | "CreateMessages"
57 >> beam.Map(create_message).with_output_types(typing.Tuple[bytes, bytes])
58 )
59
60
61def run(argv=None, save_main_session=True):
62 parser = argparse.ArgumentParser(description="Beam pipeline arguments")
63 parser.add_argument(
64 "--bootstrap_servers",
65 default="host.docker.internal:29092",
66 help="Kafka bootstrap server addresses",
67 )
68 parser.add_argument("--input_topic", default="input-topic", help="Input topic")
69 parser.add_argument(
70 "--output_topic",
71 default=re.sub("_", "-", re.sub(".py$", "", os.path.basename(__file__))),
72 help="Output topic",
73 )
74 parser.add_argument(
75 "--deprecated_read",
76 action="store_true",
77 default="Whether to use a deprecated read. See https://github.com/apache/beam/issues/20979",
78 )
79 parser.set_defaults(deprecated_read=False)
80
81 known_args, pipeline_args = parser.parse_known_args(argv)
82
83 # # We use the save_main_session option because one or more DoFn's in this
84 # # workflow rely on global context (e.g., a module imported at module level).
85 pipeline_options = PipelineOptions(pipeline_args)
86 pipeline_options.view_as(SetupOptions).save_main_session = save_main_session
87 print(f"known args - {known_args}")
88 print(f"pipeline options - {pipeline_options.display_data()}")
89
90 with beam.Pipeline(options=pipeline_options) as p:
91 (
92 p
93 | "ReadInputsFromKafka"
94 >> ReadWordsFromKafka(
95 bootstrap_servers=known_args.bootstrap_servers,
96 topics=[known_args.input_topic],
97 group_id=f"{known_args.output_topic}-group",
98 deprecated_read=known_args.deprecated_read,
99 )
100 | "CalculateMaxWordLength" >> CalculateMaxWordLength()
101 | "CreateMessags" >> CreateMessags()
102 | "WriteOutputsToKafka"
103 >> WriteProcessOutputsToKafka(
104 bootstrap_servers=known_args.bootstrap_servers,
105 topic=known_args.output_topic,
106 deprecated_read=known_args.deprecated_read,
107 )
108 )
109
110 logging.getLogger().setLevel(logging.WARN)
111 logging.info("Building pipeline ...")
112
113
114if __name__ == "__main__":
115 run()
Pipeline Test
The elements are configured so that the lengths of words increase for the first three elements (a, bb, ccc), and the output changes each time. The length of the fourth element (d) is smaller than the previous one, and the output remains the same. Note that the last output is emitted additionally because the watermark is advanced into the end of the global window, and it fires the after watermark trigger. We can create the expected output as a list of TestWindowedValues and compare it with the pipeline output.
1# chapter2/max_word_length_with_ts_test.py
2import unittest
3
4from apache_beam.coders import coders
5from apache_beam.utils.timestamp import Timestamp
6from apache_beam.testing.test_pipeline import TestPipeline
7from apache_beam.testing.util import assert_that, equal_to, TestWindowedValue
8from apache_beam.testing.test_stream import TestStream
9from apache_beam.transforms.window import GlobalWindow, TimestampedValue
10from apache_beam.transforms.util import Reify
11from apache_beam.options.pipeline_options import PipelineOptions, StandardOptions
12
13from max_word_length_with_ts import CalculateMaxWordLength
14
15
16class MaxWordLengthTest(unittest.TestCase):
17 def test_windowing_behaviour(self):
18 options = PipelineOptions()
19 options.view_as(StandardOptions).streaming = True
20 with TestPipeline(options=options) as p:
21 """
22 We should put each element separately. The reason we do this is to ensure
23 that our trigger will be invoked in between each element. Because the trigger
24 invocation is optional, a runner might skip a particular firing. Putting each element
25 separately into addElements makes DirectRunner (our testing runner) invokes a trigger
26 for each input element.
27 """
28 test_stream = (
29 TestStream(coder=coders.StrUtf8Coder())
30 .with_output_types(str)
31 .add_elements([TimestampedValue("a", Timestamp.of(0))])
32 .add_elements([TimestampedValue("bb", Timestamp.of(10))])
33 .add_elements([TimestampedValue("ccc", Timestamp.of(20))])
34 .add_elements([TimestampedValue("d", Timestamp.of(30))])
35 .advance_watermark_to_infinity()
36 )
37
38 output = (
39 p
40 | test_stream
41 | "CalculateMaxWordLength" >> CalculateMaxWordLength()
42 | "ReifyTimestamp" >> Reify.Timestamp()
43 )
44
45 EXPECTED_OUTPUT = [
46 TestWindowedValue(
47 value="a", timestamp=Timestamp(0), windows=[GlobalWindow()]
48 ),
49 TestWindowedValue(
50 value="bb", timestamp=Timestamp(10), windows=[GlobalWindow()]
51 ),
52 TestWindowedValue(
53 value="ccc", timestamp=Timestamp(20), windows=[GlobalWindow()]
54 ),
55 TestWindowedValue(
56 value="ccc", timestamp=Timestamp(30), windows=[GlobalWindow()]
57 ),
58 TestWindowedValue(
59 value="ccc", timestamp=Timestamp(30), windows=[GlobalWindow()]
60 ),
61 ]
62
63 assert_that(output, equal_to(EXPECTED_OUTPUT), reify_windows=True)
64
65
66if __name__ == "__main__":
67 unittest.main()
The pipeline can be tested as shown below.
1python chapter2/max_word_length_test.py -v
2test_windowing_behaviour (__main__.MaxWordLengthTest) ... ok
3
4----------------------------------------------------------------------
5Ran 1 test in 0.446s
6
7OK
Pipeline Execution
Similar to the previous example, we can execute the pipeline by specifying pipeline arguments only while accepting default values of the known arguments (bootstrap_servers, input_topic …). Do not forget to update the /etc/hosts file by adding an entry for host.docker.internal as mentioned earlier.
1## start the beam pipeline
2## exclude --flink_master if using an embedded cluster
3python chapter2/max_word_length_with_ts.py --job_name=max-word-len \
4 --runner FlinkRunner --flink_master=localhost:8081 \
5 --streaming --environment_type=LOOPBACK --parallelism=3 \
6 --checkpointing_interval=10000 --experiment=use_deprecated_read
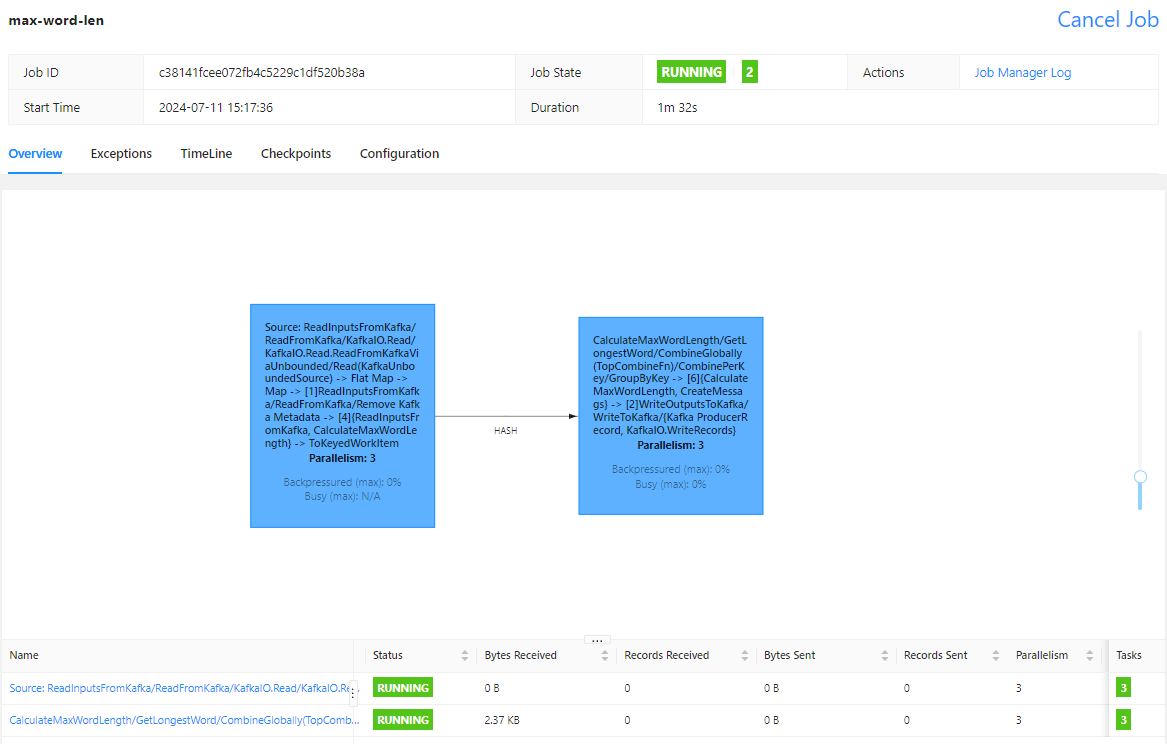
On Flink UI, we see the pipeline polls messages and performs the main transform in multiple tasks while keeping Kafka offset commit as a separate task.
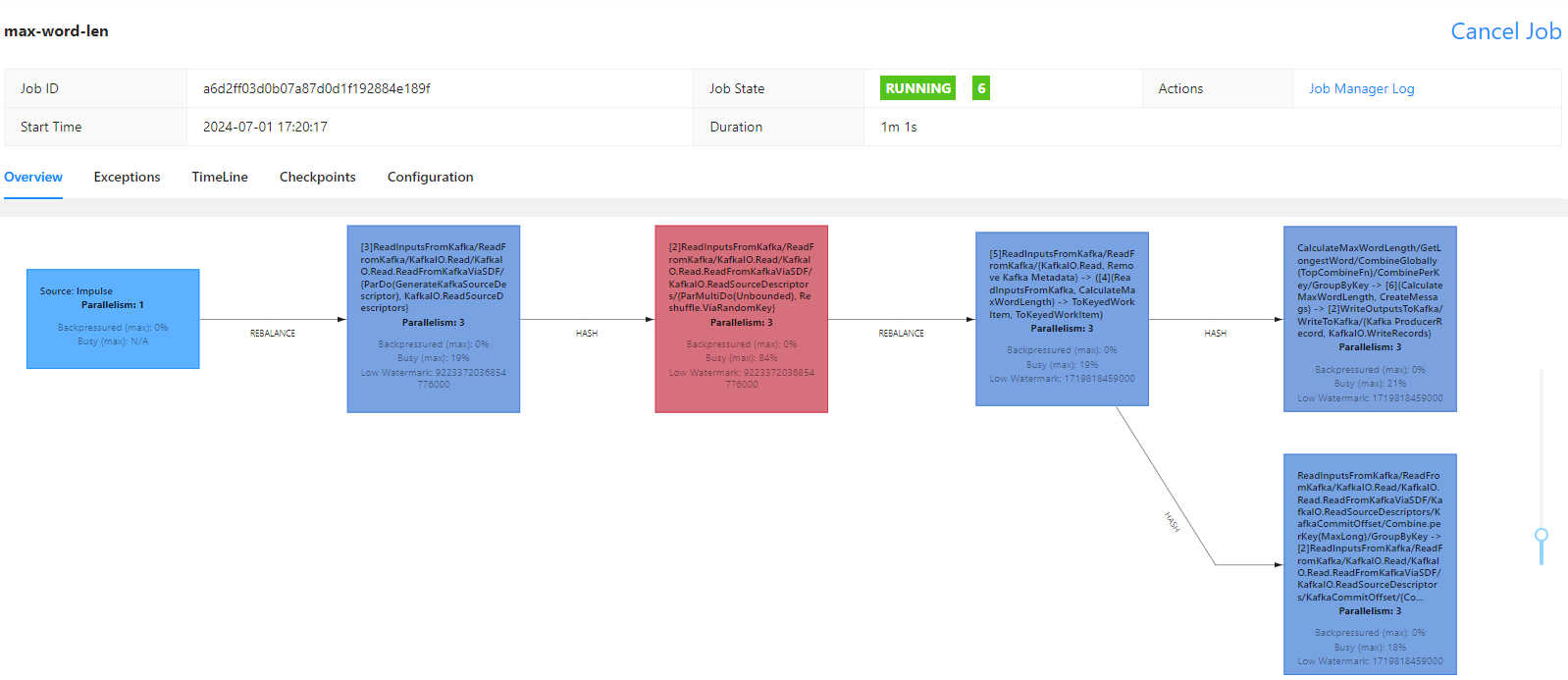
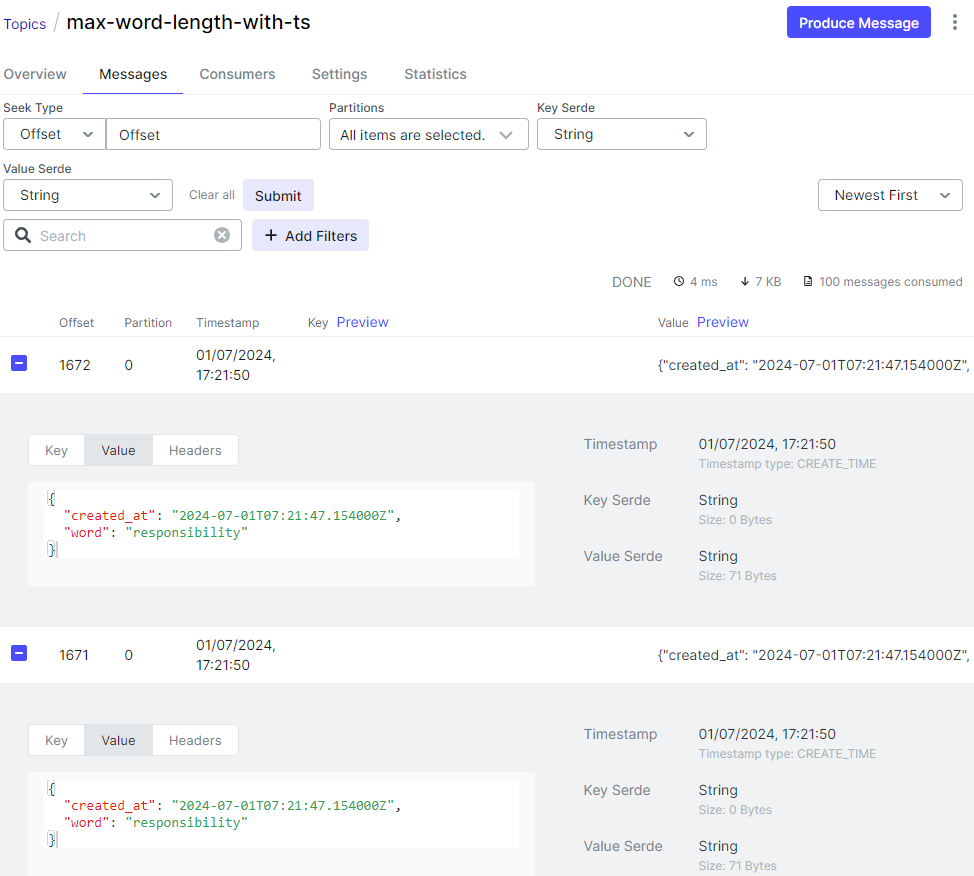
On Kafka UI, we can check the output message includes a longest word as well as its timestamp. Note that, as the input text message has multiple words, we can have multiple output messages that have the same timestamp - recall the accumulation mode is accumulating.
Update on 2024-07-11
The pipeline can be executed to use the legacy read as shown below.
1## exclude --flink_master if using an embedded cluster
2python chapter2/max_word_length_with_ts.py --deprecated_read \
3 --job_name=max-word-len --runner FlinkRunner --flink_master=localhost:8081 \
4 --streaming --environment_type=LOOPBACK --parallelism=3 --checkpointing_interval=10000










Comments