
In the previous post, we started discussing a continuous integration/continuous delivery (CI/CD) process of a dbt project by introducing two GitHub Actions workflows - slim-ci and deploy. The former is triggered when a pull request is created to the main branch, and it builds only modified models and its first-order children in a ci dataset, followed by performing tests on them. The second workflow gets triggered once a pull request is merged. Beginning with running unit tests, it packages the dbt project as a Docker container and publishes to Artifact Registry. In this post, we focus on how to deploy a dbt project in multiple environments while walking through the entire CI/CD process step-by-step.
As the CI process executes tests in multiple phases, it is advised to deploy a new release automatically in lower environments, which supports fast iteration. In higher environments, however, the testing scope is normally beyond what a development team can control. We involve business teams to perform extensive testing using BI tools and a new release can be deployed only if it is signed-off by them. Often it requires a copy of main datasets including changes in a new release. Also, those changes must not be executed in main datasets until it is approved. To meet those requirements, either blue/green deployment or the Write-Audit-Publish (WAP) pattern can be considered. In this post, we employ the WAP pattern because, while blue/green deployment requires changing dataset (or schema) names at the end, BigQuery does not support renaming datasets by default.
DBT Project
We continue using the dbt project for a fictional pizza shop. There are three staging data sets (staging_orders, staging_products, and staging_users), and they are loaded as dbt seeds. Initially the project ends up building two SCD Type 2 dimension tables (dim_products and dim_users) and one fact table (fct_orders) - see this post for more details about data modelling of those tables. The structure of the project is listed below, and the source can be found in the GitHub repository (release-lifecycle branch) of this post.
1pizza_shop
2├── analyses
3├── dbt_project.yml
4├── macros
5├── models
6│ ├── dim
7│ │ ├── dim_products.sql
8│ │ └── dim_users.sql
9│ ├── fct
10│ │ └── fct_orders.sql
11│ ├── schema.yml
12│ ├── sources.yml
13│ ├── src
14│ │ ├── src_orders.sql
15│ │ ├── src_products.sql
16│ │ └── src_users.sql
17│ └── unit_tests.yml
18├── seeds
19│ ├── properties.yml
20│ ├── staging_orders.csv
21│ ├── staging_products.csv
22│ └── staging_users.csv
23├── snapshots
24└── tests
We use four dbt profiles. The dev and prod targets are used to manage the dbt models in the development (dev) and production (prod) environments respectively. As the name suggested, the ci target is used for the CI process. Finally, the target named clone is used to clone the main dataset in the production environment as part of implementing the WAP pattern.
1# dbt_profiles/profiles.yml
2pizza_shop:
3 outputs:
4 dev:
5 type: bigquery
6 method: service-account
7 project: "{{ env_var('GCP_PROJECT_ID') }}"
8 dataset: pizza_shop_dev
9 threads: 4
10 keyfile: "{{ env_var('SA_KEYFILE') }}"
11 job_execution_timeout_seconds: 300
12 job_retries: 1
13 priority: interactive
14 location: australia-southeast1
15 ci:
16 type: bigquery
17 method: service-account
18 project: "{{ env_var('GCP_PROJECT_ID') }}"
19 dataset: "{{ env_var('CI_DATASET') }}"
20 threads: 4
21 keyfile: "{{ env_var('SA_KEYFILE') }}"
22 job_execution_timeout_seconds: 300
23 job_retries: 1
24 priority: interactive
25 location: australia-southeast1
26 prod:
27 type: bigquery
28 method: service-account
29 project: "{{ env_var('GCP_PROJECT_ID') }}"
30 dataset: pizza_shop_prod
31 threads: 4
32 keyfile: "{{ env_var('SA_KEYFILE') }}"
33 job_execution_timeout_seconds: 300
34 job_retries: 1
35 priority: interactive
36 location: australia-southeast1
37 clone:
38 type: bigquery
39 method: service-account
40 project: "{{ env_var('GCP_PROJECT_ID') }}"
41 dataset: pizza_shop_clone
42 threads: 4
43 keyfile: "{{ env_var('SA_KEYFILE') }}"
44 job_execution_timeout_seconds: 300
45 job_retries: 1
46 priority: interactive
47 location: australia-southeast1
48 target: dev
Initial Deployment
We assume that the dbt project is deployed to the dev and prod environments initially. Note that, because each environment associates with its own dataset, the source data (seeds) should be deployed to the own dataset as well. It is achieved by adding a dataset suffix (ds_suffix) to the source schema. In this way, the source data is deployed to pizza_shop_dev and pizza_shop_prod for the dev and prod environments respectively.
1# pizza_shop/models/sources.yml
2version: 2
3
4sources:
5 - name: raw
6 schema: pizza_shop_{{ var ('ds_suffix') }}
7 tables:
8 - name: users
9 identifier: staging_users
10 - name: products
11 identifier: staging_products
12 - name: orders
13 identifier: staging_orders
Initial deployment is identical in each environment. After specifying the desired dbt profile target, we can execute the dbt seed, run and test commands successively. After that, the dbt artifact (manifest.json) is uploaded to the corresponding location in a GCS bucket. Below shows commands that are related to deploying to the dev environment. Note that the artifact is used to perform dbt slim ci as discussed in the previous post.
1## deploy and test in dev
2TARGET=dev
3dbt seed --profiles-dir=dbt_profiles --project-dir=pizza_shop \
4 --target $TARGET --vars "ds_suffix: $TARGET"
5dbt run --profiles-dir=dbt_profiles --project-dir=pizza_shop \
6 --target $TARGET --vars "ds_suffix: $TARGET"
7dbt test --profiles-dir=dbt_profiles --project-dir=pizza_shop \
8 --target $TARGET --vars "ds_suffix: $TARGET"
9
10## upload manifest.json for slim ci
11gsutil --quiet cp pizza_shop/target/manifest.json \
12 gs://dbt-cicd-demo/artifact/$TARGET/manifest.json \
13 && rm -r pizza_shop/target
We can execute the same commands to deploy to the production environment by specifying the prod target. Unlike the dev environment, the artifact of the prod environment is used to clone data from the main dataset and build changes incrementally. The usage of this artifact is illustrated further below.
1## deploy and test in prod
2TARGET=prod
3dbt seed --profiles-dir=dbt_profiles --project-dir=pizza_shop \
4 --target $TARGET --vars "ds_suffix: $TARGET"
5dbt run --profiles-dir=dbt_profiles --project-dir=pizza_shop \
6 --target $TARGET --vars "ds_suffix: $TARGET"
7dbt test --profiles-dir=dbt_profiles --project-dir=pizza_shop \
8 --target $TARGET --vars "ds_suffix: $TARGET"
9
10## upload manifest.json for clone and incremental build
11gsutil --quiet cp pizza_shop/target/manifest.json \
12 gs://dbt-cicd-demo/artifact/$TARGET/manifest.json \
13 && rm -r pizza_shop/target
We can check the project is deployed successfully to both the environments by the following commands.
1bq ls --project_id=$GCP_PROJECT_ID
2# datasetId
3# -----------------
4# pizza_shop_dev
5# pizza_shop_prod
6
7gsutil ls -r gs://dbt-cicd-demo/artifact
8# gs://dbt-cicd-demo/artifact/:
9
10# gs://dbt-cicd-demo/artifact/dev/:
11# gs://dbt-cicd-demo/artifact/dev/manifest.json
12
13# gs://dbt-cicd-demo/artifact/prod/:
14# gs://dbt-cicd-demo/artifact/prod/manifest.json
Continuous Integration
To illustrate a feature release scenario, we add a new incremental model named fct_top_customers, and it collects top 10 customers who spend the most in a day.
1{{
2 config(
3 materialized = 'incremental'
4 )
5}}
6WITH cte_items_expanced AS (
7 SELECT
8 user.id AS user_id,
9 user.first_name,
10 user.last_name,
11 p.quantity AS quantity,
12 p.price AS price
13 FROM {{ ref('fct_orders') }} AS o
14 CROSS JOIN UNNEST(product) AS p
15 WHERE _PARTITIONTIME = (SELECT max(_PARTITIONTIME) FROM {{ ref('fct_orders') }})
16)
17SELECT
18 user_id,
19 first_name,
20 last_name,
21 sum(quantity) AS total_quantity,
22 sum(price) AS total_price
23FROM cte_items_expanced
24GROUP BY user_id, first_name, last_name
25ORDER BY sum(price) DESC
26LIMIT 10
The model has an associated schema. Among the schema attributes, we are particularly interested in the two test cases, which determines if the new model is good to be deployed. In reality, we would have more tests, but we assume those are sufficient.
1version: 2
2
3models:
4 - name: fct_top_customers
5 tests:
6 - dbt_utils.expression_is_true:
7 expression: "total_quantity >= 0"
8 - dbt_utils.expression_is_true:
9 expression: "total_price >= 0"
10 columns:
11 - name: user_id
12 description: Natural key of users
13 - name: first_name
14 description: First name
15 - name: last_name
16 description: Last name
17 - name: total_quantity
18 description: Total quantity purchased by user
19 - name: total_price
20 description: Total price spent by user
We can add the new model as shown below.
1cp -r extra_models/fct_top* pizza_shop/models/fct
2
3tree pizza_shop/models/fct/
4# pizza_shop/models/fct/
5# ├── fct_orders.sql
6# ├── fct_top_customers.sql
7# └── fct_top_customers.yml
8
9# 1 directory, 3 files
DBT Slim CI
Assuming a pull request is made to the main branch, we can go through dbt slim ci, which is the first step of the CI process. Thanks to the defer feature and state method, it saves time and computational resources for testing only relevant models in a dbt project. As expected, the dbt execution log shows the new model is built in the ci dataset and the associated two test cases are executed successfully.
1TARGET=ci
2export CI_DATASET=ci_$(date +'%y%m%d')
3
4gsutil --quiet cp gs://dbt-cicd-demo/artifact/dev/manifest.json manifest.json
5
6dbt build --profiles-dir=dbt_profiles --project-dir=pizza_shop --target $TARGET \
7 --select state:modified+ --defer --state $PWD --vars 'ds_suffix: dev'
8
9# 09:30:50 Running with dbt=1.8.6
10# 09:30:50 Registered adapter: bigquery=1.8.2
11# 09:30:50 Unable to do partial parsing because saved manifest not found. Starting full parse.
12# 09:30:52 [WARNING]: Deprecated functionality
13# The `tests` config has been renamed to `data_tests`. Please see
14# https://docs.getdbt.com/docs/build/data-tests#new-data_tests-syntax for more
15# information.
16# 09:30:52 Found 7 models, 3 seeds, 6 data tests, 3 sources, 587 macros, 1 unit test
17# 09:30:52 Found a seed (pizza_shop.staging_orders) >1MB in size at the same path, dbt cannot tell if it has changed: assuming they are the same
18# 09:30:52 Found a seed (pizza_shop.staging_users) >1MB in size at the same path, dbt cannot tell if it has changed: assuming they are the same
19# 09:30:52 Found a seed (pizza_shop.staging_orders) >1MB in size at the same path, dbt cannot tell if it has changed: assuming they are the same
20# 09:30:52 Found a seed (pizza_shop.staging_users) >1MB in size at the same path, dbt cannot tell if it has changed: assuming they are the same
21# 09:30:52 Found a seed (pizza_shop.staging_orders) >1MB in size at the same path, dbt cannot tell if it has changed: assuming they are the same
22# 09:30:52 Found a seed (pizza_shop.staging_users) >1MB in size at the same path, dbt cannot tell if it has changed: assuming they are the same
23# 09:30:52
24# 09:30:57 Concurrency: 4 threads (target='ci')
25# 09:30:57
26# 09:30:57 1 of 3 START sql incremental model ci_240910.fct_top_customers ................. [RUN]
27# 09:31:00 1 of 3 OK created sql incremental model ci_240910.fct_top_customers ............ [CREATE TABLE (10.0 rows, 2.1 MiB processed) in 2.78s]
28# 09:31:00 2 of 3 START test dbt_utils_expression_is_true_fct_top_customers_total_price_0 . [RUN]
29# 09:31:00 3 of 3 START test dbt_utils_expression_is_true_fct_top_customers_total_quantity_0 [RUN]
30# 09:31:01 3 of 3 PASS dbt_utils_expression_is_true_fct_top_customers_total_quantity_0 .... [PASS in 1.24s]
31# 09:31:01 2 of 3 PASS dbt_utils_expression_is_true_fct_top_customers_total_price_0 ....... [PASS in 1.62s]
32# 09:31:01
33# 09:31:01 Finished running 1 incremental model, 2 data tests in 0 hours 0 minutes and 8.94 seconds (8.94s).
34# 09:31:01
35# 09:31:01 Completed successfully
36# 09:31:01
37# 09:31:01 Done. PASS=3 WARN=0 ERROR=0 SKIP=0 TOTAL=3
We can see a table named fct_top_customers is created in the ci dataset on BigQuery Console.
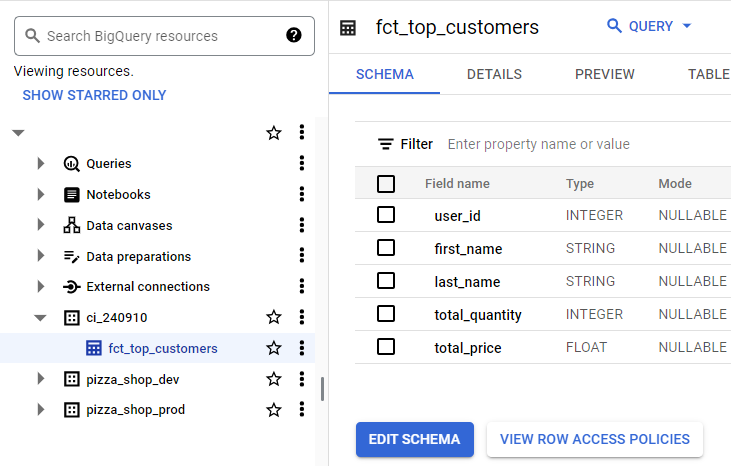
To complete dbt slim ci, the ci dataset can be deleted by executing the bq rm command.
1bq rm -r -f $CI_DATASET
DBT Unit Tests
Now we assume the pull request is merged. In the earlier step, dbt slim ci tests only those that are associated with modified models, and nothing is tested on existing models. Therefore, it is important to validate key SQL modelling logic across all models, and it is achieved by performing unit tests. To do so, we first need to create relevant models in a ci dataset. In the current project, we have a single unit testing case on the dim_users model and the src_users model is used as an input. This results in those models are created in a ci dataset if we set the selector value to +test_type:unit.
1TARGET=ci
2export CI_DATASET=ut_$(date +'%y%m%d')
3
4# build all the models that the unit tests need to run, but empty
5dbt run --profiles-dir=dbt_profiles --project-dir=pizza_shop --target $TARGET \
6 --select +test_type:unit --empty
7
8# 09:34:21 Running with dbt=1.8.6
9# 09:34:21 Registered adapter: bigquery=1.8.2
10# 09:34:22 Unable to do partial parsing because config vars, config profile, or config target have changed
11# 09:34:22 Unable to do partial parsing because profile has changed
12# 09:34:23 [WARNING]: Deprecated functionality
13# The `tests` config has been renamed to `data_tests`. Please see
14# https://docs.getdbt.com/docs/build/data-tests#new-data_tests-syntax for more
15# information.
16# 09:34:23 Found 7 models, 3 seeds, 6 data tests, 3 sources, 587 macros, 1 unit test
17# 09:34:23
18# 09:34:28 Concurrency: 4 threads (target='ci')
19# 09:34:28
20# 09:34:28 1 of 2 START sql view model ut_240910.src_users ................................ [RUN]
21# 09:34:29 1 of 2 OK created sql view model ut_240910.src_users ........................... [CREATE VIEW (0 processed) in 1.19s]
22# 09:34:29 2 of 2 START sql table model ut_240910.dim_users ............................... [RUN]
23# 09:34:32 2 of 2 OK created sql table model ut_240910.dim_users .......................... [CREATE TABLE (0.0 rows, 0 processed) in 3.12s]
24# 09:34:32
25# 09:34:32 Finished running 1 view model, 1 table model in 0 hours 0 minutes and 8.67 seconds (8.67s).
26# 09:34:32
27# 09:34:32 Completed successfully
28# 09:34:32
29# 09:34:32 Done. PASS=2 WARN=0 ERROR=0 SKIP=0 TOTAL=2
We can use the dbt test command with the same selector value to perform unit testing. As expected, only the single unit testing case is executed successfully.
1# do the actual unit tests
2dbt test --profiles-dir=dbt_profiles --project-dir=pizza_shop --target $TARGET \
3 --select test_type:unit
4
5# 09:04:48 Running with dbt=1.8.6
6# 09:04:49 Registered adapter: bigquery=1.8.2
7# 09:04:49 Found 7 models, 3 seeds, 4 data tests, 3 sources, 587 macros, 1 unit test
8# 09:04:49
9# 09:04:50 Concurrency: 4 threads (target='ci')
10# 09:04:50
11# 09:04:50 1 of 1 START unit_test dim_users::test_is_valid_date_ranges .................... [RUN]
12# 09:04:56 1 of 1 PASS dim_users::test_is_valid_date_ranges ............................... [PASS in 5.15s]
13# 09:04:56
14# 09:04:56 Finished running 1 unit test in 0 hours 0 minutes and 6.07 seconds (6.07s).
15# 09:04:56
16# 09:04:56 Completed successfully
17# 09:04:56
18# 09:04:56 Done. PASS=1 WARN=0 ERROR=0 SKIP=0 TOTAL=1
We can see the tables for the two models are created on BigQuery Console. Note that, as we executed the dbt run command with the --empty flag, the tables do not have records.
Same to dbt slim ci, the ci dataset can be deleted as shown below.
1bq rm -r -f $CI_DATASET
Continuous Delivery
For CD, deployment of a new release is made automatically in lower environments while the Write-Audit-Publish pattern is applied in higher environments.
Automatic Deployment
As the CI process executes tests in multiple phases, we assume the release is deployed to the dev environment automatically, and it can be done so by executing the following command.
1TARGET=dev
2dbt run --profiles-dir=dbt_profiles --project-dir=pizza_shop --target $TARGET \
3 --vars "ds_suffix: $TARGET"
4
5# 09:37:34 Running with dbt=1.8.6
6# 09:37:34 Registered adapter: bigquery=1.8.2
7# 09:37:34 Unable to do partial parsing because config vars, config profile, or config target have changed
8# 09:37:34 Unable to do partial parsing because profile has changed
9# 09:37:36 [WARNING]: Deprecated functionality
10# The `tests` config has been renamed to `data_tests`. Please see
11# https://docs.getdbt.com/docs/build/data-tests#new-data_tests-syntax for more
12# information.
13# 09:37:36 Found 7 models, 3 seeds, 6 data tests, 3 sources, 587 macros, 1 unit test
14# 09:37:36
15# 09:37:38 Concurrency: 4 threads (target='dev')
16# 09:37:38
17# 09:37:38 1 of 7 START sql view model pizza_shop_dev.src_orders .......................... [RUN]
18# 09:37:38 2 of 7 START sql view model pizza_shop_dev.src_products ........................ [RUN]
19# 09:37:38 3 of 7 START sql view model pizza_shop_dev.src_users ........................... [RUN]
20# 09:37:39 2 of 7 OK created sql view model pizza_shop_dev.src_products ................... [CREATE VIEW (0 processed) in 1.08s]
21# 09:37:39 4 of 7 START sql table model pizza_shop_dev.dim_products ....................... [RUN]
22# 09:37:39 3 of 7 OK created sql view model pizza_shop_dev.src_users ...................... [CREATE VIEW (0 processed) in 1.14s]
23# 09:37:39 5 of 7 START sql table model pizza_shop_dev.dim_users .......................... [RUN]
24# 09:37:39 1 of 7 OK created sql view model pizza_shop_dev.src_orders ..................... [CREATE VIEW (0 processed) in 1.64s]
25# 09:37:42 4 of 7 OK created sql table model pizza_shop_dev.dim_products .................. [CREATE TABLE (81.0 rows, 13.7 KiB processed) in 2.83s]
26# 09:37:42 5 of 7 OK created sql table model pizza_shop_dev.dim_users ..................... [CREATE TABLE (10.0k rows, 880.9 KiB processed) in 2.88s]
27# 09:37:42 6 of 7 START sql incremental model pizza_shop_dev.fct_orders ................... [RUN]
28# 09:37:46 6 of 7 OK created sql incremental model pizza_shop_dev.fct_orders .............. [MERGE (20.0k rows, 5.1 MiB processed) in 4.60s]
29# 09:37:46 7 of 7 START sql incremental model pizza_shop_dev.fct_top_customers ............ [RUN]
30# 09:37:48 7 of 7 OK created sql incremental model pizza_shop_dev.fct_top_customers ....... [CREATE TABLE (10.0 rows, 4.1 MiB processed) in 2.23s]
31# 09:37:48
32# 09:37:48 Finished running 3 view models, 2 table models, 2 incremental models in 0 hours 0 minutes and 12.21 seconds (12.21s).
33# 09:37:49
34# 09:37:49 Completed successfully
35# 09:37:49
36# 09:37:49 Done. PASS=7 WARN=0 ERROR=0 SKIP=0 TOTAL=7
Nonetheless, it is recommended to perform tests and potentially send the output to where the development team can access.
1dbt test --profiles-dir=dbt_profiles --project-dir=pizza_shop --target $TARGET \
2 --vars "ds_suffix: $TARGET"
3
4# 09:38:23 Running with dbt=1.8.6
5# 09:38:23 Registered adapter: bigquery=1.8.2
6# 09:38:24 Found 7 models, 3 seeds, 6 data tests, 3 sources, 587 macros, 1 unit test
7# 09:38:24
8# 09:38:24 Concurrency: 4 threads (target='dev')
9# 09:38:24
10# 09:38:24 1 of 7 START test dbt_utils_expression_is_true_fct_top_customers_total_price_0 . [RUN]
11# 09:38:24 2 of 7 START test dbt_utils_expression_is_true_fct_top_customers_total_quantity_0 [RUN]
12# 09:38:24 3 of 7 START test not_null_dim_products_product_key ............................ [RUN]
13# 09:38:24 4 of 7 START test not_null_dim_users_user_key .................................. [RUN]
14# 09:38:26 4 of 7 PASS not_null_dim_users_user_key ........................................ [PASS in 1.20s]
15# 09:38:26 5 of 7 START test unique_dim_products_product_key .............................. [RUN]
16# 09:38:26 1 of 7 PASS dbt_utils_expression_is_true_fct_top_customers_total_price_0 ....... [PASS in 1.20s]
17# 09:38:26 3 of 7 PASS not_null_dim_products_product_key .................................. [PASS in 1.22s]
18# 09:38:26 6 of 7 START test unique_dim_users_user_key .................................... [RUN]
19# 09:38:26 7 of 7 START unit_test dim_users::test_is_valid_date_ranges .................... [RUN]
20# 09:38:26 2 of 7 PASS dbt_utils_expression_is_true_fct_top_customers_total_quantity_0 .... [PASS in 1.27s]
21# 09:38:27 5 of 7 PASS unique_dim_products_product_key .................................... [PASS in 1.24s]
22# 09:38:27 6 of 7 PASS unique_dim_users_user_key .......................................... [PASS in 1.30s]
23# 09:38:30 7 of 7 PASS dim_users::test_is_valid_date_ranges ............................... [PASS in 4.16s]
24# 09:38:30
25# 09:38:30 Finished running 6 data tests, 1 unit test in 0 hours 0 minutes and 5.99 seconds (5.99s).
26# 09:38:30
27# 09:38:30 Completed successfully
28# 09:38:30
29# 09:38:30 Done. PASS=7 WARN=0 ERROR=0 SKIP=0 TOTAL=7
Finally, do not forget to upload the latest dbt artifact because it is used by dbt slim ci.
1gsutil --quiet cp pizza_shop/target/manifest.json gs://dbt-cicd-demo/artifact/$TARGET/manifest.json \
2 && rm -r pizza_shop/target
Write-Audit-Publish
As mentioned, there are two key requirements for deploying to higher environments (e.g. prod). First, we include business teams to perform extensive tests using BI tools, and it requires a copy of main datasets including changes in a new release. Secondly, those changes must not be executed in main datasets until it is approved. To meet those requirements, either blue/green deployment or the Write-Audit-Publish (WAP) pattern can be considered. Basically, both of them utilise the dbt clone feature, which clones selected nodes of main datasets from a specified state to audit datasets. Specifically, we can use the latest dbt artifact for cloning main datasets as well as build incrementally for all new models and any changes to existing models on audit datasets. Then, testing can be performed on audit datasets, which meets both the requirements. Note that, as BigQuery supports zero-copy table clones, it is a lightweight and cost-effective way of testing.
When it comes to selecting a deployment strategy, the WAP pattern is more applicable on BigQuery because, while blue/green deployment requires changing dataset (or schema) names at the end, BigQuery does not support renaming datasets by default. Note that, instead of publishing audited datasets to main datasets as the WAP pattern proposes, we follow typical dbt deployment steps (i.e. dbt run and dbt test) once a new release gets signed-off. This is because it is not straightforward to publish only those that are associated with changes in a new release.
Test on Cloned Dataset
We first download the latest dbt artifact of the prod environment. Then, we clone the main dataset into the audit (clone) dataset using the artifact as a state. By specifying --full-refresh, all existing models from the latest state are cloned into the audit dataset as well as all pre-existing relations are recreated there. Note that, as the new model (fct_top_customers) is not included in the latest state, the audit dataset misses the table for it.
1TARGET=clone
2
3gsutil --quiet cp gs://dbt-cicd-demo/artifact/prod/manifest.json manifest.json
4
5dbt clone --profiles-dir=dbt_profiles --project-dir=pizza_shop \
6 --target $TARGET --full-refresh --state $PWD --vars "ds_suffix: $TARGET"
7
8# 09:40:16 Running with dbt=1.8.6
9# 09:40:16 Registered adapter: bigquery=1.8.2
10# 09:40:16 Unable to do partial parsing because saved manifest not found. Starting full parse.
11# 09:40:18 [WARNING]: Deprecated functionality
12# The `tests` config has been renamed to `data_tests`. Please see
13# https://docs.getdbt.com/docs/build/data-tests#new-data_tests-syntax for more
14# information.
15# 09:40:18 Found 7 models, 3 seeds, 6 data tests, 3 sources, 587 macros, 1 unit test
16# 09:40:18
17# 09:40:22 Concurrency: 4 threads (target='clone')
18# 09:40:22
19# 09:40:28 No relation found in state manifest for model.pizza_shop.fct_top_customers
20# 09:40:28
21# 09:40:28 Completed successfully
22# 09:40:28
23# 09:40:28 Done. PASS=10 WARN=0 ERROR=0 SKIP=0 TOTAL=10
To include the table for the new model, we execute the dbt run command to build incrementally by specifying --select state:modified. We see the new table is created in the audit dataset as expected.
1dbt run --profiles-dir=dbt_profiles --project-dir=pizza_shop --target $TARGET \
2 --select state:modified --state $PWD --vars "ds_suffix: $TARGET"
3
4# 09:40:52 Running with dbt=1.8.6
5# 09:40:53 Registered adapter: bigquery=1.8.2
6# 09:40:53 Unable to do partial parsing because config vars, config profile, or config target have changed
7# 09:40:54 [WARNING]: Deprecated functionality
8# The `tests` config has been renamed to `data_tests`. Please see
9# https://docs.getdbt.com/docs/build/data-tests#new-data_tests-syntax for more
10# information.
11# 09:40:55 Found 7 models, 3 seeds, 6 data tests, 3 sources, 587 macros, 1 unit test
12# 09:40:55 Found a seed (pizza_shop.staging_orders) >1MB in size at the same path, dbt cannot tell if it has changed: assuming they are the same
13# 09:40:55 Found a seed (pizza_shop.staging_users) >1MB in size at the same path, dbt cannot tell if it has changed: assuming they are the same
14# 09:40:55
15# 09:40:56 Concurrency: 4 threads (target='clone')
16# 09:40:56
17# 09:40:56 1 of 1 START sql incremental model pizza_shop_clone.fct_top_customers .......... [RUN]
18# 09:40:59 1 of 1 OK created sql incremental model pizza_shop_clone.fct_top_customers ..... [CREATE TABLE (10.0 rows, 2.1 MiB processed) in 2.55s]
19# 09:40:59
20# 09:40:59 Finished running 1 incremental model in 0 hours 0 minutes and 3.92 seconds (3.92s).
21# 09:40:59
22# 09:40:59 Completed successfully
23# 09:40:59
24# 09:40:59 Done. PASS=1 WARN=0 ERROR=0 SKIP=0 TOTAL=1
Once the audit dataset includes all required models and relations, we can perform tests on it. A total of seven test cases are executed successfully and two of them are associated with the new model. In practice, business teams perform further tests using BI tools on this dataset, and determine whether the release can be signed-off or not.
1dbt test --profiles-dir=dbt_profiles --project-dir=pizza_shop --target $TARGET \
2 --vars "ds_suffix: $TARGET"
3
4# 09:41:23 Running with dbt=1.8.6
5# 09:41:23 Registered adapter: bigquery=1.8.2
6# 09:41:23 Unable to do partial parsing because config vars, config profile, or config target have changed
7# 09:41:25 [WARNING]: Deprecated functionality
8# The `tests` config has been renamed to `data_tests`. Please see
9# https://docs.getdbt.com/docs/build/data-tests#new-data_tests-syntax for more
10# information.
11# 09:41:25 Found 7 models, 3 seeds, 6 data tests, 3 sources, 587 macros, 1 unit test
12# 09:41:25
13# 09:41:26 Concurrency: 4 threads (target='clone')
14# 09:41:26
15# 09:41:26 1 of 7 START test dbt_utils_expression_is_true_fct_top_customers_total_price_0 . [RUN]
16# 09:41:26 2 of 7 START test dbt_utils_expression_is_true_fct_top_customers_total_quantity_0 [RUN]
17# 09:41:26 3 of 7 START test not_null_dim_products_product_key ............................ [RUN]
18# 09:41:26 4 of 7 START test not_null_dim_users_user_key .................................. [RUN]
19# 09:41:27 3 of 7 PASS not_null_dim_products_product_key .................................. [PASS in 1.22s]
20# 09:41:27 2 of 7 PASS dbt_utils_expression_is_true_fct_top_customers_total_quantity_0 .... [PASS in 1.22s]
21# 09:41:27 5 of 7 START test unique_dim_products_product_key .............................. [RUN]
22# 09:41:27 1 of 7 PASS dbt_utils_expression_is_true_fct_top_customers_total_price_0 ....... [PASS in 1.23s]
23# 09:41:27 6 of 7 START test unique_dim_users_user_key .................................... [RUN]
24# 09:41:27 7 of 7 START unit_test dim_users::test_is_valid_date_ranges .................... [RUN]
25# 09:41:27 4 of 7 PASS not_null_dim_users_user_key ........................................ [PASS in 1.25s]
26# 09:41:28 6 of 7 PASS unique_dim_users_user_key .......................................... [PASS in 1.18s]
27# 09:41:28 5 of 7 PASS unique_dim_products_product_key .................................... [PASS in 1.23s]
28# 09:41:31 7 of 7 PASS dim_users::test_is_valid_date_ranges ............................... [PASS in 3.54s]
29# 09:41:31
30# 09:41:31 Finished running 6 data tests, 1 unit test in 0 hours 0 minutes and 5.35 seconds (5.35s).
31# 09:41:31
32# 09:41:31 Completed successfully
33# 09:41:31
34# 09:41:31 Done. PASS=7 WARN=0 ERROR=0 SKIP=0 TOTAL=7
On BigQuery Console, we see the audit dataset includes the table for the new model while the prod datasets misses it.
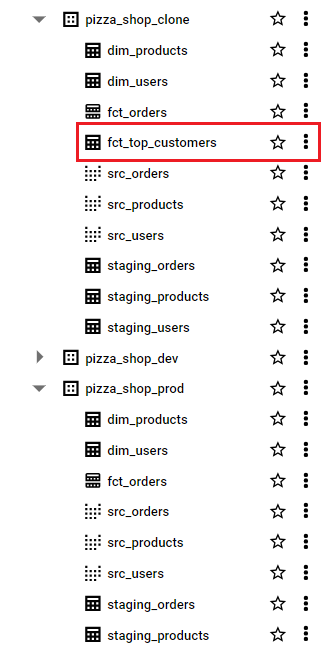
To complete testing, we can delete the audit dataset as shown below.
1bq rm -r -f "pizza_shop_$TARGET"
Deploy to Main Dataset
Assuming the release is approved, we deploy it to the prod environment by following typical dbt deployment steps. We first execute the dbt run command, and the execution log shows the new model is created.
1TARGET=prod
2dbt run --profiles-dir=dbt_profiles --project-dir=pizza_shop --target $TARGET --vars "ds_suffix: $TARGET"
3
4# 09:44:22 Running with dbt=1.8.6
5# 09:44:22 Registered adapter: bigquery=1.8.2
6# 09:44:23 Unable to do partial parsing because config vars, config profile, or config target have changed
7# 09:44:23 Unable to do partial parsing because profile has changed
8# 09:44:24 [WARNING]: Deprecated functionality
9# The `tests` config has been renamed to `data_tests`. Please see
10# https://docs.getdbt.com/docs/build/data-tests#new-data_tests-syntax for more
11# information.
12# 09:44:25 Found 7 models, 3 seeds, 6 data tests, 3 sources, 587 macros, 1 unit test
13# 09:44:25
14# 09:44:26 Concurrency: 4 threads (target='prod')
15# 09:44:26
16# 09:44:26 1 of 7 START sql view model pizza_shop_prod.src_orders ......................... [RUN]
17# 09:44:26 2 of 7 START sql view model pizza_shop_prod.src_products ....................... [RUN]
18# 09:44:26 3 of 7 START sql view model pizza_shop_prod.src_users .......................... [RUN]
19# 09:44:27 1 of 7 OK created sql view model pizza_shop_prod.src_orders .................... [CREATE VIEW (0 processed) in 1.17s]
20# 09:44:27 3 of 7 OK created sql view model pizza_shop_prod.src_users ..................... [CREATE VIEW (0 processed) in 1.17s]
21# 09:44:27 4 of 7 START sql table model pizza_shop_prod.dim_users ......................... [RUN]
22# 09:44:27 2 of 7 OK created sql view model pizza_shop_prod.src_products .................. [CREATE VIEW (0 processed) in 1.19s]
23# 09:44:27 5 of 7 START sql table model pizza_shop_prod.dim_products ...................... [RUN]
24# 09:44:30 5 of 7 OK created sql table model pizza_shop_prod.dim_products ................. [CREATE TABLE (81.0 rows, 13.7 KiB processed) in 2.66s]
25# 09:44:30 4 of 7 OK created sql table model pizza_shop_prod.dim_users .................... [CREATE TABLE (10.0k rows, 880.9 KiB processed) in 3.23s]
26# 09:44:30 6 of 7 START sql incremental model pizza_shop_prod.fct_orders .................. [RUN]
27# 09:44:35 6 of 7 OK created sql incremental model pizza_shop_prod.fct_orders ............. [MERGE (20.0k rows, 5.1 MiB processed) in 4.78s]
28# 09:44:35 7 of 7 START sql incremental model pizza_shop_prod.fct_top_customers ........... [RUN]
29# 09:44:37 7 of 7 OK created sql incremental model pizza_shop_prod.fct_top_customers ...... [CREATE TABLE (10.0 rows, 4.1 MiB processed) in 2.43s]
30# 09:44:38
31# 09:44:38 Finished running 3 view models, 2 table models, 2 incremental models in 0 hours 0 minutes and 12.90 seconds (12.90s).
32# 09:44:38
33# 09:44:38 Completed successfully
34# 09:44:38
35# 09:44:38 Done. PASS=7 WARN=0 ERROR=0 SKIP=0 TOTAL=7
By executing the dbt test command, we see all the seven testing cases are executed successfully.
1dbt test --profiles-dir=dbt_profiles --project-dir=pizza_shop --target $TARGET --vars "ds_suffix: $TARGET"
2
3# 09:45:08 Running with dbt=1.8.6
4# 09:45:08 Registered adapter: bigquery=1.8.2
5# 09:45:09 Found 7 models, 3 seeds, 6 data tests, 3 sources, 587 macros, 1 unit test
6# 09:45:09
7# 09:45:09 Concurrency: 4 threads (target='prod')
8# 09:45:09
9# 09:45:09 1 of 7 START test dbt_utils_expression_is_true_fct_top_customers_total_price_0 . [RUN]
10# 09:45:09 2 of 7 START test dbt_utils_expression_is_true_fct_top_customers_total_quantity_0 [RUN]
11# 09:45:09 3 of 7 START test not_null_dim_products_product_key ............................ [RUN]
12# 09:45:09 4 of 7 START test not_null_dim_users_user_key .................................. [RUN]
13# 09:45:10 3 of 7 PASS not_null_dim_products_product_key .................................. [PASS in 1.18s]
14# 09:45:10 5 of 7 START test unique_dim_products_product_key .............................. [RUN]
15# 09:45:10 4 of 7 PASS not_null_dim_users_user_key ........................................ [PASS in 1.29s]
16# 09:45:10 6 of 7 START test unique_dim_users_user_key .................................... [RUN]
17# 09:45:10 2 of 7 PASS dbt_utils_expression_is_true_fct_top_customers_total_quantity_0 .... [PASS in 1.31s]
18# 09:45:10 1 of 7 PASS dbt_utils_expression_is_true_fct_top_customers_total_price_0 ....... [PASS in 1.34s]
19# 09:45:11 7 of 7 START unit_test dim_users::test_is_valid_date_ranges .................... [RUN]
20# 09:45:12 5 of 7 PASS unique_dim_products_product_key .................................... [PASS in 1.23s]
21# 09:45:12 6 of 7 PASS unique_dim_users_user_key .......................................... [PASS in 1.37s]
22# 09:45:14 7 of 7 PASS dim_users::test_is_valid_date_ranges ............................... [PASS in 3.38s]
23# 09:45:14
24# 09:45:14 Finished running 6 data tests, 1 unit test in 0 hours 0 minutes and 5.23 seconds (5.23s).
25# 09:45:14
26# 09:45:14 Completed successfully
27# 09:45:14
28# 09:45:14 Done. PASS=7 WARN=0 ERROR=0 SKIP=0 TOTAL=7
Now we can see the table for the new model is created on BigQuery Console.
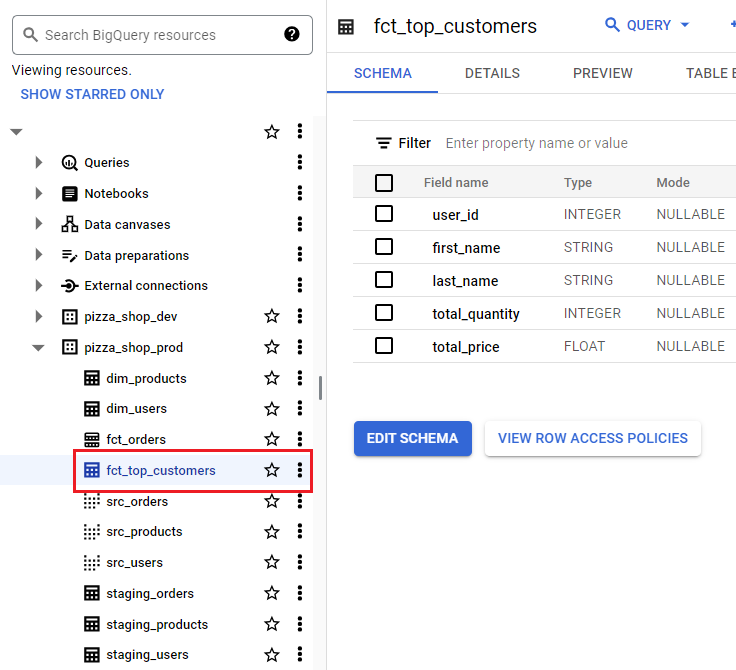
Finally, do not forget to upload the latest artifacts to be used for subsequent deployment.
1gsutil --quiet cp pizza_shop/target/manifest.json gs://dbt-cicd-demo/artifact/$TARGET/manifest.json \
2 && rm -rf pizza_shop/target










Comments