
In the previous post, we continued discussing an Apache Beam pipeline that arguments input data by calling a Remote Procedure Call (RPC) service. A pipeline was developed that makes a single RPC call for a bundle of elements. The bundle size is determined by the runner, however, we may encounter an issue e.g. if an RPC service becomes quite slower if many elements are included in a single request. We can improve the pipeline using stateful DoFn where the number elements to process and maximum wait seconds can be controlled by state and timers. Note that, although the stateful DoFn used in this post solves the data augmentation task well, in practice, we should use the built-in transforms such as BatchElements and GroupIntoBatches whenever possible.
- Part 1 Calculate K Most Frequent Words and Max Word Length
- Part 2 Calculate Average Word Length with/without Fixed Look back
- Part 3 Build Sport Activity Tracker with/without SQL
- Part 4 Call RPC Service for Data Augmentation
- Part 5 Call RPC Service in Batch using Stateless DoFn
- Part 6 Call RPC Service in Batch with Defined Batch Size using Stateful DoFn (this post)
- Part 7 Separate Droppable Data into Side Output
- Part 8 Enhance Sport Activity Tracker with Runner Motivation
- Part 9 Develop Batch File Reader and PiSampler using Splittable DoFn
- Part 10 Develop Streaming File Reader using Splittable DoFn
Development Environment
The development environment has an Apache Flink cluster, Apache Kafka cluster and gRPC server. For Flink, we can use either an embedded cluster or a local cluster while Docker Compose is used for the rest. See Part 1 for details about how to set up the development environment. The source of this post can be found in this GitHub repository.
Manage Environment
The Flink and Kafka clusters and gRPC server are managed by the following bash scripts.
./setup/start-flink-env.sh./setup/stop-flink-env.sh
Those scripts accept four flags: -f, -k and -g to start/stop individual resources or -a to manage all of them. We can add multiple flags to start/stop relevant resources. Note that the scripts assume Flink 1.18.1 by default, and we can specify a specific Flink version if it is different from it e.g. FLINK_VERSION=1.17.2 ./setup/start-flink-env.sh.
Below shows how to start resources using the start-up script. We need to launch both the Flink/Kafka clusters and gRPC server if we deploy a Beam pipeline on a local Flink cluster. Otherwise, we can start the Kafka cluster and gRPC server only.
1## start a local flink can kafka cluster
2./setup/start-flink-env.sh -f -k -g
3# [+] Running 6/6
4# ⠿ Network app-network Created 0.0s
5# ⠿ Volume "kafka_0_data" Created 0.0s
6# ⠿ Volume "zookeeper_data" Created 0.0s
7# ⠿ Container zookeeper Started 0.5s
8# ⠿ Container kafka-0 Started 0.7s
9# ⠿ Container kafka-ui Started 0.9s
10# [+] Running 2/2
11# ⠿ Network grpc-network Created 0.0s
12# ⠿ Container grpc-server Started 0.4s
13# start flink 1.18.1...
14# Starting cluster.
15# Starting standalonesession daemon on host <hostname>.
16# Starting taskexecutor daemon on host <hostname>.
17
18## start a local kafka cluster only
19./setup/start-flink-env.sh -k -g
20# [+] Running 6/6
21# ⠿ Network app-network Created 0.0s
22# ⠿ Volume "kafka_0_data" Created 0.0s
23# ⠿ Volume "zookeeper_data" Created 0.0s
24# ⠿ Container zookeeper Started 0.5s
25# ⠿ Container kafka-0 Started 0.7s
26# ⠿ Container kafka-ui Started 0.9s
27# [+] Running 2/2
28# ⠿ Network grpc-network Created 0.0s
29# ⠿ Container grpc-server Started 0.4s
Remote Procedure Call (RPC) Service
The RPC service have two methods - resolve and resolveBatch. The former accepts a request with a string and returns an integer while the latter accepts a list of string requests and returns a list of integer responses. See Part 4 for details about how the RPC service is developed.
Overall, we have the following files for the gRPC server and client applications, and the server.py gets started when we execute the start-up script with the -g flag.
1tree -P "serv*|proto" -I "*pycache*"
2.
3├── proto
4│ └── service.proto
5├── server.py
6├── server_client.py
7├── service_pb2.py
8└── service_pb2_grpc.py
9
101 directory, 5 files
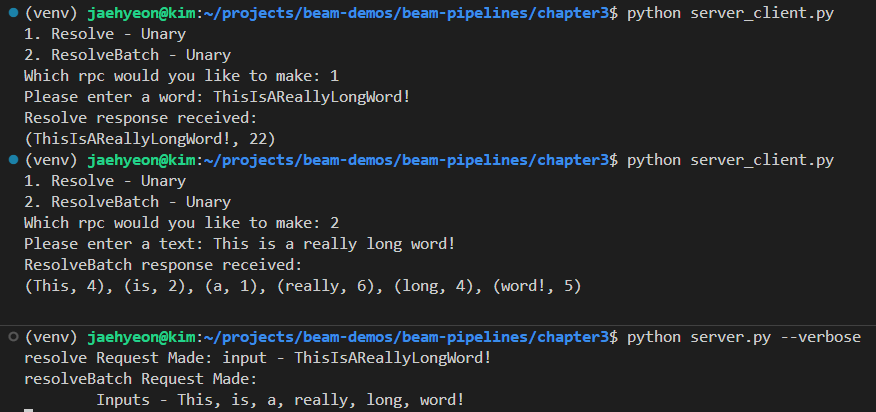
We can check the client and server applications as Python scripts. If we select 1, the next prompt requires to enter a word. Upon entering a word, it returns a tuple of the word and its length as an output. We can make an RPC request with a text if we select 2. Similar to the earlier call, it returns enriched outputs as multiple tuples.
Beam Pipeline
We develop an Apache Beam pipeline that accesses an external RPC service to augment input elements. In this version, it is configured so that a single RPC call is made for multiple elements in batch. Moreover, using state and timers, it controls how many elements to process in a batch and how long to keep elements before flushing them.
Shared Source
We have multiple pipelines that read text messages from an input Kafka topic and write outputs to an output topic. Therefore, the data source and sink transforms are refactored into a utility module as shown below. Note that, the Kafka read and write transforms have an argument called deprecated_read, which forces to use the legacy read when it is set to True. We will use the legacy read in this post to prevent a problem that is described in this GitHub issue.
1# chapter3/io_utils.py
2import re
3import typing
4
5import apache_beam as beam
6from apache_beam import pvalue
7from apache_beam.io import kafka
8
9
10def decode_message(kafka_kv: tuple):
11 print(kafka_kv)
12 return kafka_kv[1].decode("utf-8")
13
14
15def tokenize(element: str):
16 return re.findall(r"[A-Za-z\']+", element)
17
18
19class ReadWordsFromKafka(beam.PTransform):
20 def __init__(
21 self,
22 bootstrap_servers: str,
23 topics: typing.List[str],
24 group_id: str,
25 deprecated_read: bool,
26 verbose: bool = False,
27 label: str | None = None,
28 ) -> None:
29 super().__init__(label)
30 self.boostrap_servers = bootstrap_servers
31 self.topics = topics
32 self.group_id = group_id
33 self.verbose = verbose
34 self.expansion_service = None
35 if deprecated_read:
36 self.expansion_service = kafka.default_io_expansion_service(
37 ["--experiments=use_deprecated_read"]
38 )
39
40 def expand(self, input: pvalue.PBegin):
41 return (
42 input
43 | "ReadFromKafka"
44 >> kafka.ReadFromKafka(
45 consumer_config={
46 "bootstrap.servers": self.boostrap_servers,
47 "auto.offset.reset": "latest",
48 # "enable.auto.commit": "true",
49 "group.id": self.group_id,
50 },
51 topics=self.topics,
52 timestamp_policy=kafka.ReadFromKafka.create_time_policy,
53 commit_offset_in_finalize=True,
54 expansion_service=self.expansion_service,
55 )
56 | "DecodeMessage" >> beam.Map(decode_message)
57 | "ExtractWords" >> beam.FlatMap(tokenize)
58 )
59
60
61class WriteOutputsToKafka(beam.PTransform):
62 def __init__(
63 self,
64 bootstrap_servers: str,
65 topic: str,
66 deprecated_read: bool, # TO DO: remove as it applies only to ReadFromKafka
67 label: str | None = None,
68 ) -> None:
69 super().__init__(label)
70 self.boostrap_servers = bootstrap_servers
71 self.topic = topic
72 # TO DO: remove as it applies only to ReadFromKafka
73 self.expansion_service = None
74 if deprecated_read:
75 self.expansion_service = kafka.default_io_expansion_service(
76 ["--experiments=use_deprecated_read"]
77 )
78
79 def expand(self, pcoll: pvalue.PCollection):
80 return pcoll | "WriteToKafka" >> kafka.WriteToKafka(
81 producer_config={"bootstrap.servers": self.boostrap_servers},
82 topic=self.topic,
83 expansion_service=self.expansion_service,
84 )
Pipeline Source
In BatchRpcDoFnStateful, we use state and timers to control how many elements to process in a batch and how long to keep elements before flushing them.
State
BATCH_SIZE- A varying integer value is kept in this state, and its value increases by one when a new element is added to a batch. It is used to determine whether to flush the elements in a batch for processing.
BATCH- Input elements are kept in this state until being flushed.
Timers
FLUSH_TIMER- This timer is triggered when it exceeds the maximum wait seconds. Without this timer, input elements may be held forever if the number of elements is less than the defined batch size.
EOW_TIMER- This timer is set up to ensure any existing elements are flushed at the end of the window.
In the process method, we set the flush and end of window timers. These timers ensure that elements are flushed even if there is no element or fewer elements than the batch size in a batch. Then, we add a new element to the batch and increase the batch size by one. Finally, the elements are flushed if the current batch size is greater than or equal to the defined batch size.
In the flush method, it begins with collecting elements in the batch, followed by clearing up all state and timers. Then, a single RPC call is made to the resolveBatch method after unique input elements are converted into a RequestList object. Once a response is made, output elements are constructed by augmenting input elements with the response, and the output elements are returned as a list.
Note that stateful DoFn requires a key-value pair as its input because state access is within the content of the key and window. Therefore, we apply a transform called ToBuckets before the main transform. That transform converts a word into a key-value pair where the key is obtained by taking the Unicode code point for the first character of the word and the value is the word itself.
1# chapter3/rpc_pardo_stateful.py
2import os
3import argparse
4import json
5import re
6import typing
7import logging
8
9import apache_beam as beam
10from apache_beam.transforms.timeutil import TimeDomain
11from apache_beam.transforms.userstate import (
12 ReadModifyWriteStateSpec,
13 BagStateSpec,
14 TimerSpec,
15 on_timer,
16)
17from apache_beam.transforms.window import GlobalWindow
18from apache_beam.utils.windowed_value import WindowedValue
19from apache_beam.utils.timestamp import Timestamp, Duration
20from apache_beam.options.pipeline_options import PipelineOptions
21from apache_beam.options.pipeline_options import SetupOptions
22
23from io_utils import ReadWordsFromKafka, WriteOutputsToKafka
24
25
26class ValueCoder(beam.coders.Coder):
27 def encode(self, e: typing.Tuple[int, str]):
28 """Encode to bytes with a trace that coder was used."""
29 return f"x:{e[0]}:{e[1]}".encode("utf-8")
30
31 def decode(self, b: bytes):
32 s = b.decode("utf-8")
33 assert s[0:2] == "x:"
34 return tuple(s.split(":")[1:])
35
36 def is_deterministic(self):
37 return True
38
39
40beam.coders.registry.register_coder(typing.Tuple[int, str], ValueCoder)
41
42
43def create_message(element: typing.Tuple[str, int]):
44 msg = json.dumps({"word": element[0], "length": element[1]})
45 print(msg)
46 return element[0].encode("utf-8"), msg.encode("utf-8")
47
48
49def to_buckets(e: str):
50 return (ord(e[0]) % 10, e)
51
52
53class BatchRpcDoFnStateful(beam.DoFn):
54 channel = None
55 stub = None
56 hostname = "localhost"
57 port = "50051"
58
59 BATCH_SIZE = ReadModifyWriteStateSpec("batch_size", beam.coders.VarIntCoder())
60 BATCH = BagStateSpec(
61 "batch",
62 beam.coders.WindowedValueCoder(wrapped_value_coder=ValueCoder()),
63 )
64 FLUSH_TIMER = TimerSpec("flush_timer", TimeDomain.REAL_TIME)
65 EOW_TIMER = TimerSpec("end_of_time", TimeDomain.WATERMARK)
66
67 def __init__(self, batch_size: int, max_wait_secs: int):
68 self.batch_size = batch_size
69 self.max_wait_secs = max_wait_secs
70
71 def setup(self):
72 import grpc
73 import service_pb2_grpc
74
75 self.channel: grpc.Channel = grpc.insecure_channel(
76 f"{self.hostname}:{self.port}"
77 )
78 self.stub = service_pb2_grpc.RpcServiceStub(self.channel)
79
80 def teardown(self):
81 if self.channel is not None:
82 self.channel.close()
83
84 def process(
85 self,
86 element: typing.Tuple[int, str],
87 batch=beam.DoFn.StateParam(BATCH),
88 batch_size=beam.DoFn.StateParam(BATCH_SIZE),
89 flush_timer=beam.DoFn.TimerParam(FLUSH_TIMER),
90 eow_timer=beam.DoFn.TimerParam(EOW_TIMER),
91 timestamp=beam.DoFn.TimestampParam,
92 win_param=beam.DoFn.WindowParam,
93 ):
94 current_size = batch_size.read() or 0
95 if current_size == 0:
96 flush_timer.set(Timestamp.now() + Duration(seconds=self.max_wait_secs))
97 eow_timer.set(GlobalWindow().max_timestamp())
98 current_size += 1
99 batch_size.write(current_size)
100 batch.add(
101 WindowedValue(value=element, timestamp=timestamp, windows=(win_param,))
102 )
103 if current_size >= self.batch_size:
104 return self.flush(batch, batch_size, flush_timer, eow_timer)
105
106 @on_timer(FLUSH_TIMER)
107 def on_flush_timer(
108 self,
109 batch=beam.DoFn.StateParam(BATCH),
110 batch_size=beam.DoFn.StateParam(BATCH_SIZE),
111 flush_timer=beam.DoFn.TimerParam(FLUSH_TIMER),
112 eow_timer=beam.DoFn.TimerParam(EOW_TIMER),
113 ):
114 return self.flush(batch, batch_size, flush_timer, eow_timer)
115
116 @on_timer(EOW_TIMER)
117 def on_eow_timer(
118 self,
119 batch=beam.DoFn.StateParam(BATCH),
120 batch_size=beam.DoFn.StateParam(BATCH_SIZE),
121 flush_timer=beam.DoFn.TimerParam(FLUSH_TIMER),
122 eow_timer=beam.DoFn.TimerParam(EOW_TIMER),
123 ):
124 return self.flush(batch, batch_size, flush_timer, eow_timer)
125
126 def flush(
127 self,
128 batch=beam.DoFn.StateParam(BATCH),
129 batch_size=beam.DoFn.StateParam(BATCH_SIZE),
130 flush_timer=beam.DoFn.TimerParam(FLUSH_TIMER),
131 eow_timer=beam.DoFn.TimerParam(EOW_TIMER),
132 ):
133 import service_pb2
134
135 elements = list(batch.read())
136
137 batch.clear()
138 batch_size.clear()
139 if flush_timer:
140 flush_timer.clear()
141 if eow_timer:
142 eow_timer.clear()
143
144 unqiue_values = set([e.value for e in elements])
145 request_list = service_pb2.RequestList()
146 request_list.request.extend(
147 [service_pb2.Request(input=e[1]) for e in unqiue_values]
148 )
149 response = self.stub.resolveBatch(request_list)
150 resolved = dict(
151 zip([e[1] for e in unqiue_values], [r.output for r in response.response])
152 )
153
154 return [
155 WindowedValue(
156 value=(e.value[1], resolved[e.value[1]]),
157 timestamp=e.timestamp,
158 windows=e.windows,
159 )
160 for e in elements
161 ]
162
163
164def run(argv=None, save_main_session=True):
165 parser = argparse.ArgumentParser(description="Beam pipeline arguments")
166 parser.add_argument(
167 "--bootstrap_servers",
168 default="host.docker.internal:29092",
169 help="Kafka bootstrap server addresses",
170 )
171 parser.add_argument("--input_topic", default="input-topic", help="Input topic")
172 parser.add_argument(
173 "--output_topic",
174 default=re.sub("_", "-", re.sub(".py$", "", os.path.basename(__file__))),
175 help="Output topic",
176 )
177 parser.add_argument(
178 "--batch_size", type=int, default=10, help="Batch size to process"
179 )
180 parser.add_argument(
181 "--max_wait_secs",
182 type=int,
183 default=4,
184 help="Maximum wait seconds before processing",
185 )
186 parser.add_argument(
187 "--deprecated_read",
188 action="store_true",
189 default="Whether to use a deprecated read. See https://github.com/apache/beam/issues/20979",
190 )
191 parser.set_defaults(deprecated_read=False)
192
193 known_args, pipeline_args = parser.parse_known_args(argv)
194
195 # # We use the save_main_session option because one or more DoFn's in this
196 # # workflow rely on global context (e.g., a module imported at module level).
197 pipeline_options = PipelineOptions(pipeline_args)
198 pipeline_options.view_as(SetupOptions).save_main_session = save_main_session
199 print(f"known args - {known_args}")
200 print(f"pipeline options - {pipeline_options.display_data()}")
201
202 with beam.Pipeline(options=pipeline_options) as p:
203 (
204 p
205 | "ReadInputsFromKafka"
206 >> ReadWordsFromKafka(
207 bootstrap_servers=known_args.bootstrap_servers,
208 topics=[known_args.input_topic],
209 group_id=f"{known_args.output_topic}-group",
210 deprecated_read=known_args.deprecated_read,
211 )
212 | "ToBuckets"
213 >> beam.Map(to_buckets).with_output_types(typing.Tuple[int, str])
214 | "RequestRPC"
215 >> beam.ParDo(
216 BatchRpcDoFnStateful(
217 batch_size=known_args.batch_size,
218 max_wait_secs=known_args.max_wait_secs,
219 )
220 )
221 | "CreateMessags"
222 >> beam.Map(create_message).with_output_types(typing.Tuple[bytes, bytes])
223 | "WriteOutputsToKafka"
224 >> WriteOutputsToKafka(
225 bootstrap_servers=known_args.bootstrap_servers,
226 topic=known_args.output_topic,
227 deprecated_read=known_args.deprecated_read,
228 )
229 )
230
231 logging.getLogger().setLevel(logging.WARN)
232 logging.info("Building pipeline ...")
233
234
235if __name__ == "__main__":
236 run()
Pipeline Test
As described in this documentation, we can test a Beam pipeline as following.
- Create a
TestPipeline. - Create some static, known test input data.
- Create a
PCollectionof input data using theCreatetransform (if bounded source) or aTestStream(if unbounded source) - Apply the transform to the input
PCollectionand save the resulting outputPCollection. - Use
PAssertand its subclasses (or testing utils in Python) to verify that the outputPCollectioncontains the elements that you expect.
We use a text file that keeps a random text (input/lorem.txt) for testing. Then, we add the lines into a test stream and apply the main transform. Finally, we compare the actual output with an expected output. The expected output is a list of tuples where each element is a word and its length. Note that the FlinkRunner is used for testing because output collection failed by the Python DirectRunner, resulting in testing failure.
1# chapter3/rpc_pardo_stateful_test.py
2import os
3import unittest
4import typing
5from concurrent import futures
6
7import apache_beam as beam
8from apache_beam.coders import coders
9from apache_beam.testing.test_pipeline import TestPipeline
10from apache_beam.testing.util import assert_that, equal_to
11from apache_beam.testing.test_stream import TestStream
12from apache_beam.options.pipeline_options import PipelineOptions
13
14import grpc
15import service_pb2_grpc
16import server
17
18from rpc_pardo_stateful import to_buckets, BatchRpcDoFnStateful
19from io_utils import tokenize
20
21
22class MyItem(typing.NamedTuple):
23 word: str
24 length: int
25
26
27beam.coders.registry.register_coder(MyItem, beam.coders.RowCoder)
28
29
30def read_file(filename: str, inputpath: str):
31 with open(os.path.join(inputpath, filename), "r") as f:
32 return f.readlines()
33
34
35def compute_expected_output(lines: list):
36 output = []
37 for line in lines:
38 words = [(w, len(w)) for w in tokenize(line)]
39 output = output + words
40 return output
41
42
43class RpcParDooStatefulTest(unittest.TestCase):
44 server_class = server.RpcServiceServicer
45 port = 50051
46
47 def setUp(self):
48 self.server = grpc.server(futures.ThreadPoolExecutor())
49 service_pb2_grpc.add_RpcServiceServicer_to_server(
50 self.server_class(), self.server
51 )
52 self.server.add_insecure_port(f"[::]:{self.port}")
53 self.server.start()
54
55 def tearDown(self):
56 self.server.stop(None)
57
58 def test_pipeline(self):
59 pipeline_opts = {"runner": "FlinkRunner", "parallelism": 1, "streaming": True}
60 options = PipelineOptions([], **pipeline_opts)
61 with TestPipeline(options=options) as p:
62 PARENT_DIR = os.path.dirname(os.path.dirname(os.path.realpath(__file__)))
63 lines = read_file("lorem.txt", os.path.join(PARENT_DIR, "inputs"))
64 test_stream = TestStream(coder=coders.StrUtf8Coder()).with_output_types(str)
65 for line in lines:
66 test_stream.add_elements([line])
67 test_stream.advance_watermark_to_infinity()
68
69 output = (
70 p
71 | test_stream
72 | "ExtractWords" >> beam.FlatMap(tokenize)
73 | "ToBuckets"
74 >> beam.Map(to_buckets).with_output_types(typing.Tuple[int, str])
75 | "RequestRPC"
76 >> beam.ParDo(BatchRpcDoFnStateful(batch_size=10, max_wait_secs=5))
77 )
78
79 EXPECTED_OUTPUT = compute_expected_output(lines)
80
81 assert_that(output, equal_to(EXPECTED_OUTPUT))
82
83
84if __name__ == "__main__":
85 unittest.main()
We can execute the pipeline test as shown below.
1python chapter3/rpc_pardo_stateful_test.py
2WARNING:root:Waiting for grpc channel to be ready at localhost:46459.
3WARNING:root:Waiting for grpc channel to be ready at localhost:46459.
4WARNING:root:Waiting for grpc channel to be ready at localhost:46459.
5.
6----------------------------------------------------------------------
7Ran 1 test in 19.801s
8
9OK
Pipeline Execution
Note that the Kafka bootstrap server is accessible on port 29092 outside the Docker network, and it can be accessed on localhost:29092 from the Docker host machine and on host.docker.internal:29092 from a Docker container that is launched with the host network. We use both types of the bootstrap server address - the former is used by the Kafka producer app and the latter by a Java IO expansion service, which is launched in a Docker container. Note further that, for the latter to work, we have to update the /etc/hosts file by adding an entry for host.docker.internal as shown below.
1cat /etc/hosts | grep host.docker.internal
2# 127.0.0.1 host.docker.internal
We need to send messages into the input Kafka topic before executing the pipeline. Input messages can be sent by executing the Kafka text producer - python utils/faker_shifted_gen.py.
When executing the pipeline, we specify only a single known argument that enables to use the legacy read (--deprecated_read) while accepting default values of the other known arguments (bootstrap_servers, input_topic …). The remaining arguments are all pipeline arguments. Note that we deploy the pipeline on a local Flink cluster by specifying the flink master argument (--flink_master=localhost:8081). Alternatively, we can use an embedded Flink cluster if we exclude that argument.
1## start the beam pipeline
2## exclude --flink_master if using an embedded cluster
3python chapter3/rpc_pardo_stateful.py --deprecated_read \
4 --job_name=rpc-pardo-stateful --runner FlinkRunner --flink_master=localhost:8081 \
5 --streaming --environment_type=LOOPBACK --parallelism=3 --checkpointing_interval=10000
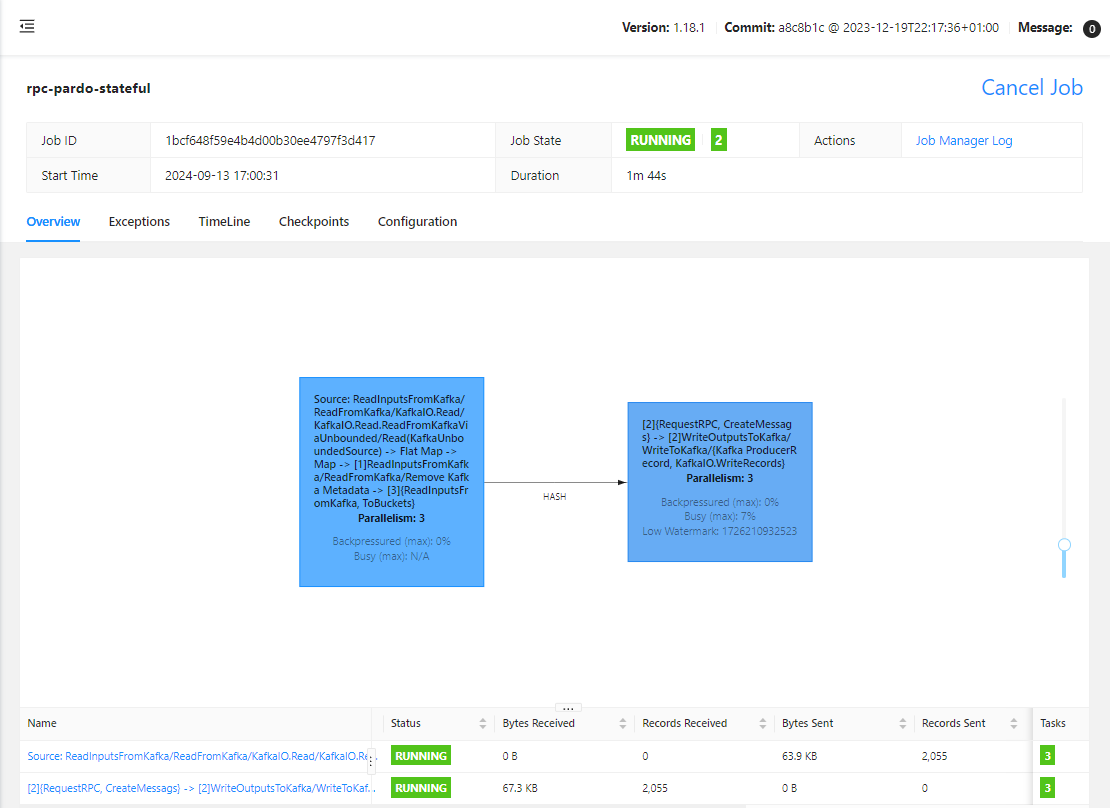
On Flink UI, we see the pipeline has two tasks. The first task is until converting words into key-value pairs while the latter executes the main transform and sends output messages to the Kafka topic.
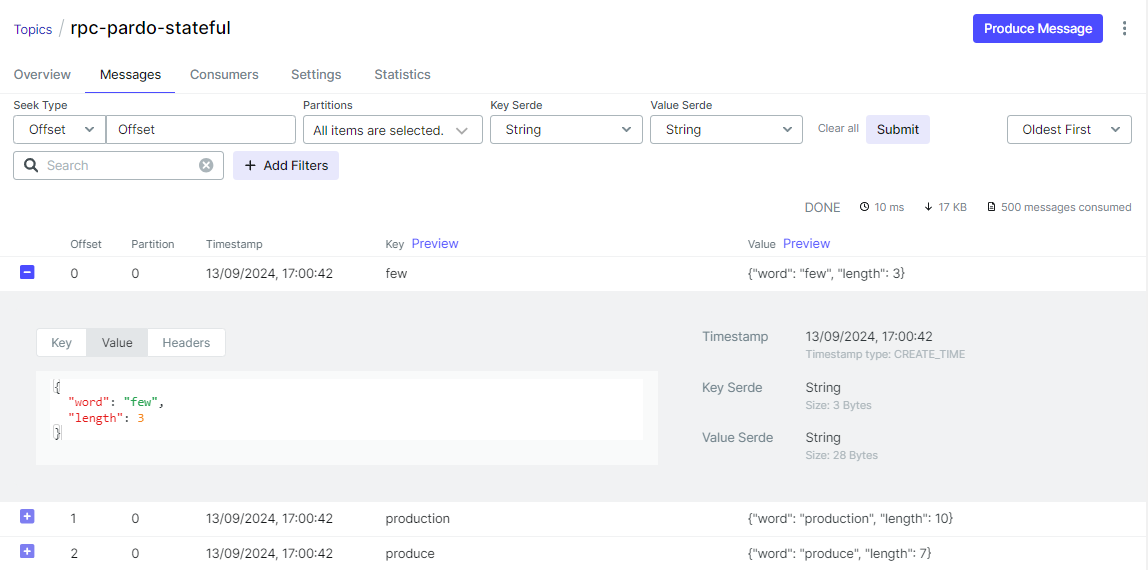
On Kafka UI, we can check the output message is a dictionary of a word and its length.










Comments