
A Splittable DoFn (SDF) is a generalization of a DoFn that enables Apache Beam developers to create modular and composable I/O components. Also, it can be applied in advanced non-I/O scenarios such as Monte Carlo simulation. In this post, we develop two Apache Beam pipelines. The first pipeline is an I/O connector, and it reads a list of files in a folder followed by processing each of the file objects in parallel. The second pipeline estimates the value of $\pi$ by performing Monte Carlo simulation.
- Part 1 Calculate K Most Frequent Words and Max Word Length
- Part 2 Calculate Average Word Length with/without Fixed Look back
- Part 3 Build Sport Activity Tracker with/without SQL
- Part 4 Call RPC Service for Data Augmentation
- Part 5 Call RPC Service in Batch using Stateless DoFn
- Part 6 Call RPC Service in Batch with Defined Batch Size using Stateful DoFn
- Part 7 Separate Droppable Data into Side Output
- Part 8 Enhance Sport Activity Tracker with Runner Motivation
- Part 9 Develop Batch File Reader and PiSampler using Splittable DoFn (this post)
- Part 10 Develop Streaming File Reader using Splittable DoFn
Splittable DoFn
A Splittable DoFn (SDF) is a generalization of a DoFn that enables Apache Beam developers to create modular and composable I/O components. Also, it can be applied in advanced non-I/O scenarios such as Monte Carlo simulation.
As described in the Apache Beam Programming Guide, an SDF is responsible for processing element and restriction pairs. A restriction represents a subset of work that would have been necessary to have been done when processing the element.
Executing an SDF follows the following steps:
- Each element is paired with a restriction (e.g. filename is paired with offset range representing the whole file).
- Each element and restriction pair is split (e.g. offset ranges are broken up into smaller pieces).
- The runner redistributes the element and restriction pairs to several workers.
- Element and restriction pairs are processed in parallel (e.g. the file is read). Within this last step, the element and restriction pair can pause its own processing and/or be split into further element and restriction pairs.
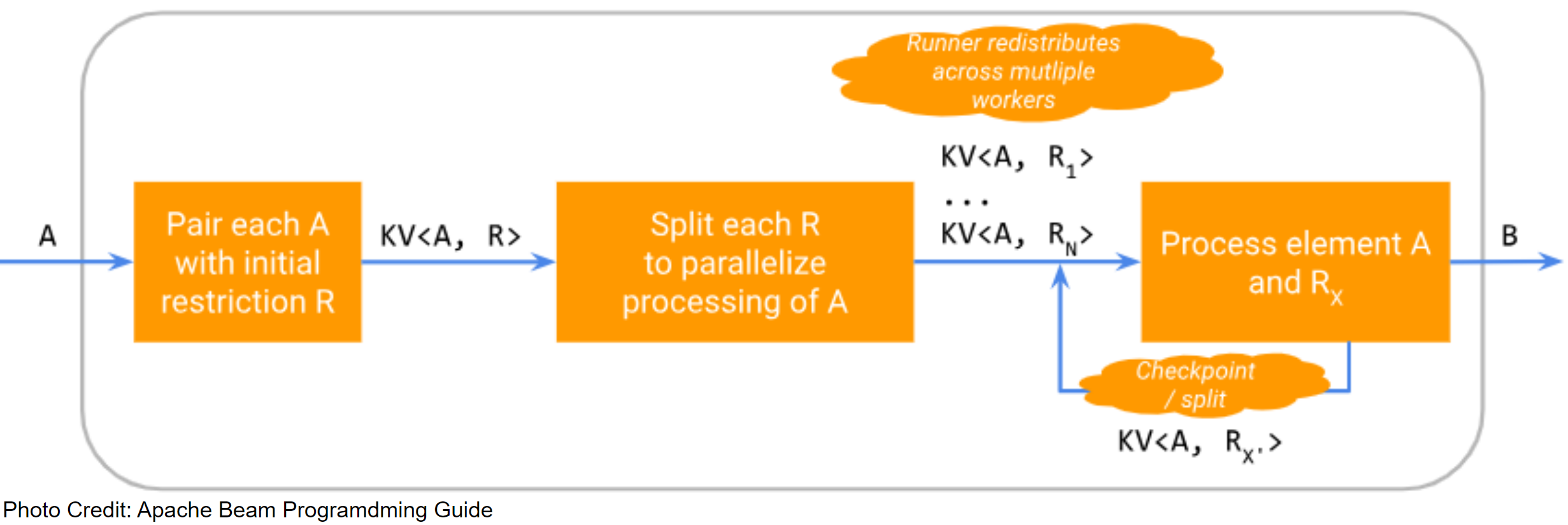
A basic SDF is composed of three parts: a restriction, a restriction provider, and a restriction tracker.
- restriction
- It represents a subset of work for a given element.
- No specific class needs to be implemented to represent a restriction.
- restriction provider
- It lets developers override default implementations used to generate and manipulate restrictions.
- It extends from the
RestrictionProviderbase class.
- restriction tracker
- It tracks for which parts of the restriction processing has been completed.
- It extends from the
RestrictionTrackerbase class.
The Python SDK has a built-in restriction (OffsetRange) and restriction tracker (OffsetRangeTracker), and we will use them in this post.
An advanced SDF has the following components for watermark estimation, and we will use them in the next post.
- watermark state
- It is a user-defined object. In its simplest form it could just be a timestamp.
- watermark estimator
- It tracks the watermark state when the processing of an element and restriction pair is in progress.
- It extends from the
WatermarkEstimatorbase class.
- watermark estimator provider
- It lets developers define how to initialize the watermark state and create a watermark estimator.
- It extends from the
WatermarkEstimatorProviderbase class.
For more details, visit Splittable DoFns in Python: a hands-on workshop.
Batch File Reader
This Beam pipeline reads a list of files in a folder followed by processing each of the file objects in parallel. The pipeline is slightly modified from an example which was introduced in a workshop at Beam Summit 2022. The source of this post can be found in this GitHub repository.
File Generator
The batch pipeline requires input files to process, and those files can be created using the file generator (faker_file_gen.py). It creates a configurable number of files (default 10) in a specified folder (default fake_files). Each file includes zero to two hundreds lines of text, which is generated by the Faker package.
1# utils/faker_file_gen.py
2import os
3import time
4import shutil
5import argparse
6import logging
7
8from faker import Faker
9
10
11def create_folder(file_path: str):
12 shutil.rmtree(file_path, ignore_errors=True)
13 os.mkdir(file_path)
14
15
16def write_to_file(fake: Faker, file_path: str, file_name: str):
17 with open(os.path.join(file_path, file_name), "w") as f:
18 f.writelines(fake.texts(nb_texts=fake.random_int(min=0, max=200)))
19
20
21if __name__ == "__main__":
22 parser = argparse.ArgumentParser(__file__, description="Fake Text File Generator")
23 parser.add_argument(
24 "-p",
25 "--file_path",
26 default=os.path.join(
27 os.path.dirname(os.path.dirname(os.path.realpath(__file__))), "fake_files"
28 ),
29 help="File path",
30 )
31 parser.add_argument(
32 "-m",
33 "--max_files",
34 type=int,
35 default=10,
36 help="The amount of time that a record should be delayed.",
37 )
38 parser.add_argument(
39 "-d",
40 "--delay_seconds",
41 type=float,
42 default=0.5,
43 help="The amount of time that a record should be delayed.",
44 )
45
46 args = parser.parse_args()
47
48 logging.getLogger().setLevel(logging.INFO)
49 logging.info(
50 f"Create files: max files {args.max_files}, delay seconds {args.delay_seconds}..."
51 )
52
53 fake = Faker()
54 Faker.seed(1237)
55
56 create_folder(args.file_path)
57 current = 0
58 while True:
59 write_to_file(
60 fake,
61 args.file_path,
62 f"{''.join(fake.random_letters(length=10)).lower()}.txt",
63 )
64 current += 1
65 if current % 5 == 0:
66 logging.info(f"Created {current} files so far...")
67 if current == args.max_files:
68 break
69 time.sleep(args.delay_seconds)
Once executed, we can check input files are created in a specified folder.
1$ python utils/faker_file_gen.py --file_path fake_files --max_files 10 --delay_seconds 0.5
2INFO:root:Create files: max files 10, delay seconds 0.5...
3INFO:root:Created 5 files so far...
4INFO:root:Created 10 files so far...
5
6$ tree fake_files/
7fake_files/
8├── dhmfhxwbqd.txt
9├── dzpjwroqdd.txt
10├── humlastzob.txt
11├── jfdlxdnsre.txt
12├── qgtyykdzdk.txt
13├── uxgrwaisgj.txt
14├── vcqlxrcqnx.txt
15├── ydlceysnkc.txt
16├── ylgvjqjhrb.txt
17└── zpjinqrdyw.txt
18
191 directory, 10 files
SDF for File Processing
The pipeline has two DoFn objects.
GenerateFilesFn- It reads each of the files in the input folder (element) followed by yielding a custom object (
MyFile). The custom object keeps details of a file object that include the file name and start/end positions. As we use the defaultOffsetRestrictionTrackerin the subsequent DoFn, it is necessary to keep the start and end positions because those are used to set up the initial offset range.
- It reads each of the files in the input folder (element) followed by yielding a custom object (
ProcessFilesFn- It begins with recovering the current restriction using the parameter of type
RestrictionParam, which is passed as argument. Then, it tries to claim/lock the position. Once claimed, it proceeds to processing the associated element and restriction pair, which is just yielding a text that keeps the file name and current position.
- It begins with recovering the current restriction using the parameter of type
1# chapter7/file_read.py
2import os
3import typing
4import logging
5
6import apache_beam as beam
7from apache_beam import RestrictionProvider
8from apache_beam.io.restriction_trackers import OffsetRange, OffsetRestrictionTracker
9
10
11class MyFile(typing.NamedTuple):
12 name: str
13 start: int
14 end: int
15
16
17class GenerateFilesFn(beam.DoFn):
18 def process(self, element: str) -> typing.Iterable[MyFile]:
19 for file in os.listdir(element):
20 if os.path.isfile(os.path.join(element, file)):
21 num_lines = sum(1 for _ in open(os.path.join(element, file)))
22 new_file = MyFile(file, 0, num_lines)
23 yield new_file
24
25
26class ProcessFilesFn(beam.DoFn, RestrictionProvider):
27 def process(
28 self,
29 element: MyFile,
30 tracker: OffsetRestrictionTracker = beam.DoFn.RestrictionParam(),
31 ):
32 restriction = tracker.current_restriction()
33 for current_position in range(restriction.start, restriction.stop + 1):
34 if tracker.try_claim(current_position):
35 m = f"file: {element.name}, position: {current_position}"
36 logging.info(m)
37 yield m
38 else:
39 return
40
41 def create_tracker(self, restriction: OffsetRange) -> OffsetRestrictionTracker:
42 return OffsetRestrictionTracker(restriction)
43
44 def initial_restriction(self, element: MyFile) -> OffsetRange:
45 return OffsetRange(start=element.start, stop=element.end)
46
47 def restriction_size(self, element: MyFile, restriction: OffsetRange) -> int:
48 return restriction.size()
Beam Pipeline
The pipeline begins with passing the input folder name to the GenerateFilesFn DoFn. Then, the DoFn yields the custom MyFile objects while reading the whole list of files in the input folder. Finally, the custom objects are processed by the ProcessFilesFn DoFn.
1# chapter7/batch_file_read.py
2import os
3import logging
4import argparse
5
6import apache_beam as beam
7from apache_beam.options.pipeline_options import PipelineOptions
8from apache_beam.options.pipeline_options import SetupOptions
9
10from file_read import GenerateFilesFn, ProcessFilesFn
11
12
13def run(argv=None, save_main_session=True):
14 parser = argparse.ArgumentParser(description="Beam pipeline arguments")
15 parser.add_argument(
16 "-p",
17 "--file_path",
18 default=os.path.join(
19 os.path.dirname(os.path.dirname(os.path.realpath(__file__))), "fake_files"
20 ),
21 help="File path",
22 )
23
24 known_args, pipeline_args = parser.parse_known_args(argv)
25
26 # # We use the save_main_session option because one or more DoFn's in this
27 # # workflow rely on global context (e.g., a module imported at module level).
28 pipeline_options = PipelineOptions(pipeline_args)
29 pipeline_options.view_as(SetupOptions).save_main_session = save_main_session
30 print(f"known args - {known_args}")
31 print(f"pipeline options - {pipeline_options.display_data()}")
32
33 with beam.Pipeline(options=pipeline_options) as p:
34 (
35 p
36 | beam.Create([known_args.file_path])
37 | beam.ParDo(GenerateFilesFn())
38 | beam.ParDo(ProcessFilesFn())
39 )
40
41 logging.getLogger().setLevel(logging.INFO)
42 logging.info("Building pipeline ...")
43
44
45if __name__ == "__main__":
46 run()
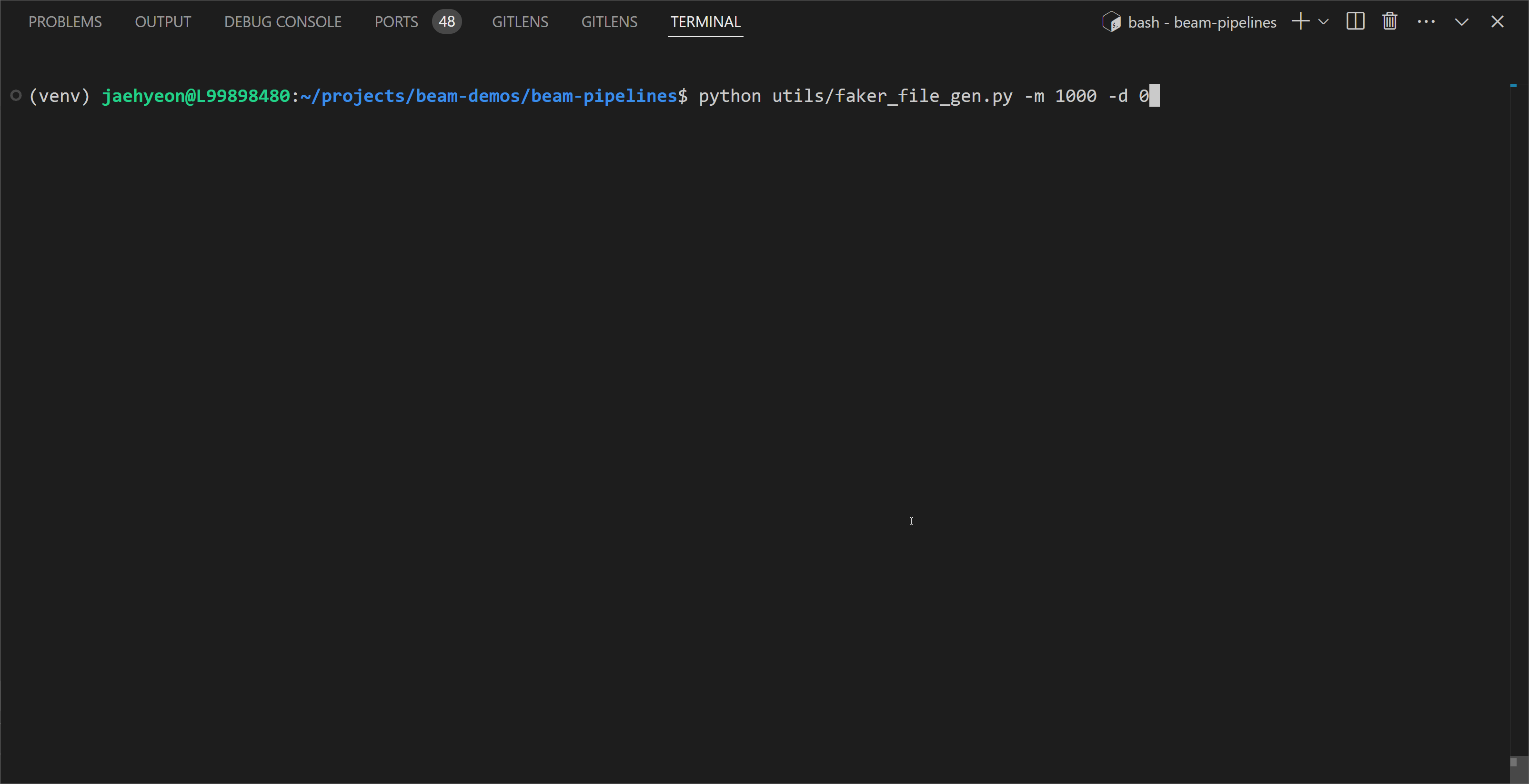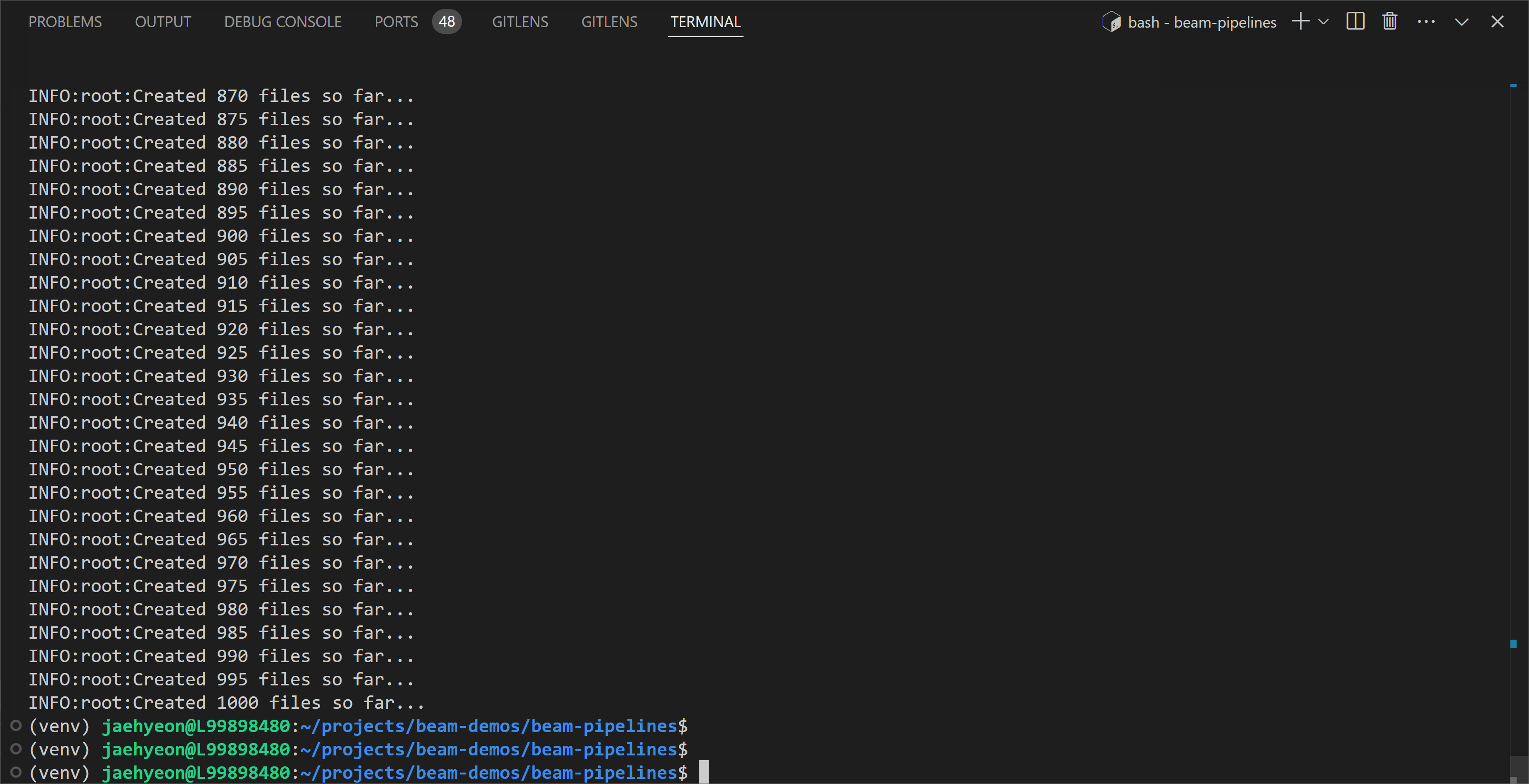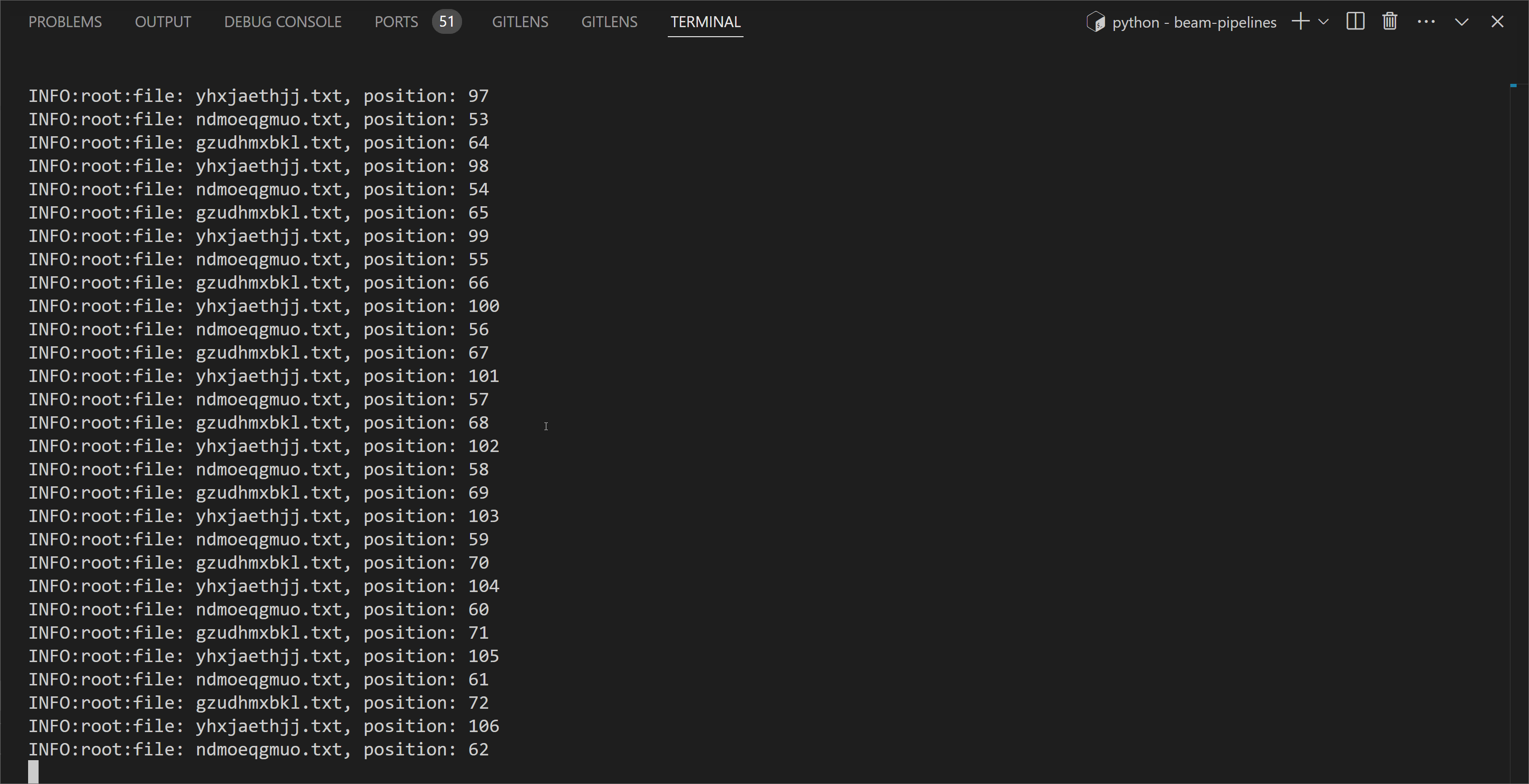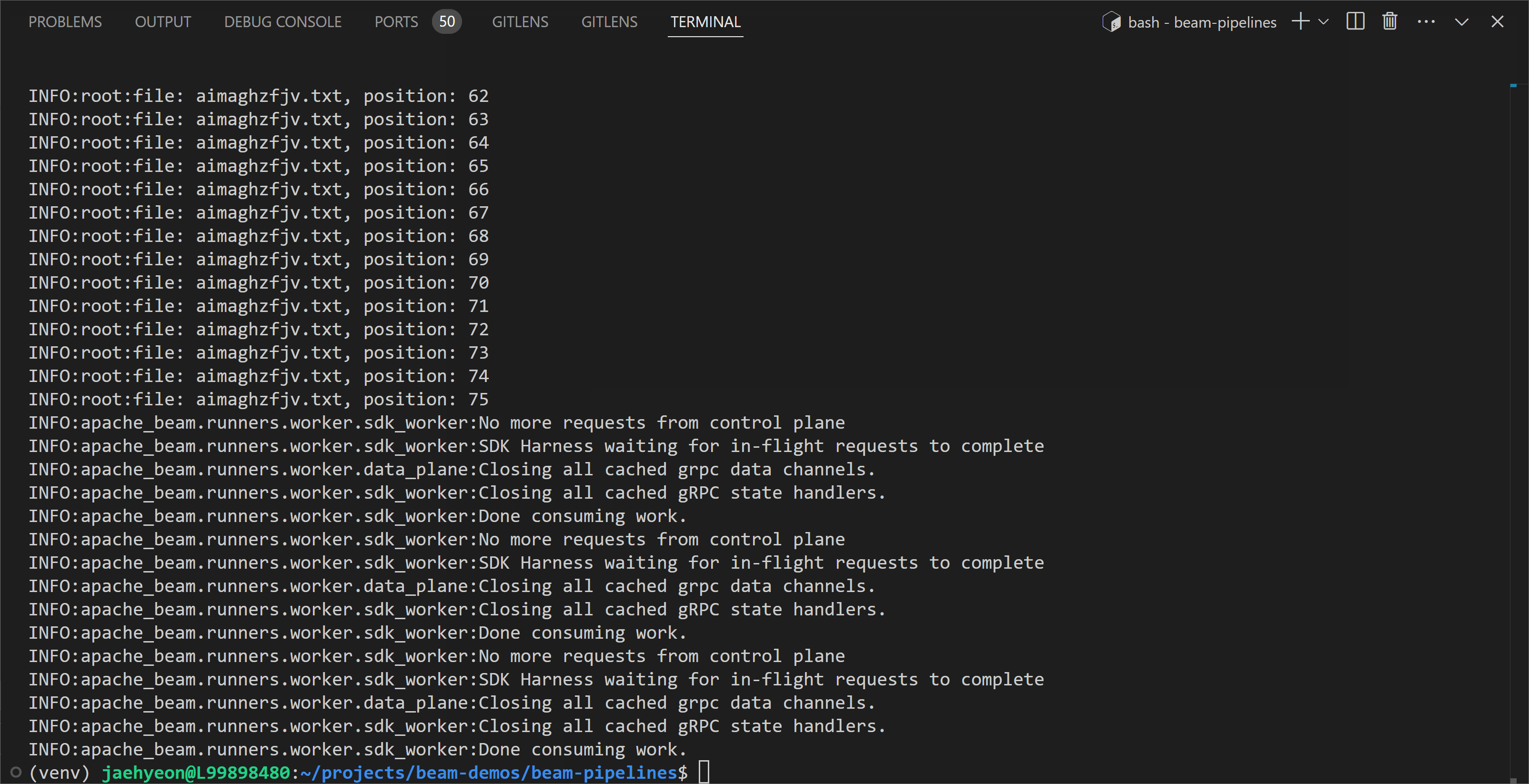
We can create input files and run the pipeline using the Direct Runner as shown below.
1python utils/faker_file_gen.py -m 1000 -d 0
2python chapter7/batch_file_read.py \
3 --direct_num_workers=3 --direct_running_mode=multi_threading
PI Sampler
This pipeline performs a Monte Carlo simulation to estimate $\pi$. Let say we have a square that is centered at the origin of a two-dimensional space. If the length of its side is two, its area becomes four. Now we draw a circle of radius one, centered at the origin as well. Then, its area becomes $\pi$. In this circumstance, if we randomly place a dot within the square, the probability that we place the dot within the circle is $\pi$/4. To estimate this probability empirically, we can place many dots in the square. If we label the case as positive when a dot is placed within the circle and as negative otherwise, we have the following empirical relationship.
- $\pi$/4 $\approx$
# positive/# total
Therefore, we can estimate the value of $\pi$ with one of the following formulas.
- $\pi$ $\approx$ 4 x
# positive/# totalor 4 x (1 -# negative/# total)
The pipeline has two DoFn objects as shown below.
GenerateExperiments- It yields a fixed number of samples (
num_samples) to simulate in multiple experiments (parallelism). Therefore, it ends up creatingnum_samples*parallelismsimulations in total.
- It yields a fixed number of samples (
PiSamplerDoFn- Similar to the earlier pipeline, it begins with recovering the current restriction using the parameter of type
RestrictionParam, which is passed as argument. Then, it tries to claim/lock the position. Once claimed, it generates two random numbers between zero and one followed by yielding one if their squired sum is greater than one. i.e. It tracks negative cases.
- Similar to the earlier pipeline, it begins with recovering the current restriction using the parameter of type
After completing all simulations, the resulting values are added, which calculates the number of all negative cases. Finally, the value of $\pi$ is estimated by applying the second formula mentioned above.
1import random
2import logging
3import argparse
4
5import apache_beam as beam
6from apache_beam import RestrictionProvider
7from apache_beam.io.restriction_trackers import OffsetRange, OffsetRestrictionTracker
8from apache_beam.options.pipeline_options import PipelineOptions
9from apache_beam.options.pipeline_options import SetupOptions
10
11
12class GenerateExperiments(beam.DoFn):
13 def __init__(self, parallelism: int, num_samples: int):
14 self.parallelism = parallelism
15 self.num_samples = num_samples
16
17 def process(self, ignored_element):
18 for i in range(self.parallelism):
19 if (i + 1) % 10 == 0:
20 logging.info(f"sending {i + 1}th experiment")
21 yield self.num_samples
22
23
24class PiSamplerDoFn(beam.DoFn, RestrictionProvider):
25 def process(
26 self,
27 element: int,
28 tracker: OffsetRestrictionTracker = beam.DoFn.RestrictionParam(),
29 ):
30 restriction = tracker.current_restriction()
31 for current_position in range(restriction.start, restriction.stop + 1):
32 if tracker.try_claim(current_position):
33 x, y = random.random(), random.random()
34 if x * x + y * y > 1:
35 yield 1
36 else:
37 return
38
39 def create_tracker(self, restriction: OffsetRange) -> OffsetRestrictionTracker:
40 return OffsetRestrictionTracker(restriction)
41
42 def initial_restriction(self, element: int) -> OffsetRange:
43 return OffsetRange(start=0, stop=element)
44
45 def restriction_size(self, element: int, restriction: OffsetRange) -> int:
46 return restriction.size()
47
48
49def run(argv=None, save_main_session=True):
50 parser = argparse.ArgumentParser(description="Beam pipeline arguments")
51 parser.add_argument(
52 "-p", "--parallelism", type=int, default=100, help="Number of parallelism"
53 )
54 parser.add_argument(
55 "-n", "--num_samples", type=int, default=10000, help="Number of samples"
56 )
57
58 known_args, pipeline_args = parser.parse_known_args(argv)
59
60 # # We use the save_main_session option because one or more DoFn's in this
61 # # workflow rely on global context (e.g., a module imported at module level).
62 pipeline_options = PipelineOptions(pipeline_args)
63 pipeline_options.view_as(SetupOptions).save_main_session = save_main_session
64 print(f"known args - {known_args}")
65 print(f"pipeline options - {pipeline_options.display_data()}")
66
67 with beam.Pipeline(options=pipeline_options) as p:
68 (
69 p
70 | beam.Create([0])
71 | beam.ParDo(
72 GenerateExperiments(
73 parallelism=known_args.parallelism,
74 num_samples=known_args.num_samples,
75 )
76 )
77 | beam.ParDo(PiSamplerDoFn())
78 | beam.CombineGlobally(sum)
79 | beam.Map(
80 lambda e: 4
81 * (1 - e / (known_args.num_samples * known_args.parallelism))
82 )
83 | beam.Map(print)
84 )
85
86 logging.getLogger().setLevel(logging.INFO)
87 logging.info("Building pipeline ...")
88
89
90if __name__ == "__main__":
91 run()
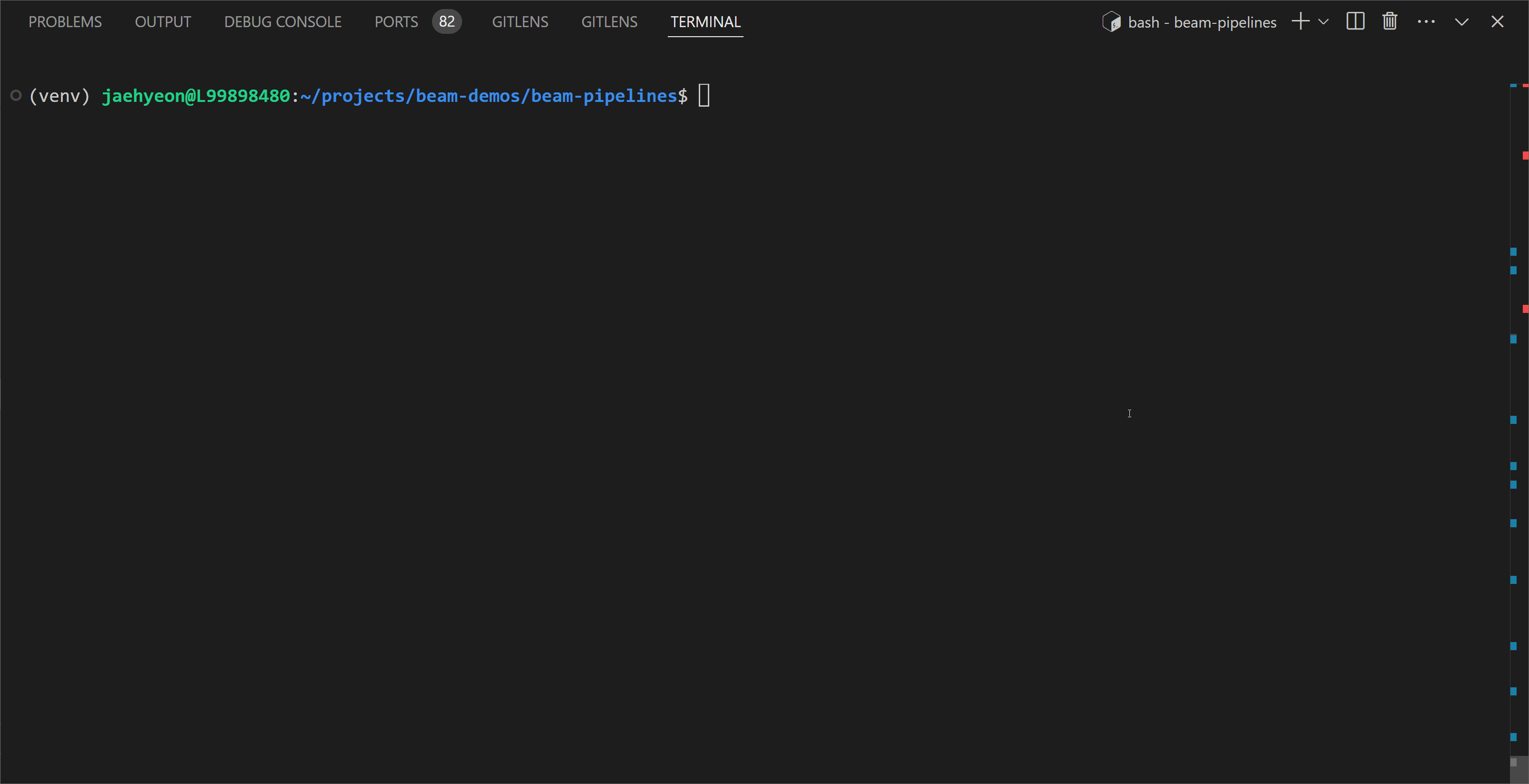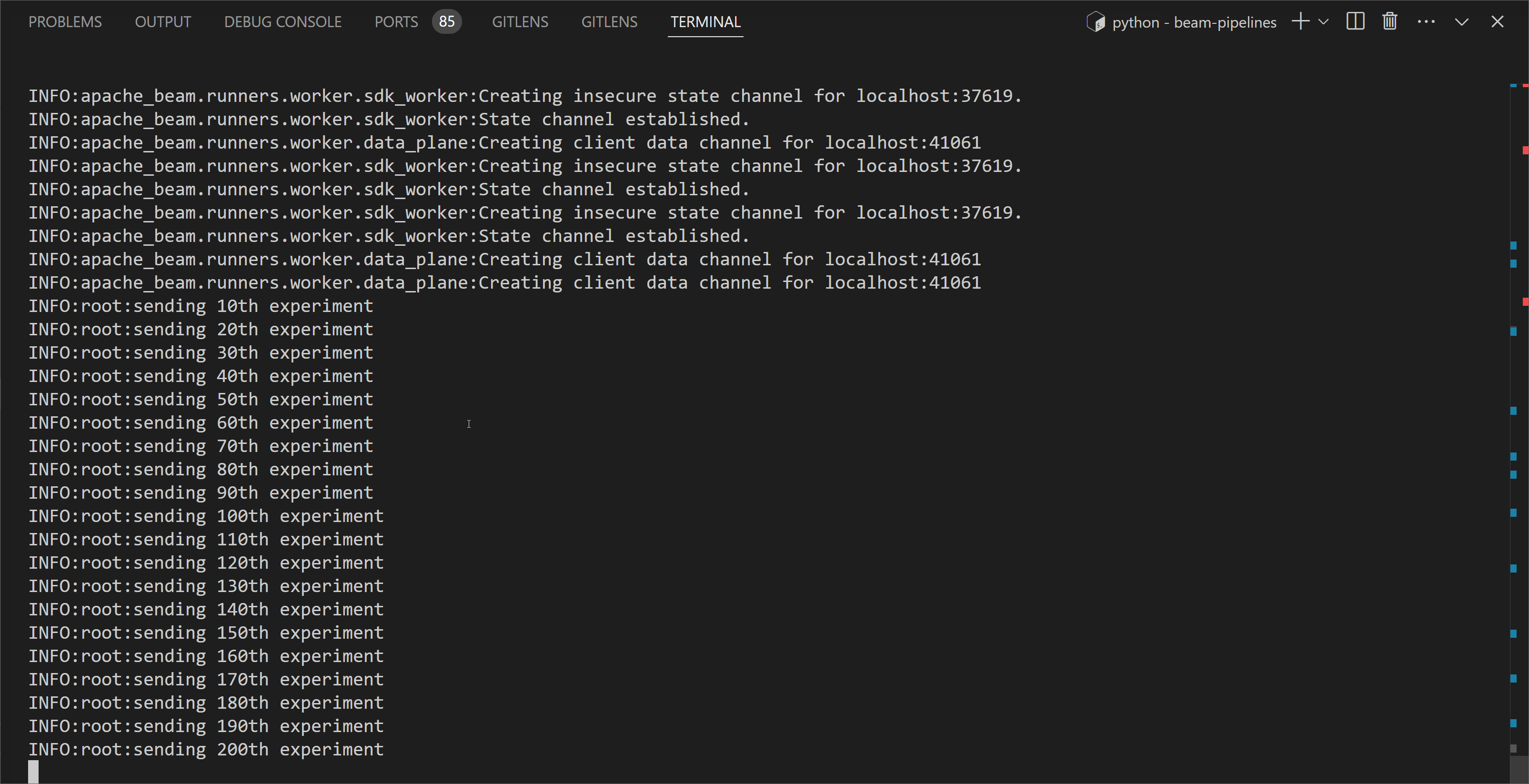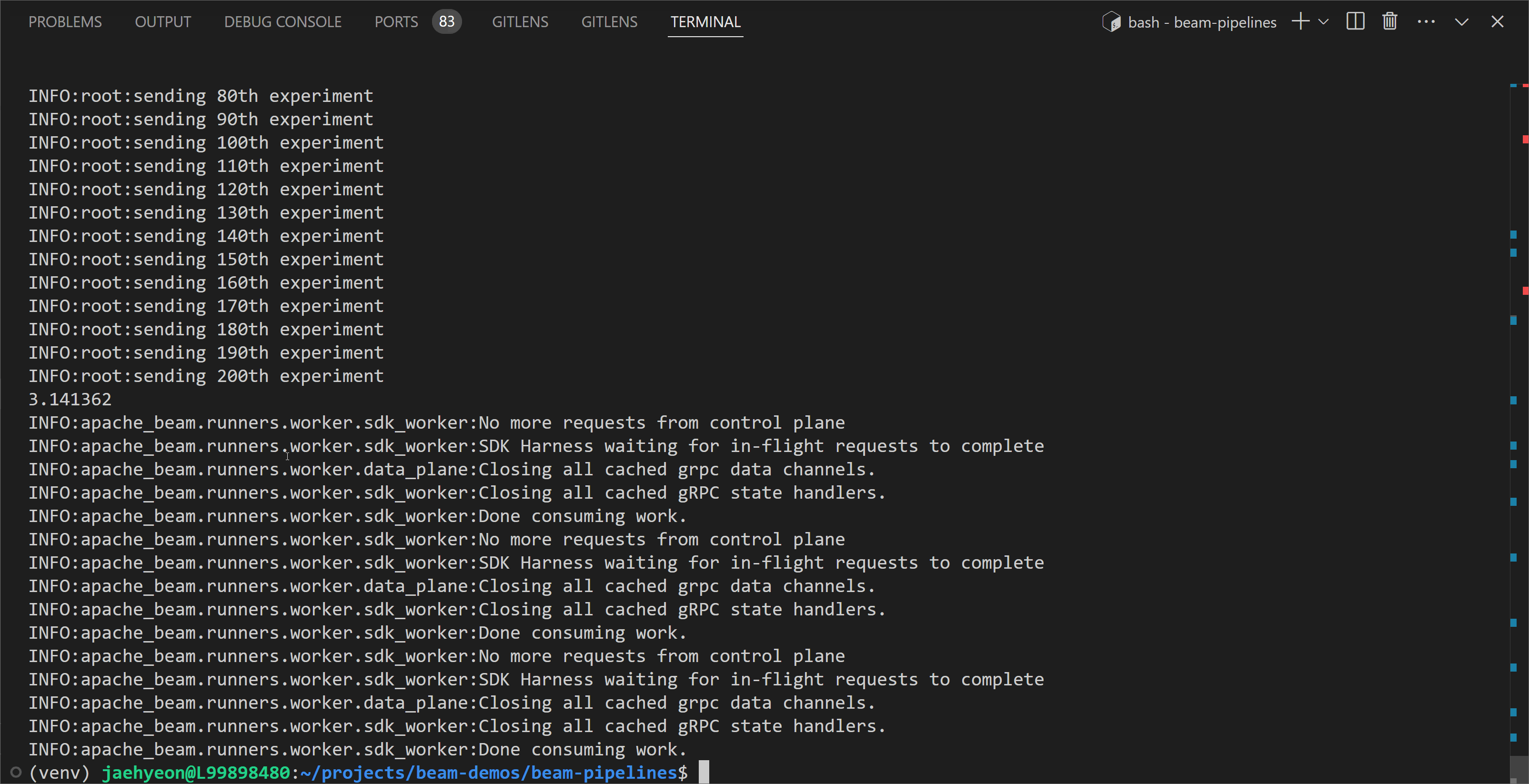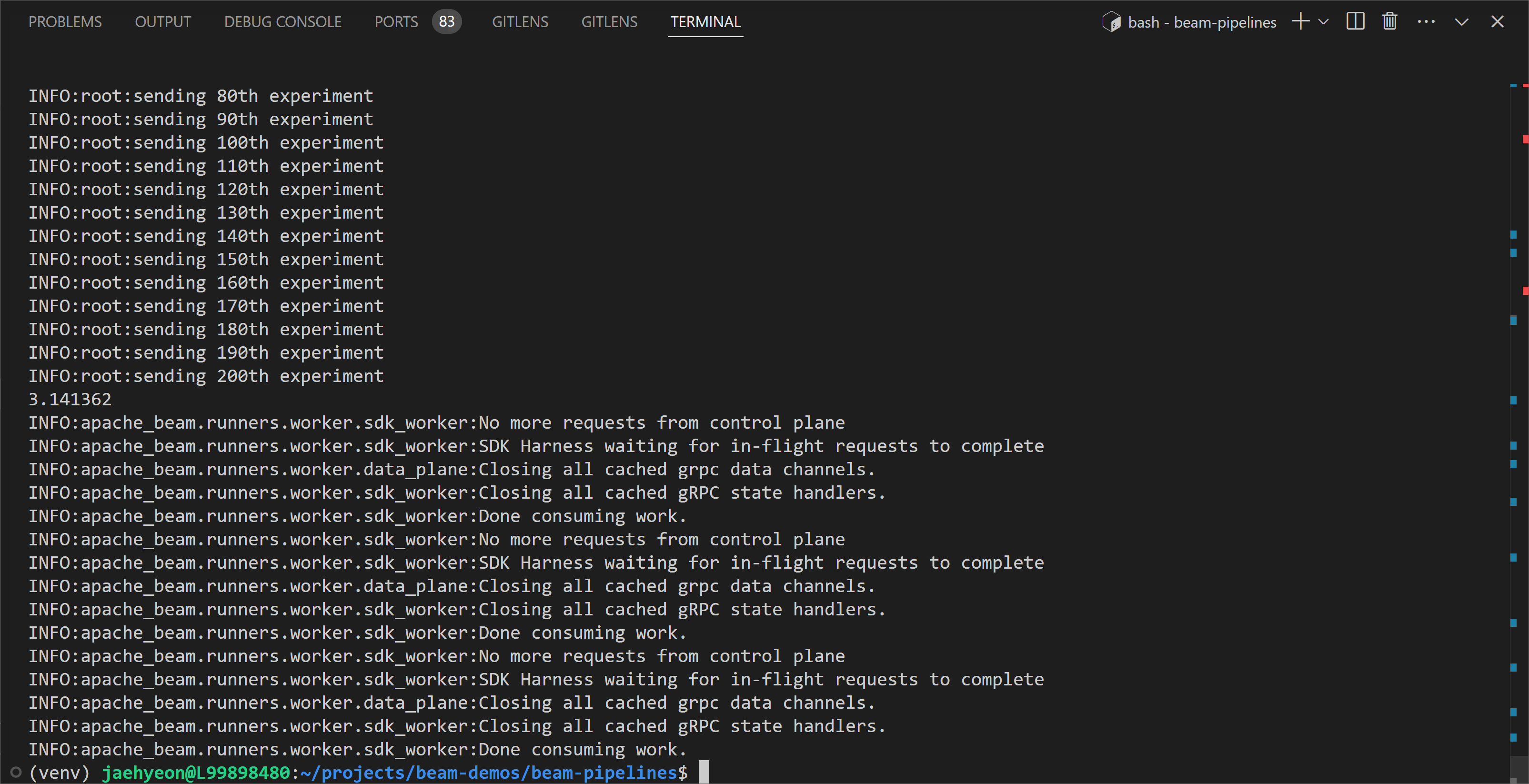
In the following example, the value of $\pi$ is estimated by 6,000,000 simulations (parallelism: 200, num_samples: 30,000). We see that the pipeline estimates $\pi$ correctly to three decimal places.
1python chapter7/pi_sampler.py -p 200 -n 30000 \
2 --direct_num_workers=3 --direct_running_mode=multi_threading










Comments