
In Part 9, we developed two Apache Beam pipelines using Splittable DoFn (SDF). One of them is a batch file reader, which reads a list of files in an input folder followed by processing them in parallel. We can extend the I/O connector so that, instead of listing files once at the beginning, it scans an input folder periodically for new files and processes whenever new files are created in the folder. The techniques used in this post can be quite useful as they can be applied to developing I/O connectors that target other unbounded (or streaming) data sources (eg Kafka) using the Python SDK.
- Part 1 Calculate K Most Frequent Words and Max Word Length
- Part 2 Calculate Average Word Length with/without Fixed Look back
- Part 3 Build Sport Activity Tracker with/without SQL
- Part 4 Call RPC Service for Data Augmentation
- Part 5 Call RPC Service in Batch using Stateless DoFn
- Part 6 Call RPC Service in Batch with Defined Batch Size using Stateful DoFn
- Part 7 Separate Droppable Data into Side Output
- Part 8 Enhance Sport Activity Tracker with Runner Motivation
- Part 9 Develop Batch File Reader and PiSampler using Splittable DoFn
- Part 10 Develop Streaming File Reader using Splittable DoFn (this post)
Splittable DoFn
A Splittable DoFn (SDF) is a generalization of a DoFn that enables Apache Beam developers to create modular and composable I/O components. Also, it can be applied in advanced non-I/O scenarios such as Monte Carlo simulation.
As described in the Apache Beam Programming Guide, an SDF is responsible for processing element and restriction pairs. A restriction represents a subset of work that would have been necessary to have been done when processing the element.
Executing an SDF follows the following steps:
- Each element is paired with a restriction (e.g. filename is paired with offset range representing the whole file).
- Each element and restriction pair is split (e.g. offset ranges are broken up into smaller pieces).
- The runner redistributes the element and restriction pairs to several workers.
- Element and restriction pairs are processed in parallel (e.g. the file is read). Within this last step, the element and restriction pair can pause its own processing and/or be split into further element and restriction pairs.
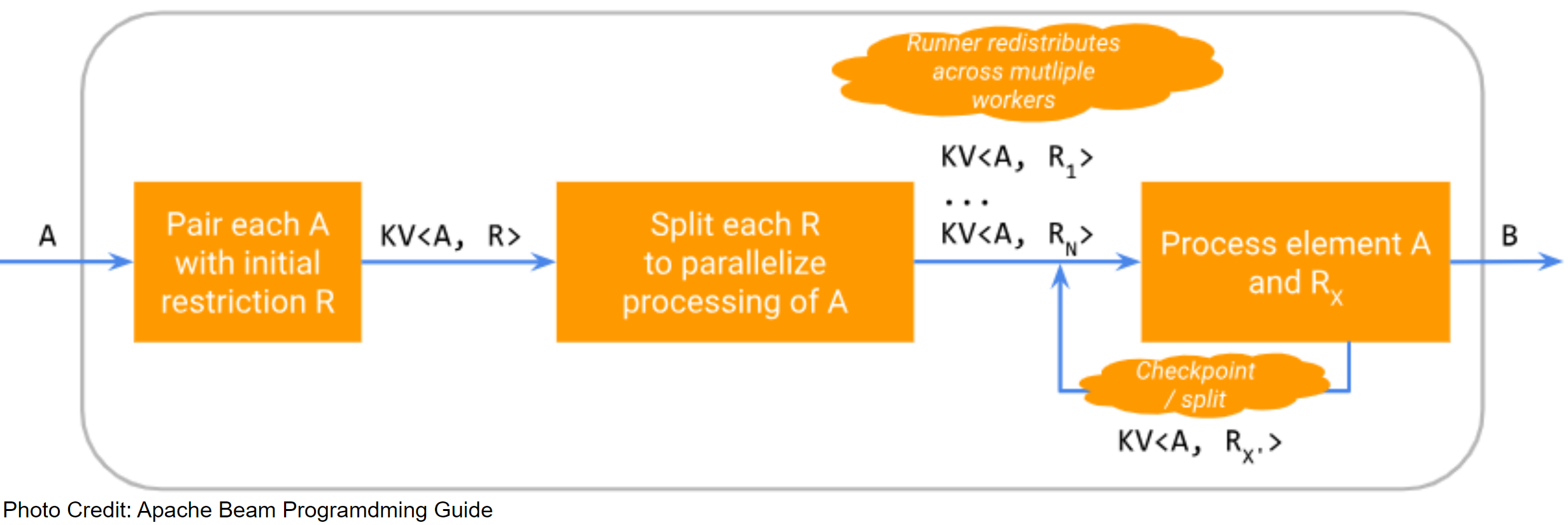
A basic SDF is composed of three parts: a restriction, a restriction provider, and a restriction tracker.
- restriction
- It represents a subset of work for a given element.
- No specific class needs to be implemented to represent a restriction.
- restriction provider
- It lets developers override default implementations used to generate and manipulate restrictions.
- It extends from the
RestrictionProviderbase class.
- restriction tracker
- It tracks for which parts of the restriction processing has been completed.
- It extends from the
RestrictionTrackerbase class.
The Python SDK has a built-in restriction (OffsetRange) and restriction tracker (OffsetRangeTracker). We will use both the built-in and custom components in this post.
An advanced SDF has the following components for watermark estimation, and we will use them in this post.
- watermark state
- It is a user-defined object. In its simplest form it could just be a timestamp.
- watermark estimator
- It tracks the watermark state when the processing of an element and restriction pair is in progress.
- It extends from the
WatermarkEstimatorbase class.
- watermark estimator provider
- It lets developers define how to initialize the watermark state and create a watermark estimator.
- It extends from the
WatermarkEstimatorProviderbase class.
For more details, visit Splittable DoFns in Python: a hands-on workshop.
Streaming File Reader
The pipeline scans an input folder periodically for new files and processes whenever new files are created in the folder. The source of this post can be found in this GitHub repository.
File Generator
The pipeline requires input files to process, and those files can be created using the file generator (faker_file_gen.py). It creates a configurable number of files (default 10) in a folder (default fake_files). Note that it generates files indefinitely if we specify the argument (-m or --max_files) to -1. Each file includes zero to two hundreds lines of text, which is generated by the Faker package.
1# utils/faker_file_gen.py
2import os
3import time
4import shutil
5import argparse
6import logging
7
8from faker import Faker
9
10
11def create_folder(file_path: str):
12 shutil.rmtree(file_path, ignore_errors=True)
13 os.mkdir(file_path)
14
15
16def write_to_file(fake: Faker, file_path: str, file_name: str):
17 with open(os.path.join(file_path, file_name), "w") as f:
18 f.writelines(fake.texts(nb_texts=fake.random_int(min=0, max=200)))
19
20
21if __name__ == "__main__":
22 parser = argparse.ArgumentParser(__file__, description="Fake Text File Generator")
23 parser.add_argument(
24 "-p",
25 "--file_path",
26 default=os.path.join(
27 os.path.dirname(os.path.dirname(os.path.realpath(__file__))), "fake_files"
28 ),
29 help="File path",
30 )
31 parser.add_argument(
32 "-m",
33 "--max_files",
34 type=int,
35 default=10,
36 help="The amount of time that a record should be delayed.",
37 )
38 parser.add_argument(
39 "-d",
40 "--delay_seconds",
41 type=float,
42 default=0.5,
43 help="The amount of time that a record should be delayed.",
44 )
45
46 args = parser.parse_args()
47
48 logging.getLogger().setLevel(logging.INFO)
49 logging.info(
50 f"Create files: max files {args.max_files}, delay seconds {args.delay_seconds}..."
51 )
52
53 fake = Faker()
54 Faker.seed(1237)
55
56 create_folder(args.file_path)
57 current = 0
58 while True:
59 write_to_file(
60 fake,
61 args.file_path,
62 f"{''.join(fake.random_letters(length=10)).lower()}.txt",
63 )
64 current += 1
65 if current % 5 == 0:
66 logging.info(f"Created {current} files so far...")
67 if current == args.max_files:
68 break
69 time.sleep(args.delay_seconds)
Once executed, we can check input files are created in a specified folder continuously.
1$ python utils/faker_file_gen.py --max_files -1 --delay_seconds 0.5
2INFO:root:Create files: max files -1, delay seconds 0.5...
3INFO:root:Created 5 files so far...
4INFO:root:Created 10 files so far...
5INFO:root:Created 15 files so far...
6
7$ tree fake_files/
8fake_files/
9├── bcgmdarvkf.txt
10├── dhmfhxwbqd.txt
11├── dzpjwroqdd.txt
12├── humlastzob.txt
13├── jfdlxdnsre.txt
14├── jpouwxftxk.txt
15├── jxfgefbnsj.txt
16├── lnazazhvpm.txt
17├── qgtyykdzdk.txt
18├── uxgrwaisgj.txt
19├── vcqlxrcqnx.txt
20├── ydlceysnkc.txt
21├── ylgvjqjhrb.txt
22├── ywwfbldecg.txt
23└── zpjinqrdyw.txt
24
251 directory, 15 files
SDF for Directory Watch
We use a custom restriction (DirectoryWatchRestriction) for the DirectoryWatchFn DoFn object. The details about the restriction and related components can be found below.
DirectoryWatchRestriction- It has two fields (already_processed and finished) where the former is used to hold the file names that have processed (i.e. claimed) already.
- To split the restriction into primary and residual, two methods are created -
as_primaryandas_residual. Theas_primaryreturns itself after updating the finished field to True, and it makes the primary restriction to be unclaimable - see the associating tracker for details. On the other hand, theas_residualmethod returns a new instance of the restriction with the existing processed file names (already_processed) and the finished field to False for subsequent processing. As can be checked in the associating tracker, the residual restriction is updated by adding a new file to process, and the processed file names can be used to identify whether the new file has already been processed or not.
DirectoryWatchRestrictionCoder- It provides a coder object for the custom restriction. Its
encode/decodemethods rely on the restriction’sto_json/from_jsonmethods.
- It provides a coder object for the custom restriction. Its
DirectoryWatchRestrictionTracker- It expects the custom restriction as an argument and returns it as the current restriction by the
current_restrictionmethod. Also, it splits the restriction into primary and residual using thetry_splitmethod. Once the restriction is split, it determines whether to claim it or not (try_claim). Specifically, it refuses to claim the restriction if it is already processed. Or it claims after adding a new file. The last part of the contract is theis_boundmethod, which signals if the current restriction represents a finite amount of work. Note that a restriction can turn from unbounded to bounded but can never turn from bounded to unbounded.
- It expects the custom restriction as an argument and returns it as the current restriction by the
DirectoryWatchRestrictionProvider- It intialises with the custom restriction where the already_processed and finished fields to an empty set and False respectively (
initial_restriction). Also, thecreate_trackermethod returns the custom restriction tracker, and the size of the restriction is returned by therestriction_sizemethod.
- It intialises with the custom restriction where the already_processed and finished fields to an empty set and False respectively (
We also employ a custom watermark estimator provider (DirectoryWatchWatermarkEstimatorProvider), and it tracks the progress in the event time. It uses ManualWatermarkEstimator to set the watermark manually from inside the process method of the DirectoryWatchFn DoFn object.
The process method of the DirectoryWatchFn DoFn adds two new arguments (tracker and watermark_estimator), which utilised the SDF components defined earlier. Also, it is wrapped by a decorator that specifies an unbounded amount of work per input element is performed (@beam.DoFn.unbounded_per_element()). Within the function, it performs the following two tasks periodically, thanks to the tracker’s defer_remainder method.
- Get new files if any
- In the
_get_new_files_if_anymethod, it creates a MyFile object for each of the files in the input folder if a file has not been processed already. A tuple of the file object and its last modified time is appended to a list named new_files, and the list is returned at the end.
- In the
- Return file objects that can be processed
- The
_check_processiblemethod tries to take all the newly discovered files and tries to claim them one by one in the restriction tracker object. If the claim fails, the method returns False and theprocessmethod immediately exits. Otherwise, it updates watermark if the last modified timestamp is larger than the current watermark. - Once the
_check_processiblemethod returns True, individual file objects are returned.
- The
1# chapter7/directory_watch.py
2import os
3import json
4import typing
5
6import apache_beam as beam
7from apache_beam import RestrictionProvider
8from apache_beam.utils.timestamp import Duration
9from apache_beam.io.iobase import RestrictionTracker
10from apache_beam.io.watermark_estimators import ManualWatermarkEstimator
11from apache_beam.transforms.core import WatermarkEstimatorProvider
12from apache_beam.runners.sdf_utils import RestrictionTrackerView
13from apache_beam.utils.timestamp import Timestamp, MIN_TIMESTAMP, MAX_TIMESTAMP
14
15from file_read import MyFile
16
17
18class DirectoryWatchRestriction:
19 def __init__(self, already_processed: typing.Set[str], finished: bool):
20 self.already_processed = already_processed
21 self.finished = finished
22
23 def as_primary(self):
24 self.finished = True
25 return self
26
27 def as_residual(self):
28 return DirectoryWatchRestriction(self.already_processed, False)
29
30 def add_new(self, file: str):
31 self.already_processed.add(file)
32
33 def size(self) -> int:
34 return 1
35
36 @classmethod
37 def from_json(cls, value: str):
38 d = json.loads(value)
39 return cls(
40 already_processed=set(d["already_processed"]), finished=d["finished"]
41 )
42
43 def to_json(self):
44 return json.dumps(
45 {
46 "already_processed": list(self.already_processed),
47 "finished": self.finished,
48 }
49 )
50
51
52class DirectoryWatchRestrictionCoder(beam.coders.Coder):
53 def encode(self, value: DirectoryWatchRestriction) -> bytes:
54 return value.to_json().encode("utf-8")
55
56 def decode(self, encoded: bytes) -> DirectoryWatchRestriction:
57 return DirectoryWatchRestriction.from_json(encoded.decode("utf-8"))
58
59 def is_deterministic(self) -> bool:
60 return True
61
62
63class DirectoryWatchRestrictionTracker(RestrictionTracker):
64 def __init__(self, restriction: DirectoryWatchRestriction):
65 self.restriction = restriction
66
67 def current_restriction(self):
68 return self.restriction
69
70 def try_claim(self, new_file: str):
71 if self.restriction.finished:
72 return False
73 self.restriction.add_new(new_file)
74 return True
75
76 def check_done(self):
77 return
78
79 def is_bounded(self):
80 return True if self.restriction.finished else False
81
82 def try_split(self, fraction_of_remainder):
83 return self.restriction.as_primary(), self.restriction.as_residual()
84
85
86class DirectoryWatchRestrictionProvider(RestrictionProvider):
87 def initial_restriction(self, element: str) -> DirectoryWatchRestriction:
88 return DirectoryWatchRestriction(set(), False)
89
90 def create_tracker(
91 self, restriction: DirectoryWatchRestriction
92 ) -> DirectoryWatchRestrictionTracker:
93 return DirectoryWatchRestrictionTracker(restriction)
94
95 def restriction_size(self, element: str, restriction: DirectoryWatchRestriction):
96 return restriction.size()
97
98 def restriction_coder(self):
99 return DirectoryWatchRestrictionCoder()
100
101
102class DirectoryWatchWatermarkEstimatorProvider(WatermarkEstimatorProvider):
103 def initial_estimator_state(self, element, restriction):
104 return MIN_TIMESTAMP
105
106 def create_watermark_estimator(self, watermark: Timestamp):
107 return ManualWatermarkEstimator(watermark)
108
109 def estimator_state_coder(self):
110 return beam.coders.TimestampCoder()
111
112
113class DirectoryWatchFn(beam.DoFn):
114 # TODO: add watermark_fn to completes the process function by advancing watermark to max timestamp
115 # without such a funcition, the pipeline never completes and we cannot perform unit testing
116 POLL_TIMEOUT = 1
117
118 @beam.DoFn.unbounded_per_element()
119 def process(
120 self,
121 element: str,
122 tracker: RestrictionTrackerView = beam.DoFn.RestrictionParam(
123 DirectoryWatchRestrictionProvider()
124 ),
125 watermark_estimater: WatermarkEstimatorProvider = beam.DoFn.WatermarkEstimatorParam(
126 DirectoryWatchWatermarkEstimatorProvider()
127 ),
128 ) -> typing.Iterable[MyFile]:
129 new_files = self._get_new_files_if_any(element, tracker)
130 if self._check_processible(tracker, watermark_estimater, new_files):
131 for new_file in new_files:
132 yield new_file[0]
133 else:
134 return
135 tracker.defer_remainder(Duration.of(self.POLL_TIMEOUT))
136
137 def _get_new_files_if_any(
138 self, element: str, tracker: DirectoryWatchRestrictionTracker
139 ) -> typing.List[typing.Tuple[MyFile, Timestamp]]:
140 new_files = []
141 for file in os.listdir(element):
142 if (
143 os.path.isfile(os.path.join(element, file))
144 and file not in tracker.current_restriction().already_processed
145 ):
146 num_lines = sum(1 for _ in open(os.path.join(element, file)))
147 new_file = MyFile(file, 0, num_lines)
148 print(new_file)
149 new_files.append(
150 (
151 new_file,
152 Timestamp.of(os.path.getmtime(os.path.join(element, file))),
153 )
154 )
155 return new_files
156
157 def _check_processible(
158 self,
159 tracker: DirectoryWatchRestrictionTracker,
160 watermark_estimater: ManualWatermarkEstimator,
161 new_files: typing.List[typing.Tuple[MyFile, Timestamp]],
162 ):
163 max_instance = watermark_estimater.current_watermark()
164 for new_file in new_files:
165 if tracker.try_claim(new_file[0].name) is False:
166 watermark_estimater.set_watermark(max_instance)
167 return False
168 if max_instance < new_file[1]:
169 max_instance = new_file[1]
170 watermark_estimater.set_watermark(max_instance)
171 return max_instance < MAX_TIMESTAMP
SDF for File Processing
The ProcessFilesFn DoFn begins with recovering the current restriction using the parameter of type RestrictionParam, which is passed as argument. Then, it tries to claim/lock the position. Once claimed, it proceeds to processing the associated element and restriction pair, which is just yielding a text that keeps the file name and current position.
1# chapter7/file_read.py
2import os
3import typing
4import logging
5
6import apache_beam as beam
7from apache_beam import RestrictionProvider
8from apache_beam.io.restriction_trackers import OffsetRange, OffsetRestrictionTracker
9
10# ...
11
12class ProcessFilesFn(beam.DoFn, RestrictionProvider):
13 def process(
14 self,
15 element: MyFile,
16 tracker: OffsetRestrictionTracker = beam.DoFn.RestrictionParam(),
17 ):
18 restriction = tracker.current_restriction()
19 for current_position in range(restriction.start, restriction.stop + 1):
20 if tracker.try_claim(current_position):
21 m = f"file: {element.name}, position: {current_position}"
22 logging.info(m)
23 yield m
24 else:
25 return
26
27 def create_tracker(self, restriction: OffsetRange) -> OffsetRestrictionTracker:
28 return OffsetRestrictionTracker(restriction)
29
30 def initial_restriction(self, element: MyFile) -> OffsetRange:
31 return OffsetRange(start=element.start, stop=element.end)
32
33 def restriction_size(self, element: MyFile, restriction: OffsetRange) -> int:
34 return restriction.size()
Beam Pipeline
The pipeline begins with passing the input folder name to the DirectoryWatchFn DoFn. Then, the DoFn yields the custom MyFile objects while scanning the input folder periodically for new files. Finally, the custom objects are processed by the ProcessFilesFn DoFn. Note that the output of the DirectoryWatchFn DoFn is shuffled using the Reshuffle transform to redistribute it to a random worker.
1# chapter7/streaming_file_read.py
2import os
3import logging
4import argparse
5
6import apache_beam as beam
7from apache_beam.transforms.util import Reshuffle
8from apache_beam.options.pipeline_options import PipelineOptions
9from apache_beam.options.pipeline_options import SetupOptions
10
11from directory_watch import DirectoryWatchFn
12from file_read import ProcessFilesFn
13
14
15def run(argv=None, save_main_session=True):
16 parser = argparse.ArgumentParser(description="Beam pipeline arguments")
17 parser.add_argument(
18 "-p",
19 "--file_path",
20 default=os.path.join(
21 os.path.dirname(os.path.dirname(os.path.realpath(__file__))), "fake_files"
22 ),
23 help="File path",
24 )
25
26 known_args, pipeline_args = parser.parse_known_args(argv)
27
28 # # We use the save_main_session option because one or more DoFn's in this
29 # # workflow rely on global context (e.g., a module imported at module level).
30 pipeline_options = PipelineOptions(pipeline_args)
31 pipeline_options.view_as(SetupOptions).save_main_session = save_main_session
32 print(f"known args - {known_args}")
33 print(f"pipeline options - {pipeline_options.display_data()}")
34
35 with beam.Pipeline(options=pipeline_options) as p:
36 (
37 p
38 | beam.Create([known_args.file_path])
39 | beam.ParDo(DirectoryWatchFn())
40 | Reshuffle()
41 | beam.ParDo(ProcessFilesFn())
42 )
43
44 logging.getLogger().setLevel(logging.INFO)
45 logging.info("Building pipeline ...")
46
47
48if __name__ == "__main__":
49 run()
We can create input files and run the pipeline using the embedded Flink Runner as shown below - it does not work with the Python Direct Runner.
1python utils/faker_file_gen.py --max_files -1 --delay_seconds 0.5
2
3python chapter7/streaming_file_read.py \
4 --runner FlinkRunner --streaming --environment_type=LOOPBACK \
5 --parallelism=3 --checkpointing_interval=10000










Comments