
The world of data is converging. The traditional divide between batch processing for historical analytics and stream processing for real-time insights is becoming increasingly blurry. Businesses demand architectures that handle both seamlessly. Enter the “Streamhouse” - an evolution of the Lakehouse concept, designed with streaming as a first-class citizen.
Today, we’ll introduce three key open-source technologies shaping this space: Apache Paimon™, Fluss, and Apache Iceberg. While each has unique strengths, their true power lies in how they can be integrated to build robust, flexible, and performant data platforms.
Let’s dive into each component:
1. Apache Paimon: The Streaming Lakehouse Table
- In Simple Terms: Think of Paimon as a specialized Lakehouse table format built from the ground up for unified streaming and batch processing. It excels where real-time updates meet analytical queries.
- Type: Stream-native Lakehouse Table Storage.
- Designed For: Managing dynamic tables that require frequent updates, deletions, or change data capture (CDC), while still being accessible for batch analytics.
- Use Cases:
- Real-time data warehousing / OLAP.
- Ingesting CDC streams (e.g., from databases).
- Building machine learning feature stores that need fresh data.
- Replacing Kappa architectures with a more manageable table abstraction.
- Strengths:
- True Streaming & Batch Unification: Natively handles both writers and readers.
- Efficient Upserts: Optimized for high-frequency inserts, updates, and deletes using merge-on-read strategies (similar to HBase/LSM-trees).
- Low Latency Updates: Achieves latency in the seconds-to-minutes range for data visibility.
- Strong Flink Integration: Developed with Apache Flink as a primary engine, offering first-class support via Flink SQL and DataStream API.
- ACID Transactions: Ensures data consistency across concurrent operations.
- Drawbacks:
- Newer ecosystem compared to Iceberg.
- Latency, while good, is not in the millisecond range like pure streaming systems.
- Origin: Originated at Alibaba, now at the Apache Software Foundation.
2. Fluss: Ultra-Low-Latency Streaming Storage
- In Simple Terms: Fluss is purpose-built pure streaming storage, optimized for getting data in and out extremely fast. It’s like a queryable, structured, columnar version of Kafka topics.
- Type: Real-time Optimized Streaming Storage.
- Designed For: Scenarios demanding the absolute lowest latency for stream ingestion and consumption.
- Use Cases:
- Real-time monitoring and alerting.
- Powering real-time dashboards and APIs.
- Feeding data into stream processing jobs with minimal delay.
- Serving as a high-speed buffer before data lands in Paimon or other storage.
- Strengths:
- Very Low Latency: Achieves millisecond-level latency for reads and writes.
- Columnar Streaming: Allows for efficient data access, including projection pushdown (reading only needed columns) directly on the stream.
- Native Flink Support: Designed to work seamlessly as a Flink source/sink.
- Structured Streaming: Unlike message queues, data has a defined schema.
- Drawbacks:
- Not designed for analytical queries over long historical periods (it’s optimized for the stream).
- Doesn’t natively support updates/deletes or ACID transactions like table formats.
- Limited ecosystem support beyond Flink currently (though intended for ASF donation).
- No built-in catalog integration; schema defined within the processing job (e.g., Flink SQL DDL).
- Origin: Originated at Ververica (derived from work at Alibaba).
3. Apache Iceberg: The Battle-Tested Batch Lakehouse Standard
- In Simple Terms: Iceberg is a widely adopted open table format primarily designed for reliable, large-scale batch analytics on data lakes. It has been progressively adding streaming capabilities.
- Type: Lakehouse Table Storage (Batch-Optimized).
- Designed For: Managing large, relatively static datasets for SQL-based analytics and BI.
- Use Cases:
- Building large-scale data lakes for BI and reporting (OLAP).
- Replacing Hive tables with better reliability and performance.
- Batch ETL/ELT processes.
- Providing a stable, versioned dataset for diverse query engines.
- Strengths:
- Massive Ecosystem: Supported by Spark, Flink, Trino, Presto, Dremio, Snowflake, major cloud vendors, and many more.
- Robustness & Scalability: Handles petabyte-scale tables reliably.
- Advanced Features: Time travel, schema evolution guarantees, hidden partitioning, ACID transactions.
- Mature and Stable: Widely deployed in production environments.
- Drawbacks:
- Streaming support is an addition, not its core design; update/CDC latencies are typically higher (minutes to hours) compared to Paimon.
- Less optimized for high-frequency concurrent writes compared to stream-native formats.
- Origin: Created by Netflix, now a top-level Apache Software Foundation project.
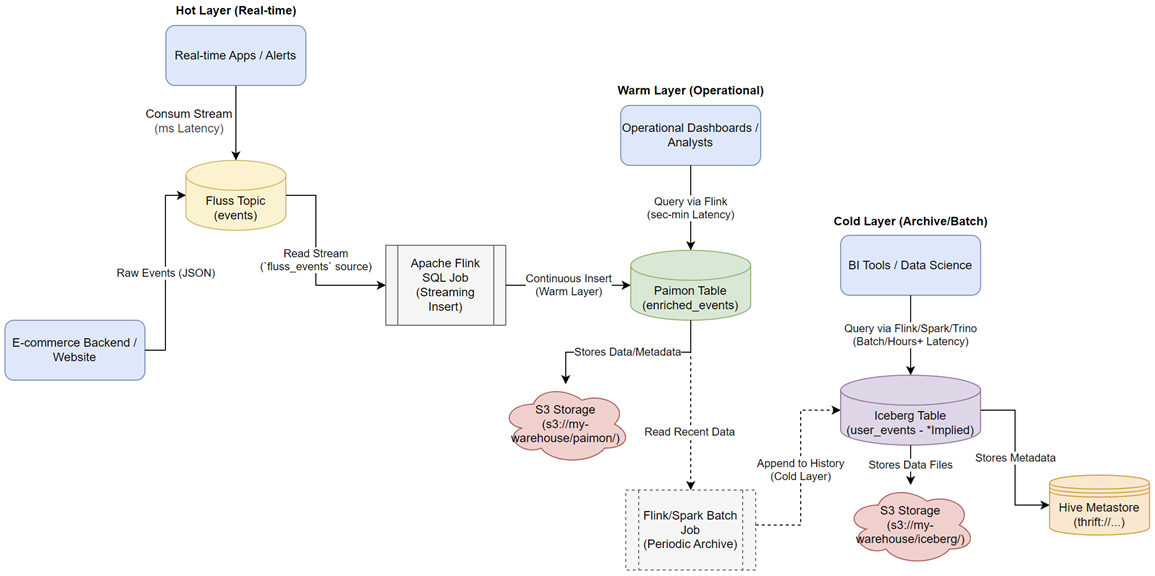
Putting It All Together: The Streamhouse Architecture
These three technologies aren’t competitors; they are complementary components of a powerful, tiered Streamhouse architecture:
- Ingestion & Real-time Access (Hot Layer): Fluss acts as the high-speed ingestion point. Data arriving here is immediately available for millisecond-latency stream processing or real-time dashboards.
- Transactional & Unified Access (Warm Layer): Data flows from Fluss (or directly ingested) into Paimon. Paimon provides durable, ACID-compliant tables supporting both real-time updates/CDC and batch/SQL queries with seconds-to-minutes freshness. This is the operational core for mixed workloads.
- Archival & Batch Analytics (Cold Layer): For long-term retention and cost-effective, large-scale batch analysis, data snapshots from Paimon (or potentially older Fluss data) can be periodically moved or archived into Iceberg. Iceberg’s broad ecosystem support makes it ideal for BI tools and large analytical jobs that don’t require sub-minute freshness.
Benefits of Integration:
- Low Latency: Fluss ensures data is actionable instantly.
- Transactional Integrity: Paimon provides reliable, mutable tables for complex workloads.
- Scalable Analytics: Iceberg offers cost-effective, deep historical analysis with wide tooling support.
- Flexibility: Choose the right storage for the right job based on latency, query patterns, and cost.
Integration with Flink and Spark
- Flink: Apache Flink shines in this architecture.
- Fluss & Paimon: Have native, first-class support in Flink. Flink SQL can treat both Fluss streams and Paimon tables as regular tables, enabling powerful unified queries across real-time and operational data.
- Iceberg: Has good Flink connector support for both batch and streaming reads/writes.
- Catalog Integration: Flink’s Catalog API works natively with Paimon (paimon catalog) and Iceberg (iceberg catalog), allowing unified metadata management. Fluss doesn’t use a catalog; its schema is defined in the job.
- Spark:
- Iceberg: Excellent, mature Spark support is a key strength of Iceberg.
- Paimon: Also provides Spark connectors for reading and writing Paimon tables, aiming for broad engine compatibility.
- Fluss: Less direct integration currently; data would typically flow through Flink to Spark or be read from Paimon/Iceberg by Spark.
Real-time User Activity Tracking for an E-commerce Platform Scenario
Imagine an e-commerce website that wants to track user actions (like clicks, page views, adding items to cart) in real-time. They have several goals:
- Immediate Reaction: Trigger actions instantly based on certain events (e.g., fraud detection on rapid clicks, real-time offer personalization).
- Operational Dashboard: Maintain an up-to-date view of user activity for the last few days, allowing analysts to query recent trends with reasonable latency (seconds to minutes). This data might need updates later (e.g., correcting event types).
- Long-term Analytics: Store all historical event data cost-effectively for large-scale batch analysis, BI reporting (e.g., monthly user engagement reports), and machine learning model training.
Conclusion
The Streamhouse concept, powered by technologies like Paimon, Fluss, and Iceberg, represents a significant step towards truly unified data architectures. By leveraging the specific strengths of each component - Fluss for speed, Paimon for unified transactional tables, and Iceberg for scalable batch analytics and archival – organizations can build platforms that are performant, flexible, and ready for both real-time demands and deep historical insights. This tiered approach, already common in large tech companies, is now becoming accessible to a wider audience through these powerful open-source projects.










Comments