
This post explores a Kotlin-based Kafka project, meticulously detailing the construction and operation of both a Kafka producer application, responsible for generating and sending order data, and a Kafka consumer application, designed to receive and process these orders. We’ll delve into each component, from build configuration to message handling, to understand how they work together in an event-driven system.
- Kafka Clients with JSON - Producing and Consuming Order Events (this post)
- Kafka Clients with Avro - Schema Registry and Order Events
- Kafka Streams - Lightweight Real-Time Processing for Supplier Stats
- Flink DataStream API - Scalable Event Processing for Supplier Stats
- Flink Table API - Declarative Analytics for Supplier Stats in Real Time
Kafka Client Applications
We will build producer and consumer apps using the IntelliJ IDEA Community edition. The source code for the applications discussed in this post can be found in the orders-json-clients folder of this GitHub repository. This project demonstrates a practical approach to developing event-driven systems with Kafka and Kotlin. Below, we’ll explore the key components that make up these applications.
Build Configuration
The build.gradle.kts file is the cornerstone of our project, defining how the Kotlin Kafka application is built and packaged using Gradle with its Kotlin DSL. It orchestrates several key aspects:
- Plugins:
kotlin("jvm"): Provides essential support for compiling Kotlin code for the Java Virtual Machine.com.github.johnrengelman.shadow: Creates a “fat JAR” (or “uber JAR”), bundling the application and all its dependencies into a single, easily deployable executable file.application: Configures the project as a runnable application, specifying its main entry point.
- Dependencies:
org.apache.kafka:kafka-clients: The official Kafka client library for interacting with Kafka brokers.com.fasterxml.jackson.module:jackson-module-kotlin: Enables seamless JSON serialization and deserialization for Kotlin data classes using the Jackson library.io.github.microutils:kotlin-logging-jvm&ch.qos.logback:logback-classic: A combination for flexible and robust logging capabilities.net.datafaker:datafaker: Used to generate realistic mock data for theOrderobjects.kotlin("test"): Supports writing unit tests for the application.
- Key Configurations:
- Specifies Java 17 as the target JVM via
jvmToolchain(17). - Sets
me.jaehyeon.MainKtas themainClassfor execution. - The
shadowJartask is configured to name the output artifactorders-json-clients-1.0.jarand to correctly merge service files from dependencies.
- Specifies Java 17 as the target JVM via
1plugins {
2 kotlin("jvm") version "2.1.20"
3 id("com.github.johnrengelman.shadow") version "8.1.1"
4 application
5}
6
7group = "me.jaehyeon"
8version = "1.0-SNAPSHOT"
9
10repositories {
11 mavenCentral()
12}
13
14dependencies {
15 // Kafka
16 implementation("org.apache.kafka:kafka-clients:3.9.0")
17 // JSON (using Jackson)
18 implementation("com.fasterxml.jackson.module:jackson-module-kotlin:2.17.0")
19 // Logging
20 implementation("io.github.microutils:kotlin-logging-jvm:3.0.5")
21 implementation("ch.qos.logback:logback-classic:1.5.13")
22 // Faker
23 implementation("net.datafaker:datafaker:2.1.0")
24 // Test
25 testImplementation(kotlin("test"))
26}
27
28kotlin {
29 jvmToolchain(17)
30}
31
32application {
33 mainClass.set("me.jaehyeon.MainKt")
34}
35
36tasks.named<com.github.jengelman.gradle.plugins.shadow.tasks.ShadowJar>("shadowJar") {
37 archiveBaseName.set("orders-json-clients")
38 archiveClassifier.set("")
39 archiveVersion.set("1.0")
40 mergeServiceFiles()
41}
42
43tasks.named("build") {
44 dependsOn("shadowJar")
45}
46
47tasks.test {
48 useJUnitPlatform()
49}
Data Model
At the heart of the messages exchanged is the me.jaehyeon.model.Order data class. This Kotlin data class concisely defines the structure of an “order” event. It includes fields like orderId (a unique string), bidTime (a string timestamp), price (a double), item (a string for the product name), and supplier (a string). Importantly, all properties are declared with default values (e.g., "" for strings, 0.0 for doubles). This design choice is crucial for JSON deserialization libraries like Jackson, which often require a no-argument constructor to instantiate objects, a feature Kotlin data classes don’t automatically provide if all properties are constructor parameters without defaults.
1package me.jaehyeon.model
2
3// Java classes usually have a default constructor automatically, but not Kotlin data classes.
4// Jackson expects a default way to instantiate objects unless you give it detailed instructions.
5data class Order(
6 val orderId: String = "",
7 val bidTime: String = "",
8 val price: Double = 0.0,
9 val item: String = "",
10 val supplier: String = "",
11)
Custom JSON (De)Serializers
To convert our Kotlin Order objects into byte arrays for Kafka transmission and vice-versa, the me.jaehyeon.serializer package provides custom implementations.
The JsonSerializer<T> class implements Kafka’s Serializer<T> interface. It uses Jackson’s ObjectMapper to transform any given object T into a JSON byte array. This ObjectMapper is specifically configured with PropertyNamingStrategies.SNAKE_CASE, ensuring that Kotlin’s camelCase property names (e.g., orderId) are serialized as snake_case (e.g., order_id) in the JSON output.
Complementing this, the JsonDeserializer<T> class implements Kafka’s Deserializer<T> interface. It takes a targetClass (such as Order::class.java) during its instantiation and uses a similarly configured ObjectMapper (also with SNAKE_CASE strategy) to convert incoming JSON byte arrays back into objects of that specified type.
JsonSerializer.kt
1package me.jaehyeon.serializer
2
3import com.fasterxml.jackson.databind.ObjectMapper
4import com.fasterxml.jackson.databind.PropertyNamingStrategies
5import org.apache.kafka.common.serialization.Serializer
6
7class JsonSerializer<T> : Serializer<T> {
8 private val objectMapper =
9 ObjectMapper()
10 .setPropertyNamingStrategy(PropertyNamingStrategies.SNAKE_CASE)
11
12 override fun serialize(
13 topic: String?,
14 data: T?,
15 ): ByteArray? = data?.let { objectMapper.writeValueAsBytes(it) }
16}
JsonDeserializer.kt
1package me.jaehyeon.serializer
2
3import com.fasterxml.jackson.databind.ObjectMapper
4import com.fasterxml.jackson.databind.PropertyNamingStrategies
5import org.apache.kafka.common.serialization.Deserializer
6
7class JsonDeserializer<T>(
8 private val targetClass: Class<T>,
9) : Deserializer<T> {
10 private val objectMapper =
11 ObjectMapper()
12 .setPropertyNamingStrategy(PropertyNamingStrategies.SNAKE_CASE)
13
14 override fun deserialize(
15 topic: String?,
16 data: ByteArray?,
17 ): T? = data?.let { objectMapper.readValue(it, targetClass) }
18}
Kafka Admin Utilities
The me.jaehyeon.kafka package houses utility functions for administrative Kafka tasks, primarily topic creation and connection verification.
The createTopicIfNotExists function proactively ensures that the target Kafka topic (e.g., “orders-json”) is available before the application attempts to use it. It uses Kafka’s AdminClient, configured with the bootstrap server address and appropriate timeouts, to attempt topic creation with a specified number of partitions and replication factor. A key feature is its ability to gracefully handle TopicExistsException, allowing the application to continue smoothly if the topic already exists or was created concurrently.
The verifyKafkaConnection function serves as a quick pre-flight check, especially for the consumer. It also employs an AdminClient to try listing topics on the cluster. If this fails, it throws a RuntimeException, signaling a connectivity issue with the Kafka brokers and preventing the application from starting in a potentially faulty state.
1package me.jaehyeon.kafka
2
3import mu.KotlinLogging
4import org.apache.kafka.clients.admin.AdminClient
5import org.apache.kafka.clients.admin.AdminClientConfig
6import org.apache.kafka.clients.admin.NewTopic
7import org.apache.kafka.common.errors.TopicExistsException
8import java.util.Properties
9import java.util.concurrent.ExecutionException
10
11private val logger = KotlinLogging.logger { }
12
13fun createTopicIfNotExists(
14 topicName: String,
15 bootstrapAddress: String,
16 numPartitions: Int,
17 replicationFactor: Short,
18) {
19 val props =
20 Properties().apply {
21 put(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapAddress)
22 put(AdminClientConfig.DEFAULT_API_TIMEOUT_MS_CONFIG, "5000")
23 put(AdminClientConfig.REQUEST_TIMEOUT_MS_CONFIG, "3000")
24 put(AdminClientConfig.RETRIES_CONFIG, "1")
25 }
26
27 AdminClient.create(props).use { client ->
28 val newTopic = NewTopic(topicName, numPartitions, replicationFactor)
29 val result = client.createTopics(listOf(newTopic))
30
31 try {
32 logger.info { "Attempting to create topic '$topicName'..." }
33 result.all().get()
34 logger.info { "Topic '$topicName' created successfully!" }
35 } catch (e: ExecutionException) {
36 if (e.cause is TopicExistsException) {
37 logger.warn { "Topic '$topicName' was created concurrently or already existed. Continuing..." }
38 } else {
39 throw RuntimeException("Unrecoverable error while creating a topic '$topicName'.", e)
40 }
41 }
42 }
43}
44
45fun verifyKafkaConnection(bootstrapAddress: String) {
46 val props =
47 Properties().apply {
48 put(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapAddress)
49 put(AdminClientConfig.DEFAULT_API_TIMEOUT_MS_CONFIG, "5000")
50 put(AdminClientConfig.REQUEST_TIMEOUT_MS_CONFIG, "3000")
51 put(AdminClientConfig.RETRIES_CONFIG, "1")
52 }
53
54 AdminClient.create(props).use { client ->
55 try {
56 client.listTopics().names().get()
57 } catch (e: Exception) {
58 throw RuntimeException("Failed to connect to Kafka at'$bootstrapAddress'.", e)
59 }
60 }
61}
Kafka Producer
The me.jaehyeon.ProducerApp object is responsible for generating Order messages and publishing them to a Kafka topic. Its operations include:
- Configuration:
- Reads the Kafka
BOOTSTRAP_ADDRESSand targetTOPIC_NAME(defaulting to “orders-json”) from environment variables, allowing for flexible deployment. - Defines constants like
NUM_PARTITIONSandREPLICATION_FACTORfor topic creation if needed.
- Reads the Kafka
- Initialization (
runmethod):- First, it calls
createTopicIfNotExists(from the admin utilities) to ensure the output topic is ready. - It then configures and instantiates a
KafkaProducer, setting properties like bootstrap servers, usingStringSerializerfor message keys, and our customJsonSerializerfor theOrderobject values. - Retry mechanisms and timeout settings (
REQUEST_TIMEOUT_MS_CONFIG,DELIVERY_TIMEOUT_MS_CONFIG,MAX_BLOCK_MS_CONFIG) are configured for enhanced robustness.
- First, it calls
- Message Production Loop:
- Continuously generates new
Orderobjects usingDatafakerfor random yet plausible data. This includes generating a UUID fororderIdand a formatted recent timestamp viagenerateBidTime().- Note that
bidTimeis delayed by an amount of seconds configured by an environment variable namedDELAY_SECONDS, which is useful for testing late data handling.
- Note that
- Wraps each
Orderin aProducerRecord, using theorderIdas the message key. - Sends the record using
producer.send(). The call to.get()on the returnedFuturemakes this send operation synchronous for this example, waiting for acknowledgment. A callback logs success (topic, partition, offset) or any exceptions. - Pauses for one second between messages to simulate a steady event stream.
- Continuously generates new
- Error Handling: Includes
try-catchblocks to handle potentialExecutionExceptionorKafkaExceptionduring the send process.
1package me.jaehyeon
2
3import me.jaehyeon.kafka.createTopicIfNotExists
4import me.jaehyeon.model.Order
5import me.jaehyeon.serializer.JsonSerializer
6import mu.KotlinLogging
7import net.datafaker.Faker
8import org.apache.kafka.clients.producer.KafkaProducer
9import org.apache.kafka.clients.producer.ProducerConfig
10import org.apache.kafka.clients.producer.ProducerRecord
11import org.apache.kafka.common.KafkaException
12import java.time.ZoneId
13import java.time.format.DateTimeFormatter
14import java.util.Properties
15import java.util.UUID
16import java.util.concurrent.ExecutionException
17import java.util.concurrent.TimeUnit
18
19object ProducerApp {
20 private val bootstrapAddress = System.getenv("BOOTSTRAP_ADDRESS") ?: "localhost:9092"
21 private val inputTopicName = System.getenv("TOPIC_NAME") ?: "orders-json"
22 private val delaySeconds = System.getenv("DELAY_SECONDS")?.toIntOrNull() ?: 5
23 private const val NUM_PARTITIONS = 3
24 private const val REPLICATION_FACTOR: Short = 3
25 private val logger = KotlinLogging.logger { }
26 private val faker = Faker()
27
28 fun run() {
29 // Create the input topic if not existing
30 createTopicIfNotExists(inputTopicName, bootstrapAddress, NUM_PARTITIONS, REPLICATION_FACTOR)
31
32 val props =
33 Properties().apply {
34 put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapAddress)
35 put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer")
36 put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, JsonSerializer::class.java.name)
37 put(ProducerConfig.RETRIES_CONFIG, "3")
38 put(ProducerConfig.REQUEST_TIMEOUT_MS_CONFIG, "3000")
39 put(ProducerConfig.DELIVERY_TIMEOUT_MS_CONFIG, "6000")
40 put(ProducerConfig.MAX_BLOCK_MS_CONFIG, "3000")
41 }
42
43 KafkaProducer<String, Order>(props).use { producer ->
44 while (true) {
45 val order =
46 Order(
47 UUID.randomUUID().toString(),
48 generateBidTime(),
49 faker.number().randomDouble(2, 1, 150),
50 faker.commerce().productName(),
51 faker.regexify("(Alice|Bob|Carol|Alex|Joe|James|Jane|Jack)"),
52 )
53 val record = ProducerRecord(inputTopicName, order.orderId, order)
54 try {
55 producer
56 .send(record) { metadata, exception ->
57 if (exception != null) {
58 logger.error(exception) { "Error sending record" }
59 } else {
60 logger.info {
61 "Sent to ${metadata.topic()} into partition ${metadata.partition()}, offset ${metadata.offset()}"
62 }
63 }
64 }.get()
65 } catch (e: ExecutionException) {
66 throw RuntimeException("Unrecoverable error while sending record.", e)
67 } catch (e: KafkaException) {
68 throw RuntimeException("Kafka error while sending record.", e)
69 }
70
71 Thread.sleep(1000L)
72 }
73 }
74 }
75
76 private fun generateBidTime(): String {
77 val randomDate = faker.date().past(delaySeconds, TimeUnit.SECONDS)
78 val formatter =
79 DateTimeFormatter
80 .ofPattern("yyyy-MM-dd HH:mm:ss")
81 .withZone(ZoneId.systemDefault())
82 return formatter.format(randomDate.toInstant())
83 }
84}
Kafka Consumer
The me.jaehyeon.ConsumerApp object is designed to subscribe to the Kafka topic, fetch the Order messages, and process them. Its key functionalities are:
- Configuration:
- Retrieves
BOOTSTRAP_ADDRESSandTOPIC_NAMEfrom environment variables.
- Retrieves
- Initialization (
runmethod):- Begins by calling
verifyKafkaConnection(from admin utilities) to check Kafka cluster accessibility. - Configures and creates a
KafkaConsumer. Essential properties includeGROUP_ID_CONFIG(e.g., “orders-json-group” for consumer group coordination),StringDeserializerfor keys, and an instance of our customJsonDeserializer(Order::class.java)for message values. - Disables auto-commit (
ENABLE_AUTO_COMMIT_CONFIG = false) for manual offset control and setsAUTO_OFFSET_RESET_CONFIG = "earliest"to start reading from the beginning of the topic for new consumer groups.
- Begins by calling
- Graceful Shutdown:
- A
Runtime.getRuntime().addShutdownHookis registered. On a shutdown signal (e.g., Ctrl+C), it sets akeepConsumingflag tofalseand callsconsumer.wakeup(). This action causesconsumer.poll()to throw aWakeupException, allowing the consumption loop to terminate cleanly.
- A
- Message Consumption Loop:
- The consumer subscribes to the specified topic.
- In a
while (keepConsuming)loop:pollSafely()is called to fetch records. This wrapper robustly handlesWakeupExceptionfor shutdown and logs other polling errors.- Each received
ConsumerRecordis processed byprocessRecordWithRetry(). This method logs theOrderdetails and includes a retry mechanism for simulated errors (currently,ERROR_THRESHOLDis set to -1, disabling simulated errors). If an error occurs, it retries up toMAX_RETRIESwith exponential backoff. If all retries fail, the error is logged, and the message is skipped. - After processing a batch,
consumer.commitSync()is called to manually commit offsets.
- Error Handling: A general
try-catchblock surrounds the main consumption logic for unrecoverable errors.
1package me.jaehyeon
2
3import me.jaehyeon.kafka.verifyKafkaConnection
4import me.jaehyeon.model.Order
5import me.jaehyeon.serializer.JsonDeserializer
6import mu.KotlinLogging
7import org.apache.kafka.clients.consumer.ConsumerConfig
8import org.apache.kafka.clients.consumer.ConsumerRecord
9import org.apache.kafka.clients.consumer.KafkaConsumer
10import org.apache.kafka.common.errors.WakeupException
11import org.apache.kafka.common.serialization.StringDeserializer
12import java.time.Duration
13import java.util.Properties
14
15object ConsumerApp {
16 private val bootstrapAddress = System.getenv("BOOTSTRAP_ADDRESS") ?: "localhost:9092"
17 private val topicName = System.getenv("TOPIC_NAME") ?: "orders-json"
18 private val logger = KotlinLogging.logger { }
19 private const val MAX_RETRIES = 3
20 private const val ERROR_THRESHOLD = -1
21
22 @Volatile
23 private var keepConsuming = true
24
25 fun run() {
26 // Verify kafka connection
27 verifyKafkaConnection(bootstrapAddress)
28
29 val props =
30 Properties().apply {
31 put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapAddress)
32 put(ConsumerConfig.GROUP_ID_CONFIG, "$topicName-group")
33 put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer")
34 put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, Order::class.java.name)
35 put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false)
36 put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest")
37 put(ConsumerConfig.DEFAULT_API_TIMEOUT_MS_CONFIG, "5000")
38 put(ConsumerConfig.REQUEST_TIMEOUT_MS_CONFIG, "3000")
39 }
40
41 val consumer =
42 KafkaConsumer<String, Order>(
43 props,
44 StringDeserializer(),
45 JsonDeserializer(Order::class.java),
46 )
47
48 Runtime.getRuntime().addShutdownHook(
49 Thread {
50 logger.info("Shutdown detected. Waking up Kafka consumer...")
51 keepConsuming = false
52 consumer.wakeup()
53 },
54 )
55
56 try {
57 consumer.use { c ->
58 c.subscribe(listOf(topicName))
59 while (keepConsuming) {
60 val records = pollSafely(c)
61 for (record in records) {
62 processRecordWithRetry(record)
63 }
64 consumer.commitSync()
65 }
66 }
67 } catch (e: Exception) {
68 RuntimeException("Unrecoverable error while consuming record.", e)
69 }
70 }
71
72 private fun pollSafely(consumer: KafkaConsumer<String, Order>) =
73 runCatching { consumer.poll(Duration.ofMillis(1000)) }
74 .getOrElse { e ->
75 when (e) {
76 is WakeupException -> {
77 if (keepConsuming) throw e
78 logger.info { "ConsumerApp wakeup for shutdown." }
79 emptyList()
80 }
81 else -> {
82 logger.error(e) { "Unexpected error while polling records" }
83 emptyList()
84 }
85 }
86 }
87
88 private fun processRecordWithRetry(record: ConsumerRecord<String, Order>) {
89 var attempt = 0
90 while (attempt < MAX_RETRIES) {
91 try {
92 attempt++
93 if ((0..99).random() < ERROR_THRESHOLD) {
94 throw RuntimeException(
95 "Simulated error for ${record.value()} from partition ${record.partition()}, offset ${record.offset()}",
96 )
97 }
98 logger.info { "Received ${record.value()} from partition ${record.partition()}, offset ${record.offset()}" }
99 return
100 } catch (e: Exception) {
101 logger.warn(e) { "Error processing record (attempt $attempt of $MAX_RETRIES)" }
102 if (attempt == MAX_RETRIES) {
103 logger.error(e) { "Failed to process record after $MAX_RETRIES attempts, skipping..." }
104 return
105 }
106 Thread.sleep(500L * attempt.toLong()) // exponential backoff
107 }
108 }
109 }
110}
Application Entry Point
The me.jaehyeon.MainKt file provides the main function, serving as the application’s command-line dispatcher. It examines the first command-line argument (args.getOrNull(0)). If it’s “producer” (case-insensitive), ProducerApp.run() is executed. If it’s “consumer”, ConsumerApp.run() is called. For any other input, or if no argument is provided, it prints a usage message. The entire logic is enclosed in a try-catch block to capture and log any fatal unhandled exceptions, ensuring the application exits with an error code (exitProcess(1)) if such an event occurs.
1package me.jaehyeon
2
3import mu.KotlinLogging
4import kotlin.system.exitProcess
5
6private val logger = KotlinLogging.logger {}
7
8fun main(args: Array<String>) {
9 try {
10 when (args.getOrNull(0)?.lowercase()) {
11 "producer" -> ProducerApp.run()
12 "consumer" -> ConsumerApp.run()
13 else -> println("Usage: <producer|consumer>")
14 }
15 } catch (e: Exception) {
16 logger.error(e) { "Fatal error in ${args.getOrNull(0) ?: "app"}. Shutting down." }
17 exitProcess(1)
18 }
19}
Run Kafka Applications
We begin by setting up our local Kafka environment using the Factor House Local project. This project conveniently provisions a Kafka cluster along with Kpow, a powerful tool for Kafka management and control, all managed via Docker Compose. Once our Kafka environment is running, we will start our Kotlin-based producer and consumer applications.
Factor House Local
To get our Kafka cluster and Kpow up and running, we’ll first need to clone the project repository and navigate into its directory. Then, we can start the services using Docker Compose as shown below. Note that we need to have a community license for Kpow to get started. See this section of the project README for details on how to request a license and configure it before proceeding with the docker compose command.
1git clone https://github.com/factorhouse/factorhouse-local.git
2cd factorhouse-local
3docker compose -f compose-kpow-community.yml up -d
Once the services are initialized, we can access the Kpow user interface by navigating to http://localhost:3000 in the web browser, where we observe the provisioned environment, including three Kafka brokers, one schema registry, and one Kafka Connect instance.

Launch Applications
Our Kotlin Kafka applications can be launched in a couple of ways, catering to different stages of development and deployment:
- With Gradle (Development Mode): This method is convenient during development, allowing for quick iterations without needing to build a full JAR file each time.
- Running the Shadow JAR (Deployment Mode): After building a “fat” JAR (also known as a shadow JAR) that includes all dependencies, the application can be run as a standalone executable. This is typical for deploying to non-development environments.
💡 To build and run the application locally, ensure that JDK 17 is installed.
1# 👉 With Gradle (Dev Mode)
2./gradlew run --args="producer"
3./gradlew run --args="consumer"
4
5# 👉 Build Shadow (Fat) JAR:
6./gradlew shadowJar
7
8# Resulting JAR:
9# build/libs/orders-json-clients-1.0.jar
10
11# 👉 Run the Fat JAR:
12java -jar build/libs/orders-json-clients-1.0.jar producer
13java -jar build/libs/orders-json-clients-1.0.jar consumer
For this post, we demonstrate starting the applications in development mode using Gradle. Once started, we see logs from both the producer sending messages and the consumer receiving them.

With the applications running and producing/consuming data, we can inspect the messages flowing through our orders-json topic using Kpow. In the Kpow UI, navigate to your topic. To correctly view the messages, we should configure the deserializers: set the Key Deserializer to String and the Value Deserializer to JSON. After applying these settings, click the Search button to view the messages.

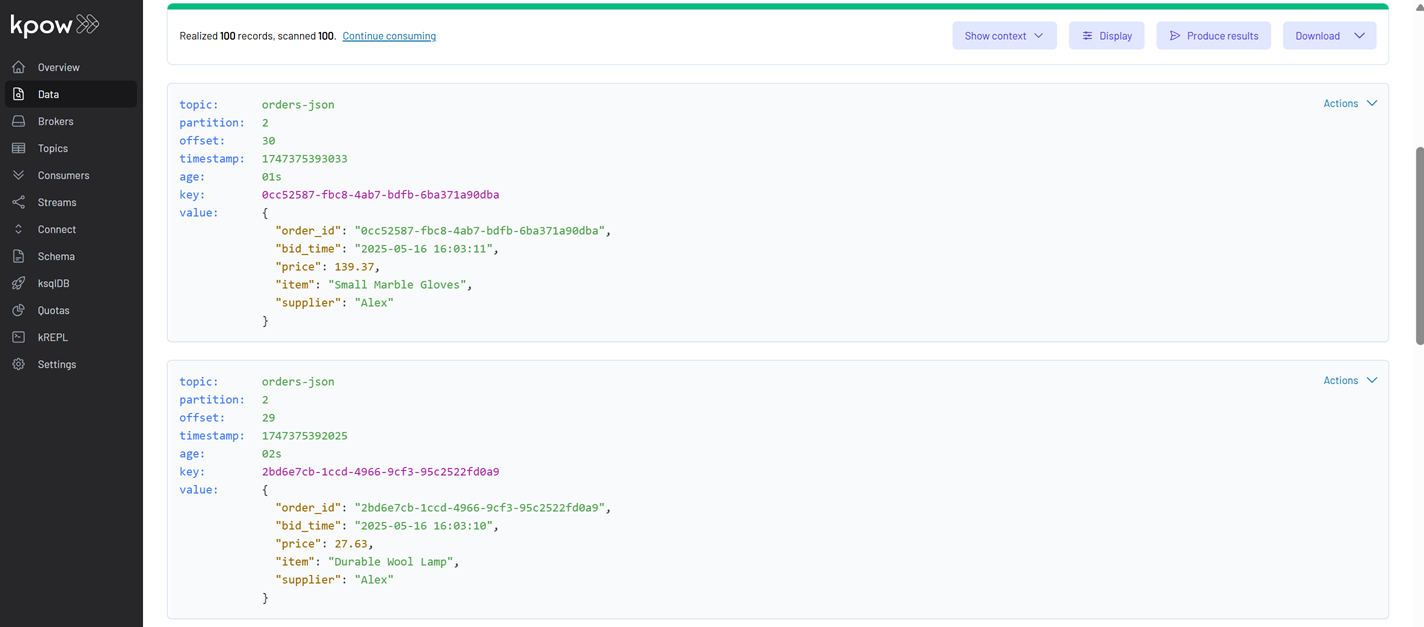
Conclusion
This post detailed the creation of Kotlin Kafka producer and consumer applications for handling JSON order data. We covered project setup, data modeling, custom serialization, client logic with error handling, deployment against a local Kafka cluster using the Factor House Local project with Kpow.










Comments