
In this post, we shift our focus from basic Kafka clients to real-time stream processing with Kafka Streams. We’ll explore a Kotlin application designed to analyze a continuous stream of Avro-formatted order events, calculate supplier statistics in tumbling windows, and intelligently handle late-arriving data. This example demonstrates the power of Kafka Streams for building lightweight, yet robust, stream processing applications directly within your Kafka ecosystem, leveraging event-time processing and custom logic.
- Kafka Clients with JSON - Producing and Consuming Order Events
- Kafka Clients with Avro - Schema Registry and Order Events
- Kafka Streams - Lightweight Real-Time Processing for Supplier Stats (this post)
- Flink DataStream API - Scalable Event Processing for Supplier Stats
- Flink Table API - Declarative Analytics for Supplier Stats in Real Time
Kafka Streams Application for Supplier Statistics
This project showcases a Kafka Streams application that:
- Consumes Avro-formatted order data from an input Kafka topic.
- Extracts event timestamps from the order data to enable accurate time-based processing.
- Proactively identifies and separates late-arriving records.
- Aggregates order data to compute supplier statistics (total price and count) within defined time windows.
- Outputs the calculated statistics and late records to separate Kafka topics.
The source code for the application discussed in this post can be found in the orders-stats-streams folder of this GitHub repository.
The Build Configuration
The build.gradle.kts file orchestrates the build, dependencies, and packaging of our Kafka Streams application.
- Plugins:
kotlin("jvm"): Enables Kotlin language support for the JVM.com.github.davidmc24.gradle.plugin.avro: Manages Avro schema compilation into Java classes.com.github.johnrengelman.shadow: Creates a “fat JAR” containing all dependencies.application: Configures the project as a runnable application.
- Repositories:
mavenCentral(): Standard Maven repository.maven("https://packages.confluent.io/maven/"): Confluent repository for Kafka Streams Avro SerDes and other Confluent components.
- Dependencies:
- Kafka:
org.apache.kafka:kafka-clientsand importantly,org.apache.kafka:kafka-streamsfor the stream processing DSL and Processor API. - Avro:
org.apache.avro:avrofor the core Avro library.io.confluent:kafka-streams-avro-serdefor Confluent’s Kafka Streams Avro SerDes, which integrate with Schema Registry.
- JSON:
com.fasterxml.jackson.module:jackson-module-kotlinfor serializing late records to JSON. - Logging:
io.github.microutils:kotlin-logging-jvmandch.qos.logback:logback-classic.
- Kafka:
- Application Configuration:
mainClass.set("me.jaehyeon.MainKt"): Defines the application’s entry point.- The
runtask is configured with environment variables (BOOTSTRAP,TOPIC,REGISTRY_URL) for Kafka connection details, simplifying local execution.
- Avro Configuration:
- The
avroblock customizes Avro code generation (e.g.,setCreateSetters(false)). tasks.named("compileKotlin") { dependsOn("generateAvroJava") }ensures Avro classes are generated before Kotlin compilation.- Generated Avro Java sources are added to the
mainsource set.
- The
- Shadow JAR Configuration:
- Configures the output fat JAR name (
orders-stats-streams) and version. mergeServiceFiles()handles merging service provider files from dependencies.
- Configures the output fat JAR name (
1plugins {
2 kotlin("jvm") version "2.1.20"
3 id("com.github.davidmc24.gradle.plugin.avro") version "1.9.1"
4 id("com.github.johnrengelman.shadow") version "8.1.1"
5 application
6}
7
8group = "me.jaehyeon"
9version = "1.0-SNAPSHOT"
10
11repositories {
12 mavenCentral()
13 maven("https://packages.confluent.io/maven/")
14}
15
16dependencies {
17 // Kafka
18 implementation("org.apache.kafka:kafka-clients:3.9.0")
19 implementation("org.apache.kafka:kafka-streams:3.9.0")
20 // AVRO
21 implementation("org.apache.avro:avro:1.11.4")
22 implementation("io.confluent:kafka-streams-avro-serde:7.9.0")
23 // Json
24 implementation("com.fasterxml.jackson.module:jackson-module-kotlin:2.13.0")
25 // Logging
26 implementation("io.github.microutils:kotlin-logging-jvm:3.0.5")
27 implementation("ch.qos.logback:logback-classic:1.5.13")
28 // Test
29 testImplementation(kotlin("test"))
30}
31
32kotlin {
33 jvmToolchain(17)
34}
35
36application {
37 mainClass.set("me.jaehyeon.MainKt")
38}
39
40avro {
41 setCreateSetters(false)
42 setFieldVisibility("PRIVATE")
43}
44
45tasks.named("compileKotlin") {
46 dependsOn("generateAvroJava")
47}
48
49sourceSets {
50 named("main") {
51 java.srcDirs("build/generated/avro/main")
52 kotlin.srcDirs("src/main/kotlin")
53 }
54}
55
56tasks.withType<com.github.jengelman.gradle.plugins.shadow.tasks.ShadowJar> {
57 archiveBaseName.set("orders-stats-streams")
58 archiveClassifier.set("")
59 archiveVersion.set("1.0")
60 mergeServiceFiles()
61}
62
63tasks.named("build") {
64 dependsOn("shadowJar")
65}
66
67tasks.named<JavaExec>("run") {
68 environment("BOOTSTRAP", "localhost:9092")
69 environment("TOPIC", "orders-avro")
70 environment("REGISTRY_URL", "http://localhost:8081")
71}
72
73tasks.test {
74 useJUnitPlatform()
75}
Avro Schema for Aggregated Statistics
The SupplierStats.avsc file defines the Avro schema for the output of our stream aggregation. This ensures type safety and schema evolution for the processed statistics.
- Type: A
recordnamedSupplierStatswithin theme.jaehyeon.avronamespace. - Fields:
window_start(string): Marks the beginning of the aggregation window.window_end(string): Marks the end of the aggregation window.supplier(string): The identifier for the supplier.total_price(double): The sum of order prices for the supplier within the window.count(long): The number of orders for the supplier within the window.
- Usage: This schema is used by the
SpecificAvroSerdeto serialize the aggregatedSupplierStatsobjects before they are written to the output Kafka topic.
1{
2 "type": "record",
3 "name": "SupplierStats",
4 "namespace": "me.jaehyeon.avro",
5 "fields": [
6 { "name": "window_start", "type": "string" },
7 { "name": "window_end", "type": "string" },
8 { "name": "supplier", "type": "string" },
9 { "name": "total_price", "type": "double" },
10 { "name": "count", "type": "long" }
11 ]
12}
Kafka Admin Utilities
The Utils.kt file provides a helper function for Kafka topic management, ensuring that necessary topics exist before the stream processing begins.
createTopicIfNotExists(...):- This function uses Kafka’s
AdminClientto programmatically create Kafka topics. - It takes the topic name, bootstrap server address, number of partitions, and replication factor as parameters.
- It’s designed to be idempotent: if the topic already exists (due to prior creation or concurrent attempts), it logs a warning and proceeds without error, preventing application startup failures.
- For other errors during topic creation, it throws a runtime exception.
- This function uses Kafka’s
1package me.jaehyeon.kafka
2
3import mu.KotlinLogging
4import org.apache.kafka.clients.admin.AdminClient
5import org.apache.kafka.clients.admin.AdminClientConfig
6import org.apache.kafka.clients.admin.NewTopic
7import org.apache.kafka.common.errors.TopicExistsException
8import java.util.Properties
9import java.util.concurrent.ExecutionException
10import kotlin.use
11
12private val logger = KotlinLogging.logger { }
13
14fun createTopicIfNotExists(
15 topicName: String,
16 bootstrapAddress: String,
17 numPartitions: Int,
18 replicationFactor: Short,
19) {
20 val props =
21 Properties().apply {
22 put(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapAddress)
23 put(AdminClientConfig.DEFAULT_API_TIMEOUT_MS_CONFIG, "5000")
24 put(AdminClientConfig.REQUEST_TIMEOUT_MS_CONFIG, "3000")
25 put(AdminClientConfig.RETRIES_CONFIG, "1")
26 }
27
28 AdminClient.create(props).use { client ->
29 val newTopic = NewTopic(topicName, numPartitions, replicationFactor)
30 val result = client.createTopics(listOf(newTopic))
31
32 try {
33 logger.info { "Attempting to create topic '$topicName'..." }
34 result.all().get()
35 logger.info { "Topic '$topicName' created successfully!" }
36 } catch (e: ExecutionException) {
37 if (e.cause is TopicExistsException) {
38 logger.warn { "Topic '$topicName' was created concurrently or already existed. Continuing..." }
39 } else {
40 throw RuntimeException("Unrecoverable error while creating a topic '$topicName'.", e)
41 }
42 }
43 }
44}
Custom Timestamp Extraction
For accurate event-time processing, Kafka Streams needs to know the actual time an event occurred, not just when it arrived at Kafka. The BidTimeTimestampExtractor customizes this logic.
- Implementation: Implements the
TimestampExtractorinterface. - Logic:
- It attempts to parse a
bid_timefield (expected format: “yyyy-MM-dd HH:mm:ss”) from the incoming AvroGenericRecord. - The parsed string is converted to epoch milliseconds.
- It attempts to parse a
- Error Handling:
- If the
bid_timefield is missing, blank, or cannot be parsed (e.g., due toDateTimeParseException), the extractor logs the issue and gracefully falls back to using thepartitionTime(the timestamp assigned by Kafka, typically close to ingestion time). This ensures the stream doesn’t halt due to malformed data.
- If the
- Significance: Using event time extracted from the data payload allows windowed operations to be based on when events truly happened, leading to more meaningful aggregations, especially in systems where data might arrive out of order or with delays.
1package me.jaehyeon.streams.extractor
2
3import mu.KotlinLogging
4import org.apache.avro.generic.GenericRecord
5import org.apache.kafka.clients.consumer.ConsumerRecord
6import org.apache.kafka.streams.processor.TimestampExtractor
7import java.time.LocalDateTime
8import java.time.ZoneId
9import java.time.format.DateTimeFormatter
10import java.time.format.DateTimeParseException
11
12class BidTimeTimestampExtractor : TimestampExtractor {
13 private val formatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss")
14 private val logger = KotlinLogging.logger { }
15
16 override fun extract(
17 record: ConsumerRecord<Any, Any>,
18 partitionTime: Long,
19 ): Long =
20 try {
21 val value = record.value() as? GenericRecord
22 val bidTime = value?.get("bid_time")?.toString()
23 when {
24 bidTime.isNullOrBlank() -> {
25 logger.warn { "Missing or blank 'bid_time'. Falling back to partitionTime: $partitionTime" }
26 partitionTime
27 }
28 else -> {
29 val parsedTimestamp =
30 LocalDateTime
31 .parse(bidTime, formatter)
32 .atZone(ZoneId.systemDefault())
33 .toInstant()
34 .toEpochMilli()
35 logger.debug { "Extracted timestamp $parsedTimestamp from bid_time '$bidTime'" }
36 parsedTimestamp
37 }
38 }
39 } catch (e: Exception) {
40 when (e.cause) {
41 is DateTimeParseException -> {
42 logger.error(e) { "Failed to parse 'bid_time'. Falling back to partitionTime: $partitionTime" }
43 partitionTime
44 }
45 else -> {
46 logger.error(e) { "Unexpected error extracting timestamp. Falling back to partitionTime: $partitionTime" }
47 partitionTime
48 }
49 }
50 }
51}
Proactive Late Record Handling
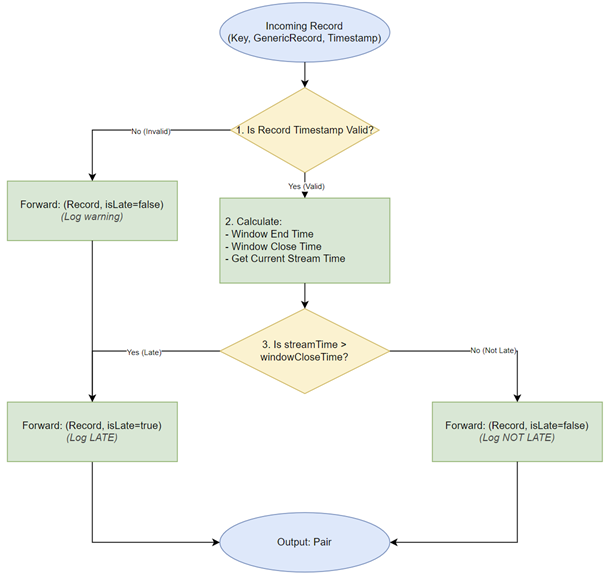
The LateRecordProcessor is a custom Kafka Streams Processor (using the lower-level Processor API) designed to identify records that would arrive too late to be included in their intended time windows.
- Parameters: Initialized with the
windowSizeandgracePerioddurations used by downstream windowed aggregations. - Logic: For each incoming record:
- It retrieves the record’s event timestamp (as assigned by
BidTimeTimestampExtractor). - It calculates the
windowEndtime for the window this record should belong to. - It then determines the
windowCloseTime(window end + grace period), which is the deadline for records to be accepted into that window. - It compares the current
streamTime(the maximum event time seen so far by this processing task) against the record’swindowCloseTime. - If
streamTimeis already pastwindowCloseTime, the record is considered “late.”
- It retrieves the record’s event timestamp (as assigned by
- Output: The processor forwards a
Paircontaining the originalGenericRecordand aBooleanflag indicating whether the record is late (true) or not (false). - Purpose: This allows the application to explicitly route late records to a separate processing path (e.g., a “skipped” topic) before they are simply dropped by downstream stateful windowed operators. This provides visibility into late data and allows for alternative handling strategies.
1package me.jaehyeon.streams.processor
2
3import mu.KotlinLogging
4import org.apache.avro.generic.GenericRecord
5import org.apache.kafka.streams.processor.api.Processor
6import org.apache.kafka.streams.processor.api.ProcessorContext
7import org.apache.kafka.streams.processor.api.Record
8import java.time.Duration
9
10class LateRecordProcessor(
11 private val windowSize: Duration,
12 private val gracePeriod: Duration,
13) : Processor<String, GenericRecord, String, Pair<GenericRecord, Boolean>> {
14 private lateinit var context: ProcessorContext<String, Pair<GenericRecord, Boolean>>
15 private val windowSizeMs = windowSize.toMillis()
16 private val gracePeriodMs = gracePeriod.toMillis()
17 private val logger = KotlinLogging.logger {}
18
19 override fun init(context: ProcessorContext<String, Pair<GenericRecord, Boolean>>) {
20 this.context = context
21 }
22
23 // The main processing method for the Processor API
24 override fun process(record: Record<String, GenericRecord>) {
25 val key = record.key()
26 val value = record.value()
27
28 // 1. Get the timestamp assigned to this specific record.
29 // This comes from your BidTimeTimestampExtractor.
30 val recordTimestamp = record.timestamp()
31
32 // Handle cases where timestamp extraction might have failed.
33 // These records can't be placed in a window correctly anyway.
34 if (recordTimestamp < 0) {
35 logger.warn { "Record has invalid timestamp $recordTimestamp. Cannot determine window. Forwarding as NOT LATE. Key=$key" }
36 // Explicitly forward the result using the context
37 context.forward(Record(key, Pair(value, false), recordTimestamp))
38 return
39 }
40
41 // 2. Determine the time window this record *should* belong to based on its timestamp.
42 // Calculate the END time of that window.
43 // Example: If window size is 5s and recordTimestamp is 12s, it belongs to
44 // window [10s, 15s). The windowEnd is 15s (15000ms).
45 // Calculation: ((12000 / 5000) + 1) * 5000 = (2 + 1) * 5000 = 15000
46 val windowEnd = ((recordTimestamp / windowSizeMs) + 1) * windowSizeMs
47
48 // 3. Calculate when this specific window "closes" for accepting late records.
49 // This is the window's end time plus the allowed grace period.
50 // Example: If windowEnd is 15s and gracePeriod is 0s, windowCloseTime is 15s.
51 // If windowEnd is 15s and gracePeriod is 2s, windowCloseTime is 17s.
52 val windowCloseTime = windowEnd + gracePeriodMs
53
54 // 4. Get the current "Stream Time".
55 // This represents the maximum record timestamp seen *so far* by this stream task.
56 // It indicates how far along the stream processing has progressed in event time.
57 val streamTime = context.currentStreamTimeMs()
58
59 // 5. THE CORE CHECK: Is the stream's progress (streamTime) already past
60 // the point where this record's window closed (windowCloseTime)?
61 // If yes, the record is considered "late" because the stream has moved on
62 // past the time it could have been included in its window (+ grace period).
63 // This mimics the logic the downstream aggregate operator uses to drop late records.
64 val isLate = streamTime > windowCloseTime
65
66 if (isLate) {
67 logger.debug {
68 "Tagging record as LATE: RecordTime=$recordTimestamp belongs to window ending at $windowEnd (closes at $windowCloseTime), but StreamTime is already $streamTime. Key=$key"
69 }
70 } else {
71 logger.trace {
72 "Tagging record as NOT LATE: RecordTime=$recordTimestamp, WindowCloseTime=$windowCloseTime, StreamTime=$streamTime. Key=$key"
73 }
74 }
75
76 // 6. Explicitly forward the result (key, tagged value, timestamp) using the context
77 // Ensure you preserve the original timestamp if needed downstream
78 context.forward(Record(key, Pair(value, isLate), recordTimestamp))
79 }
80
81 override fun close() {
82 // No resources to close
83 }
84}
Core Stream Processing Logic
The StreamsApp.kt object defines the Kafka Streams topology, orchestrating the flow of data from input to output.
- Configuration:
- Environment variables (
BOOTSTRAP,TOPIC,REGISTRY_URL) configure Kafka and Schema Registry connections. windowSize(5 seconds) andgracePeriod(5 seconds) are defined for windowed aggregations.- Output topic names are derived from the input topic name.
- Environment variables (
- Setup:
- Calls
createTopicIfNotExiststo ensure the statistics output topic and the late/skipped records topic are present. - Configures
StreamsConfigproperties, including application ID, bootstrap servers, default SerDes, and importantly, setsBidTimeTimestampExtractoras the default timestamp extractor. - Sets up Avro SerDes (
GenericAvroSerdefor input,SpecificAvroSerde<SupplierStats>for output) with Schema Registry configuration.
- Calls
- Topology Definition (
StreamsBuilder):- Source: Consumes
GenericRecordAvro messages from theinputTopicName(orders-avro-stats). - Late Record Tagging: The stream is processed by
LateRecordProcessorto tag each record with a boolean indicating if it’s late. - Branching: The stream is split based on the “late” flag:
validSource: Records not marked as late.lateSource: Records marked as late.
- Handling Late Records:
- Records in
lateSourceare transformed: an extra"late": truefield is added to their content, and they are serialized to JSON. - These JSON strings are then sent to the
skippedTopicName(orders-avro-skipped).
- Records in
- Aggregating Valid Records:
- Records in
validSourceare re-keyed bysupplier(extracted from the record) and theirpricebecomes the value. - A
groupByKeyoperation is performed. windowedBy(TimeWindows.ofSizeAndGrace(windowSize, gracePeriod))defines 5-second tumbling windows with a 5-second grace period.- An
aggregateoperation computesSupplierStats(total price and count) for each supplier within each window.
- Records in
- Outputting Statistics:
- The aggregated
SupplierStatsstream is further processed to populatewindow_startandwindow_endfields from the window metadata. - These final
SupplierStatsobjects are sent to theoutputTopicName.
- The aggregated
- Source: Consumes
- Execution: A
KafkaStreamsinstance is created with the topology and properties, then started. A shutdown hook ensures graceful closing.
1package me.jaehyeon
2
3import com.fasterxml.jackson.databind.ObjectMapper
4import com.fasterxml.jackson.module.kotlin.registerKotlinModule
5import io.confluent.kafka.streams.serdes.avro.GenericAvroSerde
6import io.confluent.kafka.streams.serdes.avro.SpecificAvroSerde
7import me.jaehyeon.avro.SupplierStats
8import me.jaehyeon.kafka.createTopicIfNotExists
9import me.jaehyeon.streams.extractor.BidTimeTimestampExtractor
10import me.jaehyeon.streams.processor.LateRecordProcessor
11import mu.KotlinLogging
12import org.apache.avro.generic.GenericRecord
13import org.apache.kafka.clients.consumer.ConsumerConfig
14import org.apache.kafka.common.serialization.Serdes
15import org.apache.kafka.streams.KafkaStreams
16import org.apache.kafka.streams.KeyValue
17import org.apache.kafka.streams.StreamsBuilder
18import org.apache.kafka.streams.StreamsConfig
19import org.apache.kafka.streams.kstream.Branched
20import org.apache.kafka.streams.kstream.Consumed
21import org.apache.kafka.streams.kstream.Grouped
22import org.apache.kafka.streams.kstream.KStream
23import org.apache.kafka.streams.kstream.KTable
24import org.apache.kafka.streams.kstream.Materialized
25import org.apache.kafka.streams.kstream.Named
26import org.apache.kafka.streams.kstream.Produced
27import org.apache.kafka.streams.kstream.TimeWindows
28import org.apache.kafka.streams.kstream.Windowed
29import org.apache.kafka.streams.processor.api.ProcessorSupplier
30import java.time.Duration
31import java.util.Properties
32
33object StreamsApp {
34 private val bootstrapAddress = System.getenv("BOOTSTRAP") ?: "kafka-1:19092"
35 private val inputTopicName = System.getenv("TOPIC") ?: "orders-avro"
36 private val registryUrl = System.getenv("REGISTRY_URL") ?: "http://schema:8081"
37 private val registryConfig =
38 mapOf(
39 "schema.registry.url" to registryUrl,
40 "basic.auth.credentials.source" to "USER_INFO",
41 "basic.auth.user.info" to "admin:admin",
42 )
43 private val windowSize = Duration.ofSeconds(5)
44 private val gracePeriod = Duration.ofSeconds(5)
45 private const val NUM_PARTITIONS = 3
46 private const val REPLICATION_FACTOR: Short = 3
47 private val logger = KotlinLogging.logger {}
48
49 // ObjectMapper for converting late source to JSON
50 private val objectMapper: ObjectMapper by lazy {
51 ObjectMapper().registerKotlinModule()
52 }
53
54 fun run() {
55 // Create output topics if not existing
56 val outputTopicName = "$inputTopicName-stats"
57 val skippedTopicName = "$inputTopicName-skipped"
58 listOf(outputTopicName, skippedTopicName).forEach { name ->
59 createTopicIfNotExists(
60 name,
61 bootstrapAddress,
62 NUM_PARTITIONS,
63 REPLICATION_FACTOR,
64 )
65 }
66
67 val props =
68 Properties().apply {
69 put(StreamsConfig.APPLICATION_ID_CONFIG, "$outputTopicName-kafka-streams")
70 put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapAddress)
71 put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String()::class.java.name)
72 put(StreamsConfig.consumerPrefix(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG), "earliest")
73 put(StreamsConfig.DEFAULT_TIMESTAMP_EXTRACTOR_CLASS_CONFIG, BidTimeTimestampExtractor::class.java.name)
74 put("schema.registry.url", registryUrl)
75 put("basic.auth.credentials.source", "USER_INFO")
76 put("basic.auth.user.info", "admin:admin")
77 }
78
79 val keySerde = Serdes.String()
80 val valueSerde =
81 GenericAvroSerde().apply {
82 configure(registryConfig, false)
83 }
84 val supplierStatsSerde =
85 SpecificAvroSerde<SupplierStats>().apply {
86 configure(registryConfig, false)
87 }
88
89 val builder = StreamsBuilder()
90 val source: KStream<String, GenericRecord> = builder.stream(inputTopicName, Consumed.with(keySerde, valueSerde))
91
92 val taggedStream: KStream<String, Pair<GenericRecord, Boolean>> =
93 source.process(
94 ProcessorSupplier {
95 LateRecordProcessor(windowSize, gracePeriod)
96 },
97 Named.`as`("process-late-records"),
98 )
99
100 val branches: Map<String, KStream<String, Pair<GenericRecord, Boolean>>> =
101 taggedStream
102 .split(Named.`as`("branch-"))
103 .branch({ _, value -> !value.second }, Branched.`as`("valid"))
104 .branch({ _, value -> value.second }, Branched.`as`("late"))
105 .noDefaultBranch()
106
107 val validSource: KStream<String, GenericRecord> =
108 branches["branch-valid"]!!
109 .mapValues { _, pair -> pair.first }
110
111 val lateSource: KStream<String, GenericRecord> =
112 branches["branch-late"]!!
113 .mapValues { _, pair -> pair.first }
114
115 lateSource
116 .mapValues { _, genericRecord ->
117 val map = mutableMapOf<String, Any?>()
118 genericRecord.schema.fields.forEach { field ->
119 val value = genericRecord.get(field.name())
120 map[field.name()] = if (value is org.apache.avro.util.Utf8) value.toString() else value
121 }
122 map["late"] = true
123 map
124 }.peek { key, mapValue ->
125 logger.warn { "Potentially late record - key=$key, value=$mapValue" }
126 }.mapValues { _, mapValue ->
127 objectMapper.writeValueAsString(mapValue)
128 }.to(skippedTopicName, Produced.with(keySerde, Serdes.String()))
129
130 val aggregated: KTable<Windowed<String>, SupplierStats> =
131 validSource
132 .map { _, value ->
133 val supplier = value["supplier"]?.toString() ?: "UNKNOWN"
134 val price = value["price"] as? Double ?: 0.0
135 KeyValue(supplier, price)
136 }.groupByKey(Grouped.with(keySerde, Serdes.Double()))
137 .windowedBy(TimeWindows.ofSizeAndGrace(windowSize, gracePeriod))
138 .aggregate(
139 {
140 SupplierStats
141 .newBuilder()
142 .setWindowStart("")
143 .setWindowEnd("")
144 .setSupplier("")
145 .setTotalPrice(0.0)
146 .setCount(0L)
147 .build()
148 },
149 { key, value, aggregate ->
150 val updated =
151 SupplierStats
152 .newBuilder(aggregate)
153 .setSupplier(key)
154 .setTotalPrice(aggregate.totalPrice + value)
155 .setCount(aggregate.count + 1)
156 updated.build()
157 },
158 Materialized.with(keySerde, supplierStatsSerde),
159 )
160 aggregated
161 .toStream()
162 .map { key, value ->
163 val windowStart = key.window().startTime().toString()
164 val windowEnd = key.window().endTime().toString()
165 val updatedValue =
166 SupplierStats
167 .newBuilder(value)
168 .setWindowStart(windowStart)
169 .setWindowEnd(windowEnd)
170 .build()
171 KeyValue(key.key(), updatedValue)
172 }.peek { _, value ->
173 logger.info { "Supplier Stats: $value" }
174 }.to(outputTopicName, Produced.with(keySerde, supplierStatsSerde))
175
176 val streams = KafkaStreams(builder.build(), props)
177 try {
178 streams.start()
179 logger.info { "Kafka Streams started successfully." }
180
181 Runtime.getRuntime().addShutdownHook(
182 Thread {
183 logger.info { "Shutting down Kafka Streams..." }
184 streams.close()
185 },
186 )
187 } catch (e: Exception) {
188 streams.close(Duration.ofSeconds(5))
189 throw RuntimeException("Error while running Kafka Streams", e)
190 }
191 }
192}
Application Entry Point
The Main.kt file provides the main function, which is the starting point for the Kafka Streams application.
- Execution: It simply calls
StreamsApp.run()to initialize and start the stream processing topology. - Error Handling: A global
try-catchblock wraps the execution. If any unhandled exception propagates up from theStreamsApp, it’s caught here, logged as a fatal error, and the application exits with a non-zero status code (exitProcess(1)).
1package me.jaehyeon
2
3import mu.KotlinLogging
4import kotlin.system.exitProcess
5
6private val logger = KotlinLogging.logger {}
7
8fun main() {
9 try {
10 StreamsApp.run()
11 } catch (e: Exception) {
12 logger.error(e) { "Fatal error in the streams app. Shutting down." }
13 exitProcess(1)
14 }
15}
Run Kafka Streams Application
To see our Kafka Streams application in action, we first need a running Kafka environment. We’ll use the Factor House Local project, which provides a Docker Compose setup for a Kafka cluster and Kpow for monitoring. Then, we’ll start a data producer (from our previous blog post example) to generate input order events, and finally, launch our Kafka Streams application.
Factor House Local Setup
If you haven’t already, set up your local Kafka environment:
- Clone the Factor House Local repository:
1git clone https://github.com/factorhouse/factorhouse-local.git 2cd factorhouse-local - Ensure your Kpow community license is configured (see the README for details).
- Start the services:
1docker compose -f compose-kpow-community.yml up -d
Once initialized, Kpow will be accessible at http://localhost:3000, showing Kafka brokers, schema registry, and other components.
Start the Kafka Order Producer
Our Kafka Streams application consumes order data from the orders-avro topic. We’ll use the Kafka producer developed in Part 2 of this series to generate this data. To effectively test our stream application’s handling of event time and late records, we’ll configure the producer to introduce a variable delay (up to 15 seconds) in the bid_time of the generated orders.
Navigate to the directory of the producer application (orders-avro-clients from the GitHub repository) and run:
1# Assuming you are in the root of the 'orders-avro-clients' project
2DELAY_SECONDS=15 ./gradlew run --args="producer"
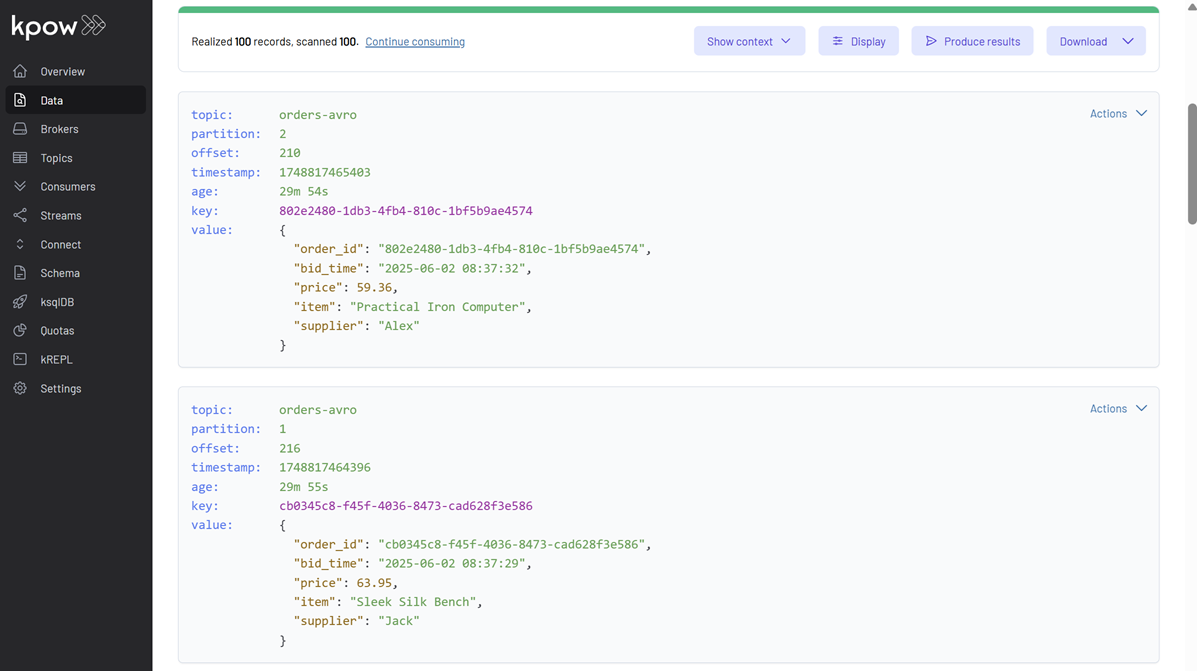
This will start populating the orders-avro topic with Avro-encoded order messages. You can inspect these messages in Kpow. For the orders-avro topic, ensure Kpow is configured with Key Deserializer: String, Value Deserializer: AVRO, and Schema Registry: Local Schema Registry.
Launch the Kafka Streams Application
With input data flowing, we can now launch our orders-stats-streams Kafka Streams application. Navigate to its project directory (orders-stats-streams from the GitHub repository).
The application can be run in two main ways:
- With Gradle (Development Mode): Ideal for development and quick testing.
1./gradlew run - Running the Shadow JAR (Deployment Mode): For deploying the application as a standalone unit. First, build the fat JAR:This creates
1./gradlew shadowJarbuild/libs/orders-stats-streams-1.0.jar. Then run it:1java -jar build/libs/orders-stats-streams-1.0.jar
💡 To build and run the application locally, ensure that JDK 17 is installed.
For this demonstration, we’ll use Gradle to run the application in development mode. Upon starting, you’ll see logs indicating the Kafka Streams application has initialized and is processing records from the orders-avro topic.
Observing the Output
Our Kafka Streams application produces results to two topics:
orders-avro-stats: Contains the aggregated supplier statistics as Avro records.orders-avro-skipped: Contains records identified as “late,” serialized as JSON.
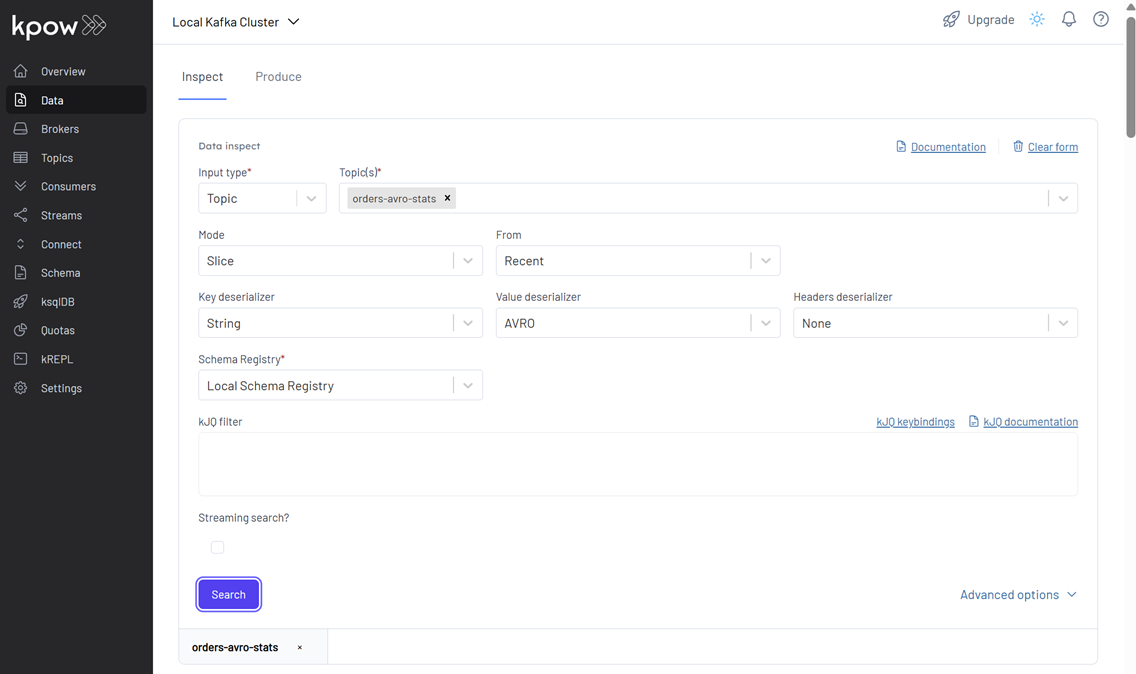
1. Supplier Statistics (orders-avro-stats):
In Kpow, navigate to the orders-avro-stats topic. Configure Kpow to view these messages:
- Key Deserializer: String
- Value Deserializer: AVRO
- Schema Registry: Local Schema Registry
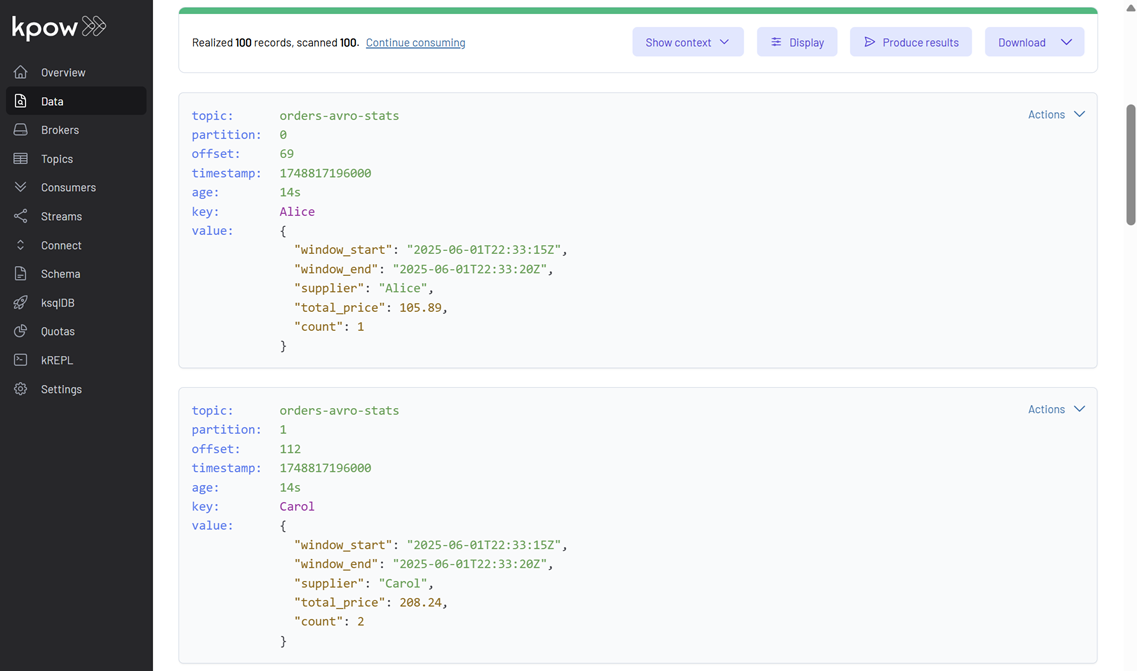
You should see SupplierStats messages, each representing the total price and count of orders for a supplier within a 5-second window. Notice the window_start and window_end fields.
2. Skipped (Late) Records (orders-avro-skipped):
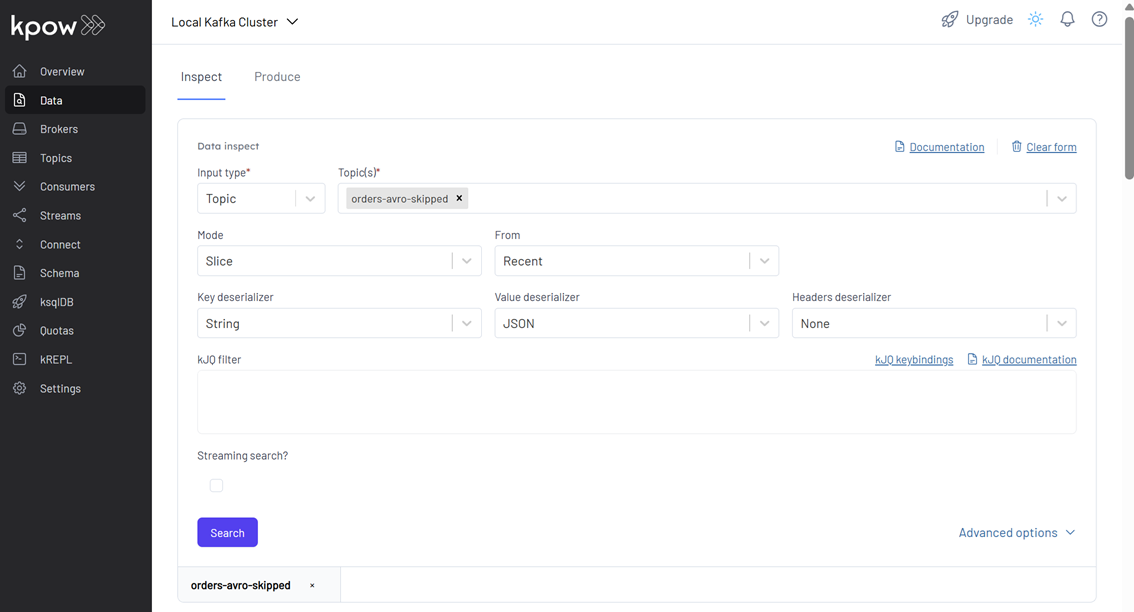
Next, inspect the orders-avro-skipped topic in Kpow. Configure Kpow as follows:
- Key Deserializer: String
- Value Deserializer: JSON
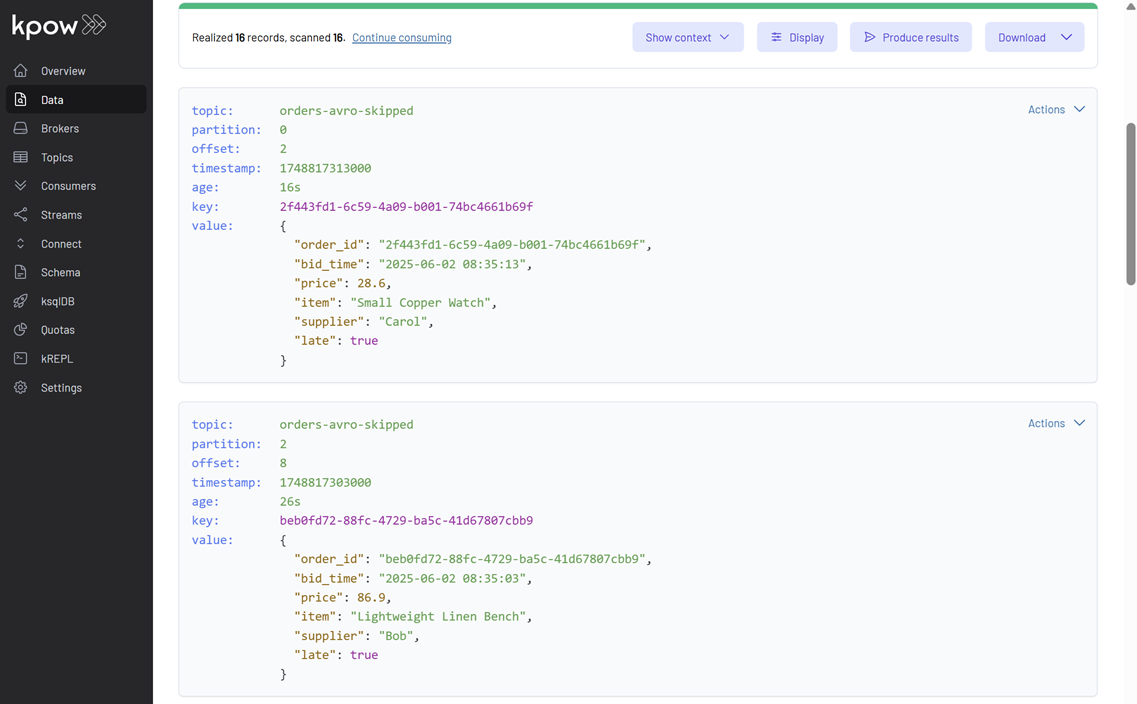
Here, you’ll find the original order records that were deemed “late” by our LateRecordProcessor. These messages have an additional late: true field, confirming they were routed by our custom logic.
We can also track the performance of the application by filtering its consumer group (orders-avro-stats-kafka-streams) in the Consumers section. This displays key metrics like group state, assigned members, read throughput, and lag:
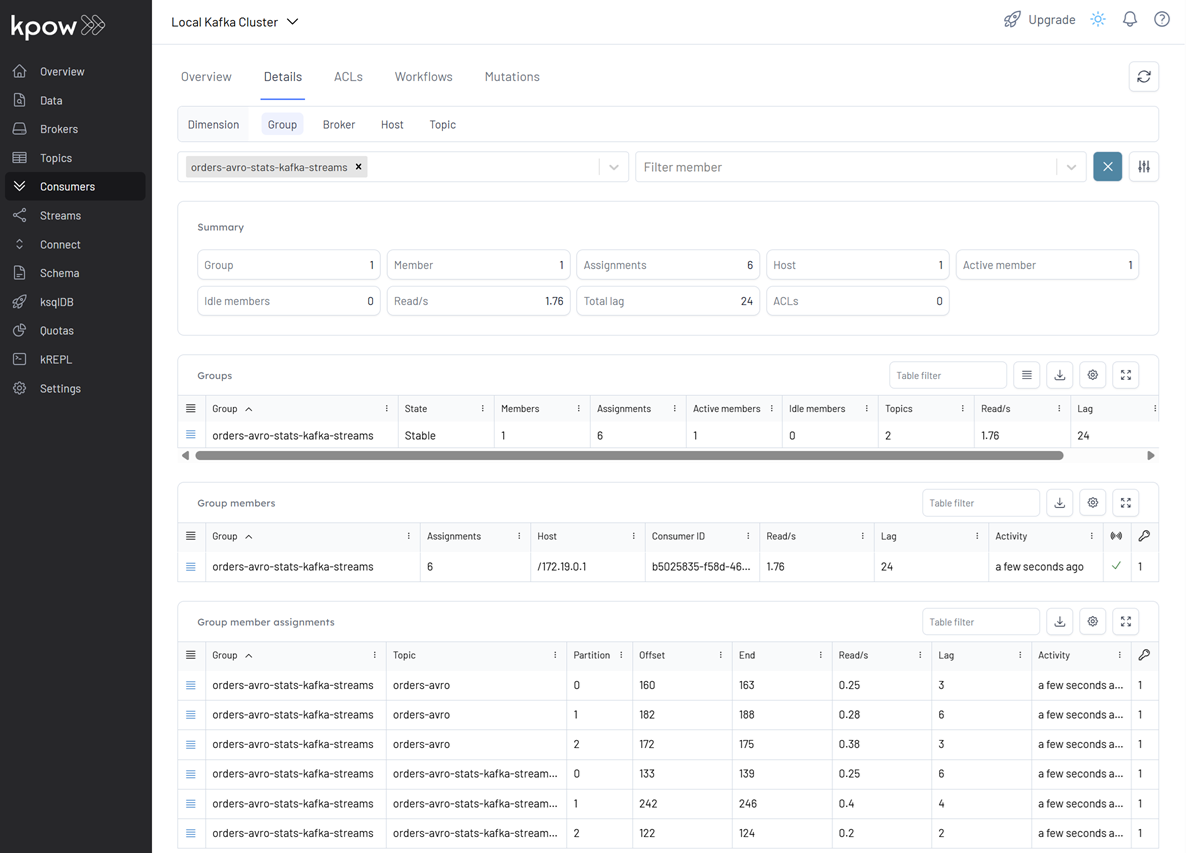
Conclusion
In this post, we’ve dived into Kafka Streams, building a Kotlin application that performs real-time aggregation of supplier order data. We’ve seen how to leverage event-time processing with a custom TimestampExtractor and how to proactively manage late-arriving data using the Processor API with a custom LateRecordProcessor. By routing late data to a separate topic and outputting clean, windowed statistics, this application demonstrates a practical approach to building resilient and insightful stream processing pipelines directly with Kafka. The use of Avro ensures data integrity, while Kpow provides excellent visibility into the streams and topics.










Comments