
In the last post, we explored the fine-grained control of Flink’s DataStream API. Now, we’ll approach the same problem from a higher level of abstraction using the Flink Table API. This post demonstrates how to build a declarative analytics pipeline that processes our continuous stream of Avro-formatted order events. We will define a Table on top of a DataStream and use SQL-like expressions to perform windowed aggregations. This example highlights the power and simplicity of the Table API for analytical tasks and showcases Flink’s seamless integration between its different API layers to handle complex requirements like late data.
- Kafka Clients with JSON - Producing and Consuming Order Events
- Kafka Clients with Avro - Schema Registry and Order Events
- Kafka Streams - Lightweight Real-Time Processing for Supplier Stats
- Flink DataStream API - Scalable Event Processing for Supplier Stats
- Flink Table API - Declarative Analytics for Supplier Stats in Real Time (this post)
Flink Table Application
We develop a Flink application that uses Flink’s Table API and SQL-like expressions to perform real-time analytics. This application:
- Consumes Avro-formatted order events from a Kafka topic.
- Uses a mix of the DataStream and Table APIs to prepare data, handle late events, and define watermarks.
- Defines a table over the streaming data, complete with an event-time attribute and watermarks.
- Runs a declarative, SQL-like query to compute supplier statistics (total price and count) in 5-second tumbling windows.
- Splits the stream to route late-arriving records to a separate “skipped” topic for analysis.
- Sinks the aggregated results to a Kafka topic using the built-in
avro-confluentformat connector.
The source code for the application discussed in this post can be found in the orders-stats-flink folder of this GitHub repository.
The Build Configuration
The build.gradle.kts file sets up the project, its dependencies, and packaging. It’s shared between the DataStream and Table API applications - see the previous post for the Flink application that uses the DataStream API.
- Plugins:
kotlin("jvm"): Enables Kotlin language support.com.github.davidmc24.gradle.plugin.avro: Compiles Avro schemas into Java classes.com.github.johnrengelman.shadow: Creates an executable “fat JAR” with all dependencies.application: Configures the project to be runnable via Gradle.
- Dependencies:
- Flink Core & Table APIs:
flink-streaming-java,flink-clients, and crucially,flink-table-api-java-bridge,flink-table-planner-loader, andflink-table-runtimefor the Table API. - Flink Connectors:
flink-connector-kafkafor Kafka integration. - Flink Formats:
flink-avroandflink-avro-confluent-registryfor handling Avro data with Confluent Schema Registry. - Note on Dependency Scope: The Flink dependencies are declared with
implementation. This allows the application to be run directly with./gradlew run. For production deployments on a Flink cluster (where the Flink runtime is already provided), these dependencies should be changed tocompileOnlyto significantly reduce the size of the final JAR.
- Flink Core & Table APIs:
- Application Configuration:
- The
applicationblock sets themainClassand passes necessary JVM arguments. Theruntask is configured with environment variables to specify Kafka and Schema Registry connection details.
- The
- Avro & Shadow JAR:
- The
avroblock configures code generation. - The
shadowJartask configures the output JAR name and merges service files, which is crucial for Flink connectors to work correctly.
- The
1plugins {
2 kotlin("jvm") version "2.1.20"
3 id("com.github.davidmc24.gradle.plugin.avro") version "1.9.1"
4 id("com.github.johnrengelman.shadow") version "8.1.1"
5 application
6}
7
8group = "me.jaehyeon"
9version = "1.0-SNAPSHOT"
10
11repositories {
12 mavenCentral()
13 maven("https://packages.confluent.io/maven")
14}
15
16dependencies {
17 // Flink Core and APIs
18 implementation("org.apache.flink:flink-streaming-java:1.20.1")
19 implementation("org.apache.flink:flink-table-api-java:1.20.1")
20 implementation("org.apache.flink:flink-table-api-java-bridge:1.20.1")
21 implementation("org.apache.flink:flink-table-planner-loader:1.20.1")
22 implementation("org.apache.flink:flink-table-runtime:1.20.1")
23 implementation("org.apache.flink:flink-clients:1.20.1")
24 implementation("org.apache.flink:flink-connector-base:1.20.1")
25 // Flink Kafka and Avro
26 implementation("org.apache.flink:flink-connector-kafka:3.4.0-1.20")
27 implementation("org.apache.flink:flink-avro:1.20.1")
28 implementation("org.apache.flink:flink-avro-confluent-registry:1.20.1")
29 // Json
30 implementation("com.fasterxml.jackson.module:jackson-module-kotlin:2.13.0")
31 // Logging
32 implementation("io.github.microutils:kotlin-logging-jvm:3.0.5")
33 implementation("ch.qos.logback:logback-classic:1.5.13")
34 // Kotlin test
35 testImplementation(kotlin("test"))
36}
37
38kotlin {
39 jvmToolchain(17)
40}
41
42application {
43 mainClass.set("me.jaehyeon.MainKt")
44 applicationDefaultJvmArgs =
45 listOf(
46 "--add-opens=java.base/java.util=ALL-UNNAMED",
47 )
48}
49
50avro {
51 setCreateSetters(true)
52 setFieldVisibility("PUBLIC")
53}
54
55tasks.named("compileKotlin") {
56 dependsOn("generateAvroJava")
57}
58
59sourceSets {
60 named("main") {
61 java.srcDirs("build/generated/avro/main")
62 kotlin.srcDirs("src/main/kotlin")
63 }
64}
65
66tasks.withType<com.github.jengelman.gradle.plugins.shadow.tasks.ShadowJar> {
67 archiveBaseName.set("orders-stats-flink")
68 archiveClassifier.set("")
69 archiveVersion.set("1.0")
70 mergeServiceFiles()
71}
72
73tasks.named("build") {
74 dependsOn("shadowJar")
75}
76
77tasks.named<JavaExec>("run") {
78 environment("TO_SKIP_PRINT", "false")
79 environment("BOOTSTRAP", "localhost:9092")
80 environment("REGISTRY_URL", "http://localhost:8081")
81}
82
83tasks.test {
84 useJUnitPlatform()
85}
Avro Schema for Supplier Statistics
The SupplierStats.avsc file defines the structure for the aggregated output data. This schema is used by the Flink Table API’s Kafka connector with the avro-confluent format to serialize the final Row results into Avro, ensuring type safety for downstream consumers.
- Type: A
recordnamedSupplierStatsin theme.jaehyeon.avronamespace. - Fields:
window_startandwindow_end(string): The start and end times of the aggregation window.supplier(string): The supplier being aggregated.total_price(double): The sum of order prices within the window.count(long): The total number of orders within the window.
1{
2 "type": "record",
3 "name": "SupplierStats",
4 "namespace": "me.jaehyeon.avro",
5 "fields": [
6 { "name": "window_start", "type": "string" },
7 { "name": "window_end", "type": "string" },
8 { "name": "supplier", "type": "string" },
9 { "name": "total_price", "type": "double" },
10 { "name": "count", "type": "long" }
11 ]
12}
Shared Utilities
These utility files provide common functionality used by both the DataStream and Table API applications.
Kafka Admin Utilities
This file provides two key helper functions for interacting with the Kafka ecosystem:
createTopicIfNotExists(...): Uses Kafka’sAdminClientto programmatically create topics. It’s designed to be idempotent, safely handling cases where the topic already exists to prevent application startup failures.getLatestSchema(...): Connects to the Confluent Schema Registry usingCachedSchemaRegistryClientto fetch the latest Avro schema for a given subject. This is essential for the Flink source to correctly deserialize incoming Avro records without hardcoding the schema in the application.
1package me.jaehyeon.kafka
2
3import io.confluent.kafka.schemaregistry.client.CachedSchemaRegistryClient
4import mu.KotlinLogging
5import org.apache.avro.Schema
6import org.apache.kafka.clients.admin.AdminClient
7import org.apache.kafka.clients.admin.AdminClientConfig
8import org.apache.kafka.clients.admin.NewTopic
9import org.apache.kafka.common.errors.TopicExistsException
10import java.util.Properties
11import java.util.concurrent.ExecutionException
12import kotlin.use
13
14private val logger = KotlinLogging.logger { }
15
16fun createTopicIfNotExists(
17 topicName: String,
18 bootstrapAddress: String,
19 numPartitions: Int,
20 replicationFactor: Short,
21) {
22 val props =
23 Properties().apply {
24 put(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapAddress)
25 put(AdminClientConfig.DEFAULT_API_TIMEOUT_MS_CONFIG, "5000")
26 put(AdminClientConfig.REQUEST_TIMEOUT_MS_CONFIG, "3000")
27 put(AdminClientConfig.RETRIES_CONFIG, "1")
28 }
29
30 AdminClient.create(props).use { client ->
31 val newTopic = NewTopic(topicName, numPartitions, replicationFactor)
32 val result = client.createTopics(listOf(newTopic))
33
34 try {
35 logger.info { "Attempting to create topic '$topicName'..." }
36 result.all().get()
37 logger.info { "Topic '$topicName' created successfully!" }
38 } catch (e: ExecutionException) {
39 if (e.cause is TopicExistsException) {
40 logger.warn { "Topic '$topicName' was created concurrently or already existed. Continuing..." }
41 } else {
42 throw RuntimeException("Unrecoverable error while creating a topic '$topicName'.", e)
43 }
44 }
45 }
46}
47
48fun getLatestSchema(
49 schemaSubject: String,
50 registryUrl: String,
51 registryConfig: Map<String, String>,
52): Schema {
53 val schemaRegistryClient =
54 CachedSchemaRegistryClient(
55 registryUrl,
56 100,
57 registryConfig,
58 )
59 logger.info { "Fetching latest schema for subject '$schemaSubject' from $registryUrl" }
60 try {
61 val latestSchemaMetadata = schemaRegistryClient.getLatestSchemaMetadata(schemaSubject)
62 logger.info {
63 "Successfully fetched schema ID ${latestSchemaMetadata.id} version ${latestSchemaMetadata.version} for subject '$schemaSubject'"
64 }
65 return Schema.Parser().parse(latestSchemaMetadata.schema)
66 } catch (e: Exception) {
67 logger.error(e) { "Failed to retrieve schema for subject '$schemaSubject' from registry $registryUrl" }
68 throw RuntimeException("Failed to retrieve schema for subject '$schemaSubject'", e)
69 }
70}
Flink Kafka Connectors
This file centralizes the creation of Flink’s Kafka sources and sinks. The Table API application uses createOrdersSource and createSkippedSink from this file. The sink for aggregated statistics is defined declaratively using a TableDescriptor instead of the createStatsSink function.
createOrdersSource(...): Configures aKafkaSourceto consumeGenericRecordAvro data.createSkippedSink(...): Creates a genericKafkaSinkfor late records, which are handled as simple key-value string pairs.
1package me.jaehyeon.kafka
2
3import me.jaehyeon.avro.SupplierStats
4import org.apache.avro.Schema
5import org.apache.avro.generic.GenericRecord
6import org.apache.flink.connector.base.DeliveryGuarantee
7import org.apache.flink.connector.kafka.sink.KafkaRecordSerializationSchema
8import org.apache.flink.connector.kafka.sink.KafkaSink
9import org.apache.flink.connector.kafka.source.KafkaSource
10import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer
11import org.apache.flink.formats.avro.registry.confluent.ConfluentRegistryAvroDeserializationSchema
12import org.apache.flink.formats.avro.registry.confluent.ConfluentRegistryAvroSerializationSchema
13import org.apache.kafka.clients.consumer.ConsumerConfig
14import org.apache.kafka.clients.producer.ProducerConfig
15import java.nio.charset.StandardCharsets
16import java.util.Properties
17
18fun createOrdersSource(
19 topic: String,
20 groupId: String,
21 bootstrapAddress: String,
22 registryUrl: String,
23 registryConfig: Map<String, String>,
24 schema: Schema,
25): KafkaSource<GenericRecord> =
26 KafkaSource
27 .builder<GenericRecord>()
28 .setBootstrapServers(bootstrapAddress)
29 .setTopics(topic)
30 .setGroupId(groupId)
31 .setStartingOffsets(OffsetsInitializer.earliest())
32 .setValueOnlyDeserializer(
33 ConfluentRegistryAvroDeserializationSchema.forGeneric(
34 schema,
35 registryUrl,
36 registryConfig,
37 ),
38 ).setProperties(
39 Properties().apply {
40 put(ConsumerConfig.FETCH_MAX_WAIT_MS_CONFIG, "500")
41 },
42 ).build()
43
44fun createStatsSink(
45 topic: String,
46 bootstrapAddress: String,
47 registryUrl: String,
48 registryConfig: Map<String, String>,
49 outputSubject: String,
50): KafkaSink<SupplierStats> =
51 KafkaSink
52 .builder<SupplierStats>()
53 .setBootstrapServers(bootstrapAddress)
54 .setKafkaProducerConfig(
55 Properties().apply {
56 setProperty(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, "true")
57 setProperty(ProducerConfig.LINGER_MS_CONFIG, "100")
58 setProperty(ProducerConfig.BATCH_SIZE_CONFIG, (64 * 1024).toString())
59 setProperty(ProducerConfig.COMPRESSION_TYPE_CONFIG, "lz4")
60 },
61 ).setDeliveryGuarantee(DeliveryGuarantee.AT_LEAST_ONCE)
62 .setRecordSerializer(
63 KafkaRecordSerializationSchema
64 .builder<SupplierStats>()
65 .setTopic(topic)
66 .setKeySerializationSchema { value: SupplierStats ->
67 value.supplier.toByteArray(StandardCharsets.UTF_8)
68 }.setValueSerializationSchema(
69 ConfluentRegistryAvroSerializationSchema.forSpecific<SupplierStats>(
70 SupplierStats::class.java,
71 outputSubject,
72 registryUrl,
73 registryConfig,
74 ),
75 ).build(),
76 ).build()
77
78fun createSkippedSink(
79 topic: String,
80 bootstrapAddress: String,
81): KafkaSink<Pair<String?, String>> =
82 KafkaSink
83 .builder<Pair<String?, String>>()
84 .setBootstrapServers(bootstrapAddress)
85 .setKafkaProducerConfig(
86 Properties().apply {
87 setProperty(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, "true")
88 setProperty(ProducerConfig.COMPRESSION_TYPE_CONFIG, "lz4")
89 setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.ByteArraySerializer")
90 setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.ByteArraySerializer")
91 },
92 ).setDeliveryGuarantee(DeliveryGuarantee.AT_LEAST_ONCE)
93 .setRecordSerializer(
94 KafkaRecordSerializationSchema
95 .builder<Pair<String?, String>>()
96 .setTopic(topic)
97 .setKeySerializationSchema { pair: Pair<String?, String> ->
98 pair.first?.toByteArray(StandardCharsets.UTF_8)
99 }.setValueSerializationSchema { pair: Pair<String?, String> ->
100 pair.second.toByteArray(StandardCharsets.UTF_8)
101 }.build(),
102 ).build()
Table API Processing Logic
The following files contain the core logic specific to the Table API implementation.
Manual Late Data Routing
Because the Table API does not have a direct equivalent to the DataStream API’s .sideOutputLateData(), we must handle late records manually. This ProcessFunction is a key component. It inspects each record’s timestamp against the current watermark and an allowedLatenessMillis threshold. Records deemed “too late” are routed to a side output, while on-time records are passed downstream to be converted into a Table.
1package me.jaehyeon.flink.processing
2
3import org.apache.flink.streaming.api.functions.ProcessFunction
4import org.apache.flink.util.Collector
5import org.apache.flink.util.OutputTag
6
7class LateDataRouter(
8 private val lateOutputTag: OutputTag<RecordMap>,
9 private val allowedLatenessMillis: Long,
10) : ProcessFunction<RecordMap, RecordMap>() {
11
12 init {
13 require(allowedLatenessMillis >= 0) {
14 "allowedLatenessMillis cannot be negative. Got: $allowedLatenessMillis"
15 }
16 }
17
18 @Throws(Exception::class)
19 override fun processElement(
20 value: RecordMap,
21 ctx: ProcessFunction<RecordMap, RecordMap>.Context,
22 out: Collector<RecordMap>,
23 ) {
24 val elementTimestamp: Long? = ctx.timestamp()
25 val currentWatermark: Long = ctx.timerService().currentWatermark()
26
27 // Element has no timestamp or watermark is still at its initial value
28 if (elementTimestamp == null || currentWatermark == Long.MIN_VALUE) {
29 out.collect(value)
30 return
31 }
32
33 // Element has a timestamp and watermark is active.
34 // An element is "too late" if its timestamp is older than current watermark - allowed lateness.
35 if (elementTimestamp < currentWatermark - allowedLatenessMillis) {
36 ctx.output(lateOutputTag, value)
37 } else {
38 out.collect(value)
39 }
40 }
41}
Timestamp and Watermark Strategy for Rows
After the initial stream processing and before converting the DataStream to a Table, we need a watermark strategy that operates on Flink’s Row type. This strategy extracts the timestamp from a specific field index in the Row (in this case, field 1, which holds the bid_time as a Long) and generates watermarks, allowing the Table API to correctly perform event-time windowing.
1package me.jaehyeon.flink.watermark
2
3import mu.KotlinLogging
4import org.apache.flink.api.common.eventtime.WatermarkStrategy
5import org.apache.flink.types.Row
6
7object RowWatermarkStrategy {
8 private val logger = KotlinLogging.logger {}
9
10 val strategy: WatermarkStrategy<Row> =
11 WatermarkStrategy
12 .forBoundedOutOfOrderness<Row>(java.time.Duration.ofSeconds(5))
13 .withTimestampAssigner { row: Row, _ ->
14 try {
15 // Get the field by index. Assumes bid_time is at index 1 and is Long.
16 val timestamp = row.getField(1) as? Long
17 if (timestamp != null) {
18 timestamp
19 } else {
20 logger.warn { "Null or invalid timestamp at index 1 in Row: $row. Using current time." }
21 System.currentTimeMillis() // Fallback
22 }
23 } catch (e: Exception) {
24 // Catch potential ClassCastException or other issues
25 logger.error(e) { "Error accessing timestamp at index 1 in Row: $row. Using current time." }
26 System.currentTimeMillis() // Fallback
27 }
28 }.withIdleness(java.time.Duration.ofSeconds(10)) // Same idleness
29}
Not Applicable Source Code
The files SupplierWatermarkStrategy, SupplierStatsAggregator, and SupplierStatsFunction are used exclusively by the Flink DataStream API application for its specific watermark and aggregation logic. They are not relevant to this Table API implementation.
Core Table API Application
This is the main driver for the Table API application. It demonstrates the powerful integration between the DataStream and Table APIs.
- Environment Setup: It initializes both a
StreamExecutionEnvironmentand aStreamTableEnvironment. - Data Ingestion and Preparation:
- It consumes Avro
GenericRecords using aKafkaSourceand maps them to aDataStream<RecordMap>. - It applies a
WatermarkStrategyto theRecordMapstream so that the subsequentLateDataRoutercan function correctly based on event time.
- It consumes Avro
- Late Data Splitting: It uses the custom
LateDataRouterProcessFunctionto split the stream into an on-time stream and a late-data side output. - DataStream-to-Table Conversion:
- The on-time
DataStream<RecordMap>is converted to aDataStream<Row>. This step transforms the data into the structured, columnar format required by the Table API. - A second
WatermarkStrategy(RowWatermarkStrategy) is applied to theDataStream<Row>. tEnv.createTemporaryViewregisters theDataStream<Row>as a table named “orders”. ASchemais defined, crucially marking thebid_timecolumn as the event-time attribute (TIMESTAMP_LTZ(3)) and telling Flink to use the watermarks generated by the DataStream (SOURCE_WATERMARK()).
- The on-time
- Declarative Query: A high-level, declarative query is executed on the “orders” table. It uses
Tumbleto define 5-second windows and performsgroupByandselectoperations with aggregate functions (sum,count) to calculate the statistics. - Sinking:
- A
TableDescriptoris defined for the Kafka sink. It specifies the sink schema and, most importantly, theavro-confluentformat, which handles serialization to Avro and integration with Schema Registry automatically. statsTable.executeInsert()writes the results of the query to the sink.- The separate late data stream is processed and sunk to its own topic.
- A
- Execution:
env.execute()starts the Flink job.
1@file:Suppress("ktlint:standard:no-wildcard-imports")
2
3package me.jaehyeon
4
5import com.fasterxml.jackson.databind.ObjectMapper
6import com.fasterxml.jackson.module.kotlin.registerKotlinModule
7import me.jaehyeon.flink.processing.LateDataRouter
8import me.jaehyeon.flink.processing.RecordMap
9import me.jaehyeon.flink.watermark.RowWatermarkStrategy
10import me.jaehyeon.flink.watermark.SupplierWatermarkStrategy
11import me.jaehyeon.kafka.createOrdersSource
12import me.jaehyeon.kafka.createSkippedSink
13import me.jaehyeon.kafka.createTopicIfNotExists
14import me.jaehyeon.kafka.getLatestSchema
15import mu.KotlinLogging
16import org.apache.avro.generic.GenericRecord
17import org.apache.flink.api.common.eventtime.WatermarkStrategy
18import org.apache.flink.api.common.typeinfo.TypeHint
19import org.apache.flink.api.common.typeinfo.TypeInformation
20import org.apache.flink.api.java.typeutils.RowTypeInfo
21import org.apache.flink.streaming.api.datastream.DataStream
22import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator
23import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment
24import org.apache.flink.streaming.connectors.kafka.table.KafkaConnectorOptions
25import org.apache.flink.table.api.DataTypes
26import org.apache.flink.table.api.Expressions.*
27import org.apache.flink.table.api.Expressions.lit
28import org.apache.flink.table.api.FormatDescriptor
29import org.apache.flink.table.api.Schema
30import org.apache.flink.table.api.Table
31import org.apache.flink.table.api.TableDescriptor
32import org.apache.flink.table.api.Tumble
33import org.apache.flink.table.api.bridge.java.StreamTableEnvironment
34import org.apache.flink.types.Row
35import org.apache.flink.util.OutputTag
36import java.time.Instant
37import java.time.LocalDateTime
38import java.time.ZoneId
39import java.time.format.DateTimeFormatter
40import java.time.format.DateTimeParseException
41
42object TableApp {
43 private val toSkipPrint = System.getenv("TO_SKIP_PRINT")?.toBoolean() ?: true
44 private val bootstrapAddress = System.getenv("BOOTSTRAP") ?: "kafka-1:19092"
45 private val inputTopicName = System.getenv("TOPIC") ?: "orders-avro"
46 private val registryUrl = System.getenv("REGISTRY_URL") ?: "http://schema:8081"
47 private val registryConfig =
48 mapOf(
49 "basic.auth.credentials.source" to "USER_INFO",
50 "basic.auth.user.info" to "admin:admin",
51 )
52 private const val INPUT_SCHEMA_SUBJECT = "orders-avro-value"
53 private const val NUM_PARTITIONS = 3
54 private const val REPLICATION_FACTOR: Short = 3
55 private val logger = KotlinLogging.logger {}
56
57 // ObjectMapper for converting late data Map to JSON
58 private val objectMapper: ObjectMapper by lazy {
59 ObjectMapper().registerKotlinModule()
60 }
61
62 fun run() {
63 // Create output topics if not existing
64 val outputTopicName = "$inputTopicName-ktl-stats"
65 val skippedTopicName = "$inputTopicName-ktl-skipped"
66 listOf(outputTopicName, skippedTopicName).forEach { name ->
67 createTopicIfNotExists(
68 name,
69 bootstrapAddress,
70 NUM_PARTITIONS,
71 REPLICATION_FACTOR,
72 )
73 }
74
75 val env = StreamExecutionEnvironment.getExecutionEnvironment()
76 env.parallelism = 3
77 val tEnv = StreamTableEnvironment.create(env)
78
79 val inputAvroSchema = getLatestSchema(INPUT_SCHEMA_SUBJECT, registryUrl, registryConfig)
80 val ordersGenericRecordSource =
81 createOrdersSource(
82 topic = inputTopicName,
83 groupId = "$inputTopicName-flink-tl",
84 bootstrapAddress = bootstrapAddress,
85 registryUrl = registryUrl,
86 registryConfig = registryConfig,
87 schema = inputAvroSchema,
88 )
89
90 // 1. Stream of GenericRecords from Kafka
91 val genericRecordStream: DataStream<GenericRecord> =
92 env
93 .fromSource(ordersGenericRecordSource, WatermarkStrategy.noWatermarks(), "KafkaGenericRecordSource")
94
95 // 2. Convert GenericRecord to Map<String, Any?> (RecordMap)
96 val recordMapStream: DataStream<RecordMap> =
97 genericRecordStream
98 .map { genericRecord ->
99 val map = mutableMapOf<String, Any?>()
100 genericRecord.schema.fields.forEach { field ->
101 val value = genericRecord.get(field.name())
102 map[field.name()] = if (value is org.apache.avro.util.Utf8) value.toString() else value
103 }
104 map as RecordMap // Cast to type alias
105 }.name("GenericRecordToMapConverter")
106 .returns(TypeInformation.of(object : TypeHint<RecordMap>() {}))
107
108 // 3. Define OutputTag for late data (now carrying RecordMap)
109 val lateMapOutputTag =
110 OutputTag(
111 "late-order-records",
112 TypeInformation.of(object : TypeHint<RecordMap>() {}),
113 )
114
115 // 4. Split late records from on-time ones
116 val statsStreamOperator: SingleOutputStreamOperator<RecordMap> =
117 recordMapStream
118 .assignTimestampsAndWatermarks(SupplierWatermarkStrategy.strategy)
119 .process(LateDataRouter(lateMapOutputTag, allowedLatenessMillis = 5000))
120 .name("LateDataRouter")
121
122 // 5. Create source table (statsTable)
123 val statsStream: DataStream<RecordMap> = statsStreamOperator
124 val rowStatsStream: DataStream<Row> =
125 statsStream
126 .map { recordMap ->
127 val orderId = recordMap["order_id"] as? String
128 val price = recordMap["price"] as? Double
129 val item = recordMap["item"] as? String
130 val supplier = recordMap["supplier"] as? String
131
132 val bidTimeString = recordMap["bid_time"] as? String
133 var bidTimeInstant: Instant? = null // Changed from bidTimeLong to bidTimeInstant
134
135 if (bidTimeString != null) {
136 try {
137 val formatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss")
138 val localDateTime = LocalDateTime.parse(bidTimeString, formatter)
139 // Convert to Instant
140 bidTimeInstant =
141 localDateTime
142 .atZone(ZoneId.systemDefault()) // Or ZoneOffset.UTC
143 .toInstant()
144 } catch (e: DateTimeParseException) {
145 logger.error(e) { "Failed to parse bid_time string '$bidTimeString'. RecordMap: $recordMap" }
146 } catch (e: Exception) {
147 logger.error(e) { "Unexpected error parsing bid_time string '$bidTimeString'. RecordMap: $recordMap" }
148 }
149 } else {
150 logger.warn { "bid_time string is null in RecordMap: $recordMap" }
151 }
152
153 Row.of(
154 orderId,
155 bidTimeInstant,
156 price,
157 item,
158 supplier,
159 )
160 }.returns(
161 RowTypeInfo(
162 arrayOf<TypeInformation<*>>(
163 TypeInformation.of(String::class.java),
164 TypeInformation.of(Instant::class.java), // bid_time (as Long milliseconds for TIMESTAMP_LTZ)
165 TypeInformation.of(Double::class.java),
166 TypeInformation.of(String::class.java),
167 TypeInformation.of(String::class.java),
168 ),
169 arrayOf("order_id", "bid_time", "price", "item", "supplier"),
170 ),
171 ).assignTimestampsAndWatermarks(RowWatermarkStrategy.strategy)
172 .name("MapToRowConverter")
173 val tableSchema =
174 Schema
175 .newBuilder()
176 .column("order_id", DataTypes.STRING())
177 .column("bid_time", DataTypes.TIMESTAMP_LTZ(3)) // Event time attribute
178 .column("price", DataTypes.DOUBLE())
179 .column("item", DataTypes.STRING())
180 .column("supplier", DataTypes.STRING())
181 .watermark("bid_time", "SOURCE_WATERMARK()") // Use watermarks from DataStream
182 .build()
183 tEnv.createTemporaryView("orders", rowStatsStream, tableSchema)
184
185 val statsTable: Table =
186 tEnv
187 .from("orders")
188 .window(Tumble.over(lit(5).seconds()).on(col("bid_time")).`as`("w"))
189 .groupBy(col("supplier"), col("w"))
190 .select(
191 col("supplier"),
192 col("w").start().`as`("window_start"),
193 col("w").end().`as`("window_end"),
194 col("price").sum().round(2).`as`("total_price"),
195 col("order_id").count().`as`("count"),
196 )
197
198 // 6. Create sink table
199 val sinkSchema =
200 Schema
201 .newBuilder()
202 .column("supplier", DataTypes.STRING())
203 .column("window_start", DataTypes.TIMESTAMP(3))
204 .column("window_end", DataTypes.TIMESTAMP(3))
205 .column("total_price", DataTypes.DOUBLE())
206 .column("count", DataTypes.BIGINT())
207 .build()
208 val kafkaSinkDescriptor: TableDescriptor =
209 TableDescriptor
210 .forConnector("kafka")
211 .schema(sinkSchema) // Set the schema for the sink
212 .option(KafkaConnectorOptions.TOPIC, listOf(outputTopicName))
213 .option(KafkaConnectorOptions.PROPS_BOOTSTRAP_SERVERS, bootstrapAddress)
214 .format(
215 FormatDescriptor
216 .forFormat("avro-confluent")
217 .option("url", registryUrl)
218 .option("basic-auth.credentials-source", "USER_INFO")
219 .option("basic-auth.user-info", "admin:admin")
220 .option("subject", "$outputTopicName-value")
221 .build(),
222 ).build()
223
224 // 7. Handle late data as a pair of key and value
225 val lateDataMapStream: DataStream<RecordMap> = statsStreamOperator.getSideOutput(lateMapOutputTag)
226 val lateKeyPairStream: DataStream<Pair<String?, String>> =
227 lateDataMapStream
228 .map { recordMap ->
229 val mutableMap = recordMap.toMutableMap()
230 mutableMap["late"] = true
231 val orderId = mutableMap["order_id"] as? String
232 try {
233 val value = objectMapper.writeValueAsString(mutableMap)
234 Pair(orderId, value)
235 } catch (e: Exception) {
236 logger.error(e) { "Error serializing late RecordMap to JSON: $mutableMap" }
237 val errorJson = "{ \"error\": \"json_serialization_failed\", \"data_keys\": \"${
238 mutableMap.keys.joinToString(
239 ",",
240 )}\" }"
241 Pair(orderId, errorJson)
242 }
243 }.returns(TypeInformation.of(object : TypeHint<Pair<String?, String>>() {}))
244 val skippedSink =
245 createSkippedSink(
246 topic = skippedTopicName,
247 bootstrapAddress = bootstrapAddress,
248 )
249
250 if (!toSkipPrint) {
251 tEnv
252 .toDataStream(statsTable)
253 .print()
254 .name("SupplierStatsPrint")
255 lateKeyPairStream
256 .map { it.second }
257 .print()
258 .name("LateDataPrint")
259 }
260
261 statsTable.executeInsert(kafkaSinkDescriptor)
262 lateKeyPairStream.sinkTo(skippedSink).name("LateDataSink")
263 env.execute("SupplierStats")
264 }
265}
Application Entry Point
The Main.kt file serves as the entry point for the application. It parses a command-line argument (datastream or table) to determine which Flink application to run. A try-catch block ensures that any fatal error during execution is logged before the application exits.
1package me.jaehyeon
2
3import mu.KotlinLogging
4import kotlin.system.exitProcess
5
6private val logger = KotlinLogging.logger {}
7
8fun main(args: Array<String>) {
9 try {
10 when (args.getOrNull(0)?.lowercase()) {
11 "datastream" -> DataStreamApp.run()
12 "table" -> TableApp.run()
13 else -> println("Usage: <datastream | table>")
14 }
15 } catch (e: Exception) {
16 logger.error(e) { "Fatal error in ${args.getOrNull(0) ?: "app"}. Shutting down." }
17 exitProcess(1)
18 }
19}
Run Flink Application
As with the DataStream job in the previous post, running the Table API application involves setting up a local Kafka environment from the Factor House Local project, starting the data producer, and then launching the Flink job with the correct argument.
Factor House Local Setup
To set up your local Kafka environment, follow these steps:
- Clone the Factor House Local repository:
1git clone https://github.com/factorhouse/factorhouse-local.git 2cd factorhouse-local - Ensure your Kpow community license is configured (see the README for details).
- Start the services:
1docker compose -f compose-kpow-community.yml up -d
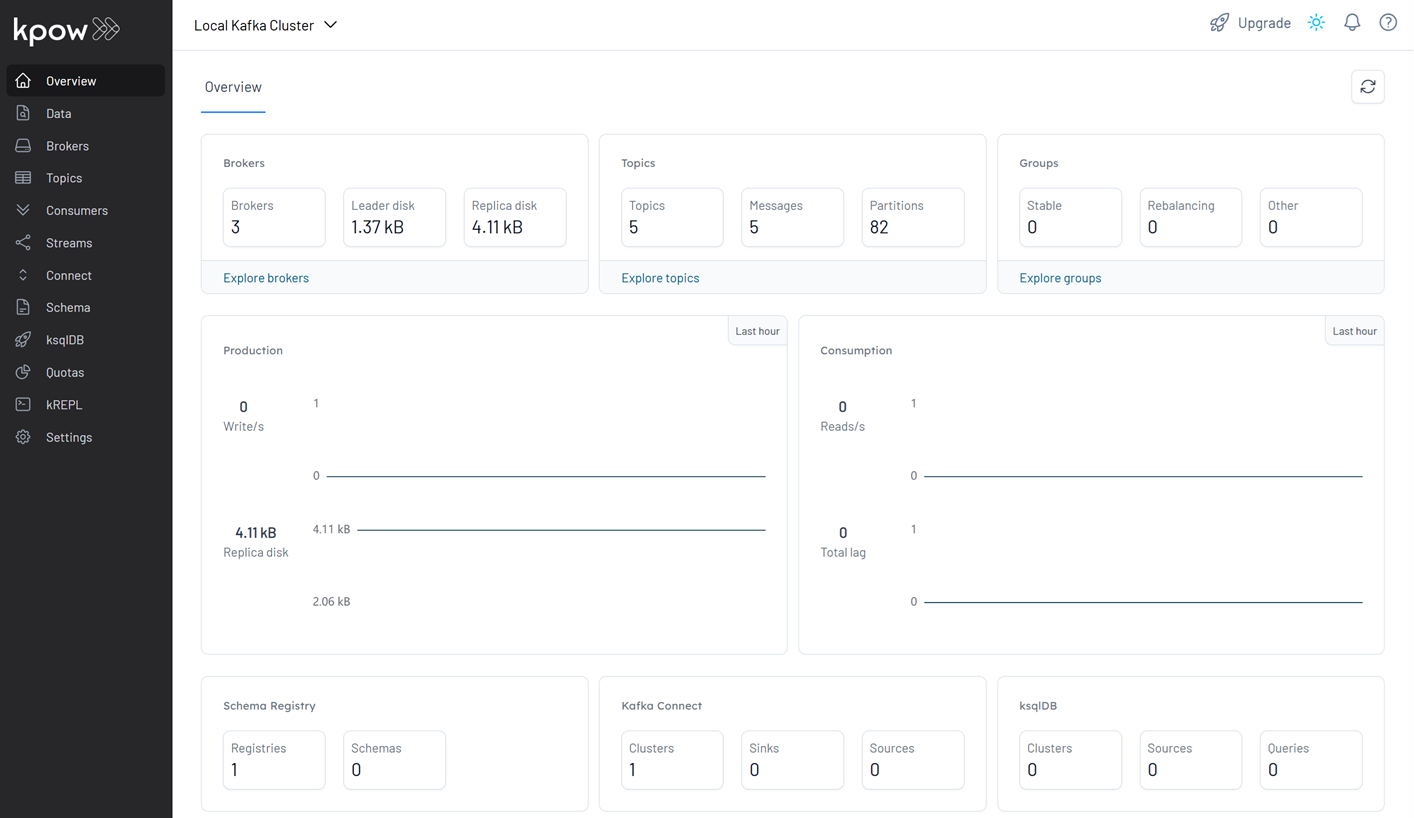
Once initialized, Kpow will be accessible at http://localhost:3000, showing Kafka brokers, schema registry, and other components.
Start the Kafka Order Producer
Next, start the Kafka data producer from the orders-avro-clients project (developed in Part 2 of this series) to populate the orders-avro topic. To properly test the application’s handling of late events, it’s crucial to run the producer with a randomized delay (up to 30 seconds).
Navigate to the producer’s project directory (orders-avro-clients) in the GitHub repository and execute the following:
1# Assuming you are in the root of the 'orders-avro-clients' project
2DELAY_SECONDS=30 ./gradlew run --args="producer"
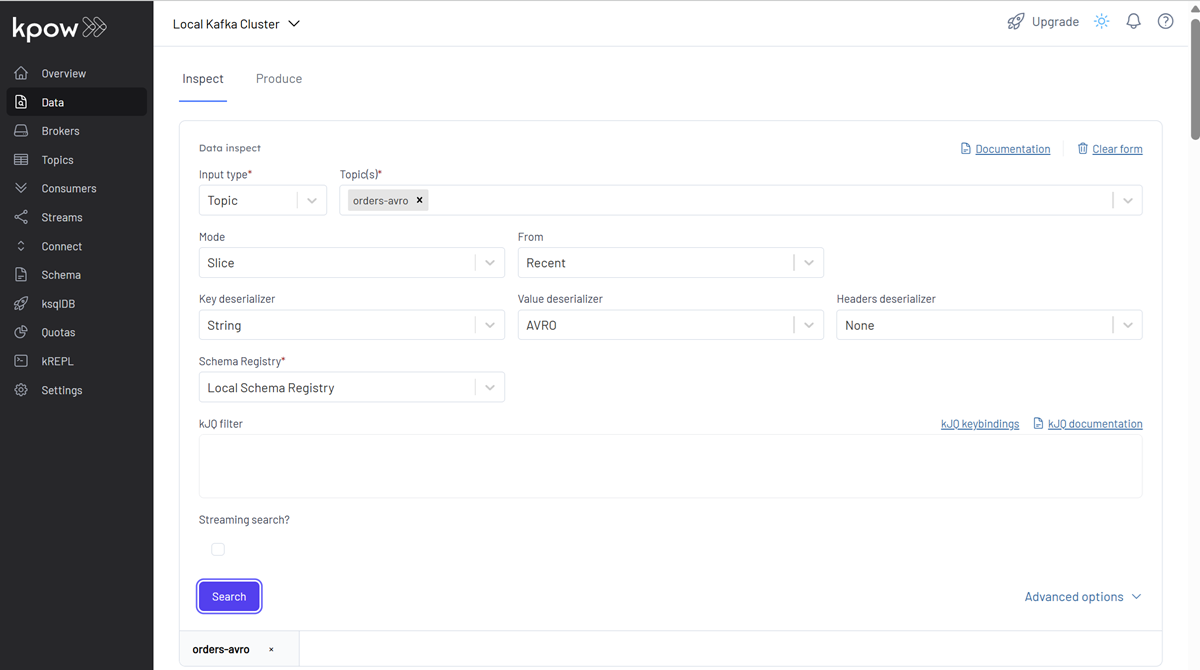
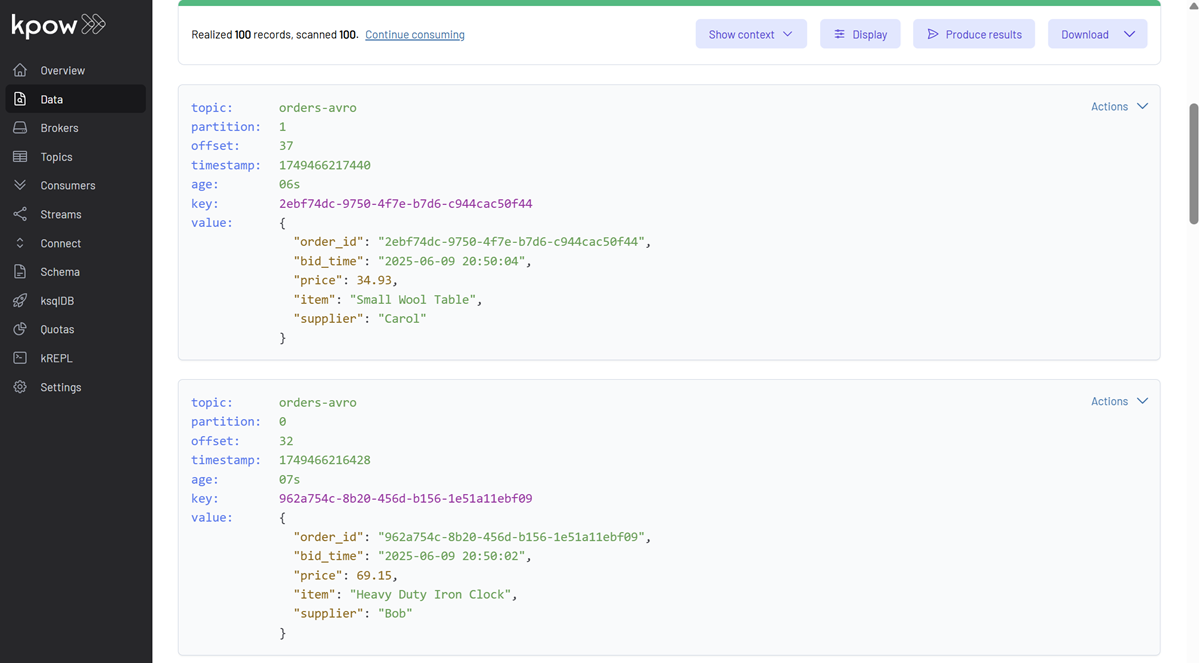
This will start populating the orders-avro topic with Avro-encoded order messages. You can inspect these messages in Kpow. Ensure Kpow is configured with Key Deserializer: String, Value Deserializer: AVRO, and Schema Registry: Local Schema Registry.
Launch the Flink Application
With the data pipeline ready, navigate to the orders-stats-flink project directory of the GitHub repository. This time, we’ll launch the job by providing table as the command-line argument to trigger the declarative, Table API-based logic.
The application can be run in two main ways:
- With Gradle (Development Mode): Ideal for development and quick testing.
1./gradlew run --args="table" - Running the Shadow JAR (Deployment Mode): For deploying the application as a standalone unit. First, build the fat JAR:This creates
1./gradlew shadowJarbuild/libs/orders-stats-flink-1.0.jar. Then run it:1java --add-opens=java.base/java.util=ALL-UNNAMED \ 2 -jar build/libs/orders-stats-flink-1.0.jar table
💡 To build and run the application locally, ensure that JDK 17 is installed.
For this demonstration, we’ll use Gradle to run the application in development mode. Upon starting, you’ll see logs indicating the Flink application has initialized and is processing records from the orders-avro topic.
Observing the Output
Our Flink application produces results to two topics:
orders-avro-ktl-stats: Contains the aggregated supplier statistics as Avro records.orders-avro-ktl-skipped: Contains records identified as “late,” serialized as JSON.
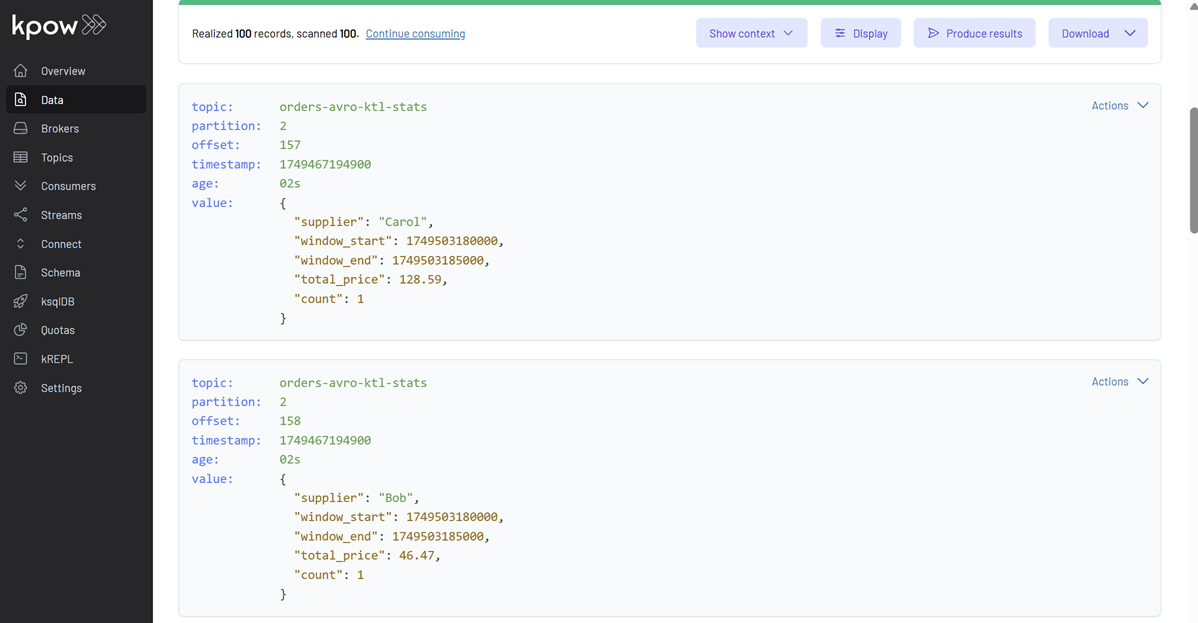
1. Supplier Statistics (orders-avro-ktl-stats):
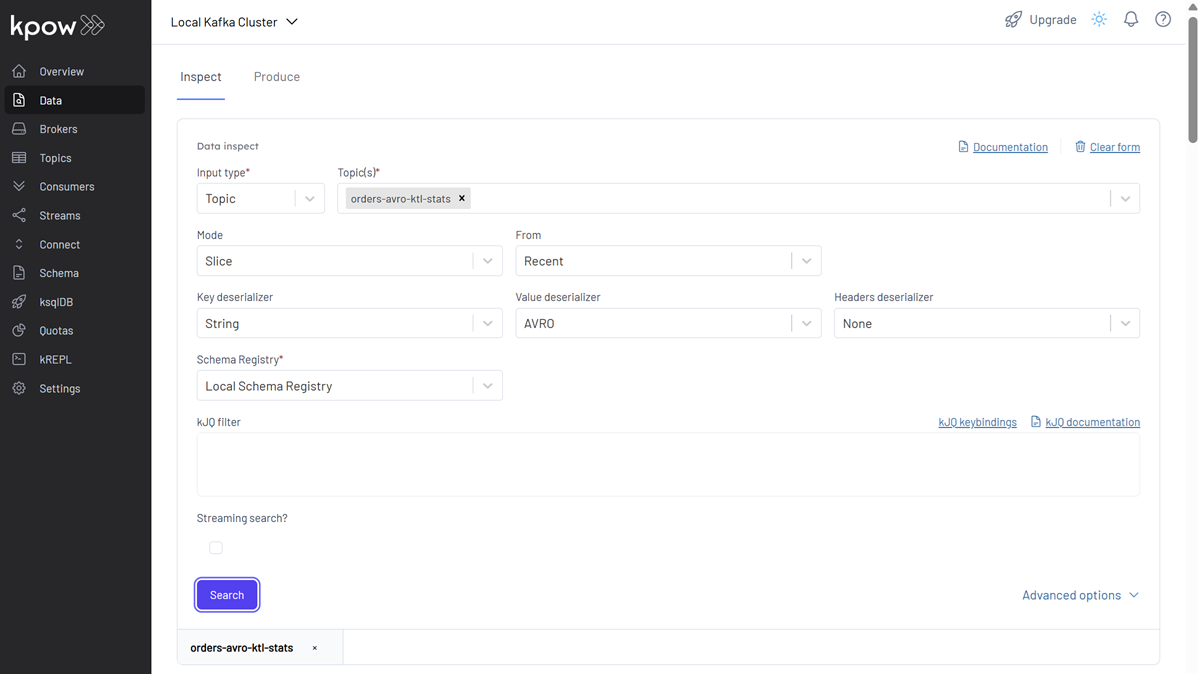
In Kpow, navigate to the orders-avro-ktl-stats topic. Configure Kpow to view these messages:
- Key Deserializer: String
- Value Deserializer: AVRO
- Schema Registry: Local Schema Registry
You should see SupplierStats messages, each representing the total price and count of orders for a supplier within a 5-second (or 5000 millisecond) window. Notice the window_start and window_end fields.
2. Skipped (Late) Records (orders-avro-ktl-skipped):
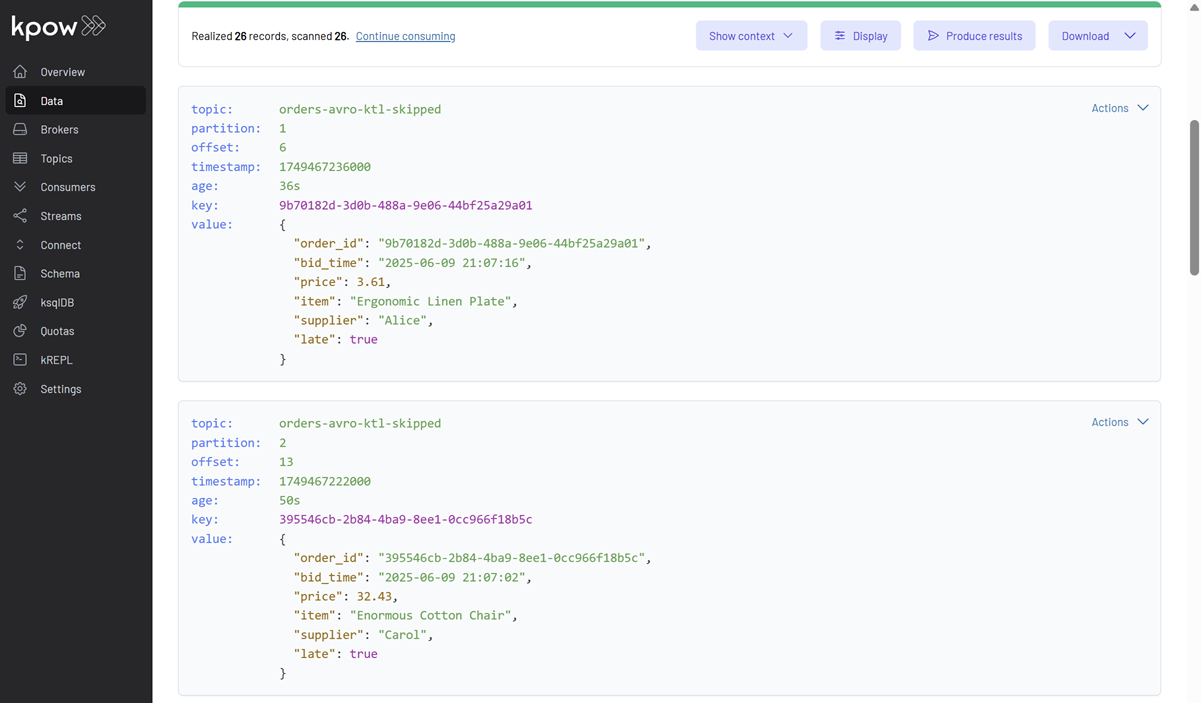
Next, inspect the orders-avro-ktl-skipped topic in Kpow. Configure Kpow as follows:
- Key Deserializer: String
- Value Deserializer: JSON
These records were intercepted and rerouted by our custom LateDataRouter ProcessFunction. This manual step was necessary to separate late data before converting the stream to a Table, demonstrating a powerful pattern of blending Flink’s APIs to solve complex requirements.
Conclusion
In this final post of our series, we’ve demonstrated the power and simplicity of Flink’s Table API for real-time analytics. We successfully built a pipeline that produced the same supplier statistics as our previous examples, but with a more concise and declarative query. We’ve seen how to define a table schema, apply event-time windowing with SQL-like expressions, and seamlessly bridge between the DataStream and Table APIs to implement custom logic like late-data routing. This journey, from basic Kafka clients to Kafka Streams and finally to the versatile APIs of Flink, illustrates the rich ecosystem available for building modern, real-time data applications in Kotlin. Flink’s Table API, in particular, proves to be an invaluable tool for analysts and developers who need to perform complex analytics on data in motion.










Comments