
In the modern data stack, providing direct access to powerful engines like Apache Spark and Flink is a double-edged sword. While it empowers users, it often leads to chaos: resource contention from “noisy neighbors,” inconsistent security enforcement, and operational fragility. The core problem is the lack of a robust control plane between users and the raw compute power. The solution, therefore, isn’t to take power away from users, but to manage it through an intelligent intermediary.
This is where a gateway-centric architecture comes in. By placing a specialized gateway at the heart of the platform, we can transform this chaos into a stable, governed, and self-service system. The Apache Kyuubi project provides a perfect blueprint for this approach, defining its role as:
Apache Kyuubi is a distributed, multi-tenant gateway providing unified access to big data engines like Spark and Flink via JDBC/ODBC for interactive queries and REST APIs for programmatic submissions.
This definition is more than just a product description; it’s a strategic vision. By embracing this model, we can finally deliver on the promise of self-service data access without sacrificing stability or governance. Let’s explore exactly how each layer of the platform is designed to support this powerful concept.
Architecture: A Layer-by-Layer Breakdown
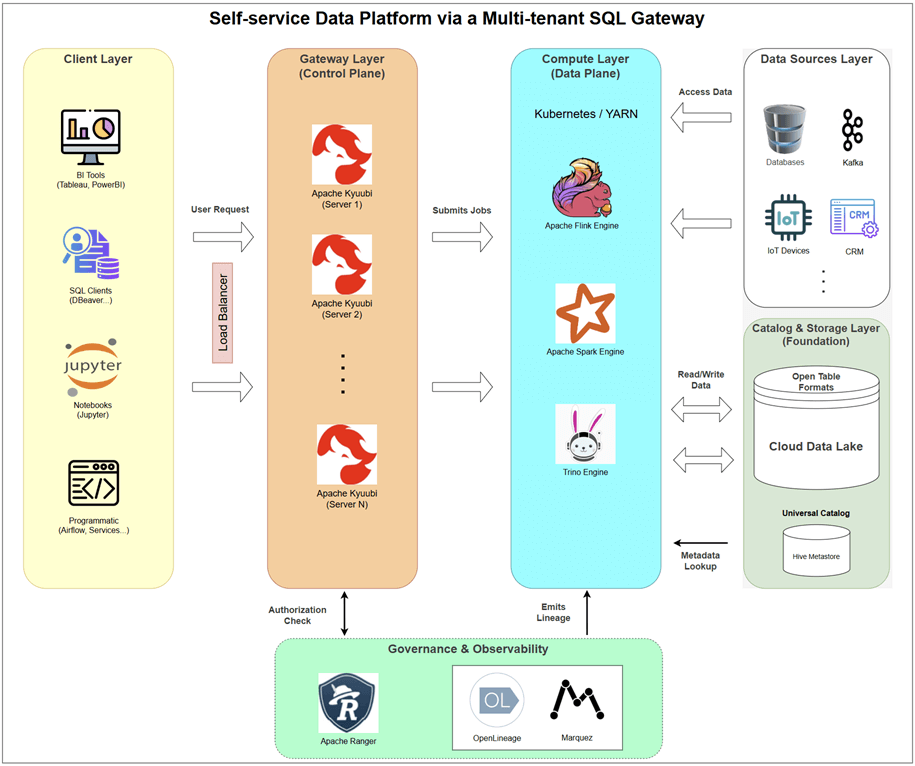
1. Client Layer: Simplicity Through Standardization
How do users connect? Via interactive SQL clients or programmatic APIs.
The primary goal of a self-service platform is to meet users where they are. The gateway makes this possible by providing multiple, standardized entry points, ensuring that both interactive users and automated systems can leverage the platform’s power. Kyuubi provides two primary connection methods: the Thrift API for interactive SQL and the REST API for programmatic batch workloads.
Thrift API: Gateway for Interactive Analytics
This is the most established and widely used connection method, ideal for analysts and data scientists using standard BI and SQL tools.
- Primary Use Case: Interactive, ad-hoc queries and data exploration.
- How it Works: Kyuubi implements the HiveServer2 Thrift protocol, which is the standard for SQL-on-Big-Data. This allows any tool that can communicate with Hive or Spark SQL to connect seamlessly to Kyuubi using a standard JDBC/ODBC driver.
- Tools: Tableau, PowerBI, DBeaver, Jupyter Notebooks (with PyHive), and other SQL-native clients.
- Gateway’s Role: From the user’s perspective, they are connecting to a traditional database. They don’t need engine-specific drivers or complex connection strings. The immense complexity of the underlying Spark or Flink engines is completely abstracted away behind one familiar JDBC/ODBC endpoint. The Thrift interface uses long-lived connections, making it well-suited for the back-and-forth nature of an interactive session.
💡 Note: While tools typically use JDBC or ODBC drivers, these drivers communicate over the Thrift protocol—hence the term “Thrift API” is technically accurate.
REST API: Interface for Programmatic Workflows
This interface is designed for automation, batch job submission, and integration into larger data pipelines.
- Primary Use Case: Submitting and managing batch jobs (e.g., SQL, Scala, Python, or JAR files) programmatically. This is perfect for ETL/ELT workflows, scheduled reports, and machine learning model training.
- How it Works: The REST API operates over standard, short-lived HTTP connections. Clients can submit a job definition (including the code and execution parameters) to a REST endpoint. Kyuubi then manages the entire lifecycle of the batch job on the user’s behalf. This stateless approach is ideal for automation and works well with load balancers in a high-availability setup.
- Tools:
- Programmatic Clients: Custom applications, workflow orchestrators like Apache Airflow, or scripts using tools like
curl. - Command-Line Tool: Kyuubi provides
kyuubi-ctl, a command-line interface that uses the REST API for managing batch jobs via YAML files.
- Programmatic Clients: Custom applications, workflow orchestrators like Apache Airflow, or scripts using tools like
💡 Tip: Because of its stateless nature, the REST API is particularly well-suited for distributed environments and works seamlessly with CI/CD systems and job schedulers.
2. Gateway Layer: Multi-Tenant Control Plane
This is the heart of the architecture, where raw compute power is transformed into a stable, governed service.
This layer is where Apache Kyuubi lives. It is not merely a pass-through proxy; it is an intelligent, distributed control plane responsible for security, stability, and resource management. It acts as the indispensable intermediary between a diverse set of users and a powerful but complex set of backend engines.
High Availability and Fault Tolerance
A gateway cannot be a single point of failure. Kyuubi is designed for resilience and can be deployed in a high-availability (HA) configuration. You run multiple Kyuubi server instances, stateless by nature, behind a load balancer. Session information and operational metadata are stored in a shared, external state store (like ZooKeeper or Etcd). If one Kyuubi server goes down, the load balancer redirects clients to a healthy instance, which can then recover the user’s session state from the shared store, providing seamless failover for end-users.
Centralized Authentication Hub
Before any query is processed, the user must be authenticated. The gateway serves as the single, secure entry point for the entire platform. It integrates directly with standard enterprise authentication protocols like LDAP and Kerberos. This centralizes all authentication logic. Instead of exposing multiple engines and configuring security on each one, you secure one endpoint: the gateway. This simplifies client configuration and dramatically reduces the security attack surface.
True Multi-Tenancy through Dynamic Resource Isolation
This is Kyuubi’s most critical feature. It enforces multi-tenancy not just logically, but physically.
Engine-per-User Isolation: When a user connects and runs a query, Kyuubi does not send it to a shared, monolithic cluster. Instead, it dynamically provisions a dedicated compute engine (e.g., a Spark application on Kubernetes) scoped specifically to that user or their session. This is the key to true multi-tenancy: one user’s poorly written query consuming 100% of its engine’s CPU has zero impact on the performance or stability of another user’s engine.
Configurable Sharing Levels: Kyuubi also offers flexible engine-sharing modes to balance isolation and performance. While the default is to isolate by user (
USERlevel), you can configure it to share an engine at theCONNECTIONlevel or even create server-scoped engines for specific use cases, giving architects fine-grained control over resource trade-offs.
Unified Interface and Intelligent Routing
The gateway abstracts away the diversity of the backend. A user connects to a single JDBC/ODBC endpoint and speaks standard SQL. They don’t need to know which engine is best for their job.
Based on session properties set by the user or administrator (e.g., kyuubi.engine.type=FLINK), the gateway intelligently routes the request. It accepts the standard SQL, identifies the target engine type, manages the entire lifecycle of that engine (provisioning, query submission, termination), and streams the results back. This turns a complex ecosystem of Spark, Flink, and Trino into a single, unified, and easy-to-use SQL service for the entire organization.
3. Compute Layer: Powerhouse Engines
What does the gateway connect to? Isolated, on-demand Spark, Flink, and Trino engines.
This is where the actual data processing occurs. The compute layer consists of powerful, specialized engines, but they are no longer directly exposed to users. Instead, they are treated as a backend resource, managed entirely by the gateway based on the workload.
- Engines:
- Apache Spark: The workhorse for large-scale batch SQL processing and ETL.
- Apache Flink: The engine for real-time, continuous SQL queries on streaming data.
- Trino: The engine for high-performance, interactive federated queries across disparate data sources.
Gateway’s Role: A Lifecycle Manager for Compute
Kyuubi’s most important function is to act as an intelligent and dynamic lifecycle manager for these powerful engines. It doesn’t just proxy queries; it completely abstracts the complexity of resource management away from the end-user. Here’s how:
On-Demand, User-Scoped Provisioning: When a user connects and runs their first query, Kyuubi intercepts the request. It authenticates the user and, based on predefined rules, submits a request to a resource manager (like Kubernetes or YARN) to launch a brand new engine instance specifically for that user or session. This is the core of multi-tenancy: the engine is created on behalf of the user, runs with their permissions, and is completely isolated from other users’ engines. This eliminates the “noisy neighbor” problem, where one user’s heavy query can destabilize the entire platform.
Intelligent Caching and Sharing: While isolating engines is key, constantly launching new ones can introduce latency. Kyuubi manages this intelligently. It can be configured to keep a warm pool of engines ready or to share an engine across multiple queries from the same user within a single session. This provides the performance of a long-running session without sacrificing the isolation between different users.
Automatic Termination and Cost Control: Kyuubi is also responsible for cleanup. It constantly monitors the engines it has launched. If an engine sits idle for a configured period (e.g., 30 minutes), Kyuubi will automatically terminate it and release its resources back to the cluster. This is absolutely critical for cost-efficiency in a cloud environment, ensuring you only pay for compute resources when they are actively being used.
Seamless Abstraction: From the user’s perspective, this entire lifecycle is invisible. They write and execute standard SQL. They don’t need to know how to write a
spark-submitcommand, craft a Kubernetes pod YAML file, or worry about memory allocation. Kyuubi handles the translation from a simple SQL query to a complex, resource-managed job on a distributed engine, ensuring the right tool is used for the right job without exposing any of the underlying complexity.
4. Governance Layer: Centralized Control at the Gateway
How do we enforce rules? The gateway is the natural “chokepoint” for governance.
In a self-service world, governance must be automated. The gateway architecture makes this feasible because every single query and every user session must pass through it. This creates a natural control point for applying rules, though the specific capabilities can vary by the backend engine.
Authorization: An Engine-Specific Approach
The gateway acts as the central point for authenticating users and integrating with an authorization engine like Apache Ranger. However, the actual enforcement of security policies is delegated to the backend compute engines. This approach leverages the native security features of each engine, meaning the depth of integration differs across the platform, which is a critical architectural consideration.
- For Apache Spark: The integration is the most mature and powerful. Kyuubi provides a specialized Kyuubi Spark Authz Plugin that deeply integrates with Apache Ranger. This plugin allows Ranger to enforce fine-grained policies—including row-level filtering and column-level masking—directly within the Spark engine for all Spark SQL queries. The gateway authenticates the user, launches a Spark engine on their behalf, and the engine then uses the Authz plugin to check with Ranger and apply policies before execution. This provides robust, centralized security for all Spark-based workloads.
- For Apache Flink: The story is more about isolation and coarse-grained control. Kyuubi provides essential security for Flink through robust authentication and session isolation. This guarantees that only authenticated users can submit jobs and that their Flink sessions are isolated from others. However, fine-grained, policy-based authorization for Flink jobs is not handled by a Kyuubi plugin. Instead, security must be enforced at the data source level. A common pattern is to use Flink’s
HiveCatalogto read data from Hive tables, where Apache Ranger’s existing Hive-level policies can be applied for access control. - For Trino: Authorization is handled by delegating to Trino’s own powerful security model. Trino has a native Apache Ranger plugin that provides comprehensive, fine-grained access control. This plugin supports policies for catalogs, schemas, tables, and columns, as well as row-level filtering and column masking. In this architecture, Kyuubi’s role is to authenticate the user and then pass the user’s identity securely to the Trino engine. Trino then uses its own Ranger plugin to enforce the centralized policies. This allows organizations to manage Spark and Trino permissions within the same Ranger UI, while the enforcement happens natively within each respective engine.
Lineage: A Universal, Automated View of Your Data’s Journey
Unlike authorization, which can be engine-specific, data lineage is applied universally and automatically across the platform. This creates a complete, trustworthy audit trail for every query, which is essential for data governance, impact analysis, and debugging complex data flows.
- How It Works: Automated Agent Injection The gateway-centric design is the key to automating lineage collection. Kyuubi is configured to automatically inject a lightweight OpenLineage agent into the runtime of every single Spark and Flink engine it provisions. Users do not need to add any special libraries or modify their code; lineage capture is a guaranteed part of the platform’s execution process. For Trino, lineage is captured via a separate, native OpenLineage plugin configured directly within the Trino coordinator.
- What is Captured? Rich, Actionable Metadata
As jobs run, the OpenLineage agent observes the execution plan and collects detailed metadata. This isn’t just a high-level overview. The agent captures:
- Job Information: The name of the job, its start and end times, and whether it succeeded or failed.
- Dataset Information (Inputs and Outputs): The physical sources (e.g., S3 paths, Kafka topics, database tables) and destinations of the data.
- Column-Level Lineage (for Spark and Trino): For supported engines, the agent can trace the dependencies between specific columns, showing exactly how an output column was derived from one or more input columns. This is invaluable for tracking sensitive data and understanding complex transformations.
- Operational Statistics: Metadata about the run itself, such as the number of rows written or bytes processed.
- Governance Backend: Visualizing the Flow
The agent sends this stream of standardized JSON-formatted lineage events to a compatible metadata service, with Marquez being the reference implementation for OpenLineage. Marquez consumes this metadata and builds a comprehensive, interactive graph of your entire data ecosystem. This provides a single, unified map showing how all datasets are created and consumed across Spark, Flink, and Trino, answering critical questions:
- “If I change this table schema, what downstream jobs and dashboards will break?”
- “This report looks wrong. Where did the data it uses come from?”
- “Which jobs are processing PII data?”
By making lineage collection an automatic, non-negotiable part of the platform architecture, governance is no longer an afterthought. It becomes a reliable, built-in feature that provides a complete and auditable view of how data moves and transforms across the entire organization.
5. Catalog & Storage Layer: Foundation of Truth
Where does the data live? In a standard data lake, accessed via the gateway’s managed engines.
This layer is the physical and logical foundation of the platform. The gateway itself doesn’t store data, but it manages the engines that access it.
- Storage: Cloud object stores like Amazon S3, GCS, or ADLS.
- Table Formats: Open table formats like Apache Iceberg, Apache Hudi, Delta Lake, and Apache Paimon, which provide transactional (ACID) capabilities on top of raw data files in your data lake.
- Catalog: A universal Hive Metastore.
- Gateway’s Role: The gateway ensures that all access to the data lake is mediated. A user cannot simply spin up their own Spark session to bypass rules. For example, to read an Iceberg table, they must submit a SQL query through Kyuubi. The gateway then authenticates them and, particularly for Spark, ensures they are authorized before provisioning an engine to perform the read.
Use Case 1: Interactive Batch Query (Spark)
Let’s trace a classic analytics workflow to see the architecture in action.
- An analyst connects Tableau to the Kyuubi JDBC endpoint.
- They write a SQL query joining several large Iceberg tables. Tableau sends this standard SQL to the Kyuubi Gateway.
- Kyuubi receives the query. It authenticates the user and checks their detailed permissions with Apache Ranger.
- Seeing this is the user’s first query, Kyuubi provisions a new, dedicated Spark application for them on Kubernetes, injecting the OpenLineage agent.
- Kyuubi forwards the SQL to the user’s isolated Spark engine.
- The Spark engine uses the Hive Metastore to find the data’s location on S3 and executes the query.
- Results are streamed back through the Spark engine, to the Kyuubi gateway, and finally to Tableau. The entire process is isolated, governed, and transparent to the user.
Use Case 2: Real-Time Streaming Query (Flink & Kafka)
The platform’s true power is its ability to handle more than just batch analytics. Let’s see how an analyst can query a live stream of clickstream data from Apache Kafka using Flink SQL, all through the same gateway.
The user connects their SQL client to the exact same Kyuubi JDBC endpoint. They then define a table backed by a Kafka topic and query it continuously:
1-- Step 1: Map a table structure onto a live Kafka topic.
2-- The underlying Flink engine uses its Kafka connector to handle this.
3CREATE TABLE ClickStream (
4 `user_id` BIGINT,
5 `url` STRING,
6 `event_timestamp` TIMESTAMP(3) METADATA FROM 'timestamp',
7 WATERMARK FOR `event_timestamp` AS `event_timestamp` - INTERVAL '5' SECOND
8) WITH (
9 'connector' = 'kafka',
10 'topic' = 'clickstream_events',
11 'properties.bootstrap.servers' = 'kafka-broker-1:9092,...',
12 'scan.startup.mode' = 'latest-offset',
13 'format' = 'json'
14);
15
16-- Step 2: Run a continuous query against the live stream.
17-- This query will run indefinitely, pushing new results to the client as they arrive.
18SELECT
19 TUMBLE_START(event_timestamp, INTERVAL '1' MINUTE) as window_start,
20 url,
21 COUNT(*) as clicks
22FROM
23 ClickStream
24GROUP BY
25 TUMBLE(event_timestamp, INTERVAL '1' MINUTE),
26 url;
How it Works:
- The user sends the
CREATE TABLEandSELECTstatements to the Kyuubi JDBC endpoint. - Kyuubi authenticates the user. Based on session properties, it recognizes this as a Flink workload and provisions a dedicated Flink session cluster on Kubernetes, again injecting the OpenLineage agent.
- Kyuubi submits the SQL to the Flink cluster.
- Flink’s SQL engine parses the query. It uses its Kafka connector to connect to the
clickstream_eventstopic and begins consuming the JSON data stream. - The
SELECTquery runs continuously. As new data arrives in Kafka, Flink processes it, calculates the tumbling window aggregates, and streams the updated results back through the Kyuubi gateway to the analyst’s SQL client. - Simultaneously, the OpenLineage agent reports to Marquez that a new data flow has been established, drawing a lineage graph from the Kafka topic to this Flink SQL job.
Conclusion: The Power of a Gateway-Centric Design
Building a successful self-service platform is not about exposing raw power, but about providing controlled, stable, and governed access. By embracing a gateway-centric architecture built around the principles embodied by Apache Kyuubi, you can finally resolve the conflict between user empowerment and platform stability. The gateway acts as the indispensable control plane, turning a potential “Wild West” of big data engines into a well-regulated, multi-tenant, and powerful SQL service for the entire organization—for both batch and real-time workloads.










Comments