
Overview
Traditional recommendation approaches such as Collaborative Filtering remain widely adopted, yet they come with notable constraints. They are particularly vulnerable to the cold-start problem, where new users lack sufficient interaction history, and they depend heavily on long-term behavioral data. As a result, they frequently overlook real-time contextual signals, including time of day, device type, location, or session intent. This can prevent them from capturing situational preferences, such as someone preferring coffee in the morning but pizza in the evening.
Contextual Multi-Armed Bandits (CMAB) address these gaps through online learning.
As a practical form of reinforcement learning, CMAB balances two goals in real time:
- Exploitation: Recommending what is known to work.
- Exploration: Trying less-tested options to discover new favorites.
By conditioning decisions on live context, CMAB adapts instantly to changing user behavior.
Why CMAB?
- Beyond A/B Testing: Instead of finding a single global winner, CMAB enables 1:1 personalization, selecting the best option for this user in this context.
- Real-Time Adaptation: Unlike batch-trained models that quickly become stale, CMAB updates incrementally, making it ideal for news/products recommendation, dynamic pricing, or inventory-aware ranking.
Several CMAB implementations exist, including Vowpal Wabbit and River ML. In this post, we use Mab2Rec for offline policy evaluation and MABWiser to build the product recommender prototype.
Data Streaming Opportunity
CMAB performs well in data streaming environments. Integrated with platforms like Kafka and Flink, it learns directly from event streams, creating a feedback loop that responds to trends and shifts in user intent in sub-seconds.
In this series, Part 1 (this post) builds a complete Python prototype to validate the algorithm and simulate user behavior. Part 2 will scale this to a distributed, event-driven architecture.
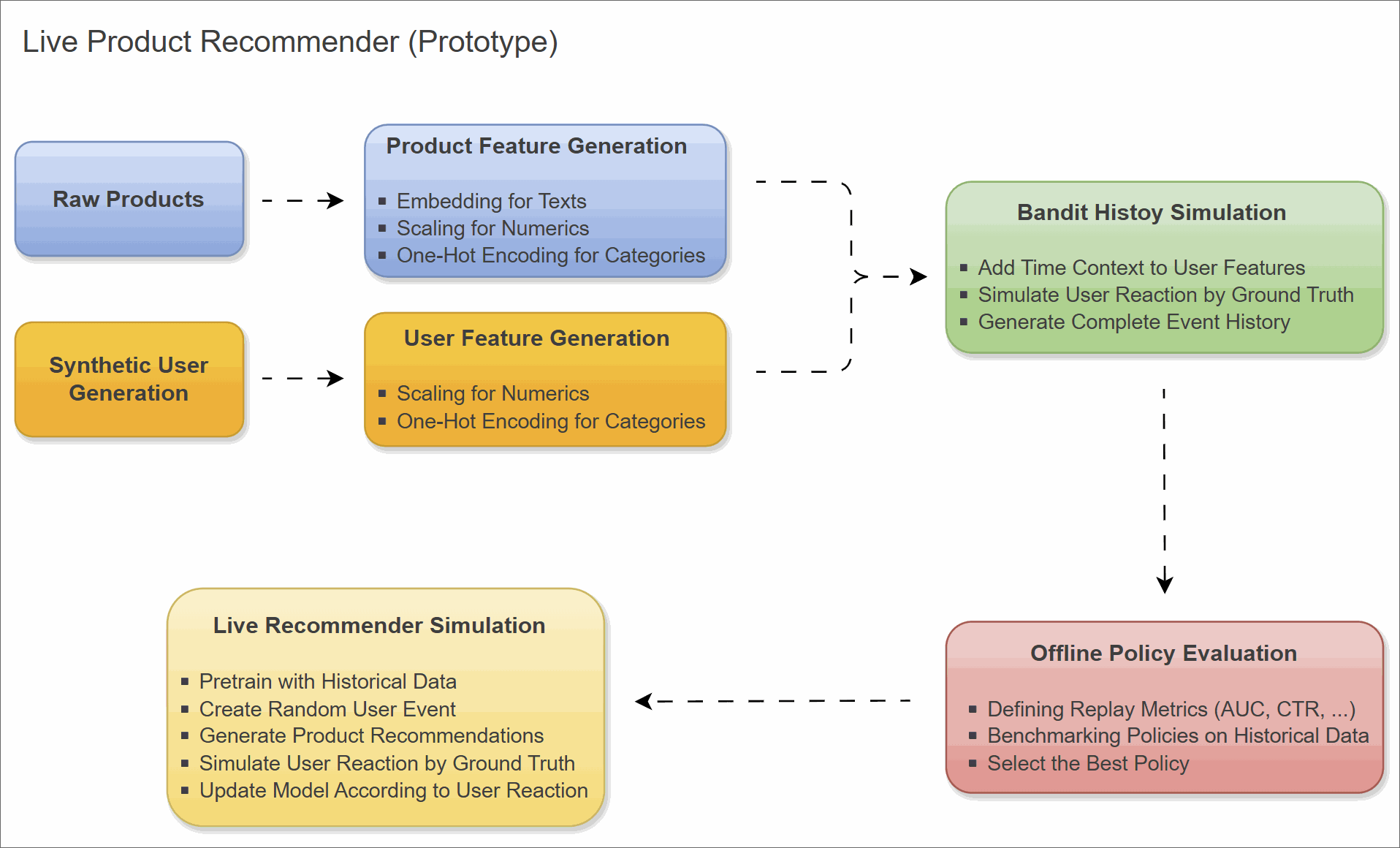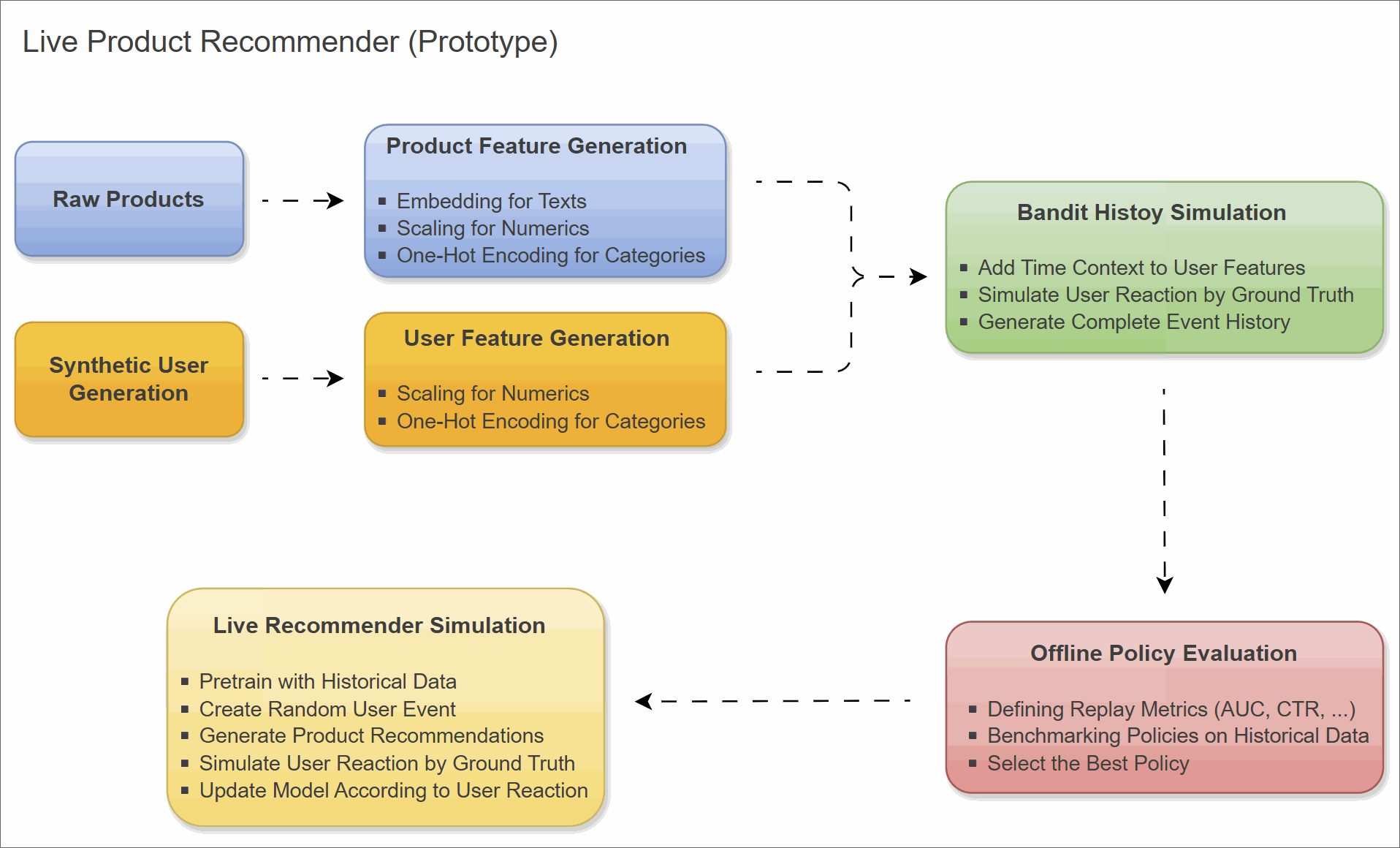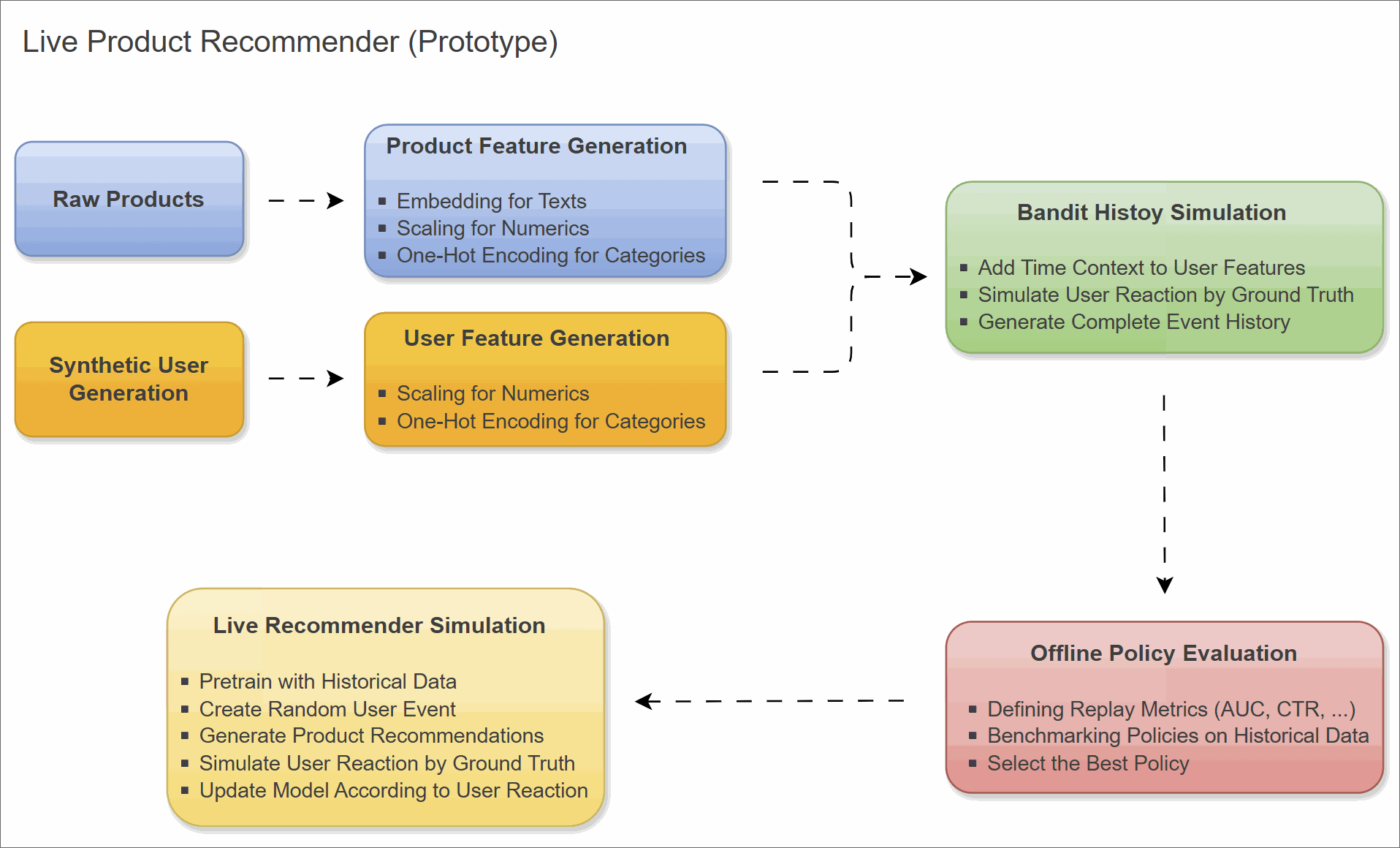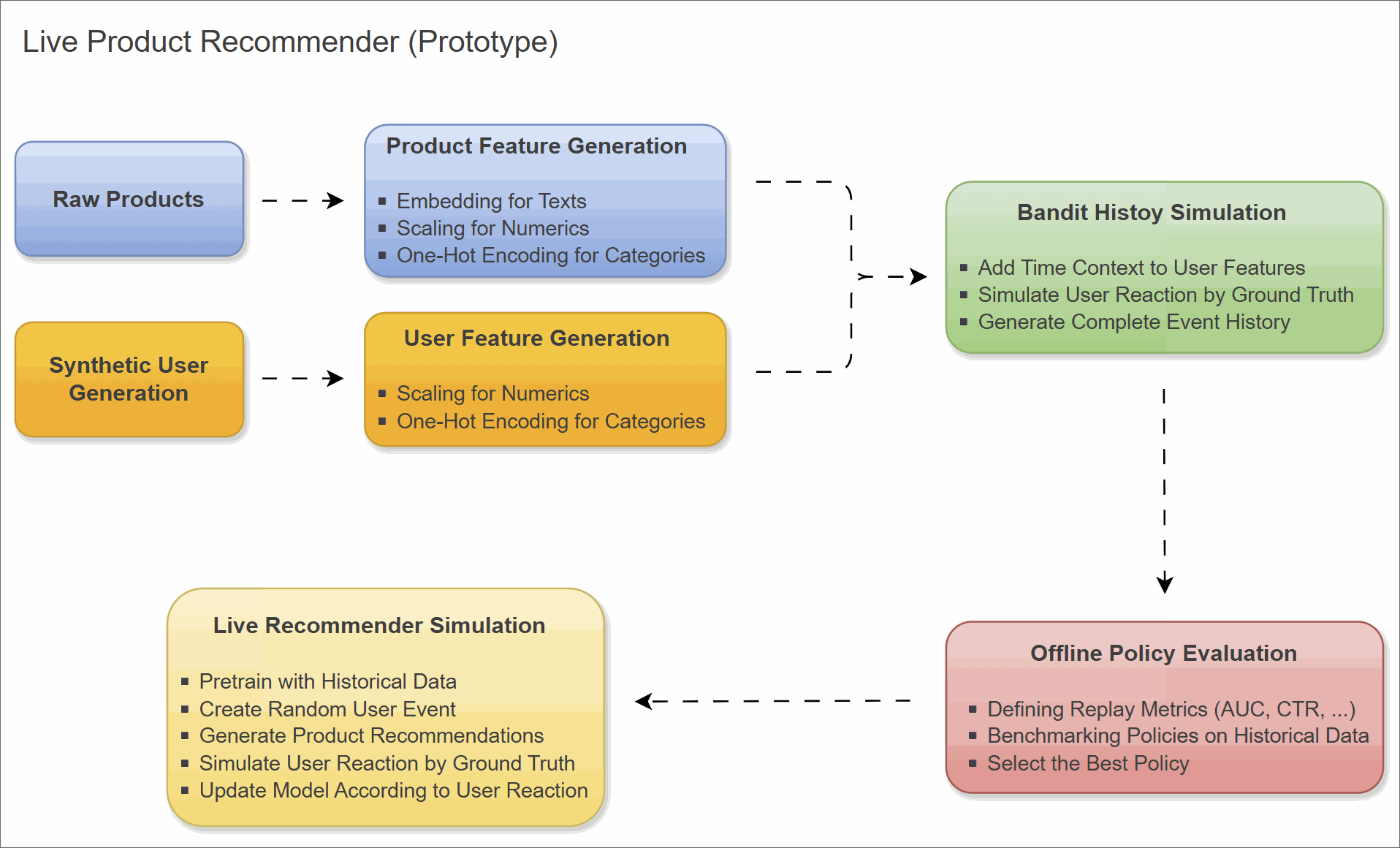
Tech Stack
We are building this prototype using Python 3.11.
Engineering Note: We explicitly chose Python 3.11 because parts of our stack (specifically
mabwiserdependencies) rely on older versions ofpandas(< 2.0). On Python 3.12+, installing these dependencies often triggers long compilation times or failures due to missing binary wheels.
We use uv for Python environment management. The core libraries include:
- MABWiser: The engine. It implements the core Contextual Bandit algorithms.
- Mab2Rec: The vehicle. A high-level wrapper that streamlines Recommender System pipelines.
- TextWiser: For converting raw text features into numerical embeddings.
- scikit-learn: For feature scaling and encoding.
- Faker & Pandas: For synthetic data generation and simulation.
The development environment can be constructed as follows:
1$ git clone https://github.com/jaehyeon-kim/streaming-demos.git
2$ cd streaming-demos
3$ uv python install 3.11
4$ uv venv --python 3.11 venv
5$ source venv/bin/activate
6(venv) $ uv pip install -r product-recommender/requirements.txt
7(venv) $ uv pip list | grep -E "mab|wiser|panda|numpy|scikit|faker"
8# Using Python 3.11.14 environment at: venv
9# faker 40.1.2
10# mab2rec 1.3.1
11# mabwiser 2.7.4
12# numpy 1.26.4
13# pandas 1.5.3
14# scikit-learn 1.8.0
15# textwiser 2.0.2
📂 Source Code for the Post
The source code for this post is available in the product-recommender folder of the streaming-demos GitHub repository.
Data Generation
We first need product and user data to generate the required features.
Products
We utilize a set of 200 raw products, each containing a product ID, name, text description, price, and high-level category.
Here is a list of sample products:
| product_id | name | description | price | category |
|---|---|---|---|---|
| 8 | The Aussie Burger | A true classic with beetroot, a fried egg, pineapple, bacon, cheese, lettuce, and tomato. | 16.99 | Burgers & Sandwiches |
| 42 | The Aussie Pizza | Tomato base topped with ham, bacon, onions, and a cracked egg in the center. | 23.99 | Pizzas |
| 61 | Chicken Parma | Classic crumbed chicken breast topped with napoli, ham, and cheese. Served with chips & salad. | 24.99 | Aussie Pub Classics |
| 101 | Fish Tacos (Baja Style) | Three tortillas with battered fish, cabbage, and creamy sauce. | 12.95 | Mexican Specialties |
Users
We generate 1,000 Synthetic Users using Faker. Each user is assigned static attributes like Age, Gender, Location, and Traffic Source. These attributes will serve as the “Context” for our Bandit.
Here is a sample of our user base:
Note that street address, postal code, city, state, and country are omitted, as only latitude and longitude are used for feature generation.
| user_id | first_name | last_name | … | age | gender | latitude | longitude | traffic_source | |
|---|---|---|---|---|---|---|---|---|---|
| 1 | Stephen | Parker | stephen.parker@example.net | … | 38 | M | -37.78525508 | 144.94969 | Search |
| 2 | Brianna | Williams | brianna.williams@example.net | … | 60 | F | -37.82290733 | 145.0040437 | Search |
| 3 | Carlos | Hunt | carlos.hunt@example.com | … | 46 | M | -37.74295704 | 144.8004261 | Search |
| 4 | Charles | Martin | charles.martin@example.com | … | 41 | M | -37.80480003 | 145.1229819 | Organic |
Feature Engineering
Bandit algorithms operate on numerical vectors, not raw text. In other words, they cannot interpret "Burger" unless it is converted into numbers. To address this, we developed a transformation pipeline to properly prepare our data:
- Product Features: We used
TextWiserto convert raw product descriptions into vector embeddings. This allows the model to understand that “Burger” and “Sandwich” are semantically closer than “Burger” and “Headphones”. We also applied One-Hot Encoding to categories (Product Category) and MinMax scaling to the price. Finally, we added a binary feature,is_coffee, which is set to 1 for coffee products (e.g., espresso, cappuccino) and 0 otherwise. - User Features: Similar to the product features, we applied One-Hot Encoding to categories (Gender and Traffic Source) and MinMax scaling to numerical fields (Age, Latitude, and Longitude).
- Pipeline Artifacts: We save these transformers as
preprocessing_artifacts.pkl. This allows our system to instantly transform any new user/product record into a compatible feature vector during inference.
Sample Processed Product Features:
Notice how the description is now represented by txt_0…txt_9 embeddings.
| product_id | txt_0 | txt_1 | txt_2 | txt_3 | txt_4 | txt_5 | txt_6 | txt_7 | txt_8 | txt_9 | cat_Appetizers & Sides | cat_Aussie Pub Classics | cat_Burgers & Sandwiches | cat_Drinks & Desserts | cat_Mexican Specialties | cat_Pasta & Risotto | cat_Pizzas | cat_Salads & Healthy Options | is_coffee | price |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8 | 0.3354452 | 0.36037982 | -0.04443971 | 0.14370468 | -0.19956689 | -0.17493485 | -0.18741444 | -0.02776922 | -0.07173516 | -0.11751403 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0.3887 |
| 42 | 0.3015529 | 0.28032377 | 0.03035132 | 0.21287075 | 0.04236558 | -0.054545 | -0.10349114 | -0.13550489 | -0.04504355 | -0.22817583 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0.5832 |
| 61 | 0.53950787 | -0.020039 | -0.36858445 | -0.10636957 | 0.00259933 | 0.15990224 | 0.04153050 | 0.11348728 | -0.02482079 | -0.23463035 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.6110 |
| 101 | 0.20630628 | -0.04121789 | 0.11134595 | -0.2160106 | 0.00511632 | -0.20131038 | 0.05482014 | -0.19734132 | 0.35356910 | 0.23985470 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0.2765 |
Sample Processed User Features:
Notice that Age, Latitude and Longitude are normalized between 0 and 1, and categorical fields are binary.
| user_id | age | latitude | longitude | gender_F | gender_M | traffic_source_Display | traffic_source_Email | traffic_source_Facebook | traffic_source_Organic | traffic_source_Search |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0.4074074 | 0.82048548 | 0.32804966 | 0 | 1 | 0 | 0 | 0 | 0 | 1 |
| 2 | 0.8148148 | 0.76928412 | 0.41833646 | 1 | 0 | 0 | 0 | 0 | 0 | 1 |
| 3 | 0.5555556 | 0.87800441 | 0.08010776 | 0 | 1 | 0 | 0 | 0 | 0 | 1 |
| 4 | 0.4629630 | 0.79390730 | 0.61590441 | 0 | 1 | 0 | 0 | 0 | 1 | 0 |
Bandit History Simulation
To evaluate whether our model can truly learn user behavior, we need a controlled Ground Truth, which is an Oracle that determines the likelihood of a simulated user clicking on a recommendation.
Crucially, this Oracle is hidden from the model. The model’s task is to infer these patterns purely from trial and error.
We also inject Dynamic Context features like Time of Day and Day of Week into the user profile at the moment of interaction. These temporal signals create realistic, fluctuating patterns that the model must adapt to.
Simulation Logic
The simulation is implemented as a class GroundTruth, and we define specific rules that govern user behaviour:
- Start from a low base logit (−2.5) to model generally low click probability.
- Rule 1: Morning coffee preference: if the user is browsing in the morning and the item is a coffee product, add a strong positive boost to the score.
- Rule 2: Weekend comfort food: if the session is on a weekend and the item is Pizza or Burgers & Sandwiches, add a moderate positive boost.
- Rule 3: Budget sensitivity: if the user is young (normalized age < 0.25) and the item is expensive (normalized price > 0.8), apply a strong negative penalty.
- Rule 4: Traffic source bias: if the user arrived via Search, add a small intent-based boost.
- Convert the final logit score into a click probability using a sigmoid function, then sample a Bernoulli trial to simulate whether a click occurs.
1# product-recommender/recsys-engine/src/bandit_simulator.py
2class GroundTruth:
3 """
4 The HIDDEN FORMULA (Ground Truth) for click simulation.
5 Determines user click behavior based on context and item features.
6 """
7
8 @staticmethod
9 def calculate_probability(user_ctx: dict, item_ctx: dict) -> float:
10 """
11 Computes the probability that a user clicks an item.
12 Uses logistic regression-style scoring with domain-specific rules.
13 """
14 score = -2.5 # Base logit: starts with a low probability
15
16 # Rule 1: Morning Coffee
17 # Users are more likely to click coffee in the morning
18 if user_ctx.get("is_morning") == 1 and item_ctx.get("is_coffee") == 1:
19 score += 2.5
20
21 # Rule 2: Weekend Comfort Food
22 # Users tend to choose Pizza or Burgers on weekends
23 if user_ctx.get("is_weekend") == 1:
24 if item_ctx.get("cat_Pizzas") == 1 or item_ctx.get("cat_Burgers & Sandwiches") == 1:
25 score += 1.8
26
27 # Rule 3: Budget Constraint
28 # Young users (<25 years) avoid expensive items (normalized price > 0.8)
29 user_age = user_ctx.get("age", 0.5) # normalized age 0-1
30 item_price = item_ctx.get("price", 0.5) # normalized price 0-1
31 if user_age < 0.25 and item_price > 0.8:
32 score -= 3.0
33
34 # Rule 4: Traffic Bias
35 # Users arriving via Search have a slightly higher propensity to click
36 if user_ctx.get("traffic_source_Search") == 1:
37 score += 0.5
38
39 # Convert logit score to probability using sigmoid function
40 return 1 / (1 + np.exp(-score))
41
42 def will_click(self, user_ctx: dict, item_ctx: dict, fake: Faker) -> int:
43 """
44 Simulates a Bernoulli trial (click = 1, no click = 0) based on probability.
45 """
46 prob = self.calculate_probability(user_ctx, item_ctx)
47 return 1 if fake.random.random() < prob else 0
Data Preparation
We generate 10,000 historical events to serve as our “Offline Training” dataset. This process involves picking a random user and a random product, then asking the Oracle “Did they click?”.
Because the user and product are matched randomly (not by a recommender), the Average Click Rate (CTR) is naturally low. In this example, it is around 13.65%, and this serves as our baseline.
💡 There are three main scripts for this post: prepare_data.py for feature engineering and bandit history simulation, evalue.py for offline policy evaluation, and local_recommender.py for running product recommendation locally. Each script accepts a --seed argument, which defaults to 1237. As long as the seed remains the same, running the scripts will produce identical outputs.
1(venv) $ python product-recommender/recsys-engine/prepare_data.py
2[2026-01-26 19:16:09] INFO : Generating 1000 synthetic users...
3[2026-01-26 19:16:09] INFO : Saved raw users to: .../users.csv
4[2026-01-26 19:16:09] INFO : Starting Feature Engineering...
5[2026-01-26 19:16:09] INFO : Saved User Features: (1000, 11)
6[2026-01-26 19:16:10] INFO : Saved Product Features: (200, 21)
7[2026-01-26 19:16:10] INFO : Saved Pipeline Artifacts to: .../preprocessing_artifacts.pkl
8[2026-01-26 19:16:10] INFO : Loaded 1000 users and 200 products.
9[2026-01-26 19:16:10] INFO : Generating 10000 events...
10[2026-01-26 19:16:10] INFO : Done. Saved Training Log to .../training_log.csv
11[2026-01-26 19:16:10] INFO : Avg Click Rate: 13.65%
12[2026-01-26 19:16:10] INFO : Data Preparation Complete.
The main dataset (training_log.csv) combines user features, dynamic context (e.g., is_morning), product ID, and the interaction result (response):
| event_id | age | … | traffic_source_Search | is_morning | is_weekend | is_weekday | product_id | response |
|---|---|---|---|---|---|---|---|---|
| 1 | 0.5925926 | … | 1 | 1 | 0 | 1 | 182 | 0 |
| 2 | 0.6111111 | … | 1 | 0 | 0 | 1 | 101 | 0 |
| 3 | 0.6296296 | … | 1 | 0 | 0 | 1 | 34 | 0 |
| 4 | 0.4814815 | … | 0 | 0 | 0 | 1 | 101 | 0 |
Offline Policy Evaluation
We benchmarked several policies using Mab2Rec on the 10,000 historical events.
The Candidates
- Random: The baseline. Recommends items blindly.
- Popularity: Recommends items with the highest global click rate.
- Result: Mediocre (AUC ~0.59). While better than random, it still fails to capture specific rules, such as “Morning Coffee” vs. “Weekend Pizza.”
- LinGreedy: Disjoint Linear Regression with $\epsilon$-greedy exploration.
- LinUCB (The Winner): Disjoint Linear Regression with Upper Confidence Bound.
- LinTS (Thompson Sampling): Bayesian regression that samples from a probability distribution.
Winner: LinUCB
While LinGreedy achieved the highest theoretical ranking accuracy (AUC ~0.88), it suffered from a low click rate (CTR ~11%) because it exploited “safe” choices too early.
LinUCB is the practical winner. It achieved a comparable ranking accuracy (AUC ~0.86) but nearly double the engagement (CTR ~20.5%) to LinGreedy.
This algorithm excels because it balances two competing goals:
- Exploitation: It uses the predicted probability of a click ($x^T \theta$) to find good items.
- Exploration: It adds a confidence interval ($\alpha \sqrt{x^T A^{-1} x}$) to the score. If the model is uncertain about a specific context (e.g., “I haven’t seen a user drink Coffee at 8 PM before”), the interval widens, boosting the score and forcing the model to test that hypothesis.
This allows LinUCB to discover high-value opportunities that the conservative LinGreedy model misses.
1(venv) $ python product-recommender/recsys-engine/evaluate.py
2Running Benchmark... (This trains and scores all models automatically)
3--------------------------------------------------------------------------------
4Available Metrics: ['AUC(score)@5', 'CTR(score)@5', 'Precision@5', 'Recall@5']
5 AUC(score)@5 CTR(score)@5 Precision@5 Recall@5
6Random 0.550000 0.102041 0.003876 0.019380
7Popularity 0.592857 0.192308 0.007752 0.038760
8LinGreedy 0.885185 0.117647 0.004651 0.023256
9LinUCB 0.860317 0.204545 0.006977 0.034884
10LinTS 0.640798 0.211538 0.008527 0.042636
11ClustersTS 0.550505 0.153846 0.004651 0.023256
12--------------------------------------------------------------------------------
Why LinUCB Outperforms the Baseline in CTR
This is the core concept of Offline Policy Evaluation.
The benchmark does not test on every single row of your history. It uses a technique called Rejection Sampling (or simply “Matching”).
Here is exactly how mab2rec calculates that 20.5%:
The Log (History): Contains a mix of “Good Decisions” and “Bad Decisions” because it was generated randomly.
- Row A: Morning User $\to$ Show Pizza $\to$ No Click (Bad Random Choice)
- Row B: Morning User $\to$ Show Coffee $\to$ Click (Lucky Random Choice)
The Test (LinUCB): The model is smart. It knows Morning users want Coffee.
- For Row A, LinUCB says: “I would recommend Coffee.”
- Mismatch! The history shows Pizza. We cannot know what would have happened if we showed Coffee. This row is IGNORED.
- For Row B, LinUCB says: “I would recommend Coffee.”
- Match! The history shows Coffee. We know the result (Click). This row is COUNTED.
- For Row A, LinUCB says: “I would recommend Coffee.”
The dataset average (13.7%) includes all the “Bad Random Choices” (Row A). The LinUCB score (20.5%) filters out the bad choices. It effectively says: “On the rare occasions where the random history actually showed the right product (Row B), did the user click?” Since LinUCB focuses only on the “Right Products,” the click rate for those specific matches is much higher than the average of the random pile.
Simulation of the Selected Product Recommender Locally
With the model selected, we built a script to simulate the product recommender locally. This script acts as the Server, the User, and the Trainer simultaneously in a continuous loop.
Step 1: Pre-training (Offline Replay)
We don’t want to start with a “dumb” model. We load the 10,000 historical events (training_log.csv) and run model.fit(). This gives the bandit a baseline knowledge of the world before the live loop begins.
Step 2: The Online Loop
We simulate a sequence of user visits:
- User Arrival: Pick a random user from the pool.
- Contextualize: Inject a simulated timestamp (e.g., varying between Mon 08:00 AM and Sat 09:00 PM). This is the key “Context” the model must react to.
- Recommend: LinUCB calculates scores for all 200 products and returns the Top 5.
- Reaction: The
GroundTruthOracle decides if the user clicks. - Online Update: We call
model.partial_fit(). This updates the matrices ($A$ and $b$) instantly. The very next recommendation will reflect this new learning.
Here is a sample of 30 recommendation records from the local simulation.
1(venv) $ python product-recommender/recsys-engine/local_recommender.py
2[2026-02-05 15:47:43] INFO : Loaded 1000 users
3[2026-02-05 15:47:43] INFO : Loading artifacts...
4[2026-02-05 15:47:48] INFO : Loaded 200 products.
5[2026-02-05 15:47:48] INFO : Pre-training model from history...
6[2026-02-05 15:47:48] INFO : Model pre-trained on 10000 events.
7
8--- STARTING LIVE LOOP (30 visits) ---
9
10User 0153 (56 yo) @ Fri 00:58 -> Recs: [200, 124, 015, 058, 011] -> Clicked: 200 (❌)
11User 0909 (21 yo) @ Sat 15:53 -> Recs: [038, 040, 017, 020, 046] -> Clicked: 038 (❌)
12User 0406 (30 yo) @ Sat 05:24 -> Recs: [020, 041, 008, 055, 040] -> Clicked: 020 (✅)
13User 0317 (31 yo) @ Sat 05:38 -> Recs: [008, 055, 057, 059, 139] -> Clicked: 055 (✅)
14User 0246 (44 yo) @ Mon 02:04 -> Recs: [015, 058, 057, 011, 124] -> Clicked: 015 (❌)
15User 0974 (61 yo) @ Fri 01:16 -> Recs: [058, 073, 124, 074, 051] -> Clicked: 058 (❌)
16User 0234 (26 yo) @ Thu 12:16 -> Recs: [036, 103, 002, 186, 070] -> Clicked: 036 (❌)
17User 0360 (35 yo) @ Sat 20:23 -> Recs: [058, 051, 008, 042, 018] -> Clicked: 042 (✅)
18User 0513 (51 yo) @ Sun 05:37 -> Recs: [051, 059, 043, 014, 020] -> Clicked: 051 (✅)
19User 0640 (33 yo) @ Mon 00:49 -> Recs: [073, 124, 023, 147, 074] -> Clicked: 073 (❌)
20User 0363 (31 yo) @ Fri 23:35 -> Recs: [200, 126, 085, 058, 018] -> Clicked: 018 (✅)
21User 0718 (58 yo) @ Sat 23:05 -> Recs: [018, 036, 040, 042, 020] -> Clicked: 018 (✅)
22User 0390 (49 yo) @ Tue 00:56 -> Recs: [147, 165, 020, 089, 047] -> Clicked: 147 (❌)
23User 0425 (39 yo) @ Thu 03:59 -> Recs: [147, 165, 062, 028, 055] -> Clicked: 147 (❌)
24User 0792 (21 yo) @ Sun 23:28 -> Recs: [042, 056, 018, 043, 046] -> Clicked: 042 (✅)
25User 0190 (41 yo) @ Sat 10:54 -> Recs: [192, 139, 189, 008, 055] -> Clicked: 192 (✅)
26User 0544 (41 yo) @ Tue 20:42 -> Recs: [018, 058, 090, 043, 147] -> Clicked: 018 (❌)
27User 0192 (17 yo) @ Sat 18:38 -> Recs: [042, 056, 018, 046, 043] -> Clicked: 042 (✅)
28User 0757 (55 yo) @ Thu 16:08 -> Recs: [015, 171, 165, 037, 126] -> Clicked: 126 (✅)
29User 0904 (60 yo) @ Sat 02:07 -> Recs: [103, 041, 017, 042, 057] -> Clicked: 042 (✅)
30User 0552 (39 yo) @ Tue 11:33 -> Recs: [192, 190, 189, 194, 193] -> Clicked: 192 (✅)
31User 0540 (36 yo) @ Sat 08:56 -> Recs: [043, 041, 192, 014, 073] -> Clicked: 043 (✅)
32User 0326 (26 yo) @ Wed 13:04 -> Recs: [015, 171, 165, 023, 126] -> Clicked: 015 (❌)
33User 0834 (29 yo) @ Sat 22:58 -> Recs: [051, 002, 042, 058, 036] -> Clicked: 051 (✅)
34User 0290 (21 yo) @ Mon 19:09 -> Recs: [058, 200, 004, 018, 085] -> Clicked: 018 (✅)
35User 0275 (18 yo) @ Wed 11:10 -> Recs: [189, 002, 160, 078, 103] -> Clicked: 189 (❌)
36User 0327 (23 yo) @ Wed 19:54 -> Recs: [200, 126, 018, 085, 058] -> Clicked: 200 (❌)
37User 0144 (67 yo) @ Thu 12:31 -> Recs: [087, 126, 047, 103, 034] -> Clicked: 087 (❌)
38User 0497 (60 yo) @ Sun 08:26 -> Recs: [192, 139, 008, 189, 059] -> Clicked: 192 (✅)
39User 0508 (64 yo) @ Tue 12:41 -> Recs: [165, 087, 026, 171, 037] -> Clicked: 165 (❌)
40
41--- END LOOP ---
Evaluation of Simulation
The system is behaving exactly as a Contextual Bandit should. It is aggressively exploiting known high-probability zones while struggling (realistically) in neutral zones.
The “Weekend Pizza” Strategy is Dominant
The model has learned that Weekends (Sat/Sun) are for Pizzas (Category 40s).
- User 0360 (Sat 20:23): Recommended
[..., 042 (Aussie Pizza), ...]$\to$ Clicked ✅. - User 0513 (Sun 05:37): Recommended
[051 (Buffalo Pizza), 059 (Lamb Pizza)...]$\to$ Clicked ✅. - User 0834 (Sat 22:58): Recommended
[051 (Buffalo Pizza)... 042 (Aussie Pizza)]$\to$ Clicked ✅. - Insight: The model pushes Pizzas hard on weekends regardless of the specific hour, resulting in a very high conversion rate for these users.
The “Morning Coffee” Precision
The model correctly switches strategies based on the hour, even distinguishing “Weekend Morning” from “Weekend Night”.
- User 0552 (Tue 11:33): It is a Weekday Morning. The model recommended 5 Coffees
[192, 190, 189, 194, 193]. The user clicked192(Long Black). ✅ - User 0497 (Sun 08:26): It is a Weekend, but it is Morning. The model prioritized Coffee (192, 189) over Pizza. The user clicked
192. ✅ - User 0508 (Tue 12:41): This is a great edge case. It is 41 minutes past the “Morning” cutoff (12:00). The model stopped recommending Coffee and switched to Lunch items (Steamed Veggies, Burritos). The user did not click ❌, but the behavior change proves the features are working perfectly.
Perfect Recommendation, No Interaction (Realism)
- User 0275 (Wed 11:10): The model recommended
189(Flat White). However, the user ignored it, and the result was ❌ (No Reward). - Why? This mimics real life. Even if the recommendation is perfect, users don’t always convert. In the
GroundTruth, the probability caps at ~50% (sigmoid of 0). This “Bad Luck” outcome confirms your evaluation pipeline is honest.
Conclusion
Across 30 simulated visits, CTR reached 53%.
This elevated CTR indicates that the model has internalized dominant temporal and demographic patterns encoded in the simulation. It aggressively exploits strong signals such as weekend pizza and morning coffee while still exploring less-certain regions.
Importantly, the simulation includes realistic noise. Even strong recommendations do not always convert, reflecting probabilistic user behavior.
What’s Next?
We have successfully prototyped a Contextual Bandit that learns time-based preferences. However, this Python script has major limitations for a production environment:
- Scalability:
Disjoint LinUCBmaintains a matrix for every product. With 10 million products, a single server will run out of memory. - Latency: The training (
partial_fit) blocks the inference (recommend). In a real system, you cannot make a user wait for the model to update. - Fault Tolerance: If the script crashes, the learned state is lost.
- Concurrency: A single Python process cannot handle thousands of concurrent requests.
In Part 2, we will transform this prototype into an Event-Driven Architecture:
- Kafka will transport click events asynchronously.
- Flink will handle distributed, stateful model training.
- Redis will serve the model matrices for sub-millisecond inference.
Stay tuned!










Comments